- Технологии повышения производительности МП

Содержание
- 2. Термины Команда. Микрооперация или микрокоманда. Микропрограмма. Микропрограммный автомат.
- 3. Повышение производительности процессоров Конвейеризация. Суперскаляризация. Увеличение количества исполнительных блоков. Введение принципа динамического исполнения команд. Гипертрейдинг. Параллелизм
- 4. Архитектура процессоров с параллелизмом уровня команд Как способ повышения производительности процессора Так было в начале эры
- 5. Суперконвейеризация Каждый этап исполнения команды разбивается на меньшие этапы и повышается частота задающего генератора
- 6. Оценка производительности идеального конвейера Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20; t = 5 – промежуточное время
- 7. Конвейер с точки зрения схемотехники КС RG КС RG КС RG CИ1 CИ2 CИ3 n Чем
- 8. Конфликты в конвейере Конфликты – это ситуации при конвейерной обработке, которые препятствуют выполнению очередной команды. Три
- 9. Причины структурных конфликтов и способы минимизации их последствий Скорость конвейера определяется скоростью исполнения самого медленного этапа
- 10. Конвейерная обработка команд суперскалярный процессор Блок выборки команд Блок декодирования Блок выборки операндов АЛУ АЛУ Блок
- 11. Суперскалярный процессор В общем случае суперскалярный процессор может менять порядок выполнения машинных команд, заданный в исходном
- 12. Конвейерное исполнение команд Принцип неупорядоченного выполнения команд Блок выборки команд Блок буфера команд Буфер очереди команд
- 13. Конфликты по управлению Возникают при конвейеризации команд меняющих значение счетчика команд. Метод выжидания Метод «задержанных переходов»
- 14. Статическое предсказание переходов Осуществляется на основе некоторой априорной информации о подлежащей исполнению программе. Известны следующие стратегии:
- 15. Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ При компилировании программы можно создать граф предполагаемых ветвлений и задать
- 16. Предикативное выполнение Предикация Блок 1 Блок 2 Блок 3 Блок 5 Блок 4 Блок 6 IN
- 17. Динамическое предсказание переходов Решение о наиболее вероятном исходе команды перехода принимается в ходе вычислений исходя из
- 18. Динамическое прогнозирование ветвлений Аппаратная реализация таблиц переходов Адрес\Тег перехода Бит перехода Бит достоверности Целевой адрес Вариант
- 19. Гибридный предиктор Макфарлинга Схема имеет два независимых предиктора, отличающиеся глубиной предыстории Счетчик выбора предиктора Младшие разряды
- 20. Общая схема гибридного предиктора
- 21. Опережающее чтение данных Спекулятивное выполнение команды Команда 1 Чтение с опережением Команда проверки Команда 9 Обработка
- 22. Выполнение одной команды зависит от результата выполнения другой Конфликты по данным и их решение Конфликт чтение
- 23. Планирование загрузки конвейера. Переименование регистров МП. Решение конфликтов по данным Базовый блок 1 программы 2 Команда
- 24. Технология динамического исполнения команд Суперскалярность. Предсказание переходов. Неупорядочное исполнение команд. Предварительная загрузка данных. Переименование регистров. Предикативное
- 25. Характеристика конвейeров МП Intel и AMD
- 26. Технология многократного декодирование команд используя CMS Предекодер Предекодер Предекодер Декодер Исполнительные блоки Команды CISC/RISC Команда VLIW
- 27. Технология макрослияния (macrofusion) Макрослияние позволяет объединять типичные пары последовательных команд (например - сравнение и условный переход)
- 28. Технология микрослияния (Micro-op fusion) Команды при декодировании могут использовать одинаковые микрокоманды Технология предусматривает однократный вызов микрокоманды
- 29. Технология резервирующей станции Команды выполняются с разным быстродействием. Команды могут зависеть друг от друга. Командам могут
- 30. Микроархитектура Pentium2 Устройство сопряжения с шиной Кэш первого уровня для команд Кэш первого уровня для данных
- 31. Микроархитектура Pentium2 блок вызова декодирования Кэш первого уровня для команд Блок выбора строк кэш Декодер длины
- 32. Микроархитектура Pentium2 блок отправки\выполнения Очередь микрокоманд 20 РЕЗЕРВАЦИЯ Блок выполнения операций с целыми числами Блок выполнения
- 33. Микроархитектура Pentium2 блок возврата Отвечает: - за отправку результатов в регистры или устройства, которым они требуются.
- 34. Пример конвейера AMD K8 часть1
- 35. Пример конвейера AMD K8 часть 2
- 36. Проблемы суперскальных МП Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП. Наличие одного счетчика команд. Ограничение
- 37. Мультитрейдовые микропроцессоры Тред – вычислительный процесс обслуживаемый отдельным набором регистров. Однотрейдовый микропроцессор – имеет один счетчик
- 38. Принцип работы мультитрейдовой архитектуры Тред 1 Тред 2 Тред N Память Коммутатор M тактов Планировщик -
- 39. Технология Hyper-Threading Реализуется идея разделения времени на аппаратном уровне Задача 1 Задача 1 АЛУ Регистры Управление
- 40. Технология Hyper-Threading
- 41. Itanium Использование сложных команд переменной длины, обрабатываемых последовательно Использование простых команд одинаковой длины, сгруппированных в связки
- 42. Этапы развития структур МП по системам команд CISC RISC VLIW VLIW EPIC Внешние команды CISC ядро
- 43. Синтез команд для процессоров VLIW Задача эффективного планирования параллельных вычислений команд возлагается на «разумный» компилятор Code
- 44. Формат связки команд Компилятор формирует связки команд длинной 128 бит. Itanium Маска 8р. Команда 1 Команда
- 45. Взаимосвязь полей команды VLIW с исполнительными блоками До 128 байт Статическая суперскалярная архитектура – одно из
- 47. Скачать презентацию
Термины
Команда.
Микрооперация или микрокоманда.
Микропрограмма.
Микропрограммный автомат.
Термины
Команда.
Микрооперация или микрокоманда.
Микропрограмма.
Микропрограммный автомат.

