- Принципы построения параллельных вычислительных систем. Лекция 2

Содержание
- 2. История. Конрад Цузе и Z3 на механических реле 1941г.
- 3. История. Первый в США электронный цифровой компьютер Джон Атанасов, Университет штата Айова аспирант Клиффорд Берри Первый
- 4. История. ЭВМ ЭНИАК Джон Мокли 1945 год, ЭВМ ЭНИАК Джон Преспер Экерт, Джон Уильям Мокли 1945г.
- 5. История. Конвейер
- 6. История. Многостадийные конвейеры Анатолий Иванович Китов 1959г.
- 7. История. Конвейер с асинхронным процессором 1961, 1962гг.
- 8. История. Компьютер с независимыми ФУ 1964г. Фирма Control Data Corporation, Сеймур Крэй
- 9. История. Компьютер с векторными операциями 1976г. Компания Cray Recearch Производительность: 160 млн.операций/сек. (160МFlops) 12 ФУ конвейерного
- 10. История. Процессоры с общей памятью 1982г. Память Процессор Процессор
- 11. История. Повышение производительности 1996г.
- 12. История. Самый дорогой компьютер 2002г. 5 тыс.процессоров Назначение: Изучение глобального потепления
- 13. История. Повышение производительности 2002г.
- 14. История. Повышение производительности 2009г.
- 15. ТОП 500 суперкомпьютеров на июнь 2018
- 16. ТОП 500 суперкомпьютеров на июнь 2018
- 17. Суперкомпьютеры Суперкомпьютер – это вычислительная система, обладающая предельными характеристиками по производительности среди имеющихся в каждый конкретный
- 18. Примеры Суперкомпьютер СКИФ МГУ (НИВЦ МГУ) 2008 Общее количество двухпроцессорных узлов 625 (1250 четырехядерных процессоров Intel
- 19. Персональные мини-кластеры T-Edge Mini - см. http://www.t-platforms.ru/ru/temini.php 4 двухпроцессорных узла на базе четырехядерных процессоров Intel Xeon
- 20. Пути достижения параллелизма Пути достижения параллелизма: независимость функционирования отдельных устройств ЭВМ; избыточность элементов вычислительной системы; использование
- 21. Процессы, потоки, нити Процесс (задача) - программа, находящаяся в режиме выполнения. С каждым процессом связывается его
- 22. Процессы, потоки, нити
- 23. Что сработает быстрее? Дано: 1 задача = Подзадача1 + Подзадача2 + Подзадача3 t=t1+t2+t3 1 процессор (1
- 24. Потоки (облегченные процессы) С каждым потоком связывается: Счетчик выполнения команд Регистры для текущих переменных Стек Состояние
- 25. Процессы, потоки, нити Преимущества использования потоков Упрощение программы в некоторых случаях, за счет использования общего адресного
- 26. Синхронность и асинхронность потоков Синхронная программная модель Однопоточность Многопоточность Асинхронная программная модель Однопоточность Многопоточность
- 27. Синхронность и асинхронность потоков
- 28. Объекты синхронизации и проблемы потоков Критическая секция (CriticalSection) Взаимоисключение (мьютекс, mutex - от MUTual EXclusion) Событие
- 29. Последовательная обработка 100 чисел – 500 тактов
- 30. Параллельная обработка 100 чисел – 250 тактов
- 31. Конвейерная обработка Определения. 1) Ступень конвейера. 2) Длина конвейера. Адрес Значение Операция Адрес Ступени конвейера: Значение
- 32. Конвейерная обработка Пусть: n – число операций; l – длина конвейера. Тогда: Время выполнения операций: Т
- 33. Конвейерная обработка Ступени конвейера Получение (Fetch) Раскодирование (Decode) Выполнение (Execute) Запись результата (Write-back) Fetch Decode Execute
- 34. Конвейерная обработка Определение. Эффективность конвейера. где: n – число операций; l – длина конвейера; – погрешность;
- 35. Технико-эксплуатационные характеристики ЭВМ быстродействие; разрядность; формы представления чисел; номенклатура и характеристики запоминающих устройств; номенклатура и характеристики
- 36. Классификации компьютеров принцип действия: (цифровые, аналоговые и гибридные); назначение: (универсальные, проблемно-ориентированные, специализированные); размеры и вычислительная мощность:
- 37. Классификации компьютеров по Флинну SISD (Single Instruction, Single Data) SIMD (Single Instruction, Multiple Data) MISD (Multiple
- 38. ILLIAC IV Начало работ – 1967г. Первый квадрат – 1972г. Наладка системы – 1975г. Эксплуатация –
- 39. MIMD Параллельные компьютеры MIMD С общей памятью С распределенной памятью Пример: Symmetric Multi Processors (SMP); Parallel
- 40. Две основные задачи параллельных вычислений С общей памятью С распределенной памятью Проблемы: Накладные расходы; Сложность параллельных
- 41. Примеры топологий сети передачи данных 7) Тор 8) Полная связь 9) Гиперкуб
- 43. Скачать презентацию

