- Ericson Memory Optimization

Содержание
- 2. Talk contents 1/2 Problem statement Why “memory optimization?” Brief architecture overview The memory hierarchy Optimizing for
- 3. Talk contents 2/2 … Aliasing Abstraction penalty problem Alias analysis (type-based) ‘restrict’ pointers Tips for reducing
- 4. Problem statement For the last 20-something years… CPU speeds have increased ~60%/year Memory speeds only decreased
- 5. Need more justification? 1/3 SIMD instructions consume data at 2-8 times the rate of normal instructions!
- 6. Need more justification? 2/3 Improvements to compiler technology double program performance every ~18 years! Proebsting’s law:
- 7. Need more justification? 3/3 On Moore’s law: Consoles don’t follow it (as such) Fixed hardware 2nd/3rd
- 8. Brief cache review Caches Code cache for instructions, data cache for data Forms a memory hierarchy
- 9. The memory hierarchy Main memory L2 cache L1 cache CPU ~1-5 cycles ~5-20 cycles ~40-100 cycles
- 10. Some cache specs †16K data scratchpad important part of design ‡configurable as 16K 4-way + 16K
- 11. Foes: 3 C’s of cache misses Compulsory misses Unavoidable misses when data read for first time
- 12. Friends: Introducing the 3 R’s Rearrange (code, data) Change layout to increase spatial locality Reduce (size,
- 13. Measuring cache utilization Profile CPU performance/event counters Give memory access statistics But not access patterns (e.g.
- 14. Code cache optimization 1/2 Locality Reorder functions Manually within file Reorder object files during linking (order
- 15. Code cache optimization 2/2 Size Beware: inlining, unrolling, large macros KISS Avoid featuritis Provide multiple copies
- 16. Data cache optimization Lots and lots of stuff… “Compressing” data Blocking and strip mining Padding data
- 17. Prefetching and preloading Software prefetching Not too early – data may be evicted before use Not
- 18. Software prefetching
- 19. Greedy prefetching
- 20. Preloading (pseudo-prefetch) (NB: This code reads one element beyond the end of the elem array.)
- 21. Structures Cache-conscious layout Field reordering (usually grouped conceptually) Hot/cold splitting Let use decide format Array of
- 22. Field reordering Likely accessed together so store them together!
- 23. Hot/cold splitting Allocate all ‘struct S’ from a memory pool Increases coherence Prefer array-style allocation No
- 24. Hot/cold splitting
- 25. Beware compiler padding Assuming 4-byte floats, for most compilers sizeof(X) == 40, sizeof(Y) == 40, and
- 26. Cache performance analysis Usage patterns Activity – indicates hot or cold field Correlation – basis for
- 27. Tree data structures Rearrange nodes Increase spatial locality Cache-aware vs. cache-oblivious layouts Reduce size Pointer elimination
- 28. Breadth-first order Pointer-less: Left(n)=2n, Right(n)=2n+1 Requires storage for complete tree of height H
- 29. Depth-first order Left(n) = n + 1, Right(n) = stored index Only stores existing nodes
- 30. van Emde Boas layout “Cache-oblivious” Recursive construction
- 31. A compact static k-d tree union KDNode { // leaf, type 11 int32 leafIndex_type; // non-leaf,
- 32. Linearization caching Nothing better than linear data Best possible spatial locality Easily prefetchable So linearize data
- 34. Memory allocation policy Don’t allocate from heap, use pools No block overhead Keeps data together Faster
- 35. The curse of aliasing What is aliasing? Aliasing is also missed opportunities for optimization What value
- 36. The curse of aliasing What is causing aliasing? Pointers Global variables/class members make it worse What
- 37. How do we do ‘anti-aliasing’? What can be done about aliasing? Better languages Less aliasing, lower
- 38. Matrix multiplication 1/3 Consider optimizing a 2x2 matrix multiplication: How do we typically optimize it? Right,
- 39. But wait! There’s a hidden assumption! a is not b or c! Compiler doesn’t (cannot) know
- 40. Matrix multiplication 3/3 A correct approach is instead writing it as: …before producing outputs Consume inputs…
- 41. Abstraction penalty problem Higher levels of abstraction have a negative effect on optimization Code broken into
- 42. C++ abstraction penalty Lots of (temporary) objects around Iterators Matrix/vector classes Objects live in heap/stack Thus
- 43. C++ abstraction penalty Pointer members in classes may alias other members: Code likely to refetch numVals
- 44. C++ abstraction penalty We know that aliasing won’t happen, and can manually solve the aliasing issue
- 45. C++ abstraction penalty Since pBuf[i] can only alias numVals in the first iteration, a quality compiler
- 46. Type-based alias analysis Some aliasing the compiler can catch A powerful tool is type-based alias analysis
- 47. Type-based alias analysis ANSI C/C++ states that… Each area of memory can only be associated with
- 48. Compatibility of C/C++ types In short… Types compatible if differing by signed, unsigned, const or volatile
- 49. What TBAA can do for you into this: It can turn this: Possible aliasing between v[i]
- 50. What TBAA can also do Cause obscure bugs in non-conforming code! Beware especially so-called “type punning”
- 51. Restrict-qualified pointers restrict keyword New to 1999 ANSI/ISO C standard Not in C++ standard yet, but
- 52. Using the restrict keyword Given this code: You really want the compiler to treat it as
- 53. Using the restrict keyword giving for the first version: and for the second version: For example,
- 54. Solving the aliasing problem The fix? Declaring the output as restrict: Alas, in practice may need
- 55. ‘const’ doesn’t help Some might think this would work: Wrong! const promises almost nothing! Says *c
- 56. SIMD + restrict = TRUE restrict enables SIMD optimizations Independent loads and stores. Operations can be
- 57. Restrict-qualified pointers Important, especially with C++ Helps combat abstraction penalty problem But beware… Tricky semantics, easy
- 58. Tips for avoiding aliasing Minimize use of globals, pointers, references Pass small variables by-value Inline small
- 59. That’s it! – Resources 1/2 Ericson, Christer. Real-time collision detection. Morgan-Kaufmann, 2005. (Chapter on memory optimization)
- 61. Скачать презентацию

