- Скорость работы программы

Содержание
- 2. Перемножение void mult_matrices(double **a, double **b, double **c, int n) { int i, j, k; double
- 3. Варианты циклов первый цикл по i, второй по j, третий по k - кратко назовем ijk
- 4. Результаты.
- 5. Оптимизация
- 6. Разворачивание циклов int i, j, k; int i1,i2; double tmp,tmp1,tmp2; double temp; double *p,*ci,*ci1,*ci2; for(i=0, i1=1,
- 7. Результаты.
- 8. Разворачивание циклов int i,j,k; double *q,*b1,*b2,*b3,*b4,*b5,*b6,*b7,*b8,*b9,*b10; double a1,a2,a3,a4,a5,a6,a7,a8,a9,a10; for(k = 0; k b1=&b[k][0]; b2=&b[k+1][0]; b3=&b[k+2][0]; b4=&b[k+3][0];
- 9. Результат
- 10. dgemm Си extern void dgemm_(char *tra, char *trb, int *m, int *n, int *k, double *alpha,
- 11. transA='T'; transB='T'; alpha=1.0; zero=0.0; // mult_matrices(a, b, c,n); dgemm_(&transA,&transB,&n,&n,&n,&alpha,a,&n,b,&n,&zero,c,&n);
- 12. Компиляция cc -g -o matmul matmuldot.o -lm -lgoto -lpthread -lgfortran Makefile PROG=matmul TESTOBJ=matmuldot.o CFLAGS=-g CLFLAGS=-g LIBS=-lm
- 13. Классификация Флина.
- 14. Openmp
- 15. Включает/отключает режим, в котором количество создаваемых нитей при входе в параллельную область может меняться динамически. Начальное
- 16. #include #include int n; #pragma omp threadprivate(n) int main(int argc, char *argv[]) { int num; n=1;
- 17. Вложенные регионы int main(){ #pragma omp parallel // параллельный регион 1 { #pragma omp parallel {
- 18. Вложенные регионы
- 20. Архитектура Fermi
- 21. Системы с разделенной памятью MPP- системы(Массово-параллельная архитектура)
- 22. Системы с массовым параллелизмом (МРР)
- 23. Особенности MPP. Достоинство Хорошая масштабируемость. Недостатки Сложности межпроцессорного взаимодействия Разработка программ.
- 24. Кластера Кластеры высокой доступности Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность). Создаются для обеспечения
- 25. Кластеры повышенной производительности Обозначаются англ. аббревиатурой HPC (High performance cluster). Позволяют увеличить скорость расчетов, разбивая задание
- 26. Вычислительные ресурсы ЮГИНФО LINUX-кластер (10 узлов, 2003 г., CPU P4 2.4 Ггц, память 512 Мб )
- 32. Софт INTEL 11.0 icc icpc ifort GCC gcc g++ gfortran MPI
- 33. Системы управления заданиями PBS (Portable Batch System) – система управления ресурсами и загрузкой кластеров. Может работать
- 34. PBS. Оригинальный opensource проект OpenPBS разработанный в 1998 году MRJ.(на данный момент не поддерживается) TORQUE (
- 35. Архитектура PBS. Сервер (pbs_server) который является центром PBS, именно сервер принимает задания от пользователей, удаляет задания,
- 36. PBS наиболее часто используемые команды qsub – команда для запуска задачи qstat – для просмотра состояния
- 37. qsub qsub [options] PBS_script #!/bin/sh #PBS -l walltime=1:00:00 #PBS -l nodes=2:LINUX cd $PBS_O_WORKDIR mpirun -np 2
- 38. опции команды qsub q - название очереди пакетной обработки -l - набор технических параметров, набираемых через
- 39. Команда qstat
- 40. Описание вывода qstat Job id - уникальный идентификатор задачи Name - имя исполняемой задачи User -
- 41. команда pestat
- 42. qdel qdel - удаление задания qdel 36807
- 43. Распараллеливания программ SPMD (Single Program Multiple Date) - на всех процессорах выполняются копии одной программы, обрабатывающие
- 44. Методологический подхода(Фостера) к решению задачи на многопроцессорной системе разбиение задачи на минимальные независимые подзадачи (partitioning); установление
- 45. Общая схема распараллеливания if (proc_id == 0) { task1(); } if (proc_id == 1) { task2();
- 46. Общая организация MPI Коммуникационная библиотека MPI стала общепризнанным стандартом в параллельном программировании для систем с распределенной
- 47. Общая организация MPI (продолжение) Для идентификации наборов процессов вводится понятие группы, объединяющей все или какую-то часть
- 48. Структура MPI Около 130 функций - функции инициализации и закрытия MPI процессов; - функции, реализующие коммуникационные
- 49. Характеристики функций Локальная функция – выполняется внутри вызывающего процесса. Ее завершение не требует коммуникаций. Нелокальная функция
- 50. Особенности MPI в Си Все процедуры являются функциями, и большинство из них возвращает код ошибки. При
- 51. Соответствие между MPI-типами и типами языка C
- 52. Особенности MPI в Фортране большинство MPI процедур являются подпрограммами (вызываются с помощью оператора CALL), код ошибки
- 53. Соответствие между MPI-типами и типам языка FORTRAN Тип MPI Тип языка FORTRAN MPI_INTEGER INTEGER MPI_REAL REAL
- 54. Базовые функции MPI Функция инициализации MPI_Init C/C++: int MPI_Init(int *argc, char ***argv) Fortran: MPI_INIT(IERROR) INTEGER IERROR
- 55. Базовые функции MPI Функция завершения MPI программ MPI_Finalize. C/C++: int MPI_Finalize(void) Fortran: MPI_FINALIZE(IERROR) INTEGER IERROR
- 56. Базовые функции MPI Функция определения числа процессов в области связи MPI_Comm_size. C/C++: int MPI_Comm_size(MPI_Comm comm, int
- 57. Базовые функции MPI . Функция определения номера процесса MPI_Comm_rank C/C++: int MPI_Comm_rank(MPI_Comm comm, int *rank) Fortran:
- 58. Базовые функции MPI Функция передачи сообщения MPI_Send. C/C++: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int
- 59. Базовые функции MPI Функция приема сообщения MPI_Recv. C/C++: int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int
- 60. Базовые функции MPI Функция отсчета времени (таймер) MPI_Wtime. C/C++: double MPI_Wtime(void) Fortran: DOUBLE PRECISION MPI_WTIME() Функция
- 62. Скачать презентацию

