- Введение в R

Содержание
- 2. Что такое R? В августе 1993 г. двое молодых новозеландских ученых Ross Ihaka и Robert Gentleman
- 3. Что такое R? Программное средство для Чтения и манипулирования данными Вычислений Проведения статистического анализа Отображения результатов
- 4. Применение, преимущества и недостатки R Коротко говоря, R применяется везде, где нужна работа с данными. Это
- 5. Применение, преимущества и недостатки R У R два главных преимущества: неимоверная гибкость свободный код. Гибкость позволяет
- 6. Применение, преимущества и недостатки R У R есть и немало недостатков. Самый главный из них —
- 7. Команды языка R В R все команды записываются в файл .Rhistory. Команды можно вызывать повторно, в
- 8. Объекты R По умолчанию R создает объекты в памяти и сохраняет их в единственный файл .Rdata.
- 9. Выход из R Команда q() Или просто закрыть окно. При этом будет предложено сохранить сессию.
- 10. Инсталляция пакетов R Инсталлировать пакет в R можно с помощью меню Packages/Install Packages. При этом будет
- 11. Язык R Базовый синтаксис
- 12. Ввод команд в R По умолчанию место для ввода команды в R обозначается знаком >: >
- 13. Ввод команд в R Последнее выражение можно получить с помощью внутреннего объекта .Last.value: > value >
- 14. Имена в R Имена в R могут быть любыми комбинациями букв, цифр и точек, но они
- 15. Использование пробелов R игнорирует лишние пробелы между именами объектов и операторами: > value > value [1]
- 16. Справка Вызов справки по функции, объекту или оператору осуществляется следующими командами: >?function >help(function) или вызовом меню
- 17. Типы данных В R есть четыре атомарных типа данных Numeric > value value [1] 605 Character
- 18. Атрибуты объекта Атрибуты важны при манипулировании объектами. У всех объектов есть два атрибута -- mode и
- 19. Пропущенные значения Во многих практических примерах некоторые элементы данных могут быть неизвестны, следовательно, им будет присвоено
- 20. Неопределенные и бесконечные значения Бесконечные и неопределенные значения (Inf, -Inf and NaN) могут быть протестированы с
- 21. Арифметические операторы
- 22. Операторы сравнения
- 23. Логические операторы
- 24. Распределения и симуляция В R есть множество распределений для симуляции данных, нахождения квантилей, вероятностей и функций
- 25. Распределения и симуляция В R каждое в имени каждого распределения используется префикс, обозначающий, нужно ли использовать
- 26. Пример norm.vals1 norm.vals2 norm.vals3 norm.vals4 # set up plotting region par(mfrow=c(2,2)) hist(norm.vals1,main="10 RVs") hist(norm.vals2,main="100 RVs") hist(norm.vals3,main="1000
- 27. Гистограммы
- 28. Интерпретация результатов С ростом размера выборки форма распределения становится больше похожа на нормальное распределение. Про объект
- 29. Центральная предельная теорема При приближении размера n выборки, взятой из популяции с математическим ожиданием μ и
- 30. Объекты R
- 31. Объекты данных в R Четыре наиболее часто используемых типа объектов данных в R – это векторы,
- 32. Создание векторов Функция c Самый простой способ создать вектор – конкатенация с помощью функции c, связывающей
- 33. Создание векторов Функции rep и seq Функция rep реплицирует элементы векторов. Например, > value > value
- 34. Функции, которые дают результат такой же длины
- 35. Функции, результатом которых является число
- 36. Создание матриц Функции dim и matrix Функция dim может использоваться для конвертации вектора в матрицу >
- 37. Создание списков Списки создаются с помощью функции list. Могут включать элементы различных видов, длины и размера
- 38. Доступ к элементам списка Через имя или по номеру позиции, на которой находится элемент, с использованием
- 39. Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия) Данные были получены с погодного буя
- 40. Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия) Примера программы на R для восстановления
- 41. Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова Пример программы на R для прогноза выработки
- 42. Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова Понимание скрытой периодичности и тенденций временного ряда
- 44. Скачать презентацию

Что такое R?
В августе 1993 г. двое молодых новозеландских ученых Ross
Что такое R?
В августе 1993 г. двое молодых новозеландских ученых Ross

Что такое R?
Программное средство для
Чтения и манипулирования данными
Вычислений
Проведения статистического анализа
Отображения
Что такое R?
Программное средство для
Чтения и манипулирования данными
Вычислений
Проведения статистического анализа
Отображения

