- Технологии хранения информации и больших объемов данных. Лекция 1

Содержание
- 2. Наполнение курса Объем курса 8 лекционных и 8 практических занятий Темы лекционных занятий Технологии хранения информации
- 3. Тематика курса Курс предназначен для ознакомления с возможностями работы с данными в современных компьютерных системах и
- 4. Лекция 1. Технологии хранения информации и больших объемов данных
- 5. Часть 1. Введение в Большие данные
- 6. Что такое Большие данные? Большие данные — это разнообразные данные, которые поступают с постоянно растущей скоростью
- 7. Насколько это необходимо? Обзор (2020) компании Data Age Reportпо технологической цифровизации до 2025 года Необходимость RTM
- 8. Задачи обработки больших данных Главной задачей обработки больших данных на сегодняшний день является максимимзация пользы от
- 9. Задачи в области Больших данных
- 10. Задачи в области Больших данных
- 11. Специалисты по работе с данными Классификация специалистов, задействованых в работе с данными, на сегодняшний день всё
- 12. Инженер данных Направления работы инженера данных Предоставление данных для аналитики (Хранилища данных, Аналитика, Визуализация) Предоставление данных
- 13. Аналитик данных Направления работы аналитика данных Формулировка бизнес-метрик для построения продуктовых решений на основе данных Построение
- 14. Конвейер обработки данных Перед извлечением из данных пользы их необходимо собрать, очистить, сохранить в нужном виде
- 15. Инфраструктура обработки данных Большие компании хранят, обрабатывают и анализируют данные на серверных вычислительных устройствах или ЦОД
- 16. Инструменты больших данных Хранение данных Управление потоками данных Обработка и анализ данных
- 17. Часть 2. Информация и данные в вычислительных устройствах
- 18. Информация Информация - нематериальная сущность, при помощи которой с любой точностью можно описывать реальные (материальные), виртуальные
- 19. Бит, байт В современных пользовательских и серверных вычислительных устройствах общего назначения информация, хранимая на носителях и
- 20. Данные Пример. Примитивные типы данных в языке программирования С++
- 21. Кодовые таблицы символов ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского
- 22. Кодовые таблицы символов
- 23. Часть 3. Вычислительная инфраструктура и вычислительные устройства
- 24. Вычислительные устройства Основные характеристики вычислительного устройства: Вычислительная мощность (процессор) Оперативная память (ОЗУ) Хранилище (дисковое пространство)
- 25. Дисковые накопители Дисковый накопитель отвечает за долговременное хранение информации пользователя. Это файлы, медиа и данные, которые
- 26. Жесткие диски Жесткий диск (или HDD) — устройство хранения данных, принцип записи информации в котором заключается
- 27. Твердотельные накопители Твердотельный накопитель (или SSD) — устройство, использующее для хранения информации флеш-память. Флеш-память (или flash
- 28. Скорость чтения и записи данных с диска Скорость чтения измеряет, насколько быстро накопитель может «читать» или
- 29. Долговечность диска Мерой эффективности и быстродействия SSD является количество операций ввода/вывода в секунду (IOPS, Input/Output Operations
- 30. Оперативная память Оперативная память компьютера - энергозависимая часть системы компьютерной памяти, в которой во время работы
- 31. Современные стандарты ОЗУ Современные ОЗУ отличаются стандартами хранения. Более новые версии стандартов отличаются более высокими номерами
- 32. Процессор Центральный процессор – интегральная схема, исполняющая машинные инструкции (коды программ). Машинный код - специфицированный набор
- 33. Инфраструктура вычислений На данный момент выделяют следующие виды вычислительных инфраструктур: Персональные компьютеры (терминал доступа к серверу)
- 34. Персональные компьютеры На данный момент персональные компьютеры используются в роли терминалов доступа к вычислительным серверам Типичная
- 35. Локальный вычислительный сервер Серверный компьютер – единица серверной вычислительной инфраструктуры Производители серверов предлагают устанавливать серверный компьютер
- 36. Центры обработки данных Центры обработки данных (ЦОД) — это специализированное здание или помещение, в котором компания
- 37. Классы ЦОД
- 38. Архитектура ЦОД (упрощенная схема)
- 39. Облачные сервисы Операторы дата-центров и облачные сервисы на коммерческой основе предоставляют ресурсы для развертывания вычислений или
- 40. Часть 4. Операционные системы для работы с данными
- 41. Классификация операционных систем
- 42. Серверные операционные системы Серверные ОС – предназначены для управления программным обеспечением, которое в свою очередь обслуживает
- 43. Офисные операционные системы Офисные/пользовательские ОС снабжены графической оболочкой (интерфейсом), удобной для взаимодействия с компьютером посредством координатного
- 44. Взаимодействие ОС
- 45. Часть 5. Форматы, файлы и введение в файловые системы
- 46. Файловые системы Файловая система определяет формат содержимого и способ физического хранения информации, которую принято группировать в
- 47. Файловые системы Файловая система – это инструмент, позволяющий операционной системе и программам обращаться к нужным файлам
- 48. Функции файловой системы Фрагментация файлов и их распределение на носителе. Поиск файла при запросе программ. Участие
- 49. Файл, формат файла Файл — именованная область данных на носителе информации, используемая как базовый объект взаимодействия
- 50. Полное имя файла
- 51. Дополнительные атрибуты файла Расширение имени файла: позволяет системе определить, каким приложением следует открывать данный файл. Обычно,
- 52. Права доступа в Linux
- 53. Операции с файлами Открытие файла – возможность обращения к файлу для последующих циклов чтения или записи
- 54. Размер файла Размер файла - это показатель того, сколько данных содержит компьютерный файл или, наоборот, сколько
- 55. Типы файлов По способу организации файлы делятся на файлы с произвольным доступом и файлы с последовательным
- 57. Скачать презентацию

