- Примеры задач анализа данных. Методы подготовки данных к анализу

Содержание
- 2. Статистический пакет - программный продукт, предназначенный для статистической обработки данных. Существуют специализированные статистические пакеты и другие
- 3. Примеры анализа данных Ошибка выборки - расхождение между характеристиками выборочной и генеральной совокупностей.
- 4. Доверительный коэффициент t находится из таблицы квантилей нормального распределения при заданной надежности γ. При стандартных значениях
- 5. Исходные данные При изучении средней длительности пребывания больных в стационаре получены следующие данные: М = 20
- 6. Задача 2 Интервальные оценки математического ожидания нормального распределения при известном σ
- 7. Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными дисперсиями.
- 8. Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными дисперсиями.
- 9. Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными дисперсиями.
- 10. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ =СРЗНАЧ(А1:А25)-ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25) =СРЗНАЧ(А1:А25)+ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)
- 11. Задача 3 Интервальные оценки математического ожидания нормального распределения при неизвестном σ Пример . По выборке объема
- 12. Задача 3 Интервальные оценки математического ожидания нормального распределения при неизвестном σ
- 13. Значение выборочного коэффициента корреляции является оценкой «истинного» теоретического значения rxy и отличается от него в силу
- 14. Задача 4 Проверка независимости признаков. Пример . Получена корреляционная таблица, составленная по выборке студентов возраста 20
- 15. Квадрат коэффициента корреляции зависимой и независимой переменных представляет долю дисперсии зависимой переменной, обусловленной влиянием независимой переменной,
- 16. Нужно упорядочить данные по возрастанию и заменить реальные значения их рангами. Рангом значения называется его номер
- 17. КОЭФФИЦИЕНТ СПИРМЕНА
- 18. КОЭФФИЦИЕНТ КОНКОРДАЦИИ
- 19. Степень согласованности мнений экспертов при получении итогового ранжирования определяется через расчет коэффициента конкордации: КОЭФФИЦИЕНТ КОНКОРДАЦИИ
- 20. КОЭФФИЦИЕНТ КОНКОРДАЦИИ В случае, когда ранжирование нестрогое (то есть допускается наличие равноценных объектов), коэффициент конкордации вычисляется
- 21. Непараметрические статистические гипотезы При обработке статистических данных большого объема часто возникает ситуация, когда закон распределения генеральной
- 22. Нормальное (гауссово, симметричное, колоколообразное) распределение (normal, Gaussian distribution)– описывает совместное воздействие на изучаемое явление небольшого числа
- 23. Биномиальное распределение (распределение Бернулли) (binomial distribution, Bernoulli distribution) – описывает распределение частоты события, обладающего постоянной вероятностью
- 24. Распределения Распределение Пуассона – описывает события, при которых с возрастанием значения случайной величины, вероятность появления ее
