- Big Data Analytics

Содержание
- 2. Содержание лекции История появления термина Big Data Что же такое Big Data? Источники Big Data Объемы
- 4. История появления термина Big Data Считается, что первые упоминания термина относятся к 2005 году в изданиях
- 5. Что же такое Big Data? Big Data – это группа технологий и методов производительной обработки очень
- 6. Что же такое Big Data? Big Data – это наборы данных такого объема, когда традиционные инструменты
- 7. Источники Больших данных Торговля Промышленность Экономика Наука
- 8. Объемы Больших данных Square Kilometre Array radio telescope Large Synoptic Survey Telescope Каждый час собирает данные
- 9. Объем данных корпораций по отраслям Представленные данные относятся к 2012 году и конечно быстро меняются. Диаграмма
- 10. Определений больших данных очень много. Одно из самых распространенных: Большие данные – это данные, которые описываются
- 11. Разнообразие. В недавнем прошлом рассматривались только структурированные данные, аккуратно встроенные в таблицы реляционных баз данных, например,
- 12. Новые технологии, такие как облачные вычисления и распределенные системы, вместе с последними разработками программного обеспечения и
- 13. Отрасли экономики Применение (анализ) Финансы ? кредитные карты Страхование ? запросы, выявление мошенничества Телекоммуникации ? записи
- 14. Лучше понять и нацелить клиентов: Чтобы лучше понять и нацелить клиентов, компании дополняют свои БД данными
- 15. Понимать и оптимизировать бизнес-процессы: Большие данные все шире используются для оптимизации бизнес-процессов. Ритейлеры имеют возможность оптимизировать
- 16. Здравоохранение Вычислительные мощности, созданные для анализа больших данных, позволяют находить новые подходы и методы лечения, лучше
- 17. Повышение безопасности и укрепление законопорядка: Службы безопасности используют анализ больших данных для срыва террористических заговоров и
- 18. Улучшение спортивных результатов: Наиболее элитарные виды спорта в настоящее время уже используют анализ больших данных. Многие
- 19. «Совершенствование и оптимизация» городов и стран: "Большие данные" используется для улучшения многих аспектов жизни наших городов
- 20. Оперативные данные Даже такие простые занятия, как прослушивание музыки или чтение книги сейчас генерируют данные. Цифровые
- 21. Данные разговоров Наши разговоры теперь записываются в цифровом формате. Все началось с электронных писем, но в
- 22. Данные датчиков Мы все чаще попадаем в окружение датчиков, которые собирают и передают данные. Ваш смартфон
- 23. Интернет вещей Сейчас у нас есть смарт-телевизоры, которые способны собирать и обрабатывать данные, у нас есть
- 24. Большие данные способны обращать в «цифру» то, что никогда раньше не оценивалось количественно: для это введен
- 25. Подход Big Data обязан своим рождением экономике и бизнесу. Там он, прежде всего, и используется. Причина
- 26. Еще одно отличие заключается в том, что в торговле, бизнесе в целом, правила «мягкие», социологические, культурные,
- 27. 1 Astrophysics - астрофизика 2 Biology - биология 3 Nanoscience - нанотехнологии 4 Power and Communication
- 28. В настоящий момент нет различия в употреблении терминов Big Data и Big Data Analytics. Эти термины
- 29. Data Mining - это процесс поддержки принятия решений, основанный на поиске в сырых данных скрытых закономерностей,
- 30. Data Mining Статистический анализ Технологии визуализации Технологии БД Технологии машинного обучения Технологии распознавания образов Искусственный интеллект
- 31. Big Data Analytics Статистический анализ Технологии визуализации Технологии БД Технологии машинного обучения Технологии распознавания образов Искусственный
- 32. MapReduce Simplied Data Processing on Large Clusters MapReduce - это модель программирования для обработки и генерации
- 33. MapReduce Диаграмма S 1 = AA A C C G T G A G T T
- 34. Shuffle and Sort MapReduce подсчет статистики по словам
- 35. Примеры заданий для MapReduce S 1 = AA A C C G T G A G
- 36. S 1 = AA A C C G T G A G T T A T
- 37. S 1 = AA A C C G T G A G T T A T
- 38. Графы и MapReduce S 1 = AA A C C G T G A G T
- 39. S 1 = AA A C C G T G A G T T A T
- 40. Программные реализации MapReduce S 1 = AA A C C G T G A G T
- 41. Поиск похожих объектов S 1 = AA A C C G T G A G T
- 42. Поиск похожих объектов Метрики расстояний Сумма абсолютных разниц по каждому измерению Манхетенновское расстояние (в честь решетчатой
- 43. Метрики расстояний Пример 1) Длина зеленого отрезка (L2) ≈ 8, 435 2) Синей ломаной (L1) =
- 44. Другие метрики расстояний Косинусное расстояние (Cosine Distance) = это угол между векторами. например, A = 00111;
- 45. Edit distance Пример из биоинформатики S 1 = AA A C C G T G A
- 46. Другие метрики расстояний 3. Расстояние Хемминга (Hamming Distance) = число позиций, в которых соответствующие символы двух