Наполнение курса
Объем курса
8 лекционных и 8 практических занятий
Темы лекционных занятий
Технологии хранения
Наполнение курса
Объем курса
8 лекционных и 8 практических занятий
Темы лекционных занятий
Технологии хранения

Тематика курса
Курс предназначен для ознакомления с возможностями работы с данными в
Тематика курса
Курс предназначен для ознакомления с возможностями работы с данными в

Лекция 1. Технологии хранения информации и больших объемов данных
Лекция 1. Технологии хранения информации и больших объемов данных

Часть 1. Введение в Большие данные
Часть 1. Введение в Большие данные

Что такое Большие данные?
Большие данные — это разнообразные данные, которые поступают
Что такое Большие данные?
Большие данные — это разнообразные данные, которые поступают
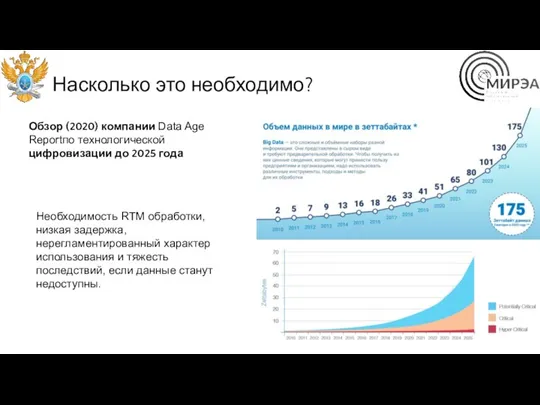
Насколько это необходимо?
Обзор (2020) компании Data Age Reportпо технологической цифровизации до
Насколько это необходимо?
Обзор (2020) компании Data Age Reportпо технологической цифровизации до

Задачи обработки больших данных
Главной задачей обработки больших данных на сегодняшний день
Задачи обработки больших данных
Главной задачей обработки больших данных на сегодняшний день

Задачи в области Больших данных
Задачи в области Больших данных

Задачи в области Больших данных
Задачи в области Больших данных

Специалисты по работе с данными
Классификация специалистов, задействованых в работе с данными,
Специалисты по работе с данными
Классификация специалистов, задействованых в работе с данными,

