- Information extraction methods from network sources

Содержание
- 2. Содержание 4 What Is the Web? 1 2 3 5 6 WEB 2.0 The Bow Tie
- 3. What Is the Web?
- 4. What Is the Web 4 How do you think: Is there some difference between WWW and
- 5. What Is the Web The World Wide Web (WWW) is an open source information space where
- 6. WEB structure and content The basic units - connected (nodes) are pieces of information The edges
- 7. Size of the Web Number of pages Technically, infinite (because of dynamically generated content) Much duplication
- 8. Size of the Web http://www.worldwidewebsize.com/ The size of the World Wide Web: Estimated size of Google's
- 9. Size of the Web http://www.worldwidewebsize.com/ The size of the World Wide Web: Estimated size of Google's
- 10. Size of the Web http://www.internetlivestats.com/total-number-of-websites/ 9
- 11. How Many People Would It Take Memorise The Internet? Size of the Web If the web
- 12. To appreciate the task of WEB search and analysis we need some structure to view the
- 13. The web as a graph Pages = nodes, hyperlinks = edges Ignore content Directed graph High
- 14. What can the graph tell us? Distinguish “important” pages from unimportant ones Page rank Discover communities
- 15. What can the graph tell us? PageRank is an algorithm used by Google Search to rank
- 16. What can the graph tell us? The picture is illustrating the basic principle of PageRank. The
- 17. What can the graph tell us? Entities that many other entities point to are called Authorities.
- 18. What can the graph tell us? TrustRank is a link analysis technique described by researchers of
- 19. Back to the web Created by Tim Burners-Lee A research project in 1989-1991 at CERN An
- 20. The web as a network The nodes are documents (pages) The edges are links How do
- 21. Hypertext (The coolest thing about the web)
- 22. Different ways to manage information Alphabetically Hierarchy (like folders) Classification systems All of these have one
- 23. Earlier non linear connections Academic references (also in legal decisions and patents) Relevant to the web?
- 24. Memex Vannevar Bush, 1945 Article: “As We May Think” Our memory is not linear. Hypothetical model
- 25. Changes in the web over time
- 26. Static pages >> Query (dynamic) pages In the early days – static pages of contact Today?
- 27. Importance of static pages “The Backbone of the Internet” Reliable over time Include most links Navigational
- 28. The web as a directed graph Viewing social and economic networks in terms of their graph
- 29. What is a path in a directed graph? “A Path from node A to a node
- 30. What is Strong Connectivity in a directed graph? “A directed graph is Strongly connected if there
- 31. The Concept of Reachability Since connectivity does not describe all of the connections in a graph,
- 32. Strongly connected components Parts of a graph that have strong connectivity In other words – a
- 33. How does all that help us understand the web? We can map reachability using the super-graph
- 34. The Bow Tie Structure
- 35. History of Bow Tie model Created in 1999 by Andrei Broder and his colleagues from IBM,
- 36. Web graph structure Web may be considered to have five major components Central core – strongly
- 37. Web graph structure Tendrils – cannot reach SCC and cannot be reached by it - about
- 38. The bow tie structure
- 39. Different kinds of nodes In the SCC In the “inbound” part In the “outbound” part Tendrils
