- Презентация к уроку в 9 классе Системы оптического распознавания документов

Содержание
- 2. Системы оптического распознавания символов При coздании электронных библиотек и архивов путем перевода книг и документов в
- 3. Оптическое распознавание символов Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод
- 4. Однако для получения документа в формате текстового файла необходимо провести распознавание текста, т. е. преобразовать элементы
- 5. Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т. д. Далее
- 6. Хорошее качество текста Растровый метод распознавания текста Если исходный документ имеет типографское качество (достаточно крупный шрифт,
- 7. Хорошее качество текста Растровый метод распознавания текста Сначала растровое изображение страницы разделяется на изображения отдельных символов.
- 8. Хорошее качество текста Растровый метод распознавания текста Растровое изображение каждого символа последовательно накладывается на растровые шаблоны
- 9. Плохое качество текста Структурный метод распознавания При распознавании документов с низким качеством печати (машинописный текст, факс
- 10. Плохое качество текста Структурный метод распознавания При pacпознавании структурным методом в искаженном символьном изображении выделяются характерные
- 11. Системы оптического распознавания форм При проведении Единого государственного экзамена, при заполнении налоговых деклараций и т. д.
- 12. Бланком называется стандартный лист бумаги, на котором размещается постоянная информация и отведено место для переменной. Сложность
- 13. Для обработки бланков предназначено специальное приложение FineReader Forms. Для распознавания содержимого бланка необходимо предварительно создать шаблон
- 14. Системы распознавания рукописного текста С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали
- 15. Системы распознавания рукописного текста
- 16. Программы оптического распознавания текста
- 17. Программы оптического распознавания документов Для ввода текстов в память компьютера с бумажных носителей используют сканеры и
- 18. Принцип работы сканера состоит в следующем: в результате преобразования света получается электрический сигнал, содержащий информацию об
- 20. Программы распознавания текста Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition
- 21. OCR CUNEIFORM Это бесплатная программа сканирования и распознавания текста российского разработчика Cognitive Technologies. OCR CuneiForm обеспечивает
- 22. ABBYY FineReader Популярная проприетарная программа распознавания текста компании ABBYY Программа производит распознавание текста с более 180
- 23. Окно программы FineReader
- 24. Процесс обработки FineReader Сканирование (сканер, цифровой фотоаппарат, цифровая видеокамера). Сегментация - выделение блоков на изображении. Распознавание
- 25. OmniPage Популярная программа распознавания текста российской компании ABBYY Программа отличается высокой скоростью и точностью распознавания. Распознаются
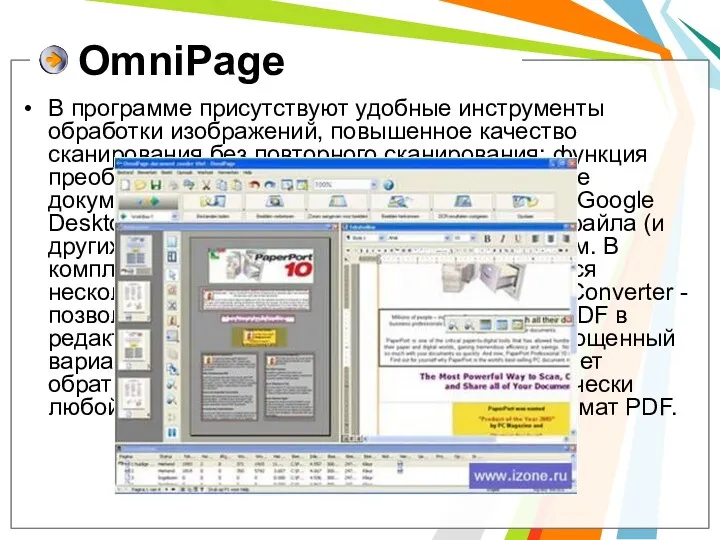
- 26. OmniPage В программе присутствуют удобные инструменты обработки изображений, повышенное качество сканирования без повторного сканирования; функция преобразования
- 27. Readiris Программа сканирования и распознавания текста компании I.R.I.S. Поддерживается распознавание текста с более 120 языков распознавания,
- 28. Readiris Содержит региональные пакеты для распознавания азиатских языков и языков среднего востока.
- 29. Kirtas Technologies Arabic OCR Может распознавать арабские и английские символы на одной странице.
- 30. Zonal OCR Помогает автоматизировать извлечение данных из компьютерных изображений.
- 31. Brainware Извлечение данных из документов и их обработка — например, счета, извещения, накладные и платёжки
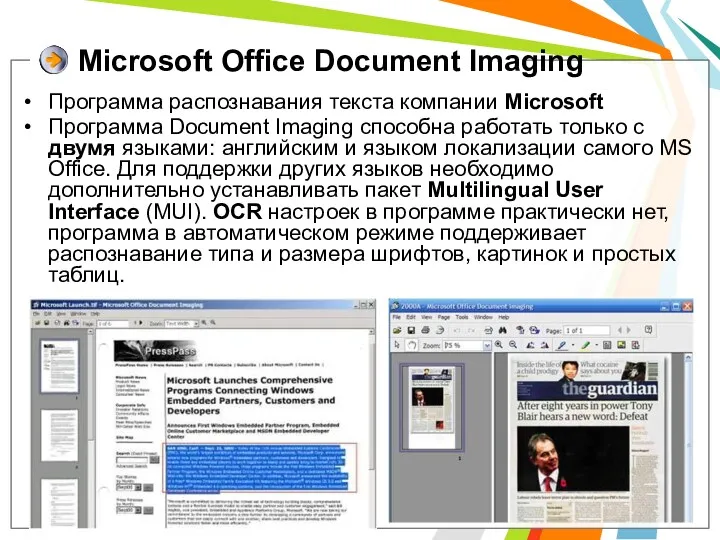
- 32. Microsoft Office Document Imaging Программа распознавания текста компании Microsoft Программа Document Imaging способна работать только с
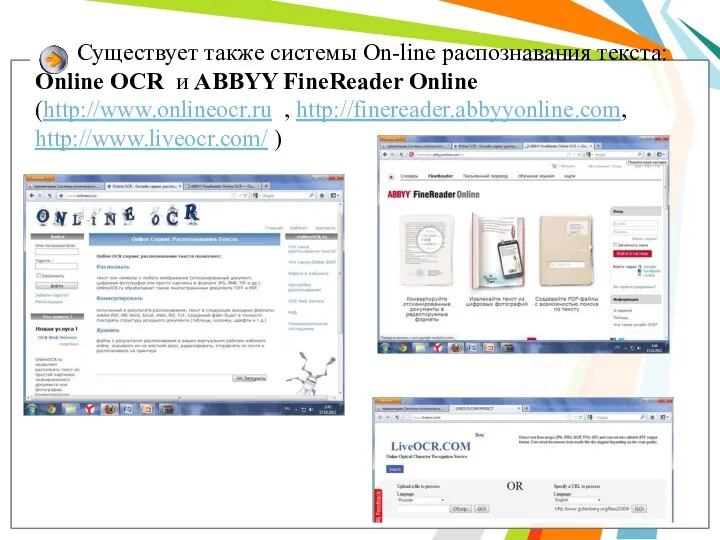
- 33. Существует также системы On-line распознавания текста: Online OCR и ABBYY FineReader Online (http://www.onlineocr.ru , http://finereader.abbyyonline.com, http://www.liveocr.com/
- 34. Подведение итогов урока В чем состоят различия в технологии распознавания текста при использовании растрового и векторного
- 36. Скачать презентацию