Talk contents 1/2
Problem statement
Why “memory optimization?”
Brief architecture overview
The memory hierarchy
Optimizing for
Talk contents 1/2
Problem statement
Why “memory optimization?”
Brief architecture overview
The memory hierarchy
Optimizing for

Talk contents 2/2
…
Aliasing
Abstraction penalty problem
Alias analysis (type-based)
‘restrict’ pointers
Tips for reducing aliasing
Talk contents 2/2
…
Aliasing
Abstraction penalty problem
Alias analysis (type-based)
‘restrict’ pointers
Tips for reducing aliasing

Problem statement
For the last 20-something years…
CPU speeds have increased ~60%/year
Memory speeds
Problem statement
For the last 20-something years…
CPU speeds have increased ~60%/year
Memory speeds

Need more justification? 1/3
SIMD instructions consume
data at 2-8 times the rate
of
Need more justification? 1/3
SIMD instructions consume
data at 2-8 times the rate
of

Need more justification? 2/3
Improvements to
compiler technology
double program performance
every ~18 years!
Proebsting’s law:
Corollary:
Need more justification? 2/3
Improvements to
compiler technology
double program performance
every ~18 years!
Proebsting’s law:
Corollary:

Need more justification? 3/3
On Moore’s law:
Consoles don’t follow it (as such)
Fixed
Need more justification? 3/3
On Moore’s law:
Consoles don’t follow it (as such)
Fixed

