- Введение в ИТ

Содержание
- 2. Course content
- 3. 1.3. Quality assessment
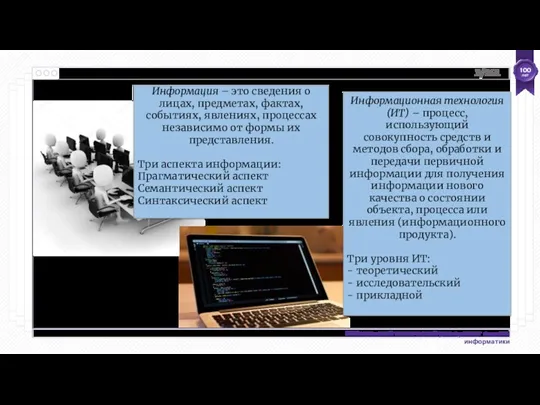
- 6. Пять базовых элементов компьютера, согласно Джон фон Неймана: - арифметико-логическое устройство (арифметические и логические операции над
- 7. Программное обеспечение (ПО) – организованная совокупность обрабатывающих программ и обрабатываемых данных Общее ПО – предназначено для
- 8. Системы программирования Системы программирования предназначены для автоматизации процесса написания программ. В их состав входит язык программирования
- 9. Вычислительные комплексы и сети Обработка информации при помощи ЭВМ развивается по двум направлениям: - с использованием
- 11. 1. Пример Сжатие без потерь Может восстановить всю исходную информацию из сжатых данных Сжатие с потерями
- 12. 1.1. Modern video lossy compression methods MPEG1 H.261 ... ... H.265 MPEG4/H.264 NZ Freeview TV H.266
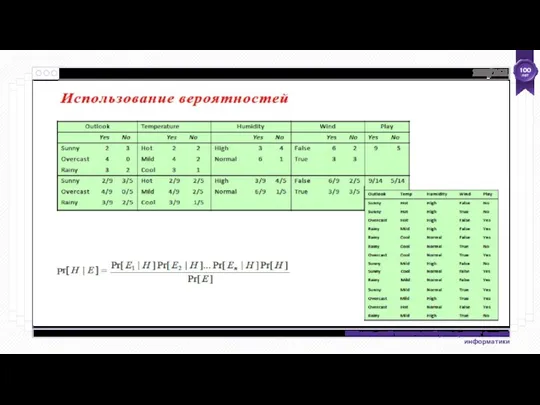
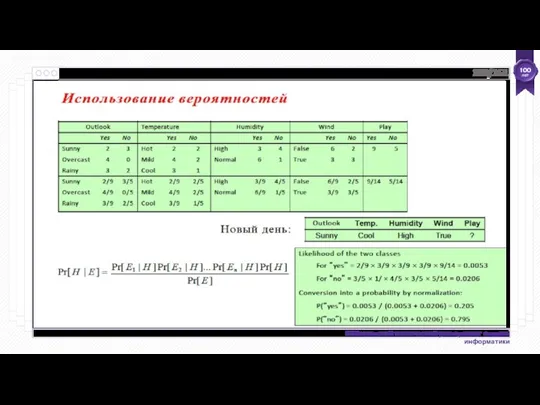
- 13. 1.2. Quality assessment Оценка качества - это характеристика обработанного видео по сравнению с оригиналом.
- 14. 1.3. The current models used by quality assessment Peak signal-to-noise ratio (PSNR) Structural similarity image metric
- 15. 1.4. The current models used by quality assessment Comparison of image fidelity measures for “Einstein” image
- 16. 1.5. Возможные решения Создание новых алгоритмов качества, использующих языки программирования Создание новых баз субъективного качества, использующих
- 17. Опыт в области фактического анализа данных Weka Интеллектуальный анализ данных с помощью Weka Объяснение принципов популярных
- 18. Интеллектуальный анализ данных - это переход от необработанных данных к информации, которая может использоваться для предсказаний,
- 19. Идеальная ситуация 1: У нас много исторических данных 2: у нас есть данные о текущей ситуации
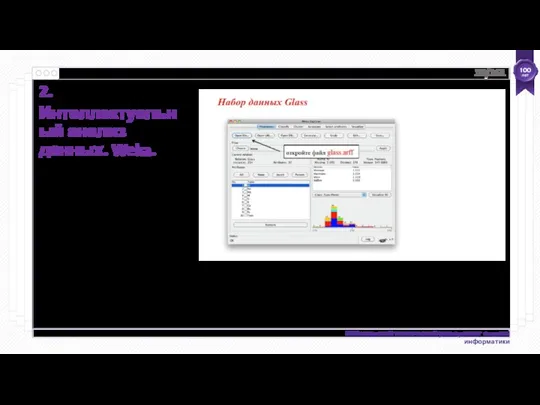
- 20. RQ: «Что такое Weka?» ● Птичка? ● Среда для анализа знаний? 2. Интеллектуальный анализ данных. Weka.
- 21. Установка Weka: предварительный просмотр http://www.cs.waikato.ac.nz/ml/weka. Нажмите кнопку Загрузить и установить Выберите, подходящую версию для вашего компьютера;
- 22. 2. Интеллектуальный анализ данных. Weka.
- 23. 2. Интеллектуальный анализ данных. Weka.
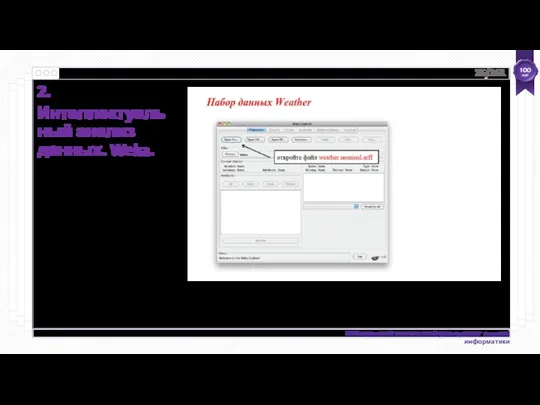
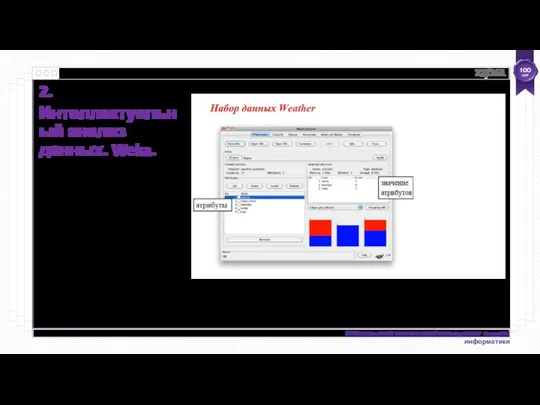
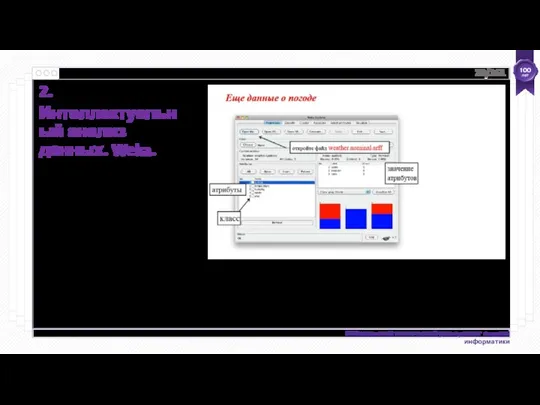
- 24. Интеллектуальный анализ данных с помощью Weka Набор данных - это набор экземпляров. Экземпляр - это единственный
- 25. 2. Интеллектуальный анализ данных. Weka.
- 26. 2. Интеллектуальный анализ данных. Weka.
- 27. 2. Интеллектуальный анализ данных. Weka.
- 28. 2. Интеллектуальный анализ данных. Weka.
- 29. 2. Интеллектуальный анализ данных. Weka.
- 30. 2. Интеллектуальный анализ данных. Weka.
- 31. 2. Интеллектуальный анализ данных. Weka.
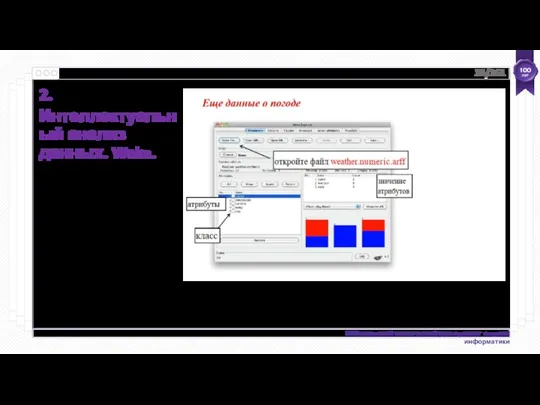
- 32. Интеллектуальный анализ данных с помощью Weka @relation weather @attribute outlook {sunny, overcast, rainy} @attribute temperature numeric
- 33. Интеллектуальный анализ данных с помощью Weka Общее правило экспериментального дизайна - контролировать любые факторы, которые в
- 34. 1. Практикум В этом тесте используется набор данных contact-lenses.arff , который был помещен в папку данных
- 35. В сфере электроснабжения важно как можно раньше определить будущий спрос на электроэнергию. Если можно будет сделать
- 36. Какой из атрибутов, взятый сам по себе, хуже всего показывает класс? Имеет ли класс Iris-virginica склонность
- 37. Создание набора данных. Weka. Создать набор данных формата ARFF. Набор данных должен содержать минимум 3 атрибута.
- 38. 2. Интеллектуальный анализ данных. Weka.
- 39. 2. Интеллектуальный анализ данных. Weka.
- 40. 2. Интеллектуальный анализ данных. Weka.
- 41. 2. Интеллектуальный анализ данных. Weka.
- 42. 2. Интеллектуальный анализ данных. Weka.
- 43. Сбор данных для интеллектуального анализа Идеальный Датасет – это очищенная выборка без ошибок, выбросов и пропущенных
- 44. Использование готовых датасетов. Kaggle - более 50 000 общедоступных наборов данных 3 легальных способа сбора чужих
- 45. СБОР ДАННЫХ НА ПРИМЕРЕ СБОРА СУБЪЕКТИВНЫХ ОЦЕНОК. Базы данных видео со сбором субъективных оценок составляют важную
- 46. Субъективные тесты Сборы субъективных оценок на сегодняшней момент. Методология двойной или одинарной непрерывной шкалы качества стимулов
- 47. Субъективные тесты Основные рекомендации по сбору субъективных оценок: Лабораторная среда Стимулы Участники
- 48. Откройте набор данных Glass.arff . Используйте матрицу неточностей, чтобы определить, сколько экземпляров headlamps было ошибочно классифицировано
- 49. 4. Практикум Найти последний документ по Методики субъективной оценки качества телевизионных изображений. Написать название первым пунктом.
- 50. 2. Лабораторная работа По полученной базе данных определить и выписать 4 пунктом: - метод сбора информации
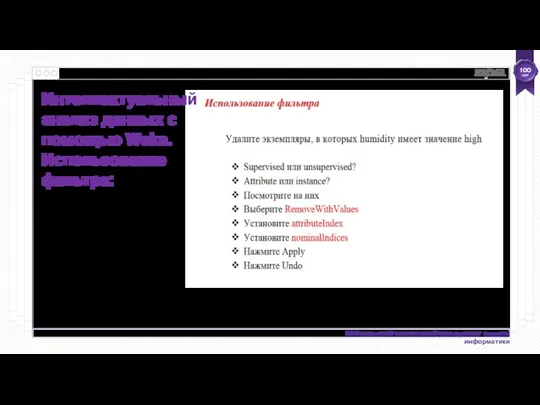
- 51. Интеллектуальный анализ данных с помощью Weka. Использование фильтра:
- 52. Интеллектуальный анализ данных с помощью Weka. Использование фильтра:
- 53. Интеллектуальный анализ данных с помощью Weka. Использование фильтра:
- 54. Интеллектуальный анализ данных с помощью Weka. Использование фильтра:
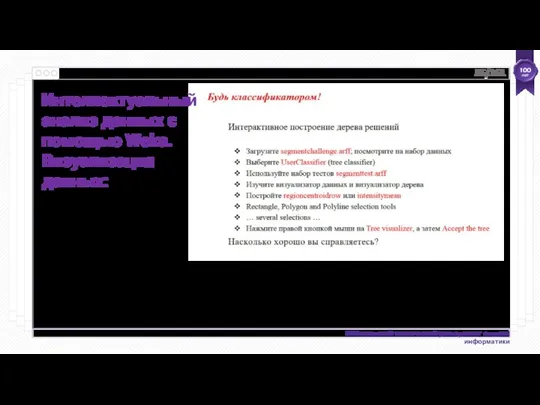
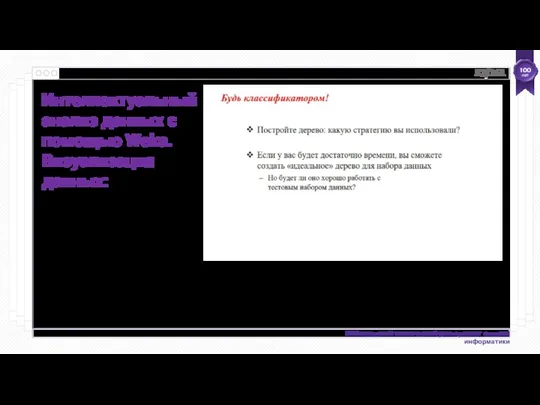