- 25. Критерий Пирсона
- 26. Статистические гипотезы
- 27. Критерий t Стьюдента направлен на оценку различий величин средних двух выборок X и Y, которые распределены
- 28. Задача 4 Использование t-критерия Поскольку р-значение равно 0,01 и меньше α
- 29. По двум независимым выборкам, объемы которых соответственно n=60 и m=50, извлеченным из нормальных генеральных совокупностей, найдены
- 30. Задача 6 Сравнение 2-х дисперсий нормальных генеральных совокупностей (F-критерий).
- 31. МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ Реальные данные для анализа редко бывают хорошего качества С целью повышения
- 32. МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ Очистка от шумов и сглаживание рядов данных Редактирование аномальных значений Восстановление
- 33. искусственные — связаны с ошибками ввода данных, некорректной работой программ или технических систем регистрации и ввода
- 34. ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ Атрибут Возраст представлен следующими двадцатью значениями: {3, 56,23, 39, 156, 52, 41, 22,
- 35. В основе метода лежит оценка мер расстояния между всеми наблюдениями в n-мерном пространстве данных Значение Si
- 36. S3 и S5 - кандидаты в аномальные, для них значение p = 5 превышает заданный порог
- 37. МЕТОДЫ КОРРЕКТИРОВКИ АНОМАЛЬНЫХ ЗНАЧЕНИЙ Удаление записи с аномальным значением Ручная замена аномальных значений Сглаживание и фильтрация
- 38. ПРОИСХОЖДЕНИЕ ПРОПУСКОВ В ДАННЫХ В процессе ввода данных, ошибки. При сбое в работе автоматических систем регистрации.
- 39. МЕТОДЫ ВОССТАНОВЛЕНИЯ ПРОПУЩЕННЫХ ЗНАЧЕНИЙ Ручная обработка пропусков (применим только для небольших выборок данных ) Подстановка констант
- 40. Классификация Регрессия Кластеризация Ассоциация Последовательность DATA MINING – КЛАССЫ РЕШАЕМЫХ ЗАДАЧ
- 41. Нахождение функциональной зависимости между входными атрибутами и дискретным выходным атрибутом. Классификация позволяет отнести объект к одному
- 42. Регрессией называется зависимость среднего значения одной случайной величины от некоторой другой (или от нескольких случайных величин).
- 43. РЕГРЕССИОННЫЙ АНАЛИЗ
- 44. РЕГРЕССИОННЫЙ АНАЛИЗ
- 45. РЕГРЕССИОННЫЙ АНАЛИЗ Пересечение с осью ОУ Наклон
- 46. Построение диаграммы Ось Х ввести текст «Толщина рубца, мм»; Ось Y – «Время криодеструкции, мин».
- 47. Регрессионный анализ данных
- 48. РЕГРЕССИОННЫЙ АНАЛИЗ
- 49. РЕГРЕССИОННЫЙ АНАЛИЗ
- 50. После проведения эксперимента необходимо убедиться в существовании линейной зависимости, адекватности линейной модели в пределах выбранного диапазона
- 51. Разбиение объектов на кластеры, т.е. группы схожих элементов: Кластеризация пациентов со схожей историей болезни, особенностями восстановления
- 52. Анализ транзакций, т.е. событий, происходящих вместе. Обнаружение зависимости вида «Из события А c определенной вероятностью следует
- 53. Анализ событий, связанных между собой по времени. «После события А спустя определенное время произойдет событие B»:
- 55. Скачать презентацию