Повышение производительности процессоров
Конвейеризация.
Суперскаляризация.
Увеличение количества исполнительных блоков.
Введение принципа динамического исполнения команд.
Гипертрейдинг.
Параллелизм исполнения команд на
Повышение производительности процессоров
Конвейеризация.
Суперскаляризация.
Увеличение количества исполнительных блоков.
Введение принципа динамического исполнения команд.
Гипертрейдинг.
Параллелизм исполнения команд на

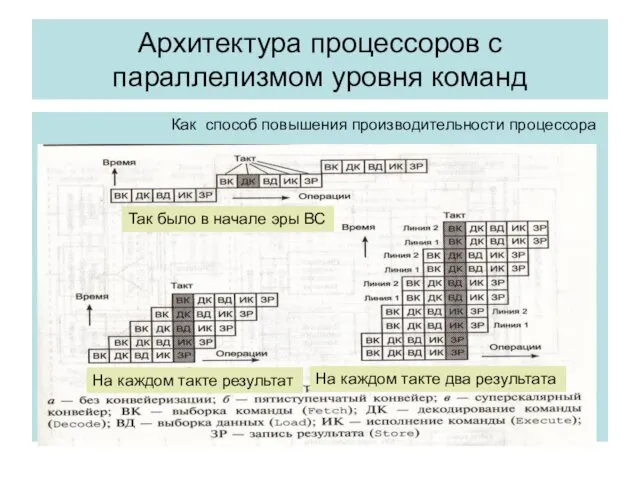
Архитектура процессоров с параллелизмом уровня команд
Как способ повышения производительности процессора
Так было в начале
Архитектура процессоров с параллелизмом уровня команд
Как способ повышения производительности процессора
Так было в начале
Суперконвейеризация
Каждый этап исполнения команды разбивается на меньшие этапы
и повышается частота задающего генератора
Суперконвейеризация
Каждый этап исполнения команды разбивается на меньшие этапы
и повышается частота задающего генератора

Оценка производительности идеального конвейера
Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20;
t = 5 – промежуточное
Оценка производительности идеального конвейера
Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20;
t = 5 – промежуточное

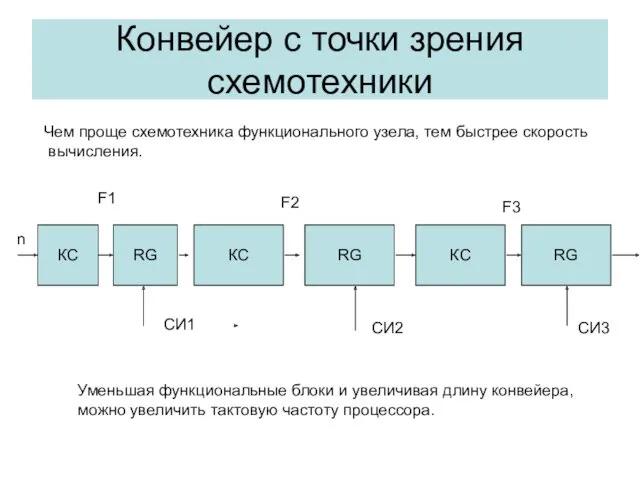
Конвейер с точки зрения схемотехники
КС
RG
КС
RG
КС
RG
CИ1
CИ2
CИ3
n
Чем проще схемотехника функционального узела, тем быстрее скорость
вычисления.
F1
F3
F2
Уменьшая
Конвейер с точки зрения схемотехники
КС
RG
КС
RG
КС
RG
CИ1
CИ2
CИ3
n
Чем проще схемотехника функционального узела, тем быстрее скорость
вычисления.
F1
F3
F2
Уменьшая
Конфликты в конвейере
Конфликты – это ситуации при конвейерной обработке, которые препятствуют выполнению очередной
Конфликты в конвейере
Конфликты – это ситуации при конвейерной обработке, которые препятствуют выполнению очередной