История. Конрад Цузе и Z3 на механических реле
1941г.
История. Конрад Цузе и Z3 на механических реле
1941г.
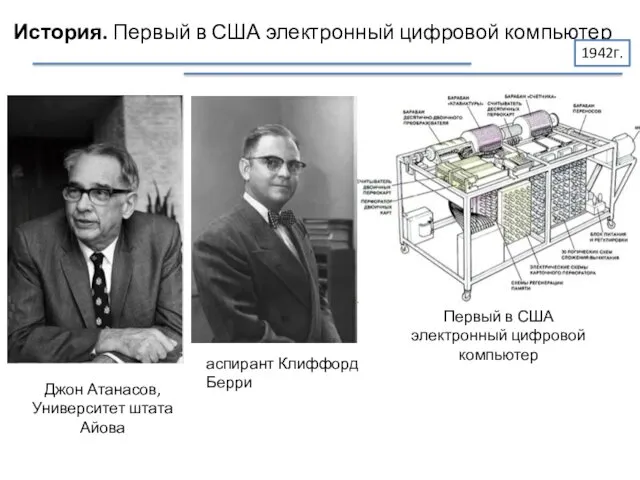
История. Первый в США электронный цифровой компьютер
Джон Атанасов,
Университет штата Айова
аспирант
История. Первый в США электронный цифровой компьютер
Джон Атанасов,
Университет штата Айова
аспирант

История. ЭВМ ЭНИАК
Джон Мокли
1945 год,
ЭВМ ЭНИАК
Джон Преспер Экерт,
Джон Уильям
История. ЭВМ ЭНИАК
Джон Мокли
1945 год,
ЭВМ ЭНИАК
Джон Преспер Экерт,
Джон Уильям
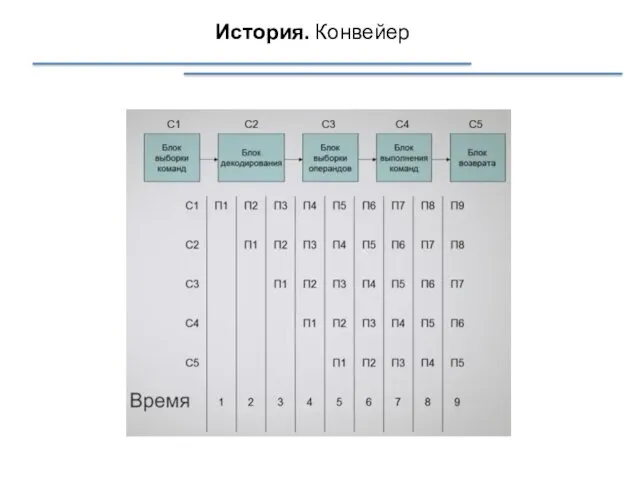
История. Конвейер
История. Конвейер

История. Многостадийные конвейеры
Анатолий Иванович Китов
1959г.
История. Многостадийные конвейеры
Анатолий Иванович Китов
1959г.

История. Конвейер с асинхронным процессором
1961, 1962гг.
История. Конвейер с асинхронным процессором
1961, 1962гг.
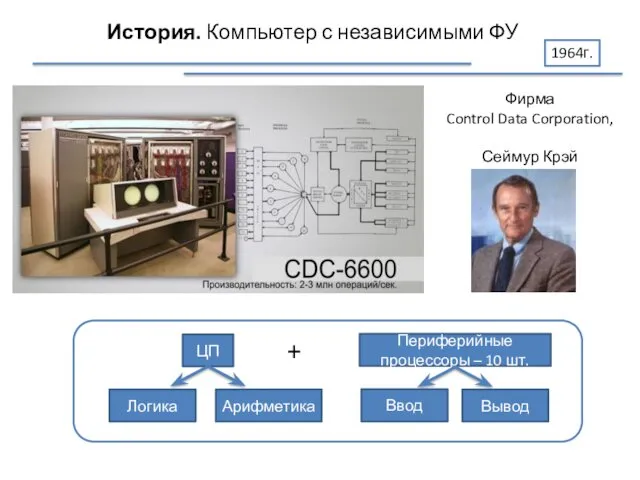
История. Компьютер с независимыми ФУ
1964г.
Фирма
Control Data Corporation,
Сеймур Крэй
История. Компьютер с независимыми ФУ
1964г.
Фирма
Control Data Corporation,
Сеймур Крэй

История. Компьютер с векторными операциями
1976г.
Компания Cray Recearch
Производительность: 160 млн.операций/сек. (160МFlops)
12 ФУ
История. Компьютер с векторными операциями
1976г.
Компания Cray Recearch
Производительность: 160 млн.операций/сек. (160МFlops)
12 ФУ

История. Процессоры с общей памятью
1982г.
Память
Процессор
Процессор
История. Процессоры с общей памятью
1982г.
Память
Процессор
Процессор

История. Повышение производительности
1996г.
История. Повышение производительности
1996г.