Статистический пакет - программный продукт, предназначенный для статистической обработки данных. Существуют
Статистический пакет - программный продукт, предназначенный для статистической обработки данных. Существуют

Примеры анализа данных
Ошибка выборки - расхождение между характеристиками выборочной и генеральной
Примеры анализа данных
Ошибка выборки - расхождение между характеристиками выборочной и генеральной

Доверительный коэффициент t находится из таблицы квантилей нормального распределения при заданной
Доверительный коэффициент t находится из таблицы квантилей нормального распределения при заданной

Исходные данные
При изучении средней длительности пребывания больных в стационаре получены следующие
Исходные данные
При изучении средней длительности пребывания больных в стационаре получены следующие

Задача 2
Интервальные оценки математического ожидания нормального распределения при известном σ
Задача 2
Интервальные оценки математического ожидания нормального распределения при известном σ
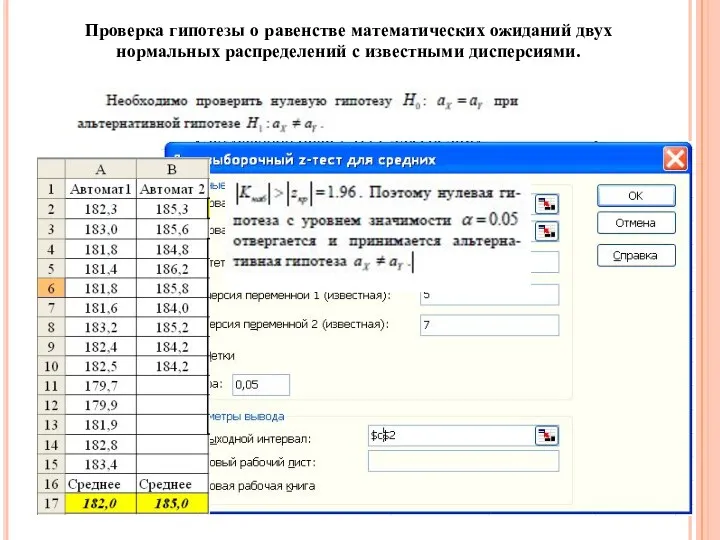
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными
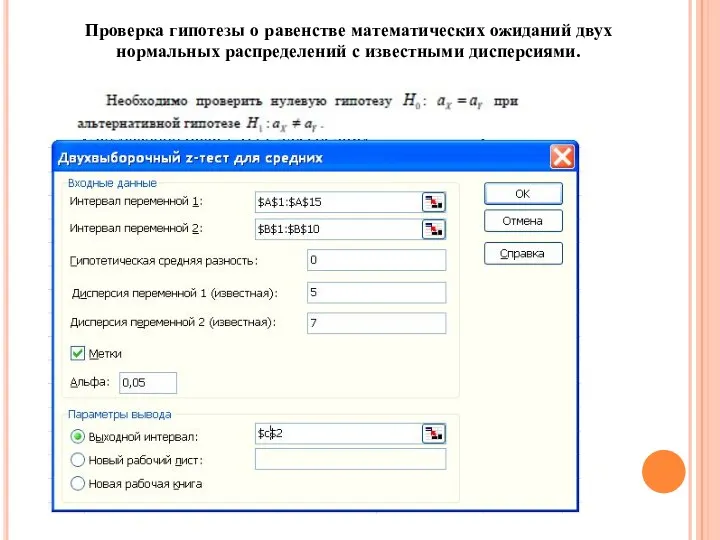
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными
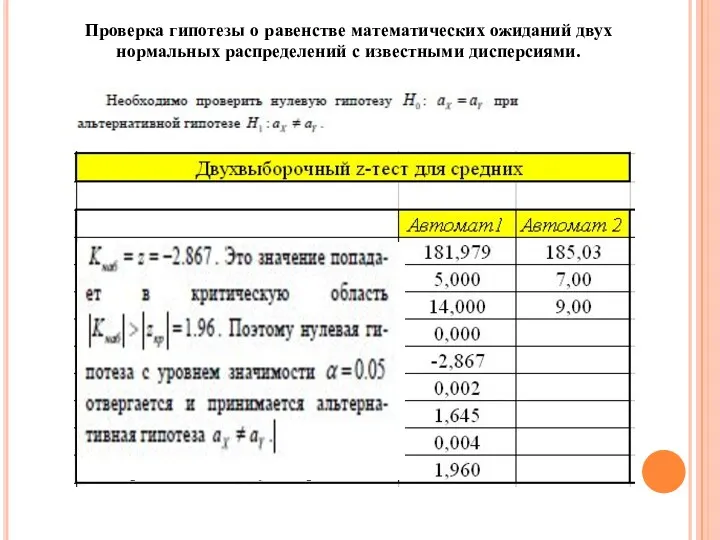
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными
Проверка гипотезы о равенстве математических ожиданий двух нормальных распределений с известными

ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
=СРЗНАЧ(А1:А25)-ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)
=СРЗНАЧ(А1:А25)+ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)
ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
=СРЗНАЧ(А1:А25)-ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)
=СРЗНАЧ(А1:А25)+ДОВЕРИТ(I1;СТАНДОТКЛОН(А1:А25);25)

Задача 3
Интервальные оценки математического ожидания нормального распределения при неизвестном σ
Пример .
Задача 3
Интервальные оценки математического ожидания нормального распределения при неизвестном σ
Пример .

Задача 3
Интервальные оценки математического ожидания нормального распределения при неизвестном σ
Задача 3
Интервальные оценки математического ожидания нормального распределения при неизвестном σ

Значение выборочного коэффициента корреляции является оценкой «истинного» теоретического значения rxy и
Значение выборочного коэффициента корреляции является оценкой «истинного» теоретического значения rxy и

Задача 4
Проверка независимости признаков.
Пример . Получена корреляционная таблица, составленная по выборке
Задача 4
Проверка независимости признаков.
Пример . Получена корреляционная таблица, составленная по выборке

Квадрат коэффициента корреляции зависимой и независимой переменных представляет долю дисперсии зависимой

Нужно упорядочить данные по возрастанию и заменить реальные значения их рангами.
Нужно упорядочить данные по возрастанию и заменить реальные значения их рангами.