- 47. Big Data Analytics Big data is generally understood to refer to techniques developed to analyse data
- 48. Big Data Analytics IMPLEMENTING BIG DATA: 7 TECHNIQUES TO CONSIDER Whether your business wants to discover
- 49. Big Data Analytics 1. ASSOCIATION RULE LEARNING Are people who purchase tea more or less likely
- 50. Big Data Analytics 2. CLASSIFICATION TREE ANALYSIS Which categories does this document belong to? Statistical classification
- 51. Big Data Analytics 3. GENETIC ALGORITHMS Which TV programs should we broadcast, and in what time
- 52. Big Data Analytics 4. MACHINE LEARNING Which movies from our catalogue would this customer most likely
- 53. Big Data Analytics 5. REGRESSION ANALYSIS How does your age affect the kind of car you
- 54. Big Data Analytics 6. SENTIMENT ANALYSIS How well is our new return policy being received? Sentiment
- 55. Big Data Analytics 7. SOCIAL NETWORK ANALYSIS How many degrees of separation are you from Kevin
- 56. Big Data Analytics
- 57. Mathematics for Analysis of Petascale Data needs of various scientific domains Application Domains 1 Astrophysics 2
- 58. Big Data Analytics • Statistics • Optimization • Uncertainty quantification • Machine learning • Network and
- 59. Big Data Analytics The analysis of extensive quantities of data and the need to grasp value
- 60. List of Big Data Analytical Methods A/B testing 16) Signal Processing Association rule learning 17) Spatial
- 61. Big Data Analytics Being aware of the limitations of Big Data Methods and potential methodological issues
- 62. Big Data Analytics Traditional data mining and mining of Big Data
- 63. Классификация — отнесение входного вектора (объекта, события, наблюдения) к одному из заранее известных классов. Кластеризация —
- 64. Классификация и предсказание (classification and prediction) Пример – целенаправленный найм (focused hiring) Кластерный анализ (cluster analysis)
- 65. Data Mining для анализа финансовых данных Проектирование и строительство хранилищ данных для многомерного анализа данных и
- 66. Data Mining в розничной торговле Проектирование и построение хранилищ данных на основе использования преимуществ технологий интеллектуального
- 67. Data Mining в телекоммуникациях Многомерный анализ телекоммуникационных данных Выявление необычных паттернов и определение мошенничества Сервисы мобильной
- 68. Методы классификации и прогнозирования. Деревья решений Метод деревьев решений (decision trees) является одним из наиболее популярных
- 69. Пусть решается задача, в которой надо ответить на вопрос: «Играть ли в гольф?». Чтобы решить задачу
- 70. Играть ли в гольф? Data Mining Примеры
- 71. База данных содержит ретроспективные данные о клиентах банка, являющиеся её атрибутами: годовой доход, долги, займы, кредитная
- 72. Методы классификации и прогнозирования. Деревья решений Big Data Analytics Примеры
- 73. Выделение архетипа пользователя Выделение связей между группами пользователей Выделение сообществ Анализ круга общения Выделение нетипичных пользователей
- 74. Примеры Задачи кластеризации на графах применение алгоритма Girvan and Newman The network of friendships in the
- 75. Результаты применения метода MLP (Markov Cluster Algorithm) Примеры Задачи кластеризации на графах
- 76. Авторы метода ставят задачу весьма парадоксальным образом: «Как искать иголку в многомерном стоге сена, не зная,
- 77. Метод Dynamic Quantum Clustering В n-мерном признаковом пространстве строится функция φ, являющаяся суммой гауссовых функций с
- 78. Метод Dynamic Quantum Clustering Парзеновская функция (синяя кривая) и соответствующий ей квантовый потенциал (красная кривая). Парзеновская
- 79. Анализ цен акций компаний, входящих в лист индекса Standard and Poor’s S&P500 за период 1 января
- 80. 01.01.2000 – 24.03.2011 Примеры Результаты применения метода Quantum Clustering на примере данных фондового рынка С математической
- 81. Анализируется пространственное распределение 139798 галактик (каталогизированные данные из Sloan Digital Sky Survey (SDSS). Для каждой галактики
- 82. Хорошо видна эволюция начального распределения (cлева) к структуре, которая действительно напоминает полотно из волокон и пустот
- 83. "Гусеница" - будущий классический метод анализа временных рядов - Каковы принципиальные отличия метода "Гусеница" от других
- 84. Важнейшим условием успешного развития мировой экономики на современном этапе становится возможность фиксировать и анализировать огромные массивы
- 85. Важнейшим условием успешного развития мировой экономики на современном этапе становится возможность фиксировать и анализировать огромные массивы
- 86. Big Data. Bibliography Bernard Marr. “Big Data: Using SMART Big Data, Analytics and Metrics To Make
- 87. 8) Денис Серов. “Аналитика “больших данных”– новые перспективы”. “Storage News”, №1 (49), 2012. 9) Zhanpeng Huang,
- 89. Скачать презентацию