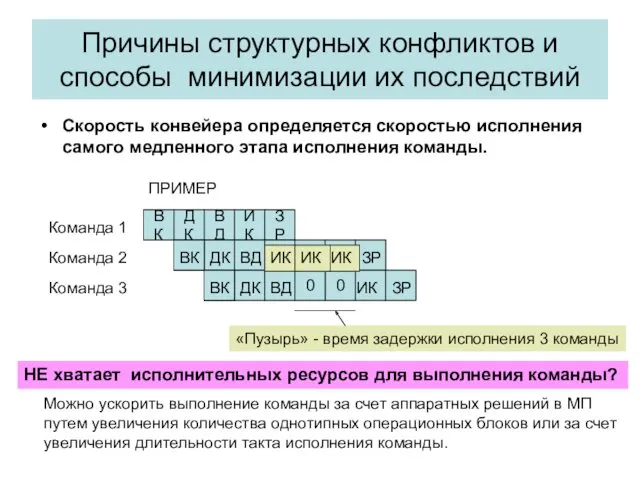
Причины структурных конфликтов и способы минимизации их последствий
Скорость конвейера определяется скоростью исполнения самого
Причины структурных конфликтов и способы минимизации их последствий
Скорость конвейера определяется скоростью исполнения самого
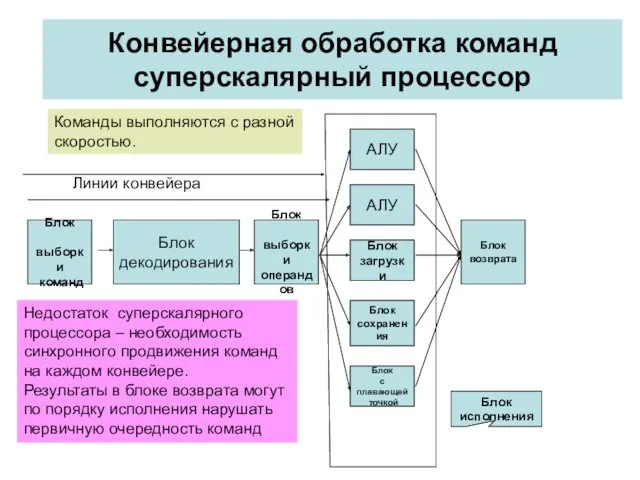
Конвейерная обработка команд суперскалярный процессор
Блок
выборки
команд
Блок
декодирования
Блок
выборки
операндов
АЛУ
АЛУ
Блок
загрузки
Блок
сохранения
Блок
с плавающей
точкой
Блок
возврата
Блок
исполнения
Команды выполняются с
Конвейерная обработка команд суперскалярный процессор
Блок
выборки
команд
Блок
декодирования
Блок
выборки
операндов
АЛУ
АЛУ
Блок
загрузки
Блок
сохранения
Блок
с плавающей
точкой
Блок
возврата
Блок
исполнения
Команды выполняются с
Суперскалярный процессор
В общем случае суперскалярный процессор может менять порядок
выполнения машинных команд, заданный
Суперскалярный процессор
В общем случае суперскалярный процессор может менять порядок
выполнения машинных команд, заданный
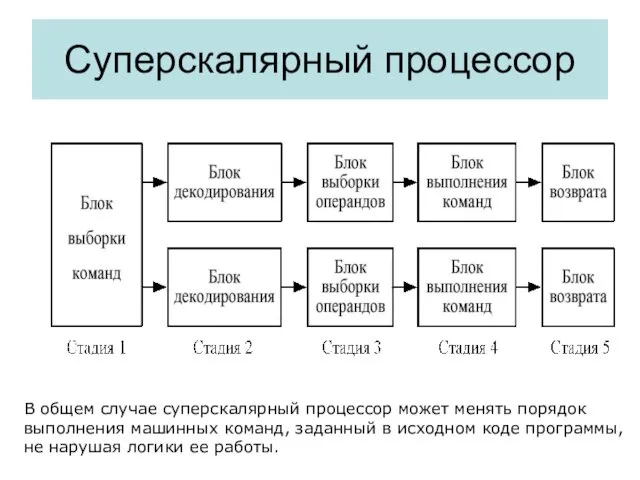
Конвейерное исполнение команд
Принцип неупорядоченного выполнения
команд
Блок
выборки
команд
Блок
буфера
команд
Буфер
очереди
команд
Блок
выборки
данных
Блок
неупорядоченного
выполнения
команд
Блок
восстановления
последовательности
выполнения
команд
Динамический принцип исполнения команд
Конвейерное исполнение команд
Принцип неупорядоченного выполнения
команд
Блок
выборки
команд
Блок
буфера
команд
Буфер
очереди
команд
Блок
выборки
данных
Блок
неупорядоченного
выполнения
команд
Блок
восстановления
последовательности
выполнения
команд
Динамический принцип исполнения команд
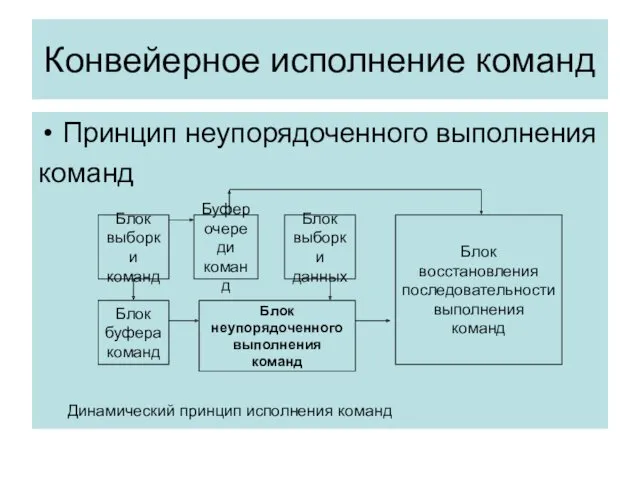
Конфликты по управлению
Возникают при конвейеризации команд меняющих значение счетчика команд.
Метод
выжидания
Метод
«задержанных
переходов»
Метод
предсказания
переходов
Статический
Динамический
R1=R2+R3
If R2=0, then
Слот
Конфликты по управлению
Возникают при конвейеризации команд меняющих значение счетчика команд.
Метод
выжидания
Метод
«задержанных
переходов»
Метод
предсказания
переходов
Статический
Динамический
R1=R2+R3
If R2=0, then
Слот
Статическое предсказание переходов
Осуществляется на основе некоторой априорной информации о подлежащей исполнению программе. Известны
Статическое предсказание переходов
Осуществляется на основе некоторой априорной информации о подлежащей исполнению программе. Известны

Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ
При компилировании программы можно создать граф предполагаемых ветвлений
Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ
При компилировании программы можно создать граф предполагаемых ветвлений

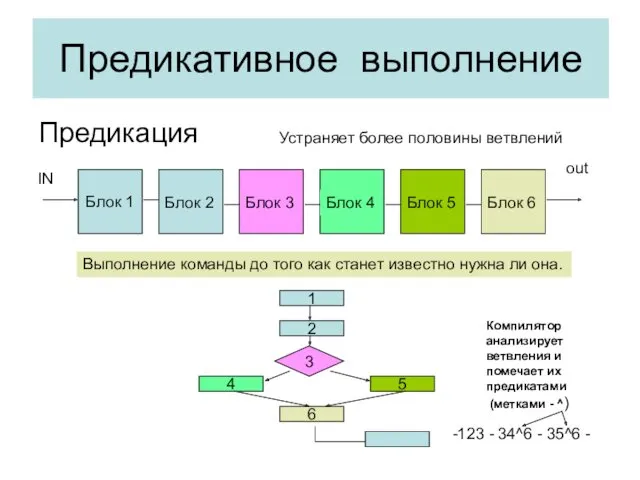
Предикативное выполнение
Предикация
Блок 1
Блок 2
Блок 3
Блок 5
Блок 4
Блок 6
IN
out
Выполнение команды до того как
Предикативное выполнение
Предикация
Блок 1
Блок 2
Блок 3
Блок 5
Блок 4
Блок 6
IN
out
Выполнение команды до того как
Динамическое предсказание переходов
Решение о наиболее вероятном исходе команды перехода принимается в ходе вычислений
Динамическое предсказание переходов
Решение о наиболее вероятном исходе команды перехода принимается в ходе вычислений

