- 287744_1

Содержание
- 2. Конвейеризация вычислений Наиболее важный архитектурный прием повышения производительности – конвейеризация вычислений. Конвейерная обработка в общем случае
- 3. First pipelined processor – IBM Stretch (1962). Potential overlap among instructions is called instruction-level parallelism (ILP).
- 4. IF Pipelining allows to overlap different instructions at different stages. Unpipelined:
- 5. Определение эффективности конвейеров. Для характеристики эффективности используют три метрики: ускорение, эффективность и производительность. Ускорение S –
- 6. Метрики конвейера Эффективность E – доля ускорения, приходящаяся на одну ступень конвейера. E = S/K =
- 7. Проблемы, возникающие на конвейере CPI – Cycles Per Instructions Pipeline CPI = Ideal pipeline CPI +
- 8. Конфликты по данным RAW ( Read After Write ). Рассмотрим команды i и j (i предшествует
- 9. Устранение конфликтов по данным Программные методы Оптимизирующий компилятор пытается создать такой код, чтобы между командами, которые
- 10. Аппаратные методы Фактическое разрешение конфликтов возлагается на аппаратные методы (суперскалярные процессоры). Очевидный метод – приостановка. Но
- 11. Bypassing
- 12. Переименование регистров (Registers Renaming) Существенной зависимостью является только RAW. Зависимости WAR и WAW являются несущественными. Причины
- 13. Переименование регистров Для преодоления несущественных WAR и WAW зависимостей используется механизм динамического отображения определяемых текстом программы
- 15. Пример конвейера RISC – processor. Basic instructions: LOAD Instruction fetch - “IF” stage 1. PC →
- 16. Пример конвейера STORE Instruction fetch “IF” stage 1. PC → Mem, “Read” 2. Memory[PC] → IR
- 17. Пример конвейера ADD/SUB Instruction fetch “IF” stage 1. PC → Mem, “Read” 2. Memory[PC] → IR
- 18. BR.Z Instruction fetch “IF” stage PC → Mem, “Read” Memory[PC] → IR PC +4→PC Decoding “EX”
- 19. JMP “IF” stage Instruction fetch PC → Mem, “Read” Memory[PC] → IR PC +4→PC Decoding (PC)
- 20. Пример конвейера
- 21. Пример конвейера Stages divided by pipeline registers/latches. Pipeline registers Reg. PC contains PC Reg. F/D contains
- 22. Data Hazards Pipelines Limitations Structural hazards Data hazards Control hazards Data Hazards Two different instructions use
- 23. Конфликты по управлению Методы решения проблемы условного перехода Наибольшие проблемы при создании эффективного конвейера обусловлены командами,
- 24. На стадии декодирования команды K3 обнаружено, что K3 - команда условного перехода. После этого команда К4
- 25. Если конвейер будет приостановлен на три такта на каждой команде условного перехода, то это существенно снижает
- 26. Метод возврата Штраф за нарушение естественного порядка выполнения команд Условный переход прогнозируется как невыполняемый. Выполнение программы
- 27. Рассмотрим, что происходит, когда на конвейер попадает команда условного перехода. Предположим, что команда K3 оказалась командой
- 28. Предсказание переходов Предсказание переходов является одним из наиболее эффективных способов борьбы с конфликтами по управлению. Идея
- 29. Предсказание переходов (Prediction) Точность предсказания – процентное отношение числа правильных предсказаний к их общему количеству. Доказано,
- 30. Статическое предсказание Статическое предсказание делается на этапе компиляции программы. Используют следующие стратегии: Переход происходит всегда (ПВ);
- 31. При предсказании на основе кода операции предполагается, что для одних команд переход произойдет, а для других
- 32. Branch Prediction Ветвления бывают случайные и регулярные. Регулярные ветвления довольно хорошо предсказываются на основе предыдущей статистики
- 33. Динамическое предсказание Идея динамического предсказания ветвлений предполагает накопление информации о предшествующих переходах. Решение о наиболее вероятном
- 34. 1-битная схема прогноза Состояние “0” – предсказывается, что перехода не будет; Состояние “1” – предсказывается, что
- 35. Двухбитная схема прогноза (предиктор Смита) ПВ (“верно”) 00 – очень малая вероятность перехода (сильное предсказание) 01
- 36. Когда автомат находится в состоянии 00, то предсказывается, что перехода не будет not taken). Если же
- 37. Двухуровневые схемы предсказаний Одноуровневые схемы предсказания ориентированы на те команды условного перехода, исход которых существенно зависит
- 38. Двухуровневые схемы предсказаний Рассмотрим небольшой фрагмент из текста программы тестового пакета SPEC92 (наихудший случай для двухбитной
- 39. Двухуровневые схемы предсказаний cmp eax, 2 jne l1; B1 xor eax, eax l1: cmp ebx, 2
- 40. Двухуровневые схемы предсказаний Можно проследить, были ли совершены k последних команд переходов, независимо от того, какие
- 41. Двухуровневые схемы предсказаний Представлена BHT предиктора (2,2) – 2бита глобальной истории и 2 бита локальной истории
- 42. Branch Target Buffer BTB является ассоциативным FIFO буфером.
- 46. Гибридные схемы предсказания Характерна сильная зависимость точности предсказания от особенностей программ, в которых эти стратегии реализуются.
- 47. IP
- 48. Селектор Обычно для выбора селектора используют 2-битный счетчик с насыщением. Граф переходов автомата Мура, описывающего поведение
- 50. Скачать презентацию