Brief cache review
Caches
Code cache for instructions, data cache for data
Forms a
Brief cache review
Caches
Code cache for instructions, data cache for data
Forms a
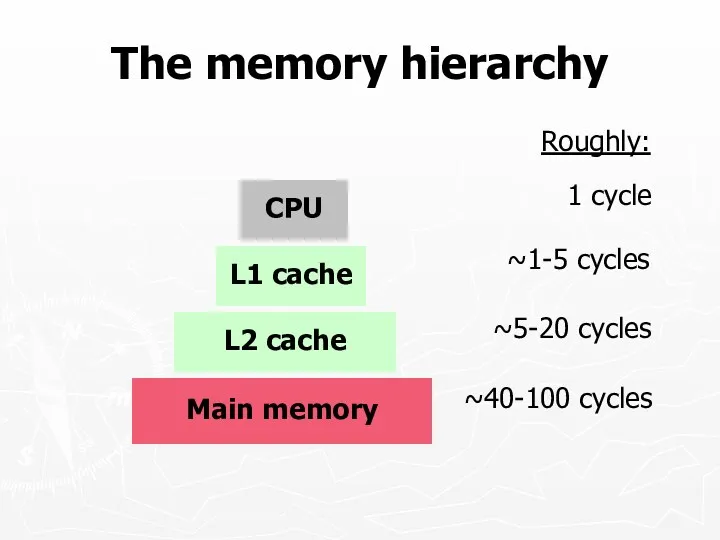
The memory hierarchy
Main memory
L2 cache
L1 cache
CPU
~1-5 cycles
~5-20 cycles
~40-100 cycles
1 cycle
Roughly:
The memory hierarchy
Main memory
L2 cache
L1 cache
CPU
~1-5 cycles
~5-20 cycles
~40-100 cycles
1 cycle
Roughly:
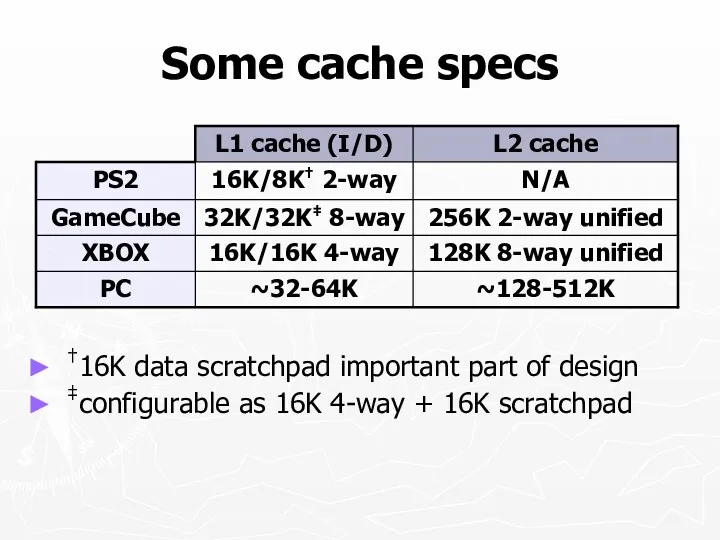
Some cache specs
†16K data scratchpad important part of design
‡configurable as 16K
Some cache specs
†16K data scratchpad important part of design
‡configurable as 16K

Foes: 3 C’s of cache misses
Compulsory misses
Unavoidable misses when data read
Foes: 3 C’s of cache misses
Compulsory misses
Unavoidable misses when data read

Friends: Introducing the 3 R’s
Rearrange (code, data)
Change layout to increase spatial
Friends: Introducing the 3 R’s
Rearrange (code, data)
Change layout to increase spatial

Measuring cache utilization
Profile
CPU performance/event counters
Give memory access statistics
But not access patterns
Measuring cache utilization
Profile
CPU performance/event counters
Give memory access statistics
But not access patterns

Code cache optimization 1/2
Locality
Reorder functions
Manually within file
Reorder object files during linking
Code cache optimization 1/2
Locality
Reorder functions
Manually within file
Reorder object files during linking

Code cache optimization 2/2
Size
Beware: inlining, unrolling, large macros
KISS
Avoid featuritis
Provide multiple copies
Code cache optimization 2/2
Size
Beware: inlining, unrolling, large macros
KISS
Avoid featuritis
Provide multiple copies

Data cache optimization
Lots and lots of stuff…
“Compressing” data
Blocking and strip mining
Padding
Data cache optimization
Lots and lots of stuff…
“Compressing” data
Blocking and strip mining
Padding

Prefetching and preloading
Software prefetching
Not too early – data may be evicted
Prefetching and preloading
Software prefetching
Not too early – data may be evicted

Software prefetching
Software prefetching

Greedy prefetching
Greedy prefetching

Preloading (pseudo-prefetch)
(NB: This code reads one element beyond the end of
Preloading (pseudo-prefetch)
(NB: This code reads one element beyond the end of

Structures
Cache-conscious layout
Field reordering (usually grouped conceptually)
Hot/cold splitting
Let use decide format
Array of
Structures
Cache-conscious layout
Field reordering (usually grouped conceptually)
Hot/cold splitting
Let use decide format
Array of
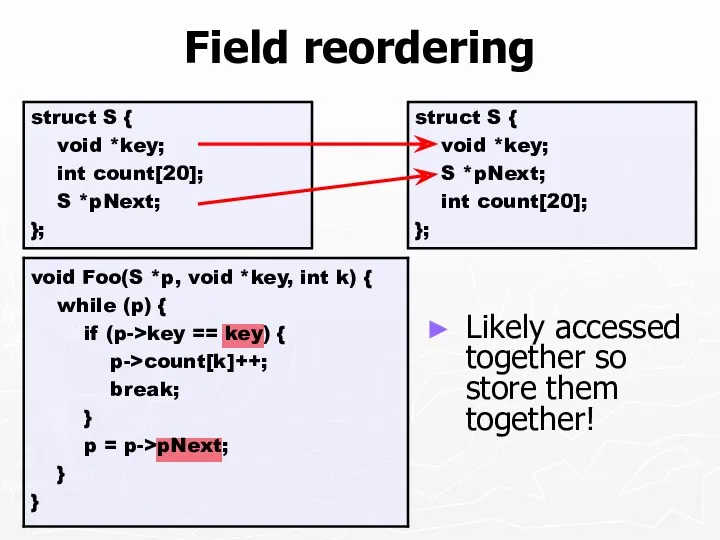
Field reordering
Likely accessed together so store them together!
Field reordering
Likely accessed together so store them together!

