Параллельное и распределенное программирование. Технология программирования гетерогенных систем OpenCL презентация
- Параллельное и распределенное программирование. Технология программирования гетерогенных систем OpenCL

Содержание
- 2. Модель потоков GPU
- 3. План Wavefronts и warps Планирование потоков на графических процессорах Синхронизация
- 4. Модель исполнения. Индексное пространство Gx , Gy – глобальные размеры; Sx, Sy – локальные размеры рабочей
- 5. Work Groups относительно HW Threads Ядра OpenCL структурированы в рабочие группы, которые сопоставляются с вычислительными единицами
- 6. Work-Item планирование Аппаратное обеспечение создает wavefronts, группируя рабочие элементы рабочей группы Сначала по размеру X Все
- 7. Wavefront планирование Размер Wavefront - 64 рабочих элемента Векторные инструкции выполняются каждым рабочим элементом Скалярные инструкции
- 8. Wavefront планирование В случае небезопасного чтения-записи (RAW) один wavefront остановится на четыре дополнительных цикла Если доступен
- 9. GPU загруженность Локальная память и регистры сохраняются в вычислительном блоке после того, как запланирована рабочая группа
- 10. Поток управления Хотя рабочие элементы имеют уникальные счетчики программ, на практике они выполняются на SIMD-оборудовании Рабочие
- 11. Контроль потоков Как обрабатываются рабочие элементы с разными условиями выполнения, когда одна и та же команда
- 12. Предикация для GPUs Предикат - это код условия, для которого задано значение true или false на
- 13. Расходящийся поток управления Случай 1: все нечетные рабочие элементы будут выполняться, если if, в то время
- 14. Влияние предикатов на производительность T = tstart T = tstart + t1 + t2 Do_Some_Work() Do_Other
- 15. От забора до барьера CL_{LOCAL,GLOBAL}_MEM_FENCE Забор mem_fence(cl_mem_fence_flags flags) {read|write}_mem_fence (cl_mem_fence_flags flags) Барьер barrier(cl_mem_fence_flags flags)
- 16. Оптимизация функции ядра
- 17. Coalescing при доступе к памяти Рабочие элементы обращаются к элементам буфера Один запрос к памяти будет
- 18. Coalescing при доступе к памяти Для аппаратного обеспечения 64 рабочих элемента образуют wavefront и должны выполнять
- 19. Coalescing при доступе к памяти Производительность глобальной памяти для простого копирования данных ядра полностью объединенного и
- 20. Векторизация Векторизация позволяет одному рабочему элементу выполнять сразу несколько операций Явная векторизация достигается путем использования векторных
- 21. Векторизация Векторизация повышает производительность памяти на AMD Northern Islands и Evergreen GPU
- 22. Локальная память На графических процессорах локальная память отображает в высокоскоростную память с малой задержкой, расположенную на
- 23. Константная память Константная память - это пространство памяти для хранения данных, к которым одновременно обращаются все
- 24. Загруженность Рабочие элементы из рабочей группы запускаются вместе на вычислительном устройстве Если ресурсов достаточно, несколько рабочих
- 25. Загруженность: регистры Регистры являются одним из основных ограничивающих факторов для больших ядер На текущих графических процессорах
- 26. Загруженность: регистры Рассмотрим другой пример: Графический процессор имеет 16384 регистра на единицу расчета Размер рабочей группы
- 27. Загруженность: локальная память Графические процессоры имеют ограниченную локальную память на каждом вычислительном блоке 64 КБ локальной
- 28. Загруженность: Work-items/work-groups У графических процессоров есть аппаратные ограничения на максимальное количество рабочих элементов на рабочую группу
- 29. Загруженность: ограничивающие факторы Минимальным из этих трех факторов является то, что ограничивает активное количество рабочих элементов
- 30. Сопоставление потоков Сопоставление потоков определяет, какие потоки будут получать доступ к данным Правильные сопоставления могут согласовываться
- 31. Сопоставление потоков Используя различные сопоставления, один и тот же поток может быть назначен для доступа к
- 32. Сопоставление потоков Рассмотрим последовательный алгоритм умножения матрицы Этот алгоритм подходит для декомпозиции выходных данных Мы создадим
- 33. Сопоставление потоков Отображение нитей 1: с пространством индексов MxN : Отображение нитей 2: с пространством индекса