- 55. Интеллектуальный анализ данных с помощью Weka. Визуализация данных: Использование панели Visualize Откройте iris.arff Вызовите панель «Визуализация»
- 56. Интеллектуальный анализ данных с помощью Weka. Визуализация данных:
- 57. Интеллектуальный анализ данных с помощью Weka. Визуализация данных:
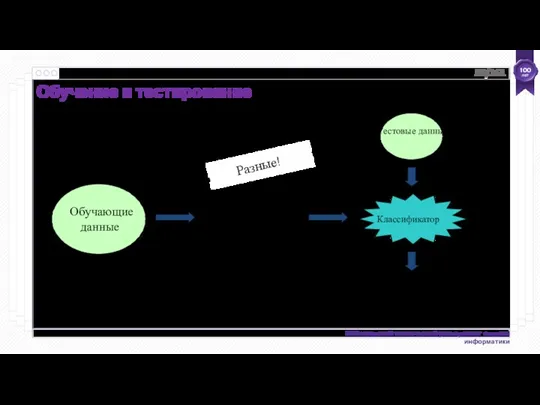
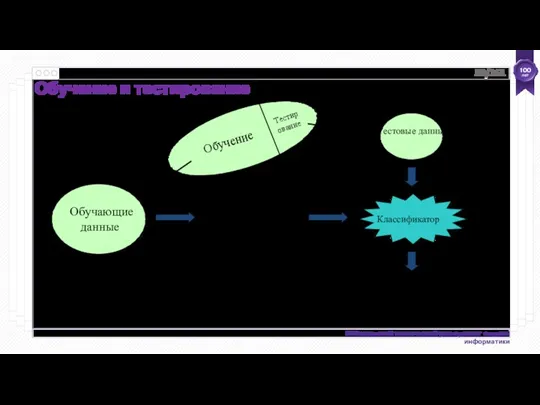
- 58. Обучающие данные Тестовые данные Классификатор Результаты оценки Обучение и тестирование Алгоритм машинного обучения Разные! Применяем классификатор
- 59. Основное предположение: как обучающие, так и тестовые наборы создаются путем независимой выборки из бесконечной совокупности. Обучение
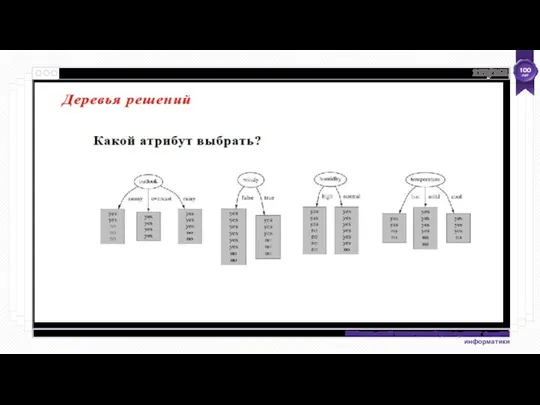
- 60. Используйте J48 для анализа набора данных сегмента Откройте файл segment-challenge.arff Выберите дерево решений J48 (trees>J48) Выберите
- 61. Основное предположение: Как обучающие, так и тестовые наборы создаются путем независимой выборки из бесконечной совокупности Всего
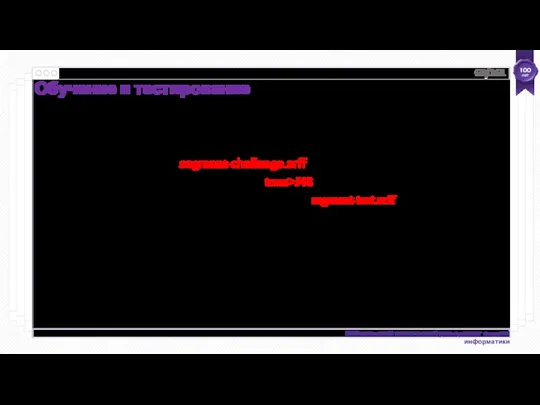
- 62. Повторное обучение и тестирование С segment-challenge.arff … и J48 (trees>J48) Установите процентное разделение на 90% З
- 63. Оцените J48 на наборе данных segment-challenge Среднее значение выборки Дисперсия Стандартное отклонение Повторное обучение и тестирование
- 64. Основное предположение: обучающие и тестовые наборы, независимо отобранные из бесконечной совокупности Ожидайте незначительных изменений в результатах…
- 65. 5. Практическая работа Откройте набор данных anneal - Сколько атрибутов имеет набор данных anneal ? -
- 66. 5. Практическая работа - Отмените действие фильтра Нормализовать и откройте его панель конфигурации. Установите шкалу на
- 67. 6. Практическая работа Поиск неверно классифицированных экземпляров Откройте набор данных iris.arff - Выберите древовидный классификатор J48
- 68. 7. Практическая работа Откройте набор данных segment-challenge.arff Выберите классификатор J48 (параметры по умолчанию), выберите разделение в
- 69. Основываясь на вышеупомянутых экспериментах, какова ваша наилучшая оценка истинной точности J48 в наборе данных проблем сегмента
- 70. Откройте набор данных diabetes.arff Выберите процентное разделение в качестве параметра теста и установите процентное соотношение для
- 71. Откройте свой набор данных. Выберите древовидный классификатор J48 и запустите его (с параметрами по умолчанию). Сколько
- 72. Какая максимальная точность, которую можно достичь с помощью UserClassifier ? Указать число и объяснить почему. Объясните
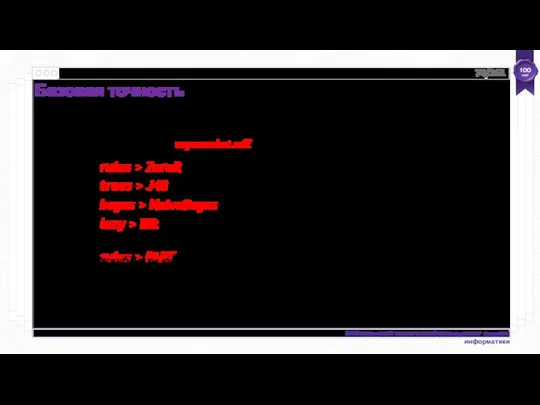
- 73. Базовая точность 76% 77% 73% 74% trees > J48 bayes > NaiveBayes lazy > IBk rules
- 74. Иногда простые методы лучше! Откройте файл supermarket.arff и слепо примените Атрибуты не являются информативными Не просто
- 75. Подумайте, могут ли различия быть значительными Всегда старайтесь придерживаться простой базы, например rules > ZeroR Посмотрите
- 76. Можем ли мы улучшить ситуацию с повторной задержкой? (т.е. уменьшить дисперсию) Перекрестная проверка Стратифицированная перекрестная проверка
- 77. Повторная задержка (оставляем 10% для тестирования, повторяем 10 раз) Один набор данных Обучение Тестирование
- 78. Перекрестная проверка 10-кратная перекрестная проверка Разделите набор данных на 10 частей Каждую часть по очереди оставляйте
- 79. Deploy! 90% данных Алгоритм машинного обучения Классификатор Результаты оценки После перекрестной проверки Weka выводит дополнительную модель,
- 80. Перекрестная проверка лучше, чем повторная задержка Стратифицированная еще лучше При 10-кратной перекрестной проверке Weka 11 раз
- 81. Результаты перекрестной проверки Базовая точность (rules > ZeroR): trees > J48 10-кратная перекрестная проверка … с
- 82. Sample mean Variance Standard deviation Σ x i n Σ (xi – x )2 x =
- 83. Почему 10-кратная? Если 20-кратная: 75.1% Перекрестная проверка действительно лучше, чем повторная задержка Это уменьшает дисперсию оценки
- 84. Простота прежде всего! Простые алгоритмы часто работают очень хорошо! Существует много видов простой структуры, например: Один
- 85. OneR: Один атрибут выполняет всю работу 1-уровневое “дерево решений” т.е. правила, которые проверяют один конкретный атрибут
- 86. Для каждого значения атрибута, создайте правило следующим образом: подсчитайте, как часто появляется каждый класс найдите наиболее
- 87. * указывает на ничью Простота прежде всего!
- 88. Используйте OneR Откройте weather.nominal.arff Выберите OneR (rules>OneR) Посмотрите на правило (примечание: Weka выполняет OneR 11 раз)
- 89. OneR: Один атрибут выполняет всю работу Невероятно простой метод, описанный в 1993 году “Очень простые правила
- 90. Iris.arff набор данных состоит из трех классов (Iris-setosa, Iris-лишай, Iris-virginica), с 50 экземпляров каждого. Какая точность
- 91. Откройте набор данных segment-challenge.arff , перейдите на вкладку Classify. Выберите классификатор J48 (параметры по умолчанию), выберите
- 92. Откройте набор данных iris.arff и перейдите на вкладку Classify . Выполните 10-кратную перекрестную проверку с помощью
- 93. Лабораторная работа 4 Откройте набор данных iris.arff Оцените точность базового метода ZeroR, используя перекрестную проверку с
- 94. Предположим, что точность ZeroR для набора данных iris.arff оценивалась с использованием перекрестной проверки с 5, 10
