- Сложность проблем. Теория сложности (Лекция 6)

Содержание
- 2. В нашем варианте машина Тьюринга состоит из управляющего устройства с конечным числам состояний (finite-state control unit),
- 3. Каждая головка имеет доступ к своей ленте и может перемещаться вдоль нее влево и вправо. Каждая
- 4. Каждый символ занимает одну ячейку, а оставшиеся ячейки ленты, расположенные справа, остаются пустыми (blank). Описанная выше
- 5. В каждый момент времени только одна из головок имеет доступ к своей ленте. Операция доступа головки
- 6. Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует исходную строку и завершает работу,
- 7. Исходные данные, распознаваемые машиной Тьюринга, называются предложением (instance) распознаваемого языка (language). Для каждой конкретной задачи машину
- 8. Количество тактов Тм, которые машина Тьюринга М должна выполнить при распознавании исходной строки, называется продолжительностью работы
- 9. Легко видеть, что Тм(п) ≥ п. Кроме временных ограничений, машина М имеет ограничения памяти SM, представляющие
- 10. Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует исходную строку и завершает работу,
- 11. Детерминированное полиномиальное время Функция р(п) является полиномиальной по целому аргументу п, если она имеет вид: где
- 12. Определение : Класс . Символом обозначается класс языков, имеющих следующие характеристики. Язык L принадлежит классу
- 13. Языки, распознаваемые за полиномиальное время, считаются "всегда простыми", а полиномиальные машины Тьюринга — "всегда эффективными". Все
- 14. В работах, посвященных теории вычислительной сложности, задача считается решенной, только если любой экземпляр данной задачи можно
- 15. Пример - язык DIV3 Пусть DIV3 — множество неотрицательных целых чисел, кратных трем. Покажем, что DIV3
- 16. 1 1 1 1 1 2 0 0 Блок управления Если записать исходные данные в виде
- 17. 1 1 1 1 1 2 0 0 Блок управления Исходная строка х принадлежит языку DIV3
- 18. 1 1 1 1 1 2 0 0 Блок управления Распознана строка языка DIV3 Следовательно, создаваемая
- 19. 1 1 1 1 1 2 0 0 Блок управления Распознана строка языка DIV3 Очевидно, что
- 20. Полиномиальные вычислительные задачи По определению класс является классом языков, распознаваемых за полиномиальное время. Задача распознавания
- 21. Вычислительное устройство, имеющее неймановскую архитектуру (иначе говоря, всем известную современную компьютерную архитектуру), состоит из счетчика, памяти
- 22. Можно доказать ,что каждую микрокоманду из указанного выше набора, можно имитировать на машине Тьюринга за полиномиальное
- 23. -символика (order notation) Символом (f(n)) обозначается функция g(п), для которой существует константа с > 0 и
- 24. Теорема. Наибольший общий делитель gcd(a, b) можно вычислить с помощью не более чем 2mах(|а|, |b|) операций
- 25. Таким образом, временная сложность алгоритма вычисления наибольшего общего делителя ( при условии a > b )
- 26. В рамках модели поразрядных вычислений на сложение и вычитание двух целых чисел i и j затрачиваются
- 27. Поразрядные оценки сложности основных операций в модулярной арифметике
- 28. Недетерминированное полиномиальное время Недетерминированной машиной Тьюринга (non-deterministic Turing machine) называется устройство, на каждом такте работы которого
- 29. Работу недетерминированной машины Тьюринга можно представить в виде серии догадок. В этом случае последовательность распознавания представляет
- 30. Размер (количество узлов) этого дерева экспоненциально зависит от размера входа. Однако, поскольку количество тактов в последовательности
- 31. Итак, временная сложность распознавания строки с помощью серии правильных догадок полиномиально зависит от размера исходных данных.
- 32. Классы сложности Задачи, которые решаются за полиномиальное время называются решаемыми, так как они обычно могут быть
- 33. Классы сложности Класс NP или NP - TIME, состоит из всех задач решаемых за полиномиальное время
- 34. Классы сложности Класс PSPACE состоит из задач, требующих полиноми- альных объемов машинной памяти, но не обязательно
- 35. Классы сложности Класс EXPTIME – эти задачи решаются за экспоненциальное время
- 36. Классы сложности Таким образом, выбор наиболее сложных задач, для которых известно решение, и использование их в
- 37. Основные понятия теории вероятностей Пусть S — произвольное, но фиксированное множество точек, называемое полем вероятностей (probability
- 38. Событие (составное, или разложимое) является подмножеством множества S и обычно обозначается прописной буквой (например, Е). Эксперимент
- 39. Событие (составное, или разложимое) является подмножеством множества S и обычно обозначается прописной буквой (например, Е). Эксперимент
- 40. 1. S1: пространство состоит из 52 точек — по одной на каждую карту. Допустим, что событие
- 41. Классическое определение вероятности. Допустим, что в ходе эксперимента извлекается одна из п = #S равновероятных точек
- 42. В примере вероятности событий E1,E2,E3 таковы: Prob[E1] = 4/52 Prob[E2] = 1/2 Prob[E3] = 9/13
- 43. Статистическое определение вероятности. Допустим, что при одинаковых условиях проводятся п экспериментов, в которых μ раз происходит