- 34. Сопоставление потоков На этом рисунке показано выполнение двух сопоставлений потоков на графических процессорах NVIDIA GeForce 285
- 35. Сопоставление потоков Расхождение во времени выполнения между сопоставлениями связано с доступом к данным на глобальной шине
- 36. Сопоставление потоков В отображении 1 последовательные потоки (tx) сопоставляются с разными строками матрицы C, а непоследовательные
- 37. Сопоставление потоков В отображении 2 последовательные потоки (tx) отображаются в последовательные элементы в матрицах B и
- 38. Сопоставление потоков В общем случае потоки могут быть созданы и сопоставлены с любым элементом данных, управляя
- 39. Транспонирование матрицы Трансформация матрицы - это простой метод Out(x,y) = In(y,x) Независимо от того, какое сопоставление
- 40. Транспонирование матрицы Если локальная память используется для буферизации данных между чтением и записью, мы можем изменить
- 41. Транспонирование матрицы На следующем рисунке показано сравнение производительности двух ядер транспонирования для матриц размера NxM на
- 42. Выводы Хотя писать простую программу OpenCL относительно легко, оптимизация кода может быть сложнее Объединение доступа к
- 43. События, профилирование и отладка
- 44. События События используются для синхронизации между отдельными командами т. е. создать граф зависимостей команд Явная синхронизация
- 45. События В дополнение к заданию зависимостей события используются для базового профилирования команд Профилирование с использованием событий
- 46. Использование событий Используя события можем: Измерить время выполнения вызовов clEnqueue *, таких как выполнение ядра или
- 47. Профилирование с событиями clGetEventProfilingInfo позволяет нам запрашивать cl_event для получения желаемых значений счетчика Информация о сроках,
- 48. Профилирование с событиями В таблице показаны типы событий, описанные с использованием cl_profiling_info перечисляемого типа
- 49. Профилирование с событиями События OpenCL могут быть легко использованы для синхронизации ядер. Этот метод является надежным
- 50. Профилирование с событиями Прежде чем получать информацию о времени, мы должны убедиться, что события, которые нас
- 51. Получении информации о событии clGetEventInfo может использоваться для возврата информации о объекте события Он может возвращать
- 52. Пользовательские события OpenCL 1.1 и выше определяют объект события пользователя. В отличие от команд clEnqueue *
- 53. Пользовательские события Простой пример пользовательских событий, которые запускаются и используются в командной очереди // Create user
- 54. Список ожидания Список ожидания - это массивы типа cl_event Все методы clEnqueue * также принимают списки
- 55. Wait Lists Обеспечивает завершение списка событий до того, как конкретная команда выполнится Обеспечивает отметку места в
- 56. Event Callbacks OpenCL 1.1 или выше позволяет зарегистрировать сallbacks для определенного статуса выполнения команды Обратные вызовы
- 57. Синхронизация командных очередей Способы синхронизации очереди команд Flush: Отправляет все команды в очередь на вычислительное устройство
- 58. Отладка с использование printf Начиная с OpenCL 1.2, OpenCL C поддерживает печать во время выполнения с
- 59. Отладка с использование printf В следующем примере выводится информация о потоках, пытающихся выполнить неправильный доступ к
- 60. CodeXL Интегрированный профайлер, анализатор ядра и отладчик, разработанные AMD Режим профилирования Собирает данные производительности из среды
- 61. Отладка с использовнием CodeXL CodeXL перехватывает вызовы OpenCL API между приложением и OpenCL ICD CodeXL может
- 62. Профилирование с CodeXL Режим профилирования Трассировка временной шкалы приложения графического процессора Счетчики производительности графического процессора при
- 63. Просмотр временной шкалы приложения Обеспечивает визуальное представление выполнения приложения
- 64. Просмотр трассировки API-интерфейса хоста Выводит список всех вызовов OpenCL API, сделанных каждым потоком хоста в приложении
- 65. Сбор счетчиков производительности ядра GPU Счетчики производительности ядра графического процессора можно использовать для поиска возможных узких
- 67. Скачать презентацию

