- Java Core. Collection framework & Generics

Содержание
- 2. Recording
- 3. Collection framework
- 4. Introduction Основные темы: Основные структуры данных Оценка сложности алгоритмов Иерархия и основные компоненты Collection framework List,
- 5. Why we need Collections framework? Collections framework – иерархия интерфейсов и классов, являющаяся частью JDK и
- 6. Data structures Какие структуры данных будем рассматривать: Массив Список Стек Очередь Хеш-таблица Множество Дерево
- 7. Big O notation Временная сложность алгоритма это зависимость времени выполнения алгоритма от количества входных данных. О
- 8. Big O notation Порядки роста:
- 9. Collections hierarchy
- 10. Collection interface Collection – основной интерфейс, от которого наследуются все коллекции (кроме Map). Представляет собой коллекцию
- 11. Iterable & Iterator Iterable – предоставляет возможность использование объекта в for-each выражении. Iterator – позволяет поочередно
- 12. Iterable & Iterator Явное использование итератора: Использование итератора в for-each loop
- 13. Iterator Удаление элементов При использовании итератора, удалять элементы нужно методом iterator.remove()
- 14. List List – представляет собой упорядоченный список объектов. Представители: ArrayList – массив объектов LinkedList – связный
- 15. ArrayList ArrayList – динамически расширяемый массив Пример:
- 16. ArrayList ArrayList состоит из: Object[] elementData – массив с хранимыми объектами int size – размер массива
- 17. ArrayList 12 13 14 15 16 0 1 2 3 4 17 18 19 20 21
- 18. ArrayList Перед добавлением методом ensureCapacityInternal проверяется заполняемость, если массив не заполнен, добавляется новый элемент и происходит
- 19. ArrayList Рассчитывается количество элементов, которые необходимо сдвинуть после удаления и происходит сдвиг элементов копированием методом System.arraycopy
- 20. ArrayList Оценка сложности основных операций:
- 21. LinkedList LinkedList – двунаправленный связный список Пример:
- 22. LinkedList LinkedList состоит из: Node first – указатель на первый элемент списка Node last – указатель
- 23. LinkedList Добавление элементов в список: next null prev null elem 13 Node size: 1 first last
- 24. LinkedList Итерация по списку или доступ к элементу осуществляется путем последовательного прохода по узлам списка с
- 25. LinkedList Оценка сложности основных операций:
- 26. Vector, Stack Редко используемые реализации списков: Vector – динамический массив (методы synchronized) Stack – реализация стека
- 27. Map Map – множество элементов, хранящихся в формате ключ-значение Особенности: Ключ – уникальный идентификатор Порядок элементов
- 28. HashMap HashMap – хеш-таблица, реализованная на основе динамического массива Пример: Не поддерживает порядок вставки элементов.
- 29. HashMap HashMap состоит из: Node [] table – содержимое хеш-таблицы Set > entrySet – кешированое множество
- 30. HashMap Как происходит добавление элемента методом put (K key, V value)? Методом int hash(Object key) вычисляется
- 31. HashMap null null null null null 0 1 2 3 4 null null null null null
- 32. HashMap null null null null 0 1 2 3 4 null null null null 11 12
- 33. HashMap Коллизия – ситуация, когда элементы с разными ключами попадают в одну и ту же корзину.
- 34. HashMap При достижении размера списка в TREEIFY_THRESHOLD равному 8 элементам, происходит ребалансировка в красно-черное дерево Метод
- 35. HashMap Расширение массива: next Node value key hash Hello 123 99 0 1 2 3 4
- 36. HashMap null null null null 0 1 2 3 4 null null null null 11 12
- 37. HashMap Оценка сложности основных операций:
- 38. LinkedHashMap LinkedHashMap – хеш-таблица, реализованная на основе динамического массива, являющаяся так же связным списком. Поддерживает порядок
- 39. LinkedHashMap LinkedHashMap содержит те же поля что и HashMap, а так же пару дополнительных: LinkedHashMap.Entry head
- 40. LinkedHashMap null null null null 0 1 2 3 4 null null null null 11 12
- 41. LinkedHashMap Поле accessOrder определяет порядок итерации по элементам: accessOrder=true – итерация в порядке обращения accessOrder=false –
- 42. TreeMap TreeMap – реализация map, элементы которой отсортированы по ключу и хранятся в структуре RBT. Natural
- 43. TreeMap TreeMap состоит из: final Comparator comparator – компаратор для сравнения элементов Entry root – корневой
- 44. TreeMap О механизме сортировки TreeMap Сортировка элементов TreeMap происходит по ключу. По умолчанию сортировка происходит согласно
- 45. TreeMap Что будет выведено на экран?
- 46. TreeMap Для сравнения ключей TreeMap использует метод compareTo либо метод compare, если указан компаратор Методы hashCode
- 47. TreeMap 7 10 11 5 12 12 5 3 10 7 11 6 8 4 19
- 48. TreeMap Оценка сложности основных операций:
- 49. Set Set – представляет собой множество уникальных элементов Представители: TreeSet – элементы отсортированы по возрастанию (RBT)
- 50. HashSet HashSet – множество элементов, использующее для хранения хеш-таблицу Пример:
- 51. HashSet Получение элемента из Hashset: Пример: Set не предоставляет методов для получения объектов (кроме обхода через
- 52. HashSet HashSet в своей реализации использует HashMap: В качестве ключа – сами объекты В качестве значения
- 53. LinkedHashSet LinkedHashSet – множество элементов, использующее для хранения хеш-таблицу в сочетании с двусвязным списком. Основана на
- 54. TreeSet TreeSet – множество элементов, отсортированных в natural order или согласно указанному Comparator. Основана на реализации
- 55. Queue Queue – представляет структуру данных очередь, работающую по принципу FIFO (first in - first out)
- 56. LinkedList as Queue LinkedList - пример реализации очереди с классически FIFO Основные методы: boolean offer(E elem)
- 57. PriorityQueue PriorityQueue - очередь с приоритетом. Элементы в очереди отсортированы в natural order или согласно указанному
- 58. PriorityQueue PriorityQueue состоит из: Object[] queue – массив с элементами очереди int size – размер очереди
- 59. PriorityQueue В основе PriorityQueue лежит структура данных - бинарная куча: Значение в любой вершине не меньше,
- 60. PriorityQueue Добавление элементов происходит методом siftUp(int k, E x) , где k – позиция вставки, Е
- 61. PriorityQueue Получениe следующего элемента очереди происходит методом siftDown(int k, E x) , где k – позиция
- 62. PriorityQueue Оценка сложности основных операций:
- 63. Deque Deque – расширяет интерфейс Queue, добавляю функциональность двунаправленной очереди Особенности: Элементы очереди упорядочены Возможность добавлять/выбирать
- 64. ArrayDeque ArrayDeque - реализация двухсторонней очереди на примере динамического массива Пример:
- 65. ArrayDeque ArrayDeque состоит из: Object[] elementData – массив с хранимыми объектами int size – размер массива
- 66. ArrayDeque Что произойдет если вставить в начало очереди: offerFirst(13) ? 2 3 4 5 null 1
- 67. Thread safety? Большая часть рассмотренных коллекций НЕ потокобезопасна (кроме hashtable, vector, stack). Для достижения потокобезопасности применяется:
- 68. EnumSet Типичный пример хранения Enum объектов:
- 69. EnumSet Для хранения множества Enum объектов используем EnumSet: EnumSet использует bit vector для хранение enum, используя
- 70. EnumMap При выборе Map можно использовать EnumMap, если в качестве ключа Enum объекты: Не оптимальное использование
- 71. Since Java 9 Добавились полезные фабричные утилитарные методы: Set.of() List.of() Map.of()
- 72. Stream API Stream API – набор инструментов (since Java 8), предоставляющих возможность функционального подхода обработки данных
- 73. Stream API Stream API предоставляет возможность работать со структурами данных в функциональном стиле, упрощает работу с
- 74. Stream Stream – последовательность элементов для, потоковой обработки Основные моменты: Предоставляет интерфейс для последовательности элементов определенного
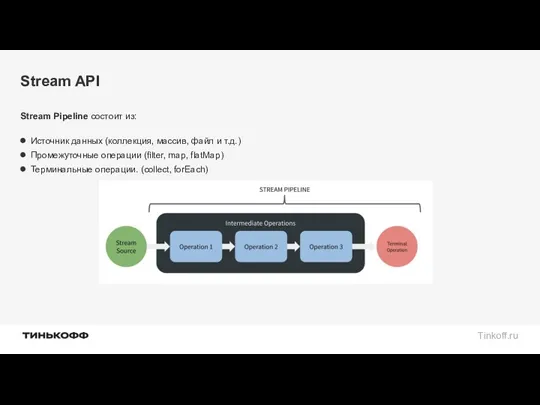
- 75. Stream API Stream Pipeline состоит из: Источник данных (коллекция, массив, файл и т.д.) Промежуточные операции (filter,
- 76. Stream Source Как создается Stream?
- 77. Intermediate operations Промежуточные операции: map(Function m) filter(Predicate p) flatMap(Function m) peek(Consumer c) skip(long n) limit(long n)
- 78. Terminal operations Терминальные операции: collect(Collector c) reduce(BinaryOperator b) findFirst() findAny() forEach(Consumer c) allMatch(Predicate p) anyMatch(Predicate p)
- 79. Collectors Основные коллекторы содержатся в утилитарном классе Collectors: toList() toSet() counting() toMap() groupingBy() joining() toCollection() averagingInt()
- 80. Short circuit Что будет выведено в stdout? Некоторые терминальные операции являются короткозамкнутыми (short circuit) что позволяет
- 81. Stream API Что будет выведено в stdout? Lazy evaluation Стримы в Java “ленивы” т.е. оптимизированы таким
- 82. Parallel streams Можно создавать параллельные потоки с помощью методов: parallelStream() parallel() Перед использованием параллельных стримов подумайте
- 83. Вопросы
- 84. Перерыв
- 85. Generics
- 86. Introduction Что обсудим: Что такое дженерики и зачем они нужны Что такое wildcards, какие они бываю
- 87. Before Java 5 Как бы мы реализовывали свою коллекцию до Java 5?
- 88. Before Java 5 При необходимости реализации или использования классов-оберток/хранилищ (коллекций) мы сталкивались с проблемами: Необходимость явного
- 89. Before Java 5 Корректное использование Collection API до появления дженериков:
- 90. Generic types introduction in Java 5 Согласно JSL: “A generic type is a generic class or
- 91. Generic types Типобезопасность во время компиляции: Основные преимущества дженериков: Универсальность алгоритмов: Отсутствие необходимости приведения типа:
- 92. Generic methods Помимо типов, можно создавать дженерик методы:
- 93. Type inference Java – статически типизированный язык, т.е. значение переменной должно быть известно на стадии компиляции
- 94. Type inference Type Inference – способность компилятора определять тип выражения из контекста
- 95. Type inference Type Inference позволяет определить параметр типа и не указывать явно: По ссылке компилятор определяет
- 96. Multiple parameter types Можно указать более одного параметра для дженерик типа:
- 97. Naming conventions Рекомендации по именованию параметров: E – элемент (при использовании Collection API) K – ключ
- 98. Raw type Raw types (или сырые типы) это дженерик тип, используемый без параметров типов
- 99. Bounded type parameter А что если есть необходимость ограничить параметр типа? Параметр типа ограничен Number: Выражение
- 100. Bounded type parameters Аналогично ограничивать параметр типа можно и дженерик методе: Параметр типа ограничен Number:
- 101. Multiple bounds Можно указывать несколько ограничений для типа параметра.
- 102. Generics and inheritance Object Number Integer
- 103. Generics and inheritance ?
- 104. Generics and inheritance List List List Collection List ArrayList Стандартный механизм наследования не применим к дженерикам
- 105. Covariance and Invariance Ковариантность – это сохранение иерархии наследования исходных типов в производных в том же
- 106. Wildcards Wildcard в дженериках называется символ ?, означающий неизвестный тип (unknown type). Wildcards позволяют обходить ограничения
- 107. Wildcards. Unbounded Используется когда нам не важен тип параметра: List означает, что список может содержать любой
- 108. Wildcards. Unbounded
- 109. Wildcards. Unbounded Нельзя поместить ни один объект в List (кроме null): Wildcard добавляет ковариантность дженерикам List
- 110. Upper Bounded Wildcards Upper bounded wildcard добавляет границу «сверху» для типа параметра дженерика: список List может
- 111. Upper Bounded Wildcards
- 112. Upper Bounded Wildcards Wildcard с верхней границей так же ковариантны List List List Возвращаемый тип -
- 113. Upper Bounded Wildcards
- 114. Lower Bounded Wildcards Lower bounded wildcard добавляет границу «снизу» для типа параметра дженерика: список List может
- 115. Lower Bounded Wildcards
- 116. Lower Bounded Wildcards Wildcard с нижней границей контравариантны Возвращаемый тип - Object: Положить можно все что
- 117. Upper Bounded Wildcards
- 118. PECS Pecs (producer-extends, consumer-super) principle stands for: Если объявляем wildcard extends, то он является поставщиком данных
- 119. Recursive type bounds В редких случаях может быть полезно ограничивать тип параметра выражением, включающим его самого:
- 120. Generics under the hood Во время компиляции стирается вся информация о типах параметров дженерика и становится
- 121. Generics under the hood Что делает компилятор: Что видим коде: Что делает компилятор: Что видим коде:
- 122. Type erasure Type erasure – стирание информации о типах-параметрах во время компиляции. Реализуется через: Замену всех
- 123. Type erasure. Type cast Добавление явного преобразования типа Что делает компилятор: Что видим коде:
- 124. Type erasure. Bridge methods После стирания типов: Реализуем простой дженерик класс:
- 125. Type erasure. Bridge methods Для сохранения полиморфизма компилятор создает синтетический Bridge метод: Компилятор добавляем bridge method:
- 126. Super type token Действительно ли нельзя получить информацию о типе параметра дженерика в runtime? Для примера
- 127. Super type token
- 128. Super type token Super type token – механизм сохранения параметра типа при помощи анонимных классов и
- 129. Super type token Тип параметра явно сохраняется в поле анонимного класса
- 130. Generic restrictions Как нельзя использовать дженерики? Тип-параметр дженерика не может быть примитивом Нельзя создать объект типа-параметра
- 131. Conclusion Итог: Дженерики помогают писать обобщенный, универсальный код Дженерики приносят типобезопасность во время компиляции и удобство
- 132. Вопросы
- 133. Homework
- 135. Скачать презентацию