Динамическое прогнозирование ветвлений
Аппаратная реализация таблиц переходов
Адрес\Тег перехода
Бит перехода
Бит достоверности
Целевой адрес
Вариант 1
Вариант 2
к
К-1
К-2
Сдвиговый регистр
Динамическое прогнозирование ветвлений
Аппаратная реализация таблиц переходов
Адрес\Тег перехода
Бит перехода
Бит достоверности
Целевой адрес
Вариант 1
Вариант 2
к
К-1
К-2
Сдвиговый регистр
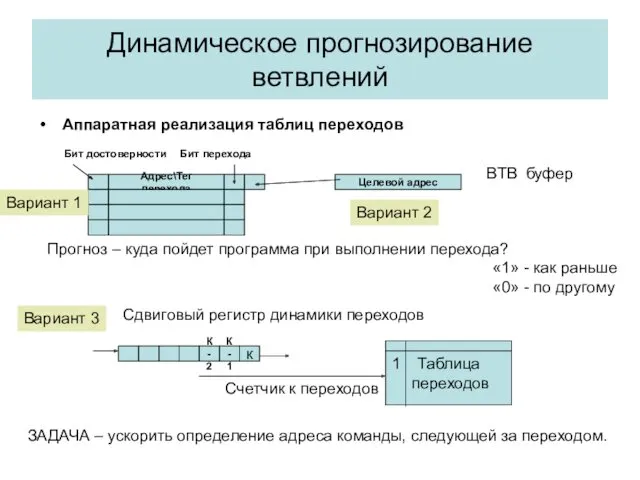
Гибридный предиктор Макфарлинга
Схема имеет два независимых предиктора, отличающиеся глубиной предыстории
Счетчик выбора предиктора
Младшие разряды
Гибридный предиктор Макфарлинга
Схема имеет два независимых предиктора, отличающиеся глубиной предыстории
Счетчик выбора предиктора
Младшие разряды
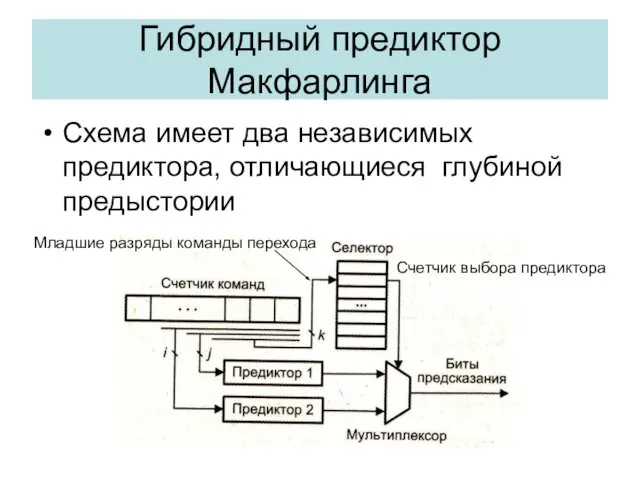
Общая схема гибридного предиктора
Общая схема гибридного предиктора
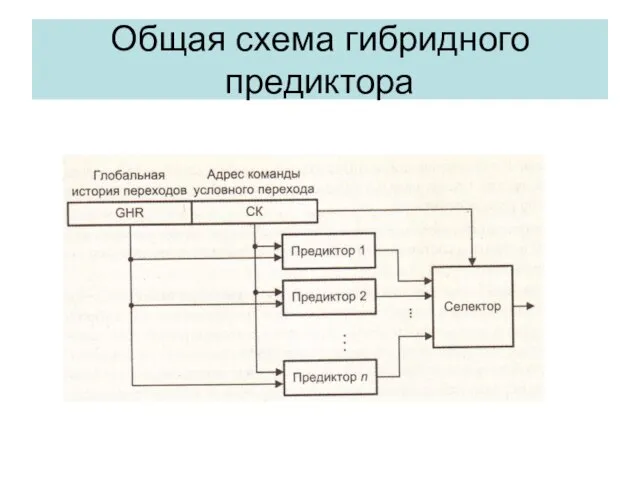
Опережающее чтение данных
Спекулятивное выполнение команды
Команда 1
Чтение
с опережением
Команда
проверки
Команда 9
Обработка
Команда 2
Команда 3
переход
Команда 4
Команда 5
Команда 6
Команда
Опережающее чтение данных
Спекулятивное выполнение команды
Команда 1
Чтение
с опережением
Команда
проверки
Команда 9
Обработка
Команда 2
Команда 3
переход
Команда 4
Команда 5
Команда 6
Команда
Выполнение одной команды зависит от результата выполнения другой
Конфликты по данным и их решение
Конфликт
Выполнение одной команды зависит от результата выполнения другой
Конфликты по данным и их решение
Конфликт
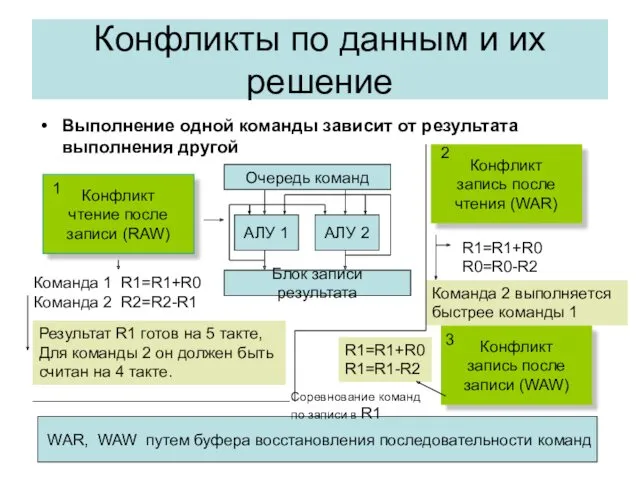
Планирование загрузки конвейера.
Переименование регистров МП.
Решение конфликтов по данным
Базовый
блок 1
программы
2
Команда
N
Компилятором выделяются
участки программы без
переходов
1
2
3
4
Действие
Запись в
Планирование загрузки конвейера.
Переименование регистров МП.
Решение конфликтов по данным
Базовый
блок 1
программы
2
Команда
N
Компилятором выделяются
участки программы без
переходов
1
2
3
4
Действие
Запись в
Технология динамического исполнения команд
Суперскалярность.
Предсказание переходов.
Неупорядочное исполнение команд.
Предварительная загрузка данных.
Переименование регистров.
Предикативное исполнение.
Резервирующая станция.
Восстановление последовательности
Технология динамического исполнения команд
Суперскалярность.
Предсказание переходов.
Неупорядочное исполнение команд.
Предварительная загрузка данных.
Переименование регистров.
Предикативное исполнение.
Резервирующая станция.
Восстановление последовательности