КОЭФФИЦИЕНТ СПИРМЕНА
КОЭФФИЦИЕНТ СПИРМЕНА
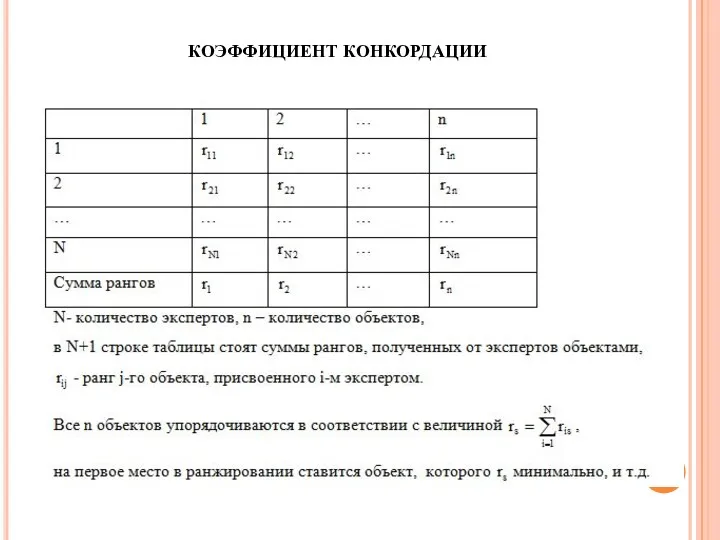
КОЭФФИЦИЕНТ КОНКОРДАЦИИ
КОЭФФИЦИЕНТ КОНКОРДАЦИИ

Степень согласованности мнений экспертов при получении итогового ранжирования определяется через расчет
Степень согласованности мнений экспертов при получении итогового ранжирования определяется через расчет

КОЭФФИЦИЕНТ КОНКОРДАЦИИ
В случае, когда ранжирование нестрогое (то есть допускается наличие равноценных
КОЭФФИЦИЕНТ КОНКОРДАЦИИ
В случае, когда ранжирование нестрогое (то есть допускается наличие равноценных

Непараметрические статистические гипотезы
При обработке статистических данных большого объема часто возникает ситуация,
Непараметрические статистические гипотезы
При обработке статистических данных большого объема часто возникает ситуация,

Нормальное (гауссово, симметричное, колоколообразное) распределение (normal, Gaussian distribution)– описывает совместное воздействие
Нормальное (гауссово, симметричное, колоколообразное) распределение (normal, Gaussian distribution)– описывает совместное воздействие

Биномиальное распределение (распределение Бернулли) (binomial distribution, Bernoulli distribution) – описывает распределение
Биномиальное распределение (распределение Бернулли) (binomial distribution, Bernoulli distribution) – описывает распределение

Распределения
Распределение Пуассона – описывает события, при которых с возрастанием значения случайной
Распределения
Распределение Пуассона – описывает события, при которых с возрастанием значения случайной

Критерий Пирсона
Критерий Пирсона

Статистические гипотезы
Статистические гипотезы

Критерий t Стьюдента направлен на оценку различий величин средних двух выборок
Критерий t Стьюдента направлен на оценку различий величин средних двух выборок
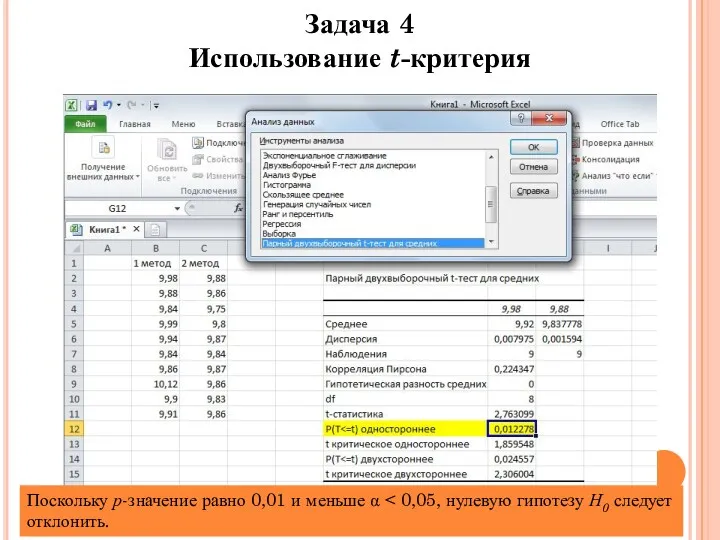
Задача 4
Использование t-критерия
Поскольку р-значение равно 0,01 и меньше α <
Задача 4
Использование t-критерия
Поскольку р-значение равно 0,01 и меньше α <

