- Адресация CIDR. Основы маршрутизации. Методы получения правил маршрутизации

Содержание
- 2. Сетевой уровень Рис. 5-19.4. Нерациональное использование пространства IP адресов Очень часто владельцы сетей класса С расходуют
- 3. Адресация и технология CIDR В связи с быстрым ростом Internet появились серьезные проблемы с нехваткой адресов
- 4. Адресация и технология CIDR Бесклассовая адресация (ClasslessInter-DomainRouting, CIDR) — метод IP-адресации, позволяет гибко управлять пространством IP-адресов,
- 5. Адресация и технология CIDR Рис. 5-19.1 Распределение адресов на основе CIDR
- 6. Адресация и технология CIDR Пусть в распоряжении некоторого поставщика услуг имеется непрерывное пространство IP-адресов в количестве
- 7. Основы и схемы IP-маршрутизации Рассмотрим. механизм IP-маршрутизации на примере составной сети, представленной на рис. 5-19.2 этой
- 8. Основы и схемы IP-маршрутизации В сложных составных сетях почти всегда существуют несколько альтернативных маршрутов для передачи
- 9. Рис.5-19.2. Принципы маршрутизации в составной сети
- 10. Упрошенная таблица маршрутизации Используя условные обозначения для сетевых адресов маршрутизаторов и номеров сетей в том виде,
- 11. Таблица 5-19.1. Таблица маршрутизации маршрутизатора 4
- 12. Основы и схемы IP-маршрутизации Перед тем как передать пакет следующему маршрутизатору, текущий маршрутизатор должен определить, на
- 13. Основы и схемы IP-маршрутизации Чаще всего в качестве адреса назначения в таблице указывается не весь IP-адрес,
- 14. Сетевой уровень Поскольку пакет может быть адресован в любую сеть составной сети, может показаться, что каждая
- 15. Таблицы маршрутизации конечных узлов Задачу маршрутизации решают не только промежуточные (маршрутизаторы), но и конечные узлы —
- 16. Таблица 5-19.2. Таблица маршрутизации конечного узла В
- 17. Сетевой уровень Конечные узлы в еще большей степени, чем маршрутизаторы, пользуются приемом маршрутизации по умолчанию. Хотя
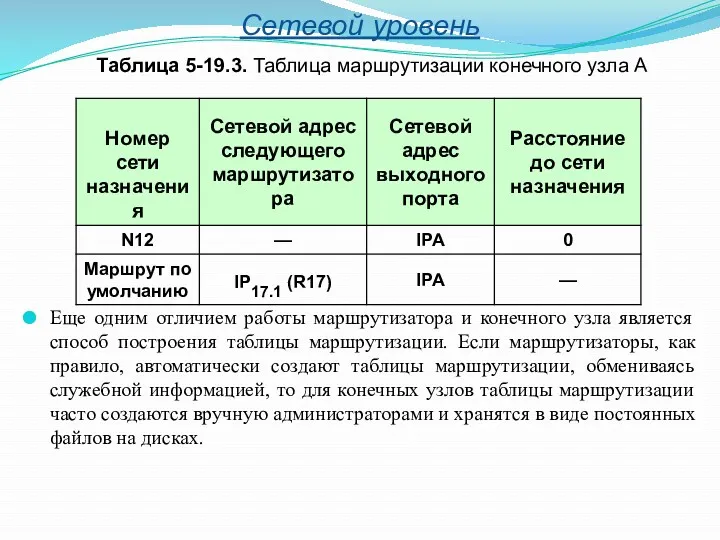
- 18. Сетевой уровень Еще одним отличием работы маршрутизатора и конечного узла является способ построения таблицы маршрутизации. Если
- 19. Просмотр таблиц маршрутизации без масок Ниже приведен алгоритм просмотра таблицы маршрутизации протоколом IP, установленным на маршрутизаторе.
- 20. Просмотр таблиц маршрутизации с учетом масок Алгоритм просмотра таблиц маршрутизации, содержащих маски, имеет много общего с
- 21. Просмотр таблиц маршрутизации с учетом масок 4. После просмотра всей таблицы маршрутизатор выполняет одно их трех
- 22. Сетевой уровень Проиллюстрируем, как маршрутизатор R2 (см. рис. 5-19.7) использует вышеописанный алгоритм для работы со своей
- 23. Рис.5-19.7. Маршрутизация с использованием масок переменной длины
- 24. Таблица 5-19.5. Таблица маршрутизатора R2 в сети с масками постоянной длины
- 25. Сетевой уровень Использование масок переменной длины Во многих случаях более эффективным является разбиение сети на подсети
- 26. Таблица 5-19.6. Таблица маршрутизатора R2 в сети с масками переменной длины
- 27. Сетевой уровень ПРИМЕЧАНИЕ - Глобальным связям между маршрутизаторами, соединенными по двухточечной схеме, не обязательно давать IP-адреса.
- 28. Сетевой уровень Пусть поступивший на R2 пакет имеет адрес назначения 129.44.192.15. Поскольку специфические маршруты в таблице
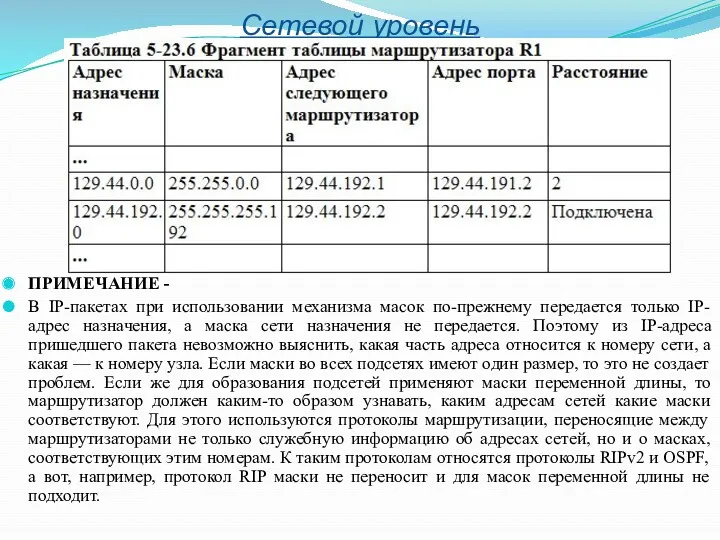
- 29. Сетевой уровень ПРИМЕЧАНИЕ - В IP-пакетах при использовании механизма масок по-прежнему передается только IP-адрес назначения, а
- 31. Скачать презентацию

