- Алгоритм LZW

Содержание
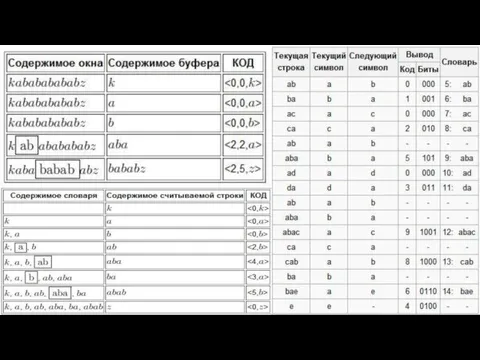
- 2. ОПИС ПРОЦЕСУ Процес стиснення виглядає наступним чином. Послідовно зчитуються символи вхідного потоку і відбувається перевірка, чи
- 3. ПСЕВДОКОД АЛГОРИТМУ Ініціалізація словника усіма можливими односимвольними фразами. Ініціалізація вхідної фрази ω першим символом повідомлення. Зчитати
- 4. LZ78 орієнтується на дані, які тільки будуть отримані (LZ78 не використовує ковзне вікно, він зберігає словник
- 7. Скачать презентацию

ОПИС ПРОЦЕСУ
Процес стиснення виглядає наступним чином. Послідовно зчитуються символи вхідного потоку
ОПИС ПРОЦЕСУ
Процес стиснення виглядає наступним чином. Послідовно зчитуються символи вхідного потоку

ПСЕВДОКОД АЛГОРИТМУ
Ініціалізація словника усіма можливими односимвольними фразами. Ініціалізація вхідної фрази
ПСЕВДОКОД АЛГОРИТМУ
Ініціалізація словника усіма можливими односимвольними фразами. Ініціалізація вхідної фрази

LZ78 орієнтується на дані, які тільки будуть отримані (LZ78 не використовує
LZ78 орієнтується на дані, які тільки будуть отримані (LZ78 не використовує
 Понятие информации. Изменение информации
Понятие информации. Изменение информации Разнообразие систем. Состав и структура системы
Разнообразие систем. Состав и структура системы Майкрософт туралы мәлімет
Майкрософт туралы мәлімет СМИ в политической системе
СМИ в политической системе Облачные технологии
Облачные технологии Windows жүйесіндегі жұмыс істеу негіздері
Windows жүйесіндегі жұмыс істеу негіздері Программа CCleaner
Программа CCleaner Проектирование информационной системы для автоматизации технических осмотров автомобилей
Проектирование информационной системы для автоматизации технических осмотров автомобилей Списки и строки
Списки и строки Скоростное прохождение игр (Speedrun)
Скоростное прохождение игр (Speedrun) Спам. Возникновение, распространение, способы защиты
Спам. Возникновение, распространение, способы защиты Mit App Inventor. Урок 7
Mit App Inventor. Урок 7 Файловая система
Файловая система Union operators, intersection, exception, grouping sets. Lecture 8
Union operators, intersection, exception, grouping sets. Lecture 8 Развитие эстетического восприятия дошкольников посредством декоративного рисования
Развитие эстетического восприятия дошкольников посредством декоративного рисования Индексаторы и операции классов. Лекция №5
Индексаторы и операции классов. Лекция №5 Робот - помощник кулинара
Робот - помощник кулинара Сетевые кабели
Сетевые кабели Электронный учебник WORD
Электронный учебник WORD An Introduction to GNSS_rev2_SD
An Introduction to GNSS_rev2_SD Информационно-логические основы ЭВМ
Информационно-логические основы ЭВМ Безопасный интернет. Для родительского собрания
Безопасный интернет. Для родительского собрания Формирование цифровых сообщений
Формирование цифровых сообщений Исследование по теме: Спутниковая связь и ее роль в жизни человека
Исследование по теме: Спутниковая связь и ее роль в жизни человека Побочные каналы утечки информации
Побочные каналы утечки информации Программирование на С++. Оператор цикла while
Программирование на С++. Оператор цикла while Профессии
Профессии Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile
Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile