- Архитектура вычислительных систем. Лекции

Содержание
- 2. Функциональные возможности ВС
- 3. Составные части понятия «архитектура» Вычислительные и логические возможности ВС. Они обусловливаются системой команд (СК), характеризующей гибкость
- 4. Классификация системы команд по назначению
- 5. Аппаратные средства. Простейшая ВС включает модули пяти типов: центральный процессор, основная память, каналы, контроллеры и внешние
- 6. Многоуровневая организация архитектуры ВС
- 7. Этапы разработки типовых проектов (характерны для процесса разработки архитектуры ЭВМ) анализ требований, предъявляемых к системе; составление
- 8. Конструкции языков программирования, вызывающие семантический разрыв Массивы (реализация принципа организации данных в виде массива возлагается на
- 9. Основные характеристики архитектуры фон Неймановского типа последовательно адресуемая единственная память линейного типа для хранения программ и
- 10. Требования ЯВУ к архитектуре ЭВМ память состоит из набора дискретных именуемых переменных. ЯВУ наряду с линейными
- 11. Примеры типов ячеек при теговой организации
- 12. Пример дескриптора Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают дополнительный уровень адресации, что
- 13. Области санкционированного доступа Достоинства: улучшается отладка программ. Сфера действия любой ошибки ограничивается размерами домена, в котором
- 14. Одноуровневая память Достоинства: сравнительно низкая стоимость программного обеспечения; независимость адресации от принципа организации памяти. Трудности реализации:
- 15. Достоинства виртуальной памяти Однородность области адресов каждый процесс может выполняться в памяти начиная с фиксированной (обычно
- 16. Виртуальная память Виртуальную память пользователя можно разделить на три типа: "активные" блоки, которые содержат программу и
- 17. Функционирование виртуальной памяти
- 18. Страничное распределение памяти
- 19. Механизм преобразования виртуального адреса в физический
- 20. Сегментное распределение
- 21. Формирование реального адреса
- 22. Управляющая ЭВМ
- 23. Схема отображения ВА в реальный адрес
- 24. Соотношение программ на ЯВУ и машинном языке Это традиционный подход. После компилирования программа переводится на машинный
- 25. Основные принципы RISC-архитектуры каждая команда независимо от ее типа выполняется за один машинный цикл, длительность которого
- 26. Отличительные особенности CISC- и RISC-архитектур Достоинства RISC-архитектуры: Компактность процессора, как следствие отсутствие проблем с охлаждением; Высокая
- 27. Экспериментальное измерение количественной оценки операций Результаты измерений в статике, проведенные для программ-компиляторов: операторы присваивания – 48
- 28. Регистровые окна VLIW Программа №1 Программа №2 Программа №3 Программа №4
- 29. VLIW-архитектура Процессор VLIW, имеющий схему, представленную выше, может выполнять в предельном случае восемь операций за один
- 30. Методы адресации
- 31. Методы адресации
- 32. Основные типы команд
- 33. Структура команд
- 34. Стековая организация регистровой памяти процессора
- 35. Основные операция и спецкоманды Операции с регистрами: Движение вниз: (P1) → P2, (P2) → P3, ...,
- 36. Программа решения математической задачи для одноадресного компьютера
- 37. Программа решения математической задачи на ЭВМ со стековой организацией памяти
- 38. Способы проектирования системы команд Сокращение набора команд, присущих СК выбранного микропроцессора. Все частоты встреч операций для
- 39. Принцип управления операциями на основе «жесткой» логики
- 40. Горизонтальное микропрограммирование Вертикальное микропрограммирование
- 41. Оценка современных компьютеров Узкие места современных ЭВМ Оценка производительности ВС Методы повышения производительности ЭВМ Компьютеры с
- 42. Основные причины возникновения узких мест в компьютере состав, принцип работы и временные характеристики арифметико-логического устройства; состав,
- 43. Методы оценки производительности ВС Пиковая производительность (суммарное количество операций, выполняемых в единицу времени всеми имеющимися в
- 44. Основные проблемы, связанные с анализом результатов контрольного тестирования производительности отделение показателей, которым можно доверять безоговорочно, от
- 45. Стандартные тесты LinPack - совокупность программ для решения задач линейной алгебры В качестве параметров используются: порядок
- 47. Закон Мура Зако́н Му́ра — эмпирическое — эмпирическое наблюдение, сделанное в 1965 году — эмпирическое наблюдение,
- 48. Увеличение скорости исполнения команд Использование новых архитектур процессоров Суперскалярная архитектура. Оптимизация выполнения команд. Конвейерная обработка. Предсказание
- 49. Увеличение скорости исполнения команд Pentium 200 МГц 0,25 мкм Intel® Pentium® III (от 450 МГц до
- 50. Использование новых архитектур процессоров Опирается на схемотехнику и усовершенствование программных методов Суперскалярность Оптимизация последовательности выполнения команд
- 51. Параллелизм на уровне команд (ILP — Instruction-Level Parallelism) Суперскалярные процессоры — это реализации ILP-процессора для последовательных
- 52. Оптимизация последовательности выполнения команд Подходы, используемые при оптимизации кода, могут существенно зависеть от критериев оптимизации. Обычно
- 53. Суммирование векторов A=B+C с помощью последовательного устройства
- 54. Суммирование векторов A=B+C с помощью двух последовательных устройств
- 55. Суммирование векторов A=B+C с помощью конвейерного устройства
- 56. Эффективность конвейерной обработки L – количество ступеней конвейера – время такта работы конвейера σ – время,
- 57. Повышение производительности за счет усовершенствования структуры ВС Усовершенствование памяти: разрядно-последовательная - разряды слова поступают для последующей
- 58. Расслоение памяти Конвейерный принцип обработки команд Параллельное функционирование нескольких независимых функциональных устройств (суперскалярная обработка)
- 59. Матричные системы (структура ILLIAC IV)
- 60. Матричные вычислительные системы Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные ВС: их каноническая архитектура
- 61. Функциональная структура матричного процессора Матричный, или векторный процессор (Array Processor) представляет собой «матрицу» связанных идентичных элементарных
- 62. Функциональная структура матричного процессора При решении сложных задач фактически один и тот же алгоритм параллельно (одновременно)
- 63. Первый матричный компьютер Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular Network — вычислительная сеть
- 64. Вычислительная система ILLIAC IV Матричная ВС ILLIAC IV создана Иллинойским университетом и корпорацией Бэрроуз (Burroughs Corporation).
- 65. Функциональная структура системы ILLIAC IV Матричная ВС ILLIAC IV (рис. 5.2) должна была состоять из четырех
- 66. Функциональная структура системы ILLIAC IV Квадрант — матричный процессор, включавший в себя устройство управления и 64
- 67. Формат представления данных системы ILLIAC IV В системе ILLIAC IV использовалось слово длиной 64 двоичных разряда.
- 68. Компонентная структура системы ILLIAC IV Элементарный процессор мог находиться в одном из двух состояний - активном
- 69. Аппаратный состав системы ILLIAC IV Подсистема ввода-вывода состояла из устройства управления, буферного запоминающего устройства и коммутатора.
- 70. Программное обеспечение системы ILLIAC IV Цель разработки ILLIAC IV — создание мощной ВС для решения задач
- 71. Программное обеспечение системы ILLIAC IV Программы В 6700, написанной, как правило, на версиях языков ALGOL или
- 72. Средства программирования системы ILLIAC IV Распределение двумерной памяти. Была разрешена адресация отдельных слов в памяти ЭП
- 73. Языки высокого уровня системы ILLIAC IV Tranquil подобен языку ALGOL и полностью не зависел от архитектуры
- 74. Применение системы ILLIAC IV Практически установлено, что ILLIAC IV была эффективна при решении широкого спектра сложных
- 75. Повышение интеллектуальности управления ЭВМ Поддержка параллелизма в аппаратно-программной среде ВС Повышение эффективности операционных систем и компиляторов,
- 76. Ссылки в сети Internet Оценка производительности ВС http://www.osp.ru/os/1996/02/58.htm http://www.sdteam.com/index.php?id=5752 http://freekniga7.narod.ru/sovremkomp/glava_3.htm Параллельная обработка данных http://www2.sscc.ru/Litera/vvv/Default.htm http://globus.smolensk.ru/user/sgma/MMORPH/N-3-html/23.htm http://www.ctc.msiu.ru/program/t-system/diploma/node5.html
- 77. Вычислительные системы Компьютерные с общей памятью (мультипроцессорные системы) Компьютерные с распределенной памятью (мультикомпьютерные системы)
- 78. Мультипроцессорные системы Первый класс – это компьютеры с общей памятью. Системы, построенные по такому принципу, иногда
- 79. Параллельные компьютеры с общей памятью
- 80. Мультикомпьютерные системы Второй класс — это компьютеры с распределенной памятью, которые по аналогии с предыдущим классом
- 81. Параллельные компьютеры с распределенной памятью
- 82. Blue Gene/L Расположение: Ливерморская национальная лаборатория имени Лоуренса Общее число процессоров 65536 штук Состоит из 64
- 83. Задачи параллельных вычислений Построении вычислительных систем с максимальной производительностью компьютеры с распределенной памятью единственным способом программирования
- 84. Организация мультипроцессорных систем (общая шина) Мультипроцессорная система с общей шиной Чтобы предотвратить одновременное обращение нескольких процессоров
- 85. Организация мультипроцессорных систем (матричный коммутатор) Матричный коммутатор позволяет разделить память на независимые модули и обеспечить возможность
- 86. Организация мультипроцессорных систем Мультипроцессорная система с омега-сетью Использование каскадных переключателей Каждый использованный коммутатор может соединить любой
- 87. Топологические связи модулей ВС Выбор той топологии связи процессоров в конкретной вычислительной системе может быть обусловлен
- 88. Варианты топологий связи процессоров и ВМ NUMA Non Uniform Memory Access
- 89. Топология двоичного гиперкубы В n-мерном пространстве в вершинах единичного n-мерного куба размещаются процессоры системы, т. е.
- 90. Достоинства и недостатки компьютеров с общей и распределенной памятью Для компьютеров с общей памятью проще создавать
- 91. Данный компьютер состоит из набора кластеров, соединенных друг с другом через межкластерную шину. Каждый кластер объединяет
- 92. Простая конфигурация с архитектурой NUMA
- 93. NUMA - архитектура NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной кэш-памяти у каждого процессорного
- 94. Проблема неоднородности доступа Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями), что в свою очередь
- 95. Языки параллельного программирования Специальные комментарии: внедрение дополнительных директив для компилятора, использование данных директив в процессе написания
- 96. Языки параллельного программирования Использование библиотек и интерфейсов, поддерживающих взаимодействие параллельных процессов: подготовка программного кода на любом
- 97. Примеры языков программирования и надстроек OpenMP High Performance Fortran (HPF) Occam, Sisal, Норма Linda, Massage Passing
- 98. Массивно-параллельная архитектура Массивно-параллельная архитектура (англ. MPP, Massive Parallel Processing) — класс архитектур параллельных вычислительных систем. Особенность
- 100. Основные классы современных параллельных компьютеров Массивно-параллельные системы (MPP) Архитектура Система состоит из однородных вычислительных узлов, включающих:
- 101. Симметричное мультипроцессирование SMP часто применяется в науке, промышленности, бизнесе, где программное обеспечение специально разрабатывается для многопоточного
- 103. Архитектура Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков).
- 104. Основные классы современных параллельных компьютеров Системы с неоднородным доступом к памяти (NUMA) Архитектура Система состоит из
- 105. Основные классы современных параллельных компьютеров Параллельные векторные системы (PVP) Архитектура Основным признаком PVP-систем является наличие специальных
- 106. Основные классы современных параллельных компьютеров Кластерные системы Архитектура Набор рабочих станций (или даже ПК) общего назначения,
- 107. Ссылки на литературу Анализ мультипроцессорных систем с иерархической памятью http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm Языки параллельной обработки http://ibd.tsi.lv/cgi/sart2.pl?T1=ZAG Архитектура и
- 108. Матричные вычислительные системы Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные ВС: их каноническая архитектура
- 109. Функциональная структура матричного процессора Матричный, или векторный процессор (Array Processor) представляет собой «матрицу» связанных идентичных элементарных
- 110. Функциональная структура матричного процессора При решении сложных задач фактически один и тот же алгоритм параллельно (одновременно)
- 111. Первый матричный компьютер Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular Network — вычислительная сеть
- 112. Вычислительная система ILLIAC IV Матричная ВС ILLIAC IV создана Иллинойским университетом и корпорацией Бэрроуз (Burroughs Corporation).
- 113. Функциональная структура системы ILLIAC IV Матричная ВС ILLIAC IV (рис. 5.2) должна была состоять из четырех
- 114. Функциональная структура системы ILLIAC IV Квадрант — матричный процессор, включавший в себя устройство управления и 64
- 115. Формат представления данных системы ILLIAC IV В системе ILLIAC IV использовалось слово длиной 64 двоичных разряда.
- 116. Компонентная структура системы ILLIAC IV Элементарный процессор мог находиться в одном из двух состояний - активном
- 117. Аппаратный состав системы ILLIAC IV Подсистема ввода-вывода состояла из устройства управления, буферного запоминающего устройства и коммутатора.
- 118. Программное обеспечение системы ILLIAC IV Цель разработки ILLIAC IV — создание мощной ВС для решения задач
- 119. Программное обеспечение системы ILLIAC IV Программы В 6700, написанной, как правило, на версиях языков ALGOL или
- 120. Средства программирования системы ILLIAC IV Распределение двумерной памяти. Была разрешена адресация отдельных слов в памяти ЭП
- 121. Языки высокого уровня системы ILLIAC IV Tranquil подобен языку ALGOL и полностью не зависел от архитектуры
- 122. Применение системы ILLIAC IV Практически установлено, что ILLIAC IV была эффективна при решении широкого спектра сложных
- 123. Классификация вычислительных систем Классификация Флинна Классификация Хокни Классификация Фенга Классификация Дункана Классификация Хендлера Классификация Шнайдера Классификация
- 124. Классификация Флина Базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором.
- 125. Архитектуры ЭВМ MIMD-архитектура MISD-архитектура SIMD- архитектура SISD- архитектура
- 126. Недостатки классификации Флина Некоторые архитектуры четко не вписываются в данную классификацию Чрезмерная заполненность класса MIMD
- 127. Классификация Хокни Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами:
- 128. Классификация Хокни
- 129. Примеры классификации Флина SISD – PDP-11, VAX 11/780, CDC 6600 и CDC 7600 SIMD – ILLIAC
- 130. Классификация Фенга Идея классификации вычислительных систем на основе двух простых характеристик. Первая - число бит n
- 131. Классификация Фенга Любую вычислительную систему C можно описать парой чисел (n, m) и представить точкой на
- 132. Примеры классификации Фенга Разрядно-последовательные пословно-последовательные (n=m=1): MINIMA с естественным описанием (1,1) Разрядно-параллельные пословно-последовательные (n>1; m=1): IBM
- 133. Недостаток не делает никакого различия между процессорными матрицами, векторно-конвейерными и многопроцессорными системами; отсутствует акцент на том,
- 134. Классификация Дункана Дункан определил набор требований для создания своей классификации. Из классификации должны быть исключены машины,
- 135. Классификация Дункана
- 136. Основные архитектуры, представленные на рисунке рисунка Систолические архитектуры представляют собой множество процессоров, объединенных регулярным образом. Обращение
- 137. Классификация Хендлера Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
- 138. Классификация Хендлера t(C) = (k, d, w) t( PEPE ) = (k×k',d×d',w×w') где: k - число
- 139. Дополнения к классификации Хендлера Хендлер предлагает использовать три операции: Первая операция (×) отражает конвейерный принцип обработки
- 140. Примеры классификации Хендлера t( MINIMA ) = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON
- 141. Классификация Шнайдера Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и
- 142. Классификация Шнайдера Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая Sa, - это последовательность,
- 143. Классификация Шнайдера (кратко) Поток ссылок: S = { (a1 ) (a2 )..., (b1 ) (b2 )...,
- 144. Классы компьютеров в соответствии с классификацией Шнайдера IssDss - фон-неймановские машины; IssDsc - фон-неймановские машины, в
- 145. Классификация Скилликорна Архитектура любого компьютера состоит из: процессора команд (IP –Instruction Processor); процессора данных (DP –
- 146. Примеры классификации Скилликорна Connection Machine 2 (1, 1, 1-1, n, n, n-n, 1-n, nxn) BBN Butterfly,
- 147. Когерентность памяти. Коммутаторы ВС. Организация когерентности многоуровневой иерархической памяти классифицировать по способу размещения данных в иерархической
- 148. Многопроцессорную ВС можно рассматривать как совокупность процессоров, подсоединенных к многоуровневой иерархической памяти. При таком представлении коммуникационная
- 149. Классифицировать по способу размещения данных в иерархической памяти и способу доступа к этим данным Явное размещение
- 150. Классифицировать по способу размещения данных в иерархической памяти и способу доступа к этим данным Неявное размещение
- 151. Кластерные системы LAN – Local Area Network, локальная сеть SAN – Storage Area Network, сеть хранения
- 152. Кластерные системы Сообщение, доставленное в компьютер-адресат, воспринимается через входной линк адаптером этого компьютера. Сообщение содержит один,
- 153. Blue Gene/L Расположение: Ливерморская национальная лаборатория имени Лоуренса Общее число процессоров 65536 штук Состоит из 64
- 154. Разместить переменную A по адресу 007 модуля 27 Разместить переменную A по адресу 0675 Считать В
- 155. Механизм неявной реализации когерентности Реализация механизма когерентности в ВС с разделяемой памятью требует аппаратурно-временных затрат. Уменьшить
- 156. Способы организации кэш-памяти при однопроцессорном подходе Прямое отображение Ассоциативное отображение Частично ассоциативное отображение
- 157. Методы обновления ОП при однопроцессорном подходе к организация механизма неявной реализации когерентности (организация когерентности при однопроцессорном
- 158. Сосредоточенная память Каждый ВМ имеет собственную локальную кэш-память, имеется общая разделяемая основная память, все ВМ подсоединены
- 159. Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с сосредоточенной памятью Алгоритм поддержки когерентности
- 160. Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с сосредоточенной памятью Для управления режимом
- 161. Реализация когерентности (многопроцессорный подход при сосредоточенной памяти) Процессор Кэш-память Оперативная память Строка N Строка N E
- 162. Прямолинейный подход к поддержанию когерентности кэшей в мультипроцессорной системе, основная память которой распределена по ВМ, заключается
- 163. Многопроцессорный подход к организация механизма неявной реализации когерентности в системах физически распределенной памятью Когерентность кэшей обеспечивается
- 164. Алгоритм DASH Каждый модуль памяти имеет для каждой строки, резидентной в модуле, список модулей, в кэшах
- 165. Каждый процессор может читать из своего кэша, если состояние читаемой строки "разделяемая" или "измененная". Если строка
- 166. Если процессор выполняет операцию записи и состояние строки, в которую производится запись "измененная", то запись выполняется
- 167. Пример обеспечения когерентности памятей ВМ
- 168. Механизм явной реализации когерентности При явной реализации когерентности используются отдельные наборы команд типа load, store для
- 169. Реализация коммутационной среды Процесс реализации коммутационной среды можно разделить на три этапа. На структурном уровне коммуникационная
- 170. Реализация коммутационной среды Адаптер ВМ Соединение ВМ в коммутационную сеть
- 171. Простые коммутаторы с временным разделением Простые коммутаторы бывают с временным и пространственным разделением. Достоинства простых коммутаторов:
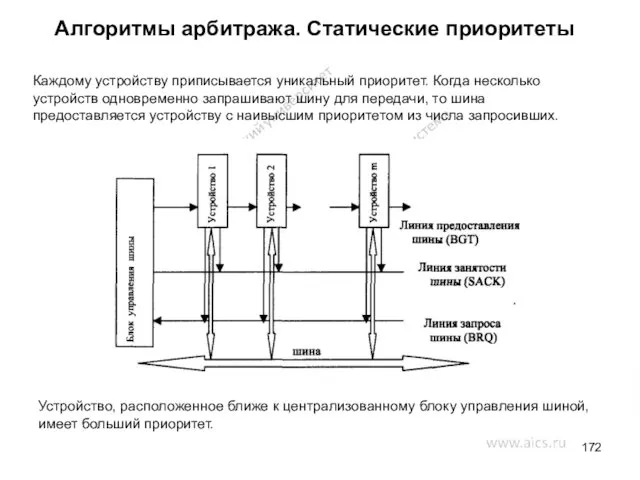
- 172. Алгоритмы арбитража. Статические приоритеты Каждому устройству приписывается уникальный приоритет. Когда несколько устройств одновременно запрашивают шину для
- 173. Алгоритмы арбитража. Фиксированные временные интервалы Алгоритм предоставляет каждому устройству одинаковый временной интервал по циклической дисциплине. Если
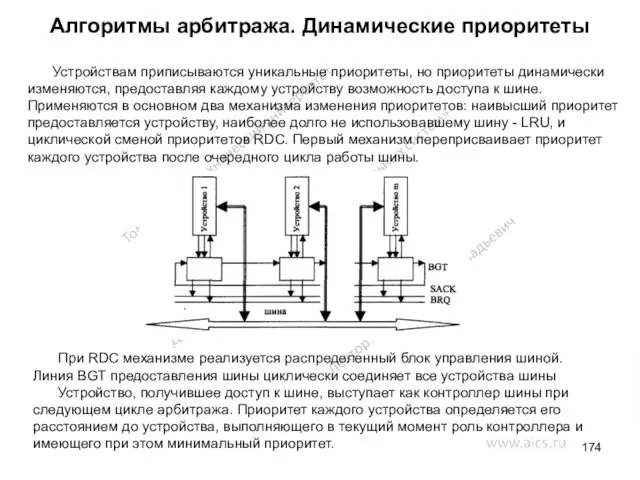
- 174. Алгоритмы арбитража. Динамические приоритеты Устройствам приписываются уникальные приоритеты, но приоритеты динамически изменяются, предоставляя каждому устройству возможность
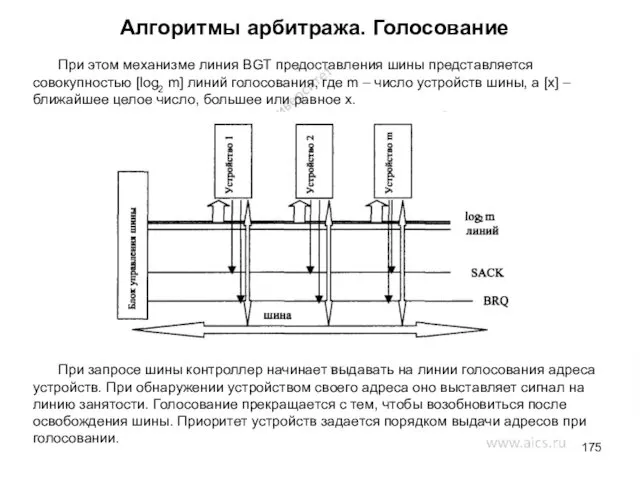
- 175. Алгоритмы арбитража. Голосование При этом механизме линия BGT предоставления шины представляется совокупностью [log2 m] линий голосования,
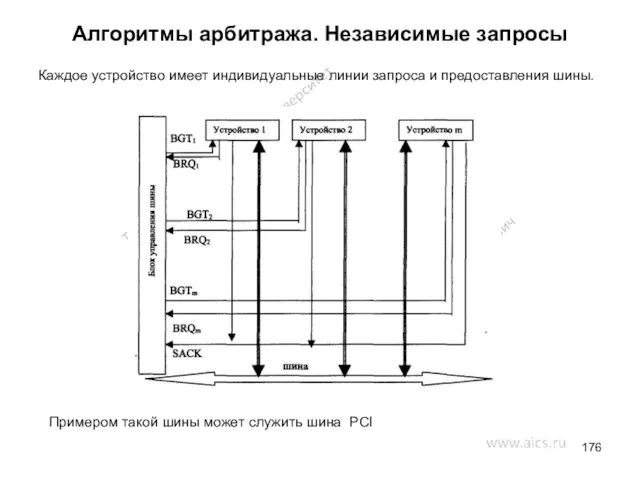
- 176. Алгоритмы арбитража. Независимые запросы Каждое устройство имеет индивидуальные линии запроса и предоставления шины. Примером такой шины
- 177. Простые коммутаторы с пространственным разделением
- 178. Прямоугольные коммутаторы 2х2
- 179. Коммутатор Клоза
- 180. Распределенные составные коммутаторы
- 181. Список литературы Иерархическая память многопроцессорных ВС http://www.uran.donetsk.ua/~masters/2001/fvti/prokopenko/diss/ch03.htm Анализ мультипроцессорных систем с иерархической памятью http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm Многопроцессорные системы
- 189. Скачать презентацию
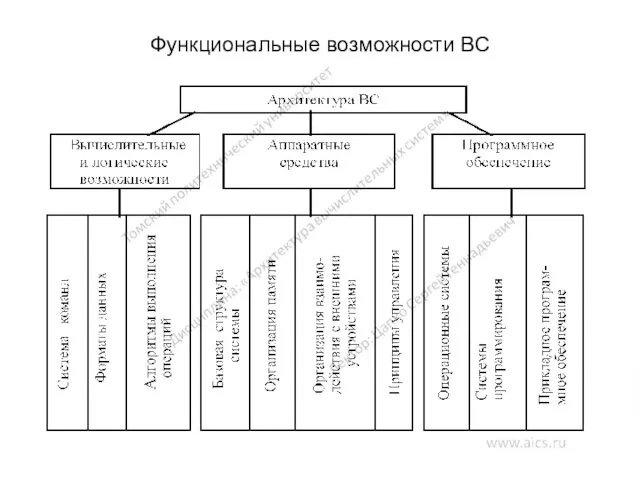
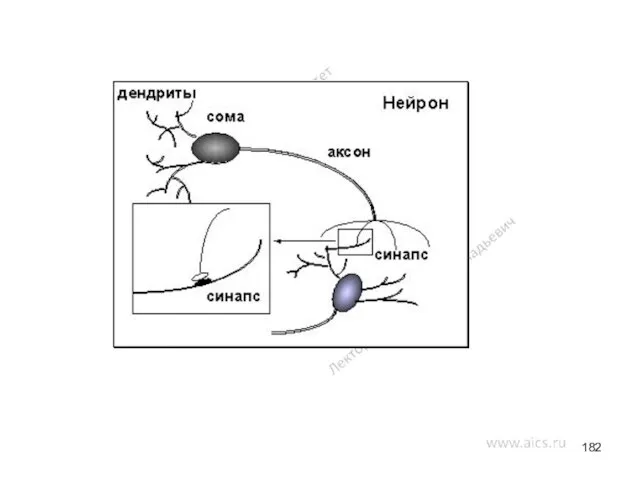
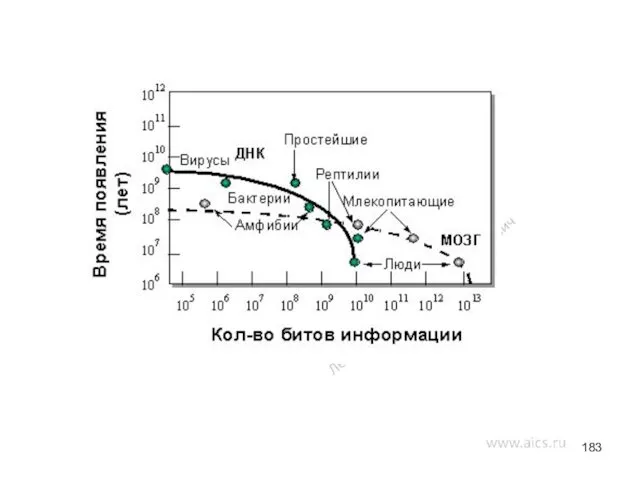
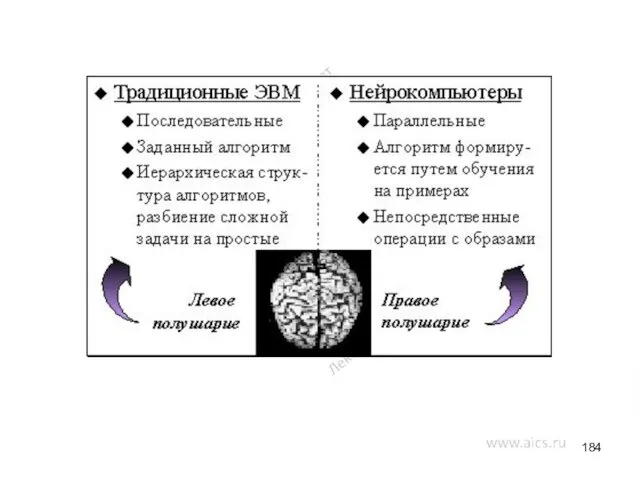
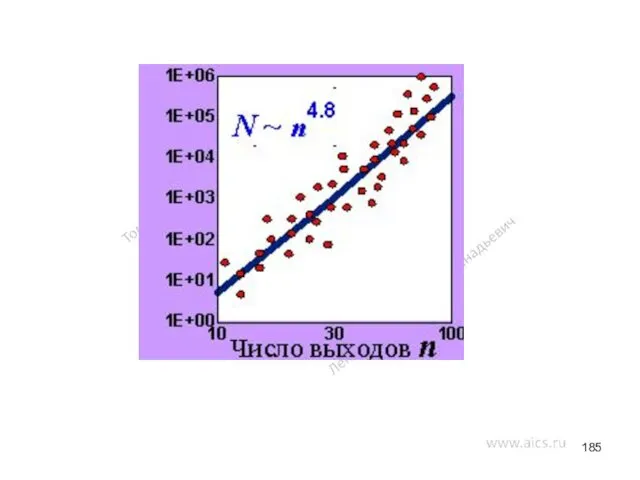
Функциональные возможности ВС
Функциональные возможности ВС