- 44. Свойства 1. Поле вероятностей само по себе является достоверным событием (sure event). Например, S= {ОРЕЛ, РЕШКА}.
- 45. 3. Вероятность любого события удовлетворяет неравенству: 0 ≤Prob[E] ≤1. 4. Если Е ⊆ F, то говорят,
- 46. Основные вычисления Обозначим через Е ⋃ F сумму событий Е и F (происходит одно из двух
- 47. Условная вероятность Пусть Е u F — два события, причем событие Е имеет ненулевую вероятность. Вероятность
- 48. Пример. Рассмотрим семьи с двумя детьми. Обозначим буквами g (girl) и b (boy) пол ребенка (девочка
- 49. Определение Независимые события События Е и F называются независимыми, тогда и только тогда, когда Prob[F|E] =
- 50. Событие Е ⋂ F представляет собой точку gg, поэтому Prob[ Е ⋂ F] = 1/4 .
- 51. Событие Е ⋂ F представляет собой точку gg, поэтому Prob[ Е ⋂ F] = 1/4 .
- 52. Правила умножения 1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F]. 2. Если события Е
- 53. Правила умножения 1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F]. 2. Если события Е
- 54. Закон полной вероятности
- 55. Случайные величины и распределения вероятностей Допустим, что дискретное пространство S содержит конечное или счетное количество изолированных
- 56. 2. Пусть S — дискретное пространство вероятностей, а ξ— случайная величина. Функция распределения дискретной случайной величины
- 57. Равномерное распределение Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение (uniform distribution):
- 58. Равномерное распределение Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение (uniform distribution): Пример. Пусть
- 59. Множество S = {0,1,2,..., 2k - 1} можно разбить на два непересекающихся подмножества: S1 = {0,1,2,...,
- 60. Множество S = {0,1,2,..., 2k - 1} можно разбить на два непересекающихся подмножества: S1 = {0,1,2,...,
- 62. Биномиальное распределение Допустим, что эксперимент имеет только два исхода — успех или неудача: "ОРЕЛ" или "РЕШКА"
- 63. Тогда: Если случайная величина ξn принимает значения 0,1,..., п, и для величины р ∈ (0,1) выполняется
- 65. Закон больших чисел Допустим, что в схеме испытаний Бернулли вероятность успеха равна р, а случайная величина
- 66. Парадокс дней рождений Рассмотрим следующую задачу: для произвольной функции f : X • Y, где Y
- 67. Можно предположить, что вычисление функции в этой задаче порождает п разных и равновероятных точек. Эти вычисления
- 68. Цвет второго шара не должен совпадать с цветом первого шара, поэтому вероятность того, что у2≠y1, равна
- 69. Итак: Полученное число представляет собой вероятность извлечь к шаров без коллизии. Следовательно, вероятность возникновения по крайней
- 70. Приравнивая эту величину к числу ε, получаем: Итак, для случайной функции, отображающей множество X на множество
- 71. Если ε = 1/2, то: Зависимость числа к от величины п означает, что для случайной функции,
- 72. Например, если квадратный корень, извлеченный из размера фрагмента данных (скажем, криптографического ключа или сообщения), скрытого в
- 73. Иначе говоря, для того, чтобы с вероятностью более 50% обнаружить двух людей, родившихся в один и
- 74. Применение парадокса дней рождений: алгоритм кенгуру Полларда для индексных вычислений Пусть р — простое число. При
- 75. Эта функция широко применяется в криптографии, поскольку она является однонаправленной: вычислить у = f(x) очень легко,
- 76. Однако, если число не слишком велико (например, если b — а ≈ 2100, то ≈ 250,
- 77. Поллард описал свой алгоритм, используя в качестве персонажей двух кенгуру — домашнего, Т, и дикого, W.
- 78. Каждый раз один из кенгуру прыгает на расстояние, которое случайным образом извлекается из множества S, причем
- 79. Допустим, что кенгуру T делает п прыжков, а потом останавливается. Требуется определить, сколько прыжков должен сделать
- 80. Используя это значение, мы можем переписать выражение (3.6.3) для следов кенгуру T в следующем виде: Кенгуру
- 81. Счетчик пути, пройденного кенгуру W, регистрирует величину : Аналогично выражению (3.6.3) выражение (3.6.4) для следов кенгуру
- 82. Именно в этот момент кенгуру Т и W встретятся в одной точке, т.е. кенгуру W попадет
- 83. В соответствии с формулами (3.6.3) и (3.6.4), когда возникает коллизия t(ξ) = w(η), выполняются равенства t(ξ+1)
- 84. После возникновения коллизии выполняется равенство: Отсюда следует, что: Поскольку оба счетчика показывают величины d(m — 1)
- 85. Следует отметить, что описанный алгоритм является вероятностным (probabilistic), т.е. он может не обнаружить коллизию (иначе говоря,
- 87. Математические модели открытого текста Один из естественных подходов к моделированию открытых текстов связан с учетом их
- 90. Эта модель также называется позначной моделью открытого текста. В такой модели открытый текст с1с2...сl имеет вероятность
- 91. где:
- 92. В такой модели открытый текст с1с2…сl имеет вероятность
- 93. Таблица частот биграмм русского языка
- 94. Модели открытого текста более высоких приближений учитывают зависимость каждого знака от большего числа предыдущих знаков. Чем
- 95. Проводились эксперименты по моделированию открытых текстов с помощью ЭВМ. (Позначная модель) алисъ проситете пригнуть стречи разве
- 97. Скачать презентацию