История. Самый дорогой компьютер
2002г.
5 тыс.процессоров
Назначение:
Изучение глобального потепления
История. Самый дорогой компьютер
2002г.
5 тыс.процессоров
Назначение:
Изучение глобального потепления
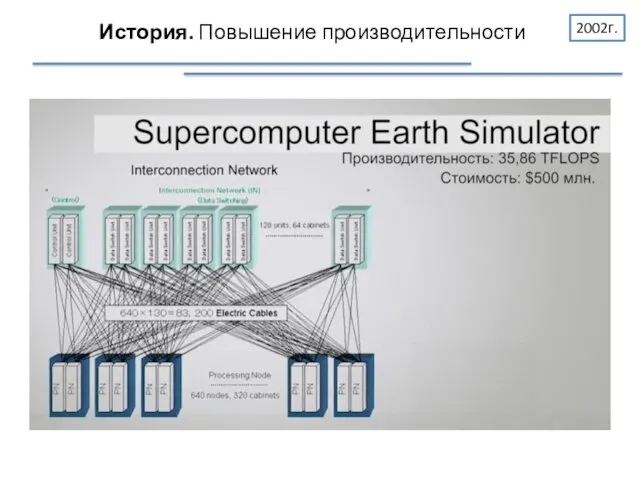
История. Повышение производительности
2002г.
История. Повышение производительности
2002г.

История. Повышение производительности
2009г.
История. Повышение производительности
2009г.
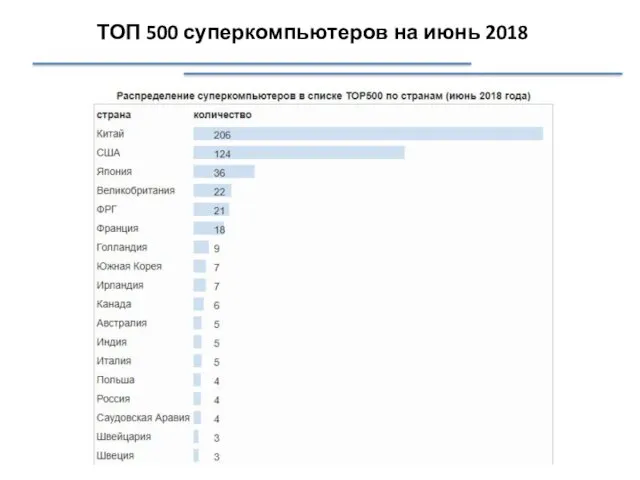
ТОП 500 суперкомпьютеров на июнь 2018
ТОП 500 суперкомпьютеров на июнь 2018
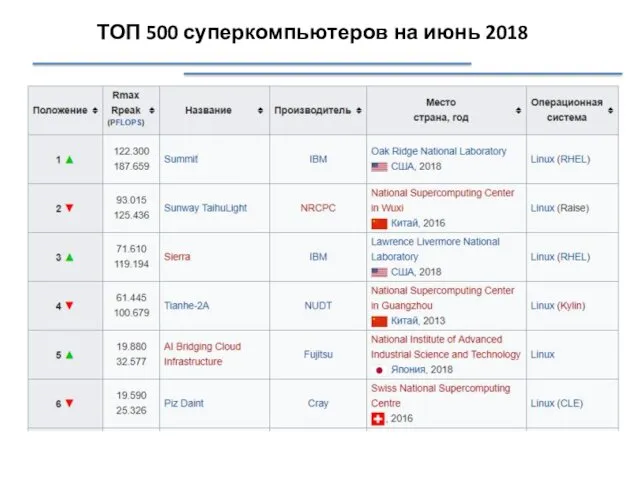
ТОП 500 суперкомпьютеров на июнь 2018
ТОП 500 суперкомпьютеров на июнь 2018

Суперкомпьютеры
Суперкомпьютер – это вычислительная система, обладающая предельными характеристиками по производительности среди
Суперкомпьютеры
Суперкомпьютер – это вычислительная система, обладающая предельными характеристиками по производительности среди

Примеры
Суперкомпьютер СКИФ МГУ
(НИВЦ МГУ) 2008
Общее количество двухпроцессорных узлов 625
(1250 четырехядерных
Примеры
Суперкомпьютер СКИФ МГУ
(НИВЦ МГУ) 2008
Общее количество двухпроцессорных узлов 625
(1250 четырехядерных

Персональные мини-кластеры
T-Edge Mini - см. http://www.t-platforms.ru/ru/temini.php
4 двухпроцессорных узла на базе
Персональные мини-кластеры
T-Edge Mini - см. http://www.t-platforms.ru/ru/temini.php
4 двухпроцессорных узла на базе