Конвейеризация вычислений
Наиболее важный архитектурный прием повышения производительности – конвейеризация вычислений.
Конвейерная
Конвейеризация вычислений
Наиболее важный архитектурный прием повышения производительности – конвейеризация вычислений.
Конвейерная

First pipelined processor – IBM Stretch (1962).
Potential overlap among instructions is
First pipelined processor – IBM Stretch (1962).
Potential overlap among instructions is

IF
Pipelining allows to overlap different instructions at different stages.
Unpipelined:
IF
Pipelining allows to overlap different instructions at different stages.
Unpipelined:

Определение эффективности конвейеров.
Для характеристики эффективности используют три метрики: ускорение, эффективность и
Определение эффективности конвейеров.
Для характеристики эффективности используют три метрики: ускорение, эффективность и

Метрики конвейера
Эффективность E – доля ускорения, приходящаяся на одну ступень конвейера.
E
Метрики конвейера
Эффективность E – доля ускорения, приходящаяся на одну ступень конвейера.
E

Проблемы, возникающие на конвейере
CPI – Cycles Per Instructions
Pipeline CPI = Ideal
Проблемы, возникающие на конвейере
CPI – Cycles Per Instructions
Pipeline CPI = Ideal

Конфликты по данным
RAW ( Read After Write ).
Рассмотрим команды i
Конфликты по данным
RAW ( Read After Write ).
Рассмотрим команды i

Устранение конфликтов по данным
Программные методы
Оптимизирующий компилятор пытается создать такой код,
Устранение конфликтов по данным
Программные методы
Оптимизирующий компилятор пытается создать такой код,

Аппаратные методы
Фактическое разрешение конфликтов возлагается на аппаратные методы (суперскалярные процессоры).
Очевидный метод
Аппаратные методы
Фактическое разрешение конфликтов возлагается на аппаратные методы (суперскалярные процессоры).
Очевидный метод
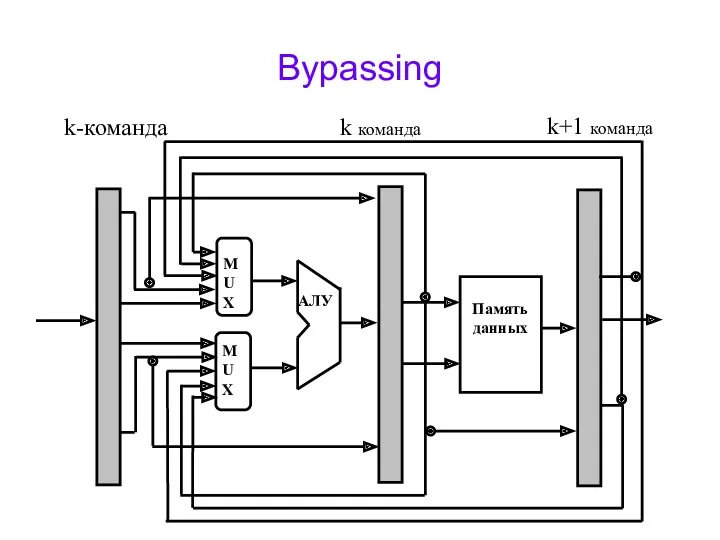
Bypassing
Bypassing

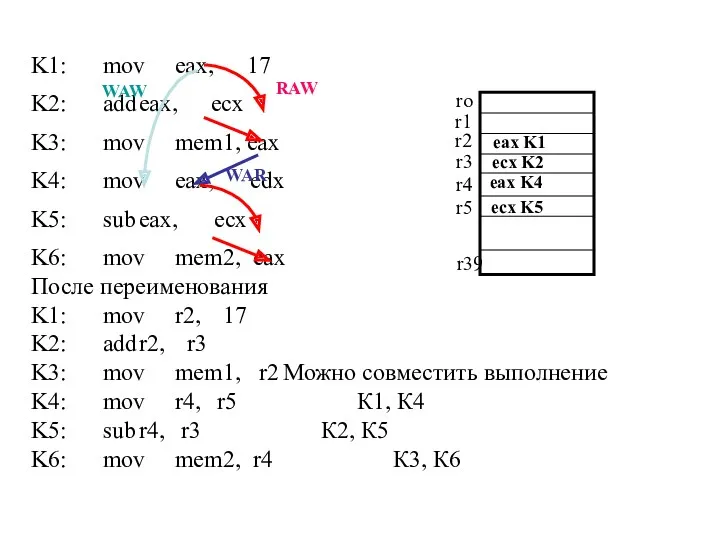
Переименование регистров (Registers Renaming)
Существенной зависимостью является только RAW.
Зависимости WAR и WAW
Переименование регистров (Registers Renaming)
Существенной зависимостью является только RAW.
Зависимости WAR и WAW

