- Теоретико-графовые модели данных

Содержание
- 2. Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. В иерархической модели сегменты объединяются в ориентированный
- 3. На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели. Схема иерархической БД представляет собой
- 4. Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
- 5. Язык описания данных иерархической модели Языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования
- 6. Описание наборов данных, предназначенных для хранения БД: DATA SET D01 = . DEVICE = , [OVFLW
- 7. Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента. Для корневого
- 8. Для ранних иерархических моделей были определены только три типа данных: X — шестнадцатеричный, Р —упакованный десятичный,
- 9. Внешние модели Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный
- 10. Пример Указать модель, проверить наличие, полное описание индивидуальной модели.
- 11. Для индивидуальной модели нужна информация со склада
- 12. Язык манипулирования данными в иерархических базах данных Для доступа к базе данных у пользователя должна быть
- 13. Пример: Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
- 14. Получить перечень винчестеров со склада1, не менее 10 с объемом 10 Гб GET UNIQUE СКЛАД WHERE
- 15. Операторы поиска данных с возможностью модификации 1.Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой
- 16. Операторы модификации данных Удалить :DELETE Обновить : UPDATE Ввести новый экземпляр сегмента: INSERT Способ доступа, который
- 17. Сетевая модель данных Базовыми объектами модели являются: - элемент данных; - агрегат данных; - запись; набор
- 18. Пример Агрегат Адрес Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.
- 19. Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый граф, связывающий отношением «один-ко-многим»
- 20. Набор Два набора
- 21. Пример взаимосвязи экземпляров двух наборов
- 22. Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого формально определена вся система.
- 23. Язык описания данных в сетевой модели Описание базы данных – области размещения Описания записей – элементов
- 24. Каждый тип записи должен быть приписан к некоторой физической области размещения: WITHIN AREA После описания записи
- 25. Описание набора и порядка включения членов в него выглядит следующим образом: SET NAME IS : OWNER
- 26. Язык манипулирования данными в сетевой модели Все операции манипулирования данными в сетевой модели делятся на навигационные
- 27. Операторы манипулирования данными в сетевой модели
- 28. В рабочей области пользователя хранятся шаблоны записей, программные переменные и три типа указателей текущего состояния: текущая
- 29. 2. Последовательный просмотр записей данного типа: FIND DUPLICATE RECORD BY CALC KEY 3. Найти владельца текущего
- 31. Скачать презентацию

Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели
Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели

На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема
На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема
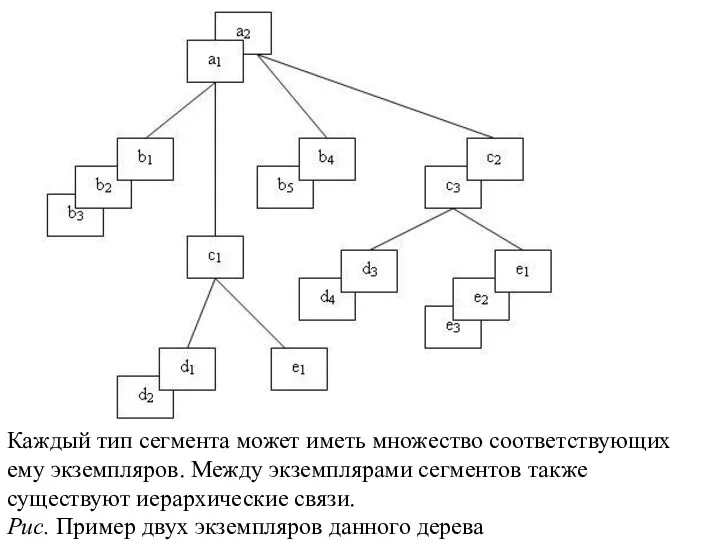
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами

Язык описания данных иерархической модели
Языковые средства описания данных (DDL, Data Definition
Язык описания данных иерархической модели
Языковые средства описания данных (DDL, Data Definition

Описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = <
Описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = <

Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним
Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним

Для ранних иерархических моделей были определены только три типа данных: X
Для ранних иерархических моделей были определены только три типа данных: X

Внешние модели
Внешняя модель представляет собой совокупность поддеревьев для физических баз данных,
Внешние модели
Внешняя модель представляет собой совокупность поддеревьев для физических баз данных,
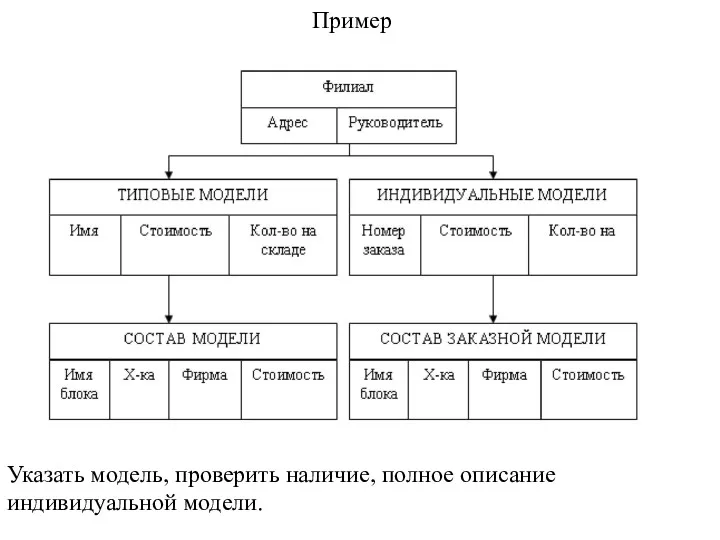
Пример
Указать модель, проверить наличие, полное описание индивидуальной модели.
Пример
Указать модель, проверить наличие, полное описание индивидуальной модели.
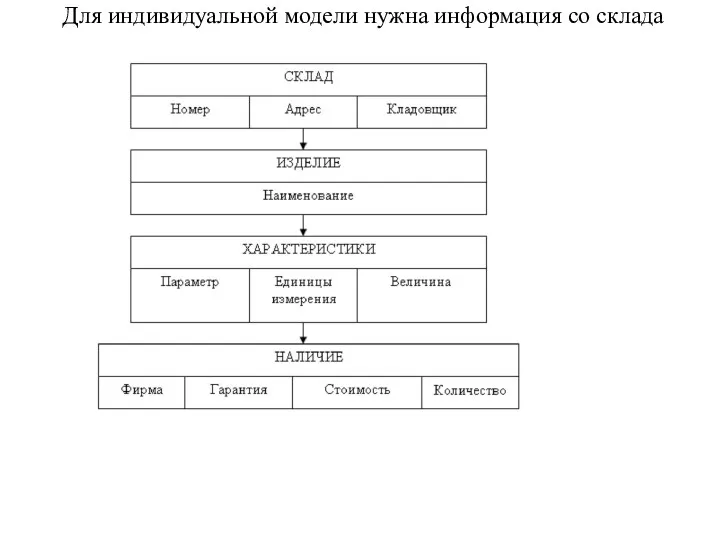
Для индивидуальной модели нужна информация со склада
Для индивидуальной модели нужна информация со склада

Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных
Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных

Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее
Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее

Получить перечень винчестеров со склада1, не менее 10 с объемом 10
Получить перечень винчестеров со склада1, не менее 10 с объемом 10

Операторы поиска данных с возможностью модификации
1.Найти и удержать единственный экземпляр сегмента.
Операторы поиска данных с возможностью модификации
1.Найти и удержать единственный экземпляр сегмента.

Операторы модификации данных
Удалить :DELETE
Обновить : UPDATE
Ввести новый экземпляр сегмента: INSERT
Операторы модификации данных
Удалить :DELETE
Обновить : UPDATE
Ввести новый экземпляр сегмента: INSERT

Сетевая модель данных
Базовыми объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
Сетевая модель данных
Базовыми объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;

Пример
Агрегат Адрес
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.
Пример
Агрегат Адрес
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.

Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется
Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется
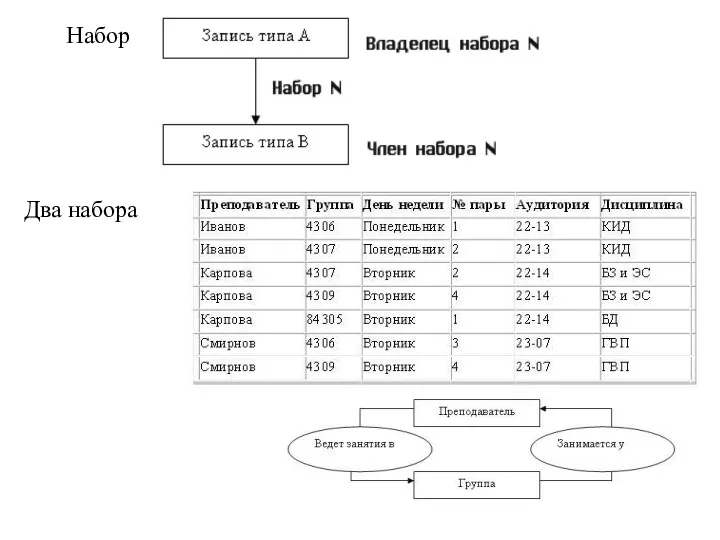
Набор
Два набора
Набор
Два набора
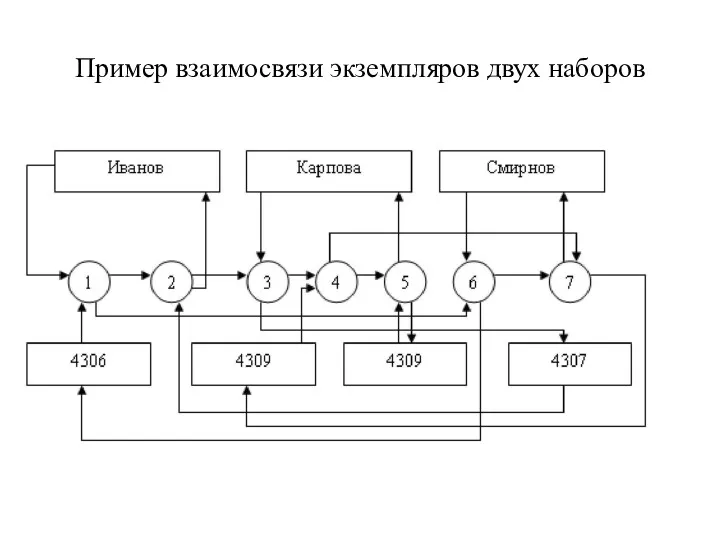
Пример взаимосвязи экземпляров двух наборов
Пример взаимосвязи экземпляров двух наборов

Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем
Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем

Язык описания данных в сетевой модели
Описание базы данных – области размещения
Описания
Язык описания данных в сетевой модели
Описание базы данных – области размещения
Описания

Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN
Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN

Описание набора и порядка включения членов в него выглядит следующим образом:
SET
Описание набора и порядка включения членов в него выглядит следующим образом:
SET