Содержание лекции
История появления термина Big Data
Что же такое Big Data?
Источники
Содержание лекции
История появления термина Big Data
Что же такое Big Data?
Источники


История появления термина Big Data
Считается, что первые упоминания термина относятся к
История появления термина Big Data
Считается, что первые упоминания термина относятся к

Что же такое Big Data?
Big Data – это группа технологий и
Что же такое Big Data?
Big Data – это группа технологий и

Что же такое Big Data?
Big Data – это наборы данных такого
Что же такое Big Data?
Big Data – это наборы данных такого

Источники Больших данных
Торговля
Промышленность
Экономика
Наука
Источники Больших данных
Торговля
Промышленность
Экономика
Наука

Объемы Больших данных
Square Kilometre Array
radio telescope
Large Synoptic Survey Telescope
Каждый час
Объемы Больших данных
Square Kilometre Array
radio telescope
Large Synoptic Survey Telescope
Каждый час
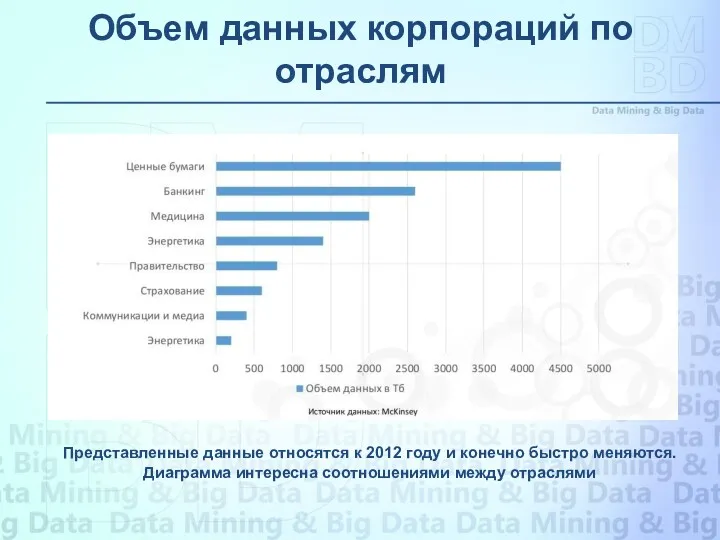
Объем данных корпораций по отраслям
Представленные данные относятся к 2012 году и
Объем данных корпораций по отраслям
Представленные данные относятся к 2012 году и

Определений больших данных очень много. Одно из самых распространенных: Большие данные
Определений больших данных очень много. Одно из самых распространенных: Большие данные

Разнообразие.
В недавнем прошлом рассматривались только структурированные данные, аккуратно встроенные
Разнообразие.
В недавнем прошлом рассматривались только структурированные данные, аккуратно встроенные

Новые технологии, такие как облачные вычисления и распределенные системы, вместе
Новые технологии, такие как облачные вычисления и распределенные системы, вместе

Отрасли экономики Применение (анализ)
Финансы ? кредитные карты
Страхование ? запросы, выявление
Отрасли экономики Применение (анализ)
Финансы ? кредитные карты
Страхование ? запросы, выявление

Лучше понять и нацелить клиентов:
Чтобы лучше понять и нацелить клиентов, компании
Лучше понять и нацелить клиентов:
Чтобы лучше понять и нацелить клиентов, компании

Понимать и оптимизировать бизнес-процессы:
Большие данные все шире используются для оптимизации бизнес-процессов.
Понимать и оптимизировать бизнес-процессы:
Большие данные все шире используются для оптимизации бизнес-процессов.

Здравоохранение
Вычислительные мощности, созданные для анализа больших данных, позволяют находить новые подходы
Здравоохранение
Вычислительные мощности, созданные для анализа больших данных, позволяют находить новые подходы

Повышение безопасности и укрепление законопорядка:
Службы безопасности используют анализ больших данных для
Повышение безопасности и укрепление законопорядка:
Службы безопасности используют анализ больших данных для

Улучшение спортивных результатов:
Наиболее элитарные виды спорта в настоящее время уже используют
Улучшение спортивных результатов: Наиболее элитарные виды спорта в настоящее время уже используют

«Совершенствование и оптимизация» городов и стран:
"Большие данные" используется для улучшения
«Совершенствование и оптимизация» городов и стран: "Большие данные" используется для улучшения

Оперативные данные
Даже такие простые занятия, как прослушивание музыки или чтение
Даже такие простые занятия, как прослушивание музыки или чтение