Инженер данных
Направления работы инженера данных
Предоставление данных для аналитики (Хранилища данных, Аналитика,
Инженер данных
Направления работы инженера данных
Предоставление данных для аналитики (Хранилища данных, Аналитика,
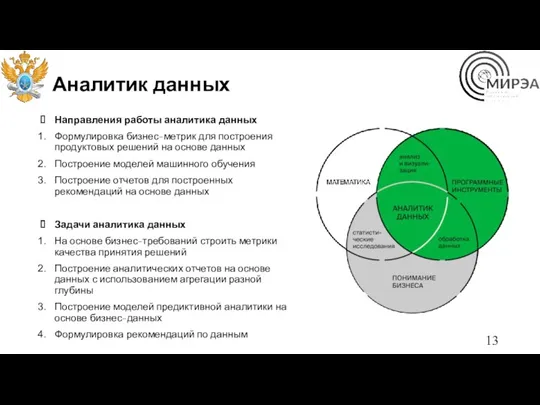
Аналитик данных
Направления работы аналитика данных
Формулировка бизнес-метрик для построения продуктовых решений на
Аналитик данных
Направления работы аналитика данных
Формулировка бизнес-метрик для построения продуктовых решений на
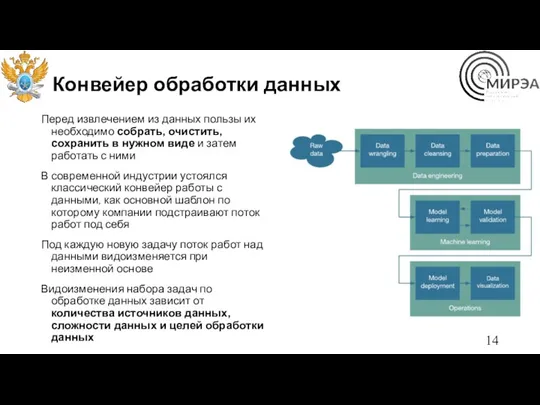
Конвейер обработки данных
Перед извлечением из данных пользы их необходимо собрать, очистить,
Конвейер обработки данных
Перед извлечением из данных пользы их необходимо собрать, очистить,

Инфраструктура обработки данных
Большие компании хранят, обрабатывают и анализируют данные на серверных
Инфраструктура обработки данных
Большие компании хранят, обрабатывают и анализируют данные на серверных

Инструменты больших данных
Хранение данных
Управление потоками данных
Обработка и анализ данных
Инструменты больших данных
Хранение данных
Управление потоками данных
Обработка и анализ данных

Часть 2. Информация и данные в вычислительных устройствах
Часть 2. Информация и данные в вычислительных устройствах

Информация
Информация - нематериальная сущность, при помощи которой с любой точностью можно
Информация
Информация - нематериальная сущность, при помощи которой с любой точностью можно

Бит, байт
В современных пользовательских и серверных вычислительных устройствах общего назначения информация,
Бит, байт
В современных пользовательских и серверных вычислительных устройствах общего назначения информация,

Данные
Пример. Примитивные типы данных в языке программирования С++
Данные
Пример. Примитивные типы данных в языке программирования С++

Кодовые таблицы символов
ASCII7 — первая кодировка, пригодная для работы с текстом.
Кодовые таблицы символов
ASCII7 — первая кодировка, пригодная для работы с текстом.

Кодовые таблицы символов
Кодовые таблицы символов

Часть 3. Вычислительная инфраструктура и вычислительные устройства
Часть 3. Вычислительная инфраструктура и вычислительные устройства

Вычислительные устройства
Основные характеристики вычислительного устройства:
Вычислительная мощность (процессор)
Оперативная память (ОЗУ)
Хранилище (дисковое пространство)
Вычислительные устройства
Основные характеристики вычислительного устройства:
Вычислительная мощность (процессор)
Оперативная память (ОЗУ)
Хранилище (дисковое пространство)

Дисковые накопители
Дисковый накопитель отвечает за долговременное хранение информации пользователя. Это файлы,
Дисковые накопители
Дисковый накопитель отвечает за долговременное хранение информации пользователя. Это файлы,