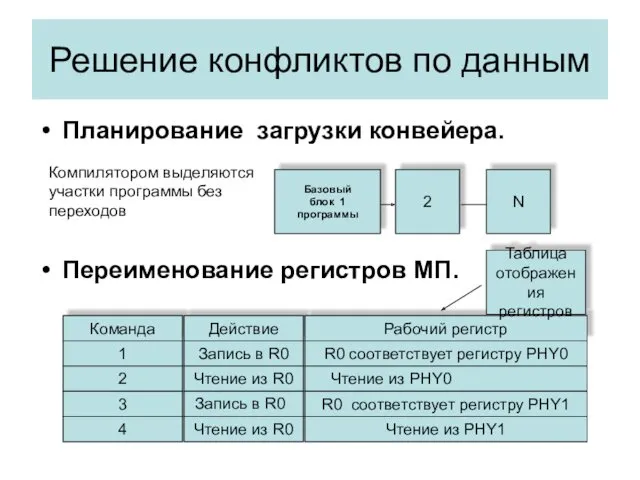
Характеристика конвейeров МП Intel и AMD
Характеристика конвейeров МП Intel и AMD
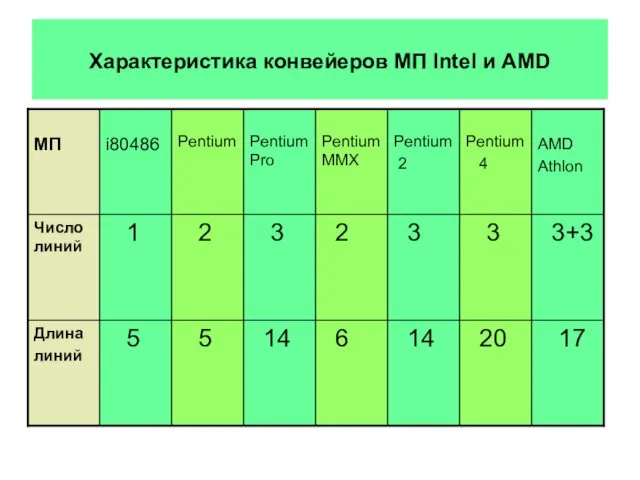
Технология многократного декодирование команд используя CMS
Предекодер
Предекодер
Предекодер
Декодер
Исполнительные
блоки
Команды CISC/RISC
Команда VLIW
Микрооперации
Микрооперации
Микрооперации
Исполнительные
блоки
Исполнительные
блоки
Макрооперации
Декодер
Декодер
Команда RISC
Команды VLIW/CISC
Команды CISC/RISC
Code Morphing
Технология многократного декодирование команд используя CMS
Предекодер
Предекодер
Предекодер
Декодер
Исполнительные
блоки
Команды CISC/RISC
Команда VLIW
Микрооперации
Микрооперации
Микрооперации
Исполнительные
блоки
Исполнительные
блоки
Макрооперации
Декодер
Декодер
Команда RISC
Команды VLIW/CISC
Команды CISC/RISC
Code Morphing
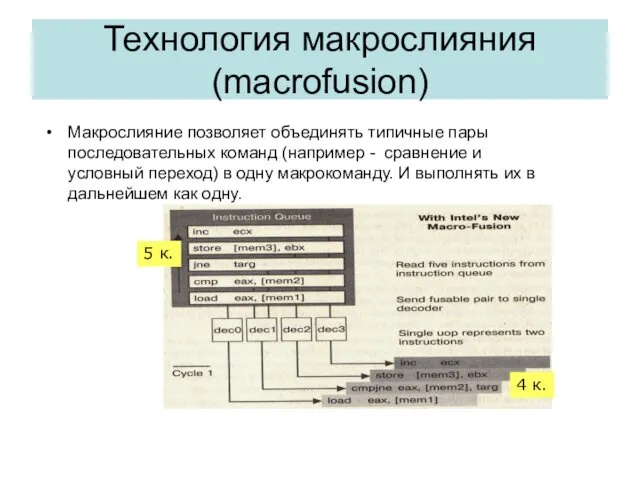
Технология макрослияния (macrofusion)
Макрослияние позволяет объединять типичные пары последовательных команд (например - сравнение и
Технология макрослияния (macrofusion)
Макрослияние позволяет объединять типичные пары последовательных команд (например - сравнение и
Технология микрослияния
(Micro-op fusion)
Команды при декодировании могут использовать одинаковые микрокоманды
Технология предусматривает однократный вызов микрокоманды
Технология микрослияния
(Micro-op fusion)
Команды при декодировании могут использовать одинаковые микрокоманды
Технология предусматривает однократный вызов микрокоманды

Технология резервирующей станции
Команды выполняются с разным быстродействием.
Команды могут зависеть друг от друга.
Командам могут
Технология резервирующей станции
Команды выполняются с разным быстродействием.
Команды могут зависеть друг от друга.
Командам могут