Данные разговоров
Наши разговоры теперь записываются в цифровом формате. Все началось с
Данные разговоров
Наши разговоры теперь записываются в цифровом формате. Все началось с

Данные датчиков
Мы все чаще попадаем в окружение датчиков, которые собирают и
Данные датчиков Мы все чаще попадаем в окружение датчиков, которые собирают и

Интернет вещей
Сейчас у нас есть смарт-телевизоры, которые способны собирать и обрабатывать
Сейчас у нас есть смарт-телевизоры, которые способны собирать и обрабатывать

Большие данные способны обращать в «цифру» то, что никогда раньше не
Большие данные способны обращать в «цифру» то, что никогда раньше не

Подход Big Data обязан своим рождением экономике и бизнесу. Там он,
Подход Big Data обязан своим рождением экономике и бизнесу. Там он,

Еще одно отличие заключается в том, что в торговле, бизнесе в
Еще одно отличие заключается в том, что в торговле, бизнесе в

1 Astrophysics - астрофизика
2 Biology - биология
3 Nanoscience - нанотехнологии
4 Power
2 Biology - биология
3 Nanoscience - нанотехнологии
4 Power

В настоящий момент нет различия в употреблении терминов Big Data и
Big
В настоящий момент нет различия в употреблении терминов Big Data и
Big

Data Mining - это процесс поддержки принятия решений, основанный на поиске
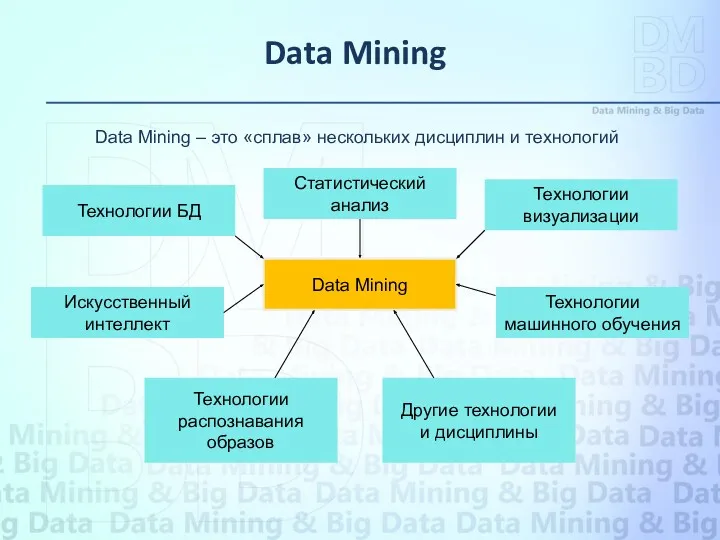
Data Mining
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
Другие технологии
Data Mining
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
Другие технологии
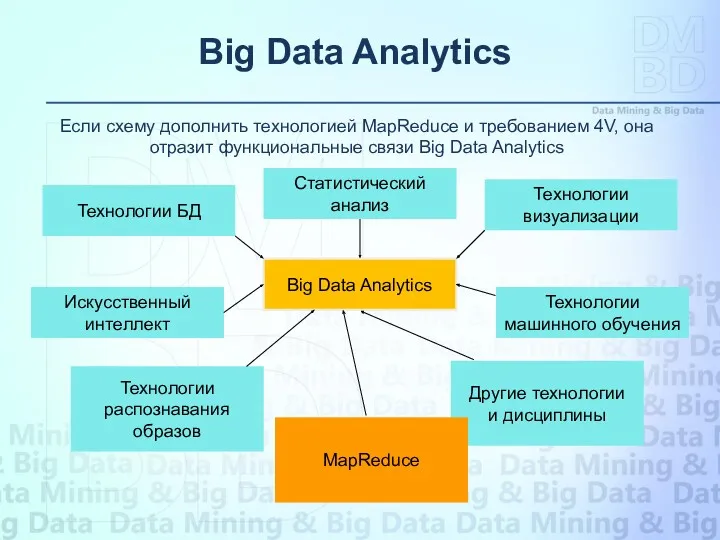
Big Data Analytics
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
Другие
Big Data Analytics
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
Другие