Составные части понятия «архитектура»
Вычислительные и логические возможности ВС. Они обусловливаются системой
Составные части понятия «архитектура»
Вычислительные и логические возможности ВС. Они обусловливаются системой
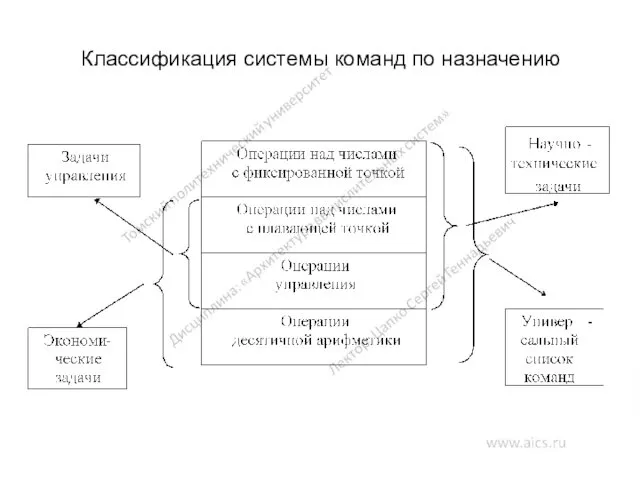
Классификация системы команд по назначению
Классификация системы команд по назначению

