- Высокопроизводительные вычисления

Содержание
- 2. Программа курса 1 Параллелизм компьютерных вычислений 2 Архитектура высокопроизводительных вычислительных систем 2.1 Классификация вычислительных систем 2.2
- 3. I. Параллелизм компьютерных вычислений
- 4. Причины вычислительного параллелизма Независимость потоков команд, одновременно существующих в системе. Несвязанность данных, обрабатываемых в одном потоке
- 5. Классификация уровней параллелизма, предложенная П. Треливеном.
- 6. Мультипроцессирование в ОС
- 7. Простой пятиуровневый конвейер в RISC-процессорах
- 8. Принцип многофункциональной обработки Самостоятельные арифметические устройства в составе центрального процессора (основные): Сложитель. Умножитель. Делитель. Устройство выполнения
- 9. Векторная обработка данных
- 10. Intel Xeon Phi Процессор с 512-битными векторными регистрами Техпроцесс: 14 нм Количество ядер: 72 Частота ядра:
- 11. II. Архитектура высокопроизводительных вычислительных систем
- 12. Классификация вычислительных систем Флинна
- 13. Классификация MIMD систем
- 14. COMA Основные особенности: Отсутствие ОП, наличие вместо неё большого кэша на каждом узле. Адрес переменной не
- 15. Виды вычислительных кластеров Кластеры, узлами которых являются ПК. Кластеры, узлами которых являются мультипроцессоры. Кластеры, включающие ПК
- 16. MIMD системы SM-MIMD (Shared Memory Multiple Instruction, Multiple Data) DM-MIMD (Distributed Memory Multiple Instruction, Multiple Data)
- 17. Sunway TaihuLight Пиковая теоретическая производительность: 125.4 Пфлопс Производительность в соответствии с тестом LINPACK : 93 Пфлопс
- 18. Архитектура суперкомпьютера Sunway TaihuLight
- 19. Узел суперкомпьютера Sunway TaihuLight SW26010 – процессор китайской архитектуры и производства. Содержит: 256 вычислительных ядер 4
- 20. Вычислительный кластер «СКИФ Cyberia» Пиковая теоретическая производительность: 62,351 Тфлопс Производительность в соответствии с тестом LINPACK :
- 21. Узлы суперкомпьютера «СКИФ Cyberia» 282 узла/564 двухъядерных процессора Intel Xeon 5150, 2,66ГГц (Woodcrest)/8Gb RAM 190 узлов/360
- 22. III. Грид-системы Грид-система (grid) представляет собой программно-аппаратный комплекс, построенный на основе кластерного вычислителя. Грид-системы ещё называют
- 23. Классификация грид-систем С точки зрения выделения вычислительных ресурсов грид-системы классифицируют следующим образом: Добровольные Научные Коммерческие
- 24. Berkeley Open Infrastructure for Network Computing (BOINC) средняя производительность > 130 терафлопс количество участников 3 млн.
- 25. IV. Облачные технологии Суть облачных технологий (облачных вычислений) состоит в предоставлении программных и виртуализированных аппаратных ресурсов
- 26. Свойства облачных технологий Самообслуживание по требованию Универсальный доступ по сети Объединение ресурсов Быстрая эластичность Учёт потребления
- 27. Классификация облачных сервисов по типу ресурса SaaS (Software as a Service) PaaS (Platform as a Service)
- 28. Модели развёртывания облачных систем Частное облако Публичное облако Общественное облако Гибридное облако
- 29. MapReduce Функция высшего порядка – в программировании функция, принимающая в качестве аргументов другие функции или возвращающая
- 30. MapReduce Map – функция высшего порядка, которая применяет переданную в качестве аргумента функцию к каждому элементу
- 31. MapReduce Шаг 1. Подготовка входных данных для функции map(). Каждый узел получает данные, соответствующие ключу Ki.
- 32. Распределённые файловые системы Распределённая файловая система (РФС) – это клиент-серверное приложение, которое позволяет клиенту хранить и
- 33. Распределённые файловые системы РФС отличается от распределённого хранилища данных тем, что для доступа к распределённым данным
- 34. Принцип работы GoogleFS
- 35. Принцип работы HDFS
- 37. V. GPGPU Общие вычисления на видеокарте
- 38. Определение GPGPU (General-Purpose computation on Graphics Processing Units – универсальные вычисления на видеокарте) – направление информатики,
- 39. Сравнение производительности ЦП и видеокарты
- 40. Сравнение архитектуры ЦП и видеокарты
- 41. Укрупнённая схема графического конвейера
- 42. Пример работы графического конвейера
- 43. Пиксельные шейдеры Программы, написанными на си-подобном языке программирования (например, High Level Shader Language - высокоуровневый язык
- 44. Основные программные интерфейсы для доступа к вычислительным ресурсам видеокарты
- 45. Applications Libraries “Drop-in” Acceleration Programming Languages OpenACC Directives Easily Accelerate Applications 3 Ways to Accelerate Applications
- 46. Some GPU-accelerated Libraries © NVIDIA 2013
- 47. OpenACC Directives © NVIDIA 2013 Program myscience ... serial code ... !$acc kernels do k =
- 48. Использование директив OpenACC для распараллеливания метода Якоби Метод Якоби – метод из численной линейной алгебры для
- 49. Nvidia CUDA __global__ спецификатор ядра (kernel) – функции выполняемой N раз N различными потоками. threadIdx встроенная
- 50. Иерархия потоков
- 51. Синхронизация потоков в блоке __syncthreads() работает как барьер, который поток может пересечь, только когда все потоки
- 52. Аппаратная реализация
- 53. Архитектура SIMT (Single-Instruction, Multiple-Thread) warp группа из 32 потоков, исполняющих одну инструкцию в один момент времени.
- 54. Типы памяти в технологии CUDA
- 55. Nvidia CUDA SDK Расширенный язык C Компилятор nvcc Отладчик gdb для GPU Профайлер Профилирование — сбор
- 56. Использование n блоков __global__ void calculate(float* A, float* B, float* C, int n) { int i
- 57. Что делать, если элементов данных больше, чем можно создать потоков? 1. Обработка одним потоком m последовательных
- 58. Что делать, если элементов данных больше, чем можно создать потоков? 2. Обработка потоком каждого (l +
- 59. Сравнение подходов обработки структур данных большого размера
- 60. Результатом выполнения операции difference && 1 будет 1, если разница difference не равна 0, и 0,
- 61. GEFORCE GTX 1080 GPU Engine Specs: NVIDIA CUDA® Cores 2560 Base Clock (MHz) 1607 Boost Clock
- 62. Intel® Core™ i7-6950X Processor Extreme Edition
- 63. Дополнительная информация Общая документация http://docs.nvidia.com/cuda/cuda-c-programming-guide Первая лабораторная работа https://nvidia.qwiklab.com Как сделать программу более гибкой относительно размера
- 64. Вопросы по V главе В чём отличие архитектуры современных видеокарт от архитектуры центрального процессора? Какие характеристики
- 65. VI. Программирование для высокопроизводительных вычислений
- 66. Проблемы параллельного программирования Равномерная загрузка процессоров / узлов (балансировка) Обмен информацией между процессорами Минимизация объёма данных,
- 67. Методология организации параллельных вычислений для SIMD архитектуры 1) Выявление ресурсоёмких и вычислительно сложных частей программы. 2)
- 68. Методология организации параллельных вычислений для MIMD архитектуры 1) Разделение вычислений на независимые части 2) Выделение информационных
- 69. Показатели качества параллельных методов Ускорение (speedup) Sp(n)=T1(n)/Tp(n) Эффективность (efficiency) Ep(n)=T1(n)/(pTp(n))=Sp(n)/p Стоимость (cost) Cp=pTp(n) Масштабируемость (scalability) вычислений
- 70. Библиотеки для обмена сообщениями MPI (Message Passing Interface) PVM (Parallel Virtual Machines) Предназначены для вычислительных систем
- 71. MPI (Message Passing Interface) Существуют бесплатные и коммерческие реализации почти для всех суперкомпьютерных платформ, а также
- 72. MPI Обмены типа точка-точка Коллективные обмены Барьерная синхронизация Передача от одного узла всем в группе Передача
- 73. OpenMP Интерфейс OpenMP задуман как стандарт для программирования на масштабируемых SMP-системах (SSMP,ccNUMA, etc.) в модели общей
- 74. Почему не использовать MPI для вычислителей с общей памятью? Модель передачи сообщений недостаточно эффективна на SMP-системах
- 75. Преимущества OpenMP «Инкрементального распараллеливание» OpenMP - достаточно гибкий механизм OpenMP-программа на однопроцессорной платформе может быть использована
- 76. Принцип параллельной обработки данных в OpenMP
- 77. Пример программы с использованием OpenMP #pragma omp parallel { #pragma omp for for(int n = 0;
- 78. Код, преобразованный компилятором int this_thread = omp_get_thread_num(), num_threads = omp_get_num_threads(); int my_start = (this_thread) * 10
- 80. Скачать презентацию