Сетевой уровень
Рис. 5-19.4. Нерациональное использование пространства IP адресов
Очень часто владельцы
Сетевой уровень
Рис. 5-19.4. Нерациональное использование пространства IP адресов
Очень часто владельцы

Адресация и технология CIDR
В связи с быстрым ростом Internet появились серьезные
Адресация и технология CIDR
В связи с быстрым ростом Internet появились серьезные

Адресация и технология CIDR
Бесклассовая адресация (ClasslessInter-DomainRouting, CIDR) — метод IP-адресации, позволяет гибко
Адресация и технология CIDR
Бесклассовая адресация (ClasslessInter-DomainRouting, CIDR) — метод IP-адресации, позволяет гибко
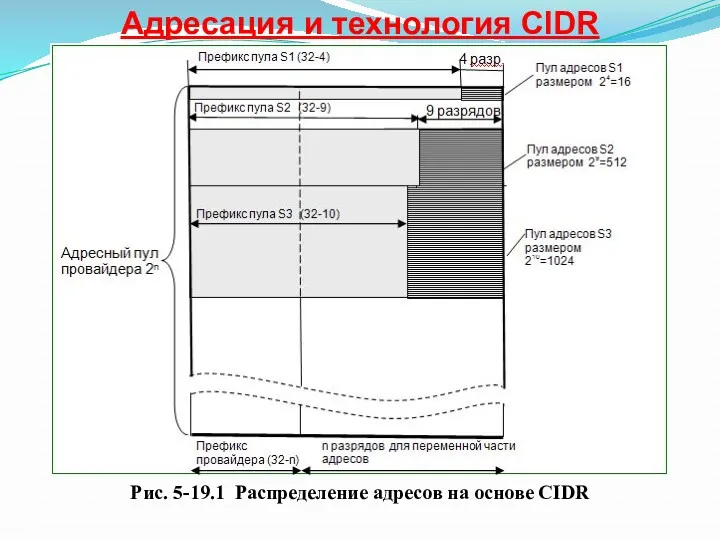
Адресация и технология CIDR
Рис. 5-19.1 Распределение адресов на основе CIDR
Адресация и технология CIDR
Рис. 5-19.1 Распределение адресов на основе CIDR