- 40. Некоторые дополнительные факты Итак, в рамках общей задачи определения структуры связей между отдельными веб-страницами было выявлено:
- 41. Неизменность пропорций и алгоритмов Было обнаружено, что пропорции названных категорий в течение нескольких месяцев оставались неизменными,
- 42. Закономерности модели Bow Tie Оказалось, что распределение степеней узлов (входящих и исходящих гиперссылок) веб-пространства (исследовались сайты
- 43. Ограничения модели Bow Tie Модель Брёдера не учитывает особенностей динамической части веб-пространства, формируемой потоками новостных сообщений.
- 44. Web 2.0
- 45. What is web 2.0? A concept made popular by Tim O’railey in 2004 Basically – the
- 46. Different implications of web 2.0 Wikipedia grew rapidly during this period, as people embraced the idea
- 47. Different implications of web 2.0 “Software that gets better as more people use it” “The wisdom
- 48. Different implications of web 2.0 The Long Tail («длинный хвост») — устоявшийся термин, пришедший из статистики
- 49. A little bit more about the structure of the web From: Albert R., Jeong H, &
- 50. About the research Trying to map reachability on the web Their main finding – the probability
- 51. Невидимый WEB
- 52. Размер невидимого Интернета оценивается в 70% размеров сети. Глубокая паутина (также известна как невидимая сеть) —
- 53. С учетом изменений в вебе, которые произошли за последние десять лет, «невидимый» интернет грубо можно поделить
- 54. Кроме полезного и содержательного с профессиональной точки зрения "Невидимого WEB" существует еще неиндексируемый интернет с невидимыми
- 55. Tor обеспечивает анонимное сетевое соединение, исключающее перехват данных и идентификацию пользователей посторонними. Анонимность трафика достигается за
- 56. Поисковики не могут обнаружить несколько видов информации. Несколько наиболее актуальных примеров: Динамически создаваемые страницы Исключенные страницы
- 57. Динамически создаваемые страницы Это страницы, которые не могут быть получены на основе алгоритмов поисковых систем. Например,
- 58. Исключенные страницы Некоторые владельцы сайтов предпочитают избегать появления тех или иных Web страниц сайтов в поисковых
- 59. Физическое ограничение скорости. Поисковые машины имеют физические ограничения по скорости поиска новых страниц. Ежесекундно идет негласное
- 60. Базы данных Большая часть мира структурированных данных была организована в БД, которые полностью доступны, но требуют
- 61. Принцип попадания страниц в индекс при помощи пауков. Паук попадает только на те страницы, на которые
- 62. «Невидимый интернет» является наиболее интересной частью интернета не только для конкурентной разведки, но и для подавляющего
- 63. Но начнем мы с нескольких русскоязычных инструментов (наши специалисты тоже не бездействуют), хотя и попытки эти
- 64. Программа Алексея Мыльникова SiteSputnik + Invisible. По ссылке http://sitesputnik.ru/ можно протестировать демоверсию программы. Инструменты и технологии
- 65. В 2006 году Google получил патент на Поиск баз данных через формы-интерфейсы. Однако, как показали исследования
- 66. Одновременно, развивается целый ряд поисковиков, в основном связанных с текстовыми публикациями по самым различным отраслям бизнеса,
- 67. Задание № 1 Выполнить поиск по тематике своей магистерской работы, используя: Демо-версию программы FileForFiles & SiteSputnik
- 68. Задание № 1 Образец личной страницы: Инструменты и технологии работы в «Невидимом интернете»
- 70. Скачать презентацию

