Статистические методы в психологии. Введение в дисциплину. Понятие измерения. Виды измерительных шкал. Описательные статистики презентация
- Статистические методы в психологии. Введение в дисциплину. Понятие измерения. Виды измерительных шкал. Описательные статистики

Содержание
- 2. Дисциплина «Статистические методы в психологии» Цель курса: научиться грамотному использованию методов статистической обработки результатов экспериментальных, научно-практических
- 3. Математические методы в психологическом исследовании Научная проверка гипотез экспериментального психологического исследования возможна лишь с привлечением методов
- 4. Математические методы в психологическом исследовании Для их корректного и результативного использования необходимо: 1) организовать психологическое исследование
- 5. Объект, предмет, свойство, признак, измерение… Следует различать объекты исследования (например, испытуемые с определенными характеристиками), их свойства
- 6. Объект, предмет, свойство, признак, измерение… Любое исследование в зависимости от того, насколько надежны полученные в нем
- 7. Особенности статистического описания и метода Статистическое описание совокупности объектов занимает промежуточное положение между индивидуальным описанием каждого
- 8. Особенности статистического описания и метода Обычно применение статистического метода предусматривает: 1) подсчёт числа объектов, входящих в
- 9. Особенности статистического описания и метода Психологическое исследование обычно начинается с некоторой гипотезы, требующей проверки с привлечением
- 10. Генеральная совокупность и выборка Генеральная совокупность – это все множество объектов, в отношении которого формулируется исследовательская
- 11. Генеральная совокупность и выборка Таким образом, после того, как сформулирована гипотеза и определены соответствующие генеральные совокупности,
- 12. Репрезентативность выборки Приемы, позволяющие получить достаточную репрезентативность выборки: Простой случайный (рандомизированный) отбор. Он предполагает обеспечение таких
- 13. Статистическая достоверность (значимость) Статистическая достоверность (значимость) результатов исследования определяется при помощи методов статистического вывода (рассмотрим это
- 14. Зависимые и независимые выборки Обычна ситуация исследования, когда интересующее исследователя свойство изучается на двух или более
- 15. Обзор классификаций признаков Качественные, количественные. Метрические, неметрические. Принадлежность к одной из шкал: Номинативная, порядковая, интервальная, абсолютная.
- 16. Различные шкалы в психологических исследованиях В зависимости от того, какая операция лежит в основе измерения признака,
- 17. Различные шкалы в психологических исследованиях Порядковая (ранговая) шкала (относится к неметрическим шкалам). Измерение в этой шкале
- 18. Различные шкалы в психологических исследованиях Интервальная шкала (относится к метрическим шкалам). При таком измерении числа отражают
- 19. Различные шкалы в психологических исследованиях Шкала отношений или абсолютная шкала (относится к метрическим шкалам). Отличается от
- 20. Различные шкалы в психологических исследованиях Определение того, в какой шкале измерено явление – первостепенный момент анализа
- 21. Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода) Выявление различий в уровне исследуемого
- 22. Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода) 3. Выявление различий в распределении
- 23. Упражнения Определите, в какой шкале представлено каждое из приведенных ниже измерений: номинативной, порядковой, интервальной, отношений? Обоснуйте
- 24. Упражнения Определите, к какому типу задач на сопоставление следует отнести нижеперечисленные задачи и почему? Установить эффективность
- 25. Научно-исследовательская работа: помощь, участие, направления квалификационных (курсовых, дипломных) работ, выполняемых под руководством профессора Григорьева Павла Евгеньевича
- 26. Вопросы для проработки и самостоятельного изучения Понятие измерения. Виды измерительных шкал и свойства психологических объектов измерения.
- 27. Рекомендованная для закрепления материала лекций литература Р. Майкл Фер, Верн Р. Бакарак. Психометрика: Введение; пер. с
- 28. Способы представления исходных данных Хотя существуют различные способы представления исходных данных (табличный, графический, аналитический) в математической
- 29. Вариационный ряд, частоты
- 30. Вариационный ряд, ранжирование Предположим, что исследователя в нашем примере интересует распределение уровня интеллекта учащихся. Для этого
- 31. Вариационный ряд, ранжирование
- 32. Таблицы распределения накопленных частот
- 33. Гистограмма
- 34. Описательные статистики
- 35. Меры центральной тенденции
- 36. Меры центральной тенденции
- 37. Меры положения
- 38. Меры изменчивости
- 39. Меры изменчивости, стандартизация
- 40. Стандартизированные шкалы, асимметрия
- 41. Асимметрия
- 42. Эксцесс
- 43. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ Нормальный закон распределения играет важнейшую роль в применении
- 44. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ Полигон частот для роста 8585 взрослых людей, родившихся
- 45. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ В дальнейшем трудами Ф. Гальтона и его последователей
- 46. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
- 47. Упражнение
- 48. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ Рассмотрим свойства нормального распределения. 1) Единицей измерения единичного
- 49. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
- 50. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ Полезно помнить, что для любого нормального распределения существуют
- 51. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ Несмотря на исходный постулат, в соответствии с которым
- 52. Разработка тестовых шкал Разработка тестовых шкал. Тестовые шкалы разрабатываются для того, чтобы оценить индивидуальный результат тестирования
- 53. Разработка тестовых шкал Исходные тестовые оценки — это количество ответов на те или иные вопросы теста,
- 54. Некоторые из известных равноинтервальных шкал в психологии
- 55. Последовательность стандартизации – разработки тестовых норм Общая последовательность стандартизации (разработки тестовых норм — таблицы пересчета «сырых»
- 56. Вопросы для проработки и самостоятельного изучения 1. Первичные описательные статистики. Меры центральной тенденции: среднее арифметическое. Преимущества
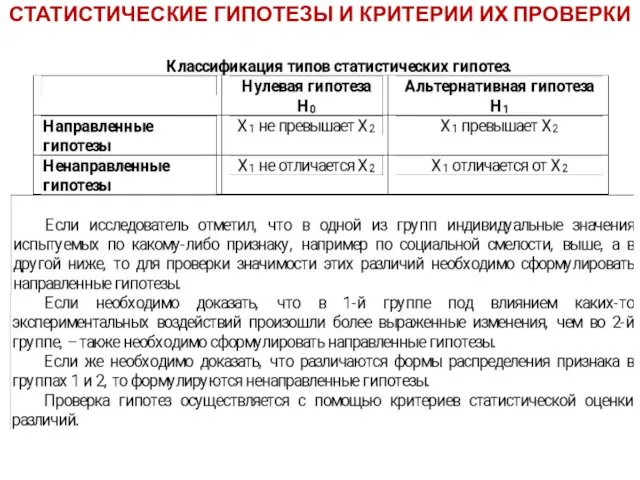
- 58. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Формулирование гипотез систематизирует предположения исследователя и представляет их в четком
- 59. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
- 60. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Статистические критерии. Статистический критерий – это решающее правило, обеспечивающее принятие
- 61. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ В большинстве случаев для того, чтобы мы признали различия статистически
- 62. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Критерии делятся на параметрические и непараметрические. Параметрические критерии включают в
- 63. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Уровни статистической значимости. Уровень значимости – это вероятность того, что
- 64. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Исторически сложилось так, что в психологии принято считать низшим уровнем
- 65. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ Мощность критерия – это его способность выявлять различия, если они
- 66. Статистическая мощность Величина мощности при проверке статистической гипотезы зависит от следующих факторов: величины уровня значимости, обозначаемого
- 67. Размер эффекта Величина эффекта определяет вероятность совершения ошибки второго рода. Коэффициент величины эффекта называется мерой эффекта
- 68. Задачи статистического сравнения двух средних или двух частот Возможный алгоритм действий
- 69. Планирование эксперимента: расчет объема выборок МОДУЛЬ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА статистических пакетов позволяют провести оценку размера выборки, достаточной
- 70. Проведение расчетов в модуле «Планирование эксперимента» (пример из программы «Медстат»
- 71. Обоснование задачи сопоставления и сравнения Очень часто перед исследователем в психологии стоит задача выявления различии между
- 72. Обоснование задачи статистической значимости сдвига в значениях исследуемого признака В психологических исследованиях часто бывает важно доказать,
- 73. Обоснование задачи статистической значимости сдвига в значениях исследуемого признака Например, мы можем сделать вывод о том,
- 74. ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