Применение, преимущества и недостатки R
Коротко говоря, R применяется везде, где нужна
Применение, преимущества и недостатки R
Коротко говоря, R применяется везде, где нужна

Применение, преимущества и недостатки R
У R два главных преимущества:
неимоверная гибкость
Применение, преимущества и недостатки R
У R два главных преимущества:
неимоверная гибкость

Применение, преимущества и недостатки R
У R есть и немало недостатков.
Самый
Применение, преимущества и недостатки R
У R есть и немало недостатков.
Самый

Команды языка R
В R все команды записываются в файл .Rhistory. Команды
Команды языка R
В R все команды записываются в файл .Rhistory. Команды

Объекты R
По умолчанию R создает объекты в памяти и сохраняет их
Объекты R
По умолчанию R создает объекты в памяти и сохраняет их

Выход из R
Команда q()
Или просто закрыть окно. При этом будет предложено
Выход из R
Команда q()
Или просто закрыть окно. При этом будет предложено
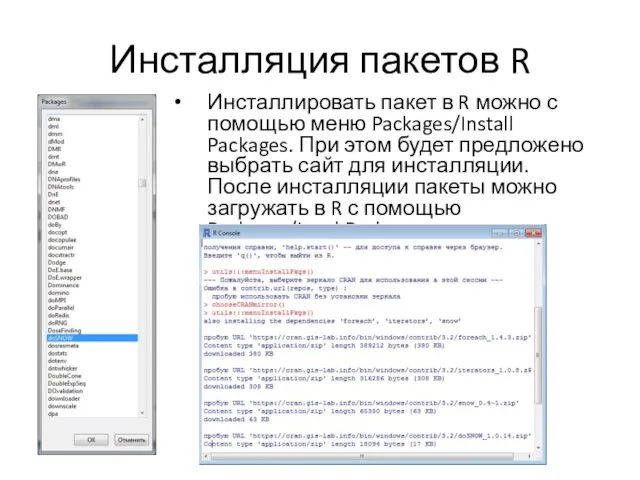
Инсталляция пакетов R
Инсталлировать пакет в R можно с помощью меню Packages/Install
Инсталляция пакетов R
Инсталлировать пакет в R можно с помощью меню Packages/Install

Язык R
Базовый синтаксис
Язык R
Базовый синтаксис

Ввод команд в R
По умолчанию место для ввода команды в R
Ввод команд в R
По умолчанию место для ввода команды в R

Ввод команд в R
Последнее выражение можно получить с помощью внутреннего объекта
Ввод команд в R
Последнее выражение можно получить с помощью внутреннего объекта

Имена в R
Имена в R могут быть любыми комбинациями букв, цифр
Имена в R
Имена в R могут быть любыми комбинациями букв, цифр

Использование пробелов
R игнорирует лишние пробелы между именами объектов и операторами:
> value
Использование пробелов
R игнорирует лишние пробелы между именами объектов и операторами:
> value

Справка
Вызов справки по функции, объекту или оператору осуществляется следующими командами:
>?function
>help(function)
или вызовом
Справка
Вызов справки по функции, объекту или оператору осуществляется следующими командами:
>?function
>help(function)
или вызовом

Типы данных
В R есть четыре атомарных типа данных
Numeric
> value <- 605
>
Типы данных
В R есть четыре атомарных типа данных
Numeric
> value <- 605
>

Атрибуты объекта
Атрибуты важны при манипулировании объектами. У всех объектов есть два
Атрибуты объекта
Атрибуты важны при манипулировании объектами. У всех объектов есть два

Пропущенные значения
Во многих практических примерах некоторые элементы данных могут быть неизвестны,
Пропущенные значения
Во многих практических примерах некоторые элементы данных могут быть неизвестны,