Модель потоков GPU
Модель потоков GPU

План
Wavefronts и warps
Планирование потоков на графических процессорах
Синхронизация
План
Wavefronts и warps
Планирование потоков на графических процессорах
Синхронизация
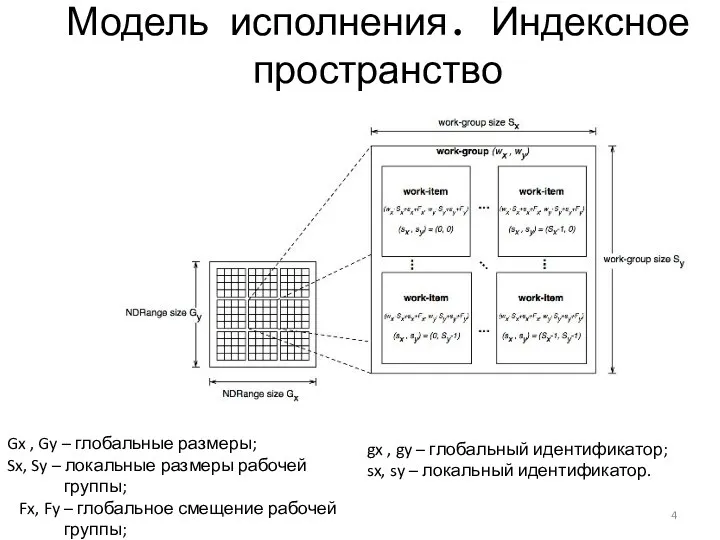
Модель исполнения. Индексное пространство
Gx , Gy – глобальные размеры;
Sx, Sy –
Модель исполнения. Индексное пространство
Gx , Gy – глобальные размеры;
Sx, Sy –
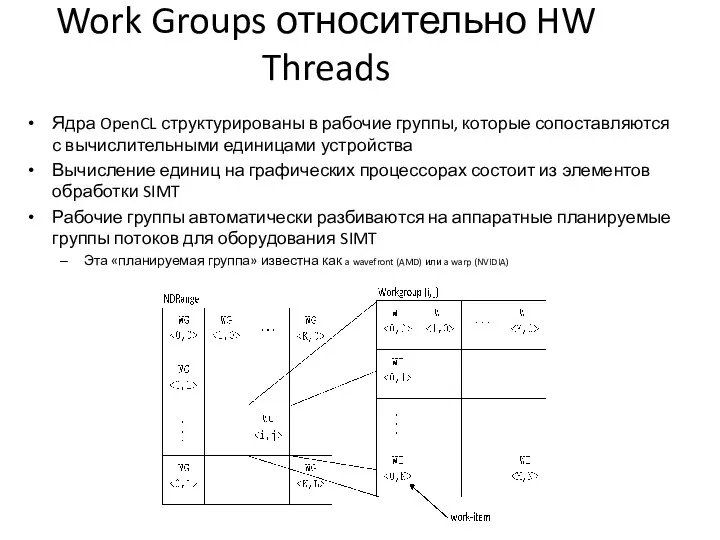
Work Groups относительно HW Threads
Ядра OpenCL структурированы в рабочие группы, которые
Work Groups относительно HW Threads
Ядра OpenCL структурированы в рабочие группы, которые

Work-Item планирование
Аппаратное обеспечение создает wavefronts, группируя рабочие элементы рабочей группы
Сначала по
Work-Item планирование
Аппаратное обеспечение создает wavefronts, группируя рабочие элементы рабочей группы
Сначала по

Wavefront планирование
Размер Wavefront - 64 рабочих элемента
Векторные инструкции выполняются каждым рабочим
Wavefront планирование
Размер Wavefront - 64 рабочих элемента
Векторные инструкции выполняются каждым рабочим

Wavefront планирование
В случае небезопасного чтения-записи (RAW) один wavefront остановится на четыре
Wavefront планирование
В случае небезопасного чтения-записи (RAW) один wavefront остановится на четыре

GPU загруженность
Локальная память и регистры сохраняются в вычислительном блоке после того,
GPU загруженность
Локальная память и регистры сохраняются в вычислительном блоке после того,

Поток управления
Хотя рабочие элементы имеют уникальные счетчики программ, на практике они
Поток управления
Хотя рабочие элементы имеют уникальные счетчики программ, на практике они

Контроль потоков
Как обрабатываются рабочие элементы с разными условиями выполнения, когда одна
Контроль потоков
Как обрабатываются рабочие элементы с разными условиями выполнения, когда одна

Предикация для GPUs
Предикат - это код условия, для которого задано значение
Предикация для GPUs
Предикат - это код условия, для которого задано значение

Расходящийся поток управления
Случай 1: все нечетные рабочие элементы будут выполняться, если
Расходящийся поток управления
Случай 1: все нечетные рабочие элементы будут выполняться, если
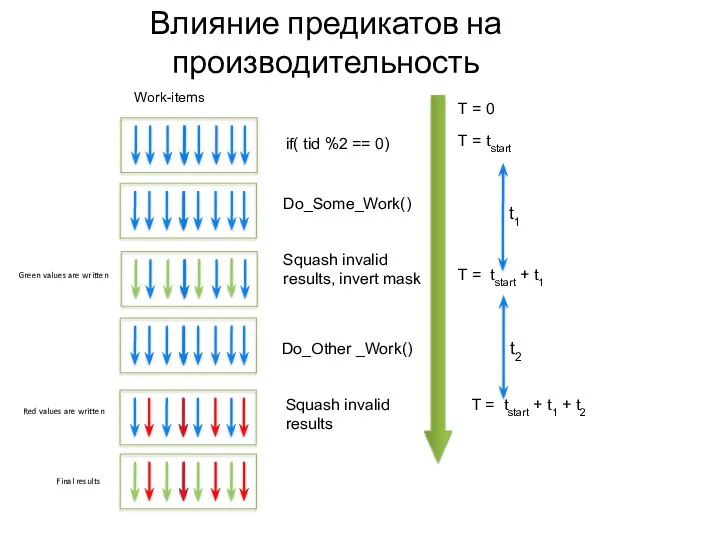
Влияние предикатов на производительность
T = tstart
T = tstart + t1 +
Влияние предикатов на производительность
T = tstart
T = tstart + t1 +