Содержание
4
What Is the Web?
1
2
3
5
6
WEB 2.0
The Bow Tie Structure
DEEP WEB
WEB structure and
Содержание
4
What Is the Web?
1
2
3
5
6
WEB 2.0
The Bow Tie Structure
DEEP WEB
WEB structure and

What Is the Web?
What Is the Web?

What Is the Web
4
How do you think:
Is there some difference between
What Is the Web
4
How do you think:
Is there some difference between

What Is the Web
The World Wide Web (WWW) is
an open
What Is the Web
The World Wide Web (WWW) is
an open

WEB structure and content
The basic units - connected (nodes) are pieces
WEB structure and content
The basic units - connected (nodes) are pieces

Size of the Web
Number of pages
Technically, infinite (because of dynamically generated
Size of the Web
Number of pages
Technically, infinite (because of dynamically generated
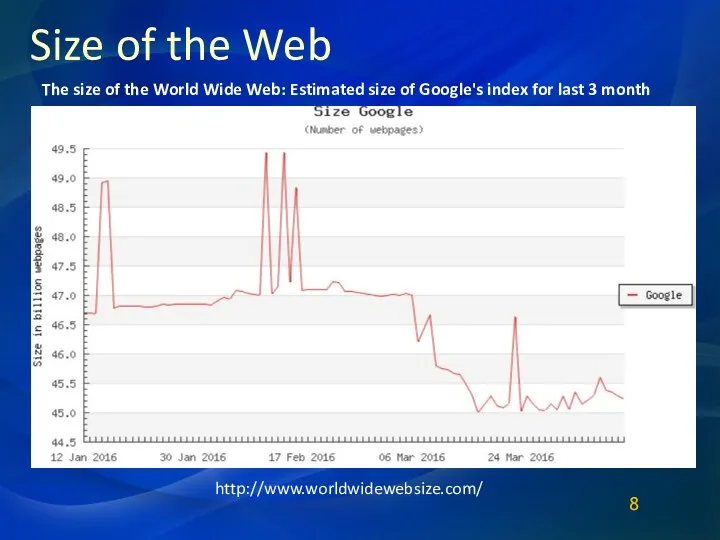
Size of the Web
http://www.worldwidewebsize.com/
The size of the World Wide Web: Estimated
Size of the Web
http://www.worldwidewebsize.com/
The size of the World Wide Web: Estimated
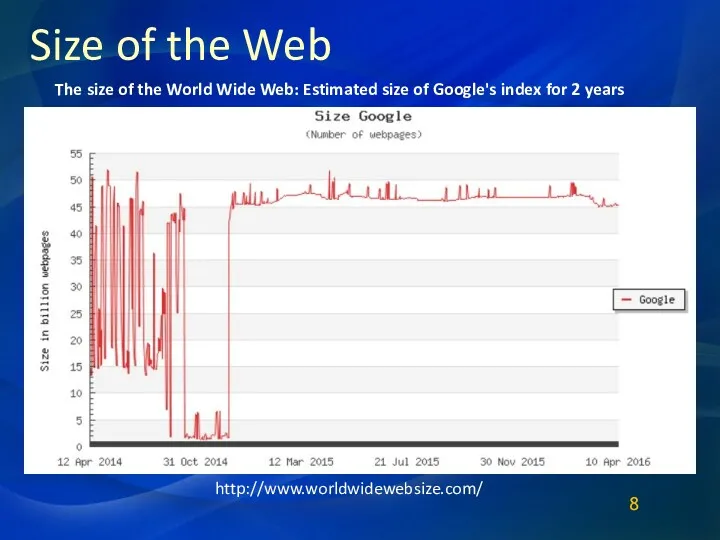
Size of the Web
http://www.worldwidewebsize.com/
The size of the World Wide Web: Estimated
Size of the Web
http://www.worldwidewebsize.com/
The size of the World Wide Web: Estimated
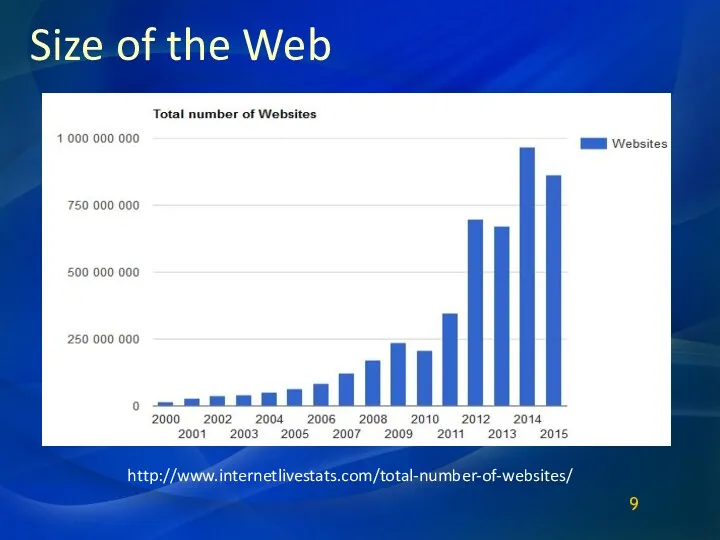
Size of the Web
http://www.internetlivestats.com/total-number-of-websites/
9
Size of the Web
http://www.internetlivestats.com/total-number-of-websites/
9

How Many People Would It Take Memorise The Internet?
Size of the
How Many People Would It Take Memorise The Internet?
Size of the

To appreciate the task of WEB search and analysis we need
To appreciate the task of WEB search and analysis we need

The web as a graph
Pages = nodes, hyperlinks = edges
Ignore content
Directed
The web as a graph
Pages = nodes, hyperlinks = edges
Ignore content
Directed

What can the graph tell us?
Distinguish “important” pages from unimportant ones
Page
What can the graph tell us?
Distinguish “important” pages from unimportant ones
Page

What can the graph tell us?
PageRank is an algorithm used by
What can the graph tell us?
PageRank is an algorithm used by