Перемножение
void mult_matrices(double **a, double **b, double **c, int n)
{
int i,
Перемножение
void mult_matrices(double **a, double **b, double **c, int n)
{
int i,

Варианты циклов
первый цикл по i, второй по j, третий по k
Варианты циклов
первый цикл по i, второй по j, третий по k
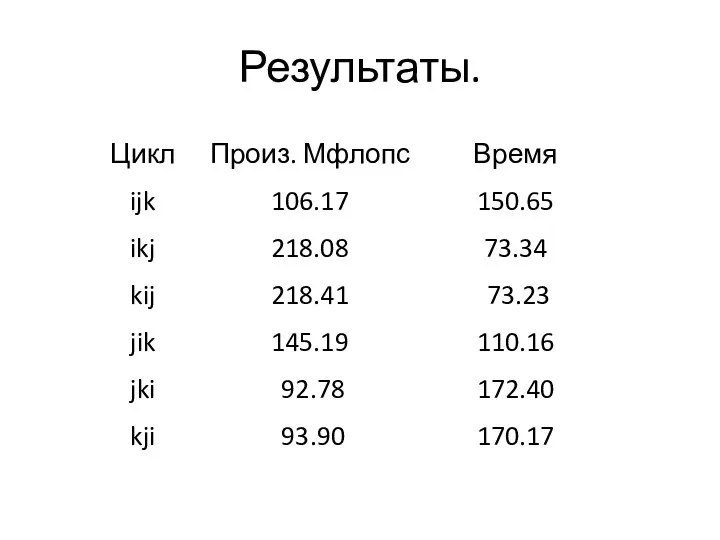
Результаты.
Результаты.
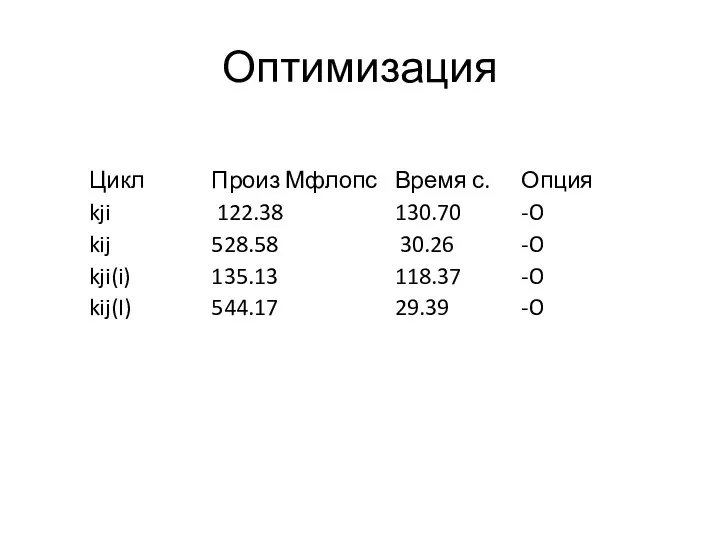
Оптимизация
Оптимизация

