- Разработка подсистемы компьютерной идентификации пользователя по клавиатурному почерку

Содержание
- 2. Классификация методов идентификации Методы идентификации пользователя по клавиатурному почерку Метод аутентификации пользователя по клавиатурному почерку на
- 3. Классификация и настройка клавиатур вычислительной техники Настройка клавиатур . - Фильтрация ввода: можно настроить Windows на
- 4. Выбор признаков идентификации При наборе фразы подсистема идентификации регистрирует два вектора Ti и Tzi. Где Ti
- 5. где Tzi – задержка на i-ом символе; n - число символов. Ti - время набора i-того
- 6. Структурная схема модели идентификации образа
- 7. Реляционная организация базы данных Преимущество реляционной организации БД: Высокая производительность; Возможность задания множества диапазонов; Простота аппаратной
- 8. Схема алгоритма программы где qx – исследуемый образ; Q* - класс, к которому отнесен неизвестный исследуемый
- 9. Рабочее окно программы (режим обучения)
- 10. Рабочее окно программы (режим записи данных)
- 11. Рабочее окно программы (режим идентификации)
- 12. Статистические данные оценки меры Хемминга
- 14. Скачать презентацию
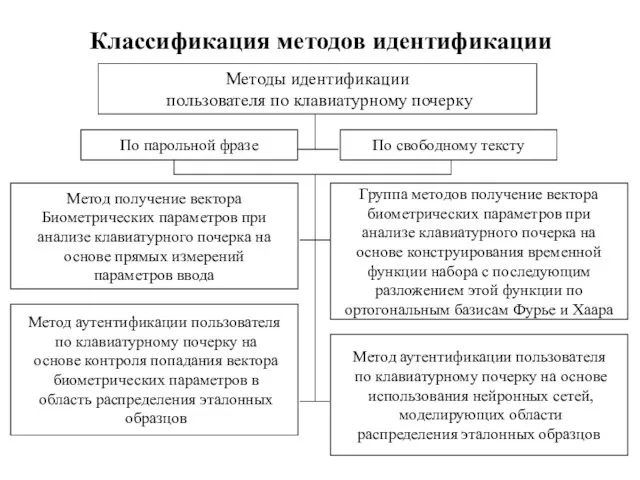
Классификация методов идентификации
Методы идентификации
пользователя по клавиатурному почерку
Метод аутентификации пользователя
по
Классификация методов идентификации
Методы идентификации
пользователя по клавиатурному почерку
Метод аутентификации пользователя
по

Классификация и настройка клавиатур вычислительной техники
Настройка клавиатур .
- Фильтрация ввода:
Классификация и настройка клавиатур вычислительной техники
Настройка клавиатур .
- Фильтрация ввода:

Выбор признаков идентификации
При наборе фразы подсистема идентификации регистрирует два вектора
Выбор признаков идентификации
При наборе фразы подсистема идентификации регистрирует два вектора

где Tzi – задержка на i-ом символе;
n - число символов.
где Tzi – задержка на i-ом символе;