What can the graph tell us?
The picture is illustrating the basic
What can the graph tell us?
The picture is illustrating the basic

What can the graph tell us?
Entities that many other entities point
What can the graph tell us?
Entities that many other entities point
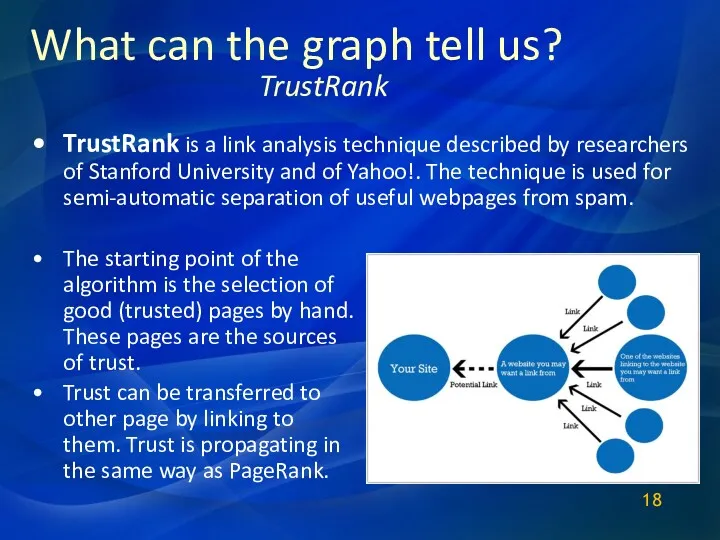
What can the graph tell us?
TrustRank is a link analysis technique
What can the graph tell us?
TrustRank is a link analysis technique

Back to the web
Created by Tim Burners-Lee
A research project in 1989-1991
Back to the web
Created by Tim Burners-Lee
A research project in 1989-1991
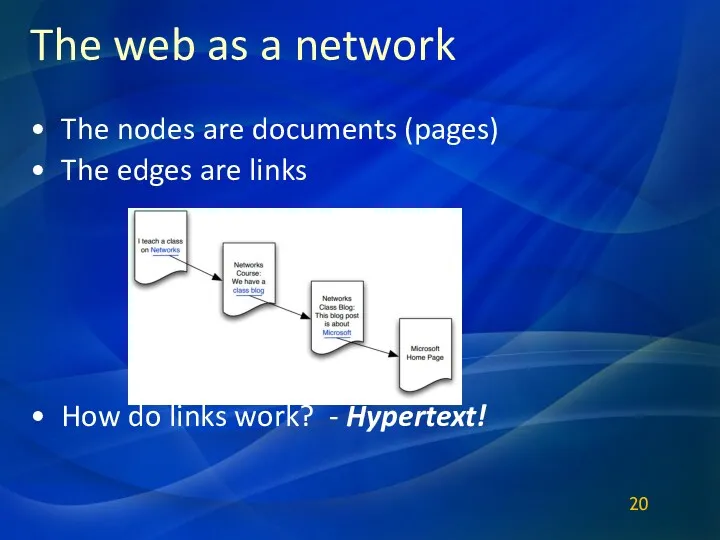
The web as a network
The nodes are documents (pages)
The edges are
The web as a network
The nodes are documents (pages)
The edges are

Hypertext
(The coolest thing about the web)
Hypertext
(The coolest thing about the web)

Different ways to manage information
Alphabetically
Hierarchy (like folders)
Classification systems
All of these have
Different ways to manage information
Alphabetically
Hierarchy (like folders)
Classification systems
All of these have
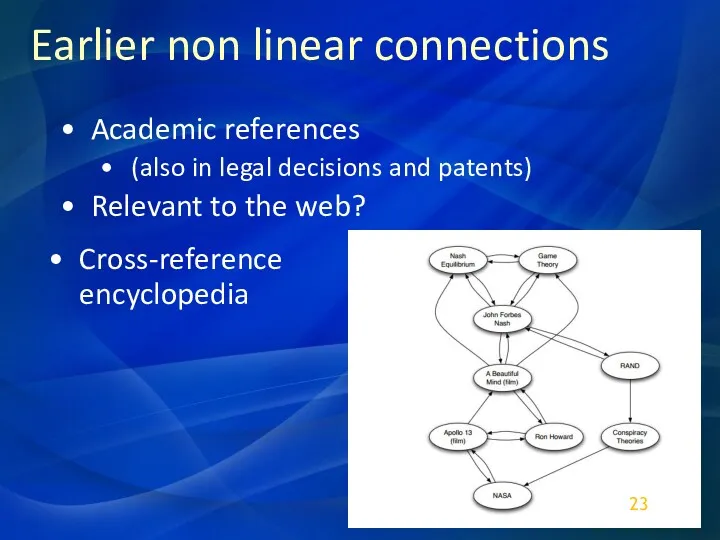
Earlier non linear connections
Academic references
(also in legal decisions and patents)
Relevant to
Earlier non linear connections
Academic references
(also in legal decisions and patents)
Relevant to