Hot/cold splitting
Allocate all ‘struct S’ from a memory pool
Increases coherence
Prefer array-style
Hot/cold splitting
Allocate all ‘struct S’ from a memory pool
Increases coherence
Prefer array-style
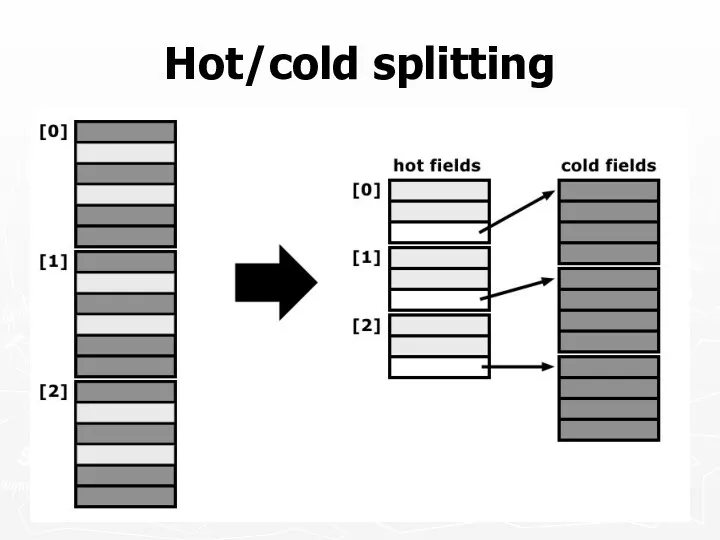
Hot/cold splitting
Hot/cold splitting

Beware compiler padding
Assuming 4-byte floats, for most compilers sizeof(X) == 40,
Beware compiler padding
Assuming 4-byte floats, for most compilers sizeof(X) == 40,

Cache performance analysis
Usage patterns
Activity – indicates hot or cold field
Correlation –
Cache performance analysis
Usage patterns
Activity – indicates hot or cold field
Correlation –