Жесткие диски
Жесткий диск (или HDD) — устройство хранения данных, принцип записи
Жесткие диски
Жесткий диск (или HDD) — устройство хранения данных, принцип записи

Твердотельные накопители
Твердотельный накопитель (или SSD) — устройство, использующее для хранения информации
Твердотельные накопители
Твердотельный накопитель (или SSD) — устройство, использующее для хранения информации

Скорость чтения и записи данных с диска
Скорость чтения измеряет, насколько быстро
Скорость чтения и записи данных с диска
Скорость чтения измеряет, насколько быстро

Долговечность диска
Мерой эффективности и быстродействия SSD является количество операций ввода/вывода в
Долговечность диска
Мерой эффективности и быстродействия SSD является количество операций ввода/вывода в

Оперативная память
Оперативная память компьютера - энергозависимая часть системы компьютерной памяти, в
Оперативная память
Оперативная память компьютера - энергозависимая часть системы компьютерной памяти, в

Современные стандарты ОЗУ
Современные ОЗУ отличаются стандартами хранения.
Более новые версии стандартов
Современные стандарты ОЗУ
Современные ОЗУ отличаются стандартами хранения.
Более новые версии стандартов

Процессор
Центральный процессор – интегральная схема, исполняющая машинные инструкции (коды программ).
Машинный
Процессор
Центральный процессор – интегральная схема, исполняющая машинные инструкции (коды программ).
Машинный

Инфраструктура вычислений
На данный момент выделяют следующие виды вычислительных инфраструктур:
Персональные компьютеры (терминал
Инфраструктура вычислений
На данный момент выделяют следующие виды вычислительных инфраструктур:
Персональные компьютеры (терминал

Персональные компьютеры
На данный момент персональные компьютеры используются в роли терминалов доступа
Персональные компьютеры
На данный момент персональные компьютеры используются в роли терминалов доступа

Локальный вычислительный сервер
Серверный компьютер – единица серверной вычислительной инфраструктуры
Производители серверов предлагают
Локальный вычислительный сервер
Серверный компьютер – единица серверной вычислительной инфраструктуры
Производители серверов предлагают

Центры обработки данных
Центры обработки данных (ЦОД) — это специализированное здание или помещение,
Центры обработки данных
Центры обработки данных (ЦОД) — это специализированное здание или помещение,
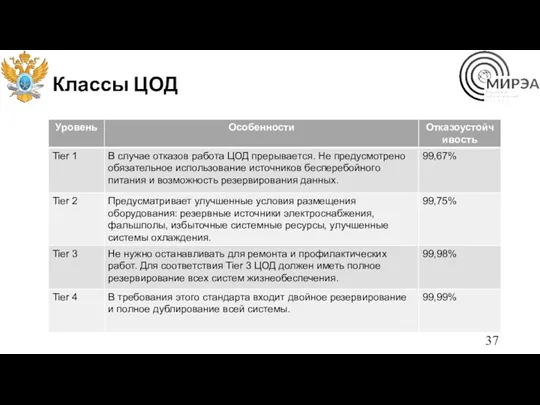
Классы ЦОД
Классы ЦОД

Архитектура ЦОД (упрощенная схема)
Архитектура ЦОД (упрощенная схема)

Облачные сервисы
Операторы дата-центров и облачные сервисы на коммерческой основе предоставляют ресурсы
Облачные сервисы
Операторы дата-центров и облачные сервисы на коммерческой основе предоставляют ресурсы

Часть 4. Операционные системы для работы с данными
Часть 4. Операционные системы для работы с данными
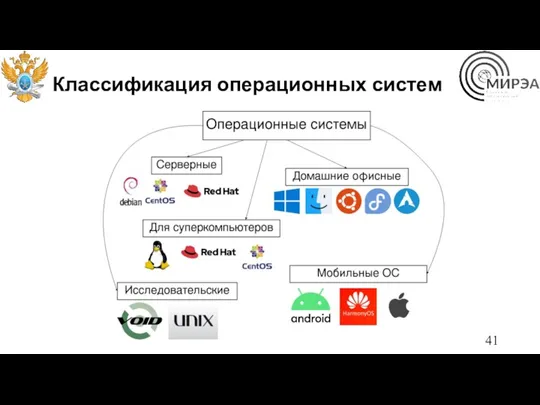
Классификация операционных систем
Классификация операционных систем