Memex
Vannevar Bush, 1945 Article: “As We May Think”
Our memory is
Memex
Vannevar Bush, 1945 Article: “As We May Think”
Our memory is

Changes in the web over time
Changes in the web over time

Static pages >> Query (dynamic) pages
In the early days – static
Static pages >> Query (dynamic) pages
In the early days – static

Importance of static pages
“The Backbone of the Internet”
Reliable over time
Include most
Importance of static pages
“The Backbone of the Internet”
Reliable over time
Include most

The web as a directed graph
Viewing social and economic networks in
The web as a directed graph
Viewing social and economic networks in

What is a path in a directed graph?
“A Path from node
What is a path in a directed graph?
“A Path from node

What is Strong Connectivity in a directed graph?
“A directed graph is
What is Strong Connectivity in a directed graph?
“A directed graph is

The Concept of Reachability
Since connectivity does not describe all of the
The Concept of Reachability
Since connectivity does not describe all of the

Strongly connected components
Parts of a graph that have strong connectivity
In other
Strongly connected components
Parts of a graph that have strong connectivity
In other
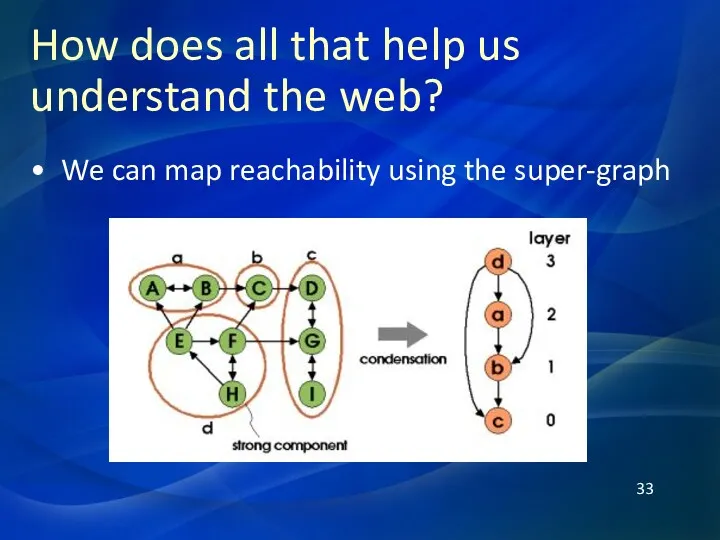
How does all that help us understand the web?
We can map
How does all that help us understand the web?
We can map

The Bow Tie Structure
The Bow Tie Structure

History of Bow Tie model
Created in 1999 by Andrei Broder
History of Bow Tie model
Created in 1999 by Andrei Broder

Web graph structure
Web may be considered to have five major components
Central
Web graph structure
Web may be considered to have five major components
Central