Аппаратные средства. Простейшая ВС включает модули пяти типов: центральный процессор, основная
Аппаратные средства. Простейшая ВС включает модули пяти типов: центральный процессор, основная
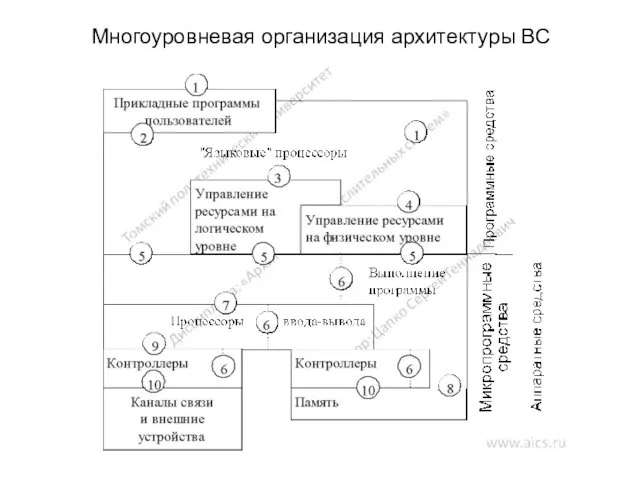
Многоуровневая организация архитектуры ВС
Многоуровневая организация архитектуры ВС

Этапы разработки типовых проектов
(характерны для процесса разработки архитектуры ЭВМ)
анализ требований, предъявляемых
Этапы разработки типовых проектов
(характерны для процесса разработки архитектуры ЭВМ)
анализ требований, предъявляемых

Конструкции языков программирования, вызывающие семантический разрыв
Массивы (реализация принципа организации данных
Конструкции языков программирования, вызывающие семантический разрыв
Массивы (реализация принципа организации данных

Основные характеристики архитектуры фон Неймановского типа
последовательно адресуемая единственная память линейного
Основные характеристики архитектуры фон Неймановского типа
последовательно адресуемая единственная память линейного

Требования ЯВУ к архитектуре ЭВМ
память состоит из набора дискретных именуемых
Требования ЯВУ к архитектуре ЭВМ
память состоит из набора дискретных именуемых
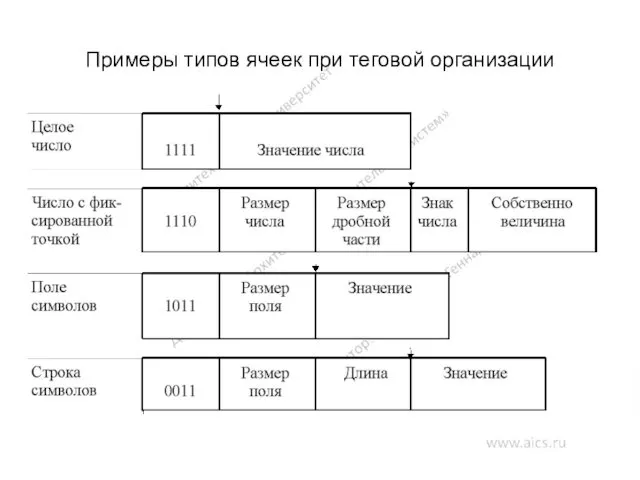
Примеры типов ячеек при теговой организации
Примеры типов ячеек при теговой организации
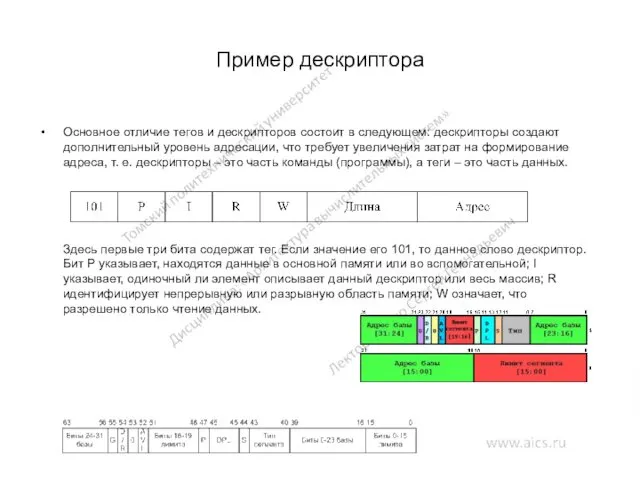
Пример дескриптора
Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают
Пример дескриптора
Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают
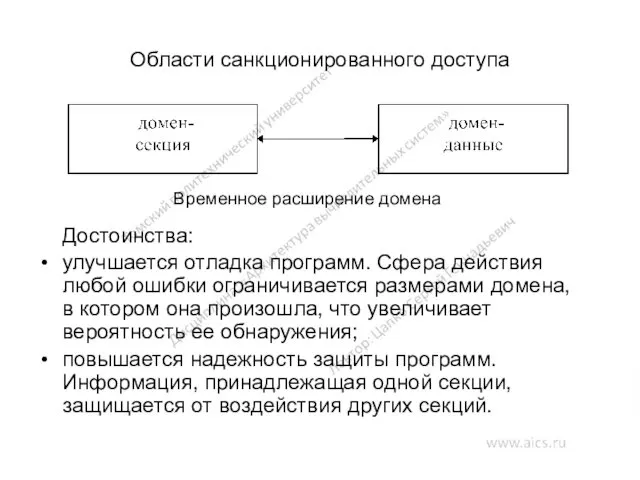
Области санкционированного доступа
Достоинства:
улучшается отладка программ. Сфера действия любой ошибки ограничивается размерами
Области санкционированного доступа
Достоинства:
улучшается отладка программ. Сфера действия любой ошибки ограничивается размерами

Одноуровневая память
Достоинства:
сравнительно низкая стоимость программного обеспечения;
независимость адресации от принципа организации памяти.
Трудности
Одноуровневая память
Достоинства:
сравнительно низкая стоимость программного обеспечения;
независимость адресации от принципа организации памяти.
Трудности

Достоинства виртуальной памяти
Однородность области адресов
каждый процесс может выполняться в памяти
Достоинства виртуальной памяти
Однородность области адресов
каждый процесс может выполняться в памяти
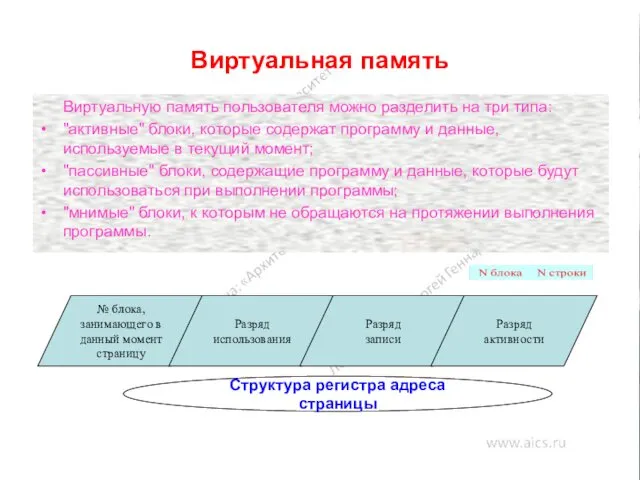
Виртуальная память
Виртуальную память пользователя можно разделить на три типа:
"активные" блоки, которые
Виртуальная память
Виртуальную память пользователя можно разделить на три типа:
"активные" блоки, которые
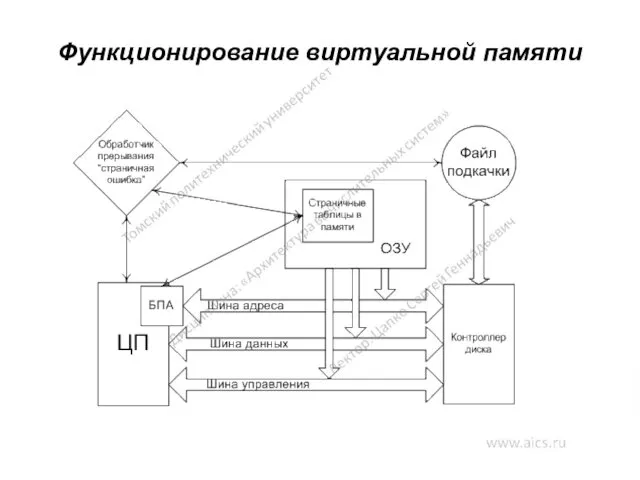
Функционирование виртуальной памяти
Функционирование виртуальной памяти
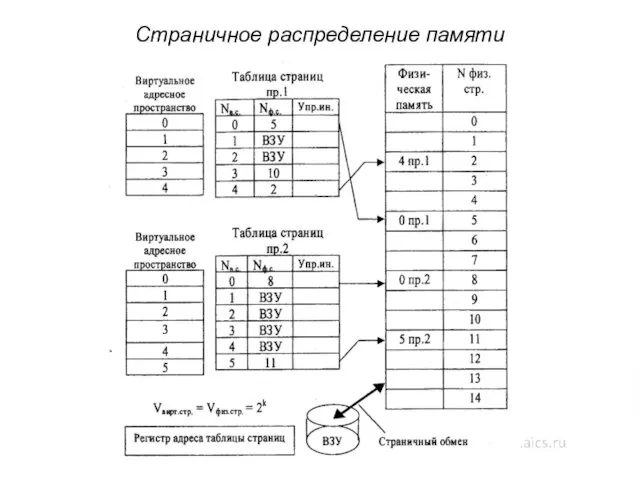
Страничное распределение памяти
Страничное распределение памяти
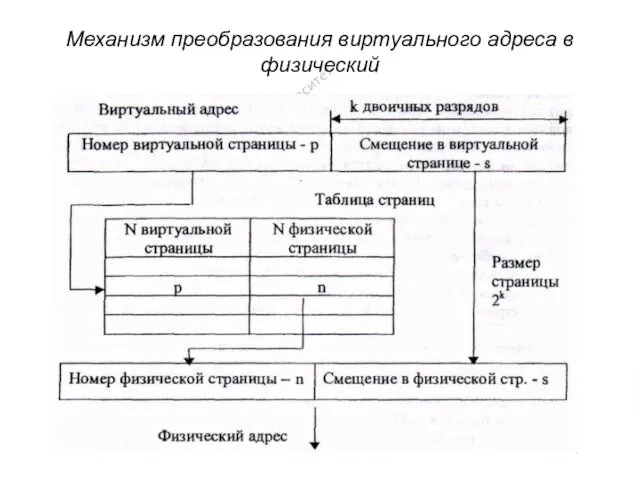
Механизм преобразования виртуального адреса в физический
Механизм преобразования виртуального адреса в физический
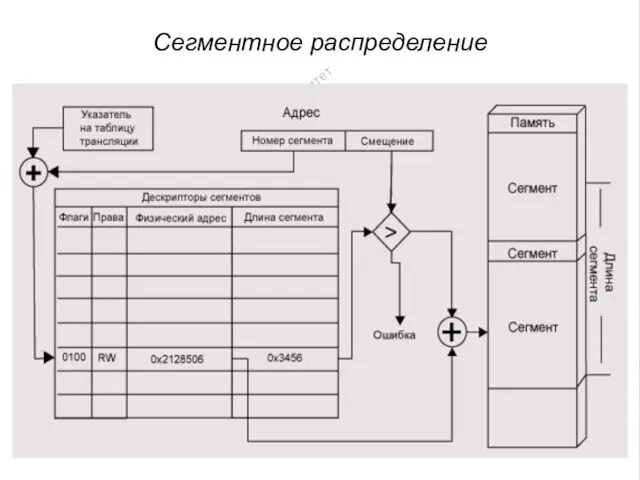
Сегментное распределение
Сегментное распределение
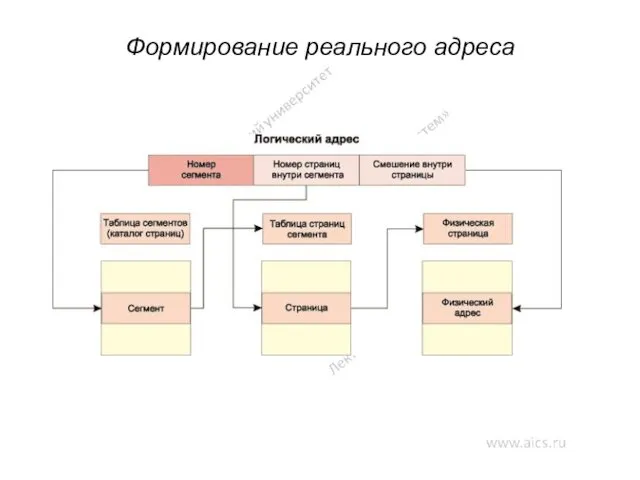
Формирование реального адреса
Формирование реального адреса
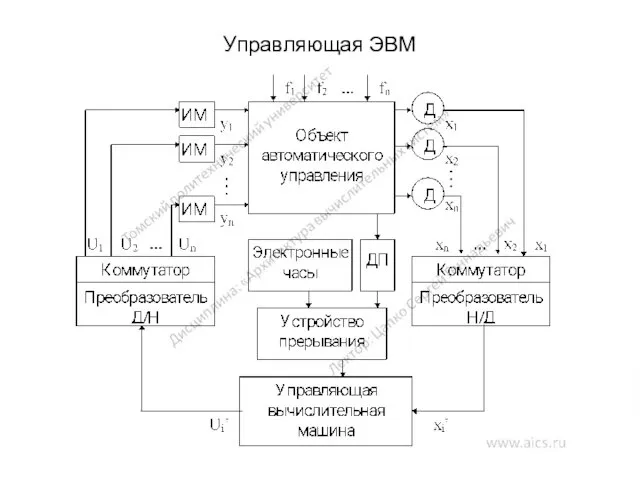
Управляющая ЭВМ
Управляющая ЭВМ
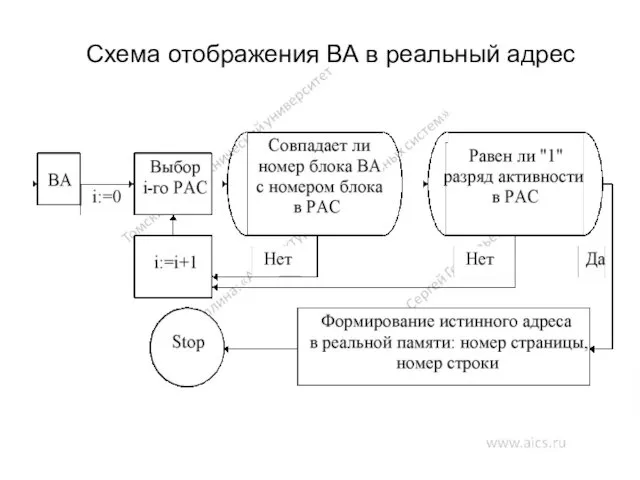
Схема отображения ВА в реальный адрес
Схема отображения ВА в реальный адрес
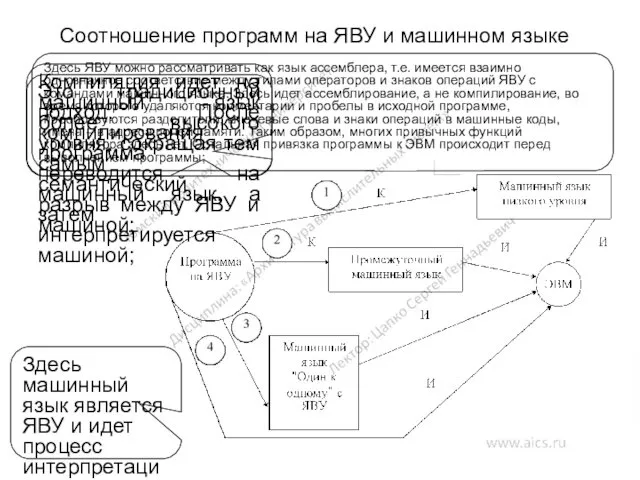
Соотношение программ на ЯВУ и машинном языке
Это традиционный подход. После
Соотношение программ на ЯВУ и машинном языке
Это традиционный подход. После

Основные принципы RISC-архитектуры
каждая команда независимо от ее типа выполняется за
Основные принципы RISC-архитектуры
каждая команда независимо от ее типа выполняется за