n - число символов.
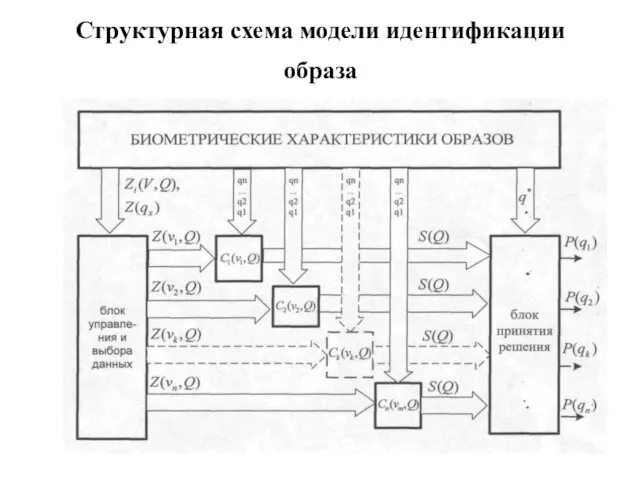
Структурная схема модели идентификации образа
Структурная схема модели идентификации образа
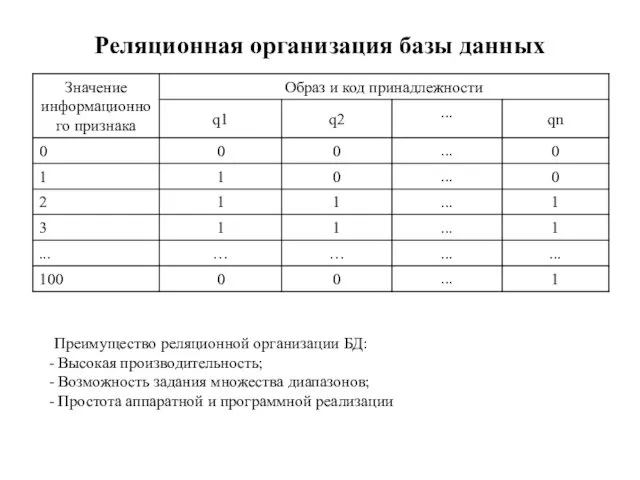
Реляционная организация базы данных
Преимущество реляционной организации БД:
Высокая производительность;
Возможность
Реляционная организация базы данных
Преимущество реляционной организации БД:
Высокая производительность;
Возможность
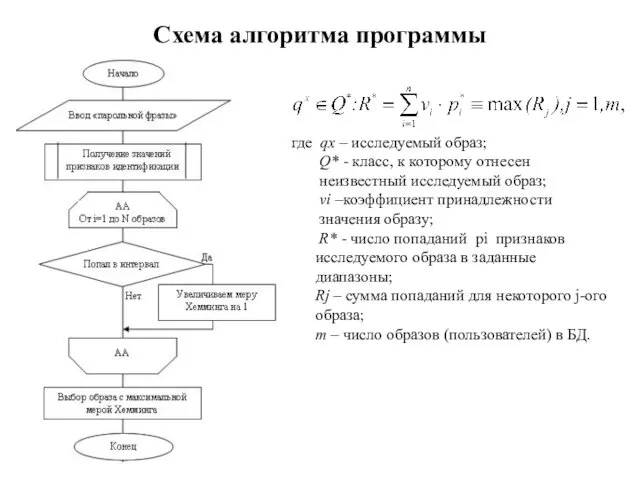
Схема алгоритма программы
где qx – исследуемый образ;
Q* - класс, к
Схема алгоритма программы
где qx – исследуемый образ;
Q* - класс, к
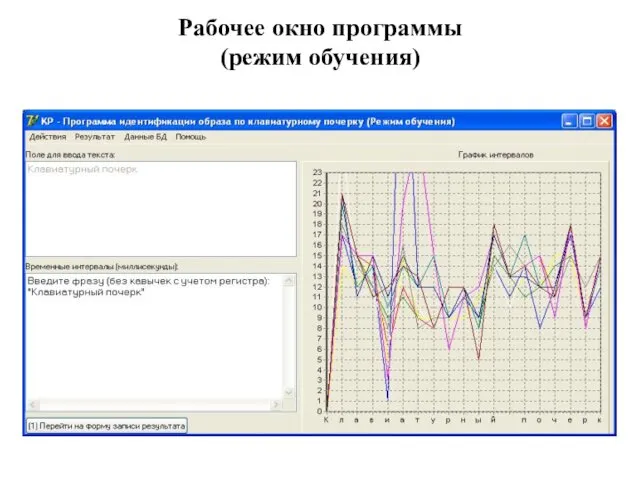
Рабочее окно программы
(режим обучения)
Рабочее окно программы
(режим обучения)
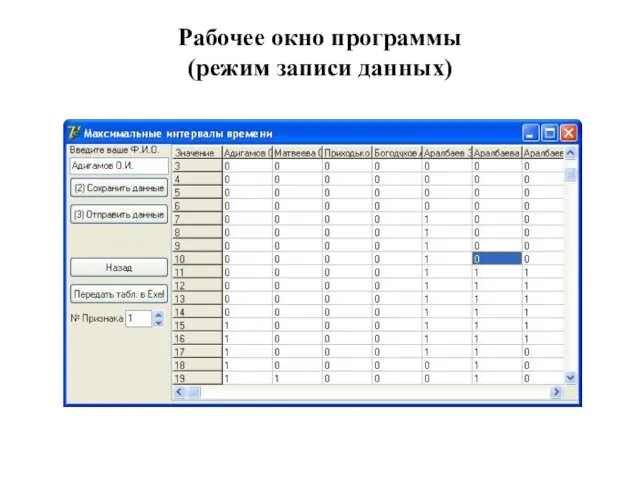
Рабочее окно программы
(режим записи данных)
Рабочее окно программы
(режим записи данных)
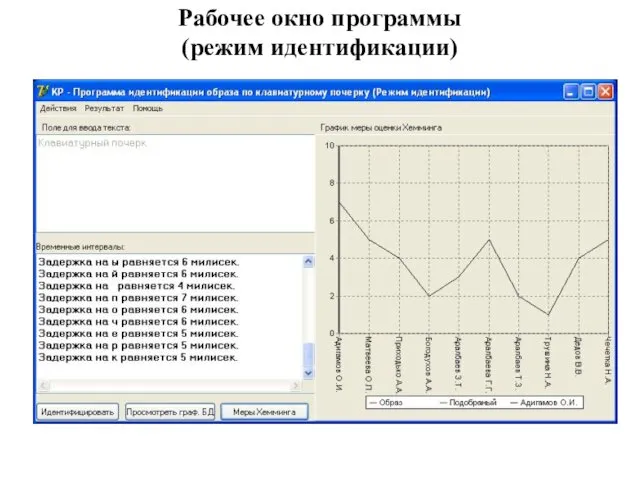
Рабочее окно программы
(режим идентификации)
Рабочее окно программы
(режим идентификации)
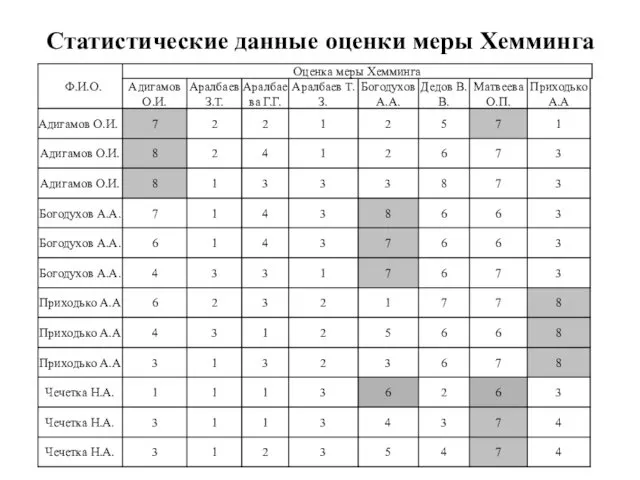
Статистические данные оценки меры Хемминга
Статистические данные оценки меры Хемминга
 Роль семьи в формировании межнациональной толерантности у детей старшего дошкольного возраста.
Роль семьи в формировании межнациональной толерантности у детей старшего дошкольного возраста. Разработка программы оптимального распределения энергии для диаграммы направленности антенной решетки
Разработка программы оптимального распределения энергии для диаграммы направленности антенной решетки А.С Пушкин Капитанская дочка
А.С Пушкин Капитанская дочка технология
технология Суточное осевое вращение Земли
Суточное осевое вращение Земли Право международной безопасности. Международное публичное право
Право международной безопасности. Международное публичное право Комплексный центр социального обслуживания населения г. Бородино. Сопровождение семей, имеющих детей-инвалидов