В нашем варианте машина Тьюринга состоит из управляющего устройства с конечным
В нашем варианте машина Тьюринга состоит из управляющего устройства с конечным

Каждая головка имеет доступ к своей ленте и может перемещаться вдоль
Каждая головка имеет доступ к своей ленте и может перемещаться вдоль

Каждый символ занимает одну ячейку, а оставшиеся ячейки ленты, расположенные справа,
Каждый символ занимает одну ячейку, а оставшиеся ячейки ленты, расположенные справа,

В каждый момент времени только одна из головок имеет доступ к
В каждый момент времени только одна из головок имеет доступ к

Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует
Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует

Исходные данные, распознаваемые машиной Тьюринга, называются предложением (instance) распознаваемого языка (language).
Для
Исходные данные, распознаваемые машиной Тьюринга, называются предложением (instance) распознаваемого языка (language).
Для

Количество тактов Тм, которые машина Тьюринга М должна выполнить при распознавании
Количество тактов Тм, которые машина Тьюринга М должна выполнить при распознавании

Легко видеть, что Тм(п) ≥ п.
Кроме временных ограничений, машина М
Легко видеть, что Тм(п) ≥ п.
Кроме временных ограничений, машина М

Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует
Если машина начинает работу с начального состояния, последовательно выполняет такты, сканирует

Детерминированное полиномиальное время
Функция р(п) является полиномиальной по целому аргументу п, если
Детерминированное полиномиальное время
Функция р(п) является полиномиальной по целому аргументу п, если

Определение : Класс .
Символом обозначается класс языков, имеющих следующие
Определение : Класс .
Символом обозначается класс языков, имеющих следующие

Языки, распознаваемые за полиномиальное время, считаются "всегда простыми", а полиномиальные машины
Языки, распознаваемые за полиномиальное время, считаются "всегда простыми", а полиномиальные машины

В работах, посвященных теории вычислительной сложности, задача считается решенной, только если
В работах, посвященных теории вычислительной сложности, задача считается решенной, только если
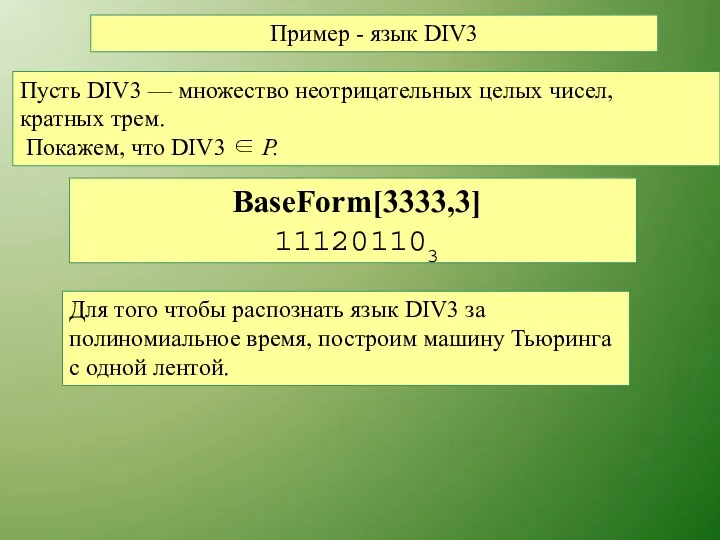
Пример - язык DIV3
Пусть DIV3 — множество неотрицательных целых чисел,
кратных
Пример - язык DIV3
Пусть DIV3 — множество неотрицательных целых чисел,
кратных
1
1
1
1
1
2
0
0
Блок
управления
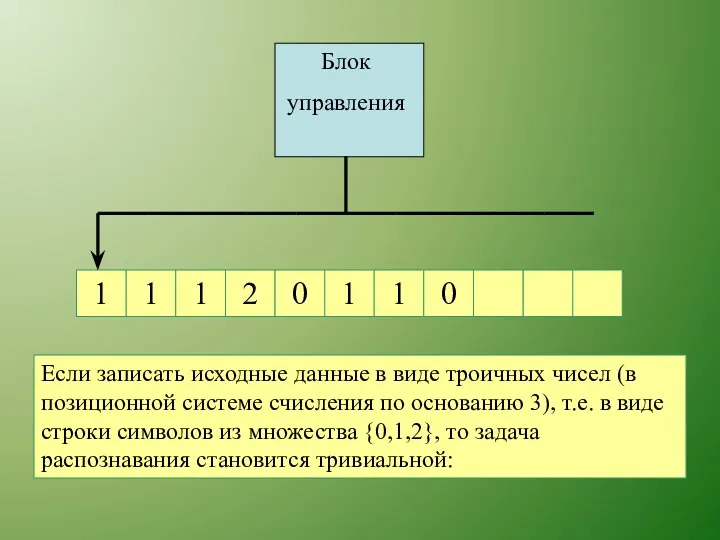
Если записать исходные данные в виде троичных чисел (в позиционной
1
1
1
1
1
2
0
0
Блок
управления
Если записать исходные данные в виде троичных чисел (в позиционной
1
1
1
1
1
2
0
0
Блок
управления
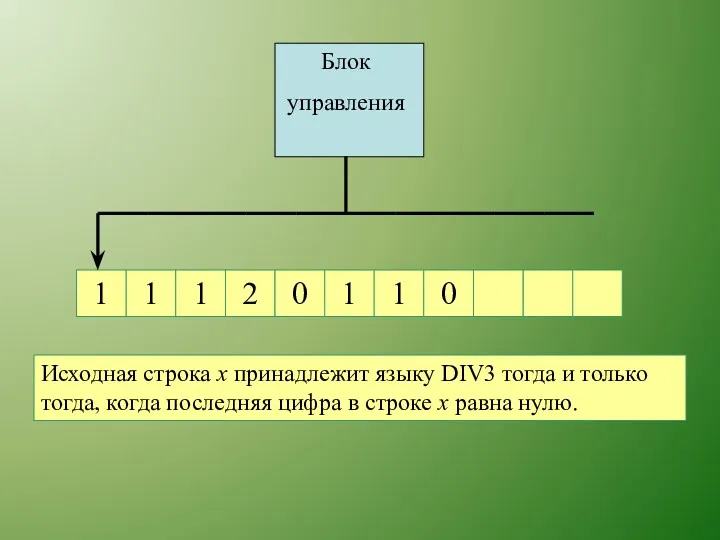
Исходная строка х принадлежит языку DIV3 тогда и только тогда,
1
1
1
1
1
2
0
0
Блок
управления
Исходная строка х принадлежит языку DIV3 тогда и только тогда,
1
1
1
1
1
2
0
0
Блок
управления
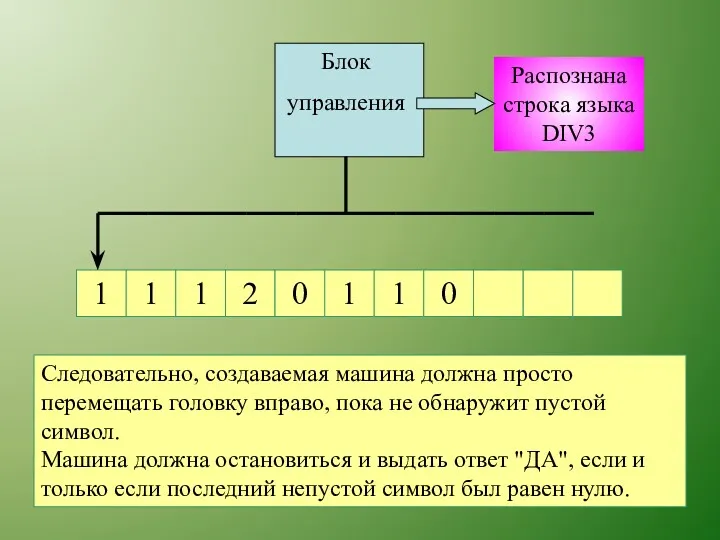
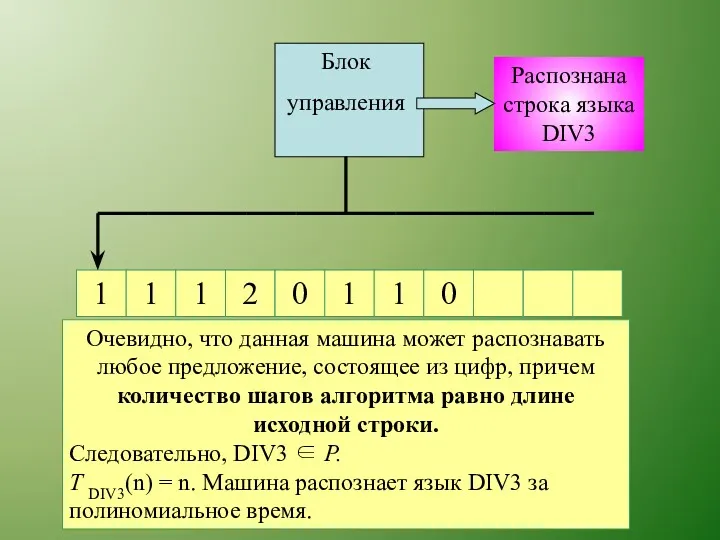
Распознана строка языка DIV3
Следовательно, создаваемая машина должна просто перемещать головку
1
1
1
1
1
2
0
0
Блок
управления
Распознана строка языка DIV3
Следовательно, создаваемая машина должна просто перемещать головку
1
1
1
1
1
2
0
0
Блок
управления
Распознана строка языка DIV3
Очевидно, что данная машина может распознавать любое
1
1
1
1
1
2
0
0
Блок
управления
Распознана строка языка DIV3
Очевидно, что данная машина может распознавать любое