Recording
Recording

Collection framework
Collection framework
Introduction
Основные темы:
Основные структуры данных
Оценка сложности алгоритмов
Иерархия и основные компоненты Collection framework
List,
Introduction
Основные темы:
Основные структуры данных
Оценка сложности алгоритмов
Иерархия и основные компоненты Collection framework
List,

Why we need Collections framework?
Collections framework – иерархия интерфейсов и классов,
Why we need Collections framework?
Collections framework – иерархия интерфейсов и классов,

Data structures
Какие структуры данных будем рассматривать:
Массив
Список
Стек
Очередь
Хеш-таблица
Множество
Дерево
Data structures
Какие структуры данных будем рассматривать:
Массив
Список
Стек
Очередь
Хеш-таблица
Множество
Дерево

Big O notation
Временная сложность алгоритма это зависимость времени выполнения
Big O notation
Временная сложность алгоритма это зависимость времени выполнения
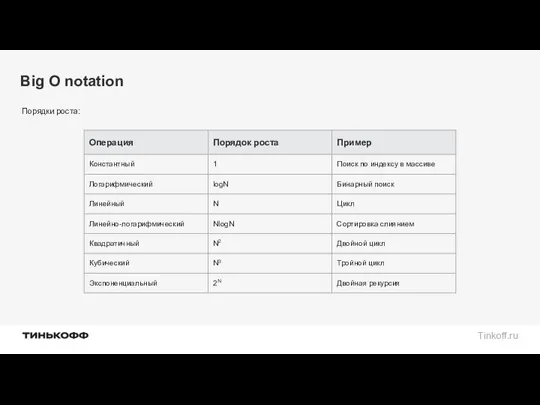
Big O notation
Порядки роста:
Big O notation
Порядки роста:
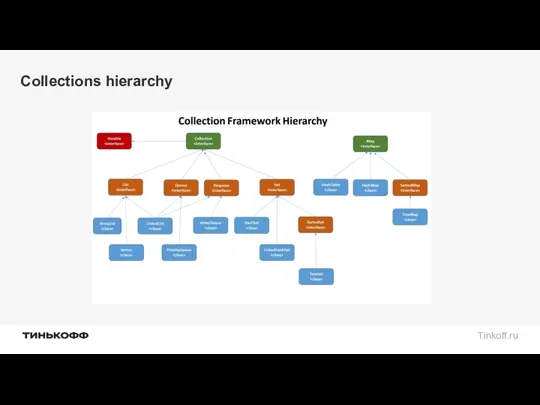
Collections hierarchy
Collections hierarchy

Collection interface
Collection – основной интерфейс, от которого наследуются все коллекции (кроме
Collection interface
Collection – основной интерфейс, от которого наследуются все коллекции (кроме
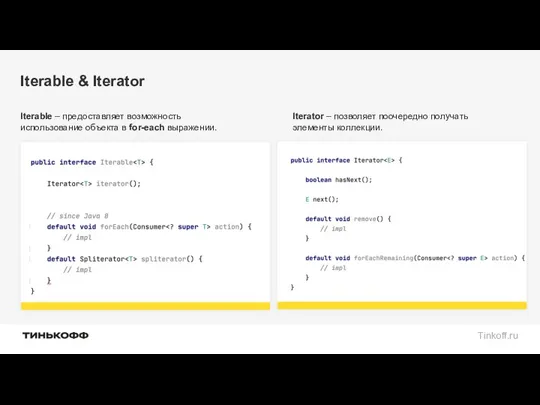
Iterable & Iterator
Iterable – предоставляет возможность использование объекта в for-each выражении.
Iterator
Iterable & Iterator
Iterable – предоставляет возможность использование объекта в for-each выражении.
Iterator
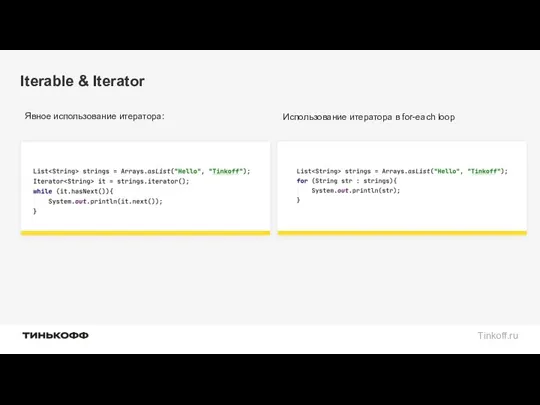
Iterable & Iterator
Явное использование итератора:
Использование итератора в for-each loop
Iterable & Iterator
Явное использование итератора:
Использование итератора в for-each loop

