- Blackfin ADSP-21535 Versus Sharc ADSP-21061

Содержание
- 2. To be covered today: Quick overview of the architectures of the both the Blackfin and Sharc
- 3. Sharc ADSP-21061[1]
- 4. Sharc’s Main Features[2]: 32/40-bit IEEE floating-point math 32-bit fixed-point MACs with 64-bit product and 80-bit accumulation
- 5. Sharc’s Main Features Cont.: Six nested levels of zero-overhead looping in hardware Four busses to memory
- 6. Blackfin ADSP-21535[3]
- 7. Blackfin’s Main Features[4]: Two 16-bit MACs, two 40-bit ALUs, and four 8-bit Video ALUs Support for
- 8. Blackfin’s Main Features Cont.: Possibility of the following parallel operations processed in one clock cycle Execution
- 9. Main Differences: The Blackfin is only a 16-bit integer processor, however can operate on 32-bit data
- 10. Main Differences Cont.: The Blackfin has 4 address registers (with corresponding base, length, and modify) to
- 11. Blackfin FIR Code Sample[5]: LSETUP(E_FIR_START,E_FIR_END) LC0=P1>>1; //Loop 1 to Ni/2 E_FIR_START: R1=PACK(R1.H,R0.H) || [I0++]=R0 || R2.L=W[I2++];
- 12. Benchmarks: For the Sharc[6] For the Blackfin[7]
- 13. Analysis: Blackfin is faster for the three algorithms Unsure of exact performance gain on the FFT
- 14. References ENCM515 Lecture Slides for January 11, 2002, [http://www.enel.ucalgary.ca/People/Smith/2002webs/encm515_02/02presentations/02january/02overviewSHARCarchitecture.ppt], Dr. Mike Smith Sharc Architecture Overview, [http://www.analog.com/technology/dsp/Sharc/architecture.html],
- 16. Скачать презентацию

To be covered today:
Quick overview of the architectures of the both
To be covered today:
Quick overview of the architectures of the both
![Sharc ADSP-21061[1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-2.jpg)
Sharc ADSP-21061[1]
Sharc ADSP-21061[1]
![Sharc’s Main Features[2]: 32/40-bit IEEE floating-point math 32-bit fixed-point MACs](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-3.jpg)
Sharc’s Main Features[2]:
32/40-bit IEEE floating-point math
32-bit fixed-point MACs with 64-bit
Sharc’s Main Features[2]:
32/40-bit IEEE floating-point math
32-bit fixed-point MACs with 64-bit

Sharc’s Main Features Cont.:
Six nested levels of zero-overhead looping in hardware
Sharc’s Main Features Cont.:
Six nested levels of zero-overhead looping in hardware
![Blackfin ADSP-21535[3]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-5.jpg)
Blackfin ADSP-21535[3]
Blackfin ADSP-21535[3]
![Blackfin’s Main Features[4]: Two 16-bit MACs, two 40-bit ALUs, and](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-6.jpg)
Blackfin’s Main Features[4]:
Two 16-bit MACs, two 40-bit ALUs, and four 8-bit
Blackfin’s Main Features[4]:
Two 16-bit MACs, two 40-bit ALUs, and four 8-bit

Blackfin’s Main Features Cont.:
Possibility of the following parallel operations processed in
Blackfin’s Main Features Cont.:
Possibility of the following parallel operations processed in

Main Differences:
The Blackfin is only a 16-bit integer processor, however can
Main Differences:
The Blackfin is only a 16-bit integer processor, however can

Main Differences Cont.:
The Blackfin has 4 address registers (with corresponding base,
Main Differences Cont.:
The Blackfin has 4 address registers (with corresponding base,
![Blackfin FIR Code Sample[5]: LSETUP(E_FIR_START,E_FIR_END) LC0=P1>>1; //Loop 1 to Ni/2](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-10.jpg)
Blackfin FIR Code Sample[5]:
LSETUP(E_FIR_START,E_FIR_END) LC0=P1>>1; //Loop 1 to Ni/2
E_FIR_START:
R1=PACK(R1.H,R0.H) || [I0++]=R0
Blackfin FIR Code Sample[5]:
LSETUP(E_FIR_START,E_FIR_END) LC0=P1>>1; //Loop 1 to Ni/2
E_FIR_START:
R1=PACK(R1.H,R0.H) || [I0++]=R0
![Benchmarks: For the Sharc[6] For the Blackfin[7]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-11.jpg)
Benchmarks:
For the Sharc[6]
For the Blackfin[7]
Benchmarks:
For the Sharc[6]
For the Blackfin[7]

