- Потоки

Содержание
- 2. Потоки, причины использования В традиционных операционных системах у каждого процесса есть адресное пространство и единственный поток
- 3. Аргумент 1 Единое адресное пространство во многих приложениях одновременно происходит несколько действий, часть которых может периодически
- 4. Аргумент 2 Легкость (то есть быстрота) создания и ликвидации потоков по сравнению с более «тяжеловесными» процессами.
- 5. Аргумент 3 Производительность. Когда потоки работают в рамках одного центрального процессора, они не приносят никакого прироста
- 6. Аргумент 4 Потоки весьма полезны для систем, имеющих несколько центральных процессоров, где есть реальная возможность параллельных
- 7. Пример 1 (2 потока) Текстовый процессор как двухпоточная программа. Один из потоков взаимодействует с пользователем, а
- 8. Пример 1 (3 потока) Третий поток может заниматься созданием резервных копий на диске, не мешая первым
- 9. Пример 2. Многопоточный веб-сервер Один из потоков — диспетчер — читает входящие рабочие запросы из сети.
- 10. Пример 2. Многопоточный веб-сервер Рабочий поток проверяет, может ли запрос быть удовлетворен из кэша веб-страниц, к
- 11. Как можно было бы написать код веб-сервера в отсутствие потоков? Можно заставить его работать в виде
- 12. Машина с конечным числом состояний При такой конструкции модель «последовательного процесса», присутствующая в первых двух случаях,
- 13. Итог, потоки дают возможность сохранить идею последовательных процессов, которые осуществляют блокирующие системные вызовы (например, для операций
- 14. Пример 3. Приложения, предназначенные для обработки очень большого объема данных . При обычном подходе блок данных
- 15. Процесс является способом группировки в единое целое взаимосвязанных ресурсов (адресное пространство, содержащее текст программы и данные,
- 16. Поток, у потока есть счетчик команд, отслеживающий, какую очередную инструкцию нужно выполнять. регистры, в которых содержатся
- 17. Использование объектов потоками
- 18. каждый поток имеет собственный стек Стек каждого потока содержит по одному фрейму для каждой уже вызванной,
- 19. Когда используется многопоточность, процесс обычно начинается с использования одного потока. Этот поток может создавать новые потоки,
- 20. Когда поток завершает свою работу, выход из него может быть осуществлен за счет вызова библиотечной процедуры,
- 21. Сложности использования потоков При выполнении системного вызова fork (UNIX) Если у родительского процесса есть несколько потоков,
- 22. Другая проблема: потоки совместно используют многие структуры данных Что происходит в том случае, если один поток
- 24. Скачать презентацию

Потоки, причины использования
В традиционных операционных системах у каждого процесса есть адресное
Потоки, причины использования
В традиционных операционных системах у каждого процесса есть адресное

Аргумент 1
Единое адресное пространство
во многих приложениях одновременно происходит несколько действий, часть
Аргумент 1
Единое адресное пространство
во многих приложениях одновременно происходит несколько действий, часть

Аргумент 2
Легкость (то есть быстрота) создания и ликвидации потоков по сравнению
Аргумент 2
Легкость (то есть быстрота) создания и ликвидации потоков по сравнению

Аргумент 3
Производительность.
Когда потоки работают в рамках одного центрального процессора, они не
Аргумент 3
Производительность.
Когда потоки работают в рамках одного центрального процессора, они не

Аргумент 4
Потоки весьма полезны для систем, имеющих несколько центральных процессоров, где
Аргумент 4
Потоки весьма полезны для систем, имеющих несколько центральных процессоров, где

Пример 1 (2 потока)
Текстовый процессор как двухпоточная программа.
Один из потоков взаимодействует
Пример 1 (2 потока)
Текстовый процессор как двухпоточная программа.
Один из потоков взаимодействует

Пример 1 (3 потока)
Третий поток может заниматься созданием резервных копий на
Пример 1 (3 потока)
Третий поток может заниматься созданием резервных копий на

Пример 2. Многопоточный веб-сервер
Один из потоков — диспетчер — читает входящие
Пример 2. Многопоточный веб-сервер
Один из потоков — диспетчер — читает входящие

Пример 2. Многопоточный веб-сервер
Рабочий поток проверяет, может ли запрос быть удовлетворен
Пример 2. Многопоточный веб-сервер
Рабочий поток проверяет, может ли запрос быть удовлетворен

Как можно было бы написать код веб-сервера в отсутствие потоков?
Можно заставить
Как можно было бы написать код веб-сервера в отсутствие потоков?
Можно заставить

Машина с конечным числом состояний
При такой конструкции модель «последовательного процесса», присутствующая
Машина с конечным числом состояний
При такой конструкции модель «последовательного процесса», присутствующая

Итог, потоки
дают возможность сохранить идею последовательных процессов, которые осуществляют блокирующие системные
Итог, потоки
дают возможность сохранить идею последовательных процессов, которые осуществляют блокирующие системные

Пример 3. Приложения, предназначенные для обработки очень большого объема данных
. При
Пример 3. Приложения, предназначенные для обработки очень большого объема данных
. При

Процесс
является способом группировки в единое целое взаимосвязанных ресурсов (адресное пространство, содержащее
Процесс
является способом группировки в единое целое взаимосвязанных ресурсов (адресное пространство, содержащее