- 75. ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ. Функциональные связи, подобные изображенным на рис. выше, являются идеализациями. Их особенность заключается
- 76. ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ. Если с увеличением (уменьшением) одного признака в основном увеличиваются (уменьшаются) значения другого,
- 77. ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
- 78. ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ. Две эти классификации не совпадают. Первая ориентирована только на величину коэффициента корреляции,
- 79. АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ НЕ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО (ПАРАМЕТРИЧЕСКИЕ ТЕСТЫ). Параметрические тесты (ПТ) предполагают известным
- 80. АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО Непараметрические тесты (НТ) не требуют знания конкретного закона
- 81. АНАЛИЗ КАЧЕСТВЕННЫХ ДАННЫХ (ТАБЛИЦА k*m) Если набор данных показывает, какой из нескольких нечисловых категорий принадлежит каждый
- 82. МОДУЛЬ ОЦЕНКИ ЭФФЕКТА ТЕРАПИИ (ИЛИ ЭФФЕКТИВНОСТИ ИНЫХ МЕТОДОВ) Расчет рисков позволяет провести оценку относительной эффективности двух
- 83. ЧБНЛ: способ оценки относительной эффективности двух методов лечения. Показывает, какое количество больных необходимо подвергнуть лечению определенным
- 84. Некоторые критерии для сравнения выборок Более подробно будут рассмотрены на лабораторных работах. 1. Критерии проверки на
- 85. Некоторые критерии для сравнения выборок 6. Многофункциональные критерии «Угловое преобразование Фишера», «Хи-квадрат Фишера» для независимых выборок,
- 86. Вопросы для проработки и самостоятельного изучения Понятие статистической гипотезы. Сущность проверки статистической гипотезы – установить, согласуются
- 87. Многомерные методы математической статистики в психологии Многомерные методы необходимы для одновременного учета многих переменных (признаков) в
- 88. Кластерный анализ: описание метода В основе кластерного анализа лежит идея классификации объектов и выделения среди этого
- 89. Кластерный анализ: описание метода При проведении кластерного анализа и последующей интерпретации полученных данных нужно учитывать следующие
- 90. Кластерный анализ: описание метода Наиболее часто кластерный анализ используется для обработки данных, полученных методами классификации, репертуарных
- 91. Обработка данных методом кластерного анализа Последовательность проведения кластерного анализа: 1. Отбор объектов для кластеризации. Объектами могут
- 92. Последовательность проведения кластерного анализа: 1. Отбор объектов для кластеризации. На данном этапе определяется, какая именно совокупность
- 93. Последовательность проведения кластерного анализа: Вариант графического представления евклидова расстояния в трехмерном пространстве показан на рисунке.
- 94. Последовательность проведения кластерного анализа: Коэффициент корреляции – двухмерная описательная статистика, количественная мера взаимосвязи (совместной изменчивости) двух
- 95. Последовательность проведения кластерного анализа: Таким образом, кластеры, уровень связи в которых от 0 до 0,368, будут
- 96. Последовательность проведения кластерного анализа: 4. Выбор и применение метода классификации для создания групп сходных объектов. В
- 97. Последовательность проведения кластерного анализа в статистическом пакете Statistica. В качестве примера описывается пример обработки данных, полученных
- 98. Последовательность проведения кластерного анализа в статистическом пакете Statistica. Данные (только численные данные) переносятся в программу Statisitica:
- 99. Последовательность проведения кластерного анализа в статистическом пакете Statistica. После нажатия на кнопку All Specs… (All Specification)
- 100. Последовательность проведения кластерного анализа в статистическом пакете Statistica. После подготовки данных мы переходим к процедуре кластерного
- 101. Последовательность проведения кластерного анализа в статистическом пакете Statistica. Далее выбираем по умолчанию Joining (tree claustering) Где
- 102. Последовательность проведения кластерного анализа в статистическом пакете Statistica. Для выбора метода кластеризации мы пользуемся строкой Amalgamation
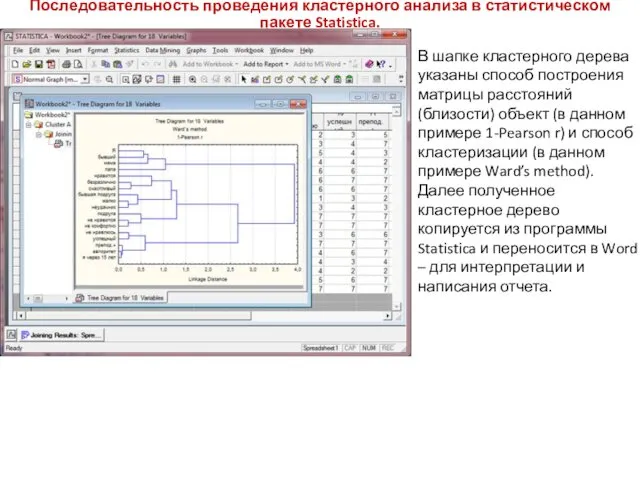
- 103. Последовательность проведения кластерного анализа в статистическом пакете Statistica. В шапке кластерного дерева указаны способ построения матрицы
- 104. Интерпретация результатов кластерного анализа Принципы интерпретации данных: 1. Основная задача кластерного анализа – это объединение объектов
- 105. Интерпретация результатов кластерного анализа Пример интерпретации кластерного дерева. Данные были получены с помощью метода репертуарных решеток
- 106. Интерпретация результатов кластерного анализа При анализе кластерного дерева можно условно выделить пять основных кластеров. Помимо них,
- 107. Интерпретация результатов кластерного анализа Следующий кластер объединяет роли «Успешный человек» и «Комфортный начальник». Можно предположить, что
- 108. Описание метода факторного анализа Факторный анализ является статистическим методом, используемым при обработке больших массивов экспериментальных данных.
- 109. Психологические задачи факторного анализа. Факторный анализ в психологии используется, во-первых, для исследований структуры личности, темперамента и
- 110. Психологические задачи факторного анализа. Например, психолог оценивает случайную выборку студентов по следующим параметрам: V1 – вес
- 111. Психологические задачи факторного анализа. Во-вторых, факторный анализ активно применяется при проведении психосемантических исследований. В этом случае
- 112. Основные понятия факторного анализа. Фактор - это искусственный статистический показатель, возникающий в результате специальных преобразований таблицы
- 113. Основные понятия факторного анализа. В процессе обработки данных необходимо понять, что является особенностями реально присущими категориальной
- 114. Обработка данных методом факторного анализа. Факторный анализ включает в себя следующие этапы : 1. Подготовка исходной
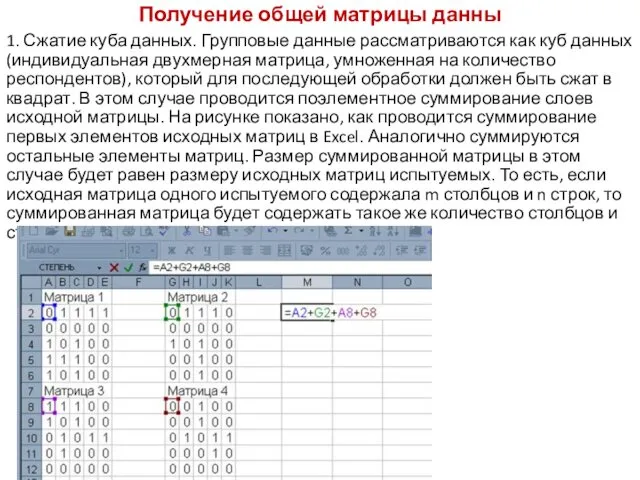
- 115. Получение общей матрицы данны 1. Сжатие куба данных. Групповые данные рассматриваются как куб данных (индивидуальная двухмерная
- 116. Получение общей матрицы данны 2. Метод «растягивания в вереницу». В этом случае исходные матрицы составляются одна
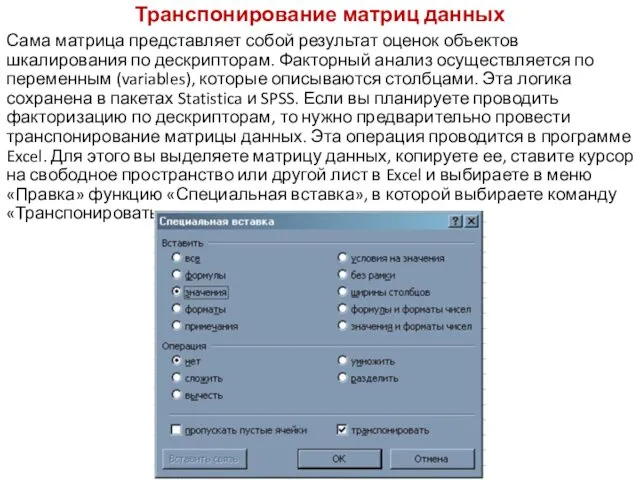
- 117. Транспонирование матриц данных Как правило, факторный анализ используется для обработки данных, полученных с использованием психосемантических методов
- 118. Транспонирование матриц данных Сама матрица представляет собой результат оценок объектов шкалирования по дескрипторам. Факторный анализ осуществляется
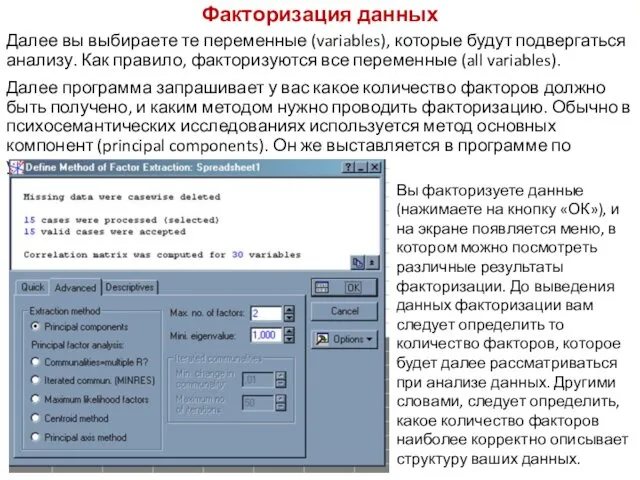
- 119. Факторизация данных На этом этапе вы обрабатываете методом факторного анализа ваши матрицы данных. Как было сказано
- 120. Факторизация данных Далее вы выбираете те переменные (variables), которые будут подвергаться анализу. Как правило, факторизуются все
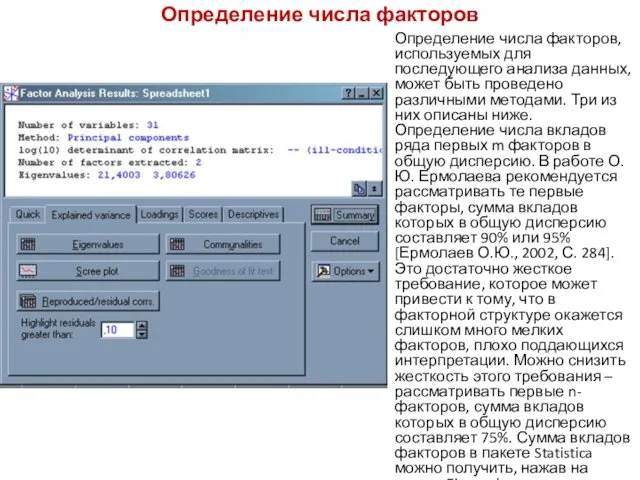
- 121. Определение числа факторов Определение числа факторов, используемых для последующего анализа данных, может быть проведено различными методами.
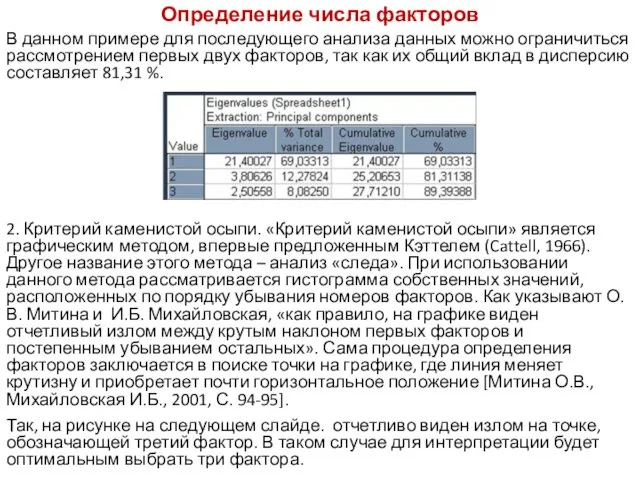
- 122. Определение числа факторов В данном примере для последующего анализа данных можно ограничиться рассмотрением первых двух факторов,
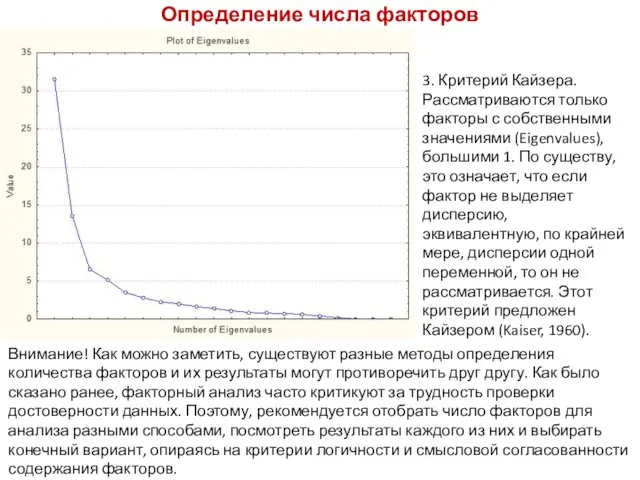
- 123. Определение числа факторов 3. Критерий Кайзера. Рассматриваются только факторы с собственными значениями (Eigenvalues), большими 1. По
- 124. Вращение факторов После того, как определено количество факторов, рассматриваемых для последующего анализа следующая процедура – вращение
- 125. Вращение факторов Внимание! На результаты процедуры вращения (на распределение факторных нагрузок переменных в факторе) оказывает влияние
- 126. Результаты анализа Далее мы можем извлечь результаты факторного анализа из программы. Как правило, нас интересуют три
- 127. Результаты анализа 2. Распределение случаев по полюсам фактора. Эти данные показывают, как распределяются случаи (cases) по
- 128. Результаты анализа 3. Вес факторов в общей дисперсии (% Total variance). Распределение факторов в общей дисперсии
- 129. Результаты анализа 3. Интерпретация данных, полученных методом факторного анализа Интерпретация данных, полученных методом факторного анализа, выступает
- 130. Результаты анализа 3. Содержательно полученные факторы интерпретируются исходя из того, какие именно переменные (в психосемантике –
- 131. Результаты анализа Хотя достаточно жесткого правила здесь нет. И выбор, с какого момента перестать включать дескрипторы
- 132. Рекомендованные к использованию в рамках дисциплины статистические компьютерные пакеты Не поленитесь установить эти пакеты, каждый из
- 134. Скачать презентацию