MapReduce
Simplied Data Processing on Large Clusters
MapReduce - это модель программирования для
MapReduce
Simplied Data Processing on Large Clusters
MapReduce - это модель программирования для
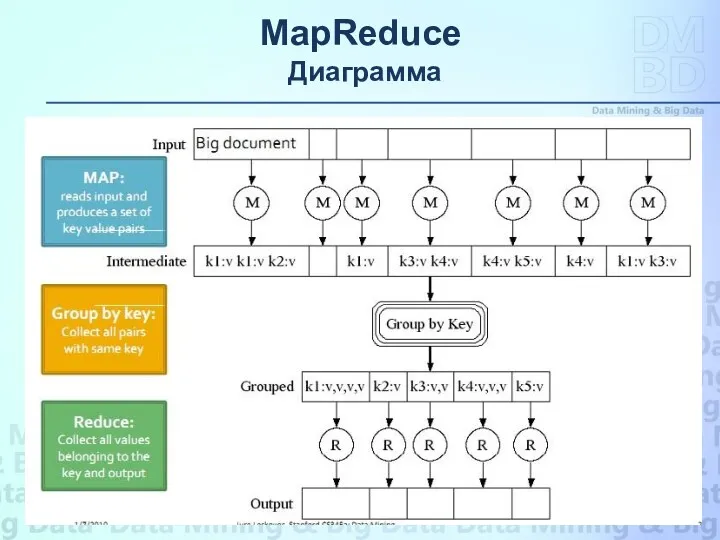
MapReduce
Диаграмма
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
MapReduce
Диаграмма
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
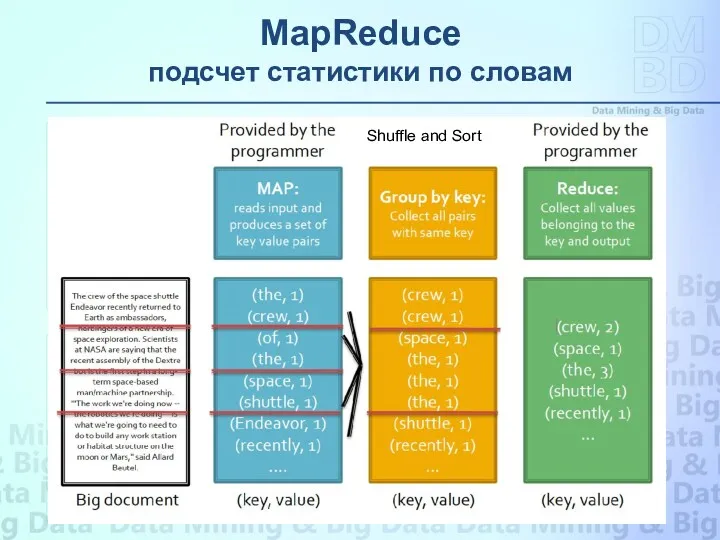
Shuffle and Sort
MapReduce
подсчет статистики по словам
Shuffle and Sort
MapReduce
подсчет статистики по словам

Примеры заданий для MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Распределенный Grep: Map функция выдает строку, если
Примеры заданий для MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Распределенный Grep: Map функция выдает строку, если

S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Обучение модели Neural Network на данных эмпирической выборки
Веса сети
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Обучение модели Neural Network на данных эмпирической выборки
Веса сети
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
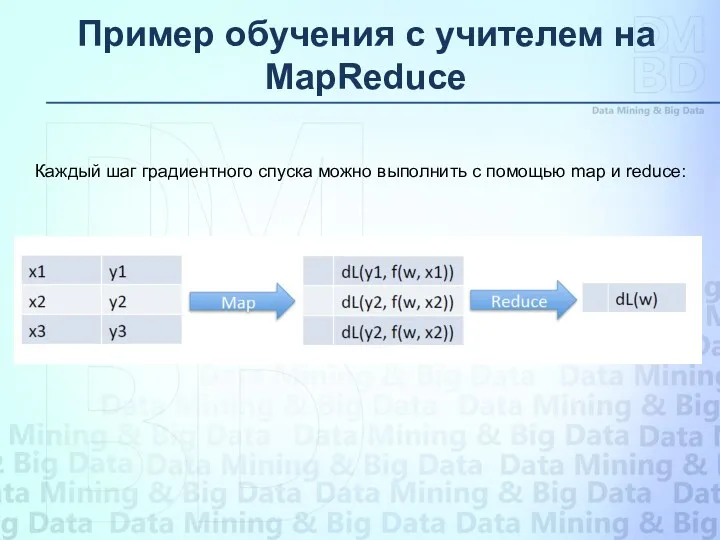
Каждый шаг градиентного спуска можно выполнить с помощью map и
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Каждый шаг градиентного спуска можно выполнить с помощью map и
Графы и MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
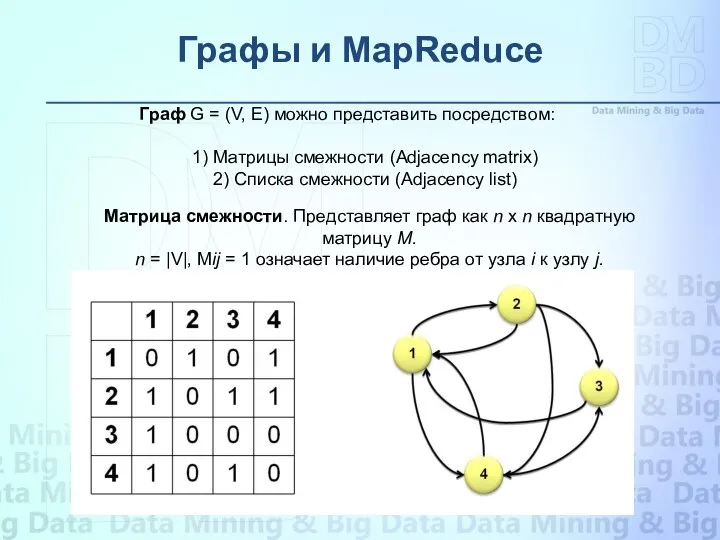
Граф G = (V, E) можно представить посредством:
1)
Графы и MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Граф G = (V, E) можно представить посредством:
1)