Переименование регистров
Для преодоления несущественных WAR и WAW зависимостей используется механизм динамического
Переименование регистров
Для преодоления несущественных WAR и WAW зависимостей используется механизм динамического
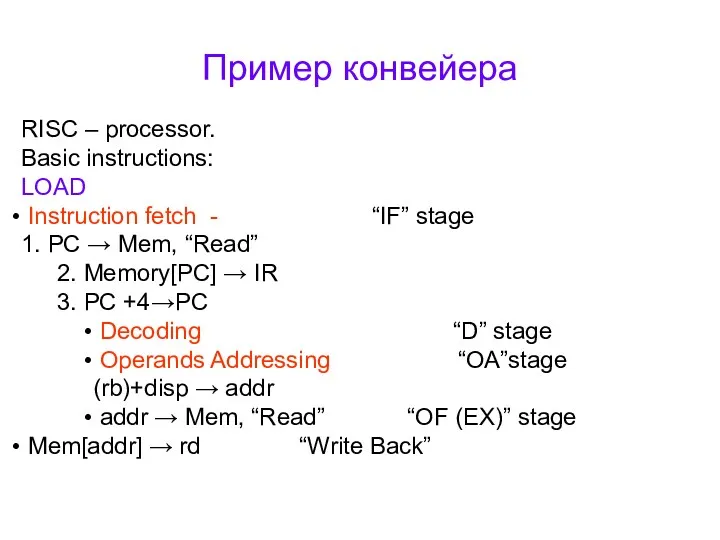
Пример конвейера
RISC – processor.
Basic instructions:
LOAD
Instruction fetch - “IF” stage
1.
Пример конвейера
RISC – processor.
Basic instructions:
LOAD
Instruction fetch - “IF” stage
1.

Пример конвейера
STORE
Instruction fetch “IF” stage
1. PC → Mem, “Read”
2.
Пример конвейера
STORE
Instruction fetch “IF” stage
1. PC → Mem, “Read”
2.

Пример конвейера
ADD/SUB
Instruction fetch “IF” stage
1. PC → Mem, “Read”
2. Memory[PC]
Пример конвейера
ADD/SUB
Instruction fetch “IF” stage
1. PC → Mem, “Read”
2. Memory[PC]
![BR.Z Instruction fetch “IF” stage PC → Mem, “Read” Memory[PC]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355111/slide-17.jpg)
BR.Z
Instruction fetch
“IF” stage
PC → Mem, “Read”
Memory[PC] → IR
PC +4→PC
Decoding
“EX” stage
(PC) +
BR.Z
Instruction fetch
“IF” stage
PC → Mem, “Read”
Memory[PC] → IR
PC +4→PC
Decoding
“EX” stage
(PC) +
![JMP “IF” stage Instruction fetch PC → Mem, “Read” Memory[PC]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355111/slide-18.jpg)
JMP
“IF” stage
Instruction fetch
PC → Mem, “Read”
Memory[PC] → IR
PC +4→PC
Decoding
(PC) + disp
JMP
“IF” stage
Instruction fetch
PC → Mem, “Read”
Memory[PC] → IR
PC +4→PC
Decoding
(PC) + disp
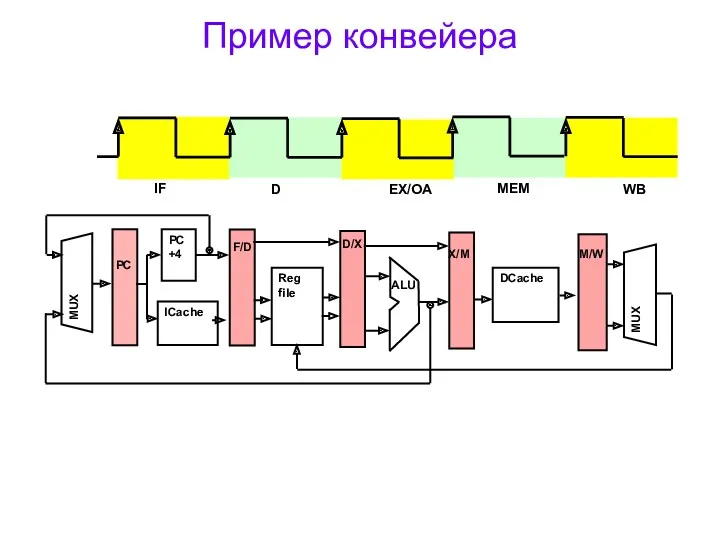
Пример конвейера
Пример конвейера