Адресация и технология CIDR
Пусть в распоряжении некоторого поставщика услуг имеется непрерывное
Адресация и технология CIDR
Пусть в распоряжении некоторого поставщика услуг имеется непрерывное

Основы и схемы IP-маршрутизации
Рассмотрим. механизм IP-маршрутизации на примере составной сети, представленной
Основы и схемы IP-маршрутизации
Рассмотрим. механизм IP-маршрутизации на примере составной сети, представленной

Основы и схемы IP-маршрутизации
В сложных составных сетях почти всегда существуют несколько
Основы и схемы IP-маршрутизации
В сложных составных сетях почти всегда существуют несколько
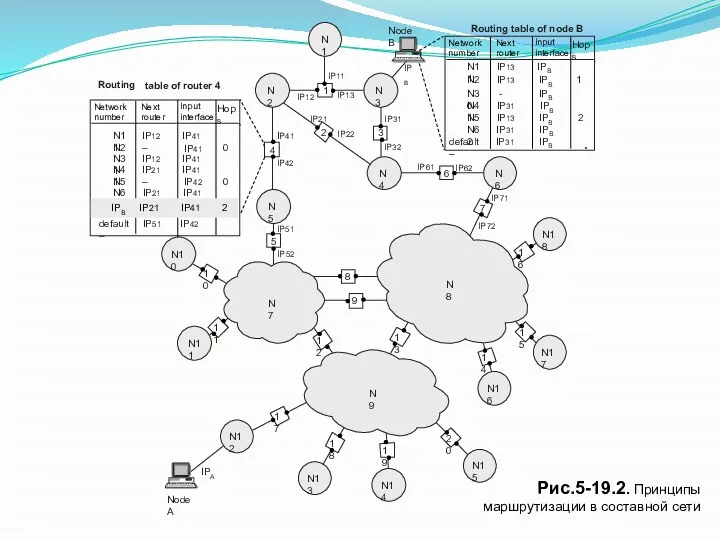
Рис.5-19.2. Принципы маршрутизации в составной сети
Рис.5-19.2. Принципы маршрутизации в составной сети

Упрошенная таблица маршрутизации
Используя условные обозначения для сетевых адресов маршрутизаторов и номеров
Упрошенная таблица маршрутизации
Используя условные обозначения для сетевых адресов маршрутизаторов и номеров
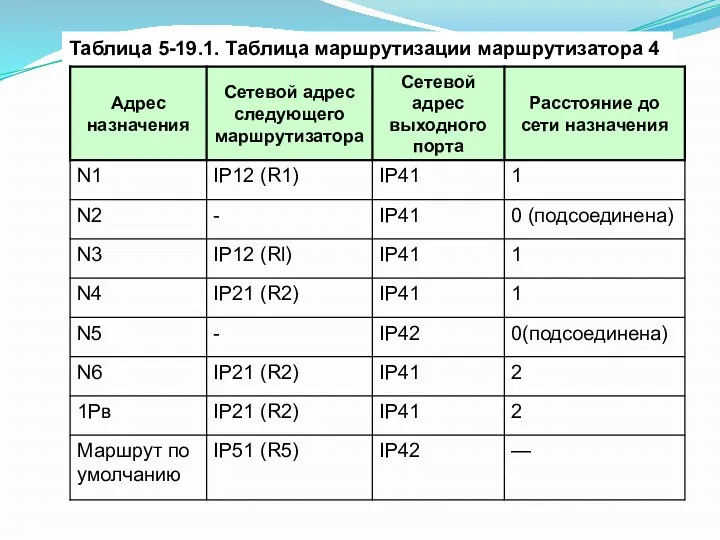
Таблица 5-19.1. Таблица маршрутизации маршрутизатора 4
Таблица 5-19.1. Таблица маршрутизации маршрутизатора 4