Web graph structure
Tendrils – cannot reach SCC and cannot be reached
Web graph structure
Tendrils – cannot reach SCC and cannot be reached
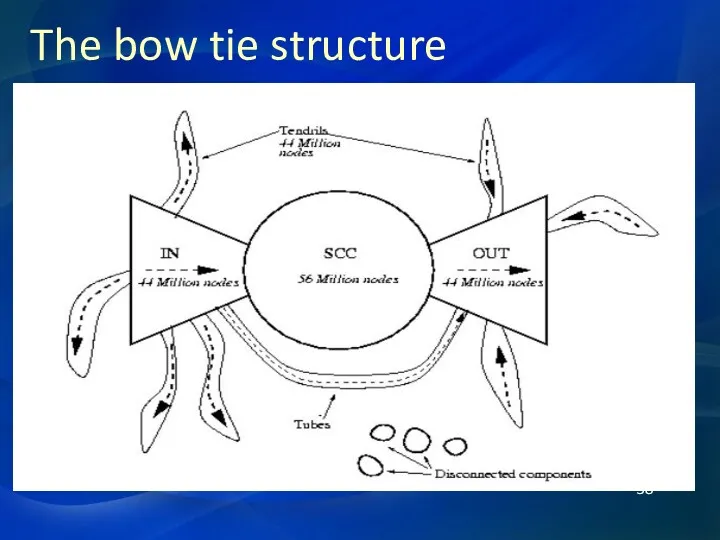
The bow tie structure
The bow tie structure
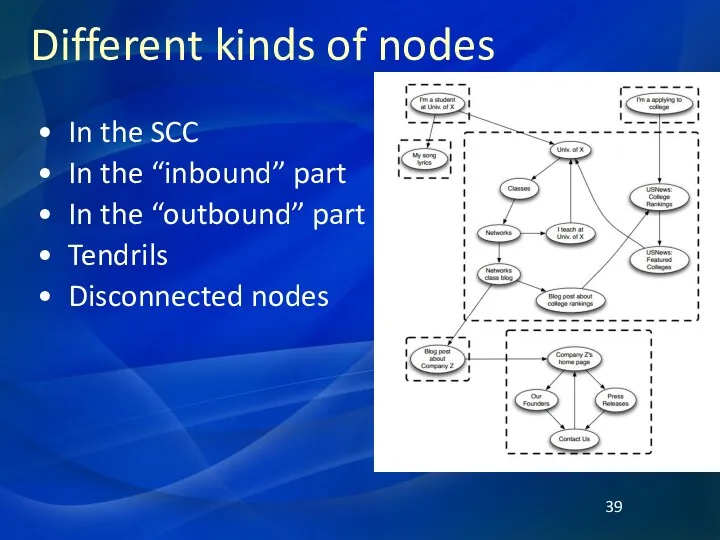
Different kinds of nodes
In the SCC
In the “inbound” part
In the “outbound”
Different kinds of nodes
In the SCC
In the “inbound” part
In the “outbound”

Некоторые дополнительные факты
Итак, в рамках общей задачи определения структуры связей между
Некоторые дополнительные факты
Итак, в рамках общей задачи определения структуры связей между

Неизменность пропорций и алгоритмов
Было обнаружено, что пропорции названных категорий в течение
Неизменность пропорций и алгоритмов
Было обнаружено, что пропорции названных категорий в течение

Закономерности модели Bow Tie
Оказалось, что распределение степеней узлов (входящих и исходящих
Закономерности модели Bow Tie
Оказалось, что распределение степеней узлов (входящих и исходящих

Ограничения модели Bow Tie
Модель Брёдера не учитывает особенностей динамической части веб-пространства,
Ограничения модели Bow Tie
Модель Брёдера не учитывает особенностей динамической части веб-пространства,

Web 2.0
Web 2.0

What is web 2.0?
A concept made popular by Tim O’railey in
What is web 2.0?
A concept made popular by Tim O’railey in

Different implications of web 2.0
Wikipedia grew rapidly during this period, as
Different implications of web 2.0
Wikipedia grew rapidly during this period, as
Different implications of web 2.0
“Software that gets better as more people
Different implications of web 2.0
“Software that gets better as more people