Пример конвейера
Stages divided by pipeline registers/latches.
Pipeline registers
Reg. PC contains PC
Пример конвейера
Stages divided by pipeline registers/latches.
Pipeline registers
Reg. PC contains PC
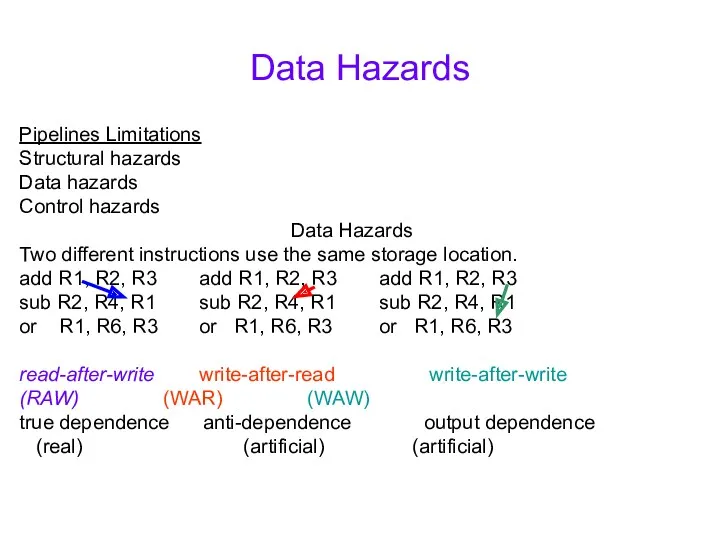
Data Hazards
Pipelines Limitations
Structural hazards
Data hazards
Control hazards
Data Hazards
Two different instructions
Data Hazards
Pipelines Limitations
Structural hazards
Data hazards
Control hazards
Data Hazards
Two different instructions

Конфликты по управлению
Методы решения проблемы условного перехода
Наибольшие проблемы при создании
Конфликты по управлению
Методы решения проблемы условного перехода
Наибольшие проблемы при создании
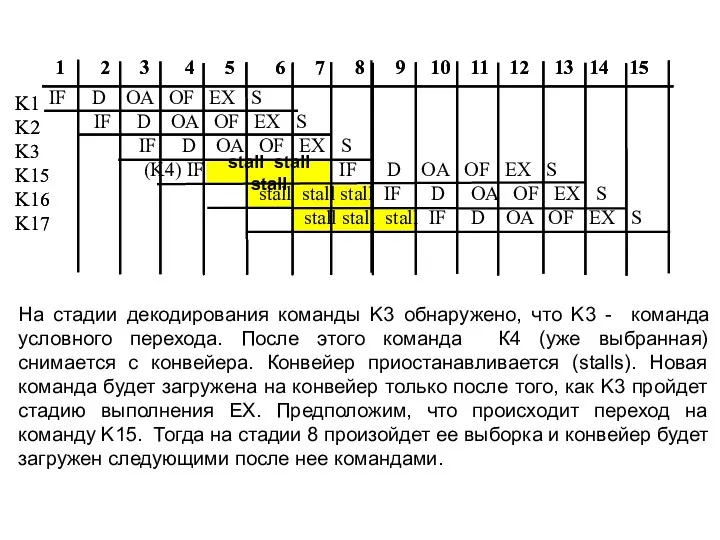
На стадии декодирования команды K3 обнаружено, что K3 - команда условного
На стадии декодирования команды K3 обнаружено, что K3 - команда условного

Если конвейер будет приостановлен на три такта на каждой команде условного
Если конвейер будет приостановлен на три такта на каждой команде условного
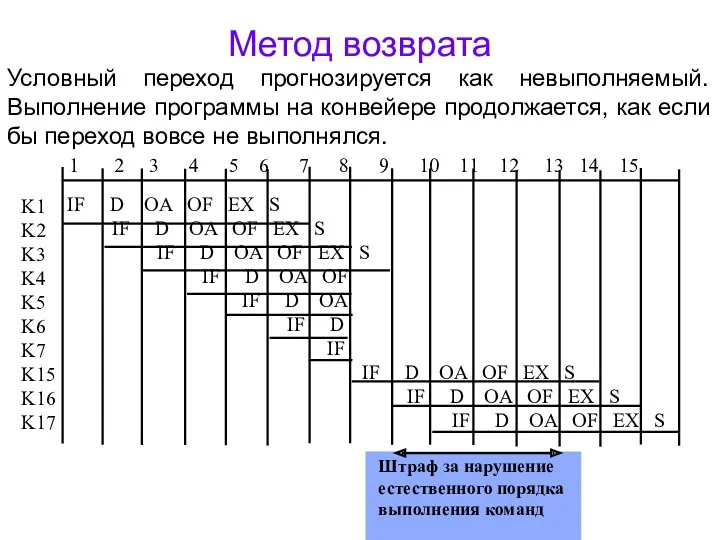
Метод возврата
Штраф за нарушение естественного порядка выполнения команд
Условный переход прогнозируется как
Метод возврата
Штраф за нарушение естественного порядка выполнения команд
Условный переход прогнозируется как