Пути достижения параллелизма
Пути достижения параллелизма:
независимость функционирования отдельных устройств ЭВМ;
избыточность элементов вычислительной
Пути достижения параллелизма
Пути достижения параллелизма:
независимость функционирования отдельных устройств ЭВМ;
избыточность элементов вычислительной

Процессы, потоки, нити
Процесс (задача) - программа, находящаяся в режиме выполнения.
С
Процессы, потоки, нити
Процесс (задача) - программа, находящаяся в режиме выполнения.
С
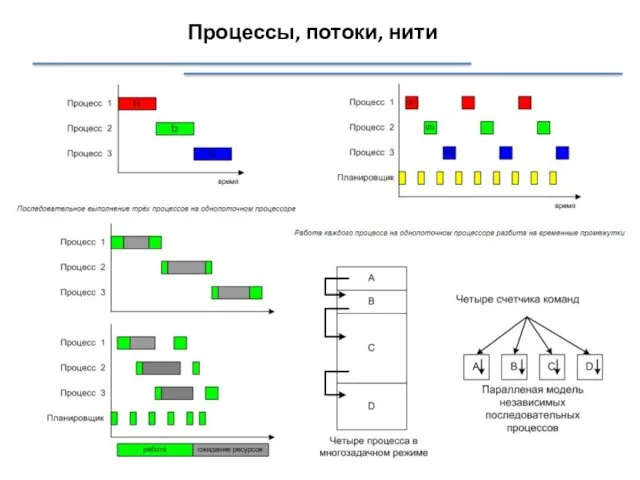
Процессы, потоки, нити
Процессы, потоки, нити

Что сработает быстрее?
Дано:
1 задача = Подзадача1 + Подзадача2 + Подзадача3
t=t1+t2+t3
1 процессор
Что сработает быстрее?
Дано:
1 задача = Подзадача1 + Подзадача2 + Подзадача3
t=t1+t2+t3
1 процессор
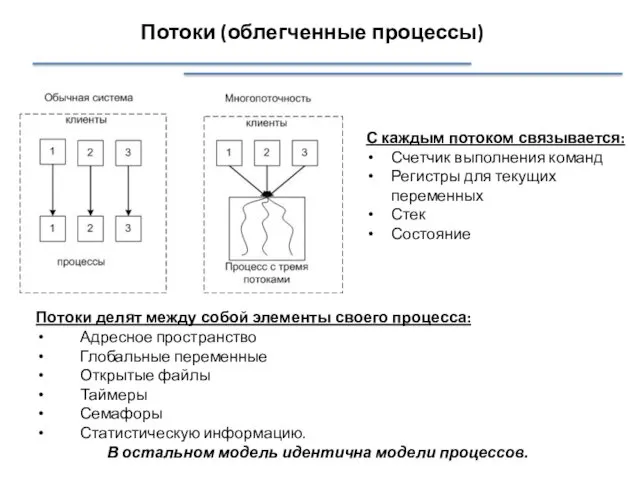
Потоки (облегченные процессы)
С каждым потоком связывается:
Счетчик выполнения команд
Регистры для
Потоки (облегченные процессы)
С каждым потоком связывается:
Счетчик выполнения команд
Регистры для

Процессы, потоки, нити
Преимущества использования потоков
Упрощение программы в некоторых случаях, за
Процессы, потоки, нити
Преимущества использования потоков
Упрощение программы в некоторых случаях, за
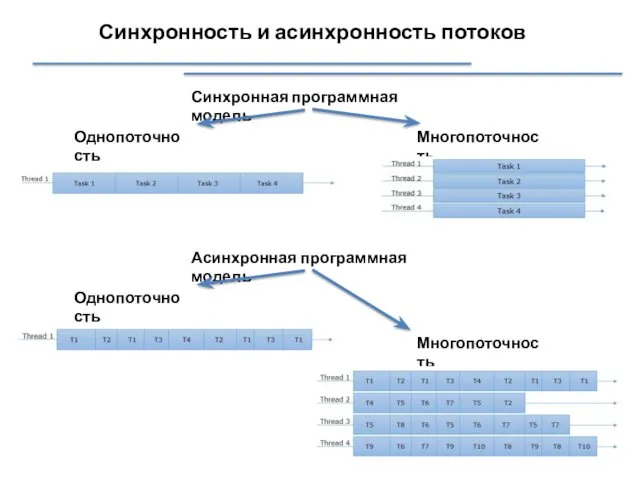
Синхронность и асинхронность потоков
Синхронная программная модель
Однопоточность
Многопоточность
Асинхронная программная модель
Однопоточность
Многопоточность
Синхронность и асинхронность потоков
Синхронная программная модель
Однопоточность
Многопоточность
Асинхронная программная модель
Однопоточность
Многопоточность
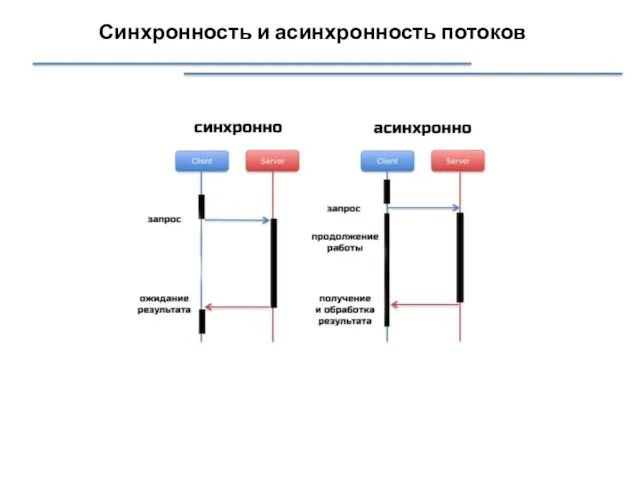
Синхронность и асинхронность потоков
Синхронность и асинхронность потоков