Системы оптического распознавания символов
При coздании электронных библиотек и архивов путем перевода
Системы оптического распознавания символов
При coздании электронных библиотек и архивов путем перевода

Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический
Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический

Однако для получения документа в формате текстового файла необходимо провести распознавание
Однако для получения документа в формате текстового файла необходимо провести распознавание

Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы,
Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы,
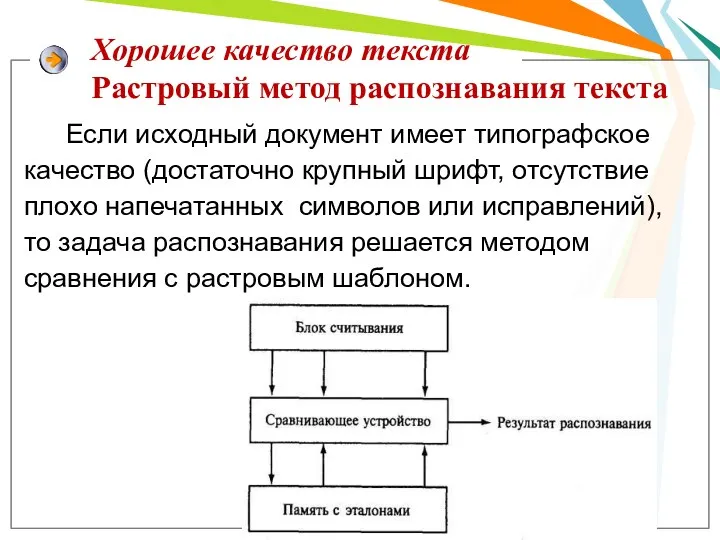
Хорошее качество текста
Растровый метод распознавания текста
Если исходный документ имеет типографское качество
Хорошее качество текста
Растровый метод распознавания текста
Если исходный документ имеет типографское качество