Программа курса
1 Параллелизм компьютерных вычислений
2 Архитектура высокопроизводительных вычислительных систем
2.1 Классификация вычислительных систем
2.2 Классификация
Программа курса
1 Параллелизм компьютерных вычислений
2 Архитектура высокопроизводительных вычислительных систем
2.1 Классификация вычислительных систем
2.2 Классификация

I. Параллелизм компьютерных вычислений
I. Параллелизм компьютерных вычислений

Причины вычислительного параллелизма
Независимость потоков команд, одновременно существующих в системе.
Несвязанность данных, обрабатываемых
Причины вычислительного параллелизма
Независимость потоков команд, одновременно существующих в системе.
Несвязанность данных, обрабатываемых
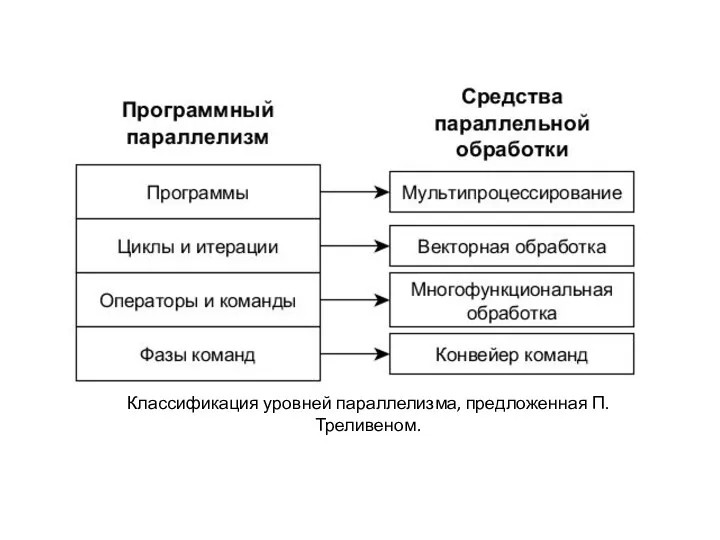
Классификация уровней параллелизма, предложенная П. Треливеном.
Классификация уровней параллелизма, предложенная П. Треливеном.

Мультипроцессирование в ОС
Мультипроцессирование в ОС
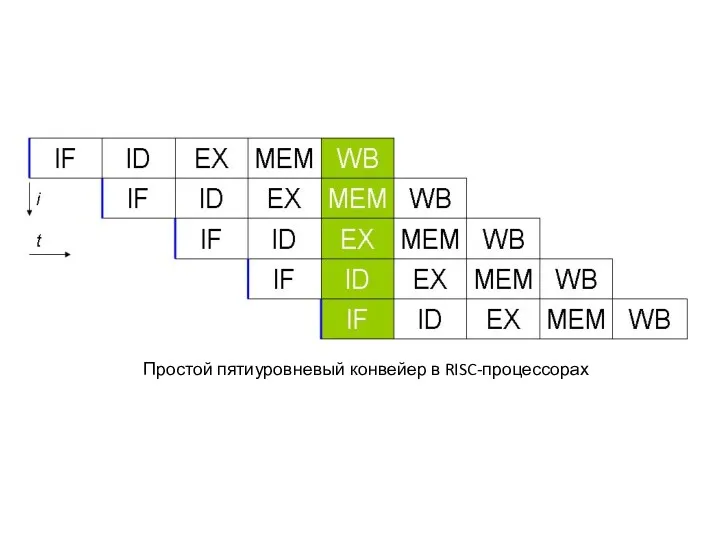
Простой пятиуровневый конвейер в RISC-процессорах
Простой пятиуровневый конвейер в RISC-процессорах