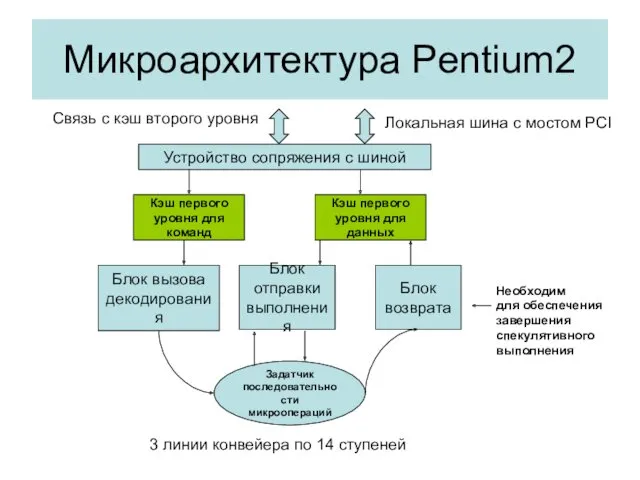
Микроархитектура Pentium2
Устройство сопряжения с шиной
Кэш первого
уровня для
команд
Кэш первого
уровня для
данных
Блок вызова
декодирования
Блок
отправки
выполнения
Блок
возврата
Задатчик
последовательности
микроопераций
Локальная шина с мостом
Микроархитектура Pentium2
Устройство сопряжения с шиной
Кэш первого
уровня для
команд
Кэш первого
уровня для
данных
Блок вызова
декодирования
Блок
отправки
выполнения
Блок
возврата
Задатчик
последовательности
микроопераций
Локальная шина с мостом
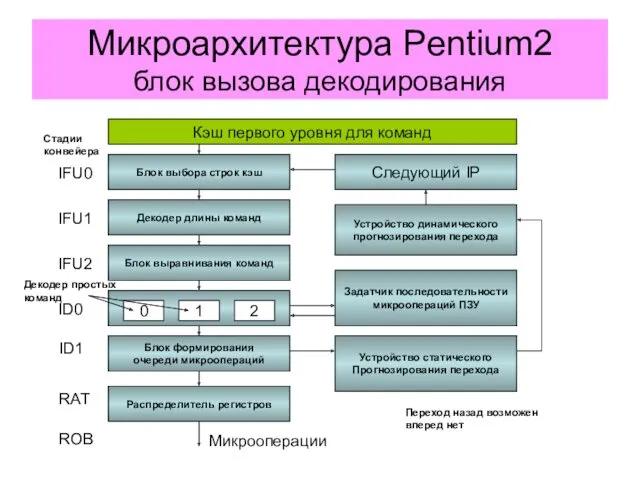
Микроархитектура Pentium2
блок вызова декодирования
Кэш первого уровня для команд
Блок выбора строк кэш
Декодер длины команд
Блок
Микроархитектура Pentium2
блок вызова декодирования
Кэш первого уровня для команд
Блок выбора строк кэш
Декодер длины команд
Блок
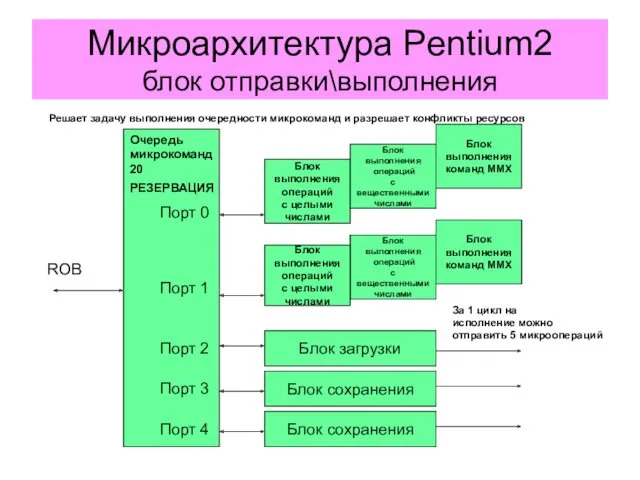
Микроархитектура Pentium2
блок отправки\выполнения
Очередь
микрокоманд
20
РЕЗЕРВАЦИЯ
Блок
выполнения
операций
с целыми
числами
Блок
выполнения
операций
с вещественными
числами
Блок
выполнения
команд ММХ
Блок загрузки
Блок сохранения
Блок сохранения
Порт 0
Порт
Микроархитектура Pentium2
блок отправки\выполнения
Очередь
микрокоманд
20
РЕЗЕРВАЦИЯ
Блок
выполнения
операций
с целыми
числами
Блок
выполнения
операций
с вещественными
числами
Блок
выполнения
команд ММХ
Блок загрузки
Блок сохранения
Блок сохранения
Порт 0
Порт
Микроархитектура Pentium2
блок возврата
Отвечает:
- за отправку результатов в регистры или устройства, которым они
Микроархитектура Pentium2
блок возврата
Отвечает:
- за отправку результатов в регистры или устройства, которым они

Пример конвейера AMD K8 часть1
Пример конвейера AMD K8 часть1
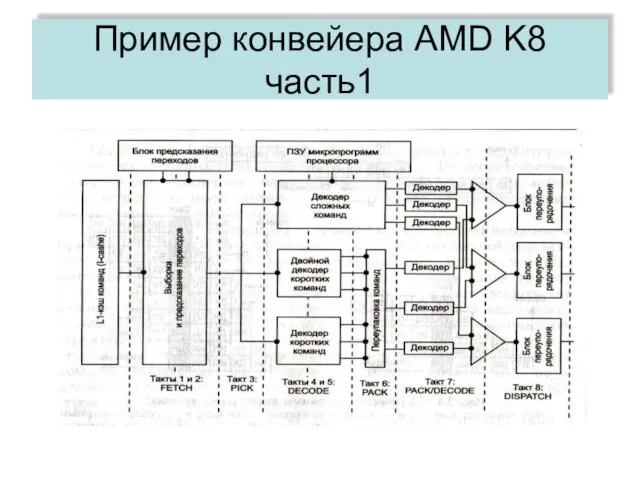
Пример конвейера AMD K8
часть 2
Пример конвейера AMD K8
часть 2
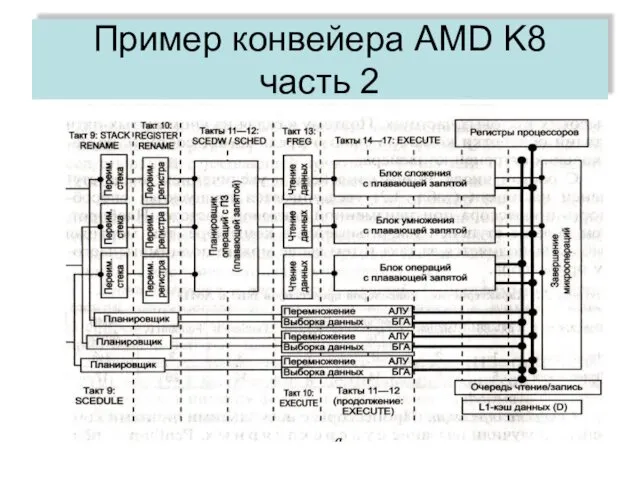
Проблемы суперскальных МП
Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП.
Наличие одного счетчика команд.
Проблемы суперскальных МП
Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП.
Наличие одного счетчика команд.