Язык манипулирования данными в сетевой модели
Все операции манипулирования данными в сетевой
Язык манипулирования данными в сетевой модели
Все операции манипулирования данными в сетевой
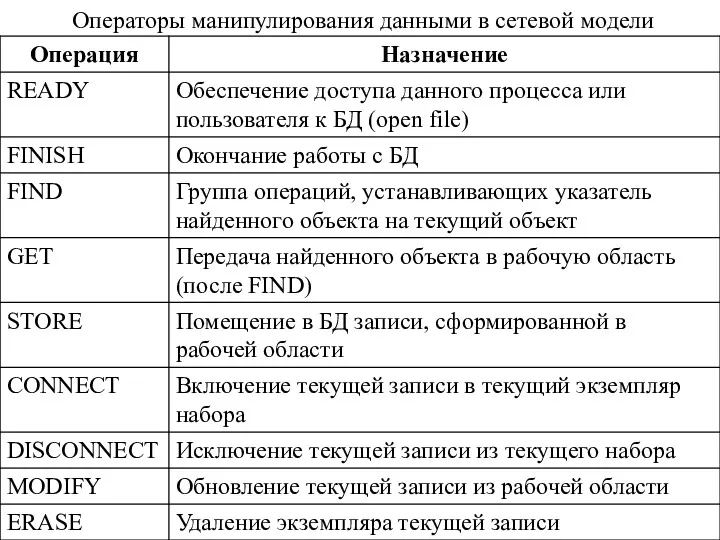
Операторы манипулирования данными в сетевой модели
Операторы манипулирования данными в сетевой модели

В рабочей области пользователя хранятся шаблоны записей, программные переменные и три
В рабочей области пользователя хранятся шаблоны записей, программные переменные и три

2. Последовательный просмотр записей данного типа:
FIND DUPLICATE <Имя записи> RECORD
2. Последовательный просмотр записей данного типа:
FIND DUPLICATE <Имя записи> RECORD
 De compras — покупки
De compras — покупки Презентация по МХК Жилища древних людей
Презентация по МХК Жилища древних людей История освоения Арктики
История освоения Арктики Презентации к праздникам.
Презентации к праздникам. Алгебра высказываний. Логические операции
Алгебра высказываний. Логические операции Вера
Вера Палеонтология. Схема соподчиненности основных систематических единиц. Царство животные простейшие (одноклеточные)
Палеонтология. Схема соподчиненности основных систематических единиц. Царство животные простейшие (одноклеточные) Презентация Готовность ребенка к школе
Презентация Готовность ребенка к школе 20231012_stat_futbolistom
20231012_stat_futbolistom Планирование работы в отделении организации медицинской помощи детям и подросткам в образовательных учреждениях
Планирование работы в отделении организации медицинской помощи детям и подросткам в образовательных учреждениях Типовые узлы комбинационного типа
Типовые узлы комбинационного типа Презентация к конспекту интегрированного занятия КОСМИЧЕСКОЕ ПУТЕШЕСТВИЕ
Презентация к конспекту интегрированного занятия КОСМИЧЕСКОЕ ПУТЕШЕСТВИЕ Правила оформления презентаций
Правила оформления презентаций Конспект бинарного урока Открытое письмо ветеранам
Конспект бинарного урока Открытое письмо ветеранам Промывочные агрегаты
Промывочные агрегаты Нормативно-правовые акты, гарантирующие право получения детям с ограниченными возможностями здоровья адекватного их возможностям образования
Нормативно-правовые акты, гарантирующие право получения детям с ограниченными возможностями здоровья адекватного их возможностям образования Требования безопасности при эксплуатации теплового оборудования на кухне
Требования безопасности при эксплуатации теплового оборудования на кухне Древнееврейское царство
Древнееврейское царство Презентация к уроку географии Иркутской области в 8 классе по теме Почвы
Презентация к уроку географии Иркутской области в 8 классе по теме Почвы органическая химия(Жиры)
органическая химия(Жиры) ПрезентацияОткуда в снежинках берётся грязь?
ПрезентацияОткуда в снежинках берётся грязь? Зинаида Гиппиус
Зинаида Гиппиус Назначение, боевые характеристики и устройство ручных осколочных и противотанковых гранат
Назначение, боевые характеристики и устройство ручных осколочных и противотанковых гранат кл Греческая культураl
кл Греческая культураl Акция Птицы Кубани. Операция День птиц
Акция Птицы Кубани. Операция День птиц Reasons to learning English
Reasons to learning English Презентация Визитная карточка воспитателя Храмовой Елены Витальевны
Презентация Визитная карточка воспитателя Храмовой Елены Витальевны Онлайн курс. Магия денег
Онлайн курс. Магия денег