Tree data structures
Rearrange nodes
Increase spatial locality
Cache-aware vs. cache-oblivious layouts
Reduce size
Pointer elimination
Tree data structures
Rearrange nodes
Increase spatial locality
Cache-aware vs. cache-oblivious layouts
Reduce size
Pointer elimination
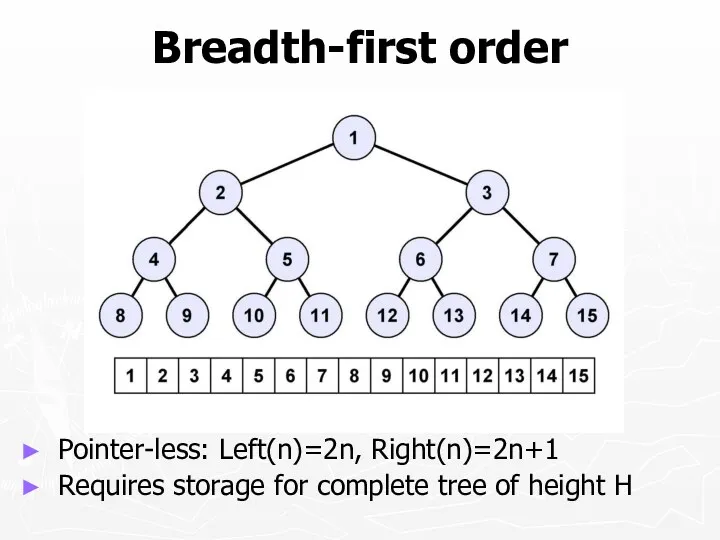
Breadth-first order
Pointer-less: Left(n)=2n, Right(n)=2n+1
Requires storage for complete tree of height H
Breadth-first order
Pointer-less: Left(n)=2n, Right(n)=2n+1
Requires storage for complete tree of height H
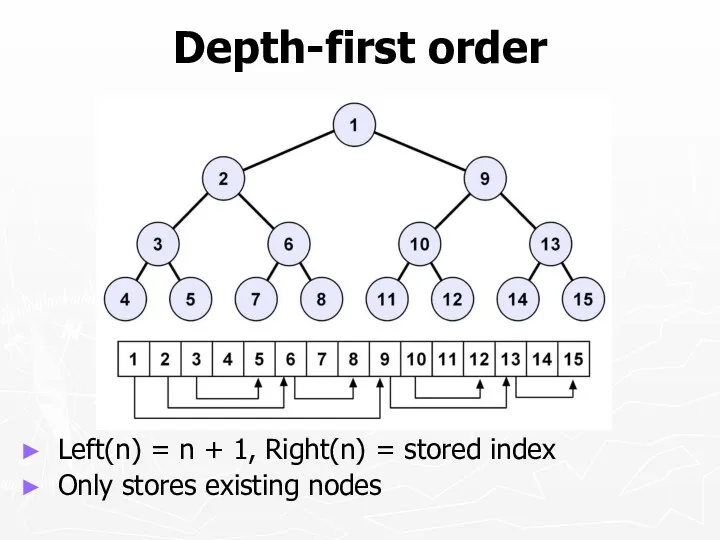
Depth-first order
Left(n) = n + 1, Right(n) = stored index
Only stores
Depth-first order
Left(n) = n + 1, Right(n) = stored index
Only stores
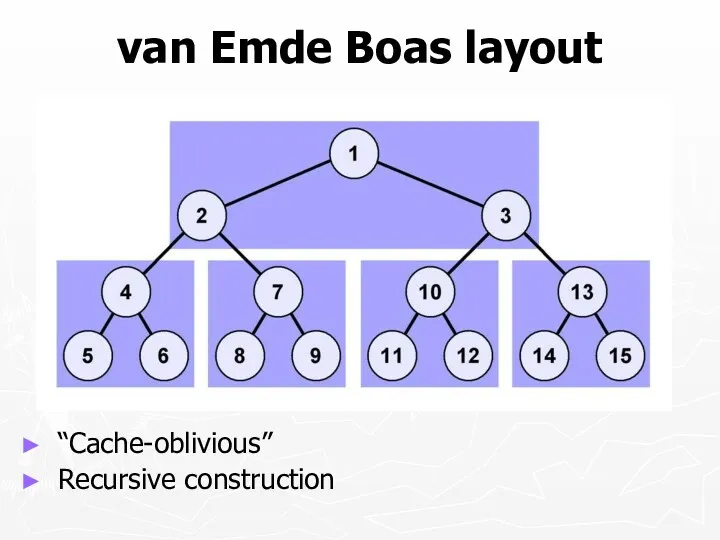
van Emde Boas layout
“Cache-oblivious”
Recursive construction
van Emde Boas layout
“Cache-oblivious”
Recursive construction
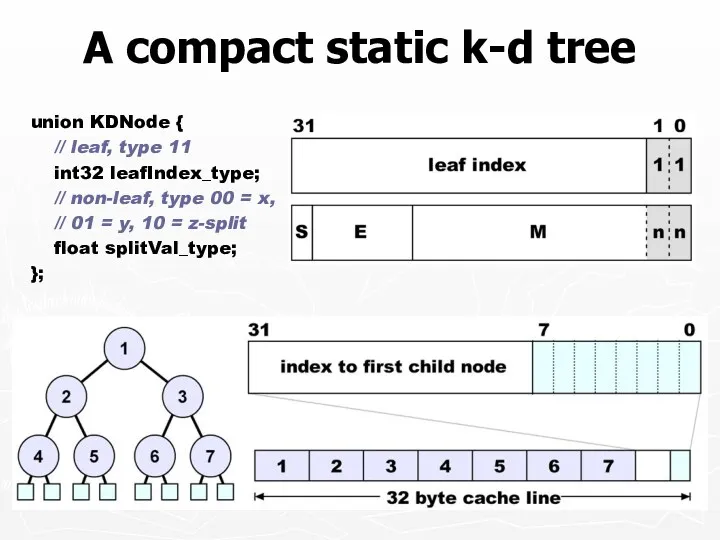
A compact static k-d tree
union KDNode {
// leaf, type 11
A compact static k-d tree
union KDNode {
// leaf, type 11