Дисциплина «Статистические методы в психологии»
Цель курса: научиться грамотному использованию методов статистической
Дисциплина «Статистические методы в психологии»
Цель курса: научиться грамотному использованию методов статистической

Математические методы в психологическом исследовании
Научная проверка гипотез экспериментального психологического исследования возможна
Математические методы в психологическом исследовании
Научная проверка гипотез экспериментального психологического исследования возможна

Математические методы в психологическом исследовании
Для их корректного и результативного использования необходимо:
Математические методы в психологическом исследовании
Для их корректного и результативного использования необходимо:

Объект, предмет, свойство, признак, измерение…
Следует различать объекты исследования (например, испытуемые с
Объект, предмет, свойство, признак, измерение…
Следует различать объекты исследования (например, испытуемые с

Объект, предмет, свойство, признак, измерение…
Любое исследование в зависимости от того, насколько
Объект, предмет, свойство, признак, измерение…
Любое исследование в зависимости от того, насколько

Особенности статистического описания и метода
Статистическое описание совокупности объектов занимает промежуточное положение
Особенности статистического описания и метода
Статистическое описание совокупности объектов занимает промежуточное положение

Особенности статистического описания и метода
Обычно применение статистического метода предусматривает:
1) подсчёт
Особенности статистического описания и метода
Обычно применение статистического метода предусматривает:
1) подсчёт

Особенности статистического описания и метода
Психологическое исследование обычно начинается с некоторой гипотезы,
Особенности статистического описания и метода
Психологическое исследование обычно начинается с некоторой гипотезы,

Генеральная совокупность и выборка
Генеральная совокупность – это все множество объектов, в
Генеральная совокупность и выборка
Генеральная совокупность – это все множество объектов, в

Генеральная совокупность и выборка
Таким образом, после того, как сформулирована гипотеза и
Генеральная совокупность и выборка
Таким образом, после того, как сформулирована гипотеза и

Репрезентативность выборки
Приемы, позволяющие получить достаточную репрезентативность выборки:
Простой случайный (рандомизированный) отбор.
Репрезентативность выборки
Приемы, позволяющие получить достаточную репрезентативность выборки:
Простой случайный (рандомизированный) отбор.

Статистическая достоверность (значимость)
Статистическая достоверность (значимость) результатов исследования определяется при помощи методов
Статистическая достоверность (значимость)
Статистическая достоверность (значимость) результатов исследования определяется при помощи методов

Зависимые и независимые выборки
Обычна ситуация исследования, когда интересующее исследователя свойство изучается
Зависимые и независимые выборки
Обычна ситуация исследования, когда интересующее исследователя свойство изучается

Обзор классификаций признаков
Качественные, количественные.
Метрические, неметрические.
Принадлежность к одной из шкал: Номинативная, порядковая,
Обзор классификаций признаков
Качественные, количественные.
Метрические, неметрические.
Принадлежность к одной из шкал: Номинативная, порядковая,

Различные шкалы в психологических исследованиях
В зависимости от того, какая операция лежит
Различные шкалы в психологических исследованиях
В зависимости от того, какая операция лежит

Различные шкалы в психологических исследованиях
Порядковая (ранговая) шкала (относится к неметрическим шкалам).
Различные шкалы в психологических исследованиях
Порядковая (ранговая) шкала (относится к неметрическим шкалам).

Различные шкалы в психологических исследованиях
Интервальная шкала (относится к метрическим шкалам). При
Различные шкалы в психологических исследованиях
Интервальная шкала (относится к метрическим шкалам). При

Различные шкалы в психологических исследованиях
Шкала отношений или абсолютная шкала (относится к
Различные шкалы в психологических исследованиях
Шкала отношений или абсолютная шкала (относится к

Различные шкалы в психологических исследованиях
Определение того, в какой шкале измерено явление
Различные шкалы в психологических исследованиях
Определение того, в какой шкале измерено явление

Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода)
Выявление
Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода)
Выявление

Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода)
3.
Некоторые элементарные типы задач психологического исследования (с точки зрения статистического метода)
3.