Iterator
Удаление элементов
При использовании итератора, удалять элементы нужно методом iterator.remove()
Iterator
Удаление элементов
При использовании итератора, удалять элементы нужно методом iterator.remove()
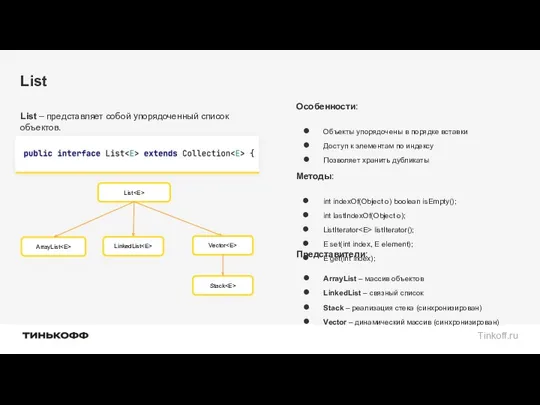
List
List – представляет собой упорядоченный список объектов.
Представители:
ArrayList – массив объектов
LinkedList –
List
List – представляет собой упорядоченный список объектов.
Представители:
ArrayList – массив объектов
LinkedList –
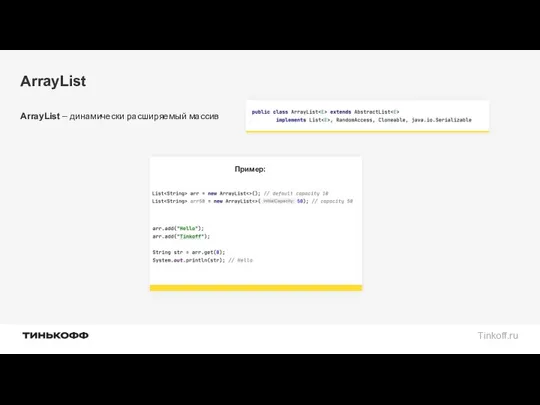
ArrayList
ArrayList – динамически расширяемый массив
Пример:
ArrayList
ArrayList – динамически расширяемый массив
Пример:
![ArrayList ArrayList состоит из: Object[] elementData – массив с хранимыми](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/396507/slide-15.jpg)
ArrayList
ArrayList состоит из:
Object[] elementData – массив с хранимыми объектами
int size –
ArrayList
ArrayList состоит из:
Object[] elementData – массив с хранимыми объектами
int size –

ArrayList
12
13
14
15
16
0
1
2
3
4
17
18
19
20
21
5
6
7
8
9
size: 10
12
13
14
15
16
0
1
2
3
4
17
18
19
20
21
5
6
7
8
9
size: 16
49
null
10
11
null
null
null
null
12
13
14
15
Увеличение массива в 1.5 раза
Добавление элемента в заполненный массив:
Метод
ArrayList
12
13
14
15
16
0
1
2
3
4
17
18
19
20
21
5
6
7
8
9
size: 10
12
13
14
15
16
0
1
2
3
4
17
18
19
20
21
5
6
7
8
9
size: 16
49
null
10
11
null
null
null
null
12
13
14
15
Увеличение массива в 1.5 раза
Добавление элемента в заполненный массив:
Метод
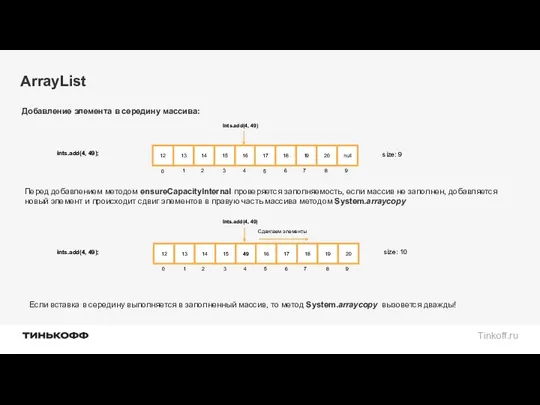
ArrayList
Перед добавлением методом ensureCapacityInternal проверяется заполняемость, если массив не заполнен, добавляется
ArrayList
Перед добавлением методом ensureCapacityInternal проверяется заполняемость, если массив не заполнен, добавляется
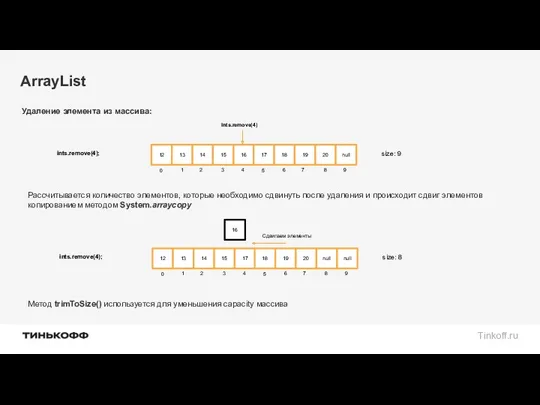
ArrayList
Рассчитывается количество элементов, которые необходимо сдвинуть после удаления и происходит сдвиг
ArrayList
Рассчитывается количество элементов, которые необходимо сдвинуть после удаления и происходит сдвиг
ArrayList
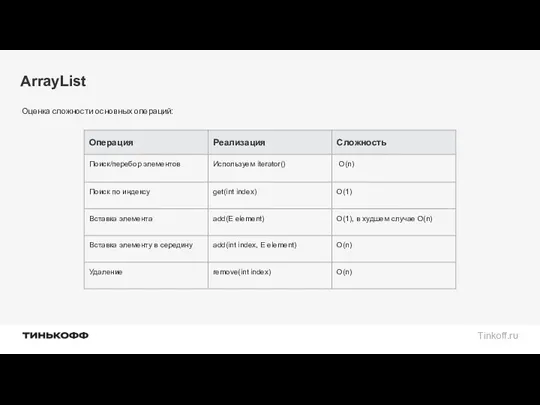
Оценка сложности основных операций:
ArrayList
Оценка сложности основных операций:
LinkedList
LinkedList – двунаправленный связный список
Пример:
LinkedList
LinkedList – двунаправленный связный список
Пример:
LinkedList
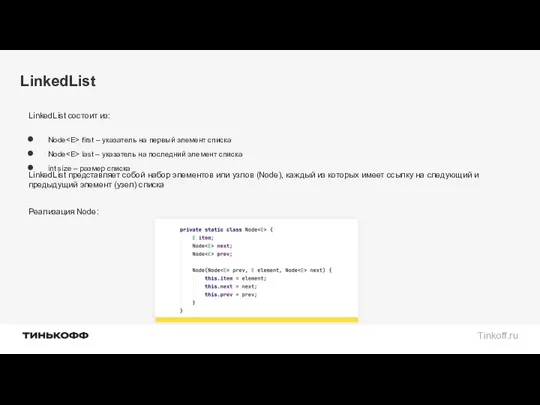
LinkedList состоит из:
Node first – указатель на первый элемент списка
Node last
LinkedList
LinkedList состоит из:
Node
Node

LinkedList
Добавление элементов в список:
next
null
prev
null
elem
13
Node
size: 1
first
last
prev
null
next
elem
13
Node
size: 3
first
list.add(13)
list.add(19)
prev
next
elem
19
Node
Для быстрого добавления элементов в начало
LinkedList
Добавление элементов в список:
next
null
prev
null
elem
13
Node
size: 1
first
last
prev
null
next
elem
13
Node
size: 3
first
list.add(13)
list.add(19)
prev
next
elem
19
Node
Для быстрого добавления элементов в начало

LinkedList
Итерация по списку или доступ к элементу осуществляется путем последовательного прохода
LinkedList
Итерация по списку или доступ к элементу осуществляется путем последовательного прохода