По двум независимым выборкам, объемы которых соответственно n=60 и m=50, извлеченным
По двум независимым выборкам, объемы которых соответственно n=60 и m=50, извлеченным

Задача 6
Сравнение 2-х дисперсий нормальных генеральных совокупностей (F-критерий).
Задача 6
Сравнение 2-х дисперсий нормальных генеральных совокупностей (F-критерий).

МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ
Реальные данные для анализа редко бывают хорошего
МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ
Реальные данные для анализа редко бывают хорошего
МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ
Очистка от шумов и сглаживание рядов данных
Редактирование
МЕТОДЫ ПОДГОТОВКИ ДАННЫХ К АНАЛИЗУ
Очистка от шумов и сглаживание рядов данных
Редактирование

искусственные — связаны с ошибками ввода данных, некорректной работой программ или
искусственные — связаны с ошибками ввода данных, некорректной работой программ или

ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Атрибут Возраст представлен следующими двадцатью значениями:
{3, 56,23,
ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Атрибут Возраст представлен следующими двадцатью значениями:
{3, 56,23,

В основе метода лежит оценка мер расстояния между всеми наблюдениями в
В основе метода лежит оценка мер расстояния между всеми наблюдениями в

S3 и S5 - кандидаты в аномальные, для них значение p
S3 и S5 - кандидаты в аномальные, для них значение p

МЕТОДЫ КОРРЕКТИРОВКИ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Удаление записи с аномальным значением
Ручная замена аномальных значений
Сглаживание
МЕТОДЫ КОРРЕКТИРОВКИ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Удаление записи с аномальным значением
Ручная замена аномальных значений
Сглаживание

ПРОИСХОЖДЕНИЕ ПРОПУСКОВ В ДАННЫХ
В процессе ввода данных, ошибки.
При сбое в работе
ПРОИСХОЖДЕНИЕ ПРОПУСКОВ В ДАННЫХ
В процессе ввода данных, ошибки.
При сбое в работе

МЕТОДЫ ВОССТАНОВЛЕНИЯ ПРОПУЩЕННЫХ ЗНАЧЕНИЙ
Ручная обработка пропусков (применим только для небольших
МЕТОДЫ ВОССТАНОВЛЕНИЯ ПРОПУЩЕННЫХ ЗНАЧЕНИЙ
Ручная обработка пропусков (применим только для небольших

Классификация
Регрессия
Кластеризация
Ассоциация
Последовательность
DATA MINING – КЛАССЫ РЕШАЕМЫХ ЗАДАЧ
Классификация
Регрессия
Кластеризация
Ассоциация
Последовательность
DATA MINING – КЛАССЫ РЕШАЕМЫХ ЗАДАЧ

Нахождение функциональной зависимости между входными атрибутами и дискретным выходным атрибутом.
Классификация
Нахождение функциональной зависимости между входными атрибутами и дискретным выходным атрибутом.
Классификация

Регрессией называется зависимость среднего значения одной случайной величины от некоторой другой
Регрессией называется зависимость среднего значения одной случайной величины от некоторой другой
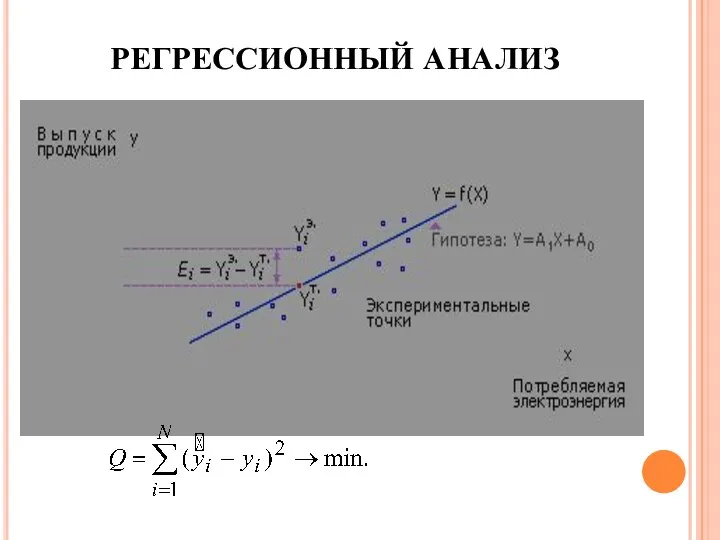
РЕГРЕССИОННЫЙ АНАЛИЗ
РЕГРЕССИОННЫЙ АНАЛИЗ