Рассмотрим, что происходит, когда на конвейер попадает команда условного перехода. Предположим,
Рассмотрим, что происходит, когда на конвейер попадает команда условного перехода. Предположим,

Предсказание переходов
Предсказание переходов является одним из наиболее эффективных способов борьбы с
Предсказание переходов
Предсказание переходов является одним из наиболее эффективных способов борьбы с

Предсказание переходов (Prediction)
Точность предсказания – процентное отношение числа правильных предсказаний к
Предсказание переходов (Prediction)
Точность предсказания – процентное отношение числа правильных предсказаний к

Статическое предсказание
Статическое предсказание делается на этапе компиляции программы.
Используют следующие стратегии:
Статическое предсказание
Статическое предсказание делается на этапе компиляции программы.
Используют следующие стратегии:

При предсказании на основе кода операции предполагается, что для одних команд
При предсказании на основе кода операции предполагается, что для одних команд

Branch Prediction
Ветвления бывают случайные и регулярные.
Регулярные ветвления довольно хорошо предсказываются
Branch Prediction
Ветвления бывают случайные и регулярные.
Регулярные ветвления довольно хорошо предсказываются

Динамическое предсказание
Идея динамического предсказания ветвлений предполагает накопление информации о предшествующих
Динамическое предсказание
Идея динамического предсказания ветвлений предполагает накопление информации о предшествующих
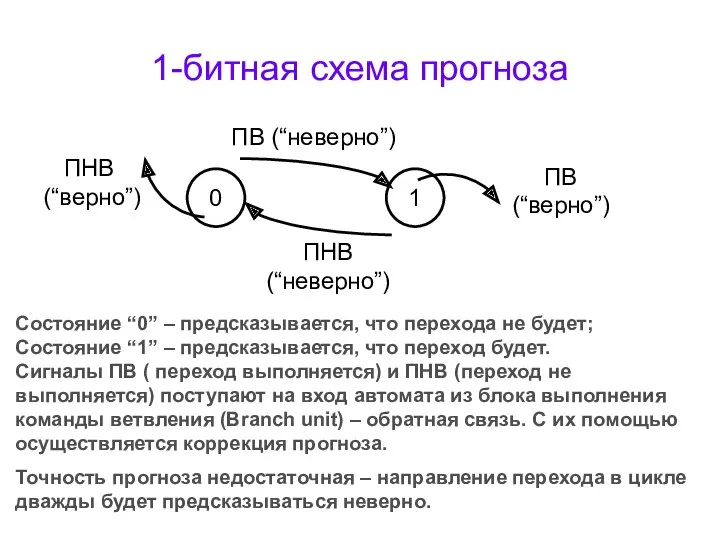
1-битная схема прогноза
Состояние “0” – предсказывается, что перехода не будет;
Состояние “1”
1-битная схема прогноза
Состояние “0” – предсказывается, что перехода не будет;
Состояние “1”
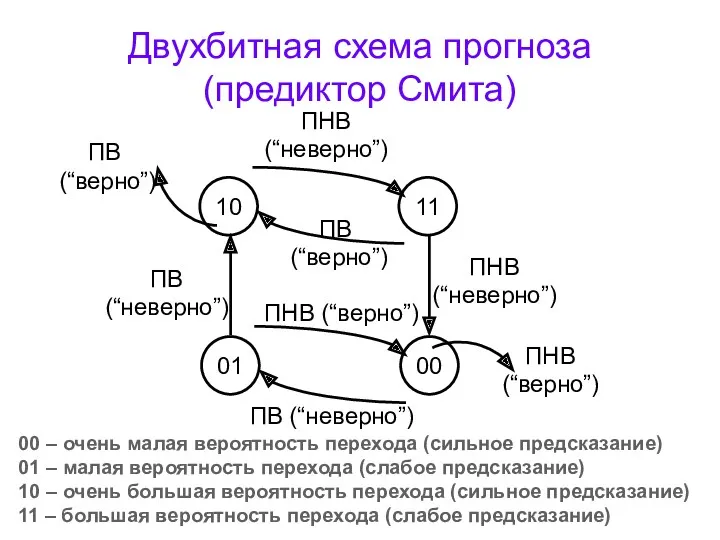
Двухбитная схема прогноза (предиктор Смита)
ПВ
(“верно”)
00 – очень малая вероятность перехода
Двухбитная схема прогноза (предиктор Смита)
ПВ
(“верно”)
00 – очень малая вероятность перехода

Когда автомат находится в состоянии 00, то предсказывается, что перехода не
Когда автомат находится в состоянии 00, то предсказывается, что перехода не

Двухуровневые схемы предсказаний
Одноуровневые схемы предсказания ориентированы на те команды условного перехода,
Двухуровневые схемы предсказаний
Одноуровневые схемы предсказания ориентированы на те команды условного перехода,