Разворачивание циклов
int i, j, k;
int i1,i2;
double tmp,tmp1,tmp2;
double
Разворачивание циклов
int i, j, k;
int i1,i2;
double tmp,tmp1,tmp2;
double

Результаты.
Результаты.

Разворачивание циклов
int i,j,k;
double *q,*b1,*b2,*b3,*b4,*b5,*b6,*b7,*b8,*b9,*b10;
double a1,a2,a3,a4,a5,a6,a7,a8,a9,a10;
for(k = 0; k < n; k+=
Разворачивание циклов
int i,j,k;
double *q,*b1,*b2,*b3,*b4,*b5,*b6,*b7,*b8,*b9,*b10;
double a1,a2,a3,a4,a5,a6,a7,a8,a9,a10;
for(k = 0; k < n; k+=
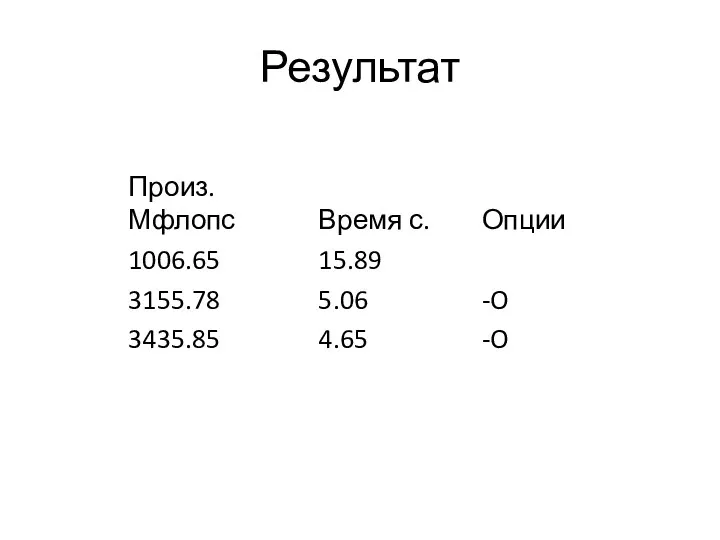
Результат
Результат

dgemm
Си
extern void dgemm_(char *tra, char *trb, int *m, int *n, int
dgemm
Си
extern void dgemm_(char *tra, char *trb, int *m, int *n, int

transA='T';
transB='T';
alpha=1.0;
zero=0.0;
// mult_matrices(a, b, c,n);
dgemm_(&transA,&transB,&n,&n,&n,&alpha,a,&n,b,&n,&zero,c,&n);
transA='T';
transB='T';
alpha=1.0;
zero=0.0;
// mult_matrices(a, b, c,n);
dgemm_(&transA,&transB,&n,&n,&n,&alpha,a,&n,b,&n,&zero,c,&n);