- 95. Любой метод машинного обучения может “переобучать” обучающие данные … … путем создания классификатора, который слишком точно
- 96. У OneR есть параметр, который ограничивает сложность таких правил Числовые атрибуты Переобучение
- 97. Поэкспериментируйте с OneR Откройте файл weather.numeric.arff Выберите OneR (rules>OneR) Результирующее правило основано на атрибуте outlook, так
- 98. Поэкспериментируйте с набором данных diabetes Откройте файл diabetes.arff Выберите ZeroR (rules>ZeroR) Используйте перекрестную проверку: 65.1% Выберите
- 99. Переобучение — это общее явление, от которого страдают все методы машинного обучения Это одна из причин,
- 103. /161
- 104. /161
- 105. /161
- 106. /161
- 107. Откройте weather.numeric.arff набор данных и проверьте данные с помощью Edit кнопки Weka в Preprocess панели. Какая
- 108. Рассмотрите сложность правила, которое генерирует OneR, измеряемое его размером - количеством тестов, которые оно включает. Будет
- 109. Откройте набор данных vote.arff и выберите классификатор NaiveBayes с параметрами по умолчанию и 10-кратной перекрестной проверкой
- 110. Вы, вероятно, думаете, что если бы вы продолжали копировать атрибут «расходы на образование» и оценивали его
- 111. Лабораторная работа 5 Откройте набор данных breast-cancer.arff в текстовом редакторе и прочтите комментарии в начале, чтобы
- 112. /161
- 113. /161
- 114. /161
- 115. /161
- 116. /161
- 117. /161
- 118. /161
- 119. /161
- 120. /161
- 121. /161
- 122. /161
- 123. /161
- 124. Это задание посвящено деревьям решений и алгоритму J48. Мы уже использовали J48 много раз, поэтому вместо
- 125. Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48. Одно из значений
- 126. Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48. Одним из простых
- 127. /161
- 128. /161
- 129. /161
- 130. /161
- 131. /161
- 132. /161
- 133. /161
- 134. /161
- 135. /161
- 136. Откройте набор данных breast-cancer.arff и перейдите на вкладку Классифицировать. Выберите классификатор IBk. Какая его точность, оцениваемая
- 137. Подтвердите свой ответ, запустив IBk со значением по умолчанию 1 для KNN, используя следующие начальные числа
- 138. Давайте искусственно добавим шум в набор данных, определим наилучшее значение для KNN, используя только что обнаруженный
- 139. Какое количество соседей является наилучшим (по определению Weka), когда количество добавленного шума составляет 0%, 10%, 20%
- 140. Выберите классификатор IBk с параметрами по умолчанию и запустите визуализацию границ. Вы заметите небольшую слабую область
- 141. Откройте набор данных glass.arff , перейдите на вкладку Classify и используйте процентное разделение со значением по
- 142. С помощью перекрестной проверки Weka создает модель для каждого разделения. Какой из них используется для классификации
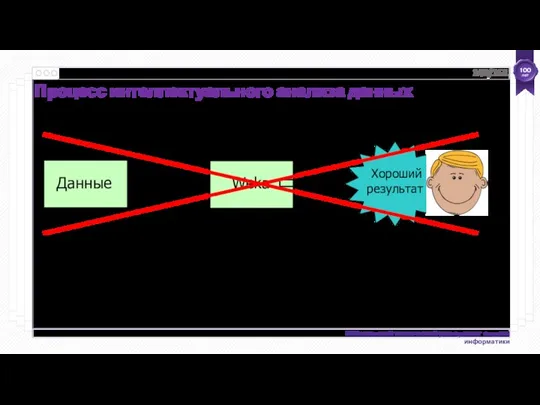
- 143. Процесс интеллектуального анализа данных Weka Данные Хороший результат /161
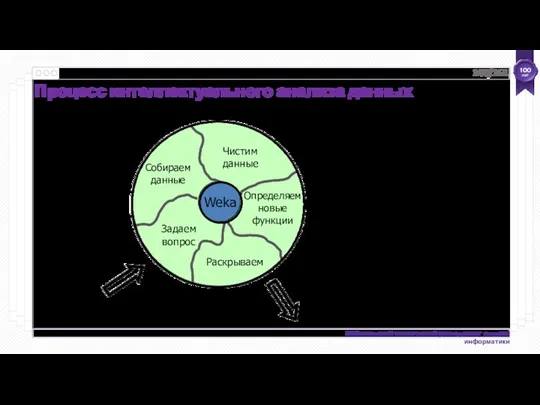
- 144. Weka Раскрываем Задаем вопрос Чистим данные Определяем новые функции Собираем данные Процесс интеллектуального анализа данных /161
- 145. Задайте вопрос Что вы хотите узнать? “Расскажите мне что-нибудь интересное о данных” этого недостаточно! Соберите данные
- 146. (Выбранные) фильтры для разработки функций AddExpression (MathExpression) Применение математического выражения к существующим атрибутам для создания новых
- 147. Weka лишь малая часть (к сожалению) … … и это легкая часть “Пусть все ваши проблемы
- 148. Подводные камни и ловушки Будьте осторожны Очень легко просчитаться в интеллектуальном анализе данных – сознательно или
- 149. Отсутствующие значения “Отсутствующие” значит … Неизвестные? Незаписанные? Неуместные? Вы должны: ?1. Пропустить случаи, когда значение атрибута
- 150. OneR и J48 работают с пропущенными значениями по разному Запустите weather-nominal.arff OneR получает 43%, J48 получает
- 151. Бесплатных обедов не бывает Задача 2-го класса со 100 бинарными атрибутами Скажем, вы знаете миллион экземпляров
- 152. Будьте осторожны Переобучение очень многогранно Отсутствующие значения – разные предположения Нет «универсального» лучшего алгоритма обучения Интеллектуальный
- 153. Интеллектуальный анализ данных и этика Законы о конфиденциальности информации (в Европе, но не в США) .
- 154. Анонимизация сложнее, чем вы думаете Когда в середине 1990-х годов Массачусетс опубликовал медицинские данные, в которых
- 155. Цель интеллектуального анализа данных состоит в том, чтобы различать … кто получает кредит кто получает спецпредложение
- 156. Корреляция не означает причинно-следственную связь По мере роста продаж мороженого растет и количество утонувших. Следовательно, употребление
- 157. Конфиденциальность личной информации Анонимизация сложнее, чем вы думаете Повторная идентификация по якобы анонимным данным Интеллектуальный анализ
- 158. Итоги курса Интеллектуальный анализ данных - это не волшебство Это огромное количество различных методов и техник
- 159. Что мы упустили? Фильтрующие классификаторы Фильтрация обучающих данных, но не тестовых во время перекрестной проверки. Оценка
- 160. Данные Зафиксированные факты Информация Шаблоны или предположения, лежащие в их основе Знания Накопление вашего набора предположений
- 161. С помощью экспериментальной установки « Исследование зрительной системы человека для определения оптимального субъективного качества в потоковом
- 163. Скачать презентацию