РЕГРЕССИОННЫЙ АНАЛИЗ
РЕГРЕССИОННЫЙ АНАЛИЗ
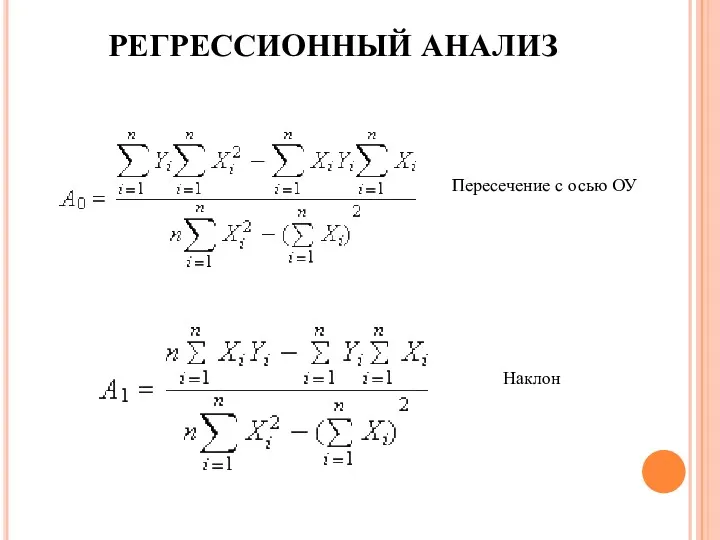
РЕГРЕССИОННЫЙ АНАЛИЗ
Пересечение с осью ОУ
Наклон
РЕГРЕССИОННЫЙ АНАЛИЗ
Пересечение с осью ОУ
Наклон
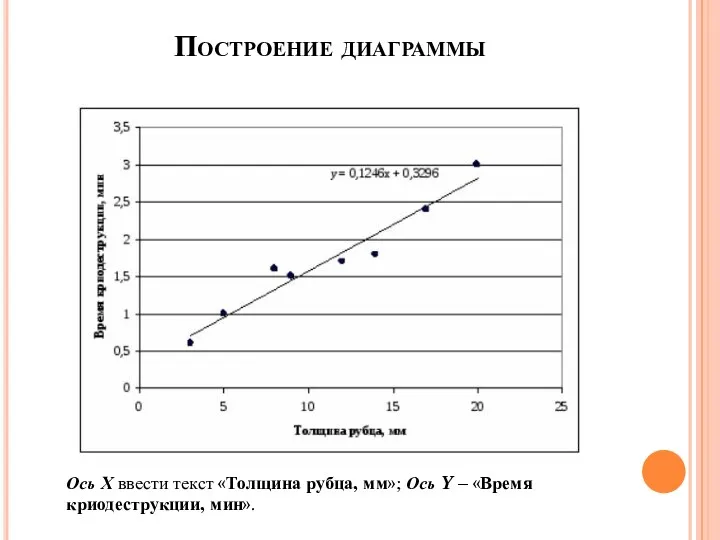
Построение диаграммы
Ось Х ввести текст «Толщина рубца, мм»; Ось Y – «Время
Построение диаграммы
Ось Х ввести текст «Толщина рубца, мм»; Ось Y – «Время
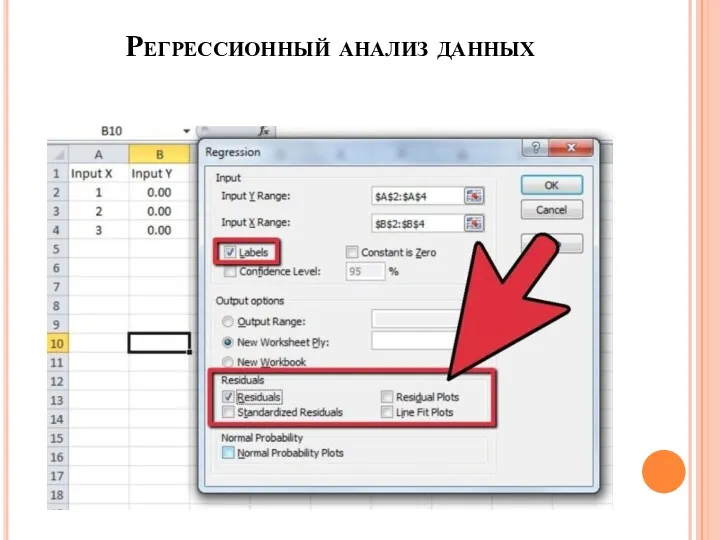
Регрессионный анализ данных
Регрессионный анализ данных

