- Физическое проектирование БД. Индексы

Содержание
- 2. План лекции Алгоритмы поиска данных, используемые СУБД. В+-деревья. Индексы СУБД Oracle. Рекомендации по использованию индексов.
- 3. Поиск данных в БД В БД часто используются операции поиска данных. Пример: Найти всех студентов с
- 4. Индекс Индекс – это структура, которая определяет соответствие значения ключа записи (атрибута или группы атрибутов) и
- 5. Бинарный поиск
- 6. Бинарное дерево поиска Бинарное дерево поиска — это дерево, в котором ключ в каждом узле должен
- 7. В+дерево Нужен более эффективный способ запроса диапазона. В современных БД для этого используется модифицированная версия дерева
- 8. B+tree индекс Oracle
- 9. Сканирование B+tree индекса Листовые блоки содержат по 2 элемента: - индексированные значения столбца - идентификатор ROWID
- 10. Сбалансированное дерево В общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством
- 11. Индексы СУБД Oracle В*Tree индексы: - наиболее часто используемый тип индекса Reverse – индексы Индексы, основанные
- 12. Создание индексов Индексы создаются в БД с помощью команды CREATE INDEX. Создание обычного индекса CREATE INDEX
- 13. Reverse – индексы Reverse index – это тоже B-tree индекс, но с обратным порядком байтов. Благодаря
- 14. Пример Reverse-индекс Значение в индексе изменяется намного больше, чем само значение в таблице, и поэтому в
- 15. Пример Программа продажи билетов на поезда В таблицу TICKET (билет) каждую секунду вставляется много новых записей.
- 16. Function-based Index Индексы на основе функций предварительно вычисляют значения функций по заданному столбцу и сохраняют результат
- 17. Bitmap Index Bitmap index – содержит отдельные битовые карты для каждого возможного значения столбца. Каждому биту
- 18. Структура bitmap-индекса
- 19. Пример BITMAP-индекса В таблице EMP есть поле SEX (пол), которое обладает низкой селективностью – может принимать
- 20. Советы по работе с индексами Создавайте индексы на следующие поля: первичный ключ, такой индекс создается автоматически;
- 21. Советы по работе с индексами Не стоит создавать индексы на поля если: Столбцы редко используются в
- 22. Составные индексы Составной индекс включает 2 и более столбца одной таблицы. В некоторых случаях использование составного
- 23. Применение составных индексов CREATE TABLE emp(id, name, sex, hobby, age) CREATE INDEX i_emp ON emp(hobby, age,
- 24. Использование индексов Каждый индекс связан с определенной таблицей Индекс обычно хранится отдельно от таблицы СУБД использует
- 26. Скачать презентацию

План лекции
Алгоритмы поиска данных, используемые СУБД.
В+-деревья.
Индексы СУБД Oracle.
Рекомендации по использованию
План лекции
Алгоритмы поиска данных, используемые СУБД.
В+-деревья.
Индексы СУБД Oracle.
Рекомендации по использованию