Course content
Course content
1.3. Quality assessment
1.3. Quality assessment


Пять базовых элементов компьютера, согласно Джон фон Неймана:
- арифметико-логическое устройство (арифметические
- арифметико-логическое устройство (арифметические

Программное обеспечение (ПО) – организованная совокупность обрабатывающих программ и обрабатываемых данных
Общее ПО –
Программное обеспечение (ПО) – организованная совокупность обрабатывающих программ и обрабатываемых данных
Общее ПО –
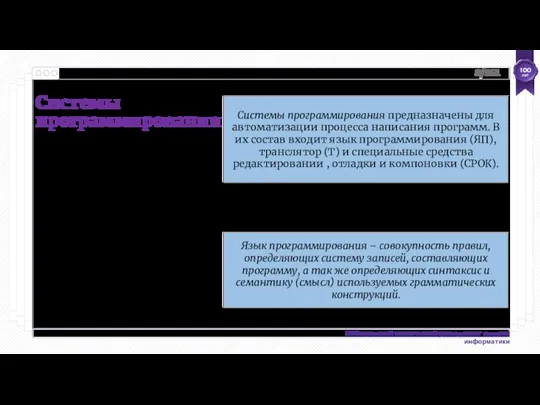
Системы программирования
Системы программирования предназначены для автоматизации процесса написания программ. В их состав
Системы программирования
Системы программирования предназначены для автоматизации процесса написания программ. В их состав

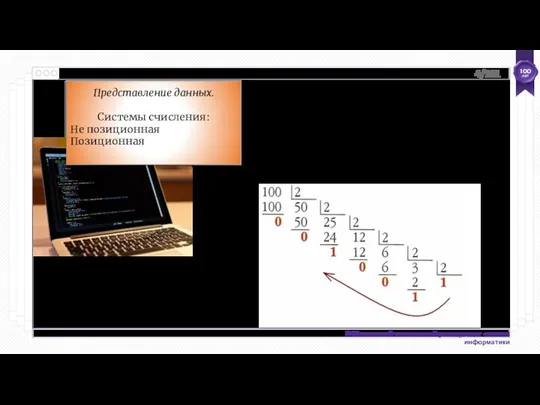
Вычислительные комплексы и сети
Обработка информации при помощи ЭВМ развивается по двум
Вычислительные комплексы и сети
Обработка информации при помощи ЭВМ развивается по двум


1. Пример
Сжатие без потерь
Может восстановить всю исходную информацию из сжатых
1. Пример
Сжатие без потерь
Может восстановить всю исходную информацию из сжатых
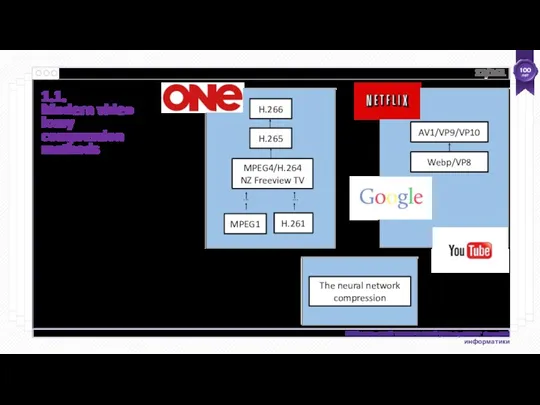
1.1.
Modern video lossy compression methods
MPEG1
H.261
... ...
H.265
MPEG4/H.264
NZ Freeview TV
H.266
Webp/VP8
AV1/VP9/VP10
The neural network
1.1.
Modern video lossy compression methods
MPEG1
H.261
... ...
H.265
MPEG4/H.264
NZ Freeview TV
H.266
Webp/VP8
AV1/VP9/VP10
The neural network
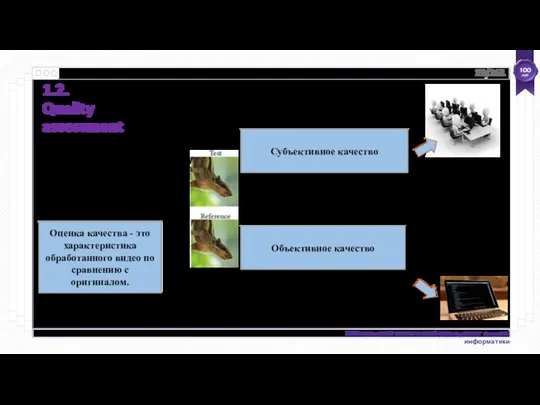
1.2.
Quality assessment
Оценка качества - это характеристика обработанного видео по сравнению
1.2.
Quality assessment
Оценка качества - это характеристика обработанного видео по сравнению