S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Список смежности. Из матрицы смежности… «вытряхиваются» все нули….
Графы и MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Список смежности. Из матрицы смежности… «вытряхиваются» все нули….
Графы и MapReduce

Программные реализации MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Google реализовал MapReduce на C++ реализовал MapReduce на
Программные реализации MapReduce
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Google реализовал MapReduce на C++ реализовал MapReduce на

Поиск похожих объектов
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Многие задачи могут быть озвучены, как «найти
Поиск похожих объектов
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Многие задачи могут быть озвучены, как «найти

Поиск похожих объектов
Метрики расстояний
Сумма абсолютных разниц по каждому измерению
Манхетенновское расстояние
Поиск похожих объектов
Метрики расстояний
Сумма абсолютных разниц по каждому измерению
Манхетенновское расстояние
Метрики расстояний
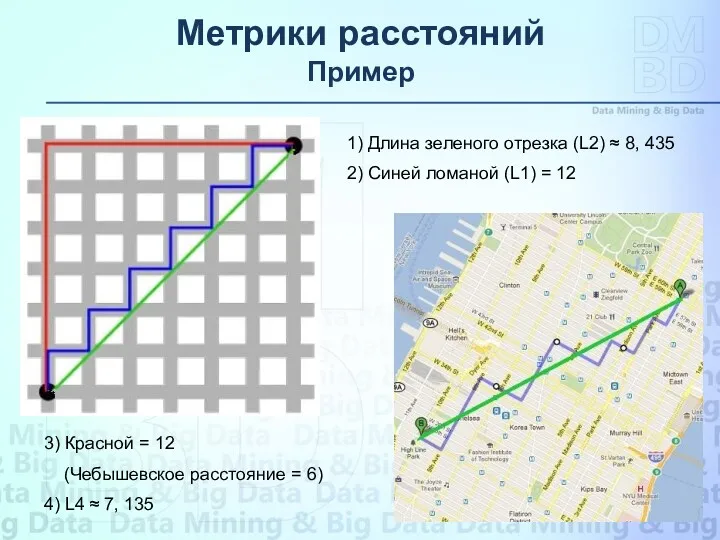
Пример
1) Длина зеленого отрезка (L2) ≈ 8, 435
2) Синей ломаной
Метрики расстояний
Пример
1) Длина зеленого отрезка (L2) ≈ 8, 435
2) Синей ломаной

Другие метрики расстояний
Косинусное расстояние (Cosine Distance) = это угол между векторами.
Другие метрики расстояний
Косинусное расстояние (Cosine Distance) = это угол между векторами.

Edit distance
Пример из биоинформатики
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Анализ первичных последовательностей
Азотистые основания, входящие в
Edit distance
Пример из биоинформатики
S
1
=
AA
A
C
C
G
T
G
A
G
T
T
A
T T
C
G
T
T
C
T
A
G
AA
Анализ первичных последовательностей
Азотистые основания, входящие в

Другие метрики расстояний
3. Расстояние Хемминга (Hamming Distance) = число позиций,
Другие метрики расстояний
3. Расстояние Хемминга (Hamming Distance) = число позиций,

Big Data Analytics
Big data is generally understood to refer to techniques
Big Data Analytics
Big data is generally understood to refer to techniques

Big Data Analytics
IMPLEMENTING BIG DATA: 7 TECHNIQUES TO CONSIDER
Whether your
Big Data Analytics
IMPLEMENTING BIG DATA: 7 TECHNIQUES TO CONSIDER
Whether your

Big Data Analytics
1. ASSOCIATION RULE LEARNING
Are people who purchase tea more
Big Data Analytics
1. ASSOCIATION RULE LEARNING
Are people who purchase tea more

Big Data Analytics
2. CLASSIFICATION TREE ANALYSIS
Which categories does this document belong
Big Data Analytics
2. CLASSIFICATION TREE ANALYSIS
Which categories does this document belong

Big Data Analytics
3. GENETIC ALGORITHMS
Which TV programs should we broadcast, and
Big Data Analytics
3. GENETIC ALGORITHMS
Which TV programs should we broadcast, and