LinkedList
Оценка сложности основных операций:
LinkedList
Оценка сложности основных операций:
Vector, Stack
Редко используемые реализации списков:
Vector – динамический массив (методы synchronized)
Stack –
Vector, Stack
Редко используемые реализации списков:
Vector
Stack
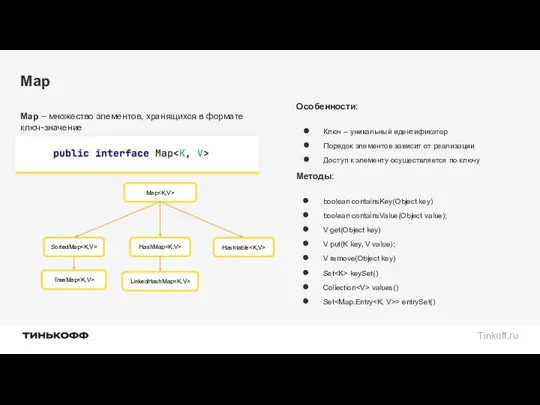
Map
Map – множество элементов, хранящихся в формате ключ-значение
Особенности:
Ключ – уникальный идентификатор
Порядок
Map
Map – множество элементов, хранящихся в формате ключ-значение
Особенности:
Ключ – уникальный идентификатор
Порядок
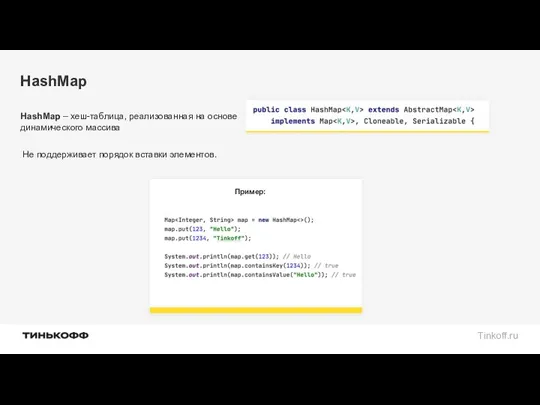
HashMap
HashMap – хеш-таблица, реализованная на основе динамического массива
Пример:
Не поддерживает порядок вставки
HashMap
HashMap – хеш-таблица, реализованная на основе динамического массива
Пример:
Не поддерживает порядок вставки
![HashMap HashMap состоит из: Node [] table – содержимое хеш-таблицы](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/396507/slide-28.jpg)
HashMap
HashMap состоит из:
Node[] table – содержимое хеш-таблицы
Set> entrySet – кешированое
HashMap
HashMap состоит из:
Node
Set

HashMap
Как происходит добавление элемента методом put (K key, V value)?
Методом int
HashMap
Как происходит добавление элемента методом put (K key, V value)?
Методом int
HashMap
null
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 0
capacity: 16
…
next
Node
value
key
hash
null
Hello
123
99
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 1
capacity: 16
…
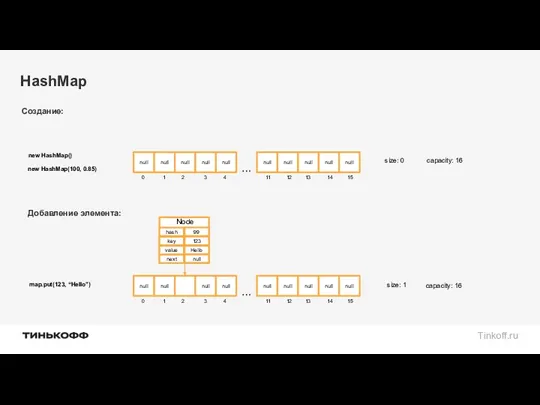
Создание:
new HashMap()
new HashMap(100, 0.85)
map.put(123, “Hello”)
Добавление элемента:
HashMap
null
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 0
capacity: 16
…
next
Node
value
key
hash
null
Hello
123
99
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 1
capacity: 16
…
Создание:
new HashMap()
new HashMap(100, 0.85)
map.put(123, “Hello”)
Добавление элемента:
HashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
next
Node
value
key
hash
Hello
123
99
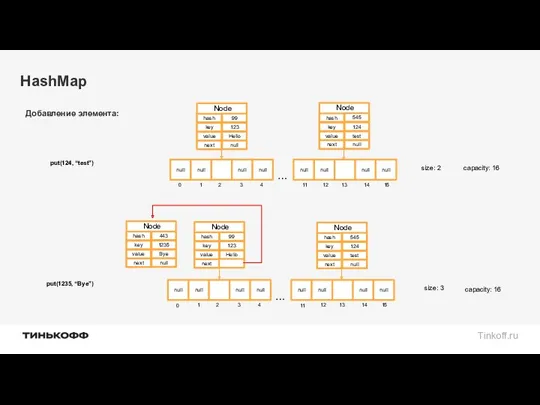
put(1235, “Bye”)
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 3
capacity: 16
…
put(124, “test”)
next
Node
value
key
hash
null
Hello
123
99
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
1235
443
Добавление элемента:
HashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
next
Node
value
key
hash
Hello
123
99
put(1235, “Bye”)
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 3
capacity: 16
…
put(124, “test”)
next
Node
value
key
hash
null
Hello
123
99
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
1235
443
Добавление элемента:

HashMap
Коллизия – ситуация, когда элементы с разными ключами попадают в одну
HashMap
Коллизия – ситуация, когда элементы с разными ключами попадают в одну

HashMap
При достижении размера списка в TREEIFY_THRESHOLD равному 8 элементам, происходит ребалансировка
HashMap
При достижении размера списка в TREEIFY_THRESHOLD равному 8 элементам, происходит ребалансировка
HashMap
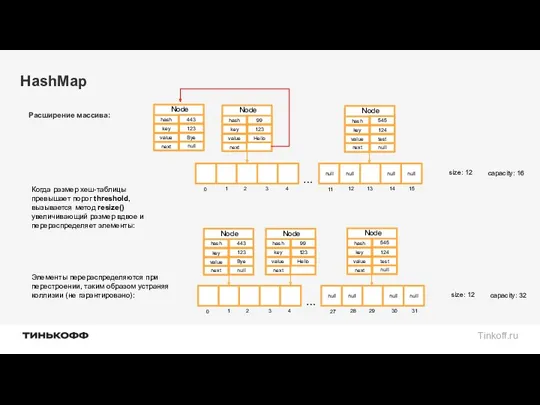
Расширение массива:
next
Node
value
key
hash
Hello
123
99
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 12
capacity: 16
…
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
123
443
next
Node
value
key
hash
Hello
123
99
0
1
2
3
4
null
null
null
null
27
28
29
30
31
size: 12
capacity: 32
…
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
123
443
Элементы перераспределяются при
перестроении, таким образом устраняя
коллизии
HashMap
Расширение массива:
next
Node
value
key
hash
Hello
123
99
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 12
capacity: 16
…
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
123
443
next
Node
value
key
hash
Hello
123
99
0
1
2
3
4
null
null
null
null
27
28
29
30
31
size: 12
capacity: 32
…
next
Node
value
key
hash
null
test
124
545
next
Node
value
key
hash
null
Bye
123
443
Элементы перераспределяются при
перестроении, таким образом устраняя
коллизии
HashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
next
Node
value
key
hash
Hello
123
99
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 1
capacity: 16
…
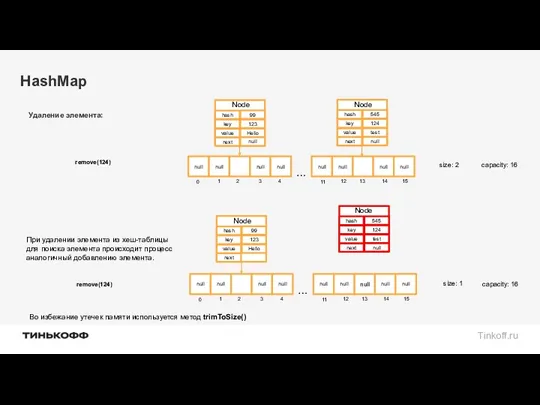
remove(124)
next
Node
value
key
hash
null
Hello
123
99
next
Node
value
key
hash
null
test
124
545
next
value
key
hash
null
test
124
545
Node
При удалении элемента из хеш-таблицы
для поиска элемента
HashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
next
Node
value
key
hash
Hello
123
99
null
null
null
null
0
1
2
3
4
null
null
null
null
null
11
12
13
14
15
size: 1
capacity: 16
…
remove(124)
next
Node
value
key
hash
null
Hello
123
99
next
Node
value
key
hash
null
test
124
545
next
value
key
hash
null
test
124
545
Node
При удалении элемента из хеш-таблицы для поиска элемента

HashMap
Оценка сложности основных операций:
HashMap
Оценка сложности основных операций:
LinkedHashMap
LinkedHashMap – хеш-таблица, реализованная на основе динамического массива, являющаяся так же
LinkedHashMap
LinkedHashMap – хеш-таблица, реализованная на основе динамического массива, являющаяся так же
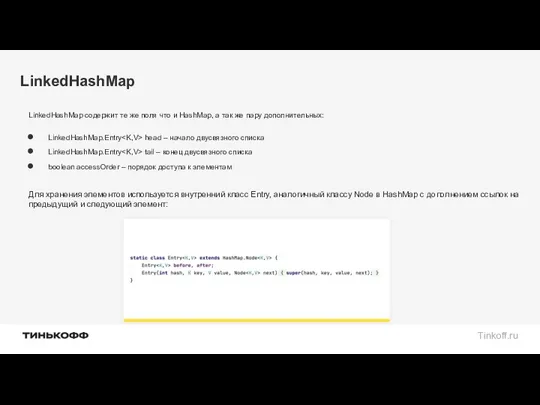
LinkedHashMap
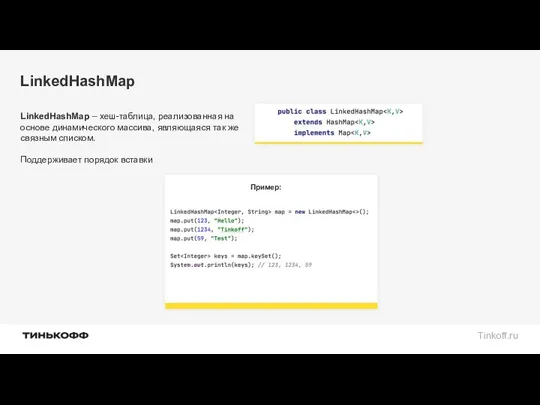
LinkedHashMap содержит те же поля что и HashMap, а так же
LinkedHashMap
LinkedHashMap содержит те же поля что и HashMap, а так же

LinkedHashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
Node
after
before
next
value
key
hash
Hello
12
51
null
null
Node
after
before
next
value
key
hash
Test
54
99
null
null
Операции удаления, получения по ключу, удаления аналогичны операциям HashMap.
LinkedHashMap
null
null
null
null
0
1
2
3
4
null
null
null
null
11
12
13
14
15
size: 2
capacity: 16
…
Node
after
before
next
value
key
hash
Hello
12
51
null
null
Node
after
before
next
value
key
hash
Test
54
99
null
null
Операции удаления, получения по ключу, удаления аналогичны операциям HashMap.