Основы и схемы IP-маршрутизации
Перед тем как передать пакет следующему маршрутизатору, текущий
Основы и схемы IP-маршрутизации
Перед тем как передать пакет следующему маршрутизатору, текущий

Основы и схемы IP-маршрутизации
Чаще всего в качестве адреса назначения в таблице
Основы и схемы IP-маршрутизации
Чаще всего в качестве адреса назначения в таблице

Сетевой уровень
Поскольку пакет может быть адресован в любую сеть составной сети,
Сетевой уровень
Поскольку пакет может быть адресован в любую сеть составной сети,

Таблицы маршрутизации конечных узлов
Задачу маршрутизации решают не только промежуточные (маршрутизаторы), но
Таблицы маршрутизации конечных узлов
Задачу маршрутизации решают не только промежуточные (маршрутизаторы), но
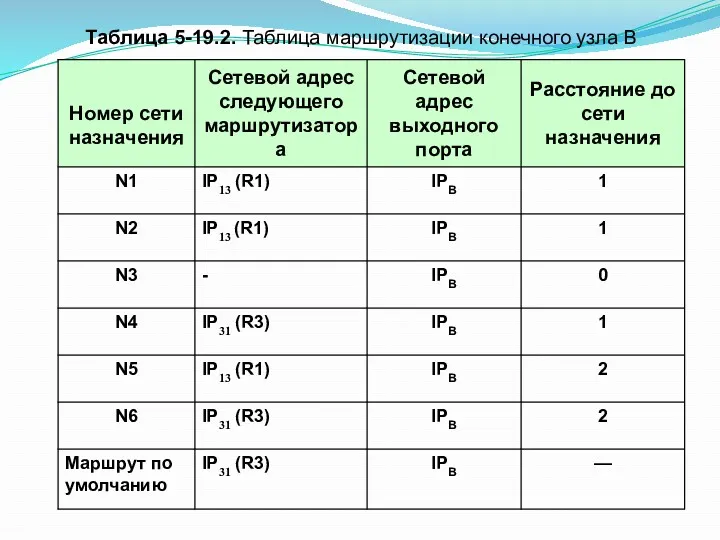
Таблица 5-19.2. Таблица маршрутизации конечного узла В
Таблица 5-19.2. Таблица маршрутизации конечного узла В

Сетевой уровень
Конечные узлы в еще большей степени, чем маршрутизаторы, пользуются приемом
Сетевой уровень
Конечные узлы в еще большей степени, чем маршрутизаторы, пользуются приемом
Сетевой уровень
Еще одним отличием работы маршрутизатора и конечного узла является способ
Сетевой уровень
Еще одним отличием работы маршрутизатора и конечного узла является способ

Просмотр таблиц маршрутизации без масок
Ниже приведен алгоритм просмотра таблицы маршрутизации протоколом
Просмотр таблиц маршрутизации без масок
Ниже приведен алгоритм просмотра таблицы маршрутизации протоколом

Просмотр таблиц маршрутизации с учетом масок
Алгоритм просмотра таблиц маршрутизации, содержащих маски,
Просмотр таблиц маршрутизации с учетом масок
Алгоритм просмотра таблиц маршрутизации, содержащих маски,

Просмотр таблиц маршрутизации с учетом масок
4. После просмотра всей таблицы маршрутизатор
Просмотр таблиц маршрутизации с учетом масок
4. После просмотра всей таблицы маршрутизатор