Компиляция
cc -g -o matmul matmuldot.o -lm -lgoto -lpthread -lgfortran
Makefile
PROG=matmul
TESTOBJ=matmuldot.o
CFLAGS=-g
CLFLAGS=-g
LIBS=-lm -lgoto -lpthread
Компиляция
cc -g -o matmul matmuldot.o -lm -lgoto -lpthread -lgfortran
Makefile
PROG=matmul
TESTOBJ=matmuldot.o
CFLAGS=-g
CLFLAGS=-g
LIBS=-lm -lgoto -lpthread
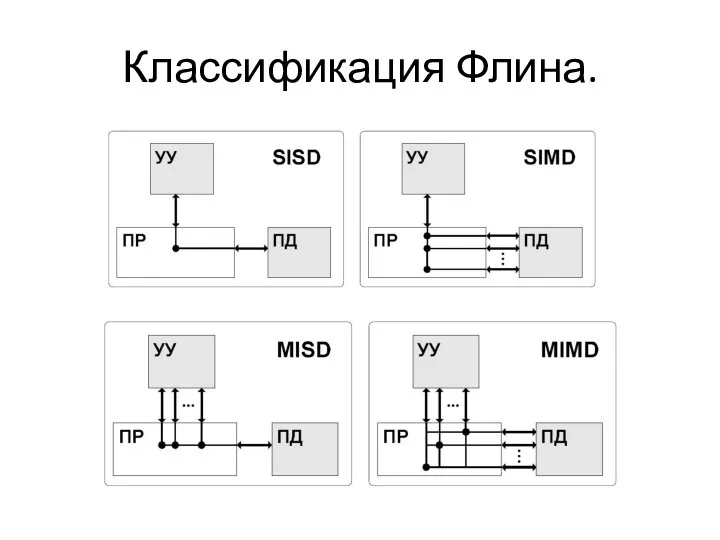
Классификация Флина.
Классификация Флина.

Openmp
Openmp

Включает/отключает режим, в котором количество создаваемых нитей при входе в параллельную
Включает/отключает режим, в котором количество создаваемых нитей при входе в параллельную

#include
#include
int n;
#pragma omp threadprivate(n)
int main(int argc, char *argv[])
{
int num;
n=1;
#pragma
#include
#include
int n;
#pragma omp threadprivate(n)
int main(int argc, char *argv[])
{
int num;
n=1;
#pragma

Вложенные регионы
int main(){
#pragma omp parallel // параллельный регион 1
{
Вложенные регионы
int main(){
#pragma omp parallel // параллельный регион 1
{
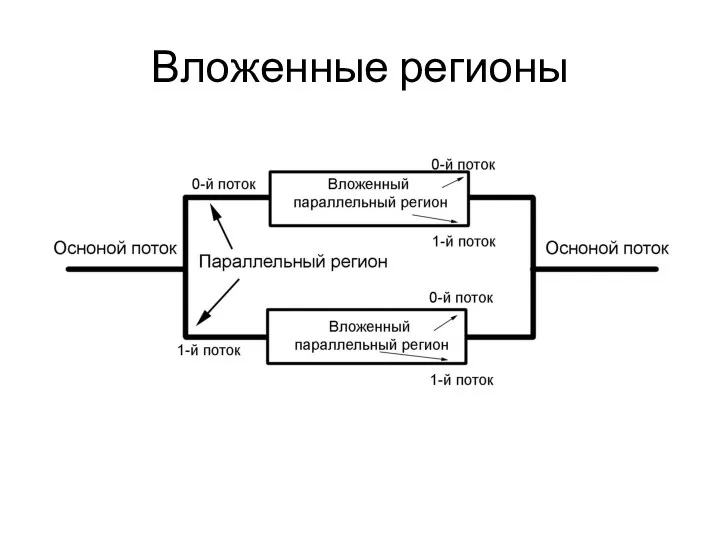
Вложенные регионы
Вложенные регионы
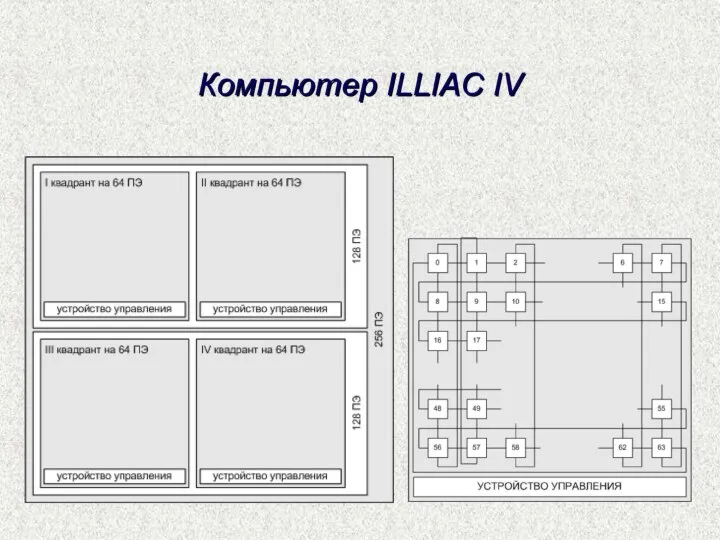