LinkedHashMap
Поле accessOrder определяет порядок итерации по элементам:
accessOrder=true – итерация в порядке
LinkedHashMap
Поле accessOrder определяет порядок итерации по элементам:
accessOrder=true – итерация в порядке
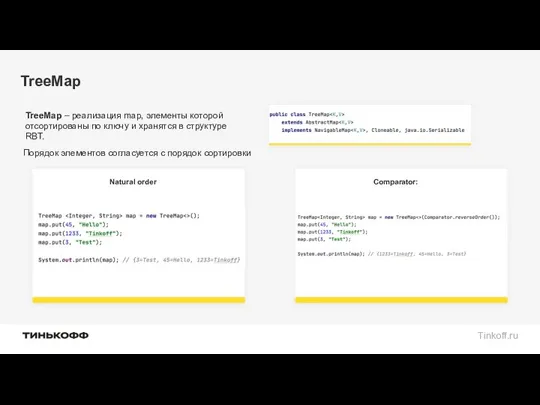
TreeMap
TreeMap – реализация map, элементы которой отсортированы по ключу и хранятся
TreeMap
TreeMap – реализация map, элементы которой отсортированы по ключу и хранятся
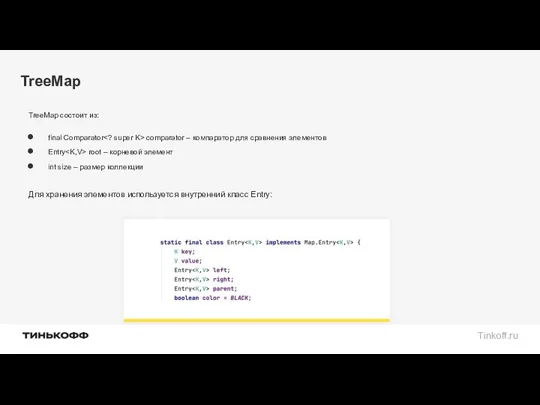
TreeMap
TreeMap состоит из:
final Comparator comparator – компаратор для сравнения
TreeMap
TreeMap состоит из:
final Comparator comparator – компаратор для сравнения
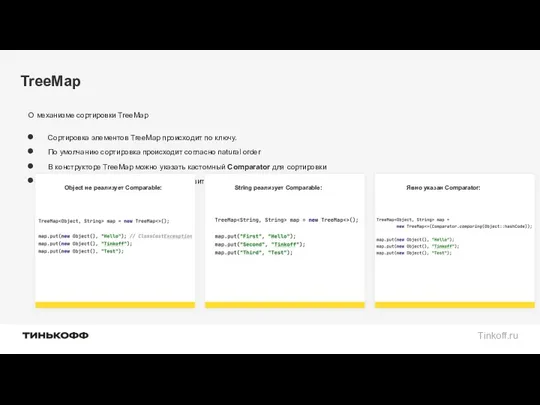
TreeMap
О механизме сортировки TreeMap
Сортировка элементов TreeMap происходит по ключу.
По умолчанию
TreeMap
О механизме сортировки TreeMap
Сортировка элементов TreeMap происходит по ключу.
По умолчанию
TreeMap
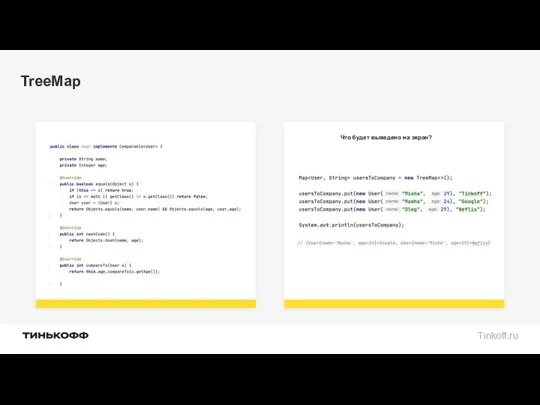
Что будет выведено на экран?
TreeMap
Что будет выведено на экран?
TreeMap
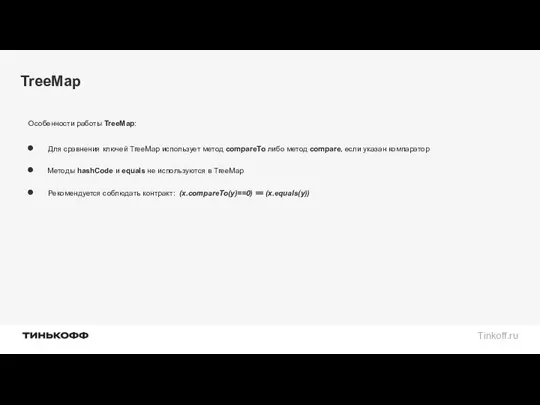
Для сравнения ключей TreeMap использует метод compareTo либо метод compare, если
TreeMap
Для сравнения ключей TreeMap использует метод compareTo либо метод compare, если

TreeMap
7
10
11
5
12
12
5
3
10
7
11
6
8
4
19
13
17
14
Обычное бинарное дерево не сбалансировано, в худших случаях
давая скорость поиска
TreeMap
7
10
11
5
12
12
5
3
10
7
11
6
8
4
19
13
17
14
Обычное бинарное дерево не сбалансировано, в худших случаях давая скорость поиска

TreeMap
Оценка сложности основных операций:
TreeMap
Оценка сложности основных операций:

Set
Set – представляет собой множество уникальных элементов
Представители:
TreeSet – элементы отсортированы по
Set
Set – представляет собой множество уникальных элементов
Представители:
TreeSet – элементы отсортированы по
HashSet
HashSet – множество элементов, использующее для хранения хеш-таблицу
Пример:
HashSet
HashSet – множество элементов, использующее для хранения хеш-таблицу
Пример:

HashSet
Получение элемента из Hashset:
Пример:
Set не предоставляет методов для получения объектов (кроме
HashSet
Получение элемента из Hashset:
Пример:
Set не предоставляет методов для получения объектов (кроме

HashSet
HashSet в своей реализации использует HashMap:
В качестве ключа – сами объекты
В
HashSet
HashSet в своей реализации использует HashMap:
В качестве ключа – сами объекты
В
LinkedHashSet
LinkedHashSet – множество элементов, использующее для хранения хеш-таблицу в сочетании с
LinkedHashSet
LinkedHashSet – множество элементов, использующее для хранения хеш-таблицу в сочетании с
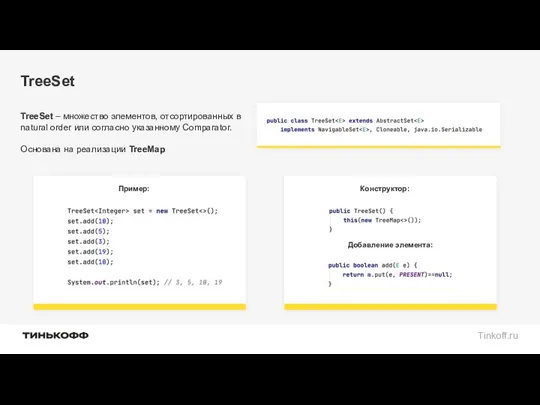
TreeSet
TreeSet – множество элементов, отсортированных в natural order или согласно указанному
TreeSet
TreeSet – множество элементов, отсортированных в natural order или согласно указанному
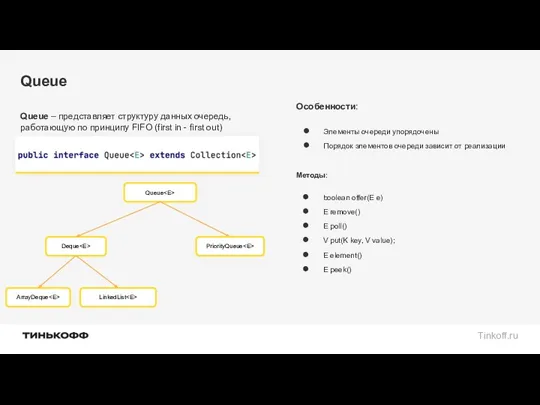
Queue
Queue – представляет структуру данных очередь, работающую по принципу FIFO (first
Queue
Queue – представляет структуру данных очередь, работающую по принципу FIFO (first