Different implications of web 2.0
The Long Tail («длинный хвост») — устоявшийся термин,
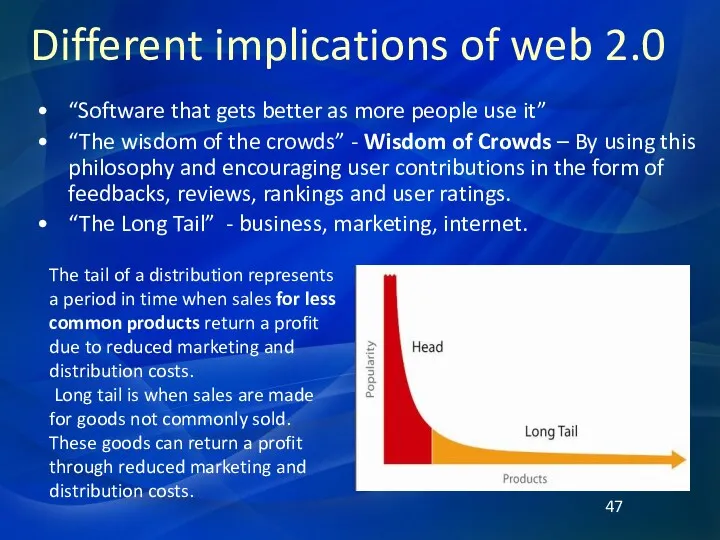
Different implications of web 2.0
The Long Tail («длинный хвост») — устоявшийся термин,

A little bit more about the structure of the web
From: Albert
A little bit more about the structure of the web
From: Albert
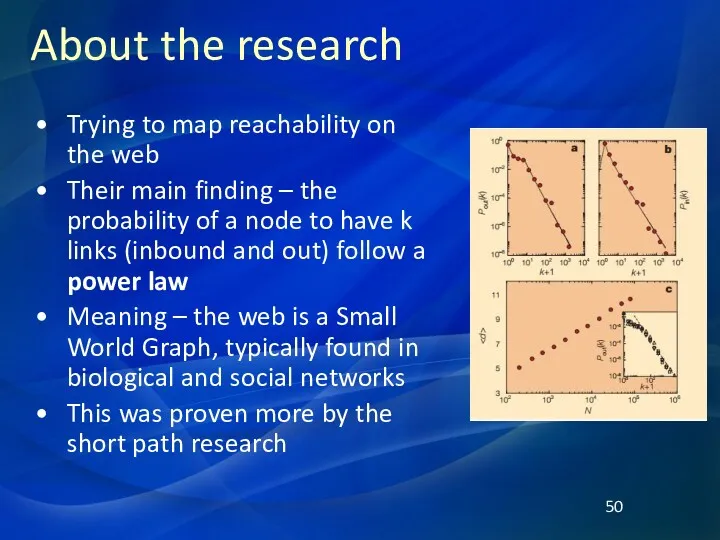
About the research
Trying to map reachability on the web
Their main finding
About the research
Trying to map reachability on the web
Their main finding

Невидимый WEB
Невидимый WEB

Размер невидимого Интернета оценивается в 70% размеров сети.
Глубокая паутина (также
Размер невидимого Интернета оценивается в 70% размеров сети.
Глубокая паутина (также

С учетом изменений в вебе, которые произошли за последние десять лет,
С учетом изменений в вебе, которые произошли за последние десять лет,

Кроме полезного и содержательного с профессиональной точки зрения "Невидимого WEB" существует
Кроме полезного и содержательного с профессиональной точки зрения "Невидимого WEB" существует

Tor обеспечивает анонимное сетевое соединение, исключающее перехват данных и идентификацию пользователей
Tor обеспечивает анонимное сетевое соединение, исключающее перехват данных и идентификацию пользователей

Поисковики не могут обнаружить несколько видов информации. Несколько наиболее актуальных примеров:
Динамически
Поисковики не могут обнаружить несколько видов информации. Несколько наиболее актуальных примеров:
Динамически

Динамически создаваемые страницы
Это страницы, которые не могут быть получены на
Динамически создаваемые страницы
Это страницы, которые не могут быть получены на

Исключенные страницы
Некоторые владельцы сайтов предпочитают избегать появления тех или иных
Исключенные страницы
Некоторые владельцы сайтов предпочитают избегать появления тех или иных

Физическое ограничение скорости.
Поисковые машины имеют физические ограничения по скорости
Физическое ограничение скорости.
Поисковые машины имеют физические ограничения по скорости

Базы данных
Большая часть мира структурированных данных была организована в БД,
Базы данных
Большая часть мира структурированных данных была организована в БД,

Принцип попадания страниц в индекс при помощи пауков.
Паук попадает только на
Принцип попадания страниц в индекс при помощи пауков.
Паук попадает только на

«Невидимый интернет» является наиболее интересной частью интернета не только для конкурентной
«Невидимый интернет» является наиболее интересной частью интернета не только для конкурентной