1.3.
The current models used by quality assessment
Peak signal-to-noise ratio (PSNR)
Structural
1.3.
The current models used by quality assessment
Peak signal-to-noise ratio (PSNR)
Structural

1.4.
The current models used by quality assessment
Comparison of image
1.4.
The current models used by quality assessment
Comparison of image

1.5. Возможные решения
Создание новых алгоритмов качества, использующих языки программирования
Создание новых
1.5. Возможные решения
Создание новых алгоритмов качества, использующих языки программирования
Создание новых
Опыт в области фактического анализа данных
Weka
Интеллектуальный анализ данных с помощью Weka
Опыт в области фактического анализа данных
Weka
Интеллектуальный анализ данных с помощью Weka

Интеллектуальный анализ данных - это переход от необработанных данных к информации,

Идеальная ситуация
1: У нас много исторических данных
2: у нас есть данные
Идеальная ситуация
1: У нас много исторических данных
2: у нас есть данные

RQ: «Что такое Weka?»
● Птичка?
● Среда для анализа знаний?
2.
RQ: «Что такое Weka?»
● Птичка?
● Среда для анализа знаний?
2.

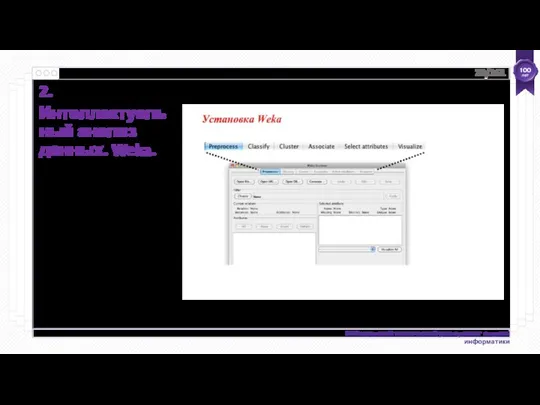
Установка Weka: предварительный просмотр
http://www.cs.waikato.ac.nz/ml/weka.
Нажмите кнопку Загрузить и установить
Выберите, подходящую версию для
http://www.cs.waikato.ac.nz/ml/weka.
Нажмите кнопку Загрузить и установить
Выберите, подходящую версию для

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

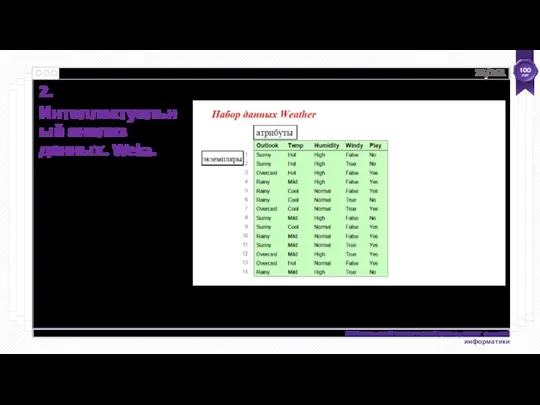
Интеллектуальный анализ данных с помощью Weka
Набор данных - это набор
Интеллектуальный анализ данных с помощью Weka
Набор данных - это набор
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

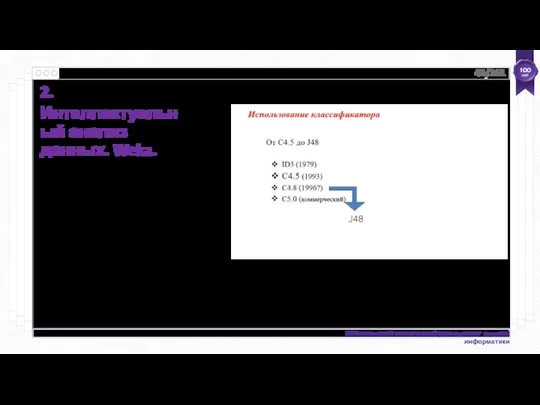
Интеллектуальный анализ данных с помощью Weka
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute
Интеллектуальный анализ данных с помощью Weka
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute

Интеллектуальный анализ данных с помощью Weka
Общее правило экспериментального дизайна - контролировать
Интеллектуальный анализ данных с помощью Weka
Общее правило экспериментального дизайна - контролировать

1. Практикум
В этом тесте используется набор данных contact-lenses.arff , который был помещен в папку данных (в вашей установке
В этом тесте используется набор данных contact-lenses.arff , который был помещен в папку данных (в вашей установке
В сфере электроснабжения важно как можно раньше определить будущий спрос на
В сфере электроснабжения важно как можно раньше определить будущий спрос на
Какой из атрибутов, взятый сам по себе, хуже всего показывает класс?
Какой из атрибутов, взятый сам по себе, хуже всего показывает класс?
Создание набора данных. Weka.
Создать набор данных формата ARFF.
Набор данных должен
Создать набор данных формата ARFF.
Набор данных должен
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

2.
Интеллектуальный анализ данных. Weka.
2.
Интеллектуальный анализ данных. Weka.

Сбор данных для интеллектуального анализа
Идеальный Датасет – это очищенная выборка
Сбор данных для интеллектуального анализа
Идеальный Датасет – это очищенная выборка

Использование готовых датасетов.
Kaggle - более 50 000 общедоступных наборов данных
3
Использование готовых датасетов.
Kaggle - более 50 000 общедоступных наборов данных
3
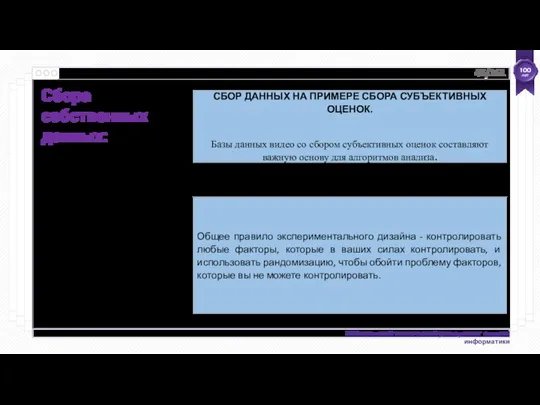
СБОР ДАННЫХ НА ПРИМЕРЕ СБОРА СУБЪЕКТИВНЫХ ОЦЕНОК.
Базы данных видео со сбором
СБОР ДАННЫХ НА ПРИМЕРЕ СБОРА СУБЪЕКТИВНЫХ ОЦЕНОК.
Базы данных видео со сбором

Субъективные тесты
Сборы субъективных оценок на сегодняшней момент.
Методология двойной или одинарной непрерывной шкалы
Субъективные тесты
Сборы субъективных оценок на сегодняшней момент.
Методология двойной или одинарной непрерывной шкалы

Субъективные тесты
Основные рекомендации по сбору субъективных оценок:
Лабораторная среда
Стимулы
Участники
Субъективные тесты
Основные рекомендации по сбору субъективных оценок:
Лабораторная среда
Стимулы
Участники
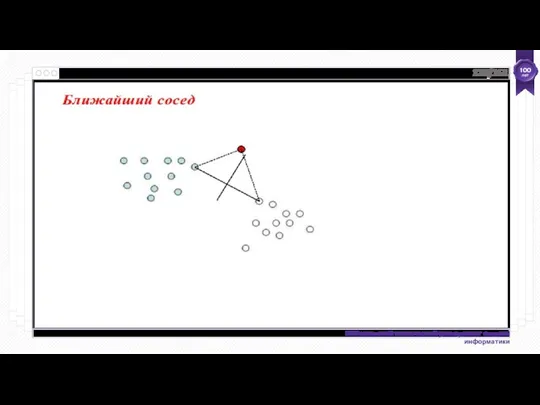
Откройте набор данных Glass.arff . Используйте матрицу неточностей, чтобы определить, сколько экземпляров headlamps было ошибочно
Откройте набор данных Glass.arff . Используйте матрицу неточностей, чтобы определить, сколько экземпляров headlamps было ошибочно
4.
Практикум
Найти последний документ по Методики субъективной оценки качества телевизионных изображений.
4.
Практикум
Найти последний документ по Методики субъективной оценки качества телевизионных изображений.