Linearization caching
Nothing better than linear data
Best possible spatial locality
Easily prefetchable
So linearize
Linearization caching
Nothing better than linear data
Best possible spatial locality
Easily prefetchable
So linearize
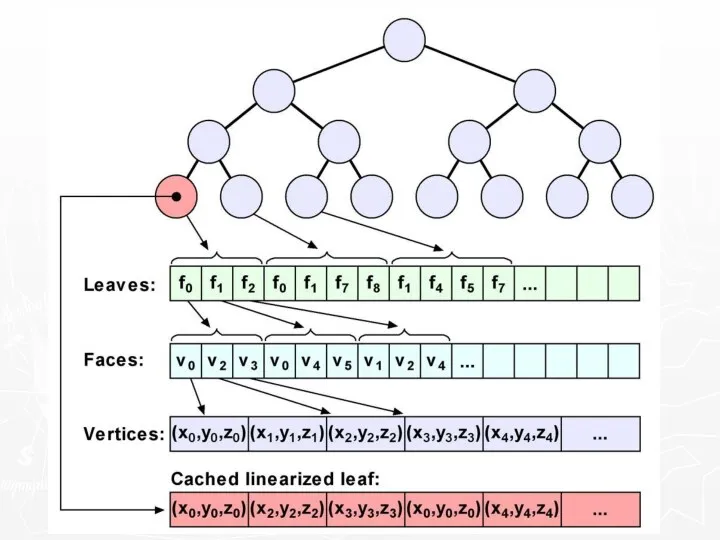

Memory allocation policy
Don’t allocate from heap, use pools
No block overhead
Keeps data
Memory allocation policy
Don’t allocate from heap, use pools
No block overhead
Keeps data
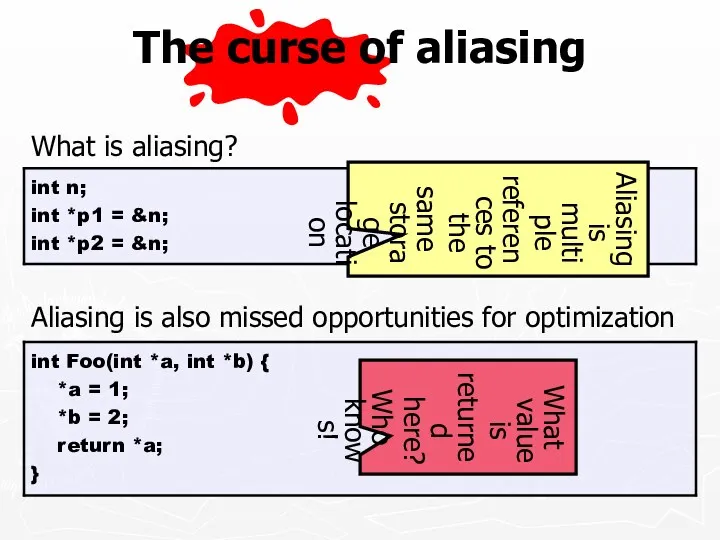
The curse of aliasing
What is aliasing?
Aliasing is also missed opportunities for
The curse of aliasing
What is aliasing?
Aliasing is also missed opportunities for

The curse of aliasing
What is causing aliasing?
Pointers
Global variables/class members make it
The curse of aliasing
What is causing aliasing?
Pointers
Global variables/class members make it

How do we do ‘anti-aliasing’?
What can be done about aliasing?
Better languages
Less
How do we do ‘anti-aliasing’?
What can be done about aliasing?
Better languages
Less

Matrix multiplication 1/3
Consider optimizing a 2x2 matrix multiplication:
How do we typically
Matrix multiplication 1/3
Consider optimizing a 2x2 matrix multiplication:
How do we typically

But wait! There’s a hidden assumption! a is not b or
But wait! There’s a hidden assumption! a is not b or
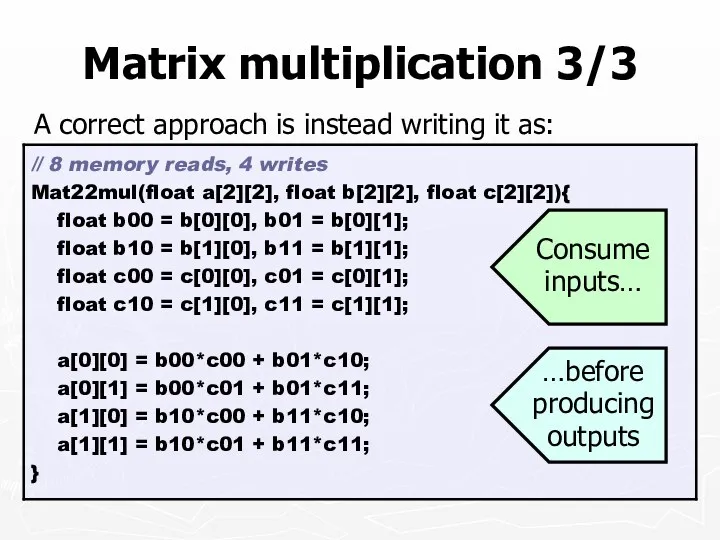
Matrix multiplication 3/3
A correct approach is instead writing it as:
…before
producing
outputs
Consume
inputs…
Matrix multiplication 3/3
A correct approach is instead writing it as:
…before
producing
outputs
Consume
inputs…