Полиномиальные вычислительные задачи
По определению класс является классом языков, распознаваемых за
Полиномиальные вычислительные задачи
По определению класс является классом языков, распознаваемых за

Вычислительное устройство, имеющее неймановскую архитектуру (иначе говоря, всем известную современную компьютерную
Вычислительное устройство, имеющее неймановскую архитектуру (иначе говоря, всем известную современную компьютерную

Можно доказать ,что каждую микрокоманду из указанного выше набора, можно имитировать
Можно доказать ,что каждую микрокоманду из указанного выше набора, можно имитировать

-символика
(order notation)
Символом (f(n)) обозначается функция g(п), для которой существует константа
-символика
(order notation)
Символом (f(n)) обозначается функция g(п), для которой существует константа

Теорема.
Наибольший общий делитель gcd(a, b) можно вычислить с помощью не
Теорема.
Наибольший общий делитель gcd(a, b) можно вычислить с помощью не

Таким образом, временная сложность алгоритма вычисления наибольшего общего делителя ( при
Таким образом, временная сложность алгоритма вычисления наибольшего общего делителя ( при

В рамках модели поразрядных вычислений на сложение и вычитание двух целых
В рамках модели поразрядных вычислений на сложение и вычитание двух целых

Поразрядные оценки сложности основных операций в модулярной арифметике
Поразрядные оценки сложности основных операций в модулярной арифметике

Недетерминированное полиномиальное время
Недетерминированной машиной Тьюринга (non-deterministic Turing machine) называется устройство, на
Недетерминированное полиномиальное время
Недетерминированной машиной Тьюринга (non-deterministic Turing machine) называется устройство, на

Работу недетерминированной машины Тьюринга можно представить в виде серии догадок.
В
Работу недетерминированной машины Тьюринга можно представить в виде серии догадок.
В

Размер (количество узлов) этого дерева экспоненциально зависит от размера входа.
Однако,
Размер (количество узлов) этого дерева экспоненциально зависит от размера входа.
Однако,