2.
Лабораторная работа
По полученной базе данных определить и выписать 4 пунктом:
2.
Лабораторная работа
По полученной базе данных определить и выписать 4 пунктом:

Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:
Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:
Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:
Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:

Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:
Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:

Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:
Интеллектуальный анализ данных с помощью Weka.
Использование фильтра:

Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Использование панели Visualize
Откройте iris.arff
Вызовите панель
Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Использование панели Visualize
Откройте iris.arff
Вызовите панель
Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Интеллектуальный анализ данных с помощью Weka.
Визуализация данных:
Обучающие данные
Тестовые данные
Классификатор
Результаты
оценки
Обучение и тестирование
Алгоритм машинного обучения
Разные!
Применяем классификатор на реальных данных
Обучающие данные
Тестовые данные
Классификатор
Результаты
оценки
Обучение и тестирование
Алгоритм машинного обучения
Разные!
Применяем классификатор на реальных данных
Основное предположение: как обучающие, так и тестовые наборы создаются путем независимой
Основное предположение: как обучающие, так и тестовые наборы создаются путем независимой
Используйте J48 для анализа набора данных сегмента
Откройте файл segment-challenge.arff
Выберите дерево решений
Используйте J48 для анализа набора данных сегмента
Откройте файл segment-challenge.arff
Выберите дерево решений
Основное предположение:
Как обучающие, так и тестовые наборы создаются путем независимой выборки
Основное предположение:
Как обучающие, так и тестовые наборы создаются путем независимой выборки
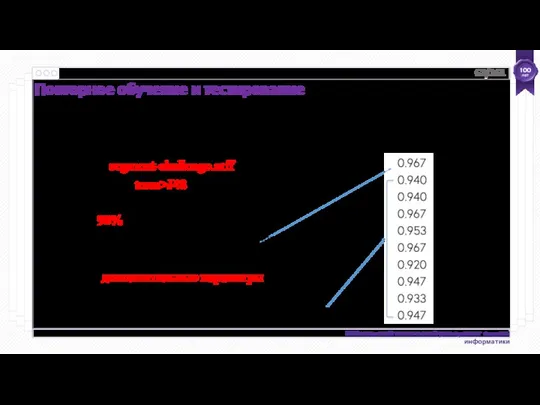
Повторное обучение и тестирование
С segment-challenge.arff …
и J48 (trees>J48)
Установите процентное разделение на
Повторное обучение и тестирование
С segment-challenge.arff …
и J48 (trees>J48)
Установите процентное разделение на

Оцените J48 на наборе данных segment-challenge
Среднее значение выборки
Дисперсия
Стандартное отклонение
Повторное обучение и
Оцените J48 на наборе данных segment-challenge
Среднее значение выборки
Дисперсия
Стандартное отклонение
Повторное обучение и

Основное предположение:
обучающие и тестовые наборы, независимо отобранные из бесконечной совокупности
Ожидайте незначительных
Основное предположение:
обучающие и тестовые наборы, независимо отобранные из бесконечной совокупности
Ожидайте незначительных

5.
Практическая работа
Откройте набор данных anneal
- Сколько атрибутов имеет набор данных anneal ?
-
5.
Практическая работа
Откройте набор данных anneal
- Сколько атрибутов имеет набор данных anneal ?
-

5.
Практическая работа
- Отмените действие фильтра Нормализовать и откройте его панель конфигурации. Установите шкалу на
5.
Практическая работа
- Отмените действие фильтра Нормализовать и откройте его панель конфигурации. Установите шкалу на

6.
Практическая работа Поиск неверно классифицированных экземпляров
Откройте набор данных iris.arff
- Выберите древовидный классификатор J48 и запустите его
6.
Практическая работа Поиск неверно классифицированных экземпляров
Откройте набор данных iris.arff
- Выберите древовидный классификатор J48 и запустите его
7.
Практическая работа
Откройте набор данных segment-challenge.arff
Выберите классификатор J48 (параметры по умолчанию), выберите разделение в процентах
Практическая работа
Откройте набор данных segment-challenge.arff
Выберите классификатор J48 (параметры по умолчанию), выберите разделение в процентах
Основываясь на вышеупомянутых экспериментах, какова ваша наилучшая оценка истинной точности J48
Основываясь на вышеупомянутых экспериментах, какова ваша наилучшая оценка истинной точности J48
Откройте набор данных diabetes.arff
Выберите процентное разделение в качестве параметра теста и установите процентное соотношение для обучения 80%. Сколько
Откройте набор данных diabetes.arff
Выберите процентное разделение в качестве параметра теста и установите процентное соотношение для обучения 80%. Сколько

Откройте свой набор данных.
Выберите древовидный классификатор J48 и запустите его (с параметрами по умолчанию). Сколько
Откройте свой набор данных.
Выберите древовидный классификатор J48 и запустите его (с параметрами по умолчанию). Сколько

Какая максимальная точность, которую можно достичь с помощью UserClassifier ? Указать число и
Какая максимальная точность, которую можно достичь с помощью UserClassifier ? Указать число и
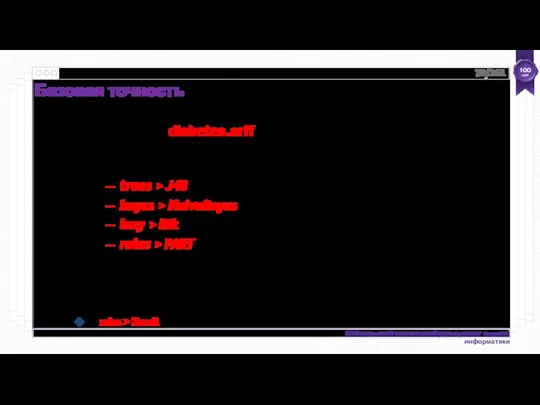
Базовая точность
76%
77%
73%
74%
trees > J48
bayes > NaiveBayes
lazy > IBk
rules > PART
(мы изучим
Базовая точность
76%
77%
73%
74%
trees > J48
bayes > NaiveBayes
lazy > IBk
rules > PART
(мы изучим
Иногда простые методы лучше!
Откройте файл supermarket.arff и слепо примените
Атрибуты не являются
Иногда простые методы лучше!
Откройте файл supermarket.arff и слепо примените
Атрибуты не являются
Подумайте, могут ли различия быть значительными
Всегда старайтесь придерживаться простой базы,
например rules
Подумайте, могут ли различия быть значительными
Всегда старайтесь придерживаться простой базы,
например rules
Можем ли мы улучшить ситуацию с повторной задержкой? (т.е. уменьшить дисперсию)
Перекрестная
Можем ли мы улучшить ситуацию с повторной задержкой? (т.е. уменьшить дисперсию)
Перекрестная

Повторная задержка
(оставляем 10% для тестирования, повторяем 10 раз)
Один набор данных
Обучение
Тестирование
Повторная задержка
(оставляем 10% для тестирования, повторяем 10 раз)
Один набор данных
Обучение
Тестирование
Перекрестная проверка
10-кратная перекрестная проверка
Разделите набор данных на 10 частей
Каждую часть по
Перекрестная проверка
10-кратная перекрестная проверка
Разделите набор данных на 10 частей
Каждую часть по
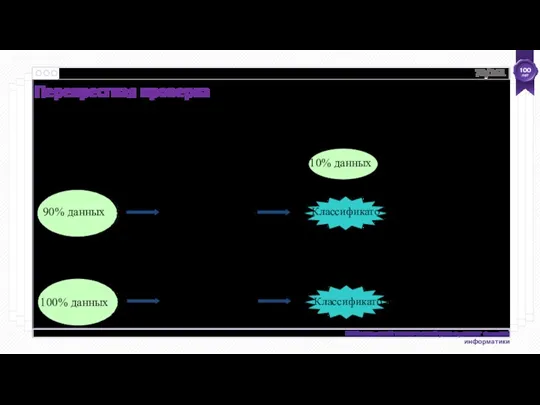
Deploy!
90% данных
Алгоритм машинного обучения
Классификатор
Результаты оценки
После перекрестной проверки Weka выводит дополнительную модель,
Deploy!
90% данных
Алгоритм машинного обучения
Классификатор
Результаты оценки
После перекрестной проверки Weka выводит дополнительную модель,
Перекрестная проверка лучше, чем повторная задержка
Стратифицированная еще лучше
При 10-кратной перекрестной проверке
Перекрестная проверка лучше, чем повторная задержка
Стратифицированная еще лучше
При 10-кратной перекрестной проверке