Поиск данных в БД
В БД часто используются операции поиска данных.
Пример:
Поиск данных в БД
В БД часто используются операции поиска данных.
Пример:
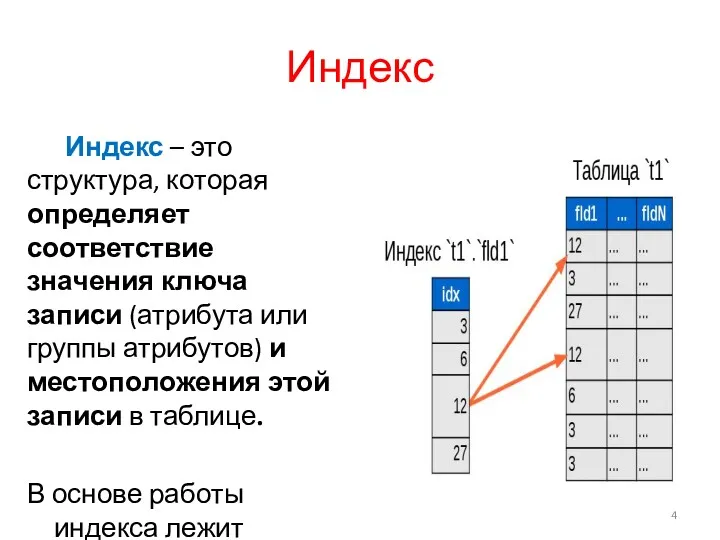
Индекс
Индекс – это структура, которая определяет соответствие значения ключа записи
Индекс
Индекс – это структура, которая определяет соответствие значения ключа записи
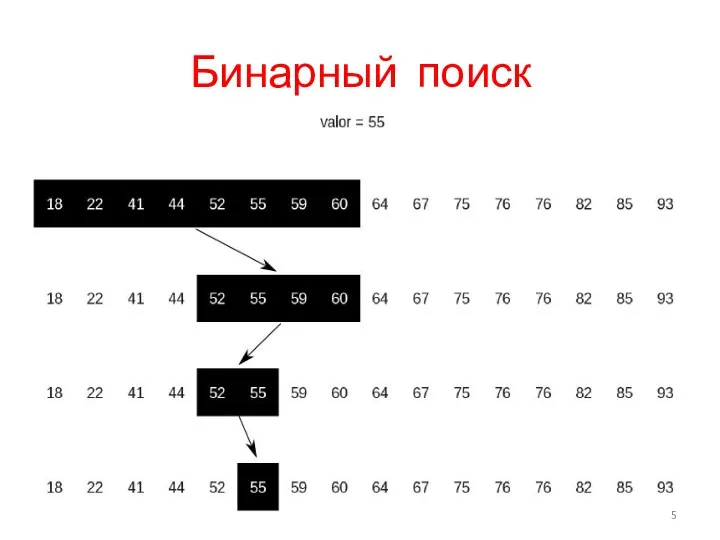
Бинарный поиск
Бинарный поиск
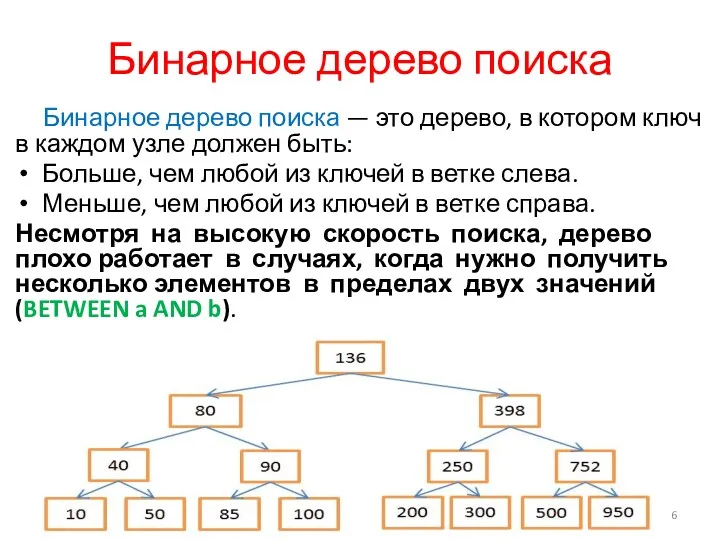
Бинарное дерево поиска
Бинарное дерево поиска — это дерево, в котором
Бинарное дерево поиска
Бинарное дерево поиска — это дерево, в котором
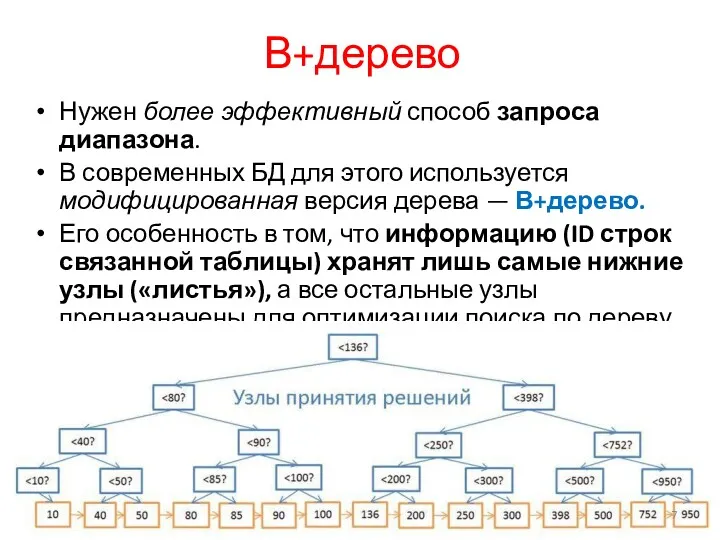
В+дерево
Нужен более эффективный способ запроса диапазона.
В современных БД для этого используется модифицированная
В+дерево
Нужен более эффективный способ запроса диапазона.
В современных БД для этого используется модифицированная
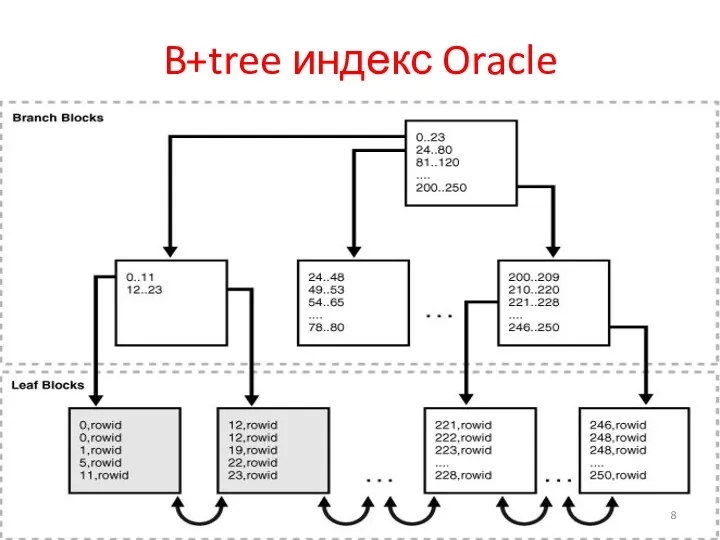
B+tree индекс Oracle
B+tree индекс Oracle