LinkedList as Queue
LinkedList - пример реализации очереди с классически FIFO
Основные методы:
boolean
LinkedList as Queue
LinkedList - пример реализации очереди с классически FIFO
Основные методы:
boolean
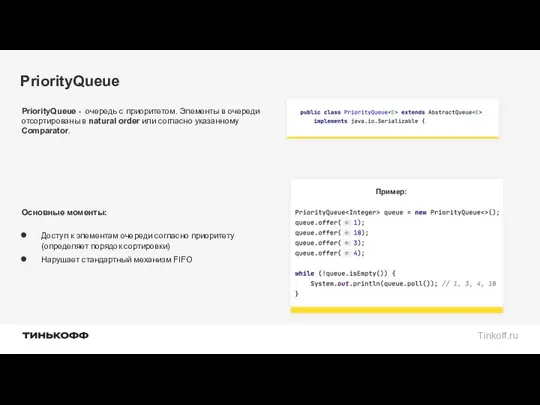
PriorityQueue
PriorityQueue - очередь с приоритетом. Элементы в очереди отсортированы в natural
PriorityQueue
PriorityQueue - очередь с приоритетом. Элементы в очереди отсортированы в natural
![PriorityQueue PriorityQueue состоит из: Object[] queue – массив с элементами](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/396507/slide-57.jpg)
PriorityQueue
PriorityQueue состоит из:
Object[] queue – массив с элементами очереди
int size –
PriorityQueue
PriorityQueue состоит из:
Object[] queue – массив с элементами очереди
int size –

PriorityQueue
В основе PriorityQueue лежит структура данных - бинарная куча:
Значение в любой
PriorityQueue
В основе PriorityQueue лежит структура данных - бинарная куча:
Значение в любой
PriorityQueue
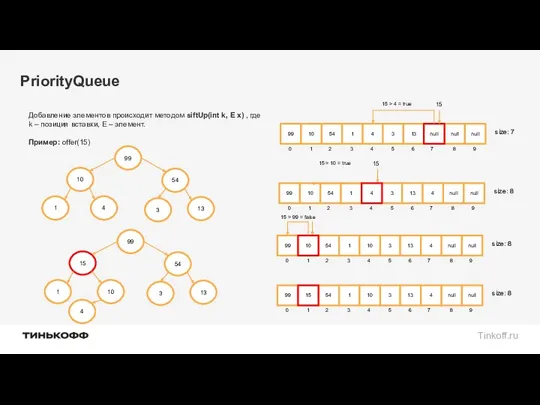
Добавление элементов происходит методом siftUp(int k, E x) , где k
PriorityQueue
Добавление элементов происходит методом siftUp(int k, E x) , где k
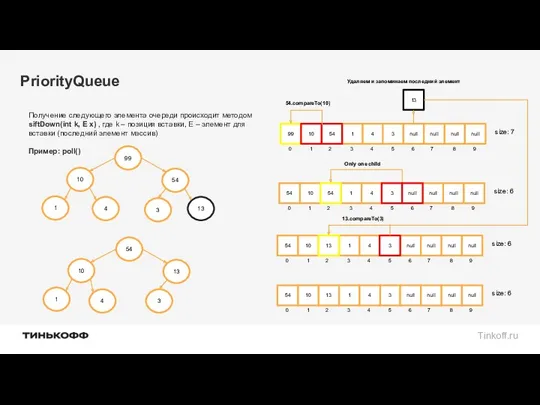
PriorityQueue
Получениe следующего элемента очереди происходит методом siftDown(int k, E x) ,
PriorityQueue
Получениe следующего элемента очереди происходит методом siftDown(int k, E x) ,

PriorityQueue
Оценка сложности основных операций:
PriorityQueue
Оценка сложности основных операций:

Deque
Deque – расширяет интерфейс Queue, добавляю функциональность двунаправленной очереди
Особенности:
Элементы очереди упорядочены
Возможность
Deque
Deque – расширяет интерфейс Queue, добавляю функциональность двунаправленной очереди
Особенности:
Элементы очереди упорядочены
Возможность
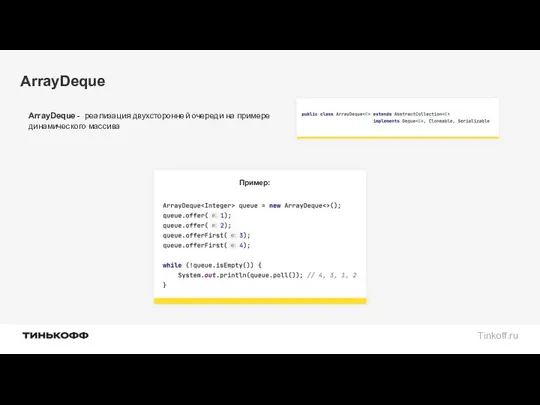
ArrayDeque
ArrayDeque - реализация двухсторонней очереди на примере динамического массива
Пример:
ArrayDeque
ArrayDeque - реализация двухсторонней очереди на примере динамического массива
Пример:
![ArrayDeque ArrayDeque состоит из: Object[] elementData – массив с хранимыми](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/396507/slide-64.jpg)
ArrayDeque
ArrayDeque состоит из:
Object[] elementData – массив с хранимыми объектами
int size –
ArrayDeque
ArrayDeque состоит из:
Object[] elementData – массив с хранимыми объектами
int size –
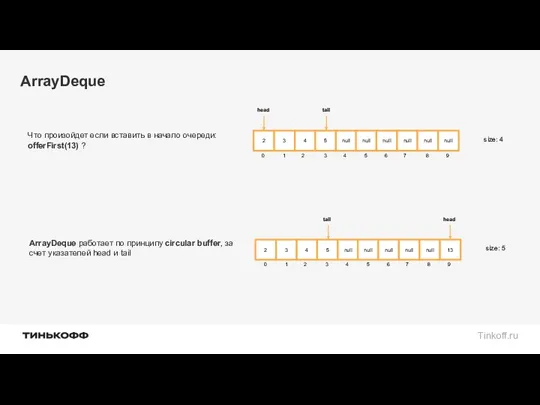
ArrayDeque
Что произойдет если вставить в начало очереди:
offerFirst(13) ?
2
3
4
5
null
1
2
3
4
null
null
null
null
null
6
7
8
9
size: 4
head
0
5
tail
ArrayDeque работает по
ArrayDeque
Что произойдет если вставить в начало очереди:
offerFirst(13) ?
2
3
4
5
null
1
2
3
4
null
null
null
null
null
6
7
8
9
size: 4
head
0
5
tail
ArrayDeque работает по
Thread safety?
Большая часть рассмотренных коллекций НЕ потокобезопасна (кроме hashtable, vector, stack).
Для
Thread safety?
Большая часть рассмотренных коллекций НЕ потокобезопасна (кроме hashtable, vector, stack).
Для

EnumSet
Типичный пример хранения Enum объектов:
EnumSet
Типичный пример хранения Enum объектов:

EnumSet
Для хранения множества Enum объектов используем EnumSet:
EnumSet использует bit vector для
EnumSet
Для хранения множества Enum объектов используем EnumSet:
EnumSet использует bit vector для

EnumMap
При выборе Map можно использовать EnumMap, если в качестве ключа Enum
EnumMap
При выборе Map можно использовать EnumMap, если в качестве ключа Enum
Since Java 9
Добавились полезные фабричные утилитарные методы:
Set.of()
List.of()
Map.of()
Since Java 9
Добавились полезные фабричные утилитарные методы:
Set.of()
List.of()
Map.of()
Stream API
Stream API – набор инструментов (since Java 8), предоставляющих возможность
Stream API
Stream API – набор инструментов (since Java 8), предоставляющих возможность

Stream API
Stream API предоставляет возможность работать со структурами данных в функциональном
Stream API
Stream API предоставляет возможность работать со структурами данных в функциональном
Stream
Stream – последовательность элементов для, потоковой обработки
Основные моменты:
Предоставляет интерфейс для последовательности
Stream
Stream – последовательность элементов для, потоковой обработки
Основные моменты:
Предоставляет интерфейс для последовательности
Stream API
Stream Pipeline состоит из:
Источник данных (коллекция, массив, файл и т.д.)
Промежуточные
Stream API
Stream Pipeline состоит из:
Источник данных (коллекция, массив, файл и т.д.)
Промежуточные
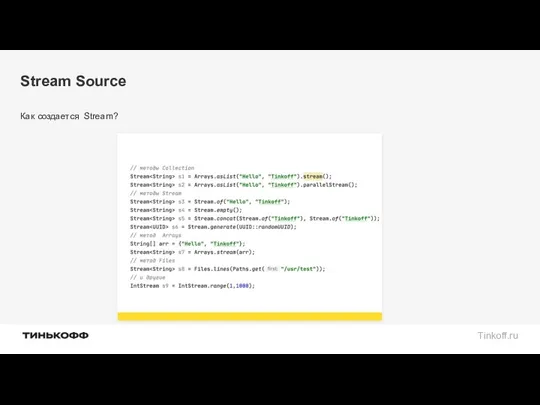
Stream Source
Как создается Stream?
Stream Source
Как создается Stream?