Объекты синхронизации и проблемы потоков
Критическая секция (CriticalSection)
Взаимоисключение (мьютекс, mutex - от
Объекты синхронизации и проблемы потоков
Критическая секция (CriticalSection)
Взаимоисключение (мьютекс, mutex - от
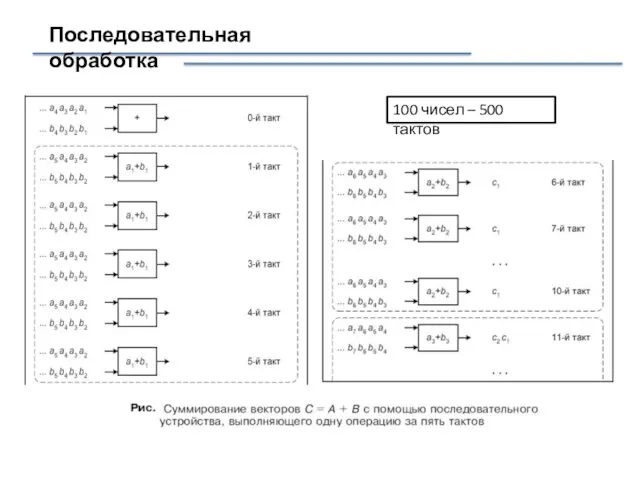
Последовательная обработка
100 чисел – 500 тактов
Последовательная обработка
100 чисел – 500 тактов
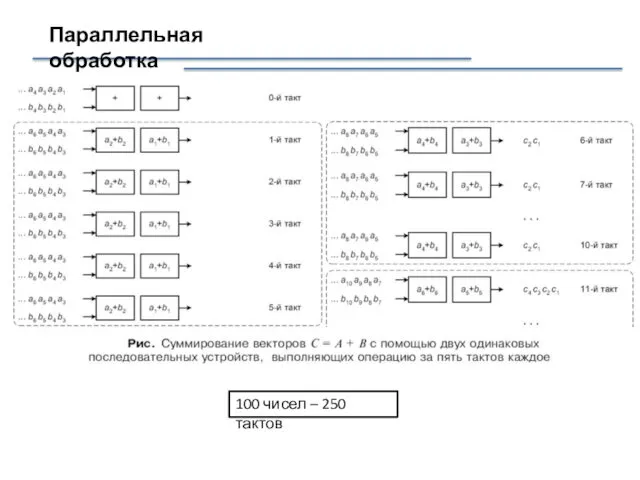
Параллельная обработка
100 чисел – 250 тактов
Параллельная обработка
100 чисел – 250 тактов
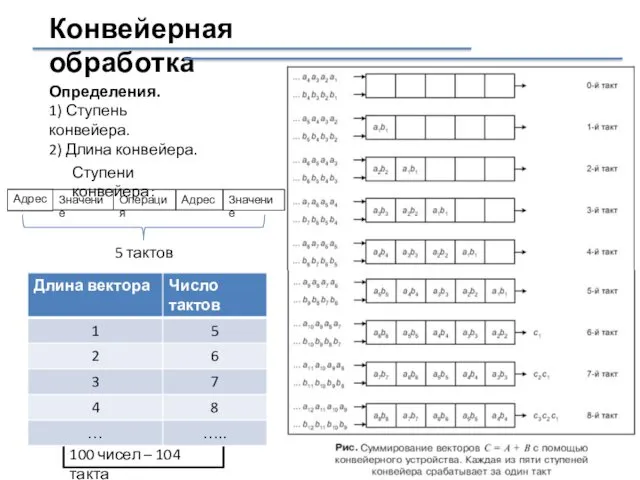
Конвейерная обработка
Определения.
1) Ступень конвейера.
2) Длина конвейера.
Адрес
Значение
Операция
Адрес
Ступени конвейера:
Значение
5 тактов
100 чисел –
Конвейерная обработка
Определения.
1) Ступень конвейера.
2) Длина конвейера.
Адрес
Значение
Операция
Адрес
Ступени конвейера:
Значение
5 тактов
100 чисел –
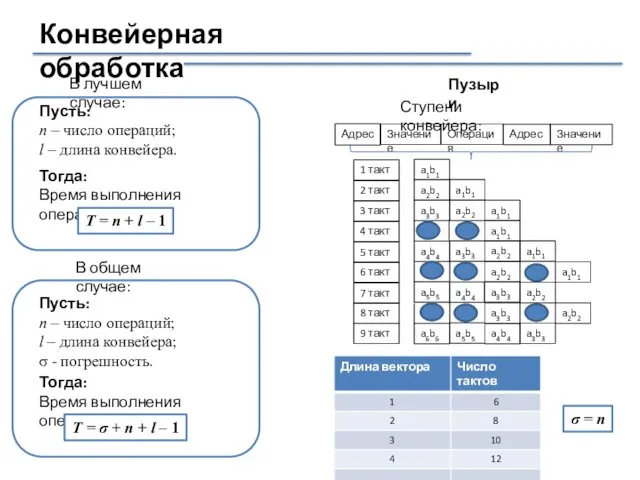