Итак, временная сложность распознавания строки с помощью серии правильных догадок полиномиально
Итак, временная сложность распознавания строки с помощью серии правильных догадок полиномиально
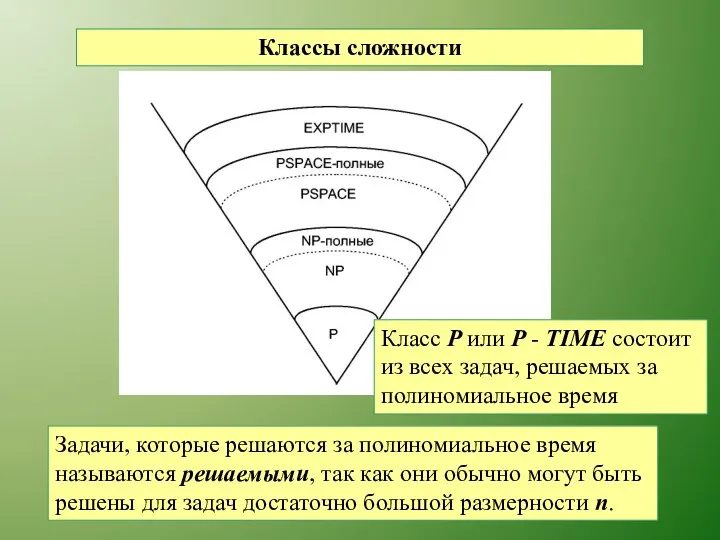
Классы сложности
Задачи, которые решаются за полиномиальное время называются решаемыми, так как
Классы сложности
Задачи, которые решаются за полиномиальное время называются решаемыми, так как
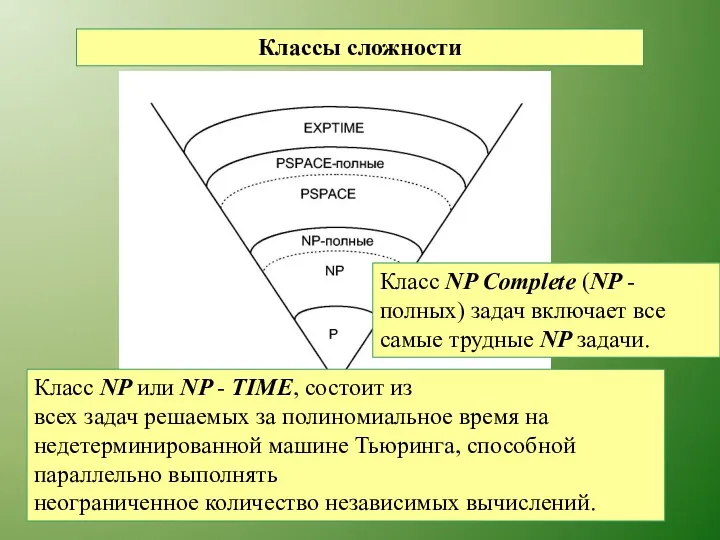
Классы сложности
Класс NP или NP - TIME, состоит из
всех задач решаемых
Классы сложности
Класс NP или NP - TIME, состоит из
всех задач решаемых
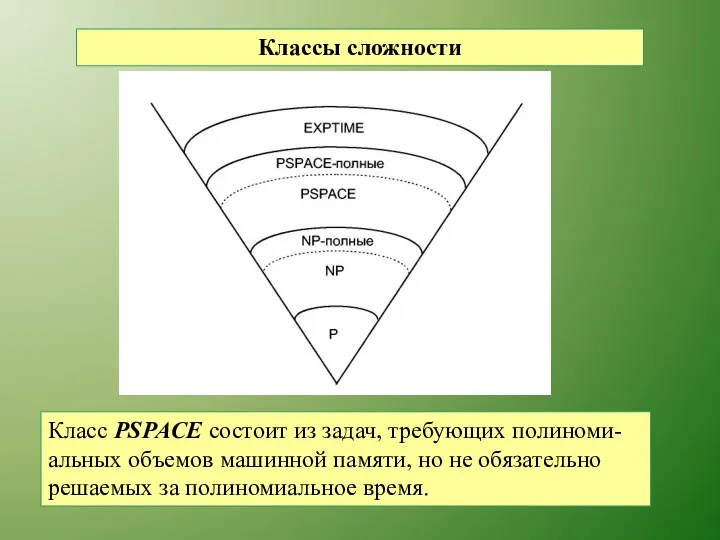
Классы сложности
Класс PSPACE состоит из задач, требующих полиноми-
альных объемов машинной памяти,
Классы сложности
Класс PSPACE состоит из задач, требующих полиноми-
альных объемов машинной памяти,
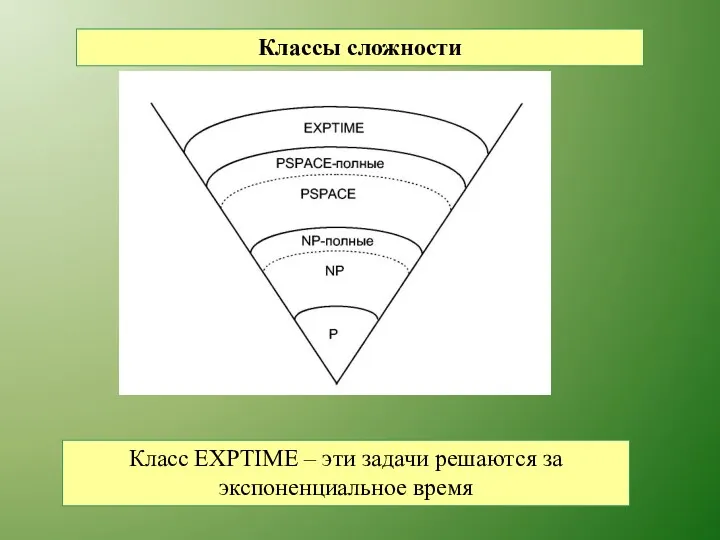
Классы сложности
Класс EXPTIME – эти задачи решаются за экспоненциальное время
Классы сложности
Класс EXPTIME – эти задачи решаются за экспоненциальное время