Big Data Analytics
4. MACHINE LEARNING
Which movies from our catalogue would this
Big Data Analytics
4. MACHINE LEARNING
Which movies from our catalogue would this

Big Data Analytics
5. REGRESSION ANALYSIS
How does your age affect the kind
Big Data Analytics
5. REGRESSION ANALYSIS
How does your age affect the kind

Big Data Analytics
6. SENTIMENT ANALYSIS
How well is our new return policy
Big Data Analytics
6. SENTIMENT ANALYSIS
How well is our new return policy

Big Data Analytics
7. SOCIAL NETWORK ANALYSIS
How many degrees of separation are
Big Data Analytics
7. SOCIAL NETWORK ANALYSIS
How many degrees of separation are

Big Data Analytics
Big Data Analytics

Mathematics for Analysis of Petascale Data
needs of various scientific domains
Application Domains
1
Mathematics for Analysis of Petascale Data
needs of various scientific domains
Application Domains
1

Big Data Analytics
• Statistics
• Optimization
• Uncertainty quantification
• Machine learning
• Network and
Big Data Analytics
• Statistics
• Optimization
• Uncertainty quantification
• Machine learning
• Network and

Big Data Analytics
The analysis of extensive quantities of data and the
Big Data Analytics
The analysis of extensive quantities of data and the

List of Big Data Analytical Methods
A/B testing 16) Signal Processing
List of Big Data Analytical Methods
A/B testing 16) Signal Processing

Big Data Analytics
Being aware of the limitations of Big Data Methods
Big Data Analytics
Being aware of the limitations of Big Data Methods
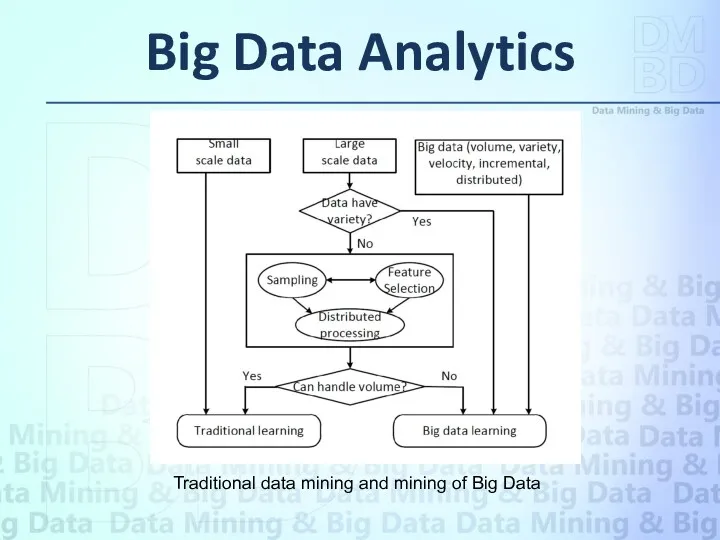
Big Data Analytics
Traditional data mining and mining of Big Data
Big Data Analytics
Traditional data mining and mining of Big Data

Классификация — отнесение входного вектора (объекта, события, наблюдения) к одному из
Классификация — отнесение входного вектора (объекта, события, наблюдения) к одному из

Классификация и предсказание (classification and prediction)
Пример – целенаправленный найм (focused hiring)
Кластерный
Классификация и предсказание (classification and prediction)
Пример – целенаправленный найм (focused hiring)
Кластерный

Data Mining для анализа финансовых данных
Проектирование и строительство хранилищ данных для

Data Mining в розничной торговле
Проектирование и построение хранилищ данных на
Data Mining в розничной торговле Проектирование и построение хранилищ данных на

Data Mining в телекоммуникациях
Многомерный анализ телекоммуникационных данных
Выявление необычных паттернов
Data Mining в телекоммуникациях
Многомерный анализ телекоммуникационных данных
Выявление необычных паттернов

Методы классификации и прогнозирования. Деревья решений
Метод деревьев решений (decision trees)
Методы классификации и прогнозирования. Деревья решений
Метод деревьев решений (decision trees)

Пусть решается задача, в которой надо ответить на вопрос: «Играть ли
Пусть решается задача, в которой надо ответить на вопрос: «Играть ли
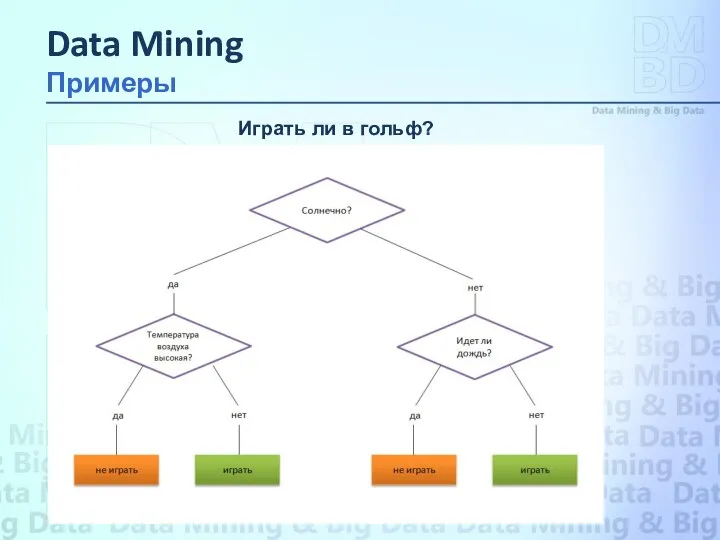
Играть ли в гольф?
Data Mining
Примеры
Играть ли в гольф?
Data Mining
Примеры