Конвейерная обработка
Пусть:
n – число операций;
l – длина конвейера.
Тогда:
Время выполнения
Конвейерная обработка
Пусть:
n – число операций;
l – длина конвейера.
Тогда:
Время выполнения
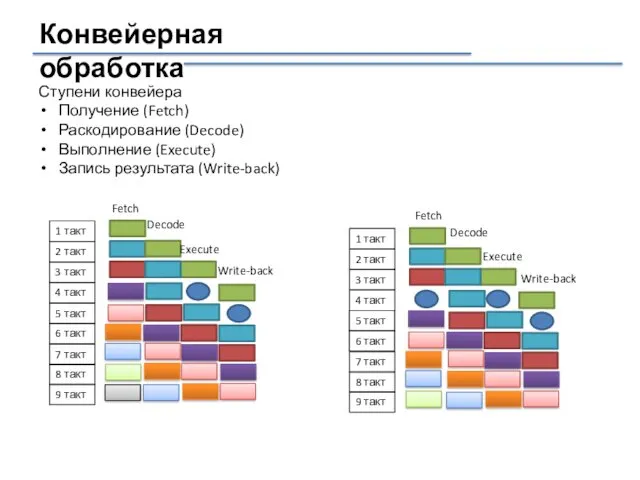
Конвейерная обработка
Ступени конвейера
Получение (Fetch)
Раскодирование (Decode)
Выполнение (Execute)
Запись результата (Write-back)
Fetch
Decode
Execute
Write-back
Fetch
Decode
Execute
Write-back
Конвейерная обработка
Ступени конвейера
Получение (Fetch)
Раскодирование (Decode)
Выполнение (Execute)
Запись результата (Write-back)
Fetch
Decode
Execute
Write-back
Fetch
Decode
Execute
Write-back
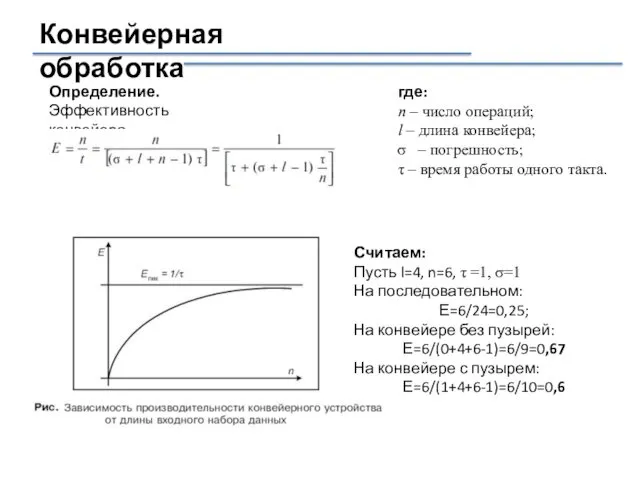
Конвейерная обработка
Определение.
Эффективность конвейера.
где:
n – число операций;
l – длина конвейера;
– погрешность;
τ
Конвейерная обработка
Определение.
Эффективность конвейера.
где:
n – число операций;
l – длина конвейера;
– погрешность;
τ