Хорошее качество текста
Растровый метод распознавания текста
Сначала растровое изображение страницы разделяется на
Хорошее качество текста
Растровый метод распознавания текста
Сначала растровое изображение страницы разделяется на

Хорошее качество текста
Растровый метод распознавания текста
Растровое изображение каждого символа последовательно накладывается
Хорошее качество текста
Растровый метод распознавания текста
Растровое изображение каждого символа последовательно накладывается

Плохое качество текста
Структурный метод распознавания
При распознавании документов с низким качеством печати
Плохое качество текста
Структурный метод распознавания
При распознавании документов с низким качеством печати

Плохое качество текста
Структурный метод распознавания
При pacпознавании структурным методом в искаженном символьном
Плохое качество текста
Структурный метод распознавания
При pacпознавании структурным методом в искаженном символьном

Системы оптического распознавания форм
При проведении Единого государственного экзамена, при заполнении
Системы оптического распознавания форм
При проведении Единого государственного экзамена, при заполнении

Бланком называется стандартный лист бумаги, на котором размещается постоянная информация и
Бланком называется стандартный лист бумаги, на котором размещается постоянная информация и

Для обработки бланков предназначено специальное приложение FineReader Forms.
Для распознавания содержимого бланка
Для обработки бланков предназначено специальное приложение FineReader Forms.
Для распознавания содержимого бланка

Системы распознавания рукописного текста
С появлением первого карманного компьютера Newton фирмы
Системы распознавания рукописного текста
С появлением первого карманного компьютера Newton фирмы
Системы распознавания рукописного текста
Системы распознавания рукописного текста

Программы оптического распознавания текста
Программы оптического распознавания текста
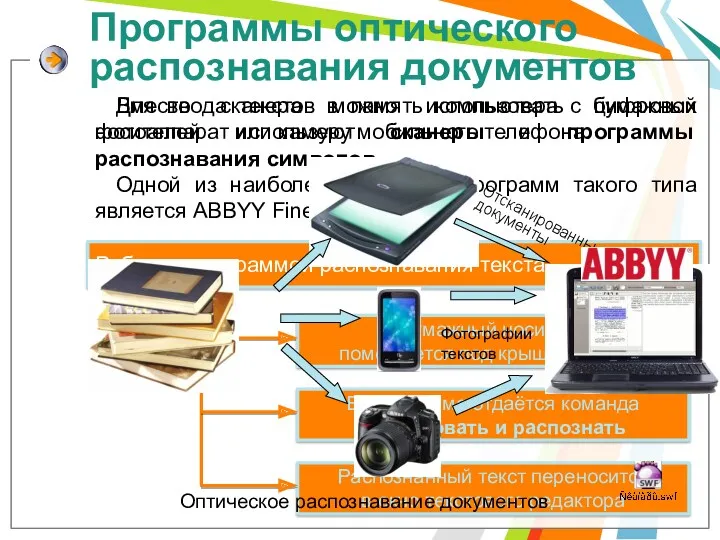
Программы оптического распознавания документов
Для ввода текстов в память компьютера с бумажных
Программы оптического распознавания документов
Для ввода текстов в память компьютера с бумажных

Принцип работы сканера состоит в следующем: в результате преобразования света
Принцип работы сканера состоит в следующем: в результате преобразования света


Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания
Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания

OCR CUNEIFORM
Это бесплатная программа сканирования и распознавания текста российского разработчика
OCR CUNEIFORM
Это бесплатная программа сканирования и распознавания текста российского разработчика

ABBYY FineReader
Популярная проприетарная программа распознавания текста компании ABBYY
Программа производит распознавание текста
ABBYY FineReader
Популярная проприетарная программа распознавания текста компании ABBYY
Программа производит распознавание текста
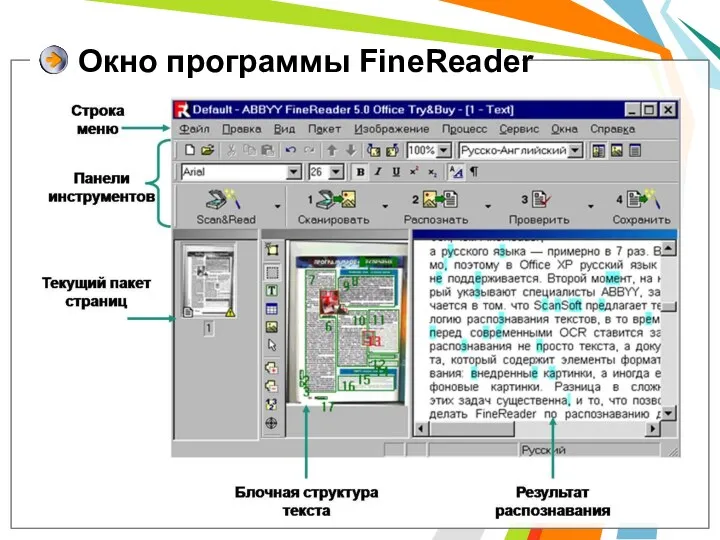
Окно программы FineReader
Окно программы FineReader