Двухуровневые схемы предсказаний
Рассмотрим небольшой фрагмент из текста программы тестового пакета SPEC92
Двухуровневые схемы предсказаний
Рассмотрим небольшой фрагмент из текста программы тестового пакета SPEC92
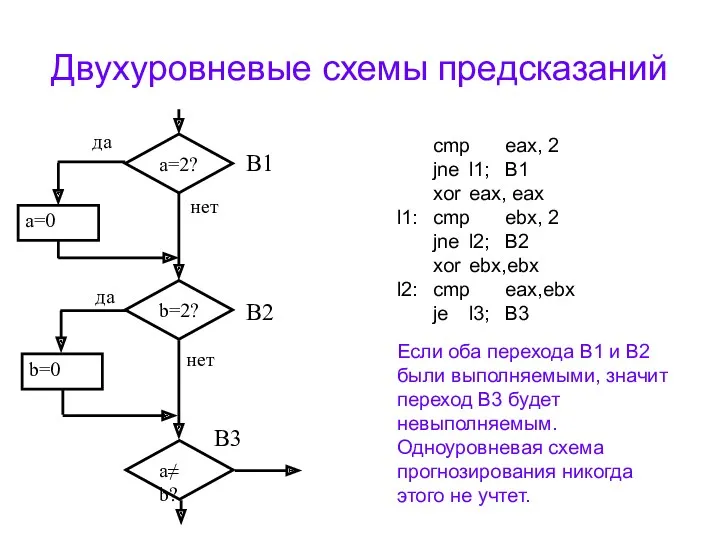
Двухуровневые схемы предсказаний
cmp eax, 2
jne l1; B1
xor eax, eax
l1: cmp ebx, 2
jne l2; B2
xor ebx,ebx
l2: cmp eax,ebx
je l3; B3
Если оба перехода B1 и
Двухуровневые схемы предсказаний
cmp eax, 2
jne l1; B1
xor eax, eax
l1: cmp ebx, 2
jne l2; B2
xor ebx,ebx
l2: cmp eax,ebx
je l3; B3
Если оба перехода B1 и