Технико-эксплуатационные характеристики ЭВМ
быстродействие;
разрядность;
формы представления чисел;
номенклатура и характеристики запоминающих устройств;
номенклатура и характеристики
Технико-эксплуатационные характеристики ЭВМ
быстродействие;
разрядность;
формы представления чисел;
номенклатура и характеристики запоминающих устройств;
номенклатура и характеристики

Классификации компьютеров
принцип действия:
(цифровые, аналоговые и гибридные);
назначение:
(универсальные, проблемно-ориентированные, специализированные);
размеры и
Классификации компьютеров
принцип действия:
(цифровые, аналоговые и гибридные);
назначение:
(универсальные, проблемно-ориентированные, специализированные);
размеры и
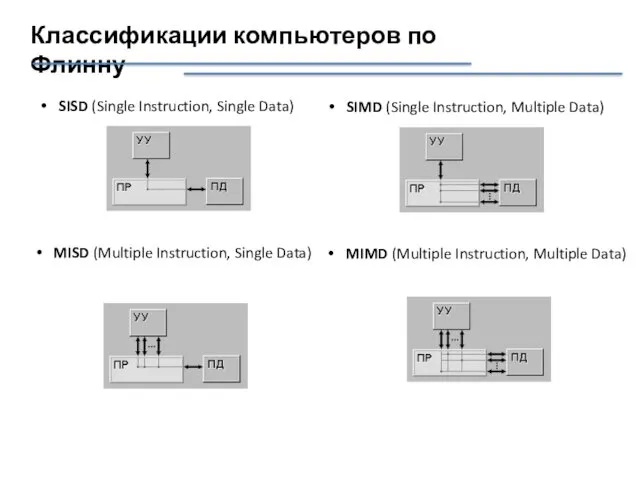
Классификации компьютеров по Флинну
SISD (Single Instruction, Single Data)
SIMD (Single Instruction, Multiple
Классификации компьютеров по Флинну
SISD (Single Instruction, Single Data)
SIMD (Single Instruction, Multiple
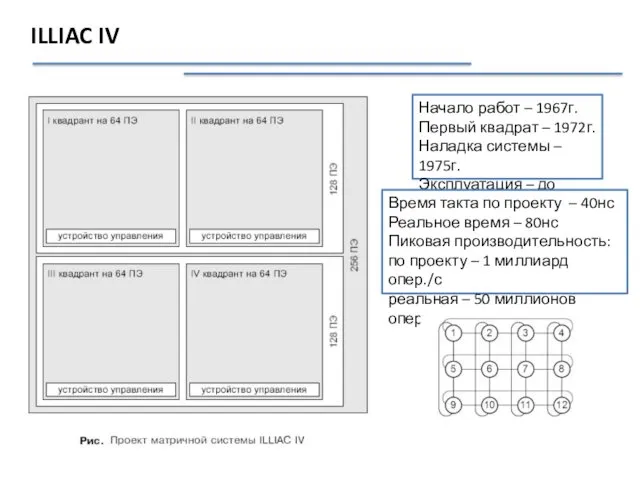
ILLIAC IV
Начало работ – 1967г.
Первый квадрат – 1972г.
Наладка системы – 1975г.
Эксплуатация
ILLIAC IV
Начало работ – 1967г.
Первый квадрат – 1972г.
Наладка системы – 1975г.
Эксплуатация
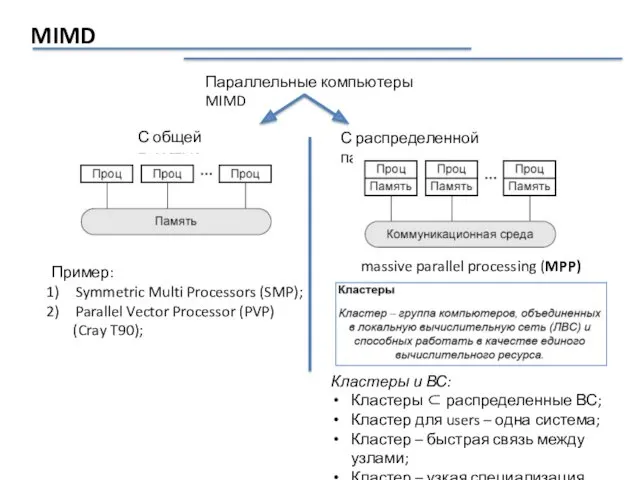
MIMD
Параллельные компьютеры MIMD
С общей памятью
С распределенной памятью
Пример:
Symmetric Multi Processors
MIMD
Параллельные компьютеры MIMD
С общей памятью
С распределенной памятью
Пример:
Symmetric Multi Processors
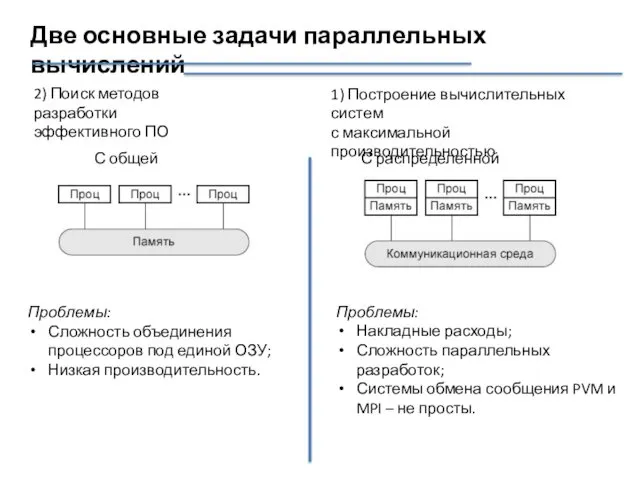
Две основные задачи параллельных вычислений
С общей памятью
С распределенной памятью
Проблемы:
Накладные расходы;
Сложность
Две основные задачи параллельных вычислений
С общей памятью
С распределенной памятью
Проблемы:
Накладные расходы;
Сложность
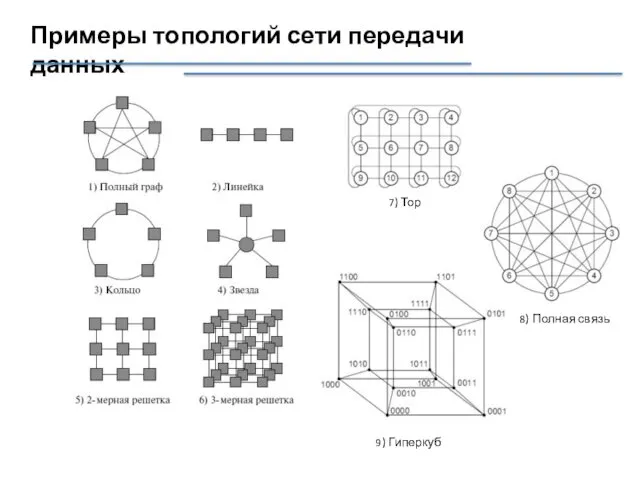
Примеры топологий сети передачи данных
7) Тор
8) Полная связь
9) Гиперкуб
Примеры топологий сети передачи данных
7) Тор
8) Полная связь
9) Гиперкуб
 Роль семьи в формировании межнациональной толерантности у детей старшего дошкольного возраста.
Роль семьи в формировании межнациональной толерантности у детей старшего дошкольного возраста. Разработка программы оптимального распределения энергии для диаграммы направленности антенной решетки
Разработка программы оптимального распределения энергии для диаграммы направленности антенной решетки А.С Пушкин Капитанская дочка