Abstraction penalty problem
Higher levels of abstraction have a negative effect on
Abstraction penalty problem
Higher levels of abstraction have a negative effect on

C++ abstraction penalty
Lots of (temporary) objects around
Iterators
Matrix/vector classes
Objects live in heap/stack
Thus
C++ abstraction penalty
Lots of (temporary) objects around
Iterators
Matrix/vector classes
Objects live in heap/stack
Thus
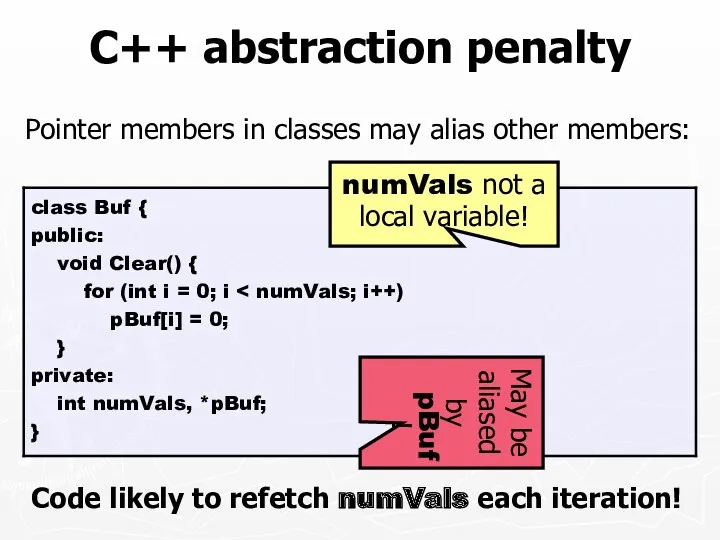
C++ abstraction penalty
Pointer members in classes may alias other members:
Code likely
C++ abstraction penalty
Pointer members in classes may alias other members:
Code likely

C++ abstraction penalty
We know that aliasing won’t happen, and can
manually solve
C++ abstraction penalty
We know that aliasing won’t happen, and can
manually solve
![C++ abstraction penalty Since pBuf[i] can only alias numVals in](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/412600/slide-44.jpg)
C++ abstraction penalty
Since pBuf[i] can only alias numVals in the first
iteration,
C++ abstraction penalty
Since pBuf[i] can only alias numVals in the first
iteration,
Type-based alias analysis
Some aliasing the compiler can catch
A powerful tool is
Type-based alias analysis
Some aliasing the compiler can catch
A powerful tool is

Type-based alias analysis
ANSI C/C++ states that…
Each area of memory can only
Type-based alias analysis
ANSI C/C++ states that…
Each area of memory can only

Compatibility of C/C++ types
In short…
Types compatible if differing by signed, unsigned,
Compatibility of C/C++ types
In short…
Types compatible if differing by signed, unsigned,

What TBAA can do for you
into this:
It can turn this:
Possible aliasing
between
v[i]
What TBAA can do for you
into this:
It can turn this:
Possible aliasing
between
v[i]
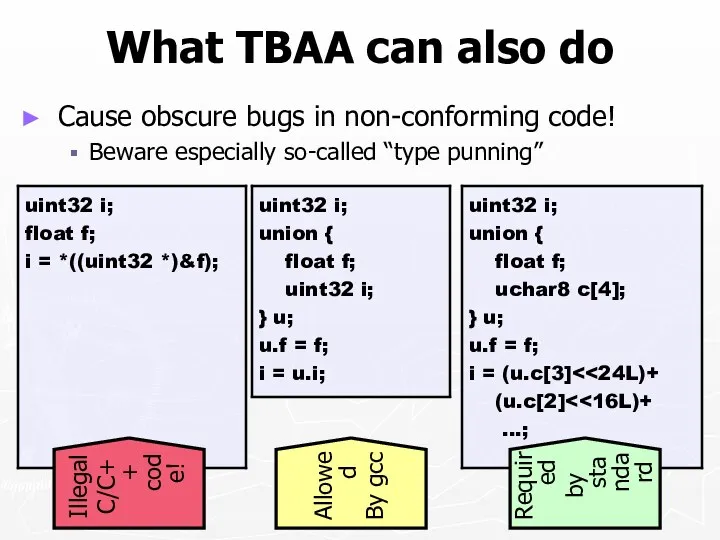
What TBAA can also do
Cause obscure bugs in non-conforming code!
Beware especially
What TBAA can also do
Cause obscure bugs in non-conforming code!
Beware especially