Неопределенные и бесконечные значения
Бесконечные и неопределенные значения (Inf, -Inf and NaN)
Неопределенные и бесконечные значения
Бесконечные и неопределенные значения (Inf, -Inf and NaN)
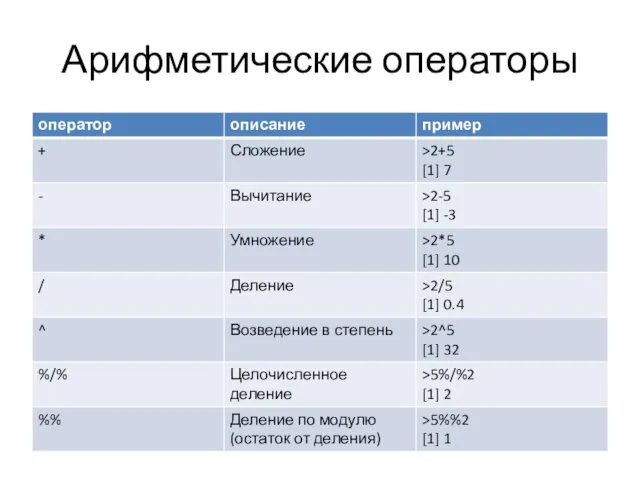
Арифметические операторы
Арифметические операторы
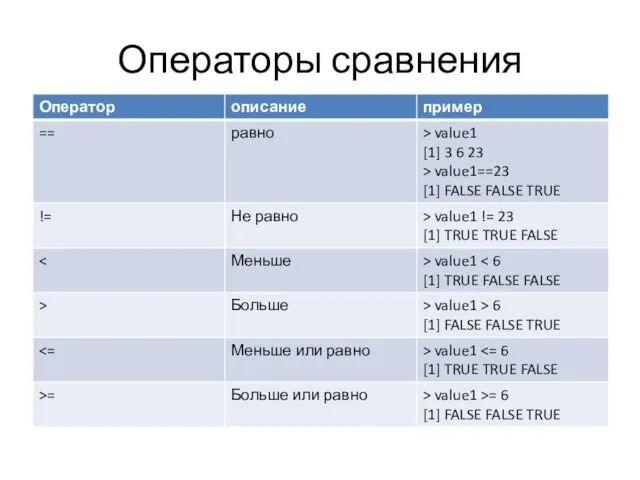
Операторы сравнения
Операторы сравнения

Логические операторы
Логические операторы

Распределения и симуляция
В R есть множество распределений для симуляции данных, нахождения
Распределения и симуляция
В R есть множество распределений для симуляции данных, нахождения

Распределения и симуляция
В R каждое в имени каждого распределения используется префикс,
Распределения и симуляция
В R каждое в имени каждого распределения используется префикс,

Пример
norm.vals1 <- rnorm(n=10)
norm.vals2 <- rnorm(n=100)
norm.vals3 <- rnorm(n=1000)
norm.vals4 <- rnorm(n=10000)
# set up
Пример
norm.vals1 <- rnorm(n=10)
norm.vals2 <- rnorm(n=100)
norm.vals3 <- rnorm(n=1000)
norm.vals4 <- rnorm(n=10000)
# set up
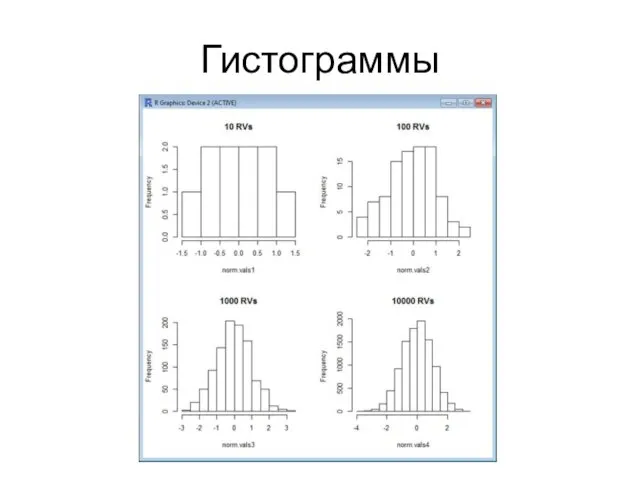
Гистограммы
Гистограммы

Интерпретация результатов
С ростом размера выборки форма распределения становится больше похожа на
Интерпретация результатов
С ростом размера выборки форма распределения становится больше похожа на

Центральная предельная теорема
При приближении размера n выборки, взятой из популяции с
Центральная предельная теорема
При приближении размера n выборки, взятой из популяции с

Объекты R
Объекты R

Объекты данных в R
Четыре наиболее часто используемых типа объектов данных в
Объекты данных в R
Четыре наиболее часто используемых типа объектов данных в

Создание векторов
Функция c
Самый простой способ создать вектор – конкатенация с помощью
Создание векторов
Функция c
Самый простой способ создать вектор – конкатенация с помощью