Intermediate operations
Промежуточные операции:
map(Function m)
filter(Predicate p)
flatMap(Function m)
peek(Consumer c)
skip(long n)
limit(long n)
sorted(Comparator r)
boxed()
parallel()
sequential()
c Java
Intermediate operations
Промежуточные операции:
map(Function m)
filter(Predicate p)
flatMap(Function m)
peek(Consumer c)
skip(long n)
limit(long n)
sorted(Comparator r)
boxed()
parallel()
sequential()
c Java

Terminal operations
Терминальные операции:
collect(Collector c)
reduce(BinaryOperator b)
findFirst()
findAny()
forEach(Consumer c)
allMatch(Predicate p)
anyMatch(Predicate p)
anyMatch
count
collect
findFirst
Terminal operations
Терминальные операции:
collect(Collector c)
reduce(BinaryOperator b)
findFirst()
findAny()
forEach(Consumer c)
allMatch(Predicate p)
anyMatch(Predicate p)
anyMatch
count
collect
findFirst

Collectors
Основные коллекторы содержатся в утилитарном классе Collectors:
toList()
toSet()
counting()
toMap()
groupingBy()
joining()
toCollection()
averagingInt() averagingLong(), averagingLong()
toMap
groupingBy
Collectors
Основные коллекторы содержатся в утилитарном классе Collectors:
toList()
toSet()
counting()
toMap()
groupingBy()
joining()
toCollection()
averagingInt() averagingLong(), averagingLong()
toMap
groupingBy

Short circuit
Что будет выведено в stdout?
Некоторые терминальные операции являются короткозамкнутыми (short
Short circuit
Что будет выведено в stdout?
Некоторые терминальные операции являются короткозамкнутыми (short

Stream API
Что будет выведено в stdout?
Lazy evaluation
Стримы в Java “ленивы”
Stream API
Что будет выведено в stdout?
Lazy evaluation
Стримы в Java “ленивы”

Parallel streams
Можно создавать параллельные потоки с помощью методов:
parallelStream()
parallel()
Перед использованием
Parallel streams
Можно создавать параллельные потоки с помощью методов:
parallelStream()
parallel()
Перед использованием

Вопросы
Вопросы

Перерыв
Перерыв

Generics
Generics
Introduction
Что обсудим:
Что такое дженерики и зачем они нужны
Что такое wildcards, какие
Introduction
Что обсудим:
Что такое дженерики и зачем они нужны
Что такое wildcards, какие
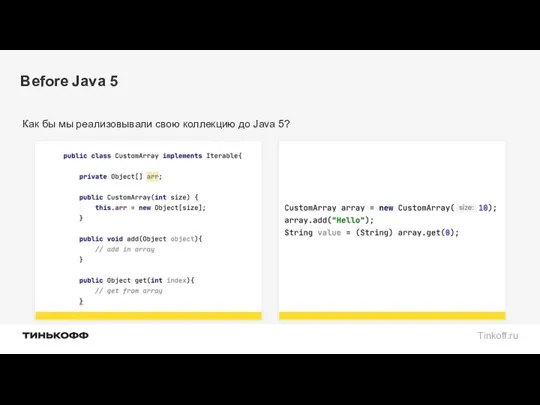
Before Java 5
Как бы мы реализовывали свою коллекцию до Java 5?
Before Java 5
Как бы мы реализовывали свою коллекцию до Java 5?
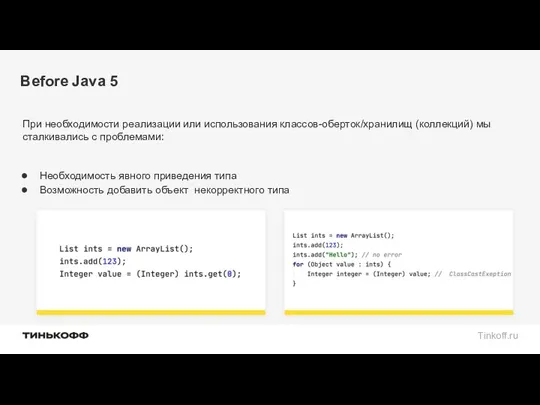
Before Java 5
При необходимости реализации или использования классов-оберток/хранилищ (коллекций) мы сталкивались
Before Java 5
При необходимости реализации или использования классов-оберток/хранилищ (коллекций) мы сталкивались

Before Java 5
Корректное использование Collection API до появления дженериков:
Before Java 5
Корректное использование Collection API до появления дженериков:
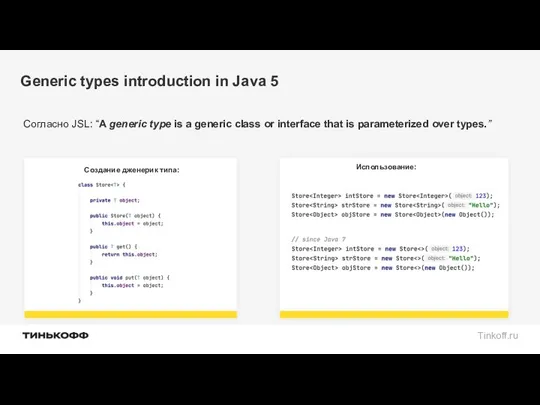
Generic types introduction in Java 5
Согласно JSL: “A generic type is a generic
Generic types introduction in Java 5
Согласно JSL: “A generic type is a generic

Generic types
Типобезопасность во время компиляции:
Основные преимущества дженериков:
Универсальность алгоритмов:
Отсутствие необходимости приведения
Generic types
Типобезопасность во время компиляции:
Основные преимущества дженериков:
Универсальность алгоритмов:
Отсутствие необходимости приведения
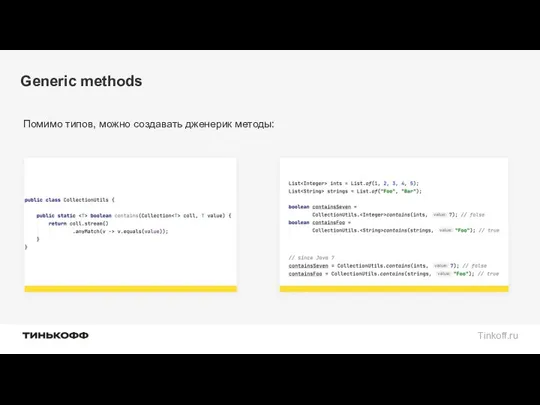
Generic methods
Помимо типов, можно создавать дженерик методы:
Generic methods
Помимо типов, можно создавать дженерик методы:

Type inference
Java – статически типизированный язык, т.е. значение переменной должно быть
Type inference
Java – статически типизированный язык, т.е. значение переменной должно быть

Type inference
Type Inference – способность компилятора определять тип выражения из контекста
Type inference
Type Inference – способность компилятора определять тип выражения из контекста

Type inference
Type Inference позволяет определить параметр типа и не указывать явно:
По
Type inference
Type Inference позволяет определить параметр типа и не указывать явно:
По
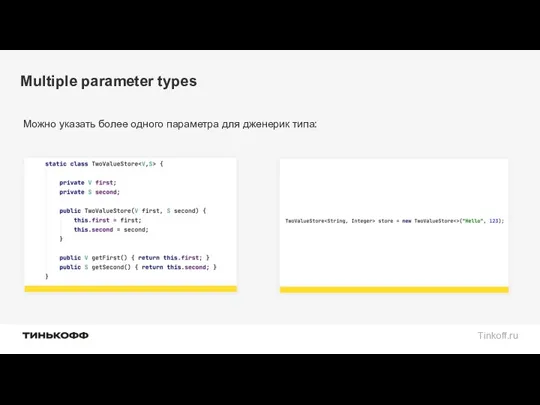
Multiple parameter types
Можно указать более одного параметра для дженерик типа:
Multiple parameter types
Можно указать более одного параметра для дженерик типа:

Naming conventions
Рекомендации по именованию параметров:
E – элемент (при использовании Collection API)
K
Naming conventions
Рекомендации по именованию параметров:
E – элемент (при использовании Collection API)
K

Raw type
Raw types (или сырые типы) это дженерик тип, используемый без
Raw type
Raw types (или сырые типы) это дженерик тип, используемый без

Bounded type parameter
А что если есть необходимость ограничить параметр типа?
Параметр типа
Bounded type parameter
А что если есть необходимость ограничить параметр типа?
Параметр типа

Bounded type parameters
Аналогично ограничивать параметр типа можно и дженерик методе:
Параметр типа
Bounded type parameters
Аналогично ограничивать параметр типа можно и дженерик методе:
Параметр типа

Multiple bounds
Можно указывать несколько ограничений для типа параметра.
Multiple bounds
Можно указывать несколько ограничений для типа параметра.
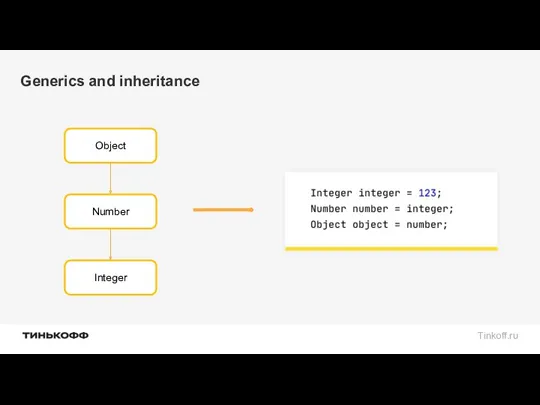
Generics and inheritance
Object
Number
Integer
Generics and inheritance
Object
Number
Integer

Generics and inheritance
?
Generics and inheritance
?