Сканирование B+tree индекса
Листовые блоки содержат по 2 элемента:
- индексированные
Сканирование B+tree индекса
Листовые блоки содержат по 2 элемента:
- индексированные

Сбалансированное дерево
В общем случае получим некоторое дерево, каждый родительский блок которого
Сбалансированное дерево
В общем случае получим некоторое дерево, каждый родительский блок которого

Индексы СУБД Oracle
В*Tree индексы:
- наиболее часто используемый тип индекса
Reverse
Индексы СУБД Oracle
В*Tree индексы:
- наиболее часто используемый тип индекса
Reverse

Создание индексов
Индексы создаются в БД с помощью команды CREATE INDEX.
Создание обычного
Создание индексов
Индексы создаются в БД с помощью команды CREATE INDEX.
Создание обычного

Reverse – индексы
Reverse index – это тоже B-tree индекс, но с
Reverse – индексы
Reverse index – это тоже B-tree индекс, но с
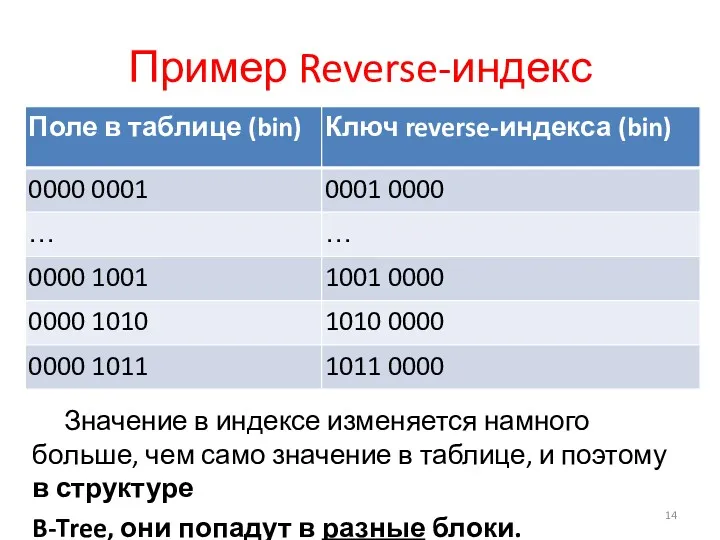
Пример Reverse-индекс
Значение в индексе изменяется намного больше, чем само значение
Пример Reverse-индекс
Значение в индексе изменяется намного больше, чем само значение

Пример
Программа продажи билетов на поезда
В таблицу TICKET (билет) каждую секунду вставляется
Пример
Программа продажи билетов на поезда
В таблицу TICKET (билет) каждую секунду вставляется

Function-based Index
Индексы на основе функций предварительно вычисляют значения функций по заданному
Function-based Index
Индексы на основе функций предварительно вычисляют значения функций по заданному