Мультитрейдовые микропроцессоры
Тред – вычислительный процесс обслуживаемый отдельным набором регистров.
Однотрейдовый микропроцессор – имеет один
Мультитрейдовые микропроцессоры
Тред – вычислительный процесс обслуживаемый отдельным набором регистров.
Однотрейдовый микропроцессор – имеет один

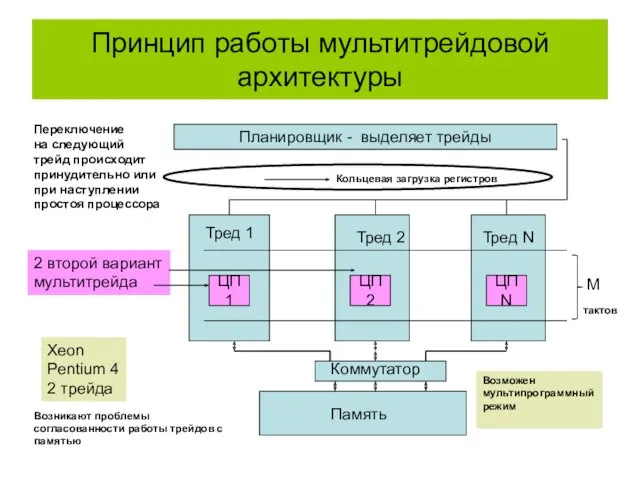
Принцип работы мультитрейдовой архитектуры
Тред 1
Тред 2
Тред N
Память
Коммутатор
M
тактов
Планировщик - выделяет трейды
Переключение
на следующий
трейд происходит
Принцип работы мультитрейдовой архитектуры
Тред 1
Тред 2
Тред N
Память
Коммутатор
M
тактов
Планировщик - выделяет трейды
Переключение
на следующий
трейд происходит
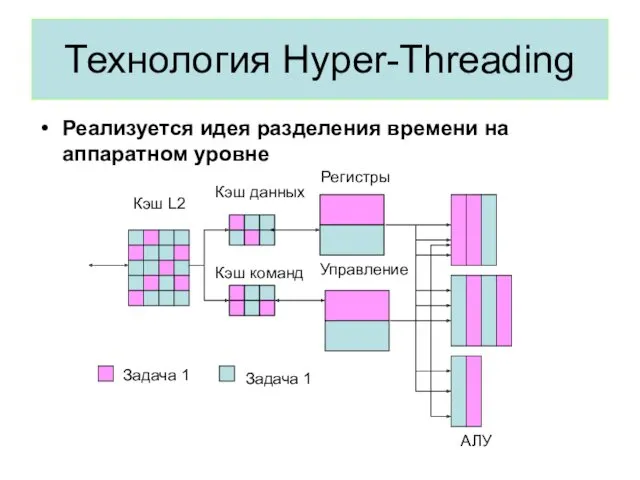
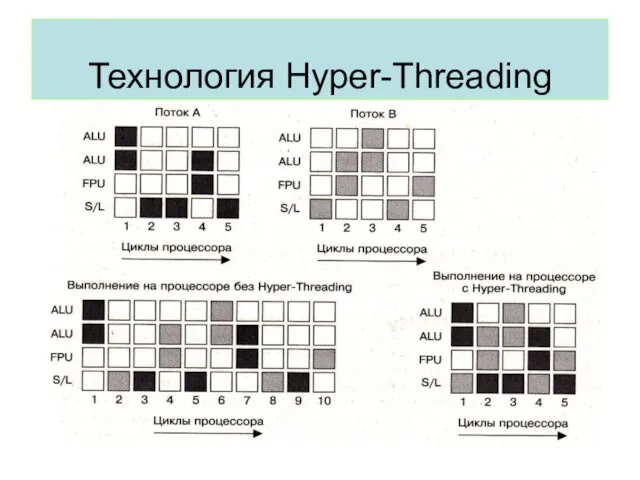
Технология Hyper-Threading
Реализуется идея разделения времени на аппаратном уровне
Задача 1
Задача 1
АЛУ
Регистры
Управление
Кэш данных
Кэш команд
Кэш L2
Технология Hyper-Threading
Реализуется идея разделения времени на аппаратном уровне
Задача 1
Задача 1
АЛУ
Регистры
Управление
Кэш данных
Кэш команд
Кэш L2
Технология Hyper-Threading
Технология Hyper-Threading
Itanium
Использование сложных команд
переменной длины, обрабатываемых
последовательно
Использование простых команд
одинаковой длины, сгруппированных в
связки VLIW
Itanium
Использование сложных команд
переменной длины, обрабатываемых
последовательно
Использование простых команд
одинаковой длины, сгруппированных в
связки VLIW