Серверные операционные системы
Серверные ОС – предназначены для управления программным обеспечением, которое
Серверные операционные системы
Серверные ОС – предназначены для управления программным обеспечением, которое

Офисные операционные системы
Офисные/пользовательские ОС снабжены графической оболочкой (интерфейсом), удобной для взаимодействия
Офисные операционные системы
Офисные/пользовательские ОС снабжены графической оболочкой (интерфейсом), удобной для взаимодействия
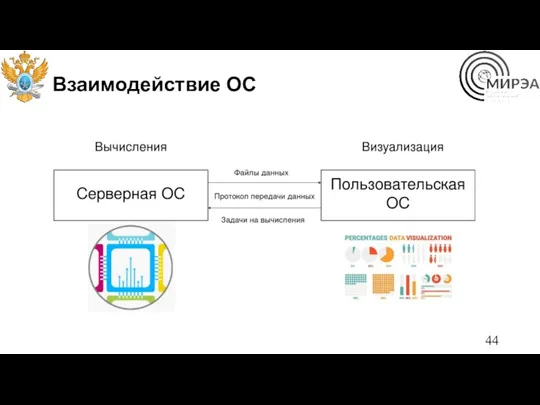
Взаимодействие ОС
Взаимодействие ОС

Часть 5. Форматы, файлы и введение в файловые системы
Часть 5. Форматы, файлы и введение в файловые системы

Файловые системы
Файловая система определяет формат содержимого и способ физического хранения информации,
Файловые системы
Файловая система определяет формат содержимого и способ физического хранения информации,

Файловые системы
Файловая система – это инструмент, позволяющий операционной системе и программам
Файловые системы
Файловая система – это инструмент, позволяющий операционной системе и программам

Функции файловой системы
Фрагментация файлов и их распределение на носителе.
Поиск файла при
Функции файловой системы
Фрагментация файлов и их распределение на носителе.
Поиск файла при

Файл, формат файла
Файл — именованная область данных на носителе информации, используемая
Файл, формат файла
Файл — именованная область данных на носителе информации, используемая
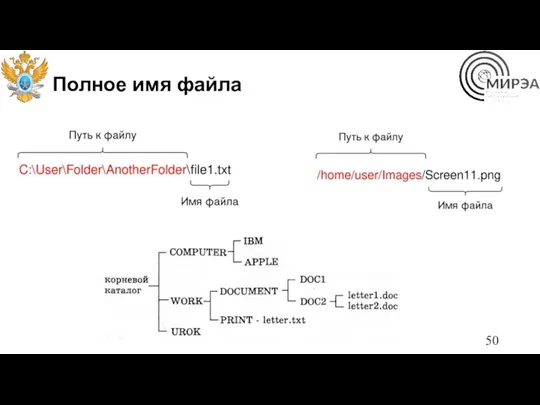
Полное имя файла
Полное имя файла

Дополнительные атрибуты файла
Расширение имени файла: позволяет системе определить, каким приложением следует
Дополнительные атрибуты файла
Расширение имени файла: позволяет системе определить, каким приложением следует

Права доступа в Linux
Права доступа в Linux
Операции с файлами
Открытие файла – возможность обращения к файлу для последующих
Операции с файлами
Открытие файла – возможность обращения к файлу для последующих

Размер файла
Размер файла - это показатель того, сколько данных содержит компьютерный
Размер файла
Размер файла - это показатель того, сколько данных содержит компьютерный