Архитектура Fermi
Архитектура Fermi

Системы с разделенной памятью
MPP- системы(Массово-параллельная архитектура)
Системы с разделенной памятью
MPP- системы(Массово-параллельная архитектура)
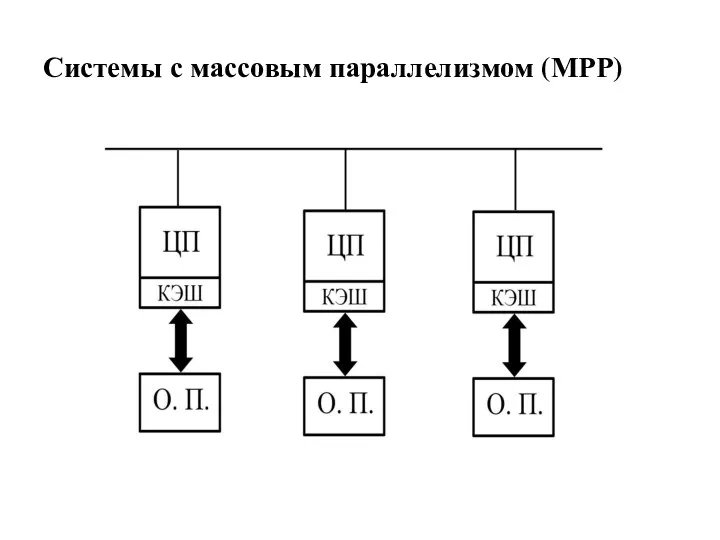
Системы с массовым параллелизмом (МРР)
Системы с массовым параллелизмом (МРР)

Особенности MPP.
Достоинство
Хорошая масштабируемость.
Недостатки
Сложности межпроцессорного взаимодействия
Разработка программ.
Особенности MPP.
Достоинство
Хорошая масштабируемость.
Недостатки
Сложности межпроцессорного взаимодействия
Разработка программ.

Кластера
Кластеры высокой доступности
Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность).
Кластера
Кластеры высокой доступности
Обозначаются аббревиатурой HA (англ. High Availability — высокая доступность).

Кластеры повышенной производительности
Обозначаются англ. аббревиатурой HPC (High performance cluster). Позволяют увеличить
Обозначаются англ. аббревиатурой HPC (High performance cluster). Позволяют увеличить

Вычислительные ресурсы ЮГИНФО
LINUX-кластер (10 узлов, 2003 г., CPU P4 2.4 Ггц,
Вычислительные ресурсы ЮГИНФО
LINUX-кластер (10 узлов, 2003 г., CPU P4 2.4 Ггц,






Софт
INTEL 11.0
icc
icpc
ifort
GCC
gcc
g++
gfortran
MPI
Софт
INTEL 11.0
icc
icpc
ifort
GCC
gcc
g++
gfortran
MPI

Системы управления заданиями
PBS (Portable Batch System) – система управления ресурсами и
Системы управления заданиями
PBS (Portable Batch System) – система управления ресурсами и

PBS.
Оригинальный opensource проект OpenPBS разработанный в 1998 году MRJ.(на данный момент
PBS.
Оригинальный opensource проект OpenPBS разработанный в 1998 году MRJ.(на данный момент

Архитектура PBS.
Сервер (pbs_server) который является центром PBS, именно сервер принимает задания
Архитектура PBS.
Сервер (pbs_server) который является центром PBS, именно сервер принимает задания