Принцип многофункциональной обработки
Самостоятельные арифметические устройства в составе центрального процессора (основные):
Сложитель.
Умножитель.
Делитель.
Устройство выполнения
Принцип многофункциональной обработки
Самостоятельные арифметические устройства в составе центрального процессора (основные):
Сложитель.
Умножитель.
Делитель.
Устройство выполнения
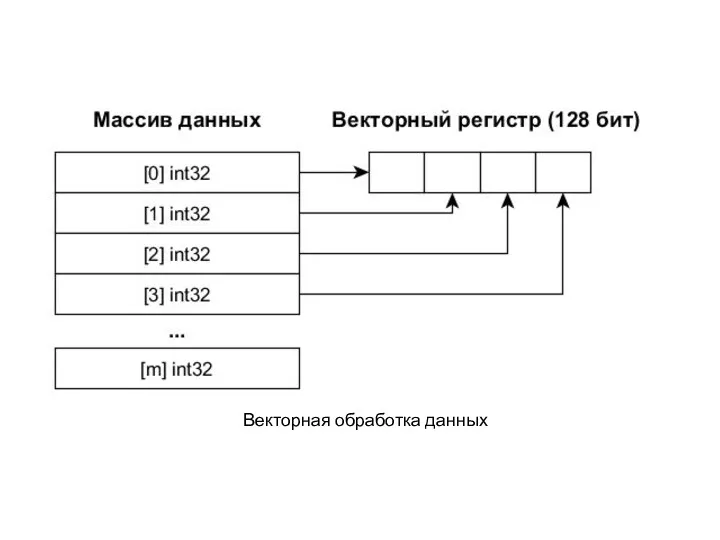
Векторная обработка данных
Векторная обработка данных

Intel Xeon Phi
Процессор с 512-битными векторными регистрами
Техпроцесс: 14 нм
Количество ядер:
Intel Xeon Phi
Процессор с 512-битными векторными регистрами
Техпроцесс: 14 нм
Количество ядер:

II. Архитектура высокопроизводительных вычислительных систем
II. Архитектура высокопроизводительных вычислительных систем
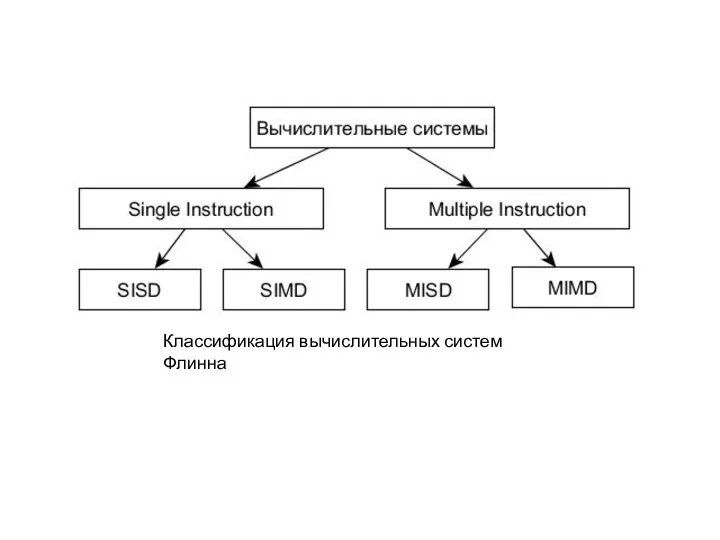
Классификация вычислительных систем Флинна
Классификация вычислительных систем Флинна
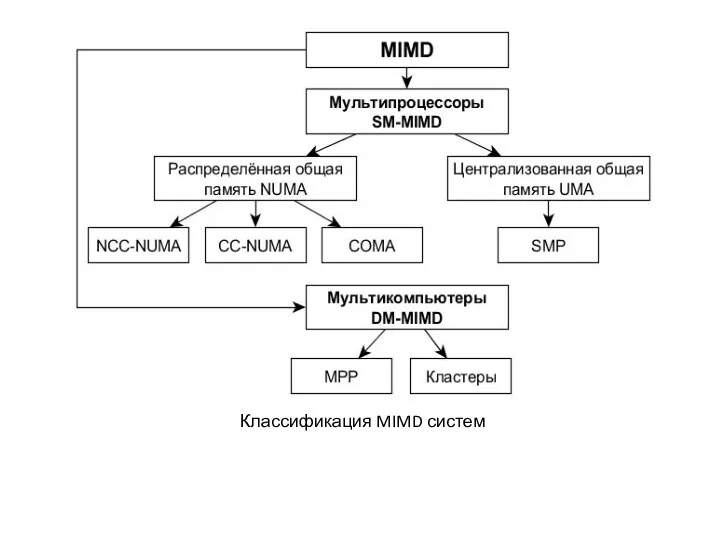
Классификация MIMD систем
Классификация MIMD систем

COMA
Основные особенности:
Отсутствие ОП, наличие вместо неё большого кэша на каждом узле.
Адрес
COMA
Основные особенности:
Отсутствие ОП, наличие вместо неё большого кэша на каждом узле.
Адрес

Виды вычислительных кластеров
Кластеры, узлами которых являются ПК.
Кластеры, узлами которых являются мультипроцессоры.
Кластеры,
Виды вычислительных кластеров
Кластеры, узлами которых являются ПК.
Кластеры, узлами которых являются мультипроцессоры.
Кластеры,

MIMD системы
SM-MIMD (Shared Memory Multiple Instruction, Multiple Data)
DM-MIMD (Distributed Memory
MIMD системы
SM-MIMD (Shared Memory Multiple Instruction, Multiple Data)
DM-MIMD (Distributed Memory

Sunway TaihuLight
Пиковая теоретическая
производительность: 125.4 Пфлопс
Производительность в соответствии
с тестом LINPACK :
Sunway TaihuLight
Пиковая теоретическая
производительность: 125.4 Пфлопс
Производительность в соответствии
с тестом LINPACK :
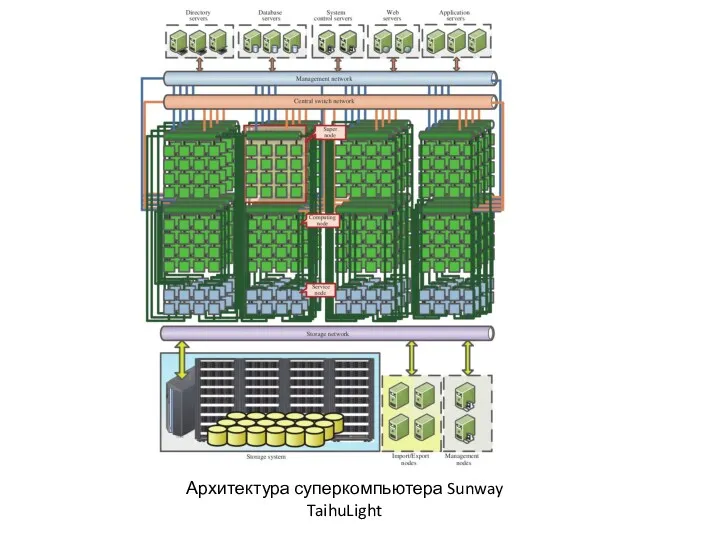
Архитектура суперкомпьютера Sunway TaihuLight
Архитектура суперкомпьютера Sunway TaihuLight