Упражнения
Определите, в какой шкале представлено каждое из приведенных ниже измерений: номинативной,
Упражнения
Определите, в какой шкале представлено каждое из приведенных ниже измерений: номинативной,

Упражнения
Определите, к какому типу задач на сопоставление следует отнести нижеперечисленные задачи
Упражнения
Определите, к какому типу задач на сопоставление следует отнести нижеперечисленные задачи

Научно-исследовательская работа: помощь, участие, направления квалификационных (курсовых, дипломных) работ, выполняемых под
Научно-исследовательская работа: помощь, участие, направления квалификационных (курсовых, дипломных) работ, выполняемых под

Вопросы для проработки и самостоятельного изучения
Понятие измерения.
Виды измерительных шкал и
Вопросы для проработки и самостоятельного изучения
Понятие измерения.
Виды измерительных шкал и

Рекомендованная для закрепления материала лекций литература
Р. Майкл Фер, Верн Р. Бакарак.
Рекомендованная для закрепления материала лекций литература
Р. Майкл Фер, Верн Р. Бакарак.
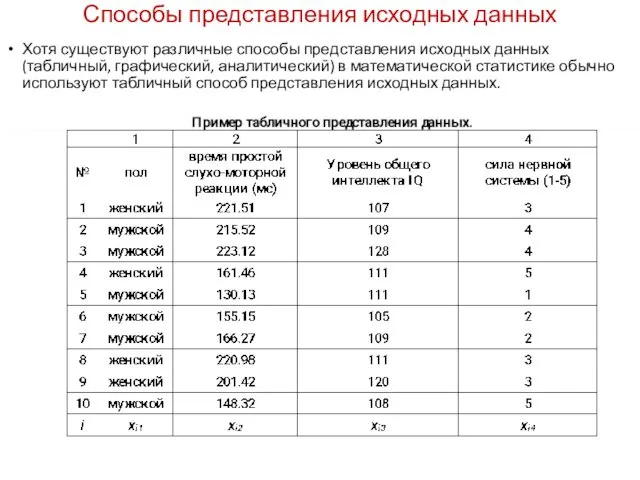
Способы представления исходных данных
Хотя существуют различные способы представления исходных данных (табличный,
Способы представления исходных данных
Хотя существуют различные способы представления исходных данных (табличный,

Вариационный ряд, частоты
Вариационный ряд, частоты

Вариационный ряд, ранжирование
Предположим, что исследователя в нашем примере интересует распределение уровня
Вариационный ряд, ранжирование
Предположим, что исследователя в нашем примере интересует распределение уровня
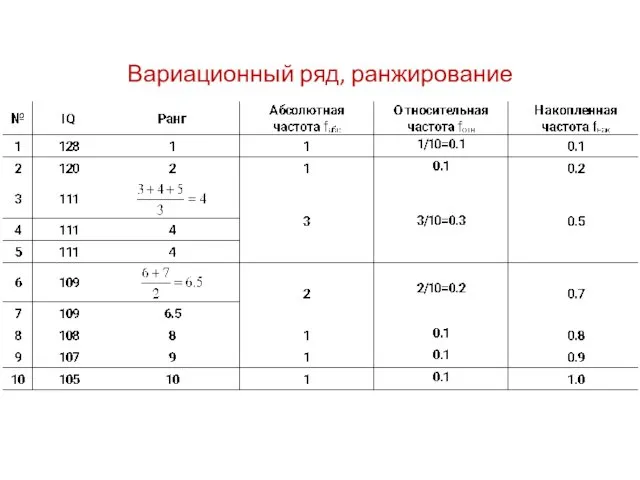
Вариационный ряд, ранжирование
Вариационный ряд, ранжирование

Таблицы распределения накопленных частот
Таблицы распределения накопленных частот
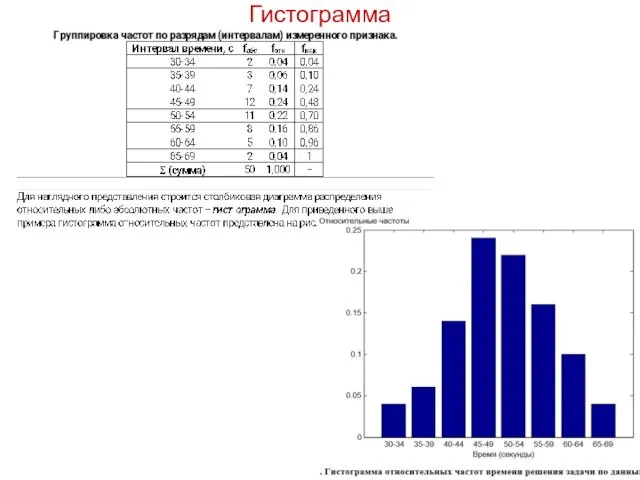
Гистограмма
Гистограмма

Описательные статистики
Описательные статистики

Меры центральной тенденции
Меры центральной тенденции

Меры центральной тенденции
Меры центральной тенденции

Меры положения
Меры положения

Меры изменчивости
Меры изменчивости

Меры изменчивости, стандартизация
Меры изменчивости, стандартизация

Стандартизированные шкалы, асимметрия
Стандартизированные шкалы, асимметрия
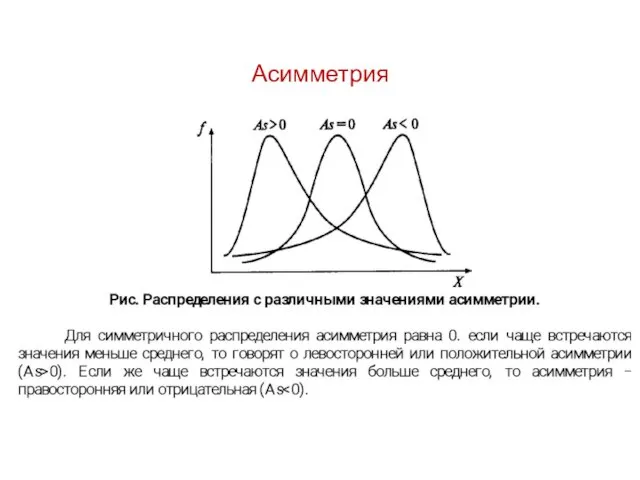
Асимметрия
Асимметрия
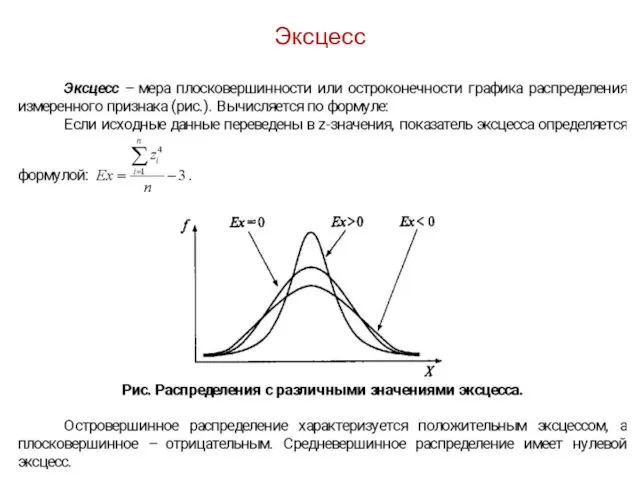
Эксцесс
Эксцесс

НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Нормальный закон распределения играет
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Нормальный закон распределения играет
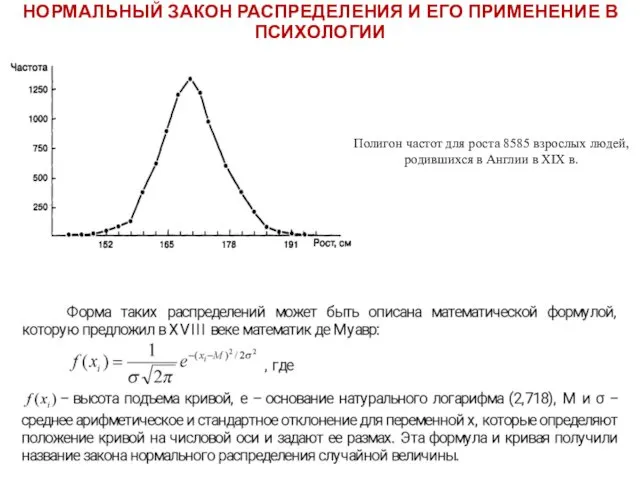
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Полигон частот для роста
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Полигон частот для роста

НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
В дальнейшем трудами Ф.
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
В дальнейшем трудами Ф.
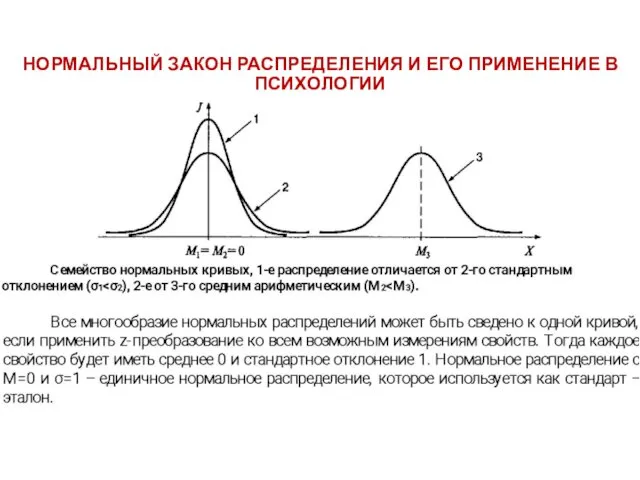
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
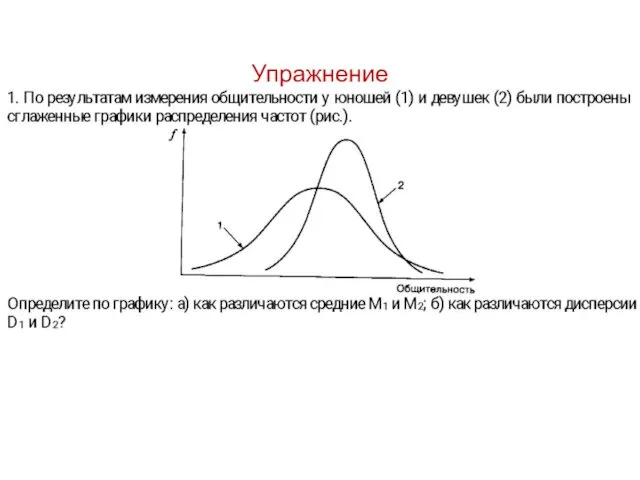
Упражнение
Упражнение

НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Рассмотрим свойства нормального распределения.
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Рассмотрим свойства нормального распределения.
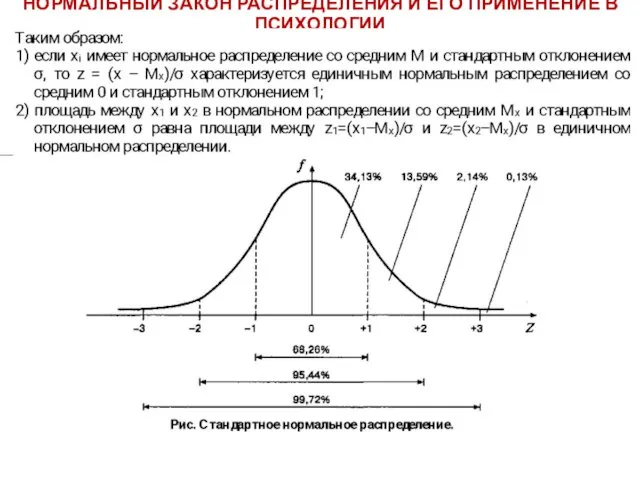
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ

НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Полезно помнить, что для
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Полезно помнить, что для

НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Несмотря на исходный постулат,
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ В ПСИХОЛОГИИ
Несмотря на исходный постулат,

Разработка тестовых шкал
Разработка тестовых шкал. Тестовые шкалы разрабатываются для того, чтобы
Разработка тестовых шкал
Разработка тестовых шкал. Тестовые шкалы разрабатываются для того, чтобы

Разработка тестовых шкал
Исходные тестовые оценки — это количество ответов на те
Разработка тестовых шкал
Исходные тестовые оценки — это количество ответов на те
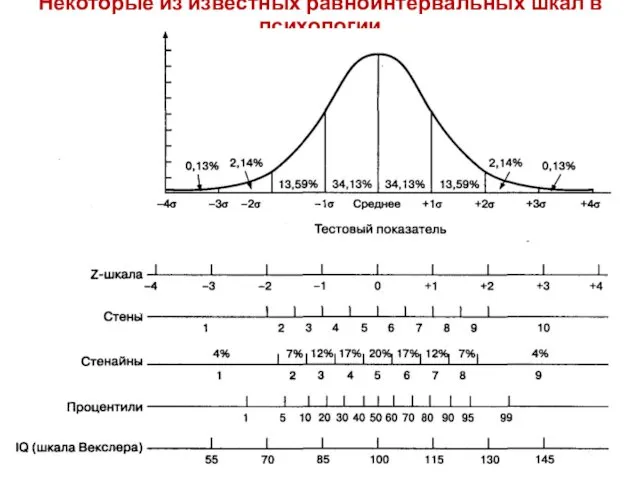
Некоторые из известных равноинтервальных шкал в психологии
Некоторые из известных равноинтервальных шкал в психологии

Последовательность стандартизации – разработки тестовых норм
Общая последовательность стандартизации (разработки тестовых норм
Последовательность стандартизации – разработки тестовых норм
Общая последовательность стандартизации (разработки тестовых норм

Вопросы для проработки и самостоятельного изучения
1. Первичные описательные статистики. Меры центральной
Вопросы для проработки и самостоятельного изучения
1. Первичные описательные статистики. Меры центральной

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Формулирование гипотез систематизирует предположения исследователя и
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Формулирование гипотез систематизирует предположения исследователя и
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Статистические критерии. Статистический критерий – это
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Статистические критерии. Статистический критерий – это

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
В большинстве случаев для того, чтобы
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
В большинстве случаев для того, чтобы

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Критерии делятся на параметрические и непараметрические.
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Критерии делятся на параметрические и непараметрические.

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Уровни статистической значимости. Уровень значимости –
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Уровни статистической значимости. Уровень значимости –

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Исторически сложилось так, что в психологии
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Исторически сложилось так, что в психологии

СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Мощность критерия – это его способность
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ И КРИТЕРИИ ИХ ПРОВЕРКИ
Мощность критерия – это его способность

Статистическая мощность
Величина мощности при проверке статистической гипотезы зависит от следующих факторов:
величины
Статистическая мощность
Величина мощности при проверке статистической гипотезы зависит от следующих факторов:
величины

Размер эффекта
Величина эффекта определяет вероятность совершения ошибки второго рода. Коэффициент величины
Размер эффекта
Величина эффекта определяет вероятность совершения ошибки второго рода. Коэффициент величины
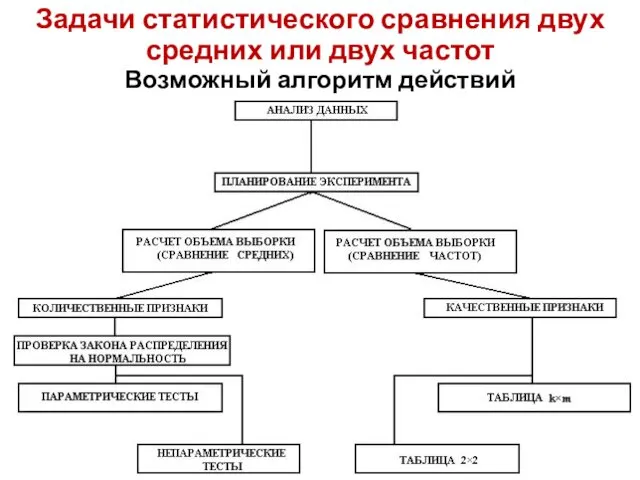
Задачи статистического сравнения двух средних или двух частот
Возможный алгоритм действий
Задачи статистического сравнения двух средних или двух частот
Возможный алгоритм действий
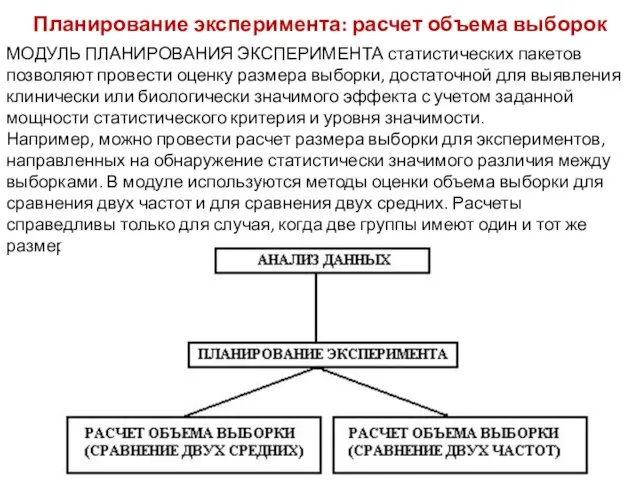
Планирование эксперимента: расчет объема выборок
МОДУЛЬ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА статистических пакетов позволяют провести
Планирование эксперимента: расчет объема выборок
МОДУЛЬ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА статистических пакетов позволяют провести
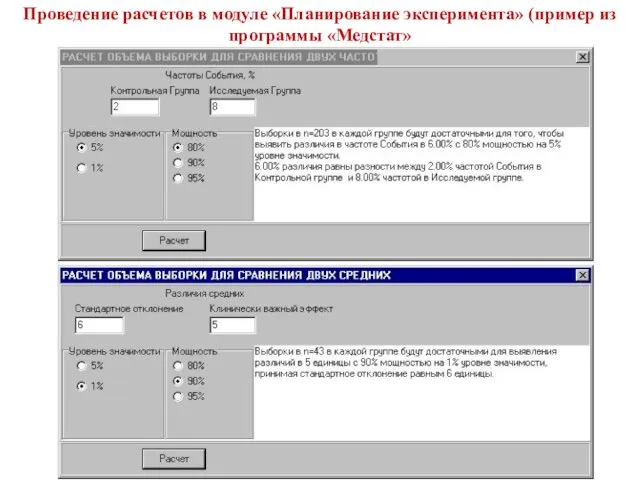
Проведение расчетов в модуле «Планирование эксперимента» (пример из программы «Медстат»
Проведение расчетов в модуле «Планирование эксперимента» (пример из программы «Медстат»