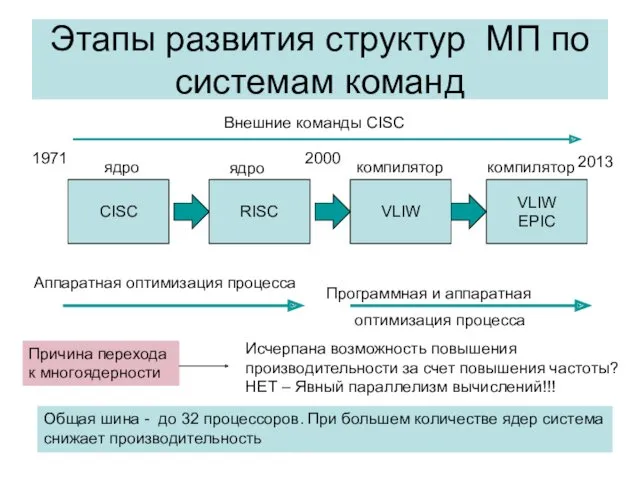
Этапы развития структур МП по системам команд
CISC
RISC
VLIW
VLIW
EPIC
Внешние команды CISC
ядро
компилятор
ядро
Аппаратная оптимизация процесса
Программная и аппаратная
оптимизация
Этапы развития структур МП по системам команд
CISC
RISC
VLIW
VLIW
EPIC
Внешние команды CISC
ядро
компилятор
ядро
Аппаратная оптимизация процесса
Программная и аппаратная
оптимизация
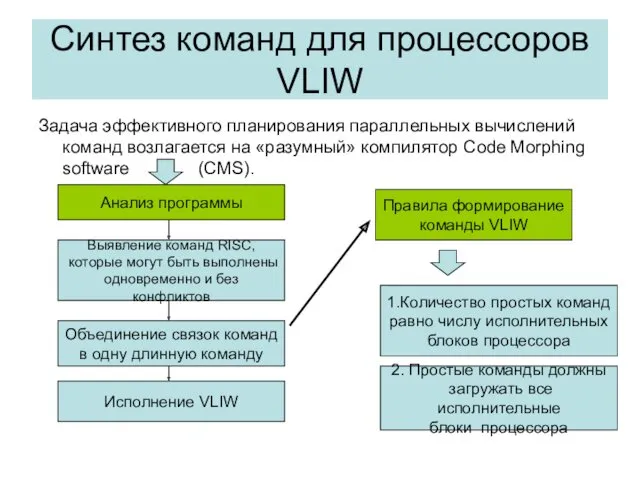
Синтез команд для процессоров VLIW
Задача эффективного планирования параллельных вычислений команд возлагается на «разумный»
Синтез команд для процессоров VLIW
Задача эффективного планирования параллельных вычислений команд возлагается на «разумный»
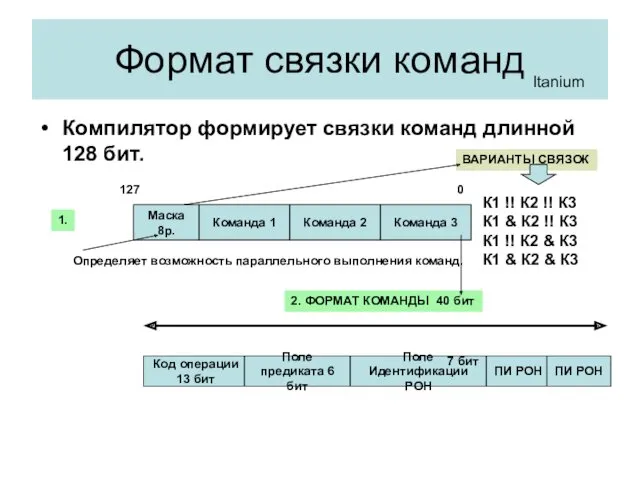
Формат связки команд
Компилятор формирует связки команд длинной 128 бит.
Itanium
Маска 8р.
Команда 1
Команда 2
Команда
Формат связки команд
Компилятор формирует связки команд длинной 128 бит.
Itanium
Маска 8р.
Команда 1
Команда 2
Команда
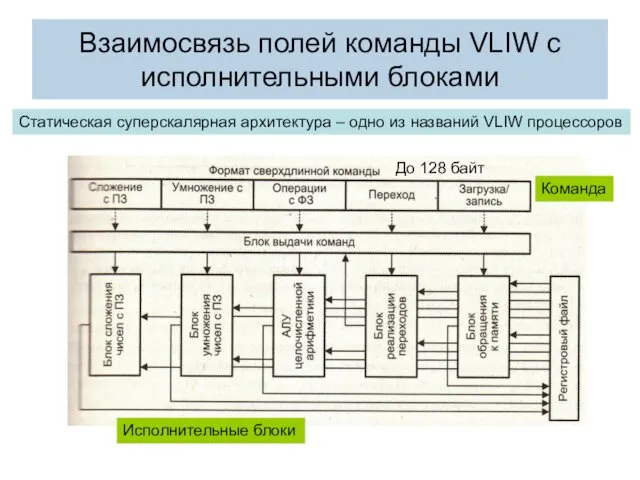
Взаимосвязь полей команды VLIW с исполнительными блоками
До 128 байт
Статическая суперскалярная архитектура – одно
Взаимосвязь полей команды VLIW с исполнительными блоками
До 128 байт
Статическая суперскалярная архитектура – одно
 Шаблоны для презентаций -школьные 1
Шаблоны для презентаций -школьные 1 Методы педагогического исследования. Работа с литературой
Методы педагогического исследования. Работа с литературой Ах, лето красное. Игра
Ах, лето красное. Игра Использование репрезентативной системы в воспитании и обучении
Использование репрезентативной системы в воспитании и обучении Вторая жизнь мусора
Вторая жизнь мусора Марк Леви
Марк Леви Культура Киевской Руси IX - XIII веков
Культура Киевской Руси IX - XIII веков Методы сведения балансов производственного пара. Причины возникновения дебалансов пара
Методы сведения балансов производственного пара. Причины возникновения дебалансов пара Электрические нагрузки. (Лекция 2)
Электрические нагрузки. (Лекция 2) Системы счисления
Системы счисления Індія
Індія 10. Австрійська та Рос. імперії
10. Австрійська та Рос. імперії Буддизм. Түсінік
Буддизм. Түсінік Население и страны Европы
Население и страны Европы Метод учебного проекта
Метод учебного проекта Қазіргі әлемдегі машина жасау өнеркәсібінің дамуы
Қазіргі әлемдегі машина жасау өнеркәсібінің дамуы Рыба охлажденная
Рыба охлажденная Имена существительные собственные и нарицательные
Имена существительные собственные и нарицательные Кремнийорганикалық қосылыстар
Кремнийорганикалық қосылыстар Улица полна неожиданностей
Улица полна неожиданностей Проектная деятельность учащихся на уроках и внеурочное время
Проектная деятельность учащихся на уроках и внеурочное время Семейство нелетающих морских птиц - пингвины
Семейство нелетающих морских птиц - пингвины Абрамов Федор Александрович (1920-1983)
Абрамов Федор Александрович (1920-1983) Ламинированные напольные покрытия
Ламинированные напольные покрытия Фронтовая поэзия Г.К. Суворова
Фронтовая поэзия Г.К. Суворова Защитники Приднестровья в 1990-е годы
Защитники Приднестровья в 1990-е годы Второе Пришествие
Второе Пришествие Цели урока
Цели урока