Поток, у потока есть
счетчик команд, отслеживающий, какую очередную инструкцию нужно
Поток, у потока есть
счетчик команд, отслеживающий, какую очередную инструкцию нужно

Использование объектов потоками
Использование объектов потоками

каждый поток имеет собственный стек
Стек каждого потока содержит по одному фрейму
каждый поток имеет собственный стек
Стек каждого потока содержит по одному фрейму

Когда используется многопоточность,
процесс обычно начинается с использования одного потока.
Этот
Когда используется многопоточность,
процесс обычно начинается с использования одного потока.
Этот

Когда поток завершает свою работу,
выход из него может быть осуществлен
Когда поток завершает свою работу,
выход из него может быть осуществлен

Сложности использования потоков
При выполнении системного вызова fork (UNIX)
Если у родительского процесса
Сложности использования потоков
При выполнении системного вызова fork (UNIX)
Если у родительского процесса

Другая проблема: потоки совместно используют многие структуры данных
Что происходит в том
Другая проблема: потоки совместно используют многие структуры данных
Что происходит в том
 Виды баз данных
Виды баз данных Искусственный интеллект и интеллектуальные информационные системы. Лекция 6
Искусственный интеллект и интеллектуальные информационные системы. Лекция 6 Интегрированный урок - исследование Моделирование биоритмов человека
Интегрированный урок - исследование Моделирование биоритмов человека Особенности подготовки школьников к ЕГЭ по информатике
Особенности подготовки школьников к ЕГЭ по информатике Функції. Масиви
Функції. Масиви Решение ЕГЭ В12 задания
Решение ЕГЭ В12 задания This is your presentation title
This is your presentation title Инструкция по работе студента в системе дистанционного обучения
Инструкция по работе студента в системе дистанционного обучения Презентация к уроку История систем счисления
Презентация к уроку История систем счисления Информация измерение
Информация измерение Види заходів протидії загрозам безпеки. Правові основи забезпечення безпеки інформаційних технологій. Інформатика. 10 (11) клас
Види заходів протидії загрозам безпеки. Правові основи забезпечення безпеки інформаційних технологій. Інформатика. 10 (11) клас Введение. ENIAC (Electronic Numerical Integrator and Computer)
Введение. ENIAC (Electronic Numerical Integrator and Computer) Безопасность во всемирной паутине
Безопасность во всемирной паутине 20231101_sdo
20231101_sdo Справочно-библиографический аппарат научной работы
Справочно-библиографический аппарат научной работы Роль журналиста в обществе
Роль журналиста в обществе Теория. HTML 5
Теория. HTML 5 Модерация. Вводная инструкция
Модерация. Вводная инструкция Добавление рисунков, объектов, эффектов. Open Office.org 2.3 Impress
Добавление рисунков, объектов, эффектов. Open Office.org 2.3 Impress Программирование на алгоритмическом языке (§ 62 - § 68)
Программирование на алгоритмическом языке (§ 62 - § 68) ВИКТОРИНА ПО ИНФОРМАТИКЕ: Занимательная информатика
ВИКТОРИНА ПО ИНФОРМАТИКЕ: Занимательная информатика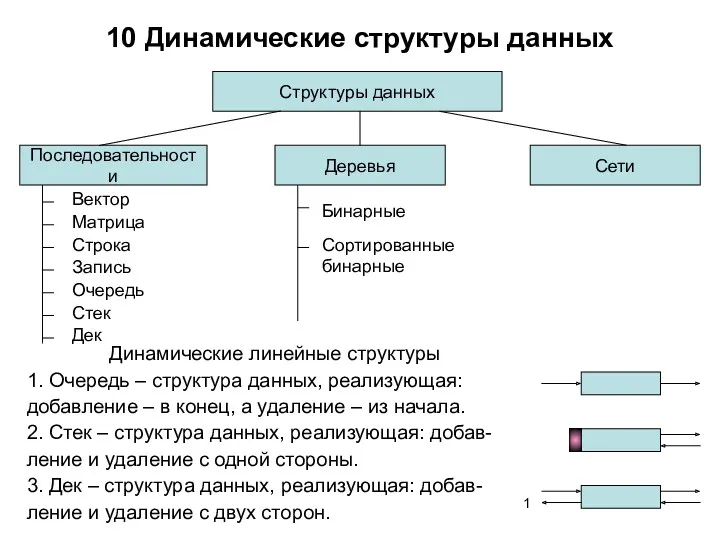 Динамические структуры данных
Динамические структуры данных Технологии проектирования компьютерных систем. Представление системы в VHDL. (Лекция 7)
Технологии проектирования компьютерных систем. Представление системы в VHDL. (Лекция 7) Одновимірні масиви. Поняття масиву даних. Види масивів. (Лекція 5)
Одновимірні масиви. Поняття масиву даних. Види масивів. (Лекція 5) Techsys Website Mockup
Techsys Website Mockup Мобильное приложение. Для страховой компании Белнефтестрах ООО ВЭБ Технологии, 2023
Мобильное приложение. Для страховой компании Белнефтестрах ООО ВЭБ Технологии, 2023 презентация к уроку информатика 6 класс Как образуются понятия
презентация к уроку информатика 6 класс Как образуются понятия Macroscop. Технический минимум
Macroscop. Технический минимум