Комплексный центр социального обслуживания населения г. Бородино. Сопровождение семей, имеющих детей-инвалидов История адаптивного спорта для лиц с поражением слуха
История адаптивного спорта для лиц с поражением слуха Презентация игра Четвёртый лишний
Презентация игра Четвёртый лишний Профессиональный стресс. Проявление хронической усталости и психического выгорания
Профессиональный стресс. Проявление хронической усталости и психического выгорания Морская политика России
Морская политика России Презентация Наша жизнь
Презентация Наша жизнь Информационно - коммуникационные технологии в работе с детьми по экологическому воспитанию
Информационно - коммуникационные технологии в работе с детьми по экологическому воспитанию Запорная арматура. Классификация
Запорная арматура. Классификация Биологическое преобразование энергии: дыхание, фотосинтез, хемосинтез
Биологическое преобразование энергии: дыхание, фотосинтез, хемосинтез Интегральное исчисление функций нескольких переменных. Двойные интегралы
Интегральное исчисление функций нескольких переменных. Двойные интегралы подготовка_к_кр_дроби_и_смешанные_числа
подготовка_к_кр_дроби_и_смешанные_числа Фильтры грубой очистки фланцевые MVI серии FF.310. Технический паспорт
Фильтры грубой очистки фланцевые MVI серии FF.310. Технический паспорт Mark Twain
Mark Twain Мышление и культура в этнопсихологии. (Тема 4)
Мышление и культура в этнопсихологии. (Тема 4) Привычки успешных мам
Привычки успешных мам Основания. Состав оснований
Основания. Состав оснований Готовность к школьному обучению
Готовность к школьному обучению Система организации оказания медицинской помощи городскому населению
Система организации оказания медицинской помощи городскому населению ВКР: Имидж гостиничного предприятия (планирование, формирование, продвижение)
ВКР: Имидж гостиничного предприятия (планирование, формирование, продвижение) Издержки фирмы
Издержки фирмы Здравствуй, школа!
Здравствуй, школа! Диагностика острой ревматической лихорадки
Диагностика острой ревматической лихорадки