Сетевой уровень
Проиллюстрируем, как маршрутизатор R2 (см. рис. 5-19.7) использует вышеописанный алгоритм
Сетевой уровень
Проиллюстрируем, как маршрутизатор R2 (см. рис. 5-19.7) использует вышеописанный алгоритм
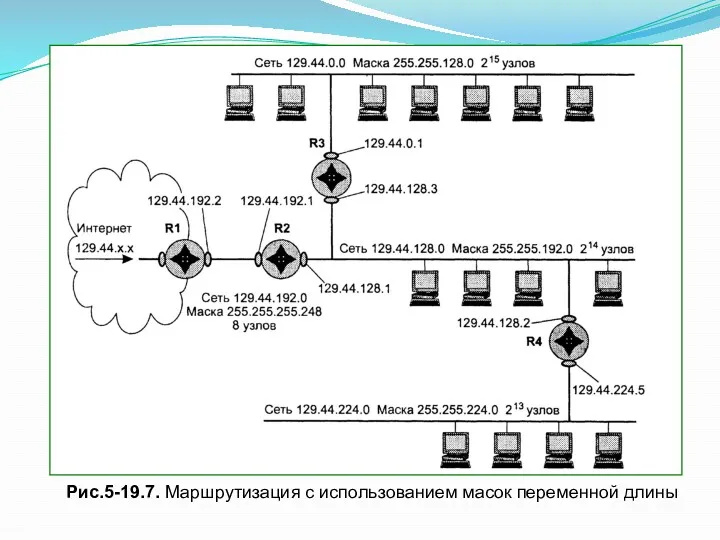
Рис.5-19.7. Маршрутизация с использованием масок переменной длины
Рис.5-19.7. Маршрутизация с использованием масок переменной длины
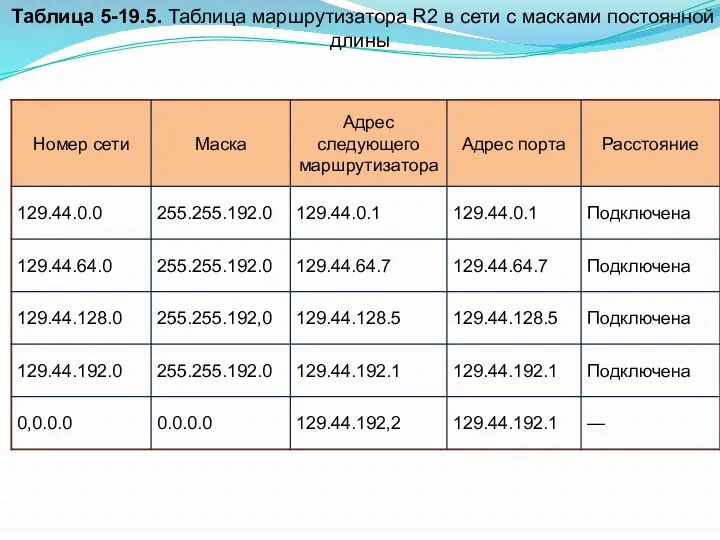
Таблица 5-19.5. Таблица маршрутизатора R2 в сети с масками постоянной длины
Таблица 5-19.5. Таблица маршрутизатора R2 в сети с масками постоянной длины

Сетевой уровень
Использование масок переменной длины
Во многих случаях более эффективным является разбиение
Сетевой уровень
Использование масок переменной длины
Во многих случаях более эффективным является разбиение
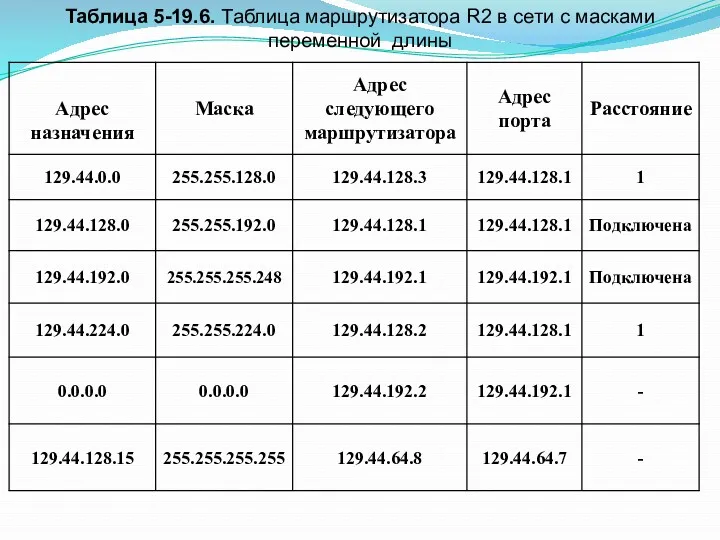
Таблица 5-19.6. Таблица маршрутизатора R2 в сети с масками переменной длины
Таблица 5-19.6. Таблица маршрутизатора R2 в сети с масками переменной длины