Обоснование задачи сопоставления и сравнения
Очень часто перед исследователем в психологии стоит
Обоснование задачи сопоставления и сравнения
Очень часто перед исследователем в психологии стоит

Обоснование задачи статистической значимости сдвига в значениях исследуемого признака
В психологических исследованиях
Обоснование задачи статистической значимости сдвига в значениях исследуемого признака
В психологических исследованиях

Обоснование задачи статистической значимости сдвига в значениях исследуемого признака
Например, мы можем
Обоснование задачи статистической значимости сдвига в значениях исследуемого признака
Например, мы можем
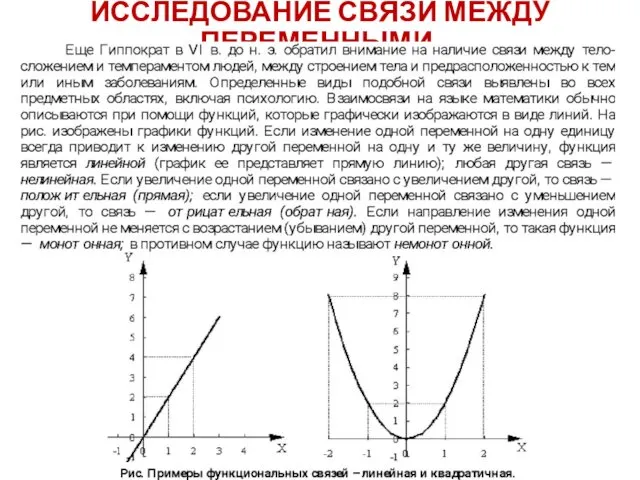
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.

ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Функциональные связи, подобные изображенным на рис. выше,
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Функциональные связи, подобные изображенным на рис. выше,

ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Если с увеличением (уменьшением) одного признака в
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Если с увеличением (уменьшением) одного признака в

ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.

ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Две эти классификации не совпадают. Первая ориентирована
ИССЛЕДОВАНИЕ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ.
Две эти классификации не совпадают. Первая ориентирована

АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ НЕ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО (ПАРАМЕТРИЧЕСКИЕ ТЕСТЫ).
АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ НЕ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО (ПАРАМЕТРИЧЕСКИЕ ТЕСТЫ).

АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО Непараметрические тесты (НТ)
АНАЛИЗ КОЛИЧЕСТВЕННЫХ ДАННЫХ, РАСПРЕДЕЛЕНИЕ КОТОРЫХ ОТЛИЧАЕТСЯ ОТ НОРМАЛЬНОГО Непараметрические тесты (НТ)

АНАЛИЗ КАЧЕСТВЕННЫХ ДАННЫХ (ТАБЛИЦА k*m) Если набор данных показывает, какой из
АНАЛИЗ КАЧЕСТВЕННЫХ ДАННЫХ (ТАБЛИЦА k*m) Если набор данных показывает, какой из

МОДУЛЬ ОЦЕНКИ ЭФФЕКТА ТЕРАПИИ (ИЛИ ЭФФЕКТИВНОСТИ ИНЫХ МЕТОДОВ)
Расчет рисков позволяет провести
МОДУЛЬ ОЦЕНКИ ЭФФЕКТА ТЕРАПИИ (ИЛИ ЭФФЕКТИВНОСТИ ИНЫХ МЕТОДОВ)
Расчет рисков позволяет провести
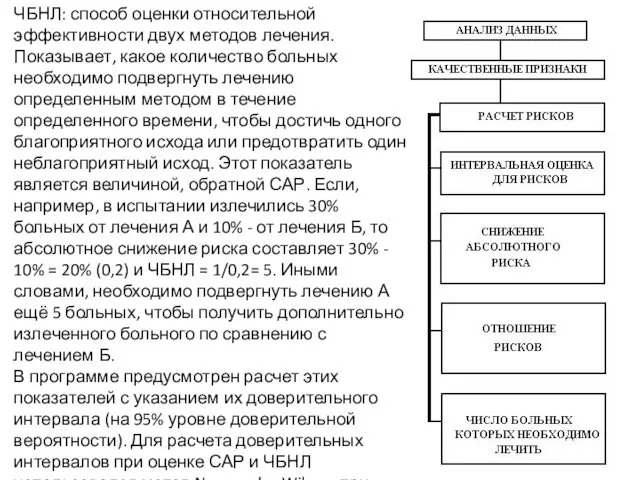
ЧБНЛ: способ оценки относительной эффективности двух методов лечения. Показывает, какое количество
ЧБНЛ: способ оценки относительной эффективности двух методов лечения. Показывает, какое количество

Некоторые критерии для сравнения выборок
Более подробно будут рассмотрены на лабораторных работах.
1.
Некоторые критерии для сравнения выборок
Более подробно будут рассмотрены на лабораторных работах.
1.

Некоторые критерии для сравнения выборок
6. Многофункциональные критерии «Угловое преобразование Фишера», «Хи-квадрат
Некоторые критерии для сравнения выборок
6. Многофункциональные критерии «Угловое преобразование Фишера», «Хи-квадрат

Вопросы для проработки и самостоятельного изучения
Понятие статистической гипотезы.
Сущность проверки статистической
Вопросы для проработки и самостоятельного изучения
Понятие статистической гипотезы.
Сущность проверки статистической

Многомерные методы математической статистики в психологии
Многомерные методы необходимы для одновременного учета
Многомерные методы математической статистики в психологии
Многомерные методы необходимы для одновременного учета

Кластерный анализ: описание метода
В основе кластерного анализа лежит идея классификации объектов
Кластерный анализ: описание метода
В основе кластерного анализа лежит идея классификации объектов

Кластерный анализ: описание метода
При проведении кластерного анализа и последующей интерпретации полученных
Кластерный анализ: описание метода
При проведении кластерного анализа и последующей интерпретации полученных

Кластерный анализ: описание метода
Наиболее часто кластерный анализ используется для обработки данных,
Кластерный анализ: описание метода
Наиболее часто кластерный анализ используется для обработки данных,

Обработка данных методом кластерного анализа
Последовательность проведения кластерного анализа:
1. Отбор объектов для кластеризации.
Обработка данных методом кластерного анализа
Последовательность проведения кластерного анализа:
1. Отбор объектов для кластеризации.

Последовательность проведения кластерного анализа:
1. Отбор объектов для кластеризации. На данном этапе
Последовательность проведения кластерного анализа:
1. Отбор объектов для кластеризации. На данном этапе
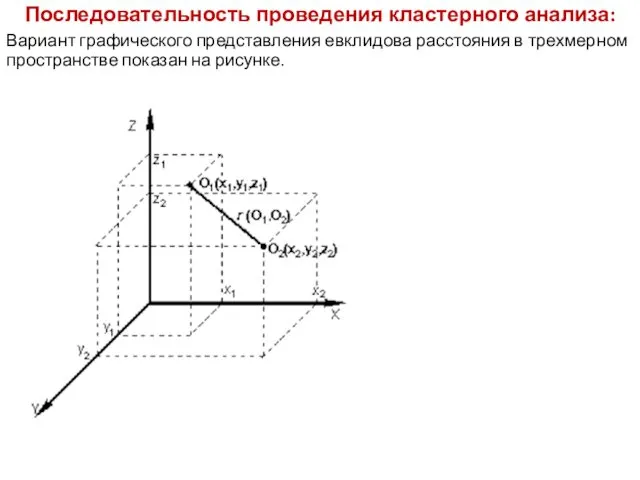
Последовательность проведения кластерного анализа:
Вариант графического представления евклидова расстояния в трехмерном пространстве
Последовательность проведения кластерного анализа:
Вариант графического представления евклидова расстояния в трехмерном пространстве

Последовательность проведения кластерного анализа:
Коэффициент корреляции – двухмерная описательная статистика, количественная мера
Последовательность проведения кластерного анализа:
Коэффициент корреляции – двухмерная описательная статистика, количественная мера

Последовательность проведения кластерного анализа:
Таким образом, кластеры, уровень связи в которых от
Последовательность проведения кластерного анализа:
Таким образом, кластеры, уровень связи в которых от