Двухуровневые схемы предсказаний
Можно проследить, были ли совершены k последних команд переходов,
Двухуровневые схемы предсказаний
Можно проследить, были ли совершены k последних команд переходов,
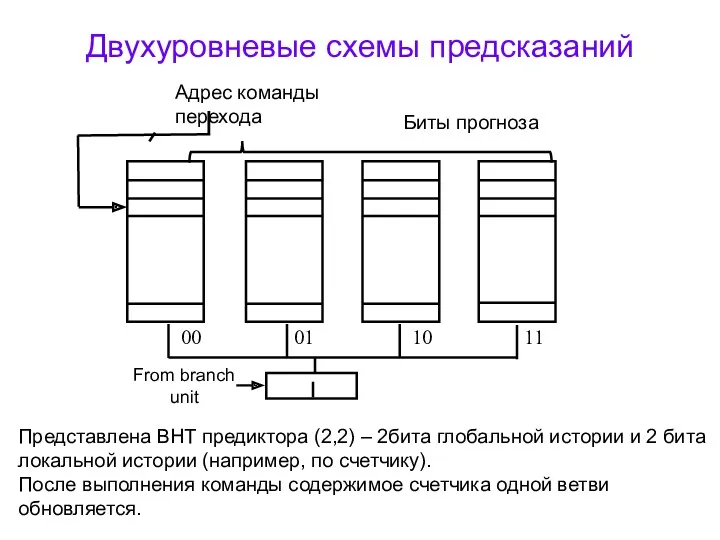
Двухуровневые схемы предсказаний
Представлена BHT предиктора (2,2) – 2бита глобальной истории и
Двухуровневые схемы предсказаний
Представлена BHT предиктора (2,2) – 2бита глобальной истории и
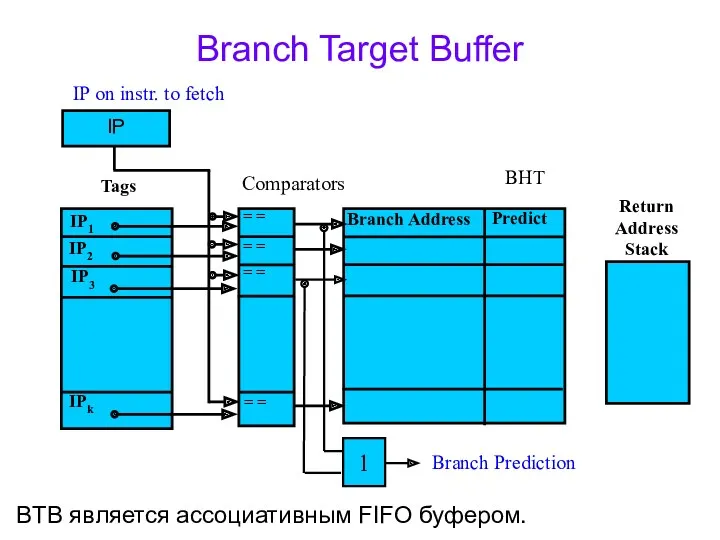
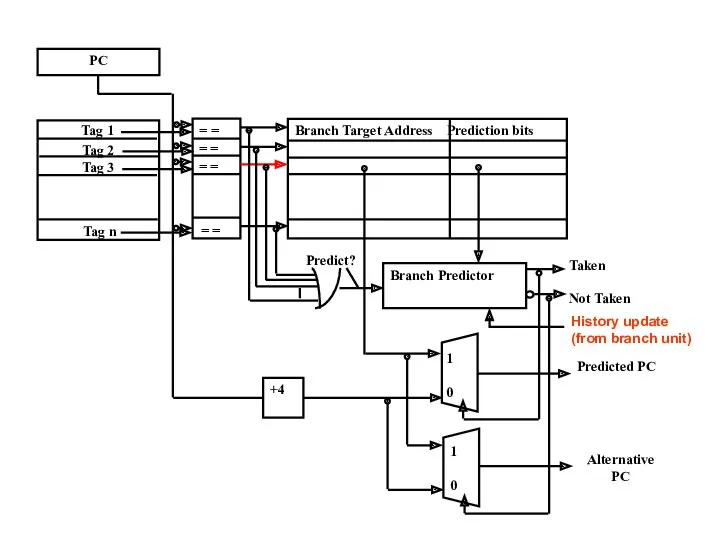
Branch Target Buffer
BTB является ассоциативным FIFO буфером.
Branch Target Buffer
BTB является ассоциативным FIFO буфером.
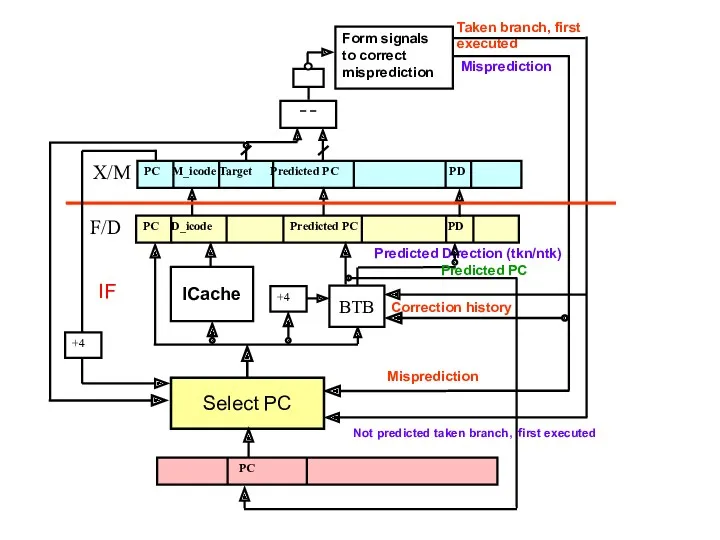
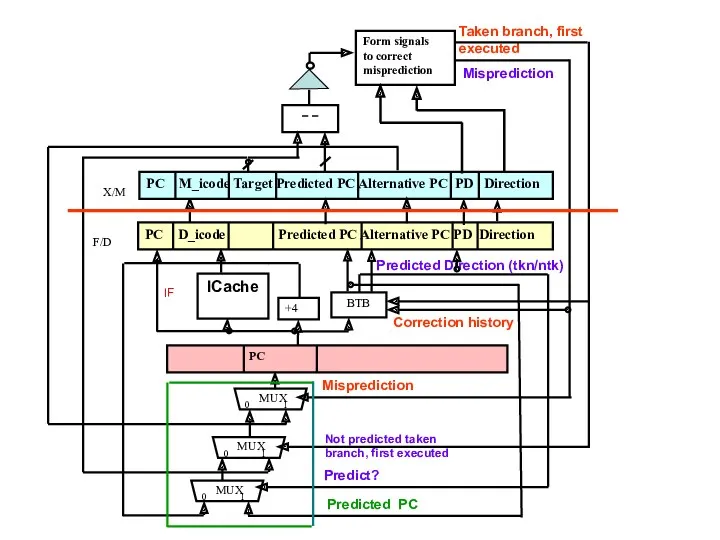