Классы сложности
Таким образом, выбор наиболее сложных задач, для которых известно решение,
Классы сложности
Таким образом, выбор наиболее сложных задач, для которых известно решение,

Основные понятия теории вероятностей
Пусть S — произвольное, но фиксированное множество точек,
Основные понятия теории вероятностей
Пусть S — произвольное, но фиксированное множество точек,

Событие (составное, или разложимое)
является подмножеством множества S и обычно
Событие (составное, или разложимое)
является подмножеством множества S и обычно

Событие (составное, или разложимое)
является подмножеством множества S и обычно
Событие (составное, или разложимое)
является подмножеством множества S и обычно

1. S1: пространство состоит из 52 точек — по одной на
1. S1: пространство состоит из 52 точек — по одной на

Классическое определение вероятности.
Допустим, что в ходе эксперимента извлекается одна из
Классическое определение вероятности.
Допустим, что в ходе эксперимента извлекается одна из
![В примере вероятности событий E1,E2,E3 таковы: Prob[E1] = 4/52 Prob[E2] = 1/2 Prob[E3] = 9/13](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/299582/slide-41.jpg)
В примере вероятности событий E1,E2,E3 таковы:
Prob[E1] = 4/52
Prob[E2] = 1/2
Prob[E3] =
В примере вероятности событий E1,E2,E3 таковы:
Prob[E1] = 4/52
Prob[E2] = 1/2
Prob[E3] =

Статистическое определение вероятности.
Допустим, что при одинаковых условиях проводятся п экспериментов, в
Статистическое определение вероятности.
Допустим, что при одинаковых условиях проводятся п экспериментов, в

Свойства
1. Поле вероятностей само по себе является достоверным событием (sure event).
Свойства
1. Поле вероятностей само по себе является достоверным событием (sure event).
![3. Вероятность любого события удовлетворяет неравенству: 0 ≤Prob[E] ≤1. 4.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/299582/slide-44.jpg)
3. Вероятность любого события удовлетворяет неравенству:
0 ≤Prob[E] ≤1.
4. Если Е ⊆
3. Вероятность любого события удовлетворяет неравенству:
0 ≤Prob[E] ≤1.
4. Если Е ⊆

Основные вычисления
Обозначим через Е ⋃ F сумму событий Е и F
Основные вычисления
Обозначим через Е ⋃ F сумму событий Е и F

Условная вероятность
Пусть Е u F — два события, причем событие
Условная вероятность
Пусть Е u F — два события, причем событие

Пример. Рассмотрим семьи с двумя детьми. Обозначим буквами g (girl) и
Пример. Рассмотрим семьи с двумя детьми. Обозначим буквами g (girl) и

Определение
Независимые события
События Е и F называются независимыми, тогда и
Определение
Независимые события
События Е и F называются независимыми, тогда и

Событие Е ⋂ F представляет собой точку gg,
поэтому Prob[ Е
Событие Е ⋂ F представляет собой точку gg,
поэтому Prob[ Е

Событие Е ⋂ F представляет собой точку gg,
поэтому Prob[ Е
Событие Е ⋂ F представляет собой точку gg,
поэтому Prob[ Е
![Правила умножения 1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/299582/slide-51.jpg)
Правила умножения
1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F].
2.
Правила умножения
1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F].
2.
![Правила умножения 1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/299582/slide-52.jpg)
Правила умножения
1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F].
2.
Правила умножения
1. Prob[E ⋂ F]= Prob[F|E] × Prob[E] = Prob[E|F]× Prob[F].
2.

Закон полной вероятности
Закон полной вероятности

Случайные величины и распределения вероятностей
Допустим, что дискретное пространство S содержит конечное
Случайные величины и распределения вероятностей
Допустим, что дискретное пространство S содержит конечное

2. Пусть S — дискретное пространство вероятностей, а ξ— случайная величина.
2. Пусть S — дискретное пространство вероятностей, а ξ— случайная величина.

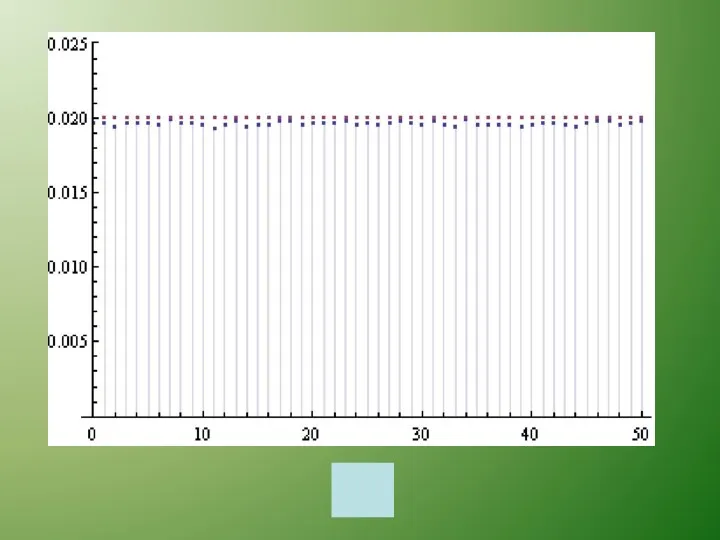
Равномерное распределение
Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение
Равномерное распределение
Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение

Равномерное распределение
Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение
Равномерное распределение
Наиболее часто в криптографии применяются случайные величины, имеющие равномерное распределение