Отличительные особенности CISC- и RISC-архитектур
Достоинства RISC-архитектуры:
Компактность процессора, как следствие отсутствие проблем
Отличительные особенности CISC- и RISC-архитектур
Достоинства RISC-архитектуры:
Компактность процессора, как следствие отсутствие проблем

Экспериментальное измерение количественной оценки операций
Результаты измерений в статике, проведенные для программ-компиляторов:
Экспериментальное измерение количественной оценки операций
Результаты измерений в статике, проведенные для программ-компиляторов:
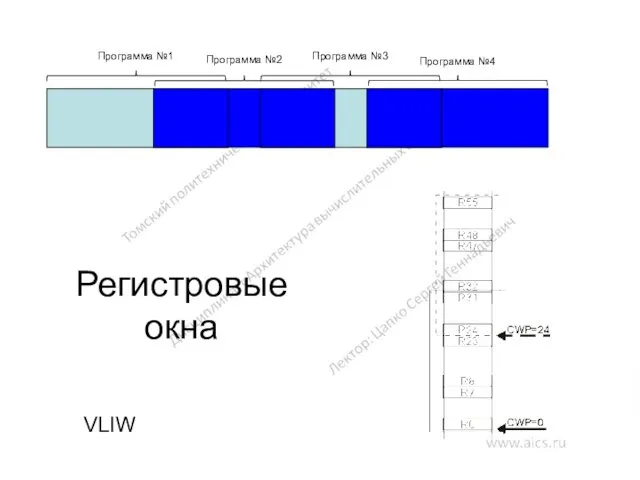
Регистровые окна
VLIW
Программа №1
Программа №2
Программа №3
Программа №4
Регистровые окна
VLIW
Программа №1
Программа №2
Программа №3
Программа №4

VLIW-архитектура
Процессор VLIW, имеющий схему, представленную выше, может выполнять в предельном случае
VLIW-архитектура
Процессор VLIW, имеющий схему, представленную выше, может выполнять в предельном случае
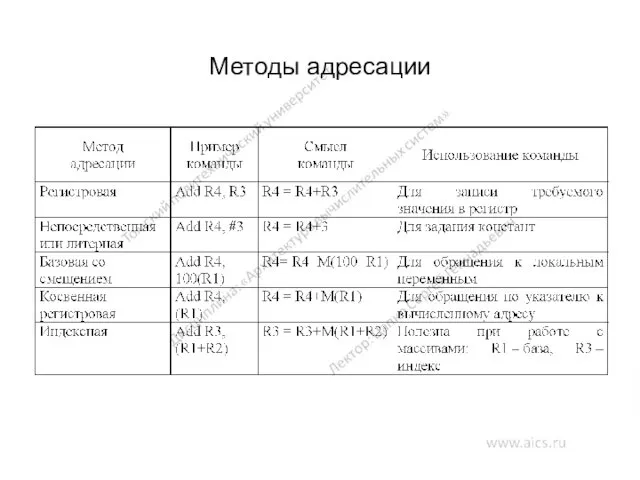
Методы адресации
Методы адресации
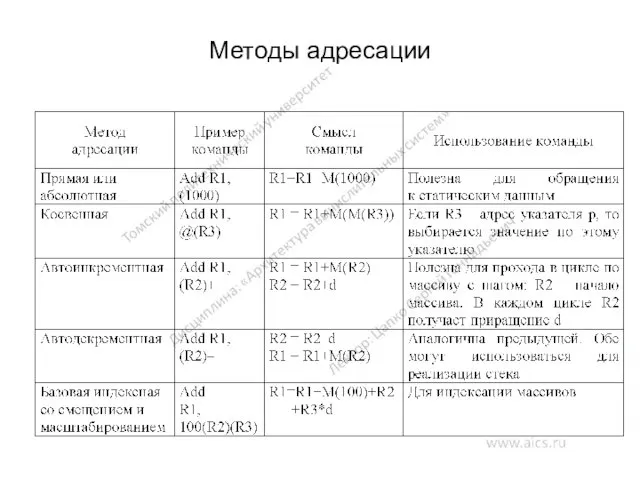
Методы адресации
Методы адресации
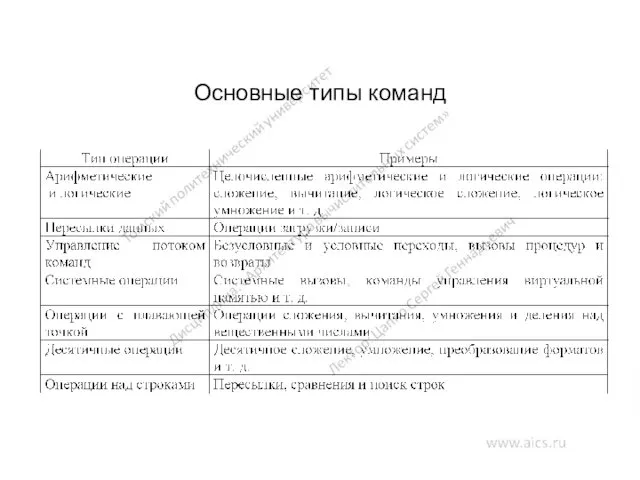
Основные типы команд
Основные типы команд
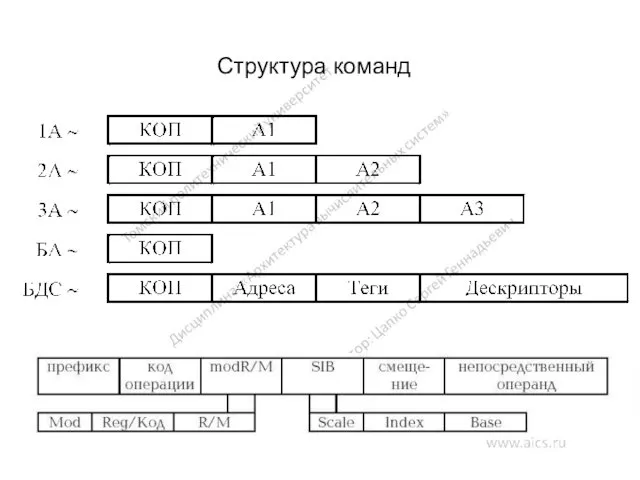
Структура команд
Структура команд
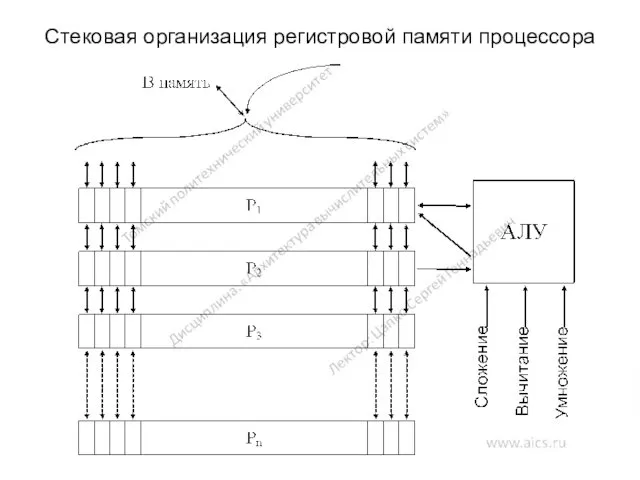
Стековая организация регистровой памяти процессора
Стековая организация регистровой памяти процессора

Основные операция и спецкоманды
Операции с регистрами:
Движение вниз: (P1) → P2, (P2) → P3, ..., а P1
Основные операция и спецкоманды
Операции с регистрами:
Движение вниз: (P1) → P2, (P2) → P3, ..., а P1

Программа решения математической задачи для одноадресного компьютера
Программа решения математической задачи для одноадресного компьютера
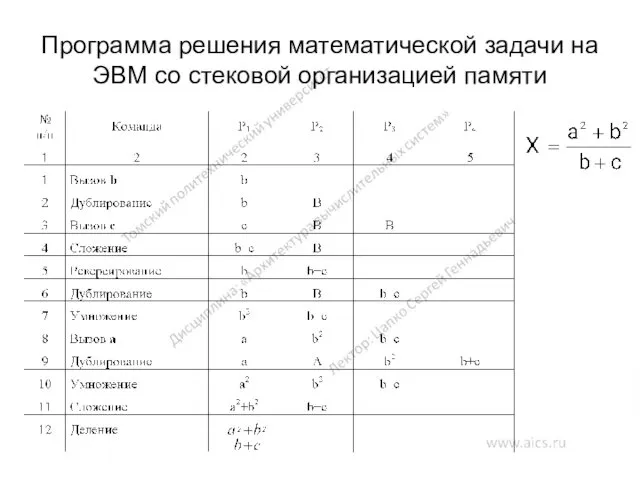
Программа решения математической задачи на ЭВМ со стековой организацией памяти
Программа решения математической задачи на ЭВМ со стековой организацией памяти

Способы проектирования системы команд
Сокращение набора команд, присущих СК выбранного микропроцессора. Все
Способы проектирования системы команд
Сокращение набора команд, присущих СК выбранного микропроцессора. Все
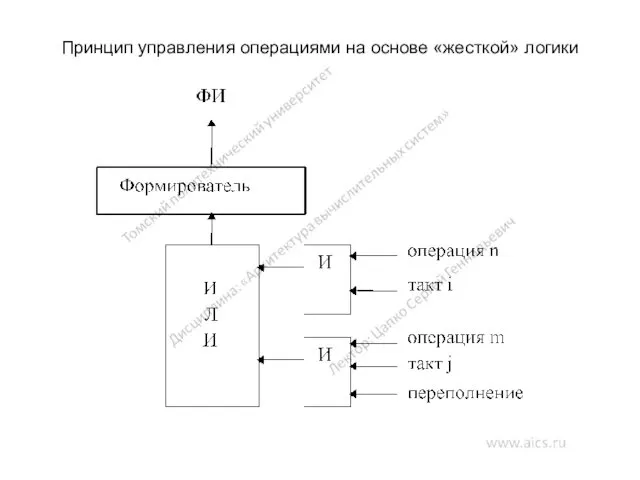
Принцип управления операциями на основе «жесткой» логики
Принцип управления операциями на основе «жесткой» логики
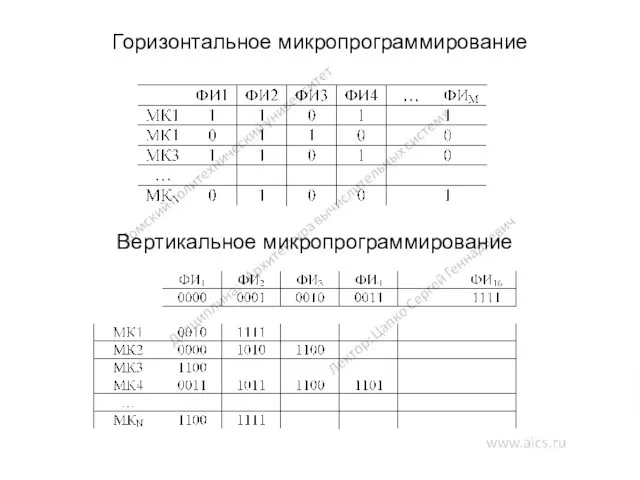
Горизонтальное микропрограммирование
Вертикальное микропрограммирование
Горизонтальное микропрограммирование
Вертикальное микропрограммирование

Оценка современных компьютеров
Узкие места современных ЭВМ
Оценка производительности ВС
Методы повышения производительности ЭВМ
Компьютеры
Оценка современных компьютеров
Узкие места современных ЭВМ
Оценка производительности ВС
Методы повышения производительности ЭВМ
Компьютеры

Основные причины возникновения узких мест в компьютере
состав, принцип работы и
Основные причины возникновения узких мест в компьютере
состав, принцип работы и

Методы оценки производительности ВС
Пиковая производительность (суммарное количество операций, выполняемых в единицу
Методы оценки производительности ВС
Пиковая производительность (суммарное количество операций, выполняемых в единицу

Основные проблемы, связанные с анализом результатов контрольного тестирования производительности
отделение показателей,
Основные проблемы, связанные с анализом результатов контрольного тестирования производительности
отделение показателей,

Стандартные тесты
LinPack - совокупность программ для решения задач линейной алгебры
В качестве
Стандартные тесты
LinPack - совокупность программ для решения задач линейной алгебры
В качестве
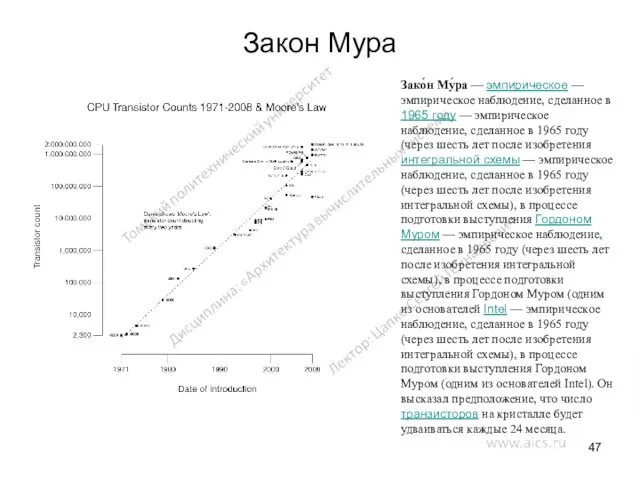
Закон Мура
Зако́н Му́ра — эмпирическое — эмпирическое наблюдение, сделанное в 1965 году — эмпирическое
Закон Мура
Зако́н Му́ра — эмпирическое — эмпирическое наблюдение, сделанное в 1965 году — эмпирическое

Увеличение скорости исполнения команд
Использование новых архитектур процессоров
Суперскалярная архитектура.
Оптимизация выполнения команд.
Конвейерная обработка.
Предсказание
Увеличение скорости исполнения команд
Использование новых архитектур процессоров
Суперскалярная архитектура.
Оптимизация выполнения команд.
Конвейерная обработка.
Предсказание

Увеличение скорости исполнения команд
Pentium 200 МГц 0,25 мкм
Intel® Pentium® III (от
Увеличение скорости исполнения команд
Pentium 200 МГц 0,25 мкм
Intel® Pentium® III (от
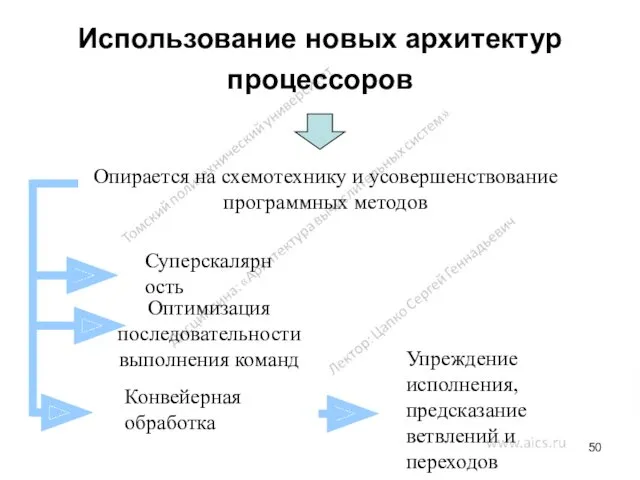
Использование новых архитектур процессоров
Опирается на схемотехнику и усовершенствование программных методов
Использование новых архитектур процессоров
Опирается на схемотехнику и усовершенствование программных методов