Гибридные схемы предсказания
Характерна сильная зависимость точности предсказания от особенностей программ, в
Гибридные схемы предсказания
Характерна сильная зависимость точности предсказания от особенностей программ, в
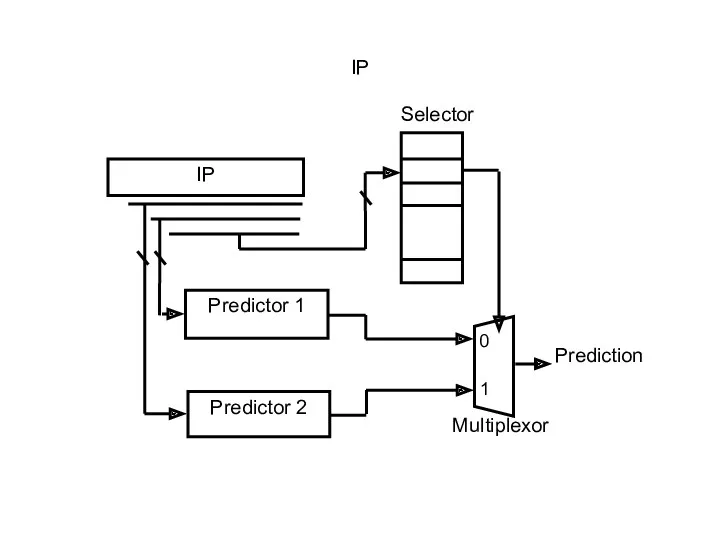
IP
IP
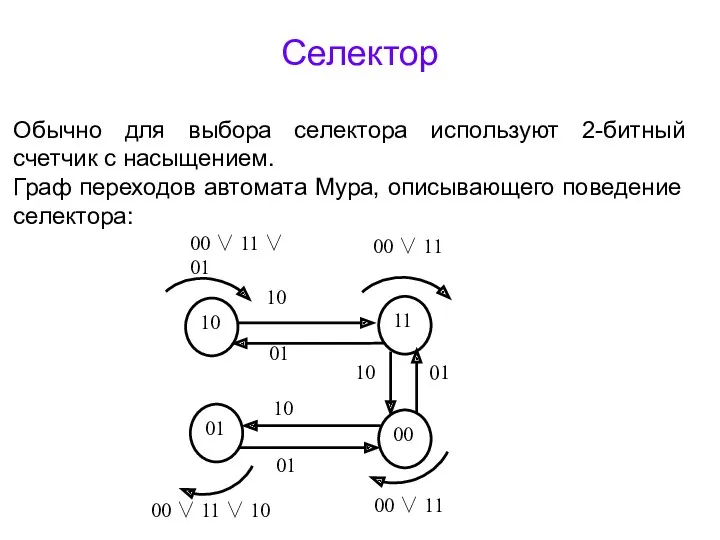
Селектор
Обычно для выбора селектора используют 2-битный счетчик с насыщением.
Граф переходов
Селектор
Обычно для выбора селектора используют 2-битный счетчик с насыщением.
Граф переходов
 Федеральный закон О промышленной безопасности опасных производственных объектов
Федеральный закон О промышленной безопасности опасных производственных объектов Підвищення ефективності перевезення м’ясних виробів
Підвищення ефективності перевезення м’ясних виробів Сельское хозяйство, его отраслевая структура
Сельское хозяйство, его отраслевая структура Познавательные УУД
Познавательные УУД Школа астрологии Елены Черных
Школа астрологии Елены Черных Военная техника Кургана для Российской армии. Кл.час.
Военная техника Кургана для Российской армии. Кл.час. Как сделать Вазу с цветами
Как сделать Вазу с цветами Электроника. Транзисторы, Операционные усилители. Лекция 16
Электроника. Транзисторы, Операционные усилители. Лекция 16 Проектирование гибких фундаментов. (Лекция 19)
Проектирование гибких фундаментов. (Лекция 19) Жизнь дана на добрые дела
Жизнь дана на добрые дела Озёра, болота, подземные воды, многолетняя мерзлота.
Озёра, болота, подземные воды, многолетняя мерзлота. Теоретические методы исследования строительных конструкций, зданий и сооружений
Теоретические методы исследования строительных конструкций, зданий и сооружений Безупречность в производстве
Безупречность в производстве Политическая карта мира.
Политическая карта мира. Средство передвижения автобус
Средство передвижения автобус Мой выбор - машиностроение
Мой выбор - машиностроение Заходер. Птичья школа
Заходер. Птичья школа банк мультимедийных презентаций
банк мультимедийных презентаций Опыт организации изучения нового материала в деятельности с детьми младшего школьного возраста
Опыт организации изучения нового материала в деятельности с детьми младшего школьного возраста Русь между Востоком и Западом. Дружина русская. Лучник
Русь между Востоком и Западом. Дружина русская. Лучник My family
My family Биомембраны. Функции и разнообразие
Биомембраны. Функции и разнообразие Кировское региональное отделение Фонда социального страхования Российской Федерации
Кировское региональное отделение Фонда социального страхования Российской Федерации Презентация Адаптация детей к детскому саду
Презентация Адаптация детей к детскому саду Блокада Ленинграда
Блокада Ленинграда Презентация по письму и развитию речи в 4 классе специального(коррекционного) обучения VIII вида.Тема.Алфавит.
Презентация по письму и развитию речи в 4 классе специального(коррекционного) обучения VIII вида.Тема.Алфавит. презентация Дети о войне
презентация Дети о войне Порушення фонематичного слуху як основа сенсорної афазії. Акустико-семантичні порушення
Порушення фонематичного слуху як основа сенсорної афазії. Акустико-семантичні порушення