Множество S = {0,1,2,..., 2k - 1} можно разбить на два
Множество S = {0,1,2,..., 2k - 1} можно разбить на два

Множество S = {0,1,2,..., 2k - 1} можно разбить на два
Множество S = {0,1,2,..., 2k - 1} можно разбить на два

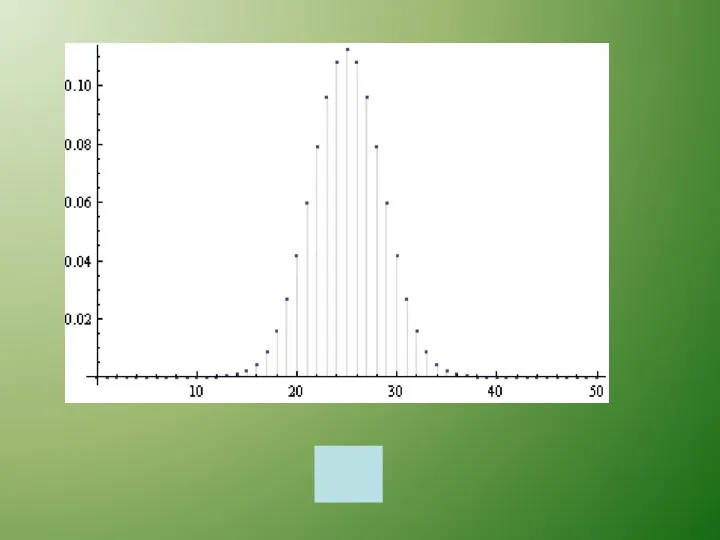
Биномиальное распределение
Допустим, что эксперимент имеет только два исхода
— успех или
Биномиальное распределение
Допустим, что эксперимент имеет только два исхода
— успех или

Тогда:
Если случайная величина ξn принимает значения 0,1,..., п,
и для
Тогда:
Если случайная величина ξn принимает значения 0,1,..., п,
и для

Закон больших чисел
Допустим, что в схеме испытаний Бернулли вероятность успеха равна
Закон больших чисел
Допустим, что в схеме испытаний Бернулли вероятность успеха равна

Парадокс дней рождений
Рассмотрим следующую задачу:
для произвольной функции f : X
Парадокс дней рождений
Рассмотрим следующую задачу:
для произвольной функции f : X

Можно предположить, что вычисление функции в этой задаче порождает п разных
Можно предположить, что вычисление функции в этой задаче порождает п разных

Цвет второго шара не должен совпадать с цветом первого шара, поэтому
Цвет второго шара не должен совпадать с цветом первого шара, поэтому

Итак:
Полученное число представляет собой вероятность извлечь к шаров без коллизии.
Следовательно,
Итак:
Полученное число представляет собой вероятность извлечь к шаров без коллизии.
Следовательно,

Приравнивая эту величину к числу ε, получаем:
Итак, для случайной функции, отображающей
Приравнивая эту величину к числу ε, получаем:
Итак, для случайной функции, отображающей

Если ε = 1/2, то:
Зависимость числа к от величины п означает,
Если ε = 1/2, то:
Зависимость числа к от величины п означает,

Например, если квадратный корень, извлеченный из размера фрагмента данных (скажем, криптографического
Например, если квадратный корень, извлеченный из размера фрагмента данных (скажем, криптографического

Иначе говоря, для того, чтобы с вероятностью более 50% обнаружить двух
Иначе говоря, для того, чтобы с вероятностью более 50% обнаружить двух

Применение парадокса дней рождений:
алгоритм кенгуру Полларда для индексных вычислений
Пусть р
Применение парадокса дней рождений:
алгоритм кенгуру Полларда для индексных вычислений
Пусть р

Эта функция широко применяется в криптографии, поскольку она является однонаправленной:
вычислить
Эта функция широко применяется в криптографии, поскольку она является однонаправленной:
вычислить

Однако, если число не слишком велико (например, если b — а
Однако, если число не слишком велико (например, если b — а

Поллард описал свой алгоритм, используя в качестве персонажей двух кенгуру —
Поллард описал свой алгоритм, используя в качестве персонажей двух кенгуру —

Каждый раз один из кенгуру прыгает на расстояние, которое случайным образом
Каждый раз один из кенгуру прыгает на расстояние, которое случайным образом

Допустим, что кенгуру T делает п прыжков, а потом останавливается.
Требуется
Допустим, что кенгуру T делает п прыжков, а потом останавливается.
Требуется

Используя это значение, мы можем переписать выражение (3.6.3) для следов кенгуру
Используя это значение, мы можем переписать выражение (3.6.3) для следов кенгуру

Счетчик пути, пройденного кенгуру W, регистрирует величину :
Аналогично выражению (3.6.3) выражение
Счетчик пути, пройденного кенгуру W, регистрирует величину :
Аналогично выражению (3.6.3) выражение

Именно в этот момент кенгуру Т и W встретятся в одной
Именно в этот момент кенгуру Т и W встретятся в одной

В соответствии с формулами (3.6.3) и (3.6.4), когда возникает коллизия t(ξ)
В соответствии с формулами (3.6.3) и (3.6.4), когда возникает коллизия t(ξ)

После возникновения коллизии выполняется равенство:
Отсюда следует, что:
Поскольку оба счетчика показывают величины
После возникновения коллизии выполняется равенство:
Отсюда следует, что:
Поскольку оба счетчика показывают величины

Следует отметить, что описанный алгоритм является вероятностным (probabilistic), т.е. он может
Следует отметить, что описанный алгоритм является вероятностным (probabilistic), т.е. он может