Последовательность проведения кластерного анализа:
4. Выбор и применение метода классификации для создания
Последовательность проведения кластерного анализа:
4. Выбор и применение метода классификации для создания
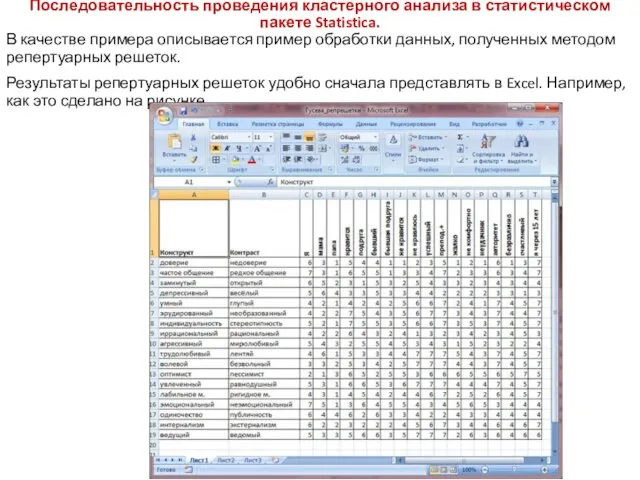
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
В качестве примера описывается
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
В качестве примера описывается
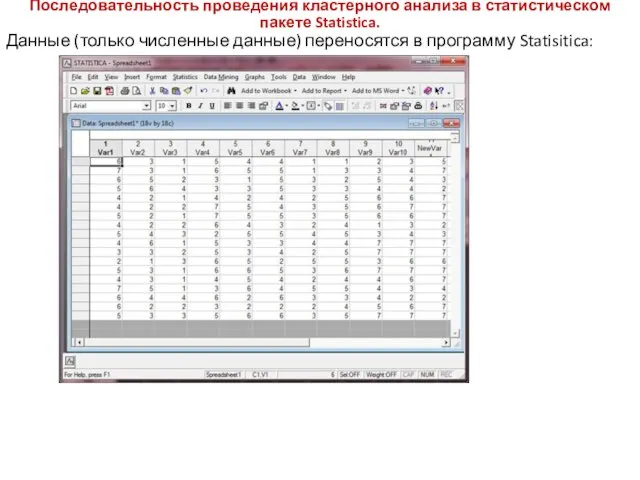
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Данные (только численные данные)
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Данные (только численные данные)
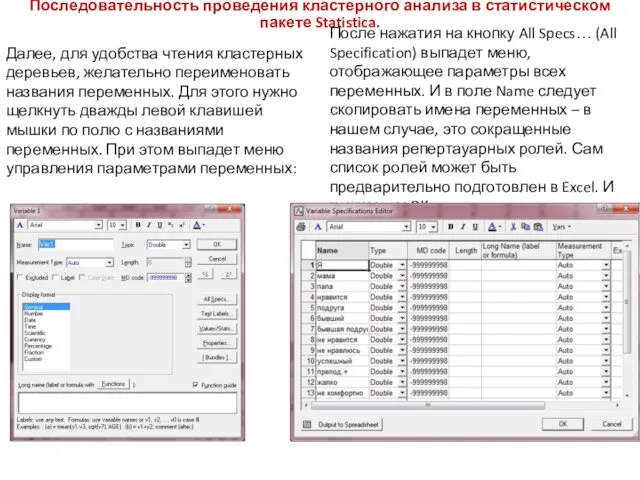
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
После нажатия на кнопку
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
После нажатия на кнопку
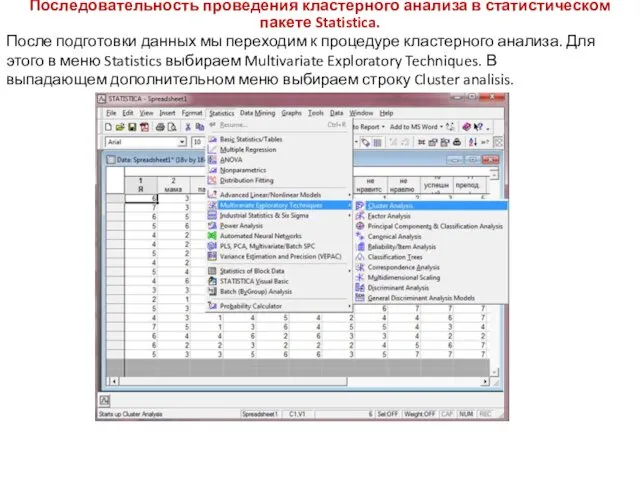
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
После подготовки данных мы
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
После подготовки данных мы
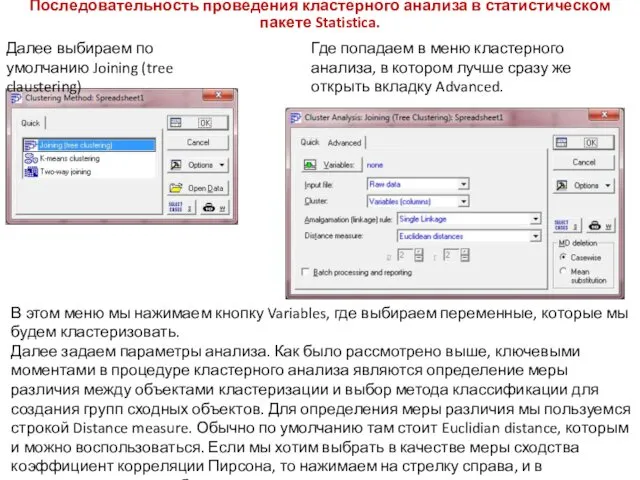
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Далее выбираем по умолчанию
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Далее выбираем по умолчанию
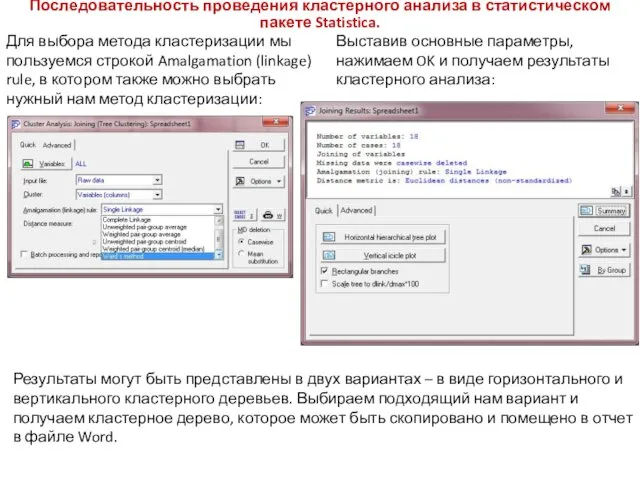
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Для выбора метода кластеризации
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
Для выбора метода кластеризации
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
В шапке кластерного дерева
Последовательность проведения кластерного анализа в статистическом пакете Statistica.
В шапке кластерного дерева

Интерпретация результатов кластерного анализа
Принципы интерпретации данных:
1. Основная задача кластерного анализа –
Интерпретация результатов кластерного анализа
Принципы интерпретации данных:
1. Основная задача кластерного анализа –

Интерпретация результатов кластерного анализа
Пример интерпретации кластерного дерева. Данные были получены с
Интерпретация результатов кластерного анализа
Пример интерпретации кластерного дерева. Данные были получены с

Интерпретация результатов кластерного анализа
При анализе кластерного дерева можно условно выделить пять
Интерпретация результатов кластерного анализа
При анализе кластерного дерева можно условно выделить пять

Интерпретация результатов кластерного анализа
Следующий кластер объединяет роли «Успешный человек» и «Комфортный
Интерпретация результатов кластерного анализа
Следующий кластер объединяет роли «Успешный человек» и «Комфортный

Описание метода факторного анализа
Факторный анализ является статистическим методом, используемым при обработке
Описание метода факторного анализа
Факторный анализ является статистическим методом, используемым при обработке

Психологические задачи факторного анализа.
Факторный анализ в психологии используется, во-первых, для исследований
Психологические задачи факторного анализа.
Факторный анализ в психологии используется, во-первых, для исследований

Психологические задачи факторного анализа.
Например, психолог оценивает случайную выборку студентов по следующим
Психологические задачи факторного анализа.
Например, психолог оценивает случайную выборку студентов по следующим

Психологические задачи факторного анализа.
Во-вторых, факторный анализ активно применяется при проведении психосемантических
Психологические задачи факторного анализа.
Во-вторых, факторный анализ активно применяется при проведении психосемантических

Основные понятия факторного анализа.
Фактор - это искусственный статистический показатель, возникающий в
Основные понятия факторного анализа.
Фактор - это искусственный статистический показатель, возникающий в

Основные понятия факторного анализа.
В процессе обработки данных необходимо понять, что является
Основные понятия факторного анализа.
В процессе обработки данных необходимо понять, что является

Обработка данных методом факторного анализа.
Факторный анализ включает в себя следующие этапы
Обработка данных методом факторного анализа.
Факторный анализ включает в себя следующие этапы
Получение общей матрицы данны
1. Сжатие куба данных. Групповые данные рассматриваются как
Получение общей матрицы данны
1. Сжатие куба данных. Групповые данные рассматриваются как

Получение общей матрицы данны
2. Метод «растягивания в вереницу». В этом случае
Получение общей матрицы данны
2. Метод «растягивания в вереницу». В этом случае