Создание векторов
Функции rep и seq
Функция rep реплицирует элементы векторов. Например,
> value
Создание векторов
Функции rep и seq
Функция rep реплицирует элементы векторов. Например,
> value

Функции, которые дают результат такой же длины
Функции, которые дают результат такой же длины

Функции, результатом которых является число
Функции, результатом которых является число

Создание матриц
Функции dim и matrix
Функция dim может использоваться для конвертации вектора
Создание матриц
Функции dim и matrix
Функция dim может использоваться для конвертации вектора

Создание списков
Списки создаются с помощью функции list. Могут включать элементы различных
Создание списков
Списки создаются с помощью функции list. Могут включать элементы различных

Доступ к элементам списка
Через имя или по номеру позиции, на которой
Доступ к элементам списка
Через имя или по номеру позиции, на которой

Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия)
Данные были
Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия)
Данные были

Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия)
Примера программы
Примеры – Прогноз скорости ветра для ветропарка в Валенсии (Ирландия)
Примера программы

Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова
Пример программы на
Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова
Пример программы на
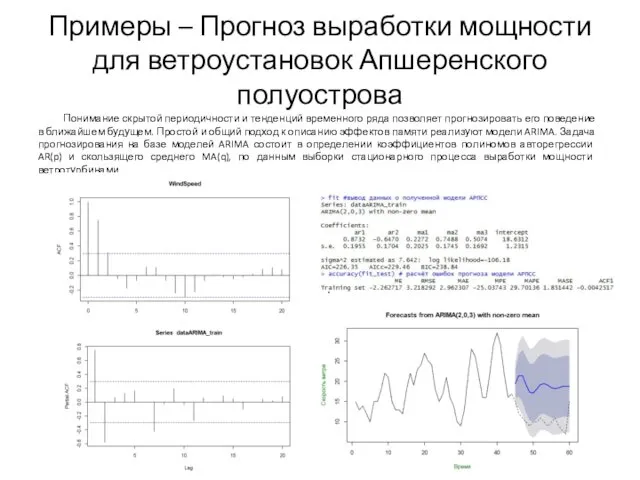
Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова
Понимание скрытой периодичности
Примеры – Прогноз выработки мощности для ветроустановок Апшеренского полуострова
Понимание скрытой периодичности
 Физиологические механизмы развития тренированности
Физиологические механизмы развития тренированности Реформация – новое отношение к миру, обновление христианства
Реформация – новое отношение к миру, обновление христианства Phonetic drill remember!
Phonetic drill remember! Использование невербальных средств в речевом общении
Использование невербальных средств в речевом общении Методические рекомендации деятельности педагога дополнительного образования в межаттестационный период
Методические рекомендации деятельности педагога дополнительного образования в межаттестационный период Урок по ПДД. 4класс
Урок по ПДД. 4класс Сколько звуков в слове
Сколько звуков в слове Компьютерная графика
Компьютерная графика Compare photos
Compare photos Занятие учебной практики. Дверные петли Врезка дверных петель
Занятие учебной практики. Дверные петли Врезка дверных петель Проценты в виде десятичной дроби
Проценты в виде десятичной дроби Weather - two word adjectives, collocations; causative verbs
Weather - two word adjectives, collocations; causative verbs Биохимия крови
Биохимия крови Строение и функции головного мозга
Строение и функции головного мозга Презентация (1)
Презентация (1) Упрощение выражений
Упрощение выражений О Fit service 2021. Федереальная международная сеть автосервисов
О Fit service 2021. Федереальная международная сеть автосервисов Газетница для хранения газет и журналов
Газетница для хранения газет и журналов Презентация Новогоднее оформление группы в детском саду
Презентация Новогоднее оформление группы в детском саду Проект прогулочный площадки
Проект прогулочный площадки Биография М.Е. Салтыкова-Щедрина
Биография М.Е. Салтыкова-Щедрина Влияние скорости охлаждения при затвердевании на структуру сплавов
Влияние скорости охлаждения при затвердевании на структуру сплавов История создания романа Война и мир. Особенности жанра
История создания романа Война и мир. Особенности жанра Наша Галактика
Наша Галактика день семьи
день семьи История искусств в системе современного гуманитарного знания
История искусств в системе современного гуманитарного знания Планирование и организация рекламной компании ООО ТК-ПРОФИ
Планирование и организация рекламной компании ООО ТК-ПРОФИ Участие медицинской сестры в организации ухода за больными с пневмонией
Участие медицинской сестры в организации ухода за больными с пневмонией