Математические модели открытого текста
Один из естественных подходов к моделированию открытых текстов
Математические модели открытого текста
Один из естественных подходов к моделированию открытых текстов



Эта модель также называется позначной моделью открытого текста.
В такой модели
Эта модель также называется позначной моделью открытого текста.
В такой модели

где:
где:
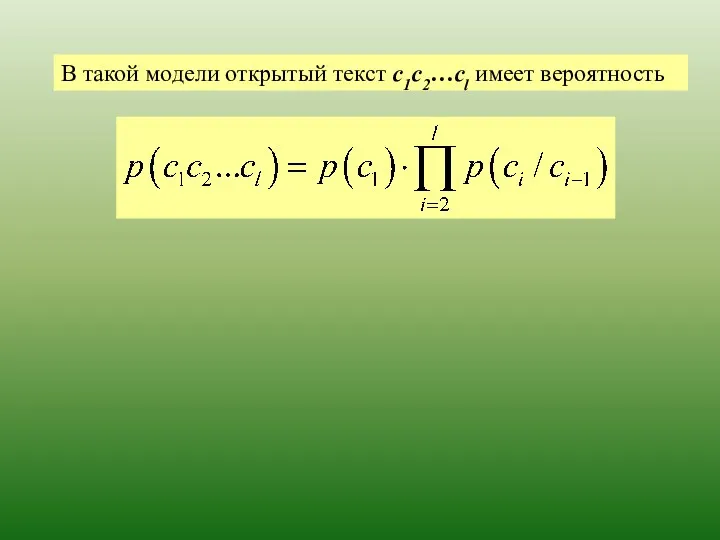
В такой модели открытый текст с1с2…сl имеет вероятность
В такой модели открытый текст с1с2…сl имеет вероятность
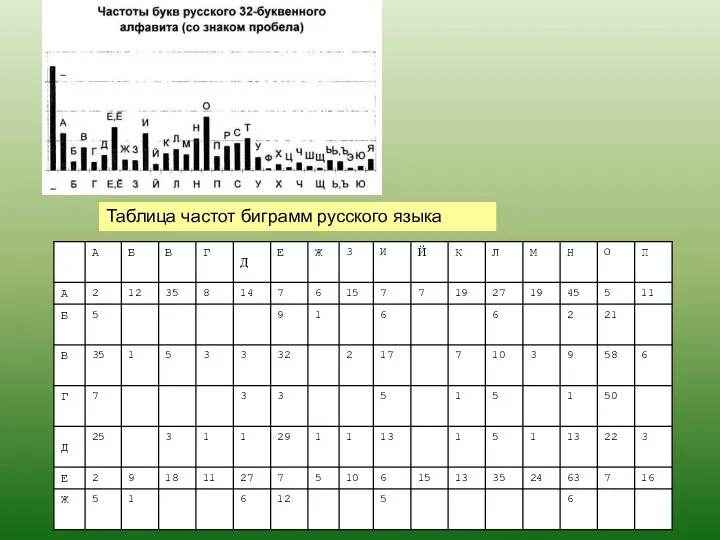
Таблица частот биграмм русского языка
Таблица частот биграмм русского языка

Модели открытого текста более высоких приближений учитывают зависимость каждого знака от
Модели открытого текста более высоких приближений учитывают зависимость каждого знака от

Проводились эксперименты по моделированию открытых текстов с помощью ЭВМ.
(Позначная модель) алисъ
Проводились эксперименты по моделированию открытых текстов с помощью ЭВМ.
(Позначная модель) алисъ
 Счет до 5 (в стихах)
Счет до 5 (в стихах) Линейные уравнения с одной переменной
Линейные уравнения с одной переменной Линейное уравнение с одной переменной
Линейное уравнение с одной переменной Квадратный корень из дроби
Квадратный корень из дроби Алгебра логики. Основные понятия
Алгебра логики. Основные понятия Закрепление изученного материала, решение выражений и задач
Закрепление изученного материала, решение выражений и задач Системная подготовка к ЕГЭ на уроках математики
Системная подготовка к ЕГЭ на уроках математики Metode numerice (curs 3)
Metode numerice (curs 3) Прямоугольник. Площадь прямоугольника
Прямоугольник. Площадь прямоугольника Движение по окружности. Задачи на ЕГЭ
Движение по окружности. Задачи на ЕГЭ Свойства и признаки параллельных прямых
Свойства и признаки параллельных прямых Тригонометрия. Единичная окружность. Определение синуса и косинуса угла. Тригонометрические тождества и формулы
Тригонометрия. Единичная окружность. Определение синуса и косинуса угла. Тригонометрические тождества и формулы Измерение углов. Задания для устного счета. Упражнение 4. 7 класс
Измерение углов. Задания для устного счета. Упражнение 4. 7 класс Уравнение. Решение задач
Уравнение. Решение задач Scientific Calculators
Scientific Calculators Интегрирование по частям
Интегрирование по частям Метод кейсов
Метод кейсов Тренажёр (табличное умножение) В сказочном лесу
Тренажёр (табличное умножение) В сказочном лесу Регрессионный анализ. Метод наименьших квадратов
Регрессионный анализ. Метод наименьших квадратов Леонард Эйлер
Леонард Эйлер Замечательные точки треугольника
Замечательные точки треугольника Координаты на прямой
Координаты на прямой задачи с величинами
задачи с величинами Умножение одночленов. Возведение одночлена в степень
Умножение одночленов. Возведение одночлена в степень Длина окружности
Длина окружности Умножение десятичных дробей на натуральное число
Умножение десятичных дробей на натуральное число Тела вращения. Геометрия
Тела вращения. Геометрия Искусственные нейронные сети
Искусственные нейронные сети