От забора до барьера
CL_{LOCAL,GLOBAL}_MEM_FENCE
Забор
mem_fence(cl_mem_fence_flags flags)
{read|write}_mem_fence
(cl_mem_fence_flags flags)
От забора до барьера
CL_{LOCAL,GLOBAL}_MEM_FENCE
Забор
mem_fence(cl_mem_fence_flags flags)
{read|write}_mem_fence
(cl_mem_fence_flags flags)

Оптимизация функции ядра
Оптимизация функции ядра
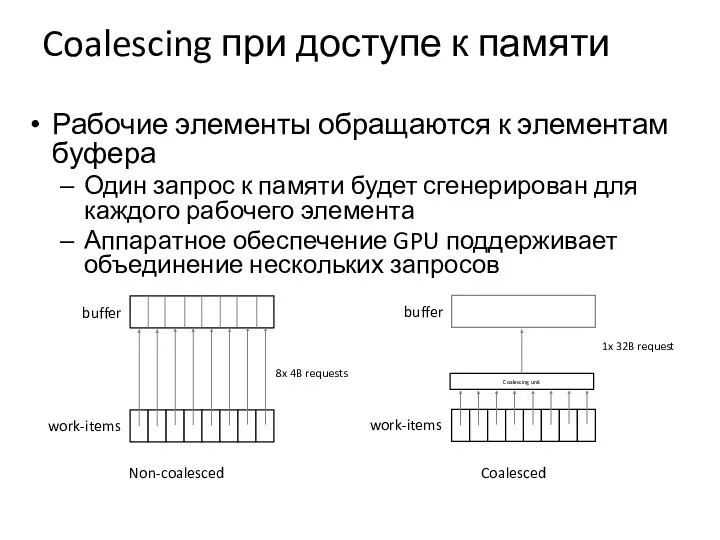
Coalescing при доступе к памяти
Рабочие элементы обращаются к элементам буфера
Один запрос
Coalescing при доступе к памяти
Рабочие элементы обращаются к элементам буфера
Один запрос

Coalescing при доступе к памяти
Для аппаратного обеспечения 64 рабочих элемента образуют
Coalescing при доступе к памяти
Для аппаратного обеспечения 64 рабочих элемента образуют
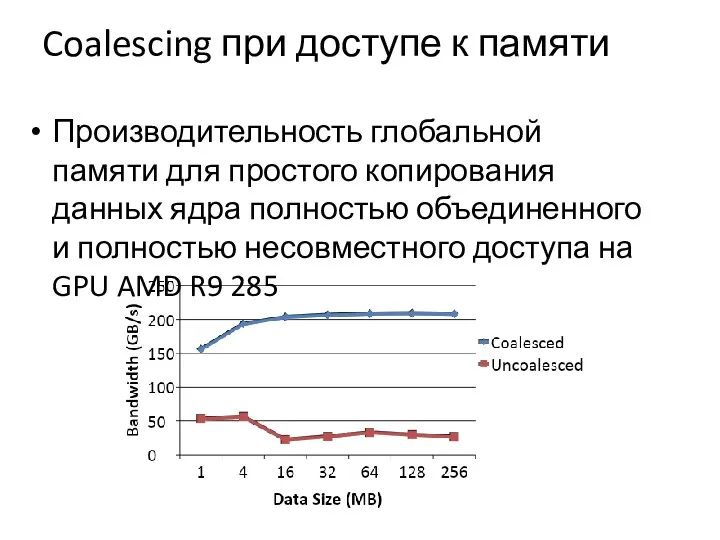
Coalescing при доступе к памяти
Производительность глобальной памяти для простого копирования данных
Coalescing при доступе к памяти
Производительность глобальной памяти для простого копирования данных