Типы файлов
По способу организации файлы делятся на файлы с произвольным доступом
Типы файлов
По способу организации файлы делятся на файлы с произвольным доступом
 Автоматизоване робоче місце інспектора з охорони праці
Автоматизоване робоче місце інспектора з охорони праці Введение в язык C#. Лекция 3-4
Введение в язык C#. Лекция 3-4 Системы управления базами данных (СУБД) Access
Системы управления базами данных (СУБД) Access Технология мультимедиа. Задания
Технология мультимедиа. Задания Программирование в Scratch. Игра Кот – обжора
Программирование в Scratch. Игра Кот – обжора Использование информационно-коммуникационных технологий на уроках русского языка н литературы. Курсовая работа
Использование информационно-коммуникационных технологий на уроках русского языка н литературы. Курсовая работа Введение. Сигналы. Классификация сигналов. Лекция 1
Введение. Сигналы. Классификация сигналов. Лекция 1 Сучасні веб-технології
Сучасні веб-технології Компьютерлік желі дегеніміз ресурстарды. Дискі, файл, принтер, коммуникациялық құрылғылар
Компьютерлік желі дегеніміз ресурстарды. Дискі, файл, принтер, коммуникациялық құрылғылар Методи та системи паралельного програмування
Методи та системи паралельного програмування Технические средства компьютерной графики
Технические средства компьютерной графики Обзор и классификация систем подвижной радиосвязи
Обзор и классификация систем подвижной радиосвязи Понятие как форма мышления
Понятие как форма мышления Понятие ресурса ОС
Понятие ресурса ОС Использование компьютера в различных отраслях
Использование компьютера в различных отраслях Введение в конфигурирование в системе 1С:Предприятие 8. Основные объекты
Введение в конфигурирование в системе 1С:Предприятие 8. Основные объекты Измерение информации
Измерение информации Безопасность будущего (кибербезопасность)
Безопасность будущего (кибербезопасность) Алгоритмизация и программирование. Решение задач на компьютере
Алгоритмизация и программирование. Решение задач на компьютере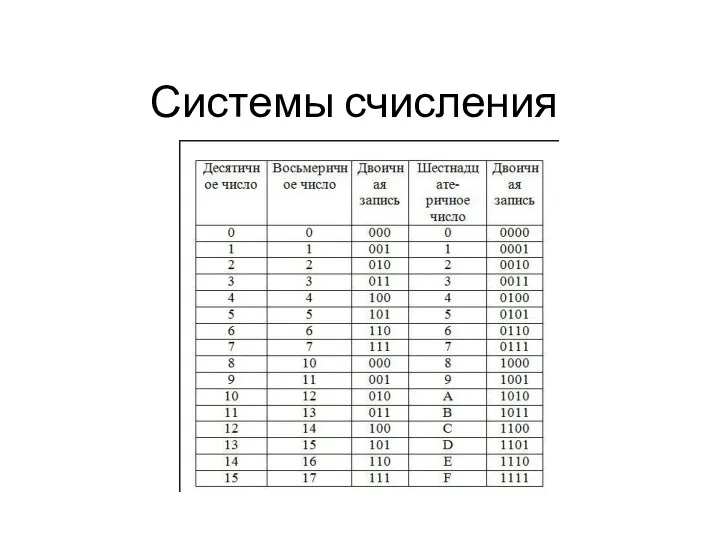 Системы счисления
Системы счисления Измерение информации
Измерение информации Материал к курсу лекций Matlab
Материал к курсу лекций Matlab Netiquette is the code of the user’s behaviour
Netiquette is the code of the user’s behaviour Использование пиксельных изображений в векторной графике и особенности работы с коллажами в Corel Draw
Использование пиксельных изображений в векторной графике и особенности работы с коллажами в Corel Draw Абсолютные, относительные и смешанные ссылки в электронных таблицах
Абсолютные, относительные и смешанные ссылки в электронных таблицах Организация ветвления. Циклы
Организация ветвления. Циклы Алгоритмы обработки массивов
Алгоритмы обработки массивов Компьютерные вирусы. Обзор и классификация компьютерных вирусов. Средства защиты от компьютерных вирусов
Компьютерные вирусы. Обзор и классификация компьютерных вирусов. Средства защиты от компьютерных вирусов