Результаты перекрестной проверки
Базовая точность (rules > ZeroR):
trees > J48
10-кратная перекрестная проверка
…
Результаты перекрестной проверки
Базовая точность (rules > ZeroR):
trees > J48
10-кратная перекрестная проверка
…
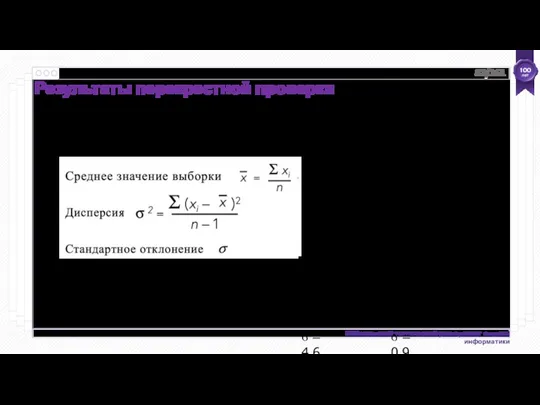
Sample mean
Variance
Standard deviation
Σ x
i
n
Σ (xi –
x )2
x =
n –
Sample mean
Variance
Standard deviation
Σ x
i
n
Σ (xi –
x )2
x =
n –

Почему 10-кратная? Если 20-кратная: 75.1%
Перекрестная проверка действительно лучше, чем повторная задержка
Это
Почему 10-кратная? Если 20-кратная: 75.1%
Перекрестная проверка действительно лучше, чем повторная задержка
Это

Простота прежде всего!
Простые алгоритмы часто работают очень хорошо!
Существует много видов простой
Простота прежде всего!
Простые алгоритмы часто работают очень хорошо!
Существует много видов простой

OneR: Один атрибут выполняет всю работу
1-уровневое “дерево решений”
т.е. правила, которые проверяют
OneR: Один атрибут выполняет всю работу
1-уровневое “дерево решений”
т.е. правила, которые проверяют

Для каждого значения атрибута, создайте правило следующим образом:
подсчитайте, как часто появляется
Для каждого значения атрибута, создайте правило следующим образом:
подсчитайте, как часто появляется
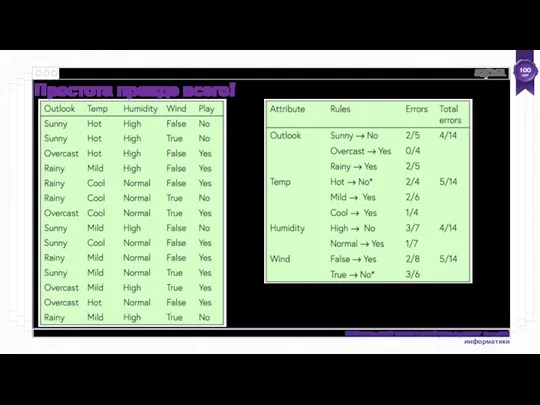
* указывает на ничью
Простота прежде всего!
* указывает на ничью
Простота прежде всего!

Используйте OneR
Откройте weather.nominal.arff
Выберите OneR (rules>OneR)
Посмотрите на правило (примечание: Weka выполняет OneR
Используйте OneR
Откройте weather.nominal.arff
Выберите OneR (rules>OneR)
Посмотрите на правило (примечание: Weka выполняет OneR

OneR: Один атрибут выполняет всю работу
Невероятно простой метод, описанный в 1993
OneR: Один атрибут выполняет всю работу
Невероятно простой метод, описанный в 1993
Iris.arff набор данных состоит из трех классов (Iris-setosa, Iris-лишай, Iris-virginica), с
Iris.arff набор данных состоит из трех классов (Iris-setosa, Iris-лишай, Iris-virginica), с
Откройте набор данных segment-challenge.arff , перейдите на вкладку Classify. Выберите классификатор
Откройте набор данных iris.arff и перейдите на вкладку Classify . Выполните
Откройте набор данных iris.arff и перейдите на вкладку Classify . Выполните
Лабораторная
работа 4
Откройте набор данных iris.arff
Оцените точность базового метода ZeroR, используя перекрестную
Лабораторная
работа 4
Откройте набор данных iris.arff
Оцените точность базового метода ZeroR, используя перекрестную
Предположим, что точность ZeroR для набора данных iris.arff оценивалась с использованием
Предположим, что точность ZeroR для набора данных iris.arff оценивалась с использованием
Любой метод машинного обучения может “переобучать” обучающие данные …
… путем создания
Любой метод машинного обучения может “переобучать” обучающие данные …
… путем создания
У OneR есть параметр, который ограничивает сложность таких правил
Числовые атрибуты
Переобучение
У OneR есть параметр, который ограничивает сложность таких правил
Числовые атрибуты
Переобучение
Поэкспериментируйте с OneR
Откройте файл weather.numeric.arff
Выберите OneR (rules>OneR)
Результирующее правило основано на атрибуте
Поэкспериментируйте с OneR
Откройте файл weather.numeric.arff
Выберите OneR (rules>OneR)
Результирующее правило основано на атрибуте
Поэкспериментируйте с набором данных diabetes
Откройте файл diabetes.arff
Выберите ZeroR (rules>ZeroR)
Используйте перекрестную проверку:
Поэкспериментируйте с набором данных diabetes
Откройте файл diabetes.arff
Выберите ZeroR (rules>ZeroR)
Используйте перекрестную проверку:

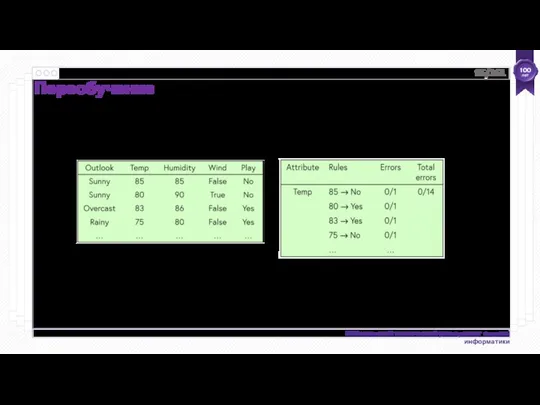
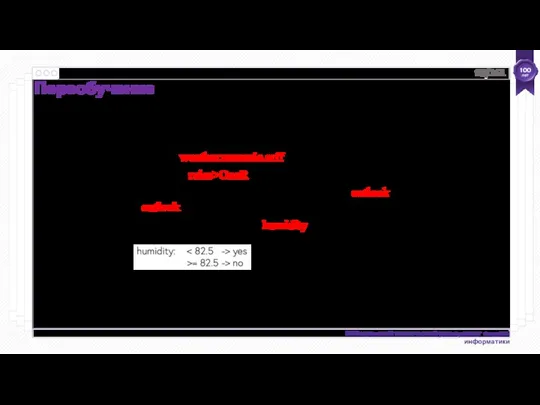
Переобучение — это общее явление, от которого страдают все методы машинного
Переобучение — это общее явление, от которого страдают все методы машинного


/161
/161

/161
/161

/161
/161

/161
/161
Откройте weather.numeric.arff набор данных и проверьте данные с помощью Edit кнопки
Откройте weather.numeric.arff набор данных и проверьте данные с помощью Edit кнопки
Рассмотрите сложность правила, которое генерирует OneR, измеряемое его размером - количеством
Рассмотрите сложность правила, которое генерирует OneR, измеряемое его размером - количеством
Откройте набор данных vote.arff и выберите классификатор NaiveBayes с параметрами по
Откройте набор данных vote.arff и выберите классификатор NaiveBayes с параметрами по
Вы, вероятно, думаете, что если бы вы продолжали копировать атрибут «расходы
Вы, вероятно, думаете, что если бы вы продолжали копировать атрибут «расходы

Лабораторная работа 5
Откройте набор данных breast-cancer.arff в текстовом редакторе и прочтите
Лабораторная работа 5
Откройте набор данных breast-cancer.arff в текстовом редакторе и прочтите