Но начнем мы с нескольких русскоязычных инструментов (наши специалисты тоже не
Но начнем мы с нескольких русскоязычных инструментов (наши специалисты тоже не
Программа Алексея Мыльникова SiteSputnik + Invisible. По ссылке http://sitesputnik.ru/ можно протестировать
Программа Алексея Мыльникова SiteSputnik + Invisible. По ссылке http://sitesputnik.ru/ можно протестировать

В 2006 году Google получил патент на Поиск баз данных через
В 2006 году Google получил патент на Поиск баз данных через

Одновременно, развивается целый ряд поисковиков, в основном связанных с текстовыми публикациями
Одновременно, развивается целый ряд поисковиков, в основном связанных с текстовыми публикациями

Задание № 1
Выполнить поиск по тематике своей магистерской работы, используя:
Демо-версию программы
Задание № 1
Выполнить поиск по тематике своей магистерской работы, используя:
Демо-версию программы
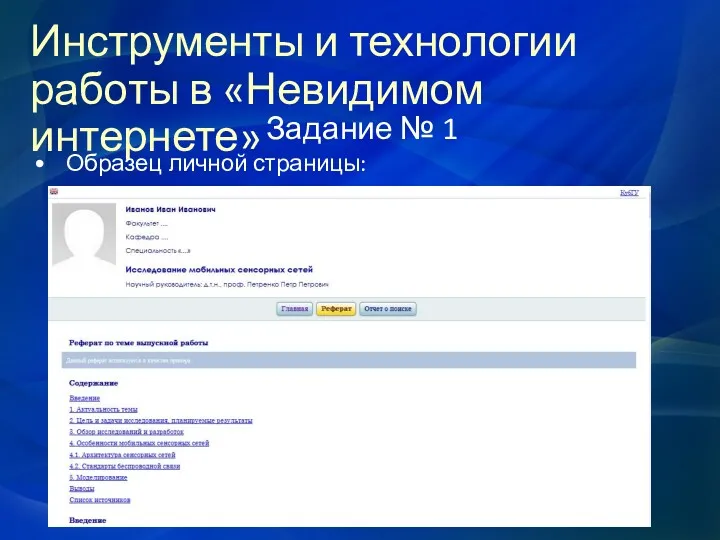
Задание № 1
Образец личной страницы:
Инструменты и технологии работы в «Невидимом интернете»
Задание № 1
Образец личной страницы:
Инструменты и технологии работы в «Невидимом интернете»
 Higher Education in England
Higher Education in England Союзы в английском языке
Союзы в английском языке My favorite clothes
My favorite clothes R. Kipling. Literature If - Если. 11 класс
R. Kipling. Literature If - Если. 11 класс Intellectual property “Know your rights”
Intellectual property “Know your rights” Summer. What do we usually do in the summer?
Summer. What do we usually do in the summer? Writing letters
Writing letters Пасха в России and Easter in England
Пасха в России and Easter in England What is your favourite season
What is your favourite season Social philosophy
Social philosophy Taekwon-Do ITF (International Taekwon-do Federation) and WTF (World Taekwon-do Federation)
Taekwon-Do ITF (International Taekwon-do Federation) and WTF (World Taekwon-do Federation) Welcome to cad/cam services
Welcome to cad/cam services The Present Continuous
The Present Continuous Present Simple
Present Simple How to write a clause. Helpful information for delegates
How to write a clause. Helpful information for delegates My Future Company
My Future Company The State Hermitage Museum
The State Hermitage Museum Computers for the disabled
Computers for the disabled My family
My family Adverbs of frequency conversation topics dialogs grammar guides
Adverbs of frequency conversation topics dialogs grammar guides Imagine that you are a member of a school ecological club. You took these photos. Present one photo to your friend
Imagine that you are a member of a school ecological club. You took these photos. Present one photo to your friend Saint Patrick`s Day
Saint Patrick`s Day Lesson 1. Nice to meet you! A1 group
Lesson 1. Nice to meet you! A1 group Ukraine
Ukraine The noun
The noun ‘For and Against’ Essay
‘For and Against’ Essay Verbs. What is a verb
Verbs. What is a verb Robots. Etymology
Robots. Etymology