Параллелизм на уровне команд
(ILP — Instruction-Level Parallelism)
Суперскалярные процессоры — это
Параллелизм на уровне команд
(ILP — Instruction-Level Parallelism)
Суперскалярные процессоры — это
Оптимизация последовательности выполнения команд
Подходы, используемые при оптимизации кода,
могут существенно зависеть от
Оптимизация последовательности выполнения команд
Подходы, используемые при оптимизации кода,
могут существенно зависеть от
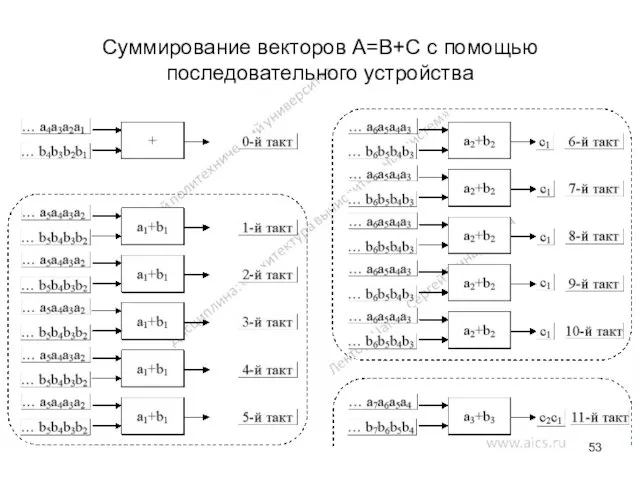
Суммирование векторов A=B+C с помощью последовательного устройства
Суммирование векторов A=B+C с помощью последовательного устройства
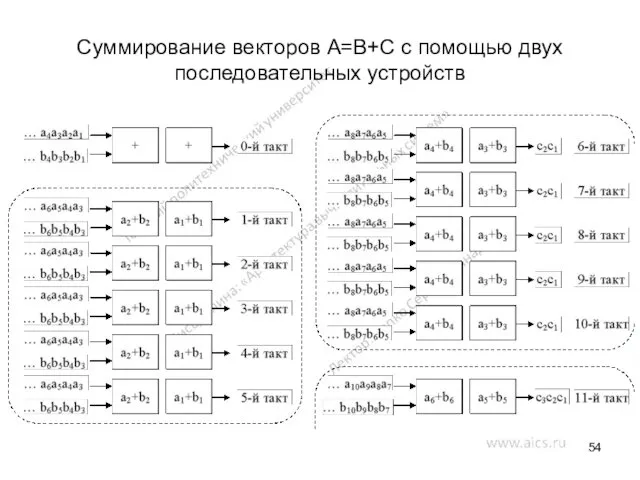
Суммирование векторов A=B+C с помощью двух последовательных устройств
Суммирование векторов A=B+C с помощью двух последовательных устройств

Суммирование векторов A=B+C с помощью конвейерного устройства
Суммирование векторов A=B+C с помощью конвейерного устройства
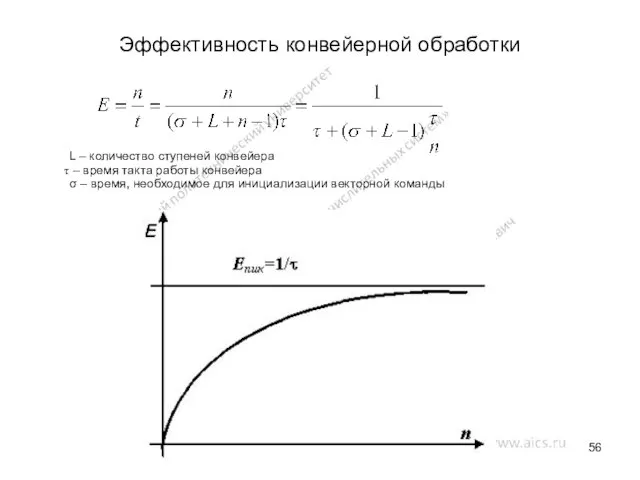
Эффективность конвейерной обработки
L – количество ступеней конвейера
– время такта работы
Эффективность конвейерной обработки
L – количество ступеней конвейера
– время такта работы

Повышение производительности за счет усовершенствования структуры ВС
Усовершенствование памяти:
разрядно-последовательная - разряды слова
Повышение производительности за счет усовершенствования структуры ВС
Усовершенствование памяти:
разрядно-последовательная - разряды слова
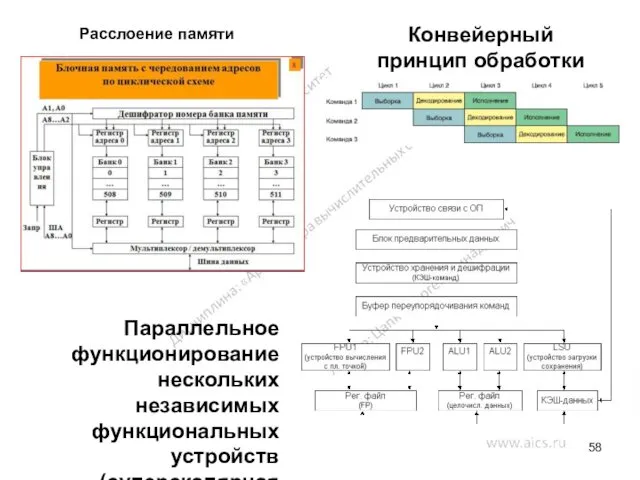
Расслоение памяти
Конвейерный принцип обработки команд
Параллельное функционирование нескольких независимых функциональных устройств (суперскалярная
Расслоение памяти
Конвейерный принцип обработки команд
Параллельное функционирование нескольких независимых функциональных устройств (суперскалярная

Матричные системы (структура ILLIAC IV)
Матричные системы (структура ILLIAC IV)

Матричные вычислительные системы
Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные
Матричные вычислительные системы
Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные
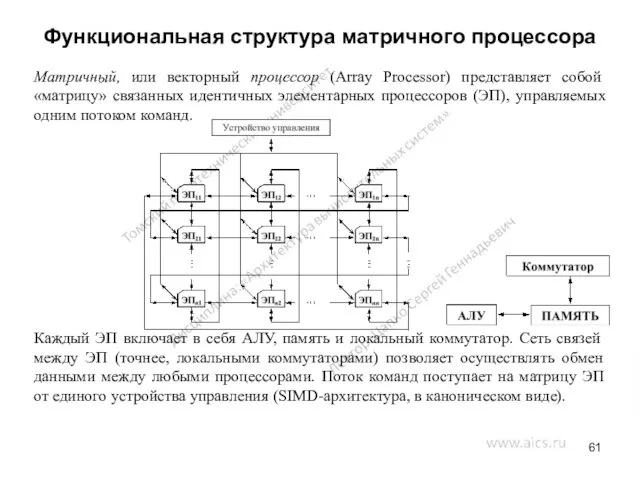
Функциональная структура матричного процессора
Матричный, или векторный процессор (Array Processor) представляет собой
Функциональная структура матричного процессора
Матричный, или векторный процессор (Array Processor) представляет собой

Функциональная структура матричного процессора
При решении сложных задач фактически один и тот
Функциональная структура матричного процессора
При решении сложных задач фактически один и тот

Первый матричный компьютер
Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular
Первый матричный компьютер
Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular

Вычислительная система ILLIAC IV
Матричная ВС ILLIAC IV создана Иллинойским университетом
Вычислительная система ILLIAC IV
Матричная ВС ILLIAC IV создана Иллинойским университетом

Функциональная структура системы ILLIAC IV
Матричная ВС ILLIAC IV (рис. 5.2)
Функциональная структура системы ILLIAC IV
Матричная ВС ILLIAC IV (рис. 5.2)

Функциональная структура системы ILLIAC IV
Квадрант — матричный процессор, включавший в себя
Функциональная структура системы ILLIAC IV
Квадрант — матричный процессор, включавший в себя

Формат представления данных системы ILLIAC IV
В системе ILLIAC IV использовалось слово
Формат представления данных системы ILLIAC IV
В системе ILLIAC IV использовалось слово
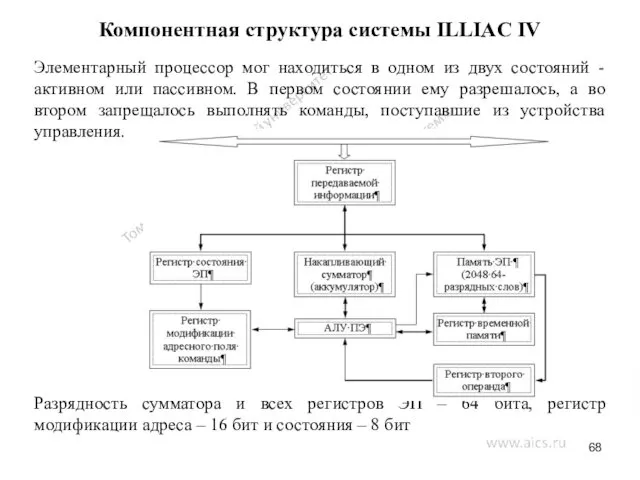
Компонентная структура системы ILLIAC IV
Элементарный процессор мог находиться в одном из
Компонентная структура системы ILLIAC IV
Элементарный процессор мог находиться в одном из

Аппаратный состав системы ILLIAC IV
Подсистема ввода-вывода состояла из устройства управления, буферного
Аппаратный состав системы ILLIAC IV
Подсистема ввода-вывода состояла из устройства управления, буферного

Программное обеспечение системы ILLIAC IV
Цель разработки ILLIAC IV — создание мощной
Программное обеспечение системы ILLIAC IV
Цель разработки ILLIAC IV — создание мощной

Программное обеспечение системы ILLIAC IV
Программы В 6700, написанной, как правило, на
Программное обеспечение системы ILLIAC IV
Программы В 6700, написанной, как правило, на

Средства программирования системы ILLIAC IV
Распределение двумерной памяти. Была разрешена адресация отдельных
Средства программирования системы ILLIAC IV
Распределение двумерной памяти. Была разрешена адресация отдельных

Языки высокого уровня системы ILLIAC IV
Tranquil подобен языку ALGOL и полностью
Языки высокого уровня системы ILLIAC IV
Tranquil подобен языку ALGOL и полностью

Применение системы ILLIAC IV
Практически установлено, что ILLIAC IV была эффективна при
Применение системы ILLIAC IV
Практически установлено, что ILLIAC IV была эффективна при

Повышение интеллектуальности управления ЭВМ
Поддержка параллелизма в аппаратно-программной среде ВС
Повышение эффективности операционных
Повышение интеллектуальности управления ЭВМ
Поддержка параллелизма в аппаратно-программной среде ВС
Повышение эффективности операционных

Ссылки в сети Internet
Оценка производительности ВС
http://www.osp.ru/os/1996/02/58.htm
http://www.sdteam.com/index.php?id=5752
http://freekniga7.narod.ru/sovremkomp/glava_3.htm
Параллельная обработка данных
http://www2.sscc.ru/Litera/vvv/Default.htm
http://globus.smolensk.ru/user/sgma/MMORPH/N-3-html/23.htm
http://www.ctc.msiu.ru/program/t-system/diploma/node5.html
Конвейерная обработка данных
http://www.ctc.msiu.ru/program/t-system/diploma/node5.html
http://www.macro.aaanet.ru/apnd_4.html
Ссылки в сети Internet
Оценка производительности ВС
http://www.osp.ru/os/1996/02/58.htm
http://www.sdteam.com/index.php?id=5752
http://freekniga7.narod.ru/sovremkomp/glava_3.htm
Параллельная обработка данных
http://www2.sscc.ru/Litera/vvv/Default.htm
http://globus.smolensk.ru/user/sgma/MMORPH/N-3-html/23.htm
http://www.ctc.msiu.ru/program/t-system/diploma/node5.html
Конвейерная обработка данных
http://www.ctc.msiu.ru/program/t-system/diploma/node5.html
http://www.macro.aaanet.ru/apnd_4.html
Вычислительные системы
Компьютерные с общей памятью (мультипроцессорные системы)
Компьютерные с распределенной памятью
(мультикомпьютерные системы)
Вычислительные системы
Компьютерные с общей памятью (мультипроцессорные системы)
Компьютерные с распределенной памятью
(мультикомпьютерные системы)

Мультипроцессорные системы
Первый класс – это компьютеры с общей памятью. Системы, построенные
Мультипроцессорные системы
Первый класс – это компьютеры с общей памятью. Системы, построенные
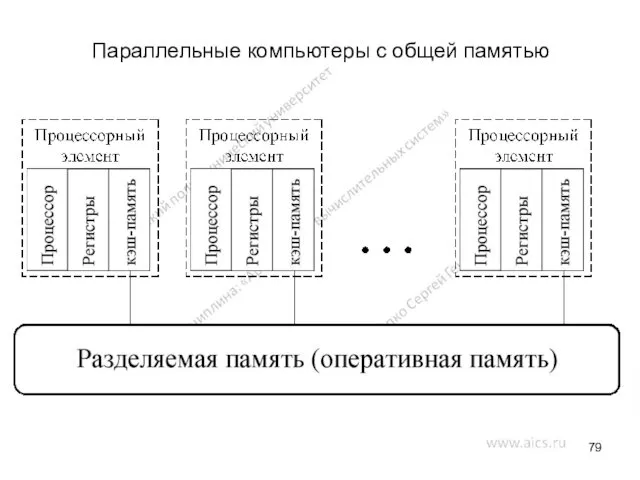
Параллельные компьютеры с общей памятью
Параллельные компьютеры с общей памятью

Мультикомпьютерные системы
Второй класс — это компьютеры с распределенной памятью, которые по
Мультикомпьютерные системы
Второй класс — это компьютеры с распределенной памятью, которые по

Параллельные компьютеры с распределенной памятью
Параллельные компьютеры с распределенной памятью

Blue Gene/L
Расположение:
Ливерморская национальная лаборатория имени Лоуренса
Общее число процессоров 65536 штук
Состоит из
Blue Gene/L
Расположение:
Ливерморская национальная лаборатория имени Лоуренса
Общее число процессоров 65536 штук
Состоит из