Процесс обработки FineReader
Сканирование (сканер, цифровой фотоаппарат, цифровая видеокамера).
Сегментация - выделение блоков
Процесс обработки FineReader
Сканирование (сканер, цифровой фотоаппарат, цифровая видеокамера).
Сегментация - выделение блоков

OmniPage
Популярная программа распознавания текста российской компании ABBYY
Программа отличается высокой скоростью и
OmniPage
Популярная программа распознавания текста российской компании ABBYY
Программа отличается высокой скоростью и
OmniPage
В программе присутствуют удобные инструменты обработки изображений, повышенное качество сканирования без
OmniPage
В программе присутствуют удобные инструменты обработки изображений, повышенное качество сканирования без

Readiris
Программа сканирования и распознавания текста компании I.R.I.S.
Поддерживается распознавание текста с
Readiris
Программа сканирования и распознавания текста компании I.R.I.S.
Поддерживается распознавание текста с

Readiris
Содержит региональные пакеты для распознавания азиатских языков и языков среднего
Readiris
Содержит региональные пакеты для распознавания азиатских языков и языков среднего

Kirtas Technologies Arabic OCR
Может распознавать арабские и английские символы на
Kirtas Technologies Arabic OCR
Может распознавать арабские и английские символы на

Zonal OCR
Помогает автоматизировать извлечение данных из компьютерных изображений.
Zonal OCR
Помогает автоматизировать извлечение данных из компьютерных изображений.

Brainware
Извлечение данных из документов и их обработка — например, счета,
Brainware
Извлечение данных из документов и их обработка — например, счета,
Microsoft Office Document Imaging
Программа распознавания текста компании Microsoft
Программа Document Imaging способна
Microsoft Office Document Imaging
Программа распознавания текста компании Microsoft
Программа Document Imaging способна
Существует также системы On-line распознавания текста: Online OCR и ABBYY FineReader
Существует также системы On-line распознавания текста: Online OCR и ABBYY FineReader

Подведение итогов урока
В чем состоят различия в технологии распознавания текста при
Подведение итогов урока
В чем состоят различия в технологии распознавания текста при
 Why do we use computers for comunication
Why do we use computers for comunication Dos-атаки
Dos-атаки Команди і виконавці команд. Урок 23. Я досліджую світ
Команди і виконавці команд. Урок 23. Я досліджую світ Архитектура компьютера
Архитектура компьютера Алгоритмизация и программирование на языке Pascal
Алгоритмизация и программирование на языке Pascal Стример. Профессия или хобби
Стример. Профессия или хобби Топология и архитектура сети
Топология и архитектура сети Представление аналогового сигнала в цифровом виде (лекция 20)
Представление аналогового сигнала в цифровом виде (лекция 20) Криптография. Симметричные алгоритмы шифрования
Криптография. Симметричные алгоритмы шифрования Food helper. Контроль над їжею
Food helper. Контроль над їжею Изучение методов создания прототипа модели с использованием установок аддитивного производства
Изучение методов создания прототипа модели с использованием установок аддитивного производства Игра Самый умный по информатике
Игра Самый умный по информатике Жанр компьютерных игр - Шутер
Жанр компьютерных игр - Шутер Общие сведения об операционных системах и программном обеспечении
Общие сведения об операционных системах и программном обеспечении Типы алгоритмов
Типы алгоритмов Архитектура, особенности, недостатки .NET. Типы данных, ключевые слова. Определение класса, метода
Архитектура, особенности, недостатки .NET. Типы данных, ключевые слова. Определение класса, метода САПР Autocad 2015. Команды редактирования
САПР Autocad 2015. Команды редактирования Разработка интеллектуальной системы для распознавания языка жестов
Разработка интеллектуальной системы для распознавания языка жестов Циклы с постусловием
Циклы с постусловием Социальная сеть Instagram
Социальная сеть Instagram Информация, ее виды и свойства
Информация, ее виды и свойства Урок Двоичная система счисления
Урок Двоичная система счисления История развития вычислительной техники
История развития вычислительной техники Часть 2. Информационные технологии проектирования электронных устройств. Лекция 6. Технологии искусственного интеллекта
Часть 2. Информационные технологии проектирования электронных устройств. Лекция 6. Технологии искусственного интеллекта Правовые нормы, относящиеся к информации
Правовые нормы, относящиеся к информации Внутреннее устройство компьютера
Внутреннее устройство компьютера Рекомендации психолога
Рекомендации психолога Классы как воплощение принципов ООП
Классы как воплощение принципов ООП