Bitmap Index
Bitmap index – содержит отдельные битовые карты для каждого возможного
Bitmap Index
Bitmap index – содержит отдельные битовые карты для каждого возможного
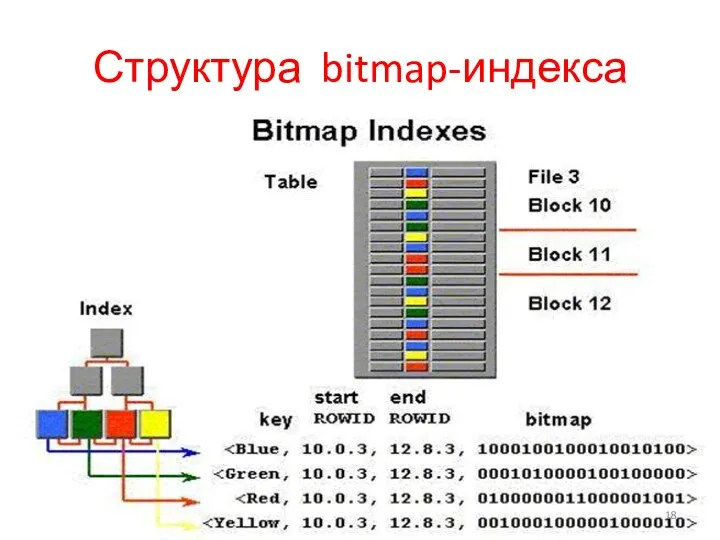
Структура bitmap-индекса
Структура bitmap-индекса

Пример BITMAP-индекса
В таблице EMP есть поле SEX (пол), которое обладает
Пример BITMAP-индекса
В таблице EMP есть поле SEX (пол), которое обладает

Советы по работе с индексами
Создавайте индексы на следующие поля:
первичный ключ, такой
Советы по работе с индексами
Создавайте индексы на следующие поля:
первичный ключ, такой

Советы по работе с индексами
Не стоит создавать индексы на поля если:
Столбцы
Советы по работе с индексами
Не стоит создавать индексы на поля если:
Столбцы

Составные индексы
Составной индекс включает 2 и более столбца одной таблицы.
В некоторых
Составные индексы
Составной индекс включает 2 и более столбца одной таблицы.
В некоторых

Применение составных индексов
CREATE TABLE emp(id, name, sex, hobby, age)
CREATE INDEX i_emp
Применение составных индексов
CREATE TABLE emp(id, name, sex, hobby, age)
CREATE INDEX i_emp
Использование индексов
Каждый индекс связан с определенной таблицей
Индекс обычно хранится отдельно от
Использование индексов
Каждый индекс связан с определенной таблицей
Индекс обычно хранится отдельно от
 Безопасность в сети Интернет
Безопасность в сети Интернет Язык РНР Управляющие конструкции
Язык РНР Управляющие конструкции Развития вычислительной техники. Электроника и наноэлектроника
Развития вычислительной техники. Электроника и наноэлектроника Как сделать презентацию к уроку
Как сделать презентацию к уроку Web-страницы и Web-сайты
Web-страницы и Web-сайты Право в интернете
Право в интернете Формальное исполнение алгоритма
Формальное исполнение алгоритма Type of Networks
Type of Networks Кодирование и обработка звуковой информации
Кодирование и обработка звуковой информации Построение диаграмм. Диаграммы вариантов использования
Построение диаграмм. Диаграммы вариантов использования Программное обеспечение ПК
Программное обеспечение ПК Тест Компьютерные сети, 11 класс
Тест Компьютерные сети, 11 класс Технологии искусственного интеллекта: машинное обучение. Лекция 7
Технологии искусственного интеллекта: машинное обучение. Лекция 7 Artificial intelligence
Artificial intelligence Как варить подкасты
Как варить подкасты Знакомство со средой Scratch
Знакомство со средой Scratch Интеллектуальные информационные системы. Искусственный интеллект
Интеллектуальные информационные системы. Искусственный интеллект Требования с точки зрения клиента
Требования с точки зрения клиента Введение в CorelDraw
Введение в CorelDraw Архивация данных. Обзор пакетов для архивации данных
Архивация данных. Обзор пакетов для архивации данных Введение. Алгоритмы работы поисковых систем и их отличия. Этапы работы в поисковом продвижении
Введение. Алгоритмы работы поисковых систем и их отличия. Этапы работы в поисковом продвижении Электронная система непрерывного обучения для сотрудников компании
Электронная система непрерывного обучения для сотрудников компании Газета Ровесник. Март 2016
Газета Ровесник. Март 2016 Пакет электронных приложений к урокам ИИКТ (в помощь учителю и ученикам)
Пакет электронных приложений к урокам ИИКТ (в помощь учителю и ученикам) Информация и ее свойства
Информация и ее свойства Метод последовательных сравнений
Метод последовательных сравнений Формирование изображения на экране монитора. Компьютерное представление цвета
Формирование изображения на экране монитора. Компьютерное представление цвета Сортировка. Метод сортировки
Сортировка. Метод сортировки