Задачи параллельных вычислений
Построении вычислительных систем с максимальной производительностью
компьютеры с распределенной памятью
единственным
Задачи параллельных вычислений
Построении вычислительных систем с максимальной производительностью
компьютеры с распределенной памятью
единственным
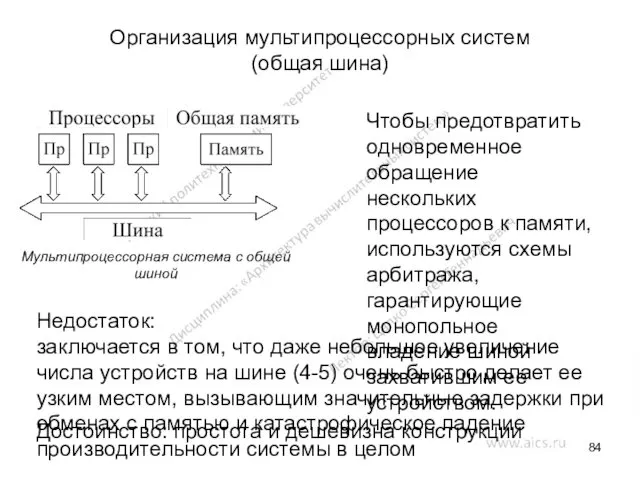
Организация мультипроцессорных систем
(общая шина)
Мультипроцессорная система с общей шиной
Чтобы предотвратить одновременное
Организация мультипроцессорных систем
(общая шина)
Мультипроцессорная система с общей шиной
Чтобы предотвратить одновременное
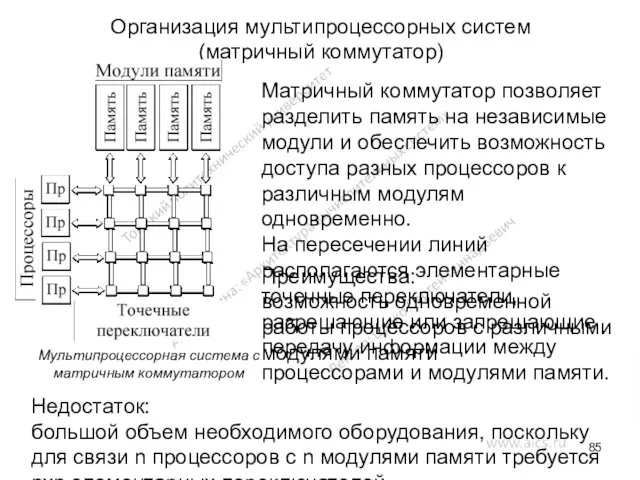
Организация мультипроцессорных систем
(матричный коммутатор)
Матричный коммутатор позволяет разделить память на независимые модули
Организация мультипроцессорных систем
(матричный коммутатор)
Матричный коммутатор позволяет разделить память на независимые модули
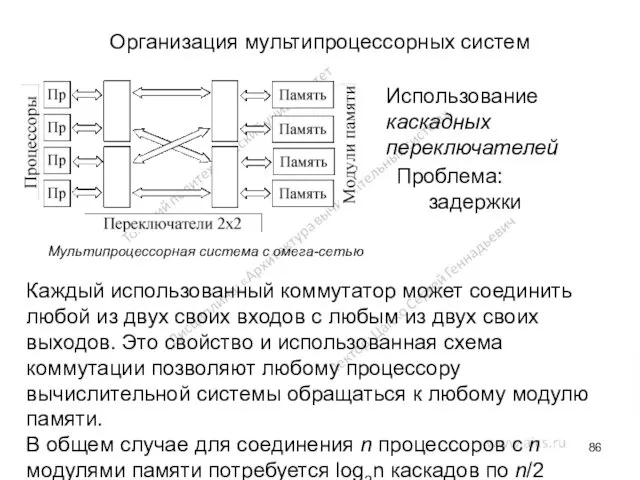
Организация мультипроцессорных систем
Мультипроцессорная система с омега-сетью
Использование каскадных переключателей
Каждый использованный коммутатор
Организация мультипроцессорных систем
Мультипроцессорная система с омега-сетью
Использование каскадных переключателей
Каждый использованный коммутатор
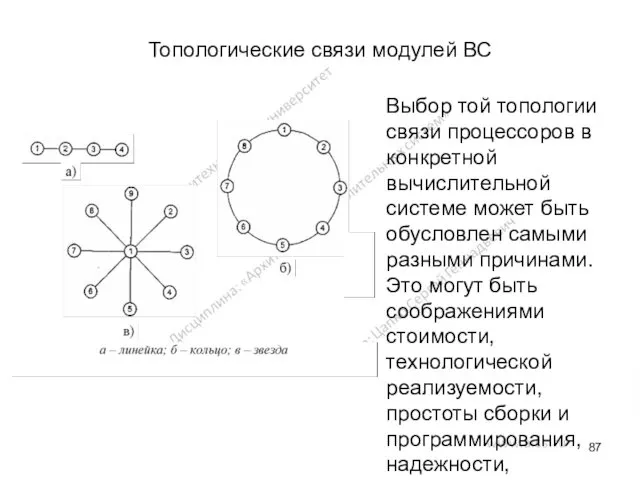
Топологические связи модулей ВС
Выбор той топологии связи процессоров в конкретной
Топологические связи модулей ВС
Выбор той топологии связи процессоров в конкретной
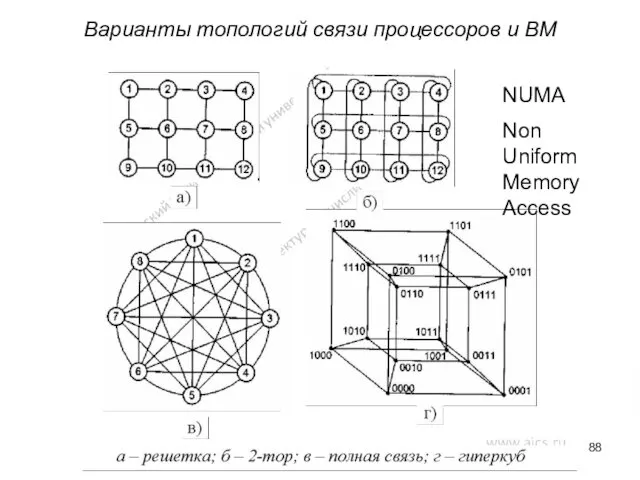
Варианты топологий связи процессоров и ВМ
NUMA
Non Uniform Memory Access
Варианты топологий связи процессоров и ВМ
NUMA
Non Uniform Memory Access
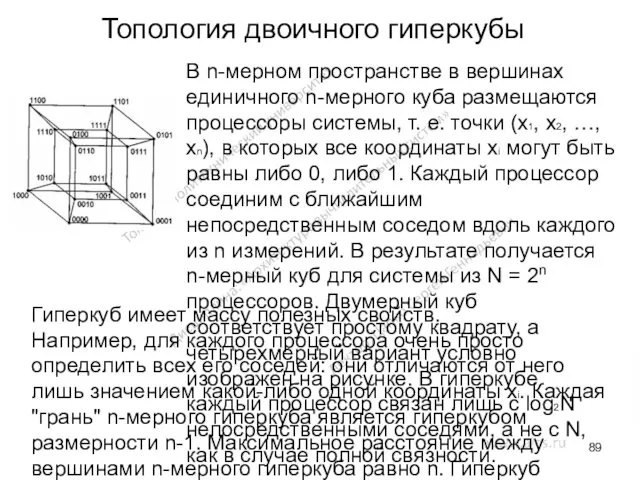
Топология двоичного гиперкубы
В n-мерном пространстве в вершинах единичного n-мерного куба размещаются
Топология двоичного гиперкубы
В n-мерном пространстве в вершинах единичного n-мерного куба размещаются

Достоинства и недостатки компьютеров с общей и распределенной памятью
Для компьютеров с
Достоинства и недостатки компьютеров с общей и распределенной памятью
Для компьютеров с

Данный компьютер состоит из набора кластеров, соединенных друг с другом через
Данный компьютер состоит из набора кластеров, соединенных друг с другом через
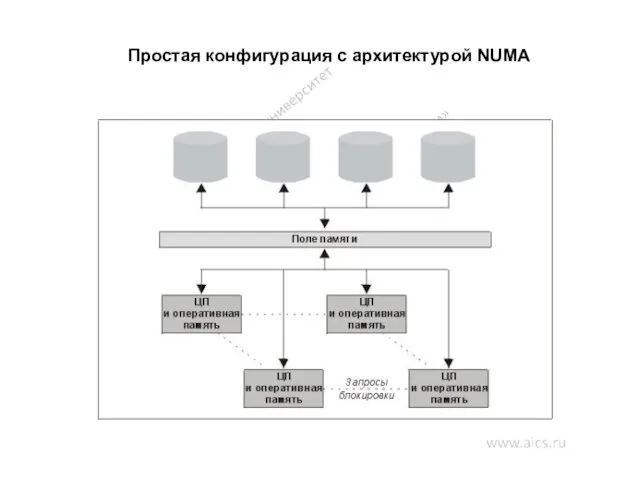
Простая конфигурация с архитектурой NUMA

NUMA - архитектура
NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной
NUMA - архитектура
NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной

Проблема неоднородности доступа
Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями),
Проблема неоднородности доступа
Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями),

Языки параллельного программирования
Специальные комментарии:
внедрение дополнительных директив для компилятора, использование данных директив
Языки параллельного программирования
Специальные комментарии:
внедрение дополнительных директив для компилятора, использование данных директив

Языки параллельного программирования
Использование библиотек и интерфейсов, поддерживающих взаимодействие параллельных процессов:
подготовка программного
Языки параллельного программирования
Использование библиотек и интерфейсов, поддерживающих взаимодействие параллельных процессов:
подготовка программного

Примеры языков программирования и надстроек
OpenMP
High Performance Fortran (HPF)
Occam, Sisal, Норма
Linda, Massage
Примеры языков программирования и надстроек
OpenMP
High Performance Fortran (HPF)
Occam, Sisal, Норма
Linda, Massage

Массивно-параллельная архитектура
Массивно-параллельная архитектура (англ. MPP, Massive Parallel Processing) — класс
Массивно-параллельная архитектура
Массивно-параллельная архитектура (англ. MPP, Massive Parallel Processing) — класс

Основные классы современных параллельных компьютеров Массивно-параллельные системы (MPP)
Архитектура
Система состоит из однородных
Основные классы современных параллельных компьютеров Массивно-параллельные системы (MPP)
Архитектура
Система состоит из однородных

Симметричное мультипроцессирование
SMP часто применяется в науке, промышленности, бизнесе, где программное
Симметричное мультипроцессирование
SMP часто применяется в науке, промышленности, бизнесе, где программное
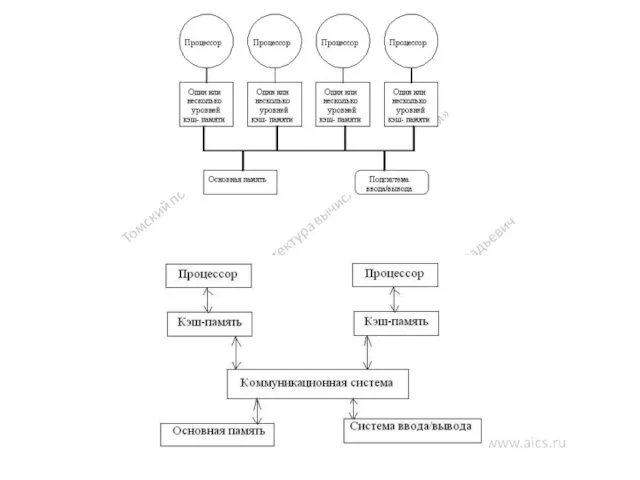

Архитектура
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно
Архитектура
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно

Основные классы современных параллельных компьютеров Системы с неоднородным доступом к памяти
Основные классы современных параллельных компьютеров Системы с неоднородным доступом к памяти

Основные классы современных параллельных компьютеров Параллельные векторные системы (PVP)
Архитектура
Основным признаком PVP-систем
Основные классы современных параллельных компьютеров Параллельные векторные системы (PVP)
Архитектура
Основным признаком PVP-систем

Основные классы современных параллельных компьютеров Кластерные системы
Архитектура
Набор рабочих станций (или
Основные классы современных параллельных компьютеров Кластерные системы
Архитектура
Набор рабочих станций (или

Ссылки на литературу
Анализ мультипроцессорных систем с иерархической памятью
http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm
Языки параллельной обработки
http://ibd.tsi.lv/cgi/sart2.pl?T1=ZAG
Архитектура
Ссылки на литературу
Анализ мультипроцессорных систем с иерархической памятью
http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm
Языки параллельной обработки
http://ibd.tsi.lv/cgi/sart2.pl?T1=ZAG
Архитектура

Матричные вычислительные системы
Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные
Матричные вычислительные системы
Матричные ВС обладают более широкими архитектурными возможностями, чем конвейерные
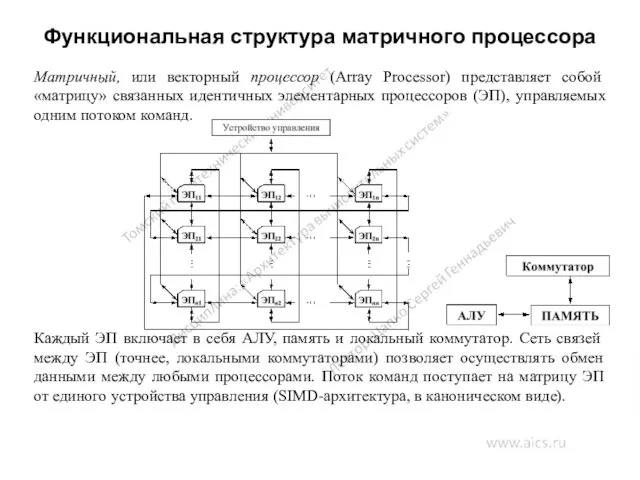
Функциональная структура матричного процессора
Матричный, или векторный процессор (Array Processor) представляет собой
Функциональная структура матричного процессора
Матричный, или векторный процессор (Array Processor) представляет собой

Функциональная структура матричного процессора
При решении сложных задач фактически один и тот
Функциональная структура матричного процессора
При решении сложных задач фактически один и тот

Первый матричный компьютер
Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular
Первый матричный компьютер
Первая матричная ВС SOLOMON (Simultaneous Operation Linked Ordinal MOdular

Вычислительная система ILLIAC IV
Матричная ВС ILLIAC IV создана Иллинойским университетом
Вычислительная система ILLIAC IV
Матричная ВС ILLIAC IV создана Иллинойским университетом

Функциональная структура системы ILLIAC IV
Матричная ВС ILLIAC IV (рис. 5.2)
Функциональная структура системы ILLIAC IV
Матричная ВС ILLIAC IV (рис. 5.2)

Функциональная структура системы ILLIAC IV
Квадрант — матричный процессор, включавший в себя
Функциональная структура системы ILLIAC IV
Квадрант — матричный процессор, включавший в себя

Формат представления данных системы ILLIAC IV
В системе ILLIAC IV использовалось слово
Формат представления данных системы ILLIAC IV
В системе ILLIAC IV использовалось слово
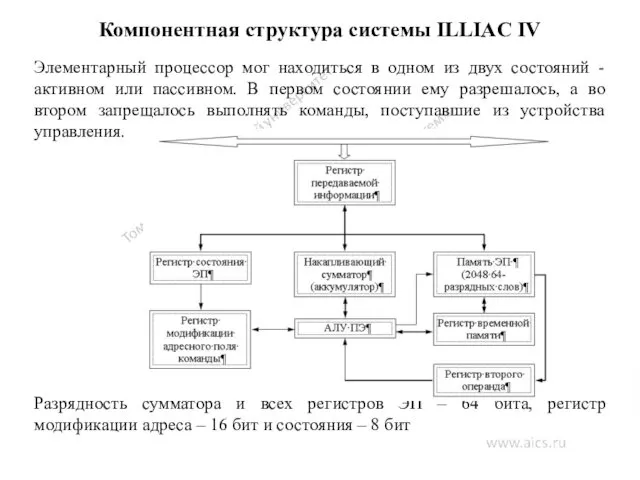
Компонентная структура системы ILLIAC IV
Элементарный процессор мог находиться в одном из
Компонентная структура системы ILLIAC IV
Элементарный процессор мог находиться в одном из

Аппаратный состав системы ILLIAC IV
Подсистема ввода-вывода состояла из устройства управления, буферного
Аппаратный состав системы ILLIAC IV
Подсистема ввода-вывода состояла из устройства управления, буферного

Программное обеспечение системы ILLIAC IV
Цель разработки ILLIAC IV — создание мощной
Программное обеспечение системы ILLIAC IV
Цель разработки ILLIAC IV — создание мощной

Программное обеспечение системы ILLIAC IV
Программы В 6700, написанной, как правило, на
Программное обеспечение системы ILLIAC IV
Программы В 6700, написанной, как правило, на

Средства программирования системы ILLIAC IV
Распределение двумерной памяти. Была разрешена адресация отдельных
Средства программирования системы ILLIAC IV
Распределение двумерной памяти. Была разрешена адресация отдельных

Языки высокого уровня системы ILLIAC IV
Tranquil подобен языку ALGOL и полностью
Языки высокого уровня системы ILLIAC IV
Tranquil подобен языку ALGOL и полностью

Применение системы ILLIAC IV
Практически установлено, что ILLIAC IV была эффективна при
Применение системы ILLIAC IV
Практически установлено, что ILLIAC IV была эффективна при