PBS наиболее часто используемые команды
qsub – команда для запуска задачи
qstat –
PBS наиболее часто используемые команды
qsub – команда для запуска задачи
qstat –
![qsub qsub [options] PBS_script #!/bin/sh #PBS -l walltime=1:00:00 #PBS -l](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/395631/slide-36.jpg)
qsub
qsub [options] PBS_script
#!/bin/sh
#PBS -l walltime=1:00:00
#PBS -l nodes=2:LINUX
cd $PBS_O_WORKDIR
mpirun -np 2 ping_DELLE
Результат
qsub
qsub [options] PBS_script
#!/bin/sh
#PBS -l walltime=1:00:00
#PBS -l nodes=2:LINUX
cd $PBS_O_WORKDIR
mpirun -np 2 ping_DELLE
Результат

опции команды qsub
q - название очереди пакетной обработки
-l - набор технических
опции команды qsub
q - название очереди пакетной обработки
-l - набор технических

Команда qstat
Команда qstat

Описание вывода qstat
Job id - уникальный идентификатор задачи
Name - имя исполняемой
Описание вывода qstat
Job id - уникальный идентификатор задачи
Name - имя исполняемой
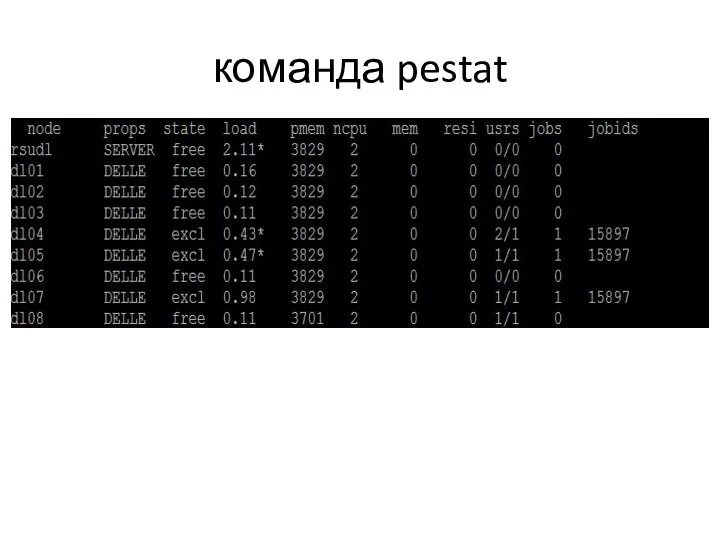
команда pestat
команда pestat

qdel
qdel - удаление задания
qdel 36807
qdel
qdel - удаление задания
qdel 36807

Распараллеливания программ
SPMD (Single Program Multiple Date) - на всех процессорах выполняются
Распараллеливания программ
SPMD (Single Program Multiple Date) - на всех процессорах выполняются

Методологический подхода(Фостера) к решению задачи на многопроцессорной системе
разбиение задачи на минимальные
Методологический подхода(Фостера) к решению задачи на многопроцессорной системе
разбиение задачи на минимальные

Общая схема распараллеливания
if (proc_id == 0) {
task1();
Общая схема распараллеливания
if (proc_id == 0) {
task1();

Общая организация MPI
Коммуникационная библиотека MPI стала общепризнанным стандартом в параллельном
Общая организация MPI
Коммуникационная библиотека MPI стала общепризнанным стандартом в параллельном

Общая организация MPI
(продолжение)
Для идентификации наборов процессов вводится понятие группы, объединяющей все
Общая организация MPI
(продолжение)
Для идентификации наборов процессов вводится понятие группы, объединяющей все

Структура MPI
Около 130 функций
- функции инициализации и закрытия MPI процессов;
- функции,
Структура MPI
Около 130 функций
- функции инициализации и закрытия MPI процессов;
- функции,

Характеристики функций
Локальная функция – выполняется внутри вызывающего процесса. Ее завершение не
Характеристики функций
Локальная функция – выполняется внутри вызывающего процесса. Ее завершение не