Узел суперкомпьютера
Sunway TaihuLight
SW26010 – процессор китайской архитектуры
и производства. Содержит:
256
Узел суперкомпьютера
Sunway TaihuLight
SW26010 – процессор китайской архитектуры
и производства. Содержит:
256

Вычислительный кластер
«СКИФ Cyberia»
Пиковая теоретическая
производительность: 62,351 Тфлопс
Производительность в соответствии
с тестом
Вычислительный кластер
«СКИФ Cyberia»
Пиковая теоретическая
производительность: 62,351 Тфлопс
Производительность в соответствии
с тестом

Узлы суперкомпьютера
«СКИФ Cyberia»
282 узла/564 двухъядерных процессора Intel Xeon 5150,
2,66ГГц (Woodcrest)/8Gb RAM
190
Узлы суперкомпьютера
«СКИФ Cyberia»
282 узла/564 двухъядерных процессора Intel Xeon 5150,
2,66ГГц (Woodcrest)/8Gb RAM
190

III. Грид-системы
Грид-система (grid) представляет собой программно-аппаратный комплекс, построенный на основе кластерного
III. Грид-системы
Грид-система (grid) представляет собой программно-аппаратный комплекс, построенный на основе кластерного

Классификация грид-систем
С точки зрения выделения вычислительных ресурсов грид-системы классифицируют следующим образом:
Добровольные
Научные
Коммерческие
Классификация грид-систем
С точки зрения выделения вычислительных ресурсов грид-системы классифицируют следующим образом:
Добровольные
Научные
Коммерческие

Berkeley Open Infrastructure for Network Computing (BOINC)
средняя производительность > 130 терафлопс
количество
Berkeley Open Infrastructure for Network Computing (BOINC)
средняя производительность > 130 терафлопс
количество

IV. Облачные технологии
Суть облачных технологий (облачных вычислений) состоит в предоставлении программных
IV. Облачные технологии
Суть облачных технологий (облачных вычислений) состоит в предоставлении программных

Свойства облачных технологий
Самообслуживание по требованию
Универсальный доступ по сети
Объединение ресурсов
Свойства облачных технологий
Самообслуживание по требованию
Универсальный доступ по сети
Объединение ресурсов

Классификация облачных сервисов по типу ресурса
SaaS (Software as a Service)
PaaS (Platform
Классификация облачных сервисов по типу ресурса
SaaS (Software as a Service)
PaaS (Platform

Модели развёртывания облачных систем
Частное облако
Публичное облако
Общественное облако
Гибридное облако
Модели развёртывания облачных систем
Частное облако
Публичное облако
Общественное облако
Гибридное облако

MapReduce
Функция высшего порядка – в программировании функция, принимающая в качестве аргументов
MapReduce
Функция высшего порядка – в программировании функция, принимающая в качестве аргументов

MapReduce
Map – функция высшего порядка, которая применяет переданную в качестве аргумента
MapReduce
Map – функция высшего порядка, которая применяет переданную в качестве аргумента

MapReduce
Шаг 1. Подготовка входных данных для функции map(). Каждый узел получает
MapReduce
Шаг 1. Подготовка входных данных для функции map(). Каждый узел получает

Распределённые файловые системы
Распределённая файловая система (РФС) – это клиент-серверное приложение, которое
Распределённые файловые системы
Распределённая файловая система (РФС) – это клиент-серверное приложение, которое

Распределённые файловые системы
РФС отличается от распределённого хранилища данных тем, что для
Распределённые файловые системы
РФС отличается от распределённого хранилища данных тем, что для
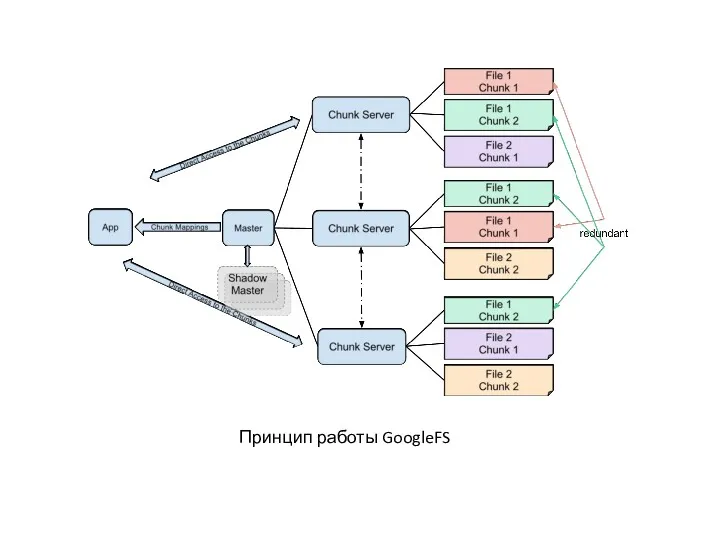
Принцип работы GoogleFS
Принцип работы GoogleFS
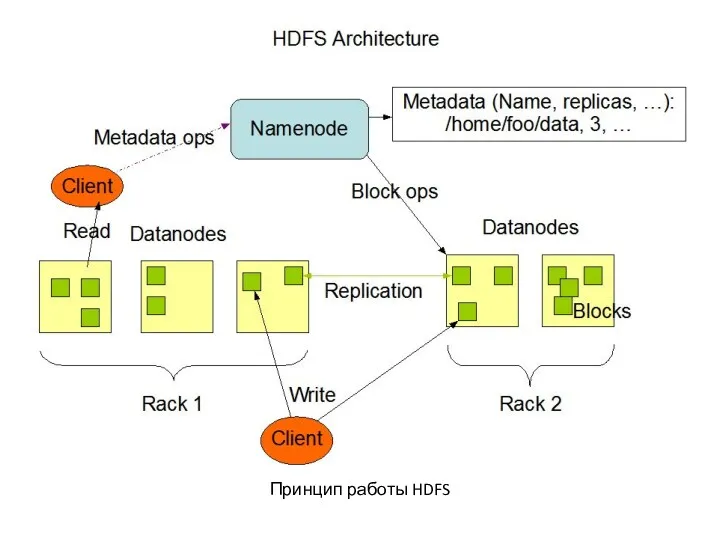
Принцип работы HDFS
Принцип работы HDFS