РЕГРЕССИОННЫЙ АНАЛИЗ
РЕГРЕССИОННЫЙ АНАЛИЗ

РЕГРЕССИОННЫЙ АНАЛИЗ
РЕГРЕССИОННЫЙ АНАЛИЗ

После проведения эксперимента необходимо убедиться в существовании линейной зависимости, адекватности линейной
После проведения эксперимента необходимо убедиться в существовании линейной зависимости, адекватности линейной

Разбиение объектов на кластеры, т.е. группы схожих элементов:
Кластеризация пациентов со схожей
Разбиение объектов на кластеры, т.е. группы схожих элементов:
Кластеризация пациентов со схожей

Анализ транзакций, т.е. событий, происходящих вместе.
Обнаружение зависимости вида «Из события
Анализ транзакций, т.е. событий, происходящих вместе.
Обнаружение зависимости вида «Из события

Анализ событий, связанных между собой по времени.
«После события А спустя
Анализ событий, связанных между собой по времени.
«После события А спустя
 Построение диаграмм и графиков в электронных таблицах
Построение диаграмм и графиков в электронных таблицах Знакомство с Word
Знакомство с Word Знаковые системы. Кодирование информации
Знаковые системы. Кодирование информации SAFA results: Operators Russian Federation
SAFA results: Operators Russian Federation Microsoft Word мәтінді құру және редакциялау
Microsoft Word мәтінді құру және редакциялау Приложение ВК
Приложение ВК Создание оригинал-макета визиток
Создание оригинал-макета визиток История становления и развития теории систем
История становления и развития теории систем Создание презентации в программе PowerPoint
Создание презентации в программе PowerPoint Операторы. Перегрузка операторов (лекция 5)
Операторы. Перегрузка операторов (лекция 5) Лабораторные занятия. Особенности лабораторной работы по информатике
Лабораторные занятия. Особенности лабораторной работы по информатике Кодирование информации
Кодирование информации Инсталляция и деинсталляция программного обеспечения
Инсталляция и деинсталляция программного обеспечения Тип даних множина
Тип даних множина Измерение информации. Единицы измерения информации
Измерение информации. Единицы измерения информации Логические основы компьютера
Логические основы компьютера Системный администратор. Примеры использования команды PING
Системный администратор. Примеры использования команды PING Архивы пользователя
Архивы пользователя Задача потребительского выбора. Задачи нелинейного программирования
Задача потребительского выбора. Задачи нелинейного программирования Code validation
Code validation Сравнительный анализ дизайна сайтов
Сравнительный анализ дизайна сайтов Протокол IPv4
Протокол IPv4 Электронная почта. История создания
Электронная почта. История создания Популярность Mова игр на примере Dota 2
Популярность Mова игр на примере Dota 2 The Essence of C++ with examples in C++84, C++98, C++11, and C++14
The Essence of C++ with examples in C++84, C++98, C++11, and C++14 Microsoft word-бұл құжаттарды құру, қарап шығу, өзгерту және басып шығару үшін арналған Microsoft Office
Microsoft word-бұл құжаттарды құру, қарап шығу, өзгерту және басып шығару үшін арналған Microsoft Office Компьютерные вирусы и защита от них
Компьютерные вирусы и защита от них Теории медиаобразования
Теории медиаобразования