Analysis:
Blackfin is faster for the three algorithms
Unsure of exact performance gain
Analysis:
Blackfin is faster for the three algorithms
Unsure of exact performance gain
![References ENCM515 Lecture Slides for January 11, 2002, [http://www.enel.ucalgary.ca/People/Smith/2002webs/encm515_02/02presentations/02january/02overviewSHARCarchitecture.ppt], Dr.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/335196/slide-13.jpg)
References
ENCM515 Lecture Slides for January 11, 2002, [http://www.enel.ucalgary.ca/People/Smith/2002webs/encm515_02/02presentations/02january/02overviewSHARCarchitecture.ppt], Dr. Mike Smith
Sharc
References
ENCM515 Lecture Slides for January 11, 2002, [http://www.enel.ucalgary.ca/People/Smith/2002webs/encm515_02/02presentations/02january/02overviewSHARCarchitecture.ppt], Dr. Mike Smith
Sharc
 Орган слуха, равновесия. Тестирование
Орган слуха, равновесия. Тестирование O’zbekistonda neft va gaz sanoatining tarixi, rivojlanish bosqichlar va istiqbollari
O’zbekistonda neft va gaz sanoatining tarixi, rivojlanish bosqichlar va istiqbollari В память о Великой войне и ее героях ст. Крымской
В память о Великой войне и ее героях ст. Крымской Занимательная атмосфера
Занимательная атмосфера Дигибридное скрещивание
Дигибридное скрещивание Методика расследования изнасилований
Методика расследования изнасилований Analisis of the natural moving the population
Analisis of the natural moving the population Устройство сверлильного станка
Устройство сверлильного станка Маркетинговые коммуникации в образовании
Маркетинговые коммуникации в образовании День гимназиста
День гимназиста Сравнение условий строительства автомобильных и железнодорожных магистралей в Финляндии и России
Сравнение условий строительства автомобильных и железнодорожных магистралей в Финляндии и России Организация ремонта колесных пар в локомотивном депо
Организация ремонта колесных пар в локомотивном депо Роль Д.А.Поспелова в отечественной кибернетике и искусственном интеллекте
Роль Д.А.Поспелова в отечественной кибернетике и искусственном интеллекте Гигиена и здоровье
Гигиена и здоровье Презентация Индийский океан
Презентация Индийский океан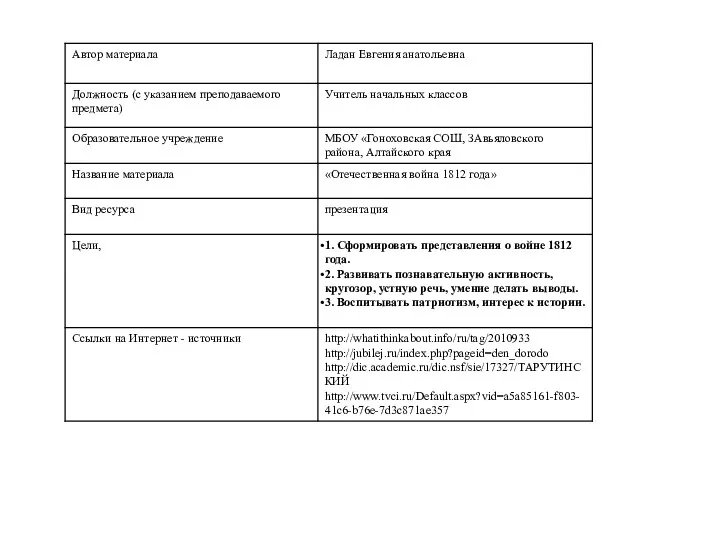 Презентация к классному часу по теме Отечественная война 1812 года
Презентация к классному часу по теме Отечественная война 1812 года Топливная промышленность России
Топливная промышленность России 24 мая – День славянской письменности и культуры
24 мая – День славянской письменности и культуры Религиозная организация христиан веры евангельской (пятидесятников), г. Ярославля
Религиозная организация христиан веры евангельской (пятидесятников), г. Ярославля Сравнение обыкновенных дробей
Сравнение обыкновенных дробей Презентация НОД Путешествие по русским народным сказкам
Презентация НОД Путешествие по русским народным сказкам Рынки. Рынок ценных бумаг. (Урок 11-12)
Рынки. Рынок ценных бумаг. (Урок 11-12) 9 Мая - День Победы (открытки учеников)
9 Мая - День Победы (открытки учеников) Урок внеклассного чтения В свои стихи я вкладываю душу
Урок внеклассного чтения В свои стихи я вкладываю душу Лента Мёбиуса
Лента Мёбиуса Сервисный тренинг EXD06 Экспертный тренинг
Сервисный тренинг EXD06 Экспертный тренинг Презентация сложение целых чисел
Презентация сложение целых чисел Взаимодействие лазерного излучения с веществом: спектроскопия и фазовое управление молекулярными колебаниями. Лекция 4
Взаимодействие лазерного излучения с веществом: спектроскопия и фазовое управление молекулярными колебаниями. Лекция 4