Векторизация
Векторизация позволяет одному рабочему элементу выполнять сразу несколько операций
Явная векторизация достигается
Векторизация
Векторизация позволяет одному рабочему элементу выполнять сразу несколько операций
Явная векторизация достигается
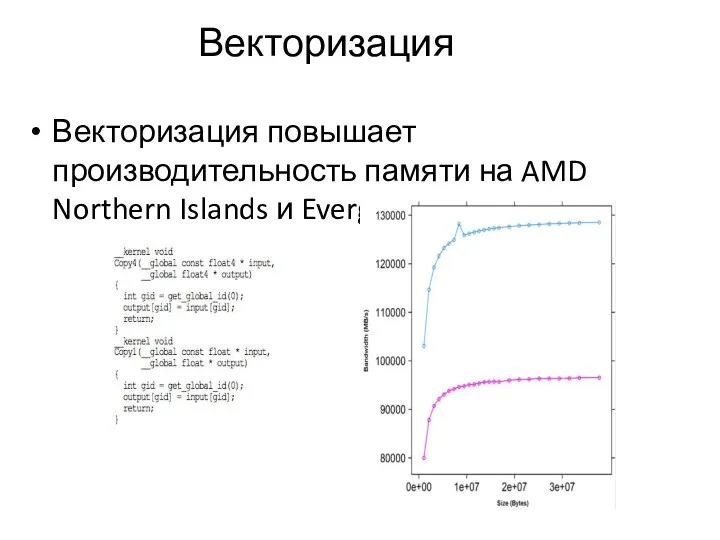
Векторизация
Векторизация повышает производительность памяти на AMD Northern Islands и Evergreen GPU
Векторизация
Векторизация повышает производительность памяти на AMD Northern Islands и Evergreen GPU

Локальная память
На графических процессорах локальная память отображает в высокоскоростную память с
Локальная память
На графических процессорах локальная память отображает в высокоскоростную память с

Константная память
Константная память - это пространство памяти для хранения данных, к
Константная память
Константная память - это пространство памяти для хранения данных, к

Загруженность
Рабочие элементы из рабочей группы запускаются вместе на вычислительном устройстве
Если ресурсов
Загруженность
Рабочие элементы из рабочей группы запускаются вместе на вычислительном устройстве
Если ресурсов

Загруженность: регистры
Регистры являются одним из основных ограничивающих факторов для больших ядер
На
Загруженность: регистры
Регистры являются одним из основных ограничивающих факторов для больших ядер
На

Загруженность: регистры
Рассмотрим другой пример:
Графический процессор имеет 16384 регистра на единицу расчета
Размер
Загруженность: регистры
Рассмотрим другой пример:
Графический процессор имеет 16384 регистра на единицу расчета
Размер

Загруженность: локальная память
Графические процессоры имеют ограниченную локальную память на каждом вычислительном
Загруженность: локальная память
Графические процессоры имеют ограниченную локальную память на каждом вычислительном

Загруженность: Work-items/work-groups
У графических процессоров есть аппаратные ограничения на максимальное количество рабочих
Загруженность: Work-items/work-groups
У графических процессоров есть аппаратные ограничения на максимальное количество рабочих

Загруженность: ограничивающие факторы
Минимальным из этих трех факторов является то, что ограничивает
Загруженность: ограничивающие факторы
Минимальным из этих трех факторов является то, что ограничивает

Сопоставление потоков
Сопоставление потоков определяет, какие потоки будут получать доступ к данным
Правильные
Сопоставление потоков
Сопоставление потоков определяет, какие потоки будут получать доступ к данным
Правильные

Сопоставление потоков
Используя различные сопоставления, один и тот же поток может быть
Сопоставление потоков
Используя различные сопоставления, один и тот же поток может быть

Сопоставление потоков
Рассмотрим последовательный алгоритм умножения матрицы
Этот алгоритм подходит для декомпозиции выходных
Сопоставление потоков
Рассмотрим последовательный алгоритм умножения матрицы
Этот алгоритм подходит для декомпозиции выходных

Сопоставление потоков
Отображение нитей 1: с пространством индексов MxN :
Отображение нитей 2:
Сопоставление потоков
Отображение нитей 1: с пространством индексов MxN :
Отображение нитей 2:
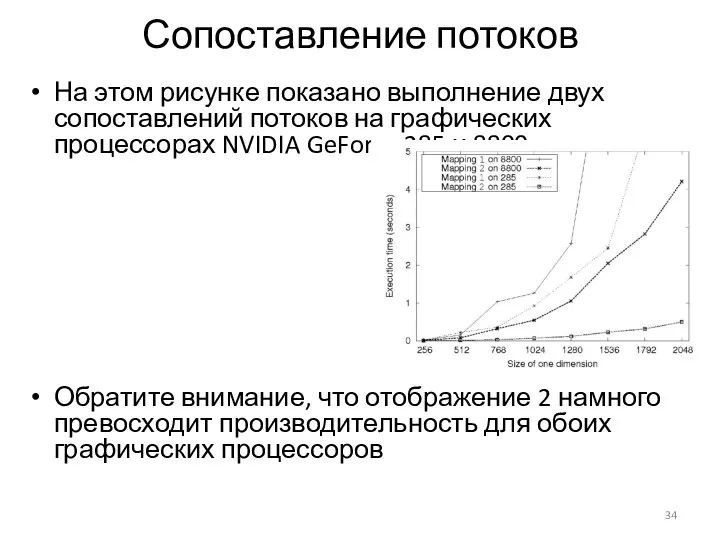
Сопоставление потоков
На этом рисунке показано выполнение двух сопоставлений потоков на графических
Сопоставление потоков
На этом рисунке показано выполнение двух сопоставлений потоков на графических