/161
/161
/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161
Это задание посвящено деревьям решений и алгоритму J48. Мы уже использовали J48
Это задание посвящено деревьям решений и алгоритму J48. Мы уже использовали J48
Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48.
Одно из
Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48.
Одно из

Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48.
Одним из
Откройте набор данных breast-cancer.arff в проводнике, перейдите на вкладку Classify и выберите J48.
Одним из

/161
/161
/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161

/161
/161
Откройте набор данных breast-cancer.arff и перейдите на вкладку Классифицировать. Выберите классификатор
Откройте набор данных breast-cancer.arff и перейдите на вкладку Классифицировать. Выберите классификатор
Подтвердите свой ответ, запустив IBk со значением по умолчанию 1 для
Подтвердите свой ответ, запустив IBk со значением по умолчанию 1 для
Давайте искусственно добавим шум в набор данных, определим наилучшее значение для
Давайте искусственно добавим шум в набор данных, определим наилучшее значение для
Какое количество соседей является наилучшим (по определению Weka), когда количество добавленного
Какое количество соседей является наилучшим (по определению Weka), когда количество добавленного
Выберите классификатор IBk с параметрами по умолчанию и запустите визуализацию границ.
Выберите классификатор IBk с параметрами по умолчанию и запустите визуализацию границ.
Откройте набор данных glass.arff , перейдите на вкладку Classify и используйте
Откройте набор данных glass.arff , перейдите на вкладку Classify и используйте
С помощью перекрестной проверки Weka создает модель для каждого разделения.
Какой
С помощью перекрестной проверки Weka создает модель для каждого разделения.
Какой
Процесс интеллектуального анализа данных
Weka
Данные
Хороший результат
/161
Процесс интеллектуального анализа данных
Weka
Данные
Хороший результат
/161
Weka
Раскрываем
Задаем вопрос
Чистим данные
Определяем новые функции
Собираем данные
Процесс интеллектуального анализа данных
/161
Weka
Раскрываем
Задаем вопрос
Чистим данные
Определяем новые функции
Собираем данные
Процесс интеллектуального анализа данных
/161

Задайте вопрос
Что вы хотите узнать?
“Расскажите мне что-нибудь интересное о данных” этого
Задайте вопрос
Что вы хотите узнать?
“Расскажите мне что-нибудь интересное о данных” этого

(Выбранные) фильтры для разработки функций
AddExpression (MathExpression)
Применение математического выражения к существующим атрибутам
(Выбранные) фильтры для разработки функций
AddExpression (MathExpression)
Применение математического выражения к существующим атрибутам

Weka лишь малая часть (к сожалению) …
… и это легкая часть
“Пусть
Weka лишь малая часть (к сожалению) …
… и это легкая часть
“Пусть

Подводные камни и ловушки
Будьте осторожны
Очень легко просчитаться в интеллектуальном анализе данных
Подводные камни и ловушки
Будьте осторожны
Очень легко просчитаться в интеллектуальном анализе данных
Отсутствующие значения
“Отсутствующие” значит …
Неизвестные?
Незаписанные?
Неуместные?
Вы должны: ?1. Пропустить случаи, когда значение атрибута отсутствует?
Отсутствующие значения
“Отсутствующие” значит …
Неизвестные?
Незаписанные?
Неуместные?
Вы должны: ?1. Пропустить случаи, когда значение атрибута отсутствует?

OneR и J48 работают с пропущенными значениями по разному
Запустите weather-nominal.arff
OneR получает
OneR и J48 работают с пропущенными значениями по разному
Запустите weather-nominal.arff
OneR получает

Бесплатных обедов не бывает
Задача 2-го класса со 100 бинарными атрибутами
Скажем, вы
Бесплатных обедов не бывает
Задача 2-го класса со 100 бинарными атрибутами
Скажем, вы

Будьте осторожны
Переобучение очень многогранно
Отсутствующие значения – разные предположения
Нет «универсального» лучшего алгоритма
Будьте осторожны
Переобучение очень многогранно
Отсутствующие значения – разные предположения
Нет «универсального» лучшего алгоритма

Интеллектуальный анализ данных и этика
Законы о конфиденциальности информации (в Европе, но
Интеллектуальный анализ данных и этика
Законы о конфиденциальности информации (в Европе, но

Анонимизация сложнее, чем вы думаете
Когда в середине 1990-х годов Массачусетс опубликовал
Анонимизация сложнее, чем вы думаете
Когда в середине 1990-х годов Массачусетс опубликовал

Цель интеллектуального анализа данных состоит в том, чтобы различать …
кто получает
Цель интеллектуального анализа данных состоит в том, чтобы различать …
кто получает

Корреляция не означает причинно-следственную связь
По мере роста продаж мороженого растет и
Корреляция не означает причинно-следственную связь
По мере роста продаж мороженого растет и

Конфиденциальность личной информации
Анонимизация сложнее, чем вы думаете
Повторная идентификация по якобы анонимным
Конфиденциальность личной информации
Анонимизация сложнее, чем вы думаете
Повторная идентификация по якобы анонимным

Итоги курса
Интеллектуальный анализ данных - это не волшебство
Это огромное количество различных
Итоги курса
Интеллектуальный анализ данных - это не волшебство
Это огромное количество различных

Что мы упустили?
Фильтрующие классификаторы
Фильтрация обучающих данных, но не тестовых во время
Что мы упустили?
Фильтрующие классификаторы
Фильтрация обучающих данных, но не тестовых во время
Данные
Зафиксированные факты
Информация
Шаблоны или предположения, лежащие в их основе
Знания
Накопление вашего набора предположений
Мудрость
Ценность,
Данные
Зафиксированные факты
Информация
Шаблоны или предположения, лежащие в их основе
Знания
Накопление вашего набора предположений
Мудрость
Ценность,

С помощью экспериментальной установки « Исследование зрительной системы человека для определения
С помощью экспериментальной установки « Исследование зрительной системы человека для определения
 Контейнеры в C++
Контейнеры в C++ Язык запросов SQL. Многотабличные запросы
Язык запросов SQL. Многотабличные запросы SQL (Structured Query Language). Структурированный язык запросов
SQL (Structured Query Language). Структурированный язык запросов Программное обеспечение компьютера (8 класс)
Программное обеспечение компьютера (8 класс) Многофайловые проекты
Многофайловые проекты Программирование на языке С. Модуль 1. Введение в язык С
Программирование на языке С. Модуль 1. Введение в язык С Основные этапы развития информационного общества. Этапы развития технических средств и информационных ресурсов
Основные этапы развития информационного общества. Этапы развития технических средств и информационных ресурсов Информация и информационные процессы
Информация и информационные процессы Жизненный цикл информационных систем
Жизненный цикл информационных систем Организация профориентационной работы в колледже с использованием цифровых технологий
Организация профориентационной работы в колледже с использованием цифровых технологий Глобальна комп'ютерна мережа
Глобальна комп'ютерна мережа Пример страницы сайта
Пример страницы сайта Персональные данные (для детей 9-11 лет)
Персональные данные (для детей 9-11 лет) Ғылыми зерттеулердегі ақпараттық технологиялар
Ғылыми зерттеулердегі ақпараттық технологиялар Компьютерлік желілері
Компьютерлік желілері Средства автоматизации делопроизводства
Средства автоматизации делопроизводства Тайный покупатель по сети ЦС. Выводы и рекомендации
Тайный покупатель по сети ЦС. Выводы и рекомендации Разработка мультимедийного сайта
Разработка мультимедийного сайта Autodesk Vault Professional
Autodesk Vault Professional Информация, информационные процессы и информационное общество
Информация, информационные процессы и информационное общество Материалы к уроку 3D графика
Материалы к уроку 3D графика Особливості формування громадянського суспільства в Україні, як фактор забезпечення інформаційної безпеки держави
Особливості формування громадянського суспільства в Україні, як фактор забезпечення інформаційної безпеки держави Компьютерный текстовый документ как структура данных
Компьютерный текстовый документ как структура данных Идеальная презентация
Идеальная презентация Смартфон. Классификация мобильных устройств
Смартфон. Классификация мобильных устройств История серии видеоигры: Grand Theft Auto
История серии видеоигры: Grand Theft Auto Введение в базы данных
Введение в базы данных Табличный процессор Microsoft Excel
Табличный процессор Microsoft Excel