Классификация вычислительных систем
Классификация Флинна
Классификация Хокни
Классификация Фенга
Классификация Дункана
Классификация
Классификация вычислительных систем
Классификация Флинна
Классификация Хокни
Классификация Фенга
Классификация Дункана
Классификация
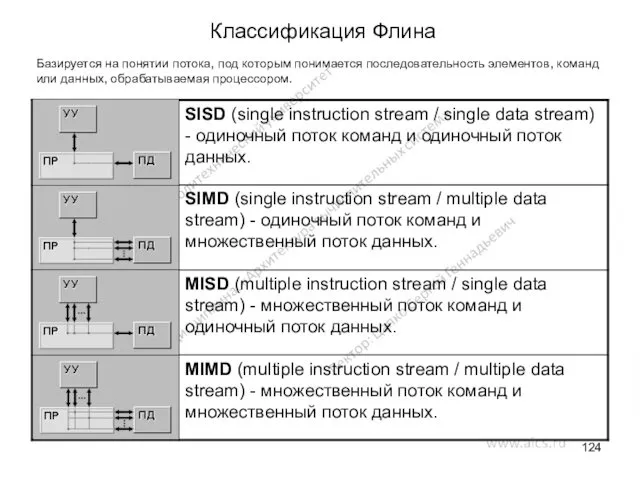
Классификация Флина
Базируется на понятии потока, под которым понимается последовательность элементов, команд
Классификация Флина
Базируется на понятии потока, под которым понимается последовательность элементов, команд
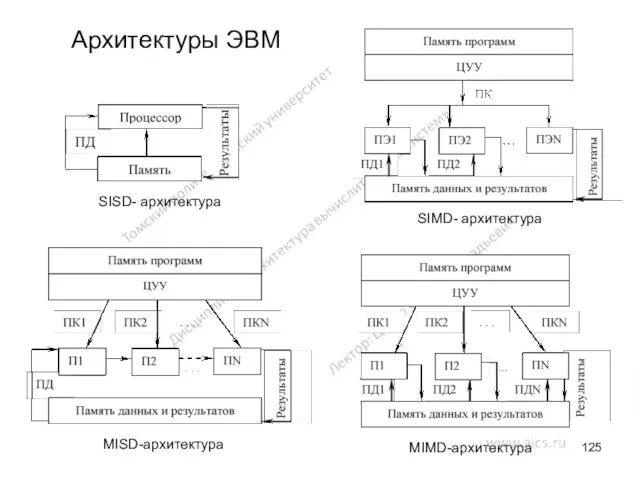
Архитектуры ЭВМ
MIMD-архитектура
MISD-архитектура
SIMD- архитектура
SISD- архитектура
Архитектуры ЭВМ
MIMD-архитектура
MISD-архитектура
SIMD- архитектура
SISD- архитектура

Недостатки классификации Флина
Некоторые архитектуры четко не вписываются в данную классификацию
Чрезмерная заполненность
Недостатки классификации Флина
Некоторые архитектуры четко не вписываются в данную классификацию
Чрезмерная заполненность

Классификация Хокни
Основная идея классификации состоит в следующем.
Множественный поток команд может быть
Классификация Хокни
Основная идея классификации состоит в следующем.
Множественный поток команд может быть
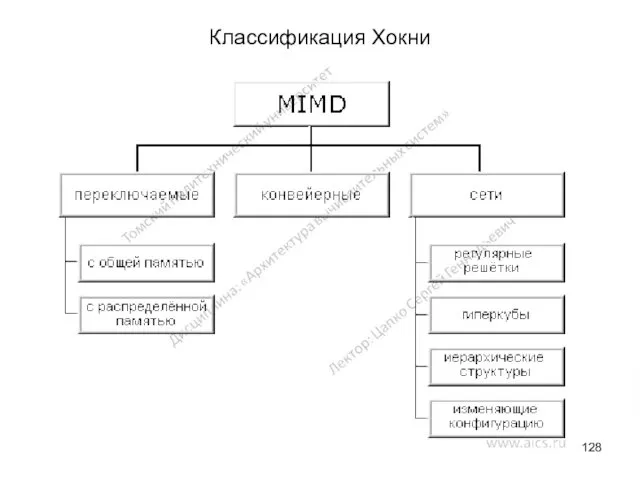
Классификация Хокни
Классификация Хокни

Примеры классификации Флина
SISD – PDP-11, VAX 11/780, CDC 6600 и CDC
Примеры классификации Флина
SISD – PDP-11, VAX 11/780, CDC 6600 и CDC

Классификация Фенга
Идея классификации вычислительных систем на основе двух простых характеристик. Первая
Классификация Фенга
Идея классификации вычислительных систем на основе двух простых характеристик. Первая
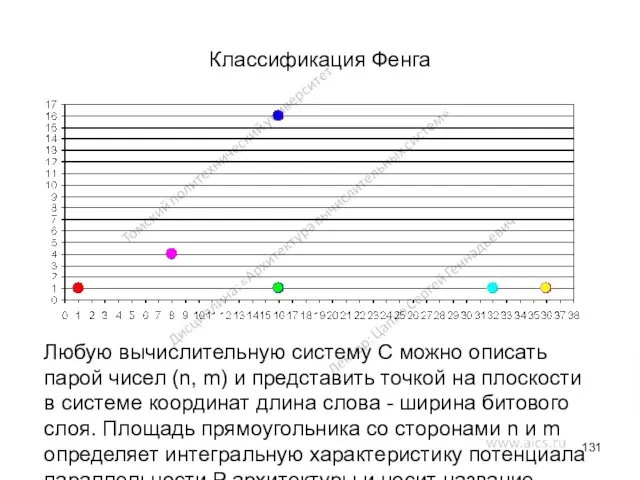
Классификация Фенга
Любую вычислительную систему C можно описать парой чисел (n, m)
Классификация Фенга
Любую вычислительную систему C можно описать парой чисел (n, m)

Примеры классификации Фенга
Разрядно-последовательные пословно-последовательные (n=m=1):
MINIMA с естественным описанием (1,1)
Разрядно-параллельные пословно-последовательные
Примеры классификации Фенга
Разрядно-последовательные пословно-последовательные (n=m=1):
MINIMA с естественным описанием (1,1)
Разрядно-параллельные пословно-последовательные

Недостаток
не делает никакого различия между процессорными матрицами, векторно-конвейерными и многопроцессорными системами;
отсутствует
Недостаток
не делает никакого различия между процессорными матрицами, векторно-конвейерными и многопроцессорными системами;
отсутствует

Классификация Дункана
Дункан определил набор требований для создания своей классификации.
Из классификации должны
Классификация Дункана
Дункан определил набор требований для создания своей классификации.
Из классификации должны
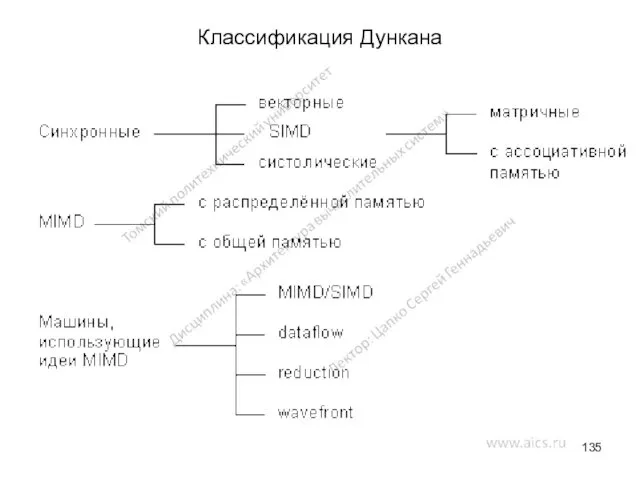
Классификация Дункана
Классификация Дункана

Основные архитектуры, представленные на рисунке рисунка
Систолические архитектуры представляют собой множество процессоров,
Основные архитектуры, представленные на рисунке рисунка
Систолические архитектуры представляют собой множество процессоров,

Классификация Хендлера
Предложенная классификация базируется на различии между тремя уровнями обработки данных
Классификация Хендлера
Предложенная классификация базируется на различии между тремя уровнями обработки данных
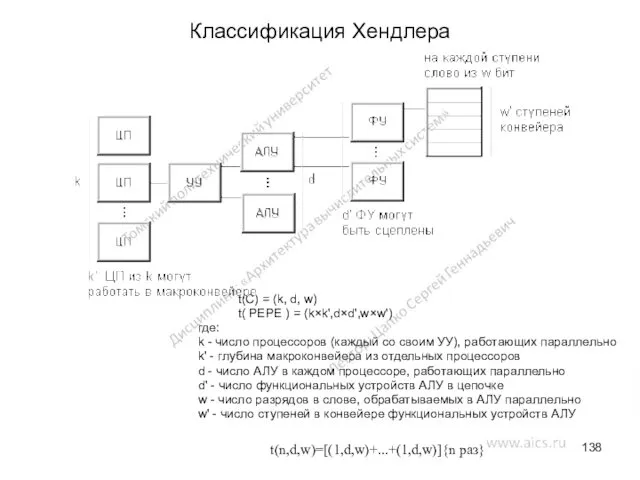
Классификация Хендлера
t(C) = (k, d, w)
t( PEPE ) = (k×k',d×d',w×w')
Классификация Хендлера
t(C) = (k, d, w)
t( PEPE ) = (k×k',d×d',w×w')

Дополнения к классификации Хендлера
Хендлер предлагает использовать три операции:
Первая операция (×) отражает
Дополнения к классификации Хендлера
Хендлер предлагает использовать три операции:
Первая операция (×) отражает

Примеры классификации Хендлера
t( MINIMA ) = (1,1,1);
t( IBM 701 ) =
Примеры классификации Хендлера
t( MINIMA ) = (1,1,1); t( IBM 701 ) =

Классификация Шнайдера
Основная идея заключается в выделении этапов выборки и непосредственно исполнения
Классификация Шнайдера
Основная идея заключается в выделении этапов выборки и непосредственно исполнения

Классификация Шнайдера
Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая
Классификация Шнайдера
Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая

Классификация Шнайдера (кратко)
Поток ссылок:
S = { (a1 < t1 > )
Классификация Шнайдера (кратко)
Поток ссылок:
S = { (a1 < t1 > )

Классы компьютеров в соответствии с классификацией Шнайдера
IssDss - фон-неймановские машины;
Классы компьютеров в соответствии с классификацией Шнайдера
IssDss - фон-неймановские машины;

Классификация Скилликорна
Архитектура любого компьютера состоит из:
процессора команд (IP –Instruction Processor);
процессора
Классификация Скилликорна
Архитектура любого компьютера состоит из:
процессора команд (IP –Instruction Processor);
процессора
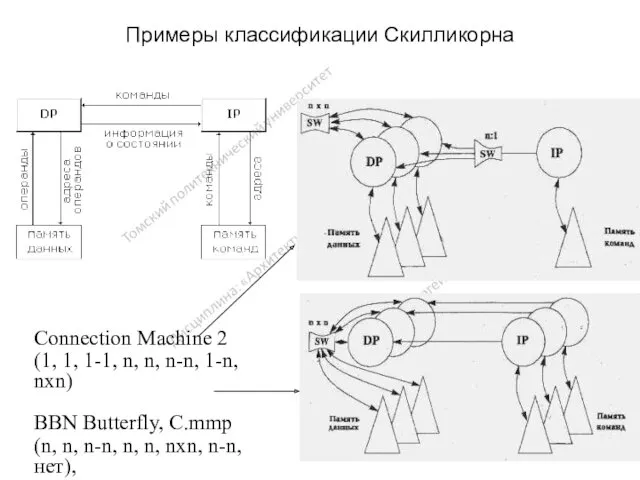
Примеры классификации Скилликорна
Connection Machine 2
(1, 1, 1-1, n, n, n-n, 1-n,
Примеры классификации Скилликорна
Connection Machine 2
(1, 1, 1-1, n, n, n-n, 1-n,

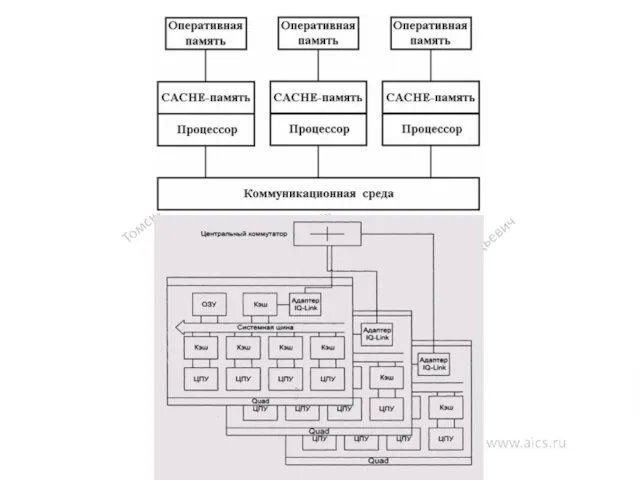
Когерентность памяти. Коммутаторы ВС.
Организация когерентности многоуровневой иерархической памяти
классифицировать по способу размещения
Когерентность памяти. Коммутаторы ВС.
Организация когерентности многоуровневой иерархической памяти
классифицировать по способу размещения

Многопроцессорную ВС можно рассматривать как совокупность процессоров, подсоединенных к многоуровневой иерархической
Многопроцессорную ВС можно рассматривать как совокупность процессоров, подсоединенных к многоуровневой иерархической

Классифицировать по способу размещения данных в иерархической памяти и способу доступа
Классифицировать по способу размещения данных в иерархической памяти и способу доступа

Классифицировать по способу размещения данных в иерархической памяти и способу доступа
Классифицировать по способу размещения данных в иерархической памяти и способу доступа

Кластерные системы
LAN – Local Area Network, локальная сеть
SAN – Storage
Кластерные системы
LAN – Local Area Network, локальная сеть
SAN – Storage

Кластерные системы
Сообщение, доставленное в компьютер-адресат, воспринимается через входной линк адаптером этого
Кластерные системы
Сообщение, доставленное в компьютер-адресат, воспринимается через входной линк адаптером этого

Blue Gene/L
Расположение:
Ливерморская национальная лаборатория имени Лоуренса
Общее число процессоров 65536 штук
Состоит из
Blue Gene/L
Расположение:
Ливерморская национальная лаборатория имени Лоуренса
Общее число процессоров 65536 штук
Состоит из
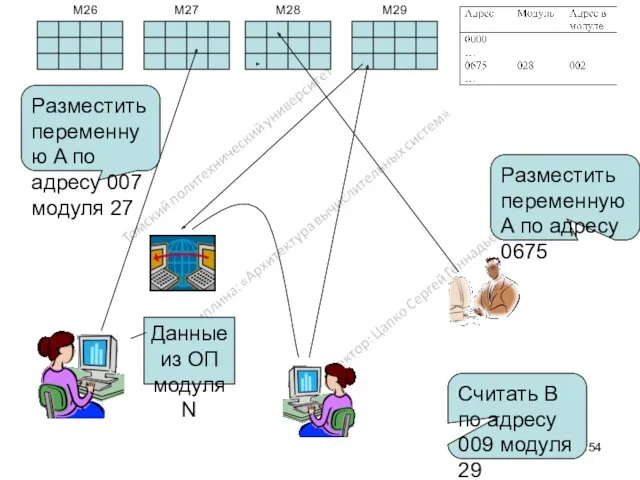
Разместить переменную A по адресу 007 модуля 27
Разместить переменную A по
Разместить переменную A по адресу 007 модуля 27
Разместить переменную A по

Механизм неявной реализации когерентности
Реализация механизма когерентности в ВС с разделяемой памятью
Механизм неявной реализации когерентности
Реализация механизма когерентности в ВС с разделяемой памятью
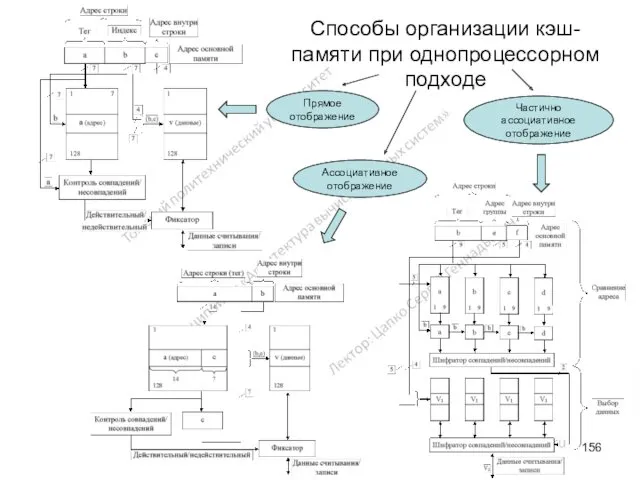
Способы организации кэш-памяти при однопроцессорном подходе
Прямое отображение
Ассоциативное отображение
Частично ассоциативное отображение
Способы организации кэш-памяти при однопроцессорном подходе
Прямое отображение
Ассоциативное отображение
Частично ассоциативное отображение