Сопоставление потоков
Расхождение во времени выполнения между сопоставлениями связано с доступом к
Сопоставление потоков
Расхождение во времени выполнения между сопоставлениями связано с доступом к

Сопоставление потоков
В отображении 1 последовательные потоки (tx) сопоставляются с разными строками
Сопоставление потоков
В отображении 1 последовательные потоки (tx) сопоставляются с разными строками

Сопоставление потоков
В отображении 2 последовательные потоки (tx) отображаются в последовательные элементы
Сопоставление потоков
В отображении 2 последовательные потоки (tx) отображаются в последовательные элементы

Сопоставление потоков
В общем случае потоки могут быть созданы и сопоставлены с
Сопоставление потоков
В общем случае потоки могут быть созданы и сопоставлены с
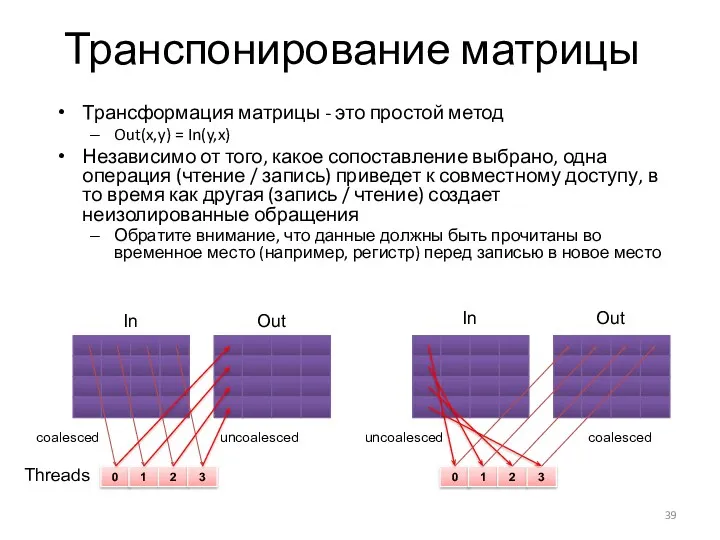
Транспонирование матрицы
Трансформация матрицы - это простой метод
Out(x,y) = In(y,x)
Независимо от того,
Транспонирование матрицы
Трансформация матрицы - это простой метод
Out(x,y) = In(y,x)
Независимо от того,
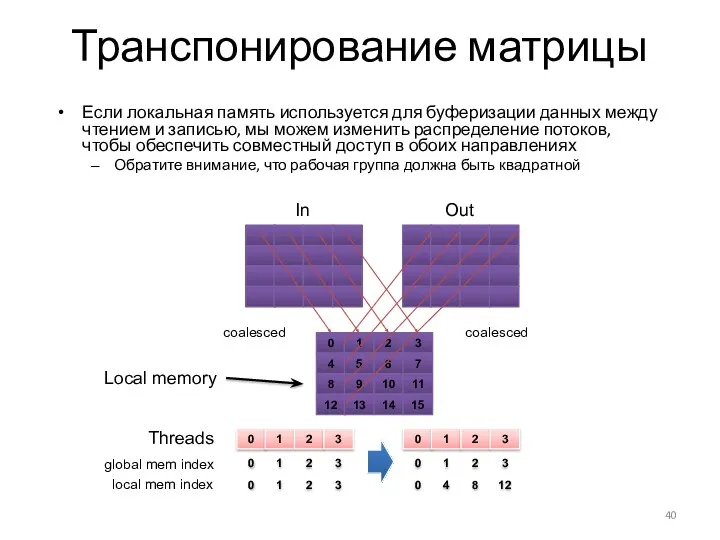
Транспонирование матрицы
Если локальная память используется для буферизации данных между чтением и
Транспонирование матрицы
Если локальная память используется для буферизации данных между чтением и
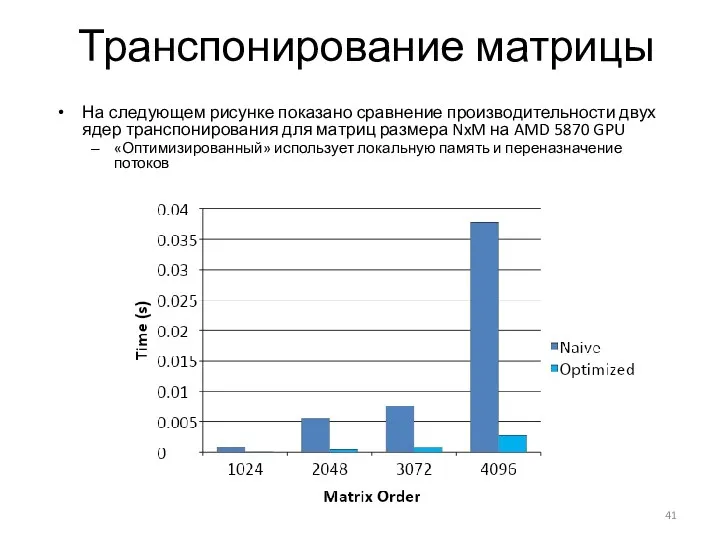
Транспонирование матрицы
На следующем рисунке показано сравнение производительности двух ядер транспонирования для
Транспонирование матрицы
На следующем рисунке показано сравнение производительности двух ядер транспонирования для