Restrict-qualified pointers
restrict keyword
New to 1999 ANSI/ISO C standard
Not in C++ standard
Restrict-qualified pointers
restrict keyword
New to 1999 ANSI/ISO C standard
Not in C++ standard

Using the restrict keyword
Given this code:
You really want the compiler to
Using the restrict keyword
Given this code:
You really want the compiler to

Using the restrict keyword
giving for the first version:
and for the second
Using the restrict keyword
giving for the first version:
and for the second

Solving the aliasing problem
The fix? Declaring the output as restrict:
Alas, in
Solving the aliasing problem
The fix? Declaring the output as restrict:
Alas, in

‘const’ doesn’t help
Some might think this would work:
Wrong! const promises almost
‘const’ doesn’t help
Some might think this would work:
Wrong! const promises almost

SIMD + restrict = TRUE
restrict enables SIMD optimizations
Independent loads and
stores. Operations
SIMD + restrict = TRUE
restrict enables SIMD optimizations
Independent loads and
stores. Operations

Restrict-qualified pointers
Important, especially with C++
Helps combat abstraction penalty problem
But beware…
Tricky semantics,
Restrict-qualified pointers
Important, especially with C++
Helps combat abstraction penalty problem
But beware…
Tricky semantics,

Tips for avoiding aliasing
Minimize use of globals, pointers, references
Pass small variables
Tips for avoiding aliasing
Minimize use of globals, pointers, references
Pass small variables

That’s it! – Resources 1/2
Ericson, Christer. Real-time collision detection. Morgan-Kaufmann, 2005.
That’s it! – Resources 1/2
Ericson, Christer. Real-time collision detection. Morgan-Kaufmann, 2005.
 Как уберечься от недостоверной информации?
Как уберечься от недостоверной информации? Верстка web-страниц
Верстка web-страниц Создание сайта для инициативной группы Министерства молодёжи, спорта и туризма ДНР
Создание сайта для инициативной группы Министерства молодёжи, спорта и туризма ДНР Системы обработки информации и управления
Системы обработки информации и управления Информационные технологии в профессиональной деятельности
Информационные технологии в профессиональной деятельности презентация на тему Представление об объектах окружающего мира
презентация на тему Представление об объектах окружающего мира Are we depend on social media
Are we depend on social media Сетевое и системное администрирование
Сетевое и системное администрирование 20231013_po
20231013_po Компьютерные игры: вредно или полезно
Компьютерные игры: вредно или полезно Автоматизированная система измерения частотных характеристик кабельных линий передачи данных на основе медной витой пары
Автоматизированная система измерения частотных характеристик кабельных линий передачи данных на основе медной витой пары Информатика. Русский язык
Информатика. Русский язык Памятка волонтеру группы в Квартале
Памятка волонтеру группы в Квартале Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій
Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій Презентация Архитектурная схема ЭВМ, Состав ПК
Презентация Архитектурная схема ЭВМ, Состав ПК Дискретная форма представления информации. 7 класс
Дискретная форма представления информации. 7 класс Разбор заданий В11. IP-адрес
Разбор заданий В11. IP-адрес Системы счисления
Системы счисления Понятие Информационно-техническое обеспечение
Понятие Информационно-техническое обеспечение Kutubxona faoliyatida amaliy dasturiy vositalardan foydalanish. Elektron hujjatlarni yaratishda tegishli dasturiy foydalanish
Kutubxona faoliyatida amaliy dasturiy vositalardan foydalanish. Elektron hujjatlarni yaratishda tegishli dasturiy foydalanish Алгоритми. Лекция 1
Алгоритми. Лекция 1 Overview of Zoho Cliq
Overview of Zoho Cliq Ювелирный магазин 1С:Розница 8
Ювелирный магазин 1С:Розница 8 Коммерческое предложение по созданию сайта
Коммерческое предложение по созданию сайта Подсистема прерываний. Лабораторная работа №3
Подсистема прерываний. Лабораторная работа №3 Использование программных продуктов фирмы 1С в учебных заведениях
Использование программных продуктов фирмы 1С в учебных заведениях Тестирование как средство контроля знаний обучающихся
Тестирование как средство контроля знаний обучающихся Python. Функции
Python. Функции