Методы обновления ОП при однопроцессорном подходе к организация механизма неявной реализации
Методы обновления ОП при однопроцессорном подходе к организация механизма неявной реализации

Сосредоточенная память
Каждый ВМ имеет собственную локальную кэш-память, имеется общая разделяемая основная
Сосредоточенная память
Каждый ВМ имеет собственную локальную кэш-память, имеется общая разделяемая основная

Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с
Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с

Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с
Многопроцессорный подход к организация механизма неявной реализации когерентности в системах с
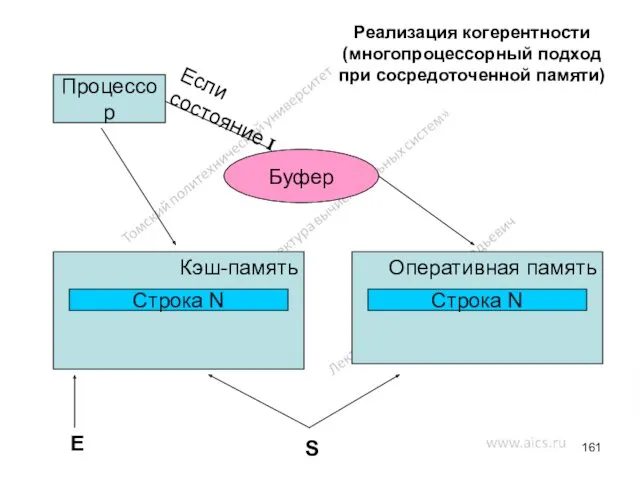
Реализация когерентности (многопроцессорный подход при сосредоточенной памяти)
Процессор
Кэш-память
Оперативная память
Строка N
Строка N
E
S
Буфер
Если состояние
Реализация когерентности (многопроцессорный подход при сосредоточенной памяти)
Процессор
Кэш-память
Оперативная память
Строка N
Строка N
E
S
Буфер
Если состояние

Прямолинейный подход к поддержанию когерентности кэшей в мультипроцессорной системе, основная память
Прямолинейный подход к поддержанию когерентности кэшей в мультипроцессорной системе, основная память

Многопроцессорный подход к организация механизма неявной реализации когерентности в системах физически
Многопроцессорный подход к организация механизма неявной реализации когерентности в системах физически

Алгоритм DASH
Каждый модуль памяти имеет для каждой строки, резидентной в модуле,
Алгоритм DASH
Каждый модуль памяти имеет для каждой строки, резидентной в модуле,

Каждый процессор может читать из своего кэша, если состояние читаемой строки
Каждый процессор может читать из своего кэша, если состояние читаемой строки

Если процессор выполняет операцию записи и состояние строки, в которую производится
Если процессор выполняет операцию записи и состояние строки, в которую производится
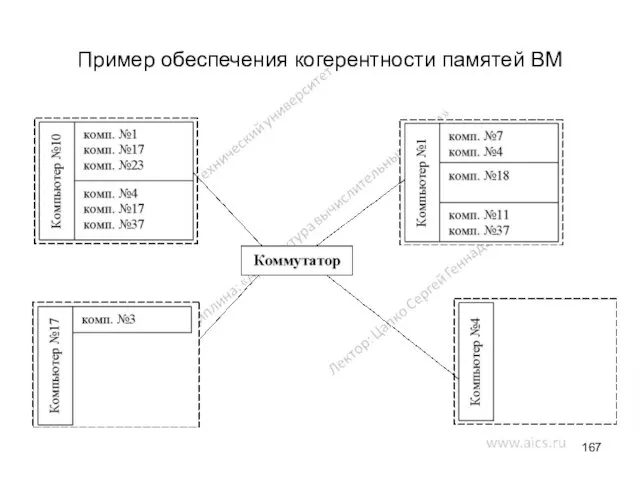
Пример обеспечения когерентности памятей ВМ
Пример обеспечения когерентности памятей ВМ

Механизм явной реализации когерентности
При явной реализации когерентности используются отдельные наборы команд
Механизм явной реализации когерентности
При явной реализации когерентности используются отдельные наборы команд

Реализация коммутационной среды
Процесс реализации коммутационной среды можно разделить на три этапа.
На
Реализация коммутационной среды
Процесс реализации коммутационной среды можно разделить на три этапа.
На
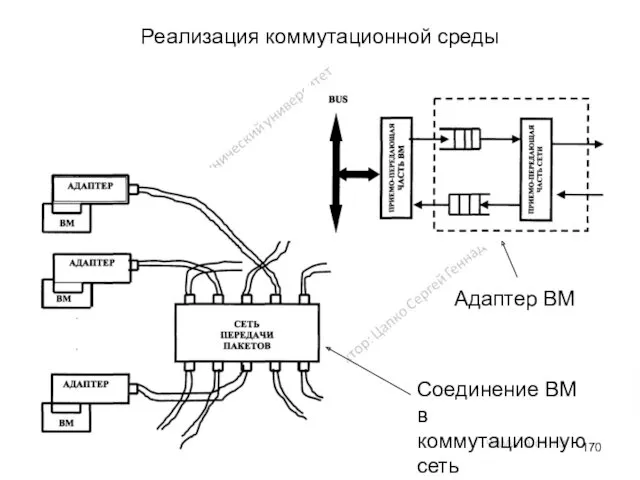
Реализация коммутационной среды
Адаптер ВМ
Соединение ВМ в коммутационную сеть
Реализация коммутационной среды
Адаптер ВМ
Соединение ВМ в коммутационную сеть
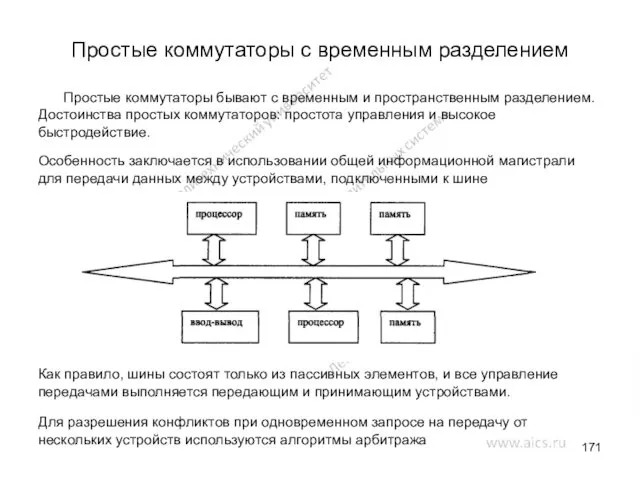
Простые коммутаторы с временным разделением
Простые коммутаторы бывают с временным и пространственным
Простые коммутаторы с временным разделением
Простые коммутаторы бывают с временным и пространственным
Алгоритмы арбитража. Статические приоритеты
Каждому устройству приписывается уникальный приоритет. Когда несколько устройств
Алгоритмы арбитража. Статические приоритеты
Каждому устройству приписывается уникальный приоритет. Когда несколько устройств

Алгоритмы арбитража.
Фиксированные временные интервалы
Алгоритм предоставляет каждому устройству одинаковый временной интервал по
Алгоритмы арбитража.
Фиксированные временные интервалы
Алгоритм предоставляет каждому устройству одинаковый временной интервал по
Алгоритмы арбитража. Динамические приоритеты
Устройствам приписываются уникальные приоритеты, но приоритеты динамически изменяются,
Алгоритмы арбитража. Динамические приоритеты
Устройствам приписываются уникальные приоритеты, но приоритеты динамически изменяются,
Алгоритмы арбитража. Голосование
При этом механизме линия BGT предоставления шины представляется совокупностью
Алгоритмы арбитража. Голосование
При этом механизме линия BGT предоставления шины представляется совокупностью
Алгоритмы арбитража. Независимые запросы
Каждое устройство имеет индивидуальные линии запроса и предоставления
Алгоритмы арбитража. Независимые запросы
Каждое устройство имеет индивидуальные линии запроса и предоставления
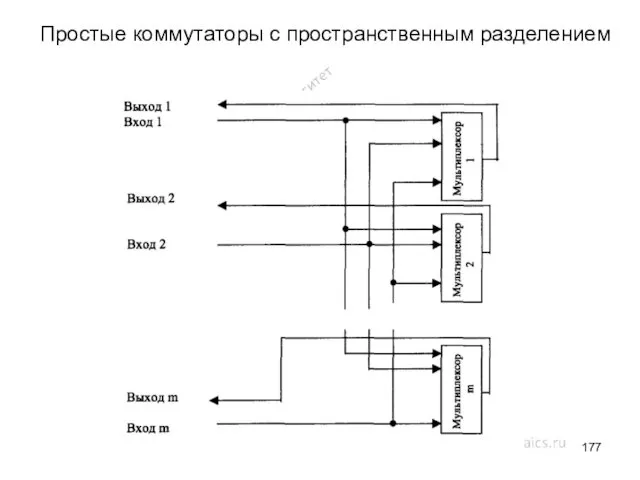
Простые коммутаторы с пространственным разделением
Простые коммутаторы с пространственным разделением
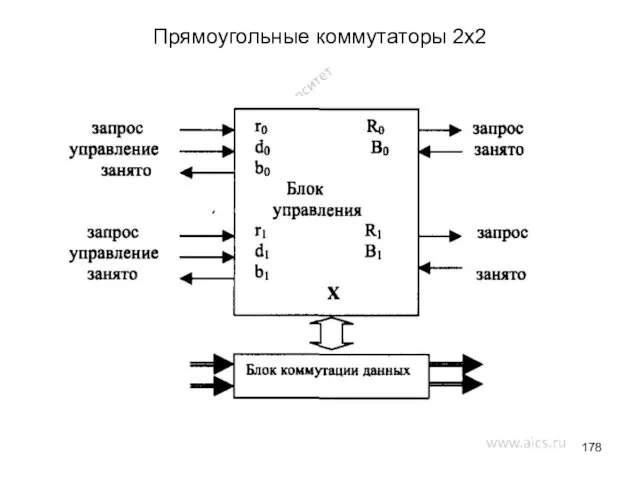
Прямоугольные коммутаторы 2х2
Прямоугольные коммутаторы 2х2
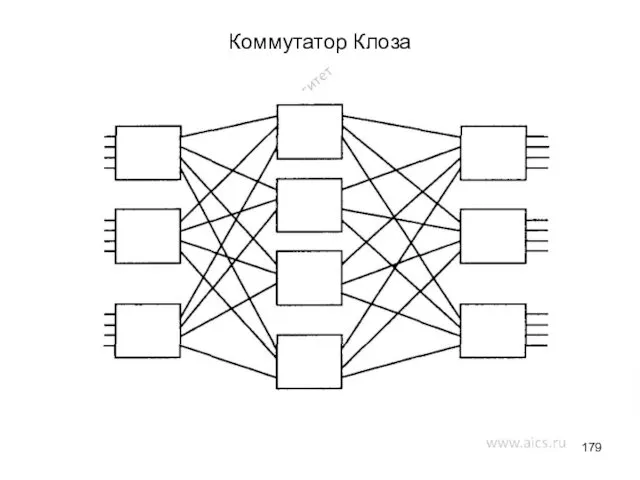
Коммутатор Клоза
Коммутатор Клоза
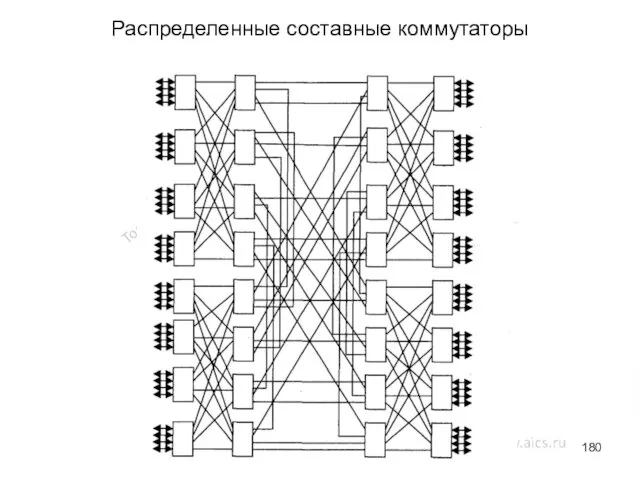
Распределенные составные коммутаторы
Распределенные составные коммутаторы

Список литературы
Иерархическая память многопроцессорных ВС
http://www.uran.donetsk.ua/~masters/2001/fvti/prokopenko/diss/ch03.htm
Анализ мультипроцессорных систем с иерархической памятью
http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm
Многопроцессорные
Список литературы
Иерархическая память многопроцессорных ВС
http://www.uran.donetsk.ua/~masters/2001/fvti/prokopenko/diss/ch03.htm
Анализ мультипроцессорных систем с иерархической памятью
http://masters.donntu.edu.ua/2001/fvti/prokopenko/diss/index.htm
Многопроцессорные


 Портландцемент. Химический состав
Портландцемент. Химический состав Завершение объединения русских земель
Завершение объединения русских земель Презентация по кулинарии 11класс.
Презентация по кулинарии 11класс. Свойства и применение нанокомпозитов
Свойства и применение нанокомпозитов Мой светлый город Волжский
Мой светлый город Волжский Проектирование разработки сеноманских отложений на Заполярном месторождении
Проектирование разработки сеноманских отложений на Заполярном месторождении Смута в российском государстве
Смута в российском государстве Цветовое решение подземного прехода
Цветовое решение подземного прехода Мама – первое слово, главное слово в нашей судьбе
Мама – первое слово, главное слово в нашей судьбе Запуск мобильного оператора Теле2 в Саранске
Запуск мобильного оператора Теле2 в Саранске Урок - экспедиция По морям по волнам
Урок - экспедиция По морям по волнам Силы в природе
Силы в природе День автомобилиста
День автомобилиста Заседание профбюро. Культурно-массовая и просветительская деятельность
Заседание профбюро. Культурно-массовая и просветительская деятельность Обновления в CSS3
Обновления в CSS3 Экономические задачи повышенного уровня сложности в ЕГЭ
Экономические задачи повышенного уровня сложности в ЕГЭ CASE-технологии
CASE-технологии Карл Павлович Брюллов (1799-1852). Итальянская тематика
Карл Павлович Брюллов (1799-1852). Итальянская тематика Система мотивации персонала в аптеках и аптечных сетях
Система мотивации персонала в аптеках и аптечных сетях Технологический процесс изготовления оснастки для сборки фильтрующих элементов наномембранных фильтров
Технологический процесс изготовления оснастки для сборки фильтрующих элементов наномембранных фильтров Котел Buderus Logamax plus GB172i
Котел Buderus Logamax plus GB172i Животные моей местности
Животные моей местности IntegreX - станок для лазерной резки
IntegreX - станок для лазерной резки 20231213_gzhel
20231213_gzhel Графикалық режим
Графикалық режим Типологический портрет политического обозревателя на примере Александра Хроленко
Типологический портрет политического обозревателя на примере Александра Хроленко Газобалонное оборудование второго поколения на СНГ и СПГ
Газобалонное оборудование второго поколения на СНГ и СПГ Текст Скворечник. Коррекционное образовательное учреждение
Текст Скворечник. Коррекционное образовательное учреждение