Выводы
Хотя писать простую программу OpenCL относительно легко, оптимизация кода может быть
Выводы
Хотя писать простую программу OpenCL относительно легко, оптимизация кода может быть

События, профилирование и отладка
События, профилирование и отладка

События
События используются для синхронизации между отдельными командами
т. е. создать граф зависимостей
События
События используются для синхронизации между отдельными командами
т. е. создать граф зависимостей

События
В дополнение к заданию зависимостей события используются для базового профилирования команд
Профилирование
События
В дополнение к заданию зависимостей события используются для базового профилирования команд
Профилирование

Использование событий
Используя события можем:
Измерить время выполнения вызовов clEnqueue *, таких как
Использование событий
Используя события можем:
Измерить время выполнения вызовов clEnqueue *, таких как

Профилирование с событиями
clGetEventProfilingInfo позволяет нам запрашивать cl_event для получения желаемых значений
Профилирование с событиями
clGetEventProfilingInfo позволяет нам запрашивать cl_event для получения желаемых значений

Профилирование с событиями
В таблице показаны типы событий, описанные с использованием cl_profiling_info
Профилирование с событиями
В таблице показаны типы событий, описанные с использованием cl_profiling_info

Профилирование с событиями
События OpenCL могут быть легко использованы для синхронизации ядер.
Этот
Профилирование с событиями
События OpenCL могут быть легко использованы для синхронизации ядер.
Этот

Профилирование с событиями
Прежде чем получать информацию о времени, мы должны убедиться,
Профилирование с событиями
Прежде чем получать информацию о времени, мы должны убедиться,

Получении информации о событии
clGetEventInfo может использоваться для возврата информации о объекте
Получении информации о событии
clGetEventInfo может использоваться для возврата информации о объекте

Пользовательские события
OpenCL 1.1 и выше определяют объект события пользователя. В отличие
Пользовательские события
OpenCL 1.1 и выше определяют объект события пользователя. В отличие

Пользовательские события
Простой пример пользовательских событий, которые запускаются и используются в командной
Пользовательские события
Простой пример пользовательских событий, которые запускаются и используются в командной

Список ожидания
Список ожидания - это массивы типа cl_event
Все методы clEnqueue *
Список ожидания
Список ожидания - это массивы типа cl_event
Все методы clEnqueue *

Wait Lists
Обеспечивает завершение списка событий до того, как конкретная команда выполнится
Обеспечивает
Wait Lists
Обеспечивает завершение списка событий до того, как конкретная команда выполнится
Обеспечивает

Event Callbacks
OpenCL 1.1 или выше позволяет зарегистрировать сallbacks для определенного статуса
Event Callbacks
OpenCL 1.1 или выше позволяет зарегистрировать сallbacks для определенного статуса

Синхронизация командных очередей
Способы синхронизации очереди команд
Flush:
Отправляет все команды в
Синхронизация командных очередей
Способы синхронизации очереди команд
Flush:
Отправляет все команды в

Отладка с использование printf
Начиная с OpenCL 1.2, OpenCL C поддерживает печать
Отладка с использование printf
Начиная с OpenCL 1.2, OpenCL C поддерживает печать

Отладка с использование printf
В следующем примере выводится информация о потоках, пытающихся
Отладка с использование printf
В следующем примере выводится информация о потоках, пытающихся