V. GPGPU
Общие вычисления на видеокарте
V. GPGPU
Общие вычисления на видеокарте

Определение
GPGPU (General-Purpose computation on Graphics Processing Units – универсальные вычисления на
Определение
GPGPU (General-Purpose computation on Graphics Processing Units – универсальные вычисления на

Сравнение производительности ЦП и видеокарты
Сравнение производительности ЦП и видеокарты
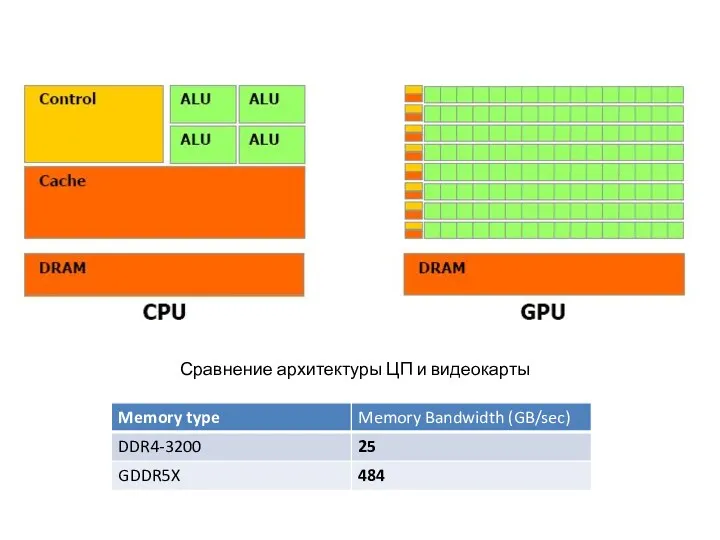
Сравнение архитектуры ЦП и видеокарты
Сравнение архитектуры ЦП и видеокарты
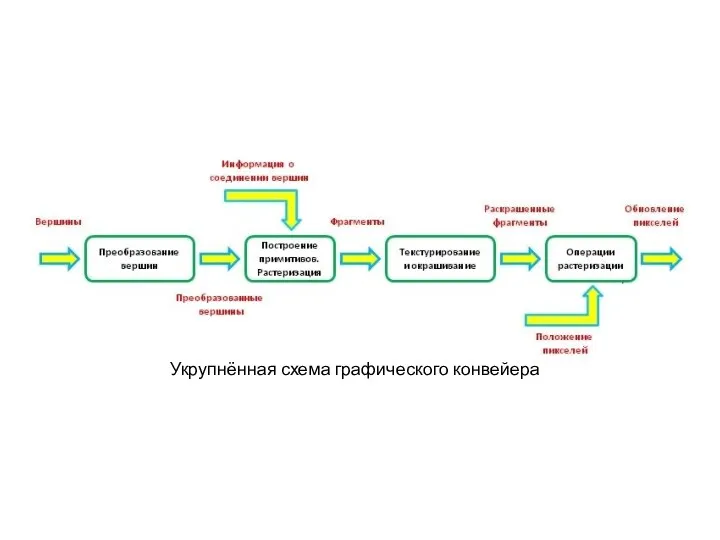
Укрупнённая схема графического конвейера
Укрупнённая схема графического конвейера
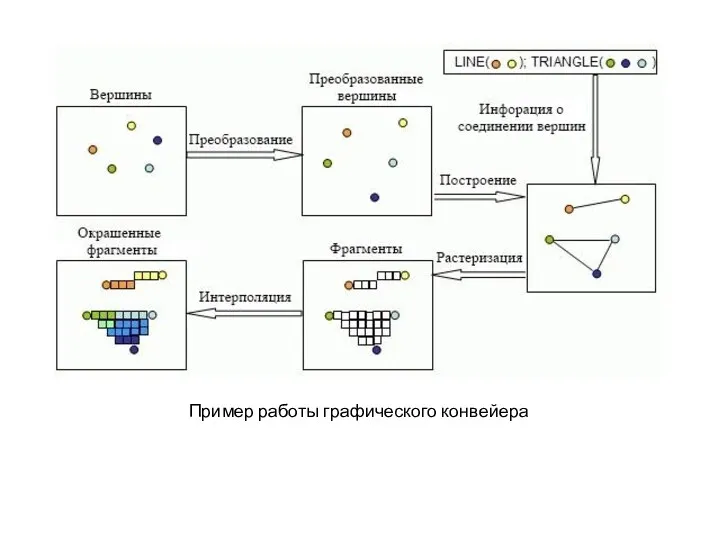
Пример работы графического конвейера
Пример работы графического конвейера

Пиксельные шейдеры
Программы, написанными на си-подобном языке программирования (например, High Level Shader
Пиксельные шейдеры
Программы, написанными на си-подобном языке программирования (например, High Level Shader
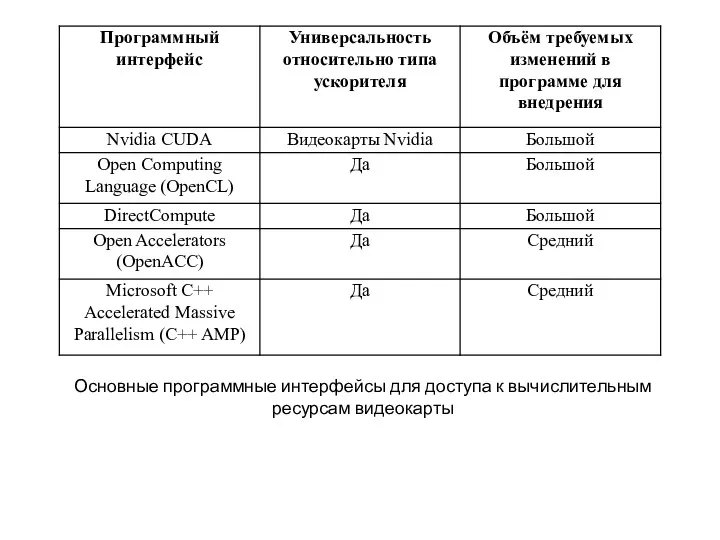
Основные программные интерфейсы для доступа к вычислительным ресурсам видеокарты
Основные программные интерфейсы для доступа к вычислительным ресурсам видеокарты
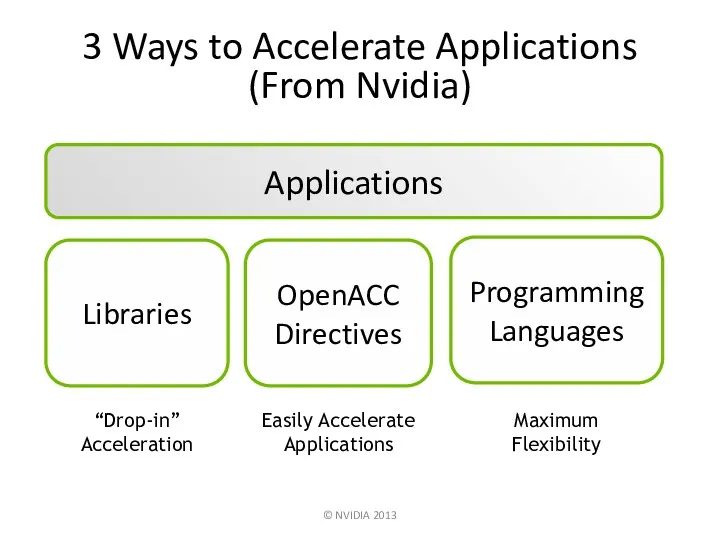
Applications
Libraries
“Drop-in” Acceleration
Programming Languages
OpenACC Directives
Easily Accelerate Applications
3 Ways to Accelerate Applications
(From Nvidia)
Maximum
Flexibility
©
Applications
Libraries
“Drop-in” Acceleration
Programming Languages
OpenACC Directives
Easily Accelerate Applications
3 Ways to Accelerate Applications
(From Nvidia)
Maximum
Flexibility
©