Сетевой уровень
ПРИМЕЧАНИЕ -
Глобальным связям между маршрутизаторами, соединенными по двухточечной схеме, не
Сетевой уровень
ПРИМЕЧАНИЕ -
Глобальным связям между маршрутизаторами, соединенными по двухточечной схеме, не

Сетевой уровень
Пусть поступивший на R2 пакет имеет адрес назначения 129.44.192.15. Поскольку
Сетевой уровень
Пусть поступивший на R2 пакет имеет адрес назначения 129.44.192.15. Поскольку
Сетевой уровень
ПРИМЕЧАНИЕ -
В IP-пакетах при использовании механизма масок по-прежнему передается только
Сетевой уровень
ПРИМЕЧАНИЕ -
В IP-пакетах при использовании механизма масок по-прежнему передается только
 Компьютер в жизни ребенка
Компьютер в жизни ребенка Создание домашней сети. Глава 6
Создание домашней сети. Глава 6 Работа с информацией при подготовке выступления
Работа с информацией при подготовке выступления Цифровое видео
Цифровое видео Инфографика как способ визуализации учебной информации
Инфографика как способ визуализации учебной информации Цифровые тренды в журналистике
Цифровые тренды в журналистике Secure remote connection
Secure remote connection Система комп’ютерного моделювання процесів життєдіяльності органів і систем організму СКІФ
Система комп’ютерного моделювання процесів життєдіяльності органів і систем організму СКІФ Технологические средства. Телекоммуникационные технологии
Технологические средства. Телекоммуникационные технологии Клієнт-серверна платформа на базі ARM процесору з використанням технології Ktor
Клієнт-серверна платформа на базі ARM процесору з використанням технології Ktor Основы построения доменной сети. Введение в Active Directory
Основы построения доменной сети. Введение в Active Directory Триггеры Oracle. СУБД. (Лекция 11)
Триггеры Oracle. СУБД. (Лекция 11) SimCorp APL
SimCorp APL Component Enabler for .NET. Introduction to Component Enabler for .NET
Component Enabler for .NET. Introduction to Component Enabler for .NET КВН по информатике.
КВН по информатике. Настройка рабочей станции с доступом в интернет по технологии Wi-Fi
Настройка рабочей станции с доступом в интернет по технологии Wi-Fi Разработка обучающей программы Виртуальный тренажер по сборке компьютера
Разработка обучающей программы Виртуальный тренажер по сборке компьютера презентация к уроку Компьютер и его части
презентация к уроку Компьютер и его части Работа со строками. Строки класса String и StringBuilder
Работа со строками. Строки класса String и StringBuilder Задачи на скорость передачи информации
Задачи на скорость передачи информации Веселый тест
Веселый тест Презентация педагогической деятельности
Презентация педагогической деятельности Беспроводные каналы
Беспроводные каналы Дипломна робота: Математичне та програмне забезпечення автоматизованої системи складання туристичного маршруту
Дипломна робота: Математичне та програмне забезпечення автоматизованої системи складання туристичного маршруту Python. Цикл while. Условие завершения цикла. Составное условие. Логические операторы. Порядок выполнения действий
Python. Цикл while. Условие завершения цикла. Составное условие. Логические операторы. Порядок выполнения действий Теория систем счисления
Теория систем счисления Информационное общество
Информационное общество Строки. Основные функции для обработки строк
Строки. Основные функции для обработки строк