CodeXL
Интегрированный профайлер, анализатор ядра и отладчик, разработанные AMD
Режим профилирования
Собирает данные производительности
CodeXL
Интегрированный профайлер, анализатор ядра и отладчик, разработанные AMD
Режим профилирования
Собирает данные производительности
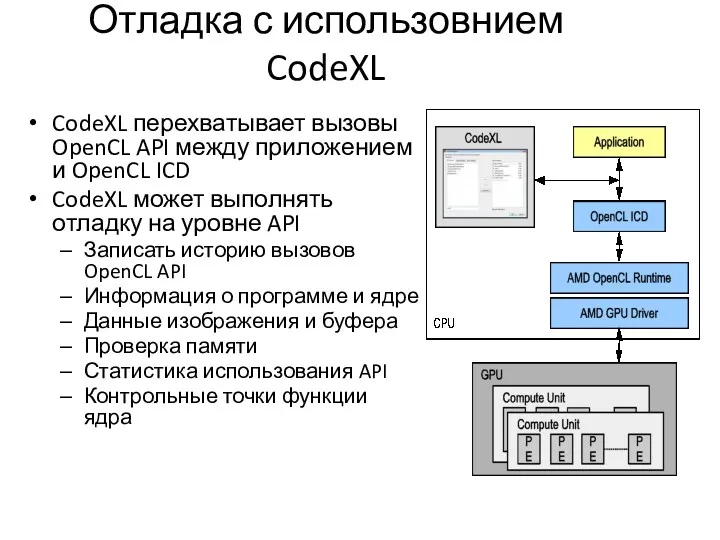
Отладка с использовнием CodeXL
CodeXL перехватывает вызовы OpenCL API между приложением и
Отладка с использовнием CodeXL
CodeXL перехватывает вызовы OpenCL API между приложением и

Профилирование с CodeXL
Режим профилирования
Трассировка временной шкалы приложения графического процессора
Счетчики производительности графического
Профилирование с CodeXL
Режим профилирования
Трассировка временной шкалы приложения графического процессора
Счетчики производительности графического

Просмотр временной шкалы приложения
Обеспечивает визуальное представление выполнения приложения
Просмотр временной шкалы приложения
Обеспечивает визуальное представление выполнения приложения

Просмотр трассировки API-интерфейса хоста
Выводит список всех вызовов OpenCL API, сделанных каждым
Просмотр трассировки API-интерфейса хоста
Выводит список всех вызовов OpenCL API, сделанных каждым

Сбор счетчиков производительности ядра GPU
Счетчики производительности ядра графического процессора можно использовать
Сбор счетчиков производительности ядра GPU
Счетчики производительности ядра графического процессора можно использовать
 Оконная графика позиционных игр. Программа для игры Норткотта
Оконная графика позиционных игр. Программа для игры Норткотта Электронная таблица Excel
Электронная таблица Excel Моделирование и формализация для 5-7 классов
Моделирование и формализация для 5-7 классов IT in The City
IT in The City Turbo Pascal. Операторы
Turbo Pascal. Операторы Текстовый редактор MS Word. Форматирование документа
Текстовый редактор MS Word. Форматирование документа Диаграмма композитной структуры. Диаграмма пакетов. Диаграмма объектов
Диаграмма композитной структуры. Диаграмма пакетов. Диаграмма объектов Разработка мобильного приложения абонента Интернет-провайдера
Разработка мобильного приложения абонента Интернет-провайдера Язык программирования Pascal
Язык программирования Pascal Базы данных. Язык запросов SQL. Введение
Базы данных. Язык запросов SQL. Введение Ақпараттық технологиялардың негізгі түсініктері. Пәнге кіріспе
Ақпараттық технологиялардың негізгі түсініктері. Пәнге кіріспе Авантелеком - Цифровая платформа управления коммуникациями для государственных и муниципальных унитарных предприятий
Авантелеком - Цифровая платформа управления коммуникациями для государственных и муниципальных унитарных предприятий Компоненты компьютера
Компоненты компьютера Методика структурного анализа потоков данных DFD (Data Flow Diagrams)
Методика структурного анализа потоков данных DFD (Data Flow Diagrams) Перевірка кваліфікаційних робіт на академічний плагіат
Перевірка кваліфікаційних робіт на академічний плагіат Поиск информации в интернете
Поиск информации в интернете Простейшие способы шифрования текста. Основы программирования Лабораторная работа №11
Простейшие способы шифрования текста. Основы программирования Лабораторная работа №11 Презентация по информатике на тему _Антивирусные программы_
Презентация по информатике на тему _Антивирусные программы_ Компьютерные сети. Сетевой уровень. (Тема 4)
Компьютерные сети. Сетевой уровень. (Тема 4) Стройэксперт презентация
Стройэксперт презентация HTML работа с текстом текст
HTML работа с текстом текст Steam. About Steam. History. User Interface. Games
Steam. About Steam. History. User Interface. Games Статистичні методи і обробка інформації у суспільній географії. (Лекція 1)
Статистичні методи і обробка інформації у суспільній географії. (Лекція 1) Учет поступивших в библиотеку документов в схемах и таблицах
Учет поступивших в библиотеку документов в схемах и таблицах Lecture02
Lecture02 Построение и исследование информационных моделей
Построение и исследование информационных моделей Диаграмма развертывания языка UML 2 (Лекция 8)
Диаграмма развертывания языка UML 2 (Лекция 8) Информационное обеспечение ИС. Внутримашинное ИО. Информационные хранилища. (Тема 8. Лекция 20)
Информационное обеспечение ИС. Внутримашинное ИО. Информационные хранилища. (Тема 8. Лекция 20)