Some GPU-accelerated Libraries
© NVIDIA 2013
Some GPU-accelerated Libraries
© NVIDIA 2013
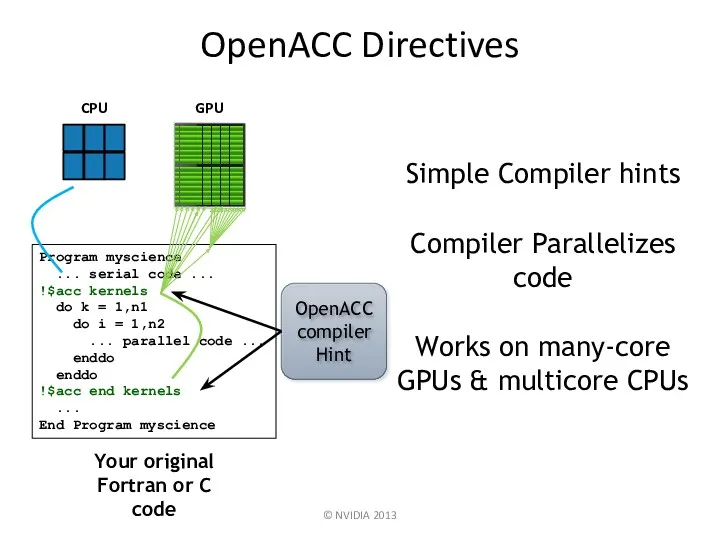
OpenACC Directives
© NVIDIA 2013
Program myscience
... serial code ...
!$acc kernels
do
OpenACC Directives
© NVIDIA 2013
Program myscience
... serial code ...
!$acc kernels
do

Использование директив OpenACC для распараллеливания метода Якоби
Метод Якоби – метод из
Использование директив OpenACC для распараллеливания метода Якоби
Метод Якоби – метод из

Nvidia CUDA
__global__ спецификатор ядра (kernel) – функции выполняемой N раз N
Nvidia CUDA
__global__ спецификатор ядра (kernel) – функции выполняемой N раз N
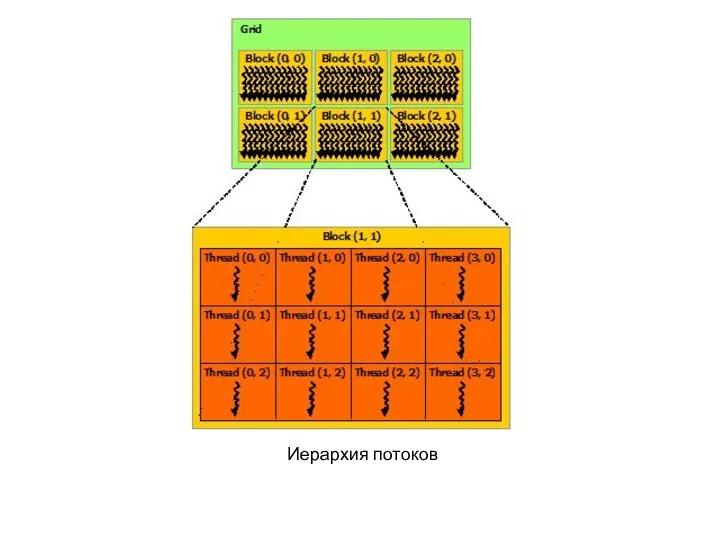
Иерархия потоков
Иерархия потоков

Синхронизация потоков в блоке
__syncthreads() работает как барьер, который поток может пересечь, только
Синхронизация потоков в блоке
__syncthreads() работает как барьер, который поток может пересечь, только
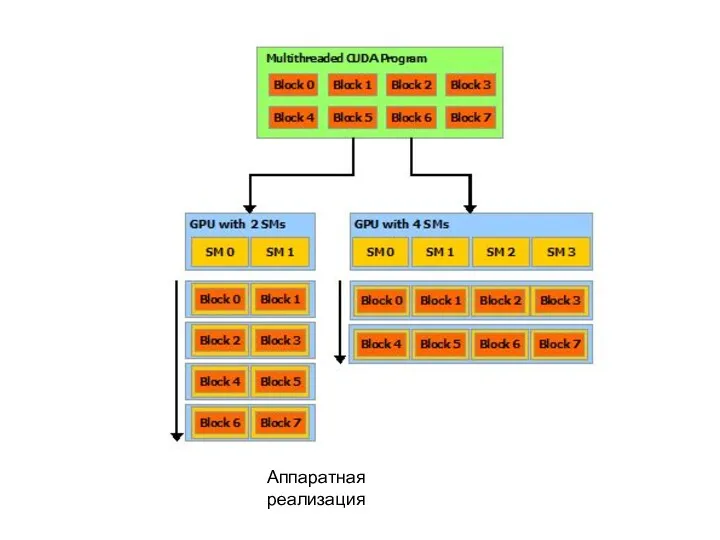
Аппаратная реализация
Аппаратная реализация

