- Множественное выравнивание. Профили. Домены. Лекция 3

Содержание
- 2. BLAST не может решить две проблемы [1] При использовании человеческого бета-глобина в виде запроса для белков
- 3. Position specific iterated BLAST: PSI-BLAST Цель PSI-BLAST - посмотреть глубже в базу данных в поисках совпадений
- 4. Поиск в PSI-BLAST выполняется в пять шагов [1] Выберите последовательность и запустите поиск в базе данных
- 5. Проверка вывода BLASTP для выявления эмпирических "правил" в отношении изменчивости аминокислот в каждой позиции 02.10.2019 Кафедра
- 6. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ A R N D C Q E G H I L
- 7. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ A R N D C Q E G H I L
- 8. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Поиск в PSI-BLAST выполняется в пять шагов [1] Выберите последовательность и
- 9. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 10. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Поиск в PSI-BLAST выполняется в пять шагов [1] Выберите последовательность и
- 11. Результаты поиска PSI-BLAST 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Кол. посл. Итерация Кол. посл. > threshold 1
- 12. Поиск PSI-BLAST: RBP4 человека по RefSeq БД, итерация 1 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 13. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Поиск PSI-BLAST: RBP4 человека по RefSeq БД, итерация 2
- 14. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Поиск PSI-BLAST: RBP4 человека по RefSeq БД, итерация 3
- 15. Парное выравнивание RBP4 с ApoD, PSI-BLAST итерация 1, E value 3e-07 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 16. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Парное выравнивание RBP4 с ApoD, PSI-BLAST итерация 2, E value 1e-42!!!
- 17. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Парное выравнивание RBP4 с ApoD, PSI-BLAST итерация 3, E value 6e-34
- 18. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Вселенная липокалинов (каждая точка - белок) retinol-binding protein odorant-binding protein apolipoprotein
- 19. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Скоринг матрицы позволяют сосредоточиться на большой (или маленькой) картине retinol-binding protein
- 20. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ retinol-binding protein retinol-binding protein PAM250 PAM30 Blosum45 Blosum80 Скоринг матрицы позволяют
- 21. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ retinol-binding protein retinol-binding protein PSI-BLAST создает скоринг матрицы более мощные чем
- 22. PSI-BLAST: оценка эффективности PSI-BLAST полезeн для обнаружения слабых, но биологически значимых связей между белками ( Основным
- 23. Искажение определяется как присутствие, по меньшей мере, одного ложно-положительного выравнивания со значением E 02.10.2019 Кафедра биоинформатики
- 24. Множественное выравнивание последовательностей Эволюционный анализ определение гомологии филогенетические построения эволюционные тестовые модели Функциональный анализ определить консервативные
- 25. Набор из трех или более белковых (или нуклеотидных) последовательностей, которые частично или полностью выровнены Гомологичные остатки
- 26. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Множественное выравнивание последовательностей N. Provart & D. Guttman. Bioinformatic Methods I.
- 27. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ HomoloGene включает группы эукариотических белков, парные и множественные выравнивания, и много
- 28. Пример. Шаг 1: в NCBI выберете меню HomoloGene и введите caveolin в поле поиска 02.10.2019 Кафедра
- 29. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Пример. Шаг 2: проверить результаты. Возьмем первый набор кавеолинов. Изменить Display
- 30. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Пример. Шаг 3: проверим множественное выравнивание. Восемь белков хорошо выравнены, хотя
- 31. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Другое множественное выравнивание, Rac: Эта вставка может быть альтернативным сплайсингом
- 32. Пример: 5 выравниваний 5 глобинов Давайте посмотрим на множественное выравнивание последовательности (MSA) пяти глобинов белков. Мы
- 33. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ ClustalW Обратите внимание как участок консервативного гистидина (▼) изменяется в зависимости
- 34. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Praline
- 35. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Probcons
- 36. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ TCoffee
- 37. Не обязательно, что существует одно "правильное" выравнивание семейства белков Эволюционируют белковые последовательности … Соответствующие трехмерные структуры
- 38. некоторые выровненные остатки, такие как цистеина, образующие дисульфидные мостики, могут быть высоко консервативны может быть консервативные
- 39. Домены 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Домен белка — элемент третичной структуры белка, представляющий собой достаточно
- 40. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Лейциновая молния Связка из 4 спиралей Глобиновая укладка α-ДОМЕНЫ
- 41. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ β-ДОМЕНЫ Up and down barrel Баррел на основе греческих ключей Jelly
- 42. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ α/β-ДОМЕНЫ Подкова α/β-пропеллер Укладка Россмана TIM-укладка Метилмалонил-коА-мутаза
- 43. Более чувствительно, чем попарное выравнивания для выявления гомологов Результат BLAST может принять форму множественного выравнивания, и
- 44. Методы множественного выравнивания Точные методы Прогрессивный (ClustalW) Итеративный (MUSCLE) Согласованный (ProbCons) Основанный на структуре (Expresso) 02.10.2019
- 45. Прогрессивный метод (ClustalW) Прогрессивные методы: используют направляющей дерево (связанное с филогенетическим деревом), чтобы определить, как объединить
- 46. Шаг 1. Построение попарных выравниваний 02.10.2019 Кафедра биоинформатики МБФ РНИМУ best Score (% идентичности) Для n
- 47. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ 5 близко родственных глобинов Конвертация баллов сходства в баллы расстояния
- 48. Множественное выравнивание для профилей скрытых Марковских моделей (HMMs - Hidden Markov models) Скрытые Марковские модели (HMMs)
- 49. Простая Марковская модель 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Дождь = собака может не захотеть выйти на
- 50. Простая скрытая Марковская модель 02.10.2019 Кафедра биоинформатики МБФ РНИМУ Наблюдение: YNNNYYNNNYN (Y=идет, N=не идет) Что лежит
- 51. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 52. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 53. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 54. Мотивы Мотив в молекулярной биологии — это характерная последовательность нуклеотидов (в ДНК, РНК) или аминокислот (в
- 55. Регулярные выражения Алфавит — совокупность отдельных символов, обозначающих определенную аминокислоту или набор аминокислот. Строка из символов
- 56. PROSITE – база данных для поиска мотивов в белках (prosite.expasy.org) PROSITE дополняет список выражений, описанных выше:
- 57. Мотив домена цинковый палец: C-х (2,4)-C-х (3)-[LIVMFYWC]- х(8)-H-x(3,5)-H 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 58. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ
- 59. 02.10.2019 Кафедра биоинформатики МБФ РНИМУ PFAM (protein family) БД – наиболее известный ресурс по анализу белковых
- 61. Скачать презентацию
 Биохимия витаминов. Классификация витаминов. Жирорастворимые витамины
Биохимия витаминов. Классификация витаминов. Жирорастворимые витамины Генетически закрепленные формы поведения и функциональные комплексы индивидуально приобретенного поведения
Генетически закрепленные формы поведения и функциональные комплексы индивидуально приобретенного поведения Функциональная анатомия мышц конечностей
Функциональная анатомия мышц конечностей лекция 2. Направления биотехнологии
лекция 2. Направления биотехнологии Шляпочные грибы. Загадки
Шляпочные грибы. Загадки Майстерність маскування
Майстерність маскування Нервная и гуморальная регуляция функций организма
Нервная и гуморальная регуляция функций организма Methods in behavioral genetics
Methods in behavioral genetics бактерии Диск
бактерии Диск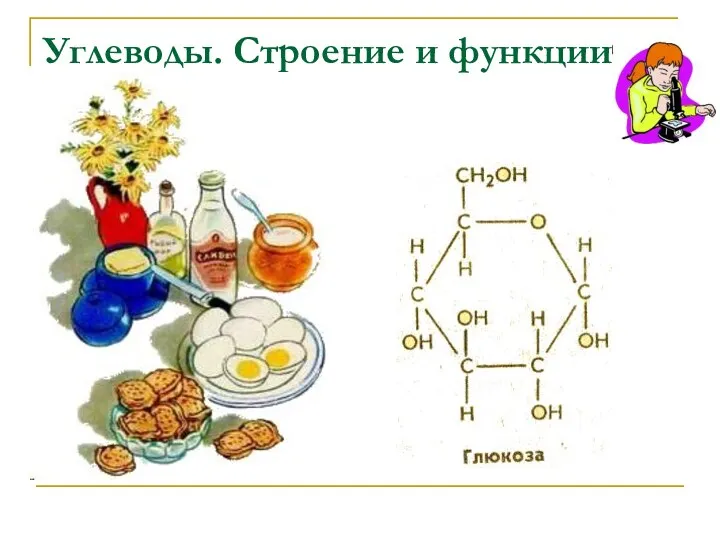 Углеводы: строение и функции.
Углеводы: строение и функции. Тайны коры головного мозга
Тайны коры головного мозга Натрий. Роль натрия в организме
Натрий. Роль натрия в организме Витамины и их роль в организме человека
Витамины и их роль в организме человека Урок-практикум по решению задач по генетике
Урок-практикум по решению задач по генетике Птицы. Внешнее строение птиц. Систематические группы птиц
Птицы. Внешнее строение птиц. Систематические группы птиц Приспособления организмов к жизни в природе
Приспособления организмов к жизни в природе Артериальная и венозная системы
Артериальная и венозная системы Человек как результат биологической и социокультурной эволюции
Человек как результат биологической и социокультурной эволюции Обмен веществ и энергии. Анаболизм
Обмен веществ и энергии. Анаболизм Птицы Крыма. Игра-викторина
Птицы Крыма. Игра-викторина Бионика органов чувств человека (9 класс)
Бионика органов чувств человека (9 класс) Бактерии
Бактерии презентация по теме:строение эукариотической клетки
презентация по теме:строение эукариотической клетки Влияние спиртов на организм человека
Влияние спиртов на организм человека Нейрон және оның құрылымы
Нейрон және оның құрылымы Дикие и домашние животные
Дикие и домашние животные Ученые - биологи
Ученые - биологи Лес – наше богатство
Лес – наше богатство