А.С Пушкин Капитанская дочка технология
технология Суточное осевое вращение Земли
Суточное осевое вращение Земли Право международной безопасности. Международное публичное право
Право международной безопасности. Международное публичное право Комплексный центр социального обслуживания населения г. Бородино. Сопровождение семей, имеющих детей-инвалидов
Комплексный центр социального обслуживания населения г. Бородино. Сопровождение семей, имеющих детей-инвалидов История адаптивного спорта для лиц с поражением слуха
История адаптивного спорта для лиц с поражением слуха Презентация игра Четвёртый лишний
Презентация игра Четвёртый лишний Профессиональный стресс. Проявление хронической усталости и психического выгорания
Профессиональный стресс. Проявление хронической усталости и психического выгорания Морская политика России
Морская политика России Презентация Наша жизнь
Презентация Наша жизнь Информационно - коммуникационные технологии в работе с детьми по экологическому воспитанию
Информационно - коммуникационные технологии в работе с детьми по экологическому воспитанию Запорная арматура. Классификация
Запорная арматура. Классификация Биологическое преобразование энергии: дыхание, фотосинтез, хемосинтез
Биологическое преобразование энергии: дыхание, фотосинтез, хемосинтез Интегральное исчисление функций нескольких переменных. Двойные интегралы
Интегральное исчисление функций нескольких переменных. Двойные интегралы подготовка_к_кр_дроби_и_смешанные_числа
подготовка_к_кр_дроби_и_смешанные_числа Фильтры грубой очистки фланцевые MVI серии FF.310. Технический паспорт
Фильтры грубой очистки фланцевые MVI серии FF.310. Технический паспорт Mark Twain
Mark Twain Мышление и культура в этнопсихологии. (Тема 4)
Мышление и культура в этнопсихологии. (Тема 4) Привычки успешных мам
Привычки успешных мам Основания. Состав оснований
Основания. Состав оснований Готовность к школьному обучению
Готовность к школьному обучению Система организации оказания медицинской помощи городскому населению
Система организации оказания медицинской помощи городскому населению ВКР: Имидж гостиничного предприятия (планирование, формирование, продвижение)
ВКР: Имидж гостиничного предприятия (планирование, формирование, продвижение) Издержки фирмы
Издержки фирмы Здравствуй, школа!
Здравствуй, школа! Диагностика острой ревматической лихорадки
Диагностика острой ревматической лихорадки