Архитектура SIMT
(Single-Instruction, Multiple-Thread)
warp группа из 32 потоков, исполняющих одну инструкцию в
Архитектура SIMT
(Single-Instruction, Multiple-Thread)
warp группа из 32 потоков, исполняющих одну инструкцию в
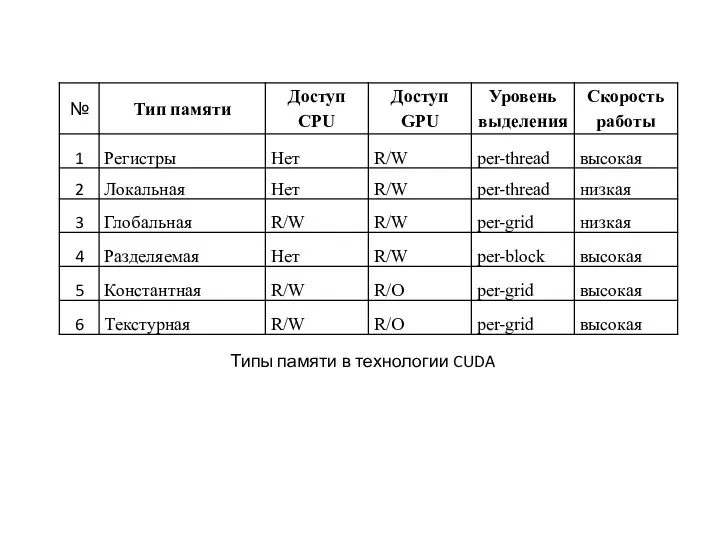
Типы памяти в технологии CUDA
Типы памяти в технологии CUDA

Nvidia CUDA SDK
Расширенный язык C
Компилятор nvcc
Отладчик gdb для GPU
Профайлер
Профилирование — сбор
Nvidia CUDA SDK
Расширенный язык C
Компилятор nvcc
Отладчик gdb для GPU
Профайлер
Профилирование — сбор

Использование n блоков
__global__ void calculate(float* A, float* B, float* C, int n) {
int i = blockIdx.x
Использование n блоков
__global__ void calculate(float* A, float* B, float* C, int n) {
int i = blockIdx.x

Что делать, если элементов данных больше, чем можно создать потоков?
1. Обработка
Что делать, если элементов данных больше, чем можно создать потоков?
1. Обработка

Что делать, если элементов данных больше, чем можно создать потоков?
2. Обработка
Что делать, если элементов данных больше, чем можно создать потоков?
2. Обработка
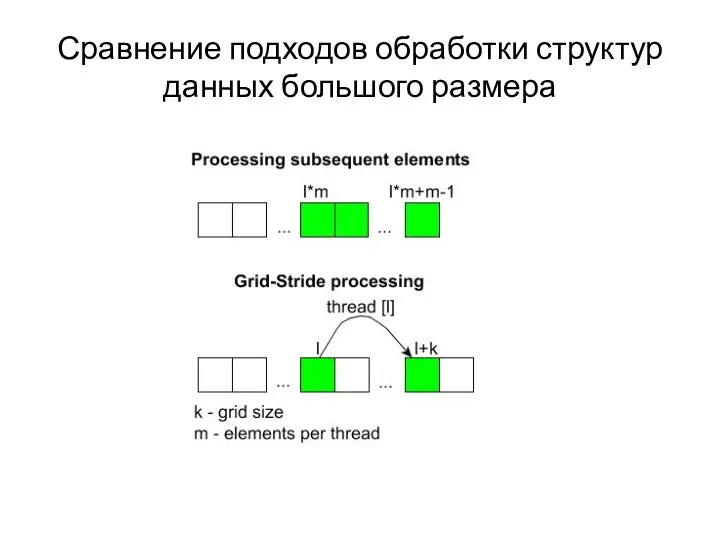
Сравнение подходов обработки структур данных большого размера
Сравнение подходов обработки структур данных большого размера

Результатом выполнения операции difference && 1 будет 1, если разница difference
Результатом выполнения операции difference && 1 будет 1, если разница difference

GEFORCE GTX 1080
GPU Engine Specs:
NVIDIA CUDA® Cores 2560
Base Clock (MHz) 1607
Boost Clock
GEFORCE GTX 1080
GPU Engine Specs:
NVIDIA CUDA® Cores 2560
Base Clock (MHz) 1607
Boost Clock
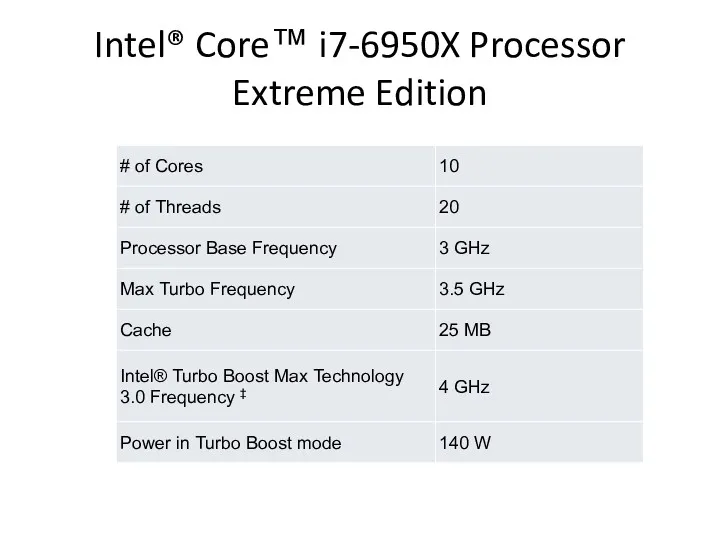
Intel® Core™ i7-6950X Processor Extreme Edition
Intel® Core™ i7-6950X Processor Extreme Edition

Дополнительная информация
Общая документация http://docs.nvidia.com/cuda/cuda-c-programming-guide
Первая лабораторная работа https://nvidia.qwiklab.com
Как сделать программу более
Дополнительная информация
Общая документация http://docs.nvidia.com/cuda/cuda-c-programming-guide
Первая лабораторная работа https://nvidia.qwiklab.com
Как сделать программу более

Вопросы по V главе
В чём отличие архитектуры современных видеокарт от архитектуры
Вопросы по V главе
В чём отличие архитектуры современных видеокарт от архитектуры

VI. Программирование для высокопроизводительных вычислений
VI. Программирование для высокопроизводительных вычислений

Проблемы параллельного программирования
Равномерная загрузка процессоров / узлов (балансировка)
Обмен информацией между процессорами
Минимизация
Проблемы параллельного программирования
Равномерная загрузка процессоров / узлов (балансировка)
Обмен информацией между процессорами
Минимизация

Методология организации параллельных вычислений для SIMD архитектуры
1) Выявление ресурсоёмких и вычислительно
Методология организации параллельных вычислений для SIMD архитектуры
1) Выявление ресурсоёмких и вычислительно