Generics and inheritance
List
Generics and inheritance
List

Covariance and Invariance
Ковариантность – это сохранение иерархии наследования исходных типов в
Covariance and Invariance
Ковариантность – это сохранение иерархии наследования исходных типов в

Wildcards
Wildcard в дженериках называется символ ?, означающий неизвестный тип (unknown type).
Wildcards
Wildcards
Wildcard в дженериках называется символ ?, означающий неизвестный тип (unknown type).
Wildcards

Wildcards. Unbounded
Используется когда нам не важен тип параметра:
List означает, что список
Wildcards. Unbounded
Используется когда нам не важен тип параметра:
List означает, что список

Wildcards. Unbounded
Wildcards. Unbounded

Wildcards. Unbounded
Нельзя поместить ни один объект в List (кроме null):
Wildcard добавляет
Wildcards. Unbounded
Нельзя поместить ни один объект в List (кроме null):
Wildcard добавляет

Upper Bounded Wildcards
Upper bounded wildcard добавляет границу «сверху» для типа параметра
Upper Bounded Wildcards
Upper bounded wildcard добавляет границу «сверху» для типа параметра

Upper Bounded Wildcards
Upper Bounded Wildcards

Upper Bounded Wildcards
Wildcard с верхней границей так же ковариантны
List
List
List
Возвращаемый
Upper Bounded Wildcards
Wildcard с верхней границей так же ковариантны
List
List List Возвращаемый

Upper Bounded Wildcards
Upper Bounded Wildcards

Lower Bounded Wildcards
Lower bounded wildcard добавляет границу «снизу» для типа параметра
Lower Bounded Wildcards
Lower bounded wildcard добавляет границу «снизу» для типа параметра

Lower Bounded Wildcards
Lower Bounded Wildcards

Lower Bounded Wildcards
Wildcard с нижней границей контравариантны
Возвращаемый тип - Object:
Положить можно
Lower Bounded Wildcards
Wildcard с нижней границей контравариантны
Возвращаемый тип - Object:
Положить можно

Upper Bounded Wildcards
Upper Bounded Wildcards

PECS
Pecs (producer-extends, consumer-super) principle stands for:
Если объявляем wildcard extends, то он
PECS
Pecs (producer-extends, consumer-super) principle stands for:
Если объявляем wildcard extends, то он

Recursive type bounds
В редких случаях может быть полезно ограничивать тип параметра
Recursive type bounds
В редких случаях может быть полезно ограничивать тип параметра

Generics under the hood
Во время компиляции стирается вся информация о типах
Generics under the hood
Во время компиляции стирается вся информация о типах

Generics under the hood
Что делает компилятор:
Что видим коде:
Что делает компилятор:
Что видим
Generics under the hood
Что делает компилятор:
Что видим коде:
Что делает компилятор:
Что видим

Type erasure
Type erasure – стирание информации о типах-параметрах во время компиляции.
Type erasure
Type erasure – стирание информации о типах-параметрах во время компиляции.

Type erasure. Type cast
Добавление явного преобразования типа
Что делает компилятор:
Что видим коде:
Type erasure. Type cast
Добавление явного преобразования типа
Что делает компилятор:
Что видим коде:

Type erasure. Bridge methods
После стирания типов:
Реализуем простой дженерик класс:
Type erasure. Bridge methods
После стирания типов:
Реализуем простой дженерик класс:

Type erasure. Bridge methods
Для сохранения полиморфизма компилятор создает синтетический Bridge метод:
Компилятор
Type erasure. Bridge methods
Для сохранения полиморфизма компилятор создает синтетический Bridge метод:
Компилятор

Super type token
Действительно ли нельзя получить информацию о типе параметра дженерика
Super type token
Действительно ли нельзя получить информацию о типе параметра дженерика

Super type token
Super type token
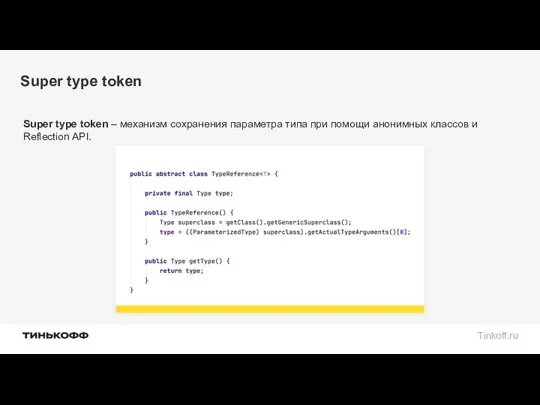
Super type token
Super type token – механизм сохранения параметра типа при
Super type token
Super type token – механизм сохранения параметра типа при
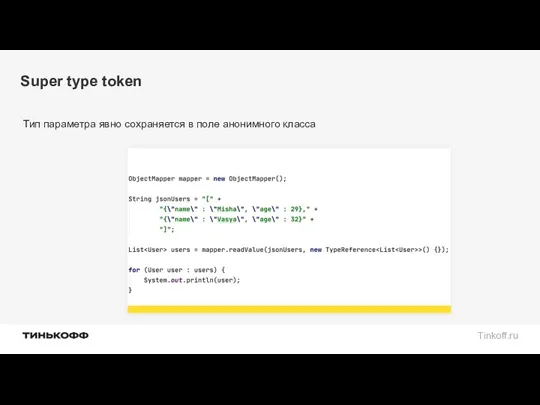
Super type token
Тип параметра явно сохраняется в поле анонимного класса
Super type token
Тип параметра явно сохраняется в поле анонимного класса

Generic restrictions
Как нельзя использовать дженерики?
Тип-параметр дженерика не может быть примитивом
Нельзя создать
Generic restrictions
Как нельзя использовать дженерики?
Тип-параметр дженерика не может быть примитивом
Нельзя создать

Conclusion
Итог:
Дженерики помогают писать обобщенный, универсальный код
Дженерики приносят типобезопасность во время компиляции
Conclusion
Итог:
Дженерики помогают писать обобщенный, универсальный код
Дженерики приносят типобезопасность во время компиляции

Вопросы
Вопросы

Homework
Homework
 Global Social Media Plan
Global Social Media Plan Чек-лист по загрузке и продвижению видео на Instagram
Чек-лист по загрузке и продвижению видео на Instagram Паттерны проектирования
Паттерны проектирования Спам. Виды спама
Спам. Виды спама презентация по теме MS DOS
презентация по теме MS DOS TRW product introduction
TRW product introduction Архитектуры обработки данных. (Лекция 6)
Архитектуры обработки данных. (Лекция 6) Microsoft Word 2010
Microsoft Word 2010 Полезно ли приложение Tik Tok?
Полезно ли приложение Tik Tok? Урок 4. Стратегия. Цели. Планы. Миллион рублей без миллиона подписчиков
Урок 4. Стратегия. Цели. Планы. Миллион рублей без миллиона подписчиков Интерфейс. Общие определени.я Интерфейс пользователя. Междупрограммный интерфейс
Интерфейс. Общие определени.я Интерфейс пользователя. Междупрограммный интерфейс ИОС различных уровней
ИОС различных уровней Перші кроки до електронного декларування. Отримання електронних цифрових підписів
Перші кроки до електронного декларування. Отримання електронних цифрових підписів Разработка информационно-программного обеспечения управления взаимодействием с клиентами с использованием мобильных устройств
Разработка информационно-программного обеспечения управления взаимодействием с клиентами с использованием мобильных устройств VoIP – это просто
VoIP – это просто Решение задач на компьютере. Алгоритмизация и программирование
Решение задач на компьютере. Алгоритмизация и программирование Архітектура операційних систем
Архітектура операційних систем Вводная лекция по Java. ООП
Вводная лекция по Java. ООП Беспроводной интернет, особенности и функционирования
Беспроводной интернет, особенности и функционирования Информационное моделирование математические модели
Информационное моделирование математические модели Введение в CALS технологии
Введение в CALS технологии Тема урока: Растровая и векторная анимация
Тема урока: Растровая и векторная анимация Жаңа ақпараттық оқыту технологиясы
Жаңа ақпараттық оқыту технологиясы Решение задачи №9 Простейший циклический алгоритм. Информатика ОГЭ 9 клас
Решение задачи №9 Простейший циклический алгоритм. Информатика ОГЭ 9 клас Обработка исключений. Предопределенные ИС
Обработка исключений. Предопределенные ИС BIM: Междисциплинарная координация
BIM: Междисциплинарная координация Тестирование программного обеспечения. Основы реляционных баз данных. Работа с SQL. (Урок 6)
Тестирование программного обеспечения. Основы реляционных баз данных. Работа с SQL. (Урок 6) Сети ЭВМ и телекоммуникации
Сети ЭВМ и телекоммуникации