Особенности MPI в Си
Все процедуры являются функциями, и большинство из них
Особенности MPI в Си
Все процедуры являются функциями, и большинство из них
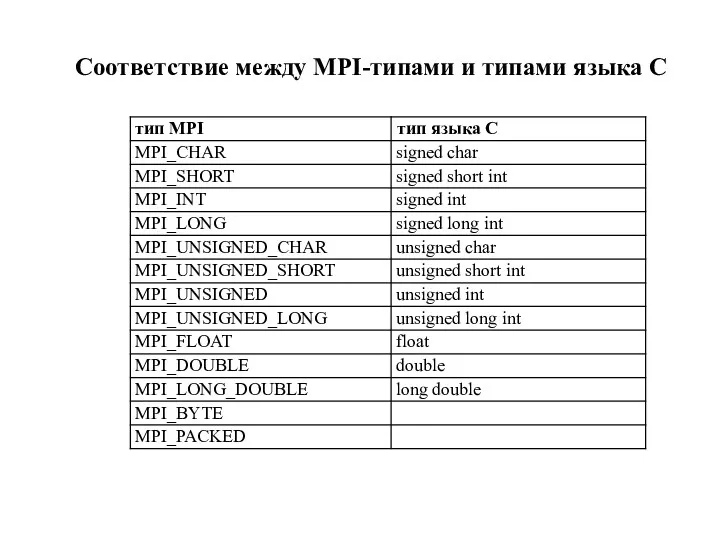
Соответствие между MPI-типами и типами языка C
Соответствие между MPI-типами и типами языка C

Особенности MPI в Фортране
большинство MPI процедур являются подпрограммами (вызываются с помощью
Особенности MPI в Фортране
большинство MPI процедур являются подпрограммами (вызываются с помощью
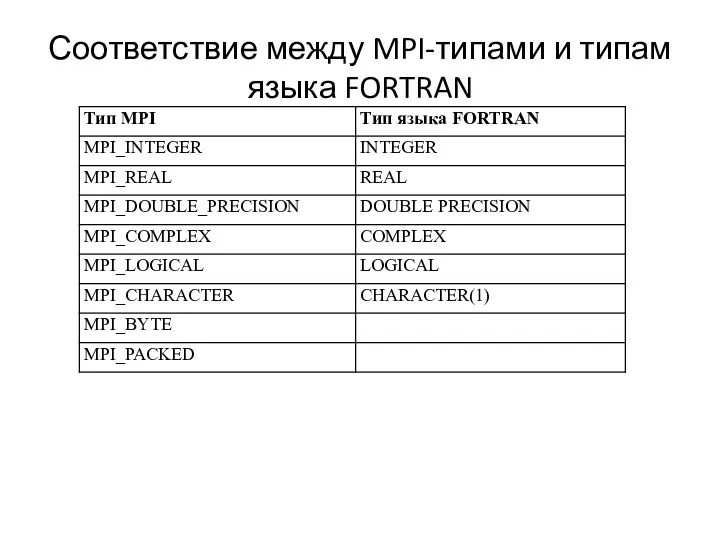
Соответствие между MPI-типами и типам языка FORTRAN
Тип MPI Тип языка FORTRAN
MPI_INTEGER INTEGER
MPI_REAL REAL
MPI_DOUBLE_PRECISION DOUBLE PRECISION
MPI_COMPLEX COMPLEX
MPI_LOGICAL LOGICAL
MPI_CHARACTER CHARACTER(1)
MPI_BYTE
MPI_PACKED
Соответствие между MPI-типами и типам языка FORTRAN
Тип MPI Тип языка FORTRAN
MPI_INTEGER INTEGER
MPI_REAL REAL
MPI_DOUBLE_PRECISION DOUBLE PRECISION
MPI_COMPLEX COMPLEX
MPI_LOGICAL LOGICAL
MPI_CHARACTER CHARACTER(1)
MPI_BYTE
MPI_PACKED

Базовые функции MPI
Функция инициализации MPI_Init
C/C++:
int MPI_Init(int *argc, char ***argv)
Fortran:
MPI_INIT(IERROR)
INTEGER IERROR
Базовые функции MPI
Функция инициализации MPI_Init
C/C++:
int MPI_Init(int *argc, char ***argv)
Fortran:
MPI_INIT(IERROR)
INTEGER IERROR

Базовые функции MPI
Функция завершения MPI программ MPI_Finalize.
C/C++:
int MPI_Finalize(void)
Fortran:
MPI_FINALIZE(IERROR)
INTEGER IERROR
Базовые функции MPI
Функция завершения MPI программ MPI_Finalize.
C/C++:
int MPI_Finalize(void)
Fortran:
MPI_FINALIZE(IERROR)
INTEGER IERROR