Транспонирование матриц данных
Как правило, факторный анализ используется для обработки данных, полученных
Транспонирование матриц данных
Как правило, факторный анализ используется для обработки данных, полученных
Транспонирование матриц данных
Сама матрица представляет собой результат оценок объектов шкалирования по
Транспонирование матриц данных
Сама матрица представляет собой результат оценок объектов шкалирования по
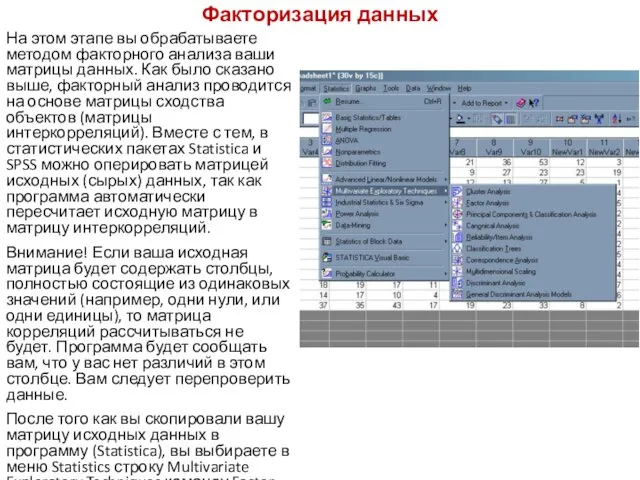
Факторизация данных
На этом этапе вы обрабатываете методом факторного анализа ваши
Факторизация данных
На этом этапе вы обрабатываете методом факторного анализа ваши
Факторизация данных
Далее вы выбираете те переменные (variables), которые будут подвергаться
Факторизация данных
Далее вы выбираете те переменные (variables), которые будут подвергаться
Определение числа факторов
Определение числа факторов, используемых для последующего анализа данных, может
Определение числа факторов
Определение числа факторов, используемых для последующего анализа данных, может
Определение числа факторов
В данном примере для последующего анализа данных можно ограничиться
Определение числа факторов
В данном примере для последующего анализа данных можно ограничиться
Определение числа факторов
3. Критерий Кайзера. Рассматриваются только факторы с собственными значениями
Определение числа факторов
3. Критерий Кайзера. Рассматриваются только факторы с собственными значениями

Вращение факторов
После того, как определено количество факторов, рассматриваемых для последующего
Вращение факторов
После того, как определено количество факторов, рассматриваемых для последующего
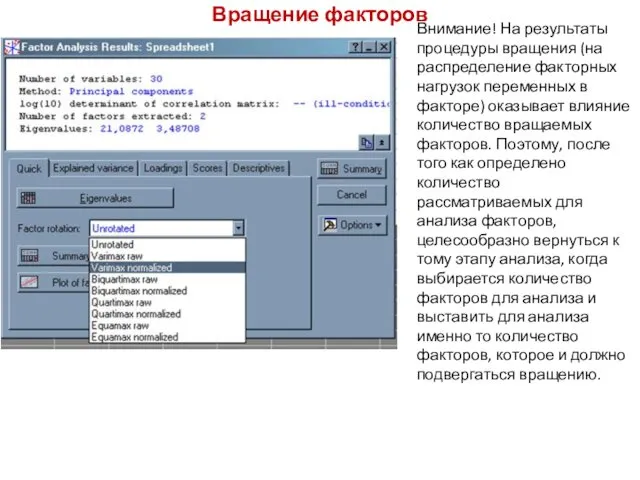
Вращение факторов
Внимание! На результаты процедуры вращения (на распределение факторных нагрузок
Вращение факторов
Внимание! На результаты процедуры вращения (на распределение факторных нагрузок

Результаты анализа
Далее мы можем извлечь результаты факторного анализа из программы.
Результаты анализа
Далее мы можем извлечь результаты факторного анализа из программы.
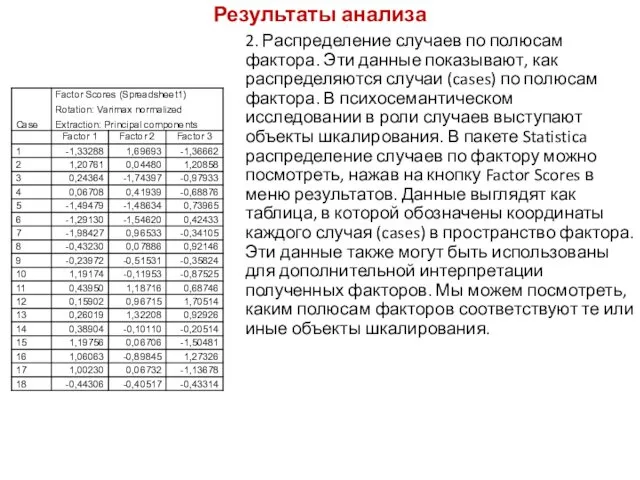
Результаты анализа
2. Распределение случаев по полюсам фактора. Эти данные показывают,
Результаты анализа
2. Распределение случаев по полюсам фактора. Эти данные показывают,
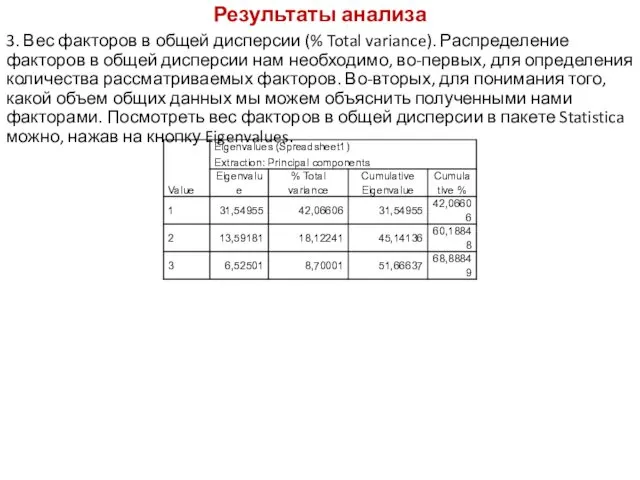
Результаты анализа
3. Вес факторов в общей дисперсии (% Total variance).
Результаты анализа
3. Вес факторов в общей дисперсии (% Total variance).

Результаты анализа
3. Интерпретация данных, полученных методом факторного анализа
Интерпретация данных, полученных
Результаты анализа
3. Интерпретация данных, полученных методом факторного анализа
Интерпретация данных, полученных

Результаты анализа
3. Содержательно полученные факторы интерпретируются исходя из того, какие
Результаты анализа
3. Содержательно полученные факторы интерпретируются исходя из того, какие

Результаты анализа
Хотя достаточно жесткого правила здесь нет. И выбор, с
Результаты анализа
Хотя достаточно жесткого правила здесь нет. И выбор, с

Рекомендованные к использованию в рамках дисциплины статистические компьютерные пакеты
Не поленитесь установить
Рекомендованные к использованию в рамках дисциплины статистические компьютерные пакеты
Не поленитесь установить
 Психоаналитическая концепция личностных нарушений. Лекция 4
Психоаналитическая концепция личностных нарушений. Лекция 4 Коммуникативные барьеры
Коммуникативные барьеры Квадровые ценности и комплексы
Квадровые ценности и комплексы Проект недели психологии в детском саду Спешите деать добро
Проект недели психологии в детском саду Спешите деать добро Развитие детского лексикона
Развитие детского лексикона Стресс в профессиональной деятельности спасателя
Стресс в профессиональной деятельности спасателя Исследование словесно-логического мышления. Диагностика мышления (продолжение)
Исследование словесно-логического мышления. Диагностика мышления (продолжение) Психология. Лекция
Психология. Лекция Методы исследования креативности
Методы исследования креативности Мир психических явлений. Основные категории психологии
Мир психических явлений. Основные категории психологии Кодекс профессиональной этики сотрудников органов внутренних дел Российской Федерации как стандарт антикоррупционного поведения
Кодекс профессиональной этики сотрудников органов внутренних дел Российской Федерации как стандарт антикоррупционного поведения Развитие детей 4-5 лет
Развитие детей 4-5 лет Сложные этические вопросы психотерапии
Сложные этические вопросы психотерапии Стресс как фактор риска профессионального выгорания медицинских работников
Стресс как фактор риска профессионального выгорания медицинских работников Особенности проявления тревожности у старших дошкольников в семьях с разной степенью гармонизации
Особенности проявления тревожности у старших дошкольников в семьях с разной степенью гармонизации Презентация: Досуг и отдых
Презентация: Досуг и отдых Культурно чувствительные подходы к изучению травмы
Культурно чувствительные подходы к изучению травмы Основы коммуникации при работе с семьей. Анализ проблем и достижений при взаимодействии с семьей
Основы коммуникации при работе с семьей. Анализ проблем и достижений при взаимодействии с семьей Взаимодействие людей в малых группах
Взаимодействие людей в малых группах Психология дошкольника. Работа педагога с детьми этого возраста
Психология дошкольника. Работа педагога с детьми этого возраста Алхимия любви
Алхимия любви Жесты и мимика как невербальные средства общения
Жесты и мимика как невербальные средства общения Ваш эннеаграммный тип
Ваш эннеаграммный тип Несчастная любовь
Несчастная любовь Программа Психология для старшеклассников
Программа Психология для старшеклассников Лидерство. Теории лидерства
Лидерство. Теории лидерства Медиация
Медиация Планирование эксперимента
Планирование эксперимента