Методология организации параллельных вычислений для MIMD архитектуры
1) Разделение вычислений на независимые
Методология организации параллельных вычислений для MIMD архитектуры
1) Разделение вычислений на независимые

Показатели качества параллельных методов
Ускорение (speedup)
Sp(n)=T1(n)/Tp(n)
Эффективность (efficiency)
Ep(n)=T1(n)/(pTp(n))=Sp(n)/p
Стоимость (cost)
Cp=pTp(n)
Масштабируемость (scalability) вычислений
сильная
слабая
Показатели качества параллельных методов
Ускорение (speedup)
Sp(n)=T1(n)/Tp(n)
Эффективность (efficiency)
Ep(n)=T1(n)/(pTp(n))=Sp(n)/p
Стоимость (cost)
Cp=pTp(n)
Масштабируемость (scalability) вычислений
сильная
слабая

Библиотеки для обмена сообщениями
MPI (Message Passing Interface)
PVM (Parallel Virtual Machines)
Предназначены для
Библиотеки для обмена сообщениями
MPI (Message Passing Interface)
PVM (Parallel Virtual Machines)
Предназначены для

MPI (Message Passing Interface)
Существуют бесплатные и коммерческие реализации почти для всех
MPI (Message Passing Interface)
Существуют бесплатные и коммерческие реализации почти для всех

MPI
Обмены типа точка-точка
Коллективные обмены
Барьерная синхронизация
Передача от одного узла всем в группе
Передача
MPI
Обмены типа точка-точка
Коллективные обмены
Барьерная синхронизация
Передача от одного узла всем в группе
Передача

OpenMP
Интерфейс OpenMP задуман как стандарт для программирования на масштабируемых SMP-системах (SSMP,ccNUMA, etc.) в
OpenMP
Интерфейс OpenMP задуман как стандарт для программирования на масштабируемых SMP-системах (SSMP,ccNUMA, etc.) в

Почему не использовать MPI для вычислителей с общей памятью?
Модель передачи сообщений
Почему не использовать MPI для вычислителей с общей памятью?
Модель передачи сообщений

Преимущества OpenMP
«Инкрементального распараллеливание»
OpenMP - достаточно гибкий механизм
OpenMP-программа на однопроцессорной платформе может быть
Преимущества OpenMP
«Инкрементального распараллеливание»
OpenMP - достаточно гибкий механизм
OpenMP-программа на однопроцессорной платформе может быть
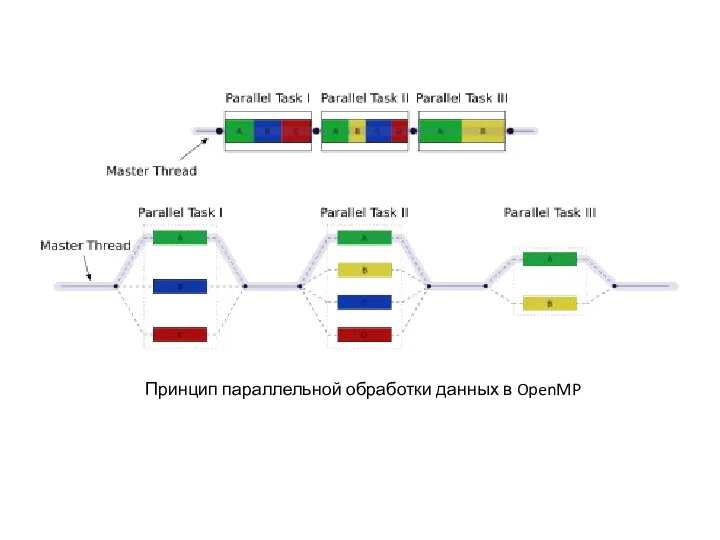
Принцип параллельной обработки данных в OpenMP
Принцип параллельной обработки данных в OpenMP

Пример программы с использованием OpenMP
#pragma omp parallel
{
#pragma omp for
for(int n =
Пример программы с использованием OpenMP
#pragma omp parallel
{
#pragma omp for
for(int n =

Код, преобразованный компилятором
int this_thread = omp_get_thread_num(), num_threads = omp_get_num_threads();
int my_start =
Код, преобразованный компилятором
int this_thread = omp_get_thread_num(), num_threads = omp_get_num_threads();
int my_start =
 Мастер-класс по печатным СМИ
Мастер-класс по печатным СМИ Нейронные сети. Возможности применения и перспективы развития
Нейронные сети. Возможности применения и перспективы развития Prefer class hierarchies to tagged classes. (Item 20, 21, 22)
Prefer class hierarchies to tagged classes. (Item 20, 21, 22) Моделирование
Моделирование Морской бой. Описание программы
Морской бой. Описание программы Бази даних. Системи управління базами даних
Бази даних. Системи управління базами даних Принципы объектно-ориентированного проектирования
Принципы объектно-ориентированного проектирования Представление аналогового сигнала в цифровом виде (лекция 20)
Представление аналогового сигнала в цифровом виде (лекция 20) Объекты и их имена
Объекты и их имена Файлы и файловая система
Файлы и файловая система Windows System Programming
Windows System Programming Розв’язування крайових задач для звичайних диференціальних рівнянь методом Гальоркіна
Розв’язування крайових задач для звичайних диференціальних рівнянь методом Гальоркіна Електронне спілкування
Електронне спілкування Введение в PL/SQL
Введение в PL/SQL Технология быстрого описания бизнес-процессов
Технология быстрого описания бизнес-процессов Текстовая информация. Тексты в памяти компьютера. Текстовые редакторы и процессоры
Текстовая информация. Тексты в памяти компьютера. Текстовые редакторы и процессоры Creating Session Beans
Creating Session Beans Уроки по теме Одномерный массив
Уроки по теме Одномерный массив Компьютерная графика и анимация. Векторная графика
Компьютерная графика и анимация. Векторная графика Компьютерная арифметика
Компьютерная арифметика Медицинское мобильное приложение Приоритет
Медицинское мобильное приложение Приоритет Информационные технологии в профессиональной деятельности. Автоматизированные банковские системы и рабочие места
Информационные технологии в профессиональной деятельности. Автоматизированные банковские системы и рабочие места Курсовая работа по дисциплине: системное программирование. Диспетчер файлов
Курсовая работа по дисциплине: системное программирование. Диспетчер файлов Обработка информации. Создание движущихся изображений. 5 класс
Обработка информации. Создание движущихся изображений. 5 класс Интегрированный урок английского языка и информатики
Интегрированный урок английского языка и информатики Программное обеспечение
Программное обеспечение Основы логики
Основы логики 5.7. Служба каталогов сетевых серверных ОС
5.7. Служба каталогов сетевых серверных ОС