Базовые функции MPI
Функция определения числа процессов в области связи MPI_Comm_size.
C/C++:
int MPI_Comm_size(MPI_Comm
Базовые функции MPI
Функция определения числа процессов в области связи MPI_Comm_size.
C/C++:
int MPI_Comm_size(MPI_Comm

Базовые функции MPI
. Функция определения номера процесса MPI_Comm_rank
C/C++:
int MPI_Comm_rank(MPI_Comm comm, int
Базовые функции MPI
. Функция определения номера процесса MPI_Comm_rank
C/C++:
int MPI_Comm_rank(MPI_Comm comm, int

Базовые функции MPI
Функция передачи сообщения MPI_Send.
C/C++:
int MPI_Send(void* buf, int count, MPI_Datatype
Базовые функции MPI
Функция передачи сообщения MPI_Send.
C/C++:
int MPI_Send(void* buf, int count, MPI_Datatype

Базовые функции MPI
Функция приема сообщения MPI_Recv.
C/C++:
int MPI_Recv(void* buf, int count, MPI_Datatype
Базовые функции MPI
Функция приема сообщения MPI_Recv.
C/C++:
int MPI_Recv(void* buf, int count, MPI_Datatype

Базовые функции MPI
Функция отсчета времени (таймер) MPI_Wtime.
C/C++:
double MPI_Wtime(void)
Fortran:
DOUBLE PRECISION MPI_WTIME()
Функция опроса
Базовые функции MPI
Функция отсчета времени (таймер) MPI_Wtime.
C/C++:
double MPI_Wtime(void)
Fortran:
DOUBLE PRECISION MPI_WTIME()
Функция опроса
 Как уберечься от недостоверной информации?
Как уберечься от недостоверной информации? Верстка web-страниц
Верстка web-страниц Создание сайта для инициативной группы Министерства молодёжи, спорта и туризма ДНР
Создание сайта для инициативной группы Министерства молодёжи, спорта и туризма ДНР Системы обработки информации и управления
Системы обработки информации и управления Информационные технологии в профессиональной деятельности
Информационные технологии в профессиональной деятельности презентация на тему Представление об объектах окружающего мира
презентация на тему Представление об объектах окружающего мира Are we depend on social media
Are we depend on social media Сетевое и системное администрирование
Сетевое и системное администрирование 20231013_po
20231013_po Компьютерные игры: вредно или полезно
Компьютерные игры: вредно или полезно Автоматизированная система измерения частотных характеристик кабельных линий передачи данных на основе медной витой пары
Автоматизированная система измерения частотных характеристик кабельных линий передачи данных на основе медной витой пары Информатика. Русский язык
Информатика. Русский язык Памятка волонтеру группы в Квартале
Памятка волонтеру группы в Квартале Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій
Розроблення модуля Управління бізнес-процесами оренди автомобілів на основі Web-технологій Презентация Архитектурная схема ЭВМ, Состав ПК
Презентация Архитектурная схема ЭВМ, Состав ПК Дискретная форма представления информации. 7 класс
Дискретная форма представления информации. 7 класс Разбор заданий В11. IP-адрес
Разбор заданий В11. IP-адрес Системы счисления
Системы счисления Понятие Информационно-техническое обеспечение
Понятие Информационно-техническое обеспечение Kutubxona faoliyatida amaliy dasturiy vositalardan foydalanish. Elektron hujjatlarni yaratishda tegishli dasturiy foydalanish
Kutubxona faoliyatida amaliy dasturiy vositalardan foydalanish. Elektron hujjatlarni yaratishda tegishli dasturiy foydalanish Алгоритми. Лекция 1
Алгоритми. Лекция 1 Overview of Zoho Cliq
Overview of Zoho Cliq Ювелирный магазин 1С:Розница 8
Ювелирный магазин 1С:Розница 8 Коммерческое предложение по созданию сайта
Коммерческое предложение по созданию сайта Подсистема прерываний. Лабораторная работа №3
Подсистема прерываний. Лабораторная работа №3 Использование программных продуктов фирмы 1С в учебных заведениях
Использование программных продуктов фирмы 1С в учебных заведениях Тестирование как средство контроля знаний обучающихся
Тестирование как средство контроля знаний обучающихся Python. Функции
Python. Функции