База данных содержит ретроспективные данные о клиентах банка, являющиеся её атрибутами:
База данных содержит ретроспективные данные о клиентах банка, являющиеся её атрибутами:
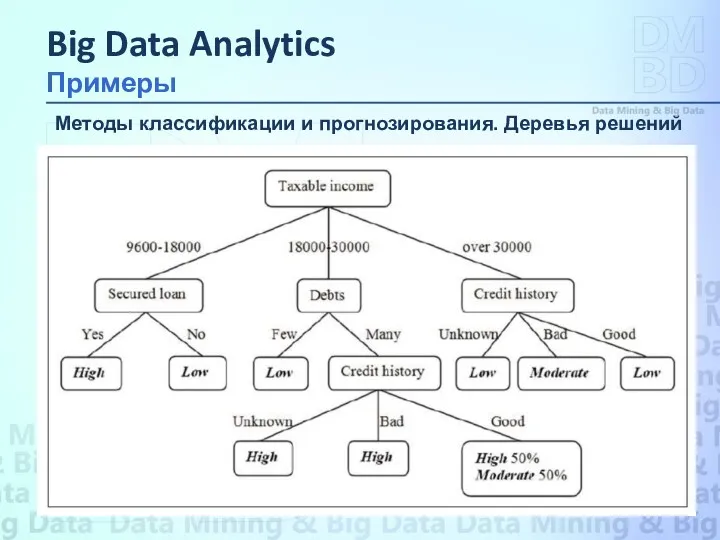
Методы классификации и прогнозирования. Деревья решений
Big Data Analytics
Примеры
Методы классификации и прогнозирования. Деревья решений
Big Data Analytics
Примеры

Выделение архетипа пользователя
Выделение связей между группами пользователей
Выделение сообществ
Анализ круга общения
Выделение нетипичных
Выделение архетипа пользователя
Выделение связей между группами пользователей
Выделение сообществ
Анализ круга общения
Выделение нетипичных
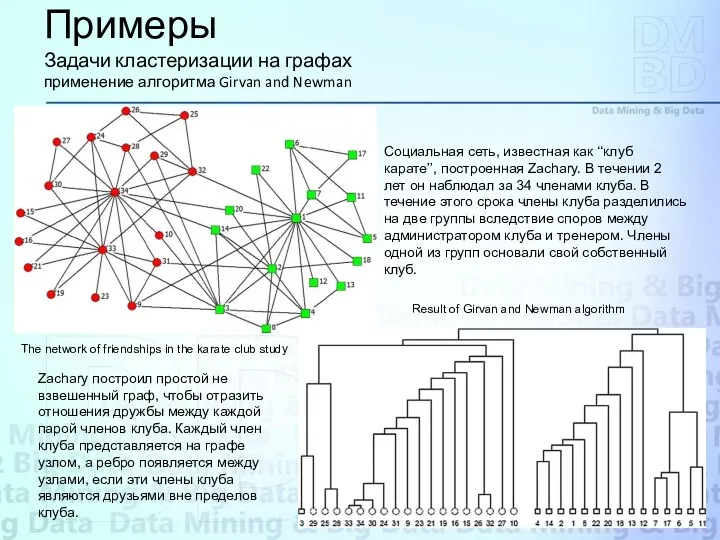
Примеры
Задачи кластеризации на графах
применение алгоритма Girvan and Newman
The network of friendships
Примеры
Задачи кластеризации на графах
применение алгоритма Girvan and Newman
The network of friendships

Результаты применения метода MLP (Markov Cluster Algorithm)
Примеры
Задачи кластеризации на графах
Результаты применения метода MLP (Markov Cluster Algorithm)
Примеры
Задачи кластеризации на графах

Авторы метода ставят задачу весьма парадоксальным образом: «Как искать иголку в
Авторы метода ставят задачу весьма парадоксальным образом: «Как искать иголку в

Метод Dynamic Quantum Clustering
В n-мерном признаковом пространстве строится функция φ, являющаяся
В n-мерном признаковом пространстве строится функция φ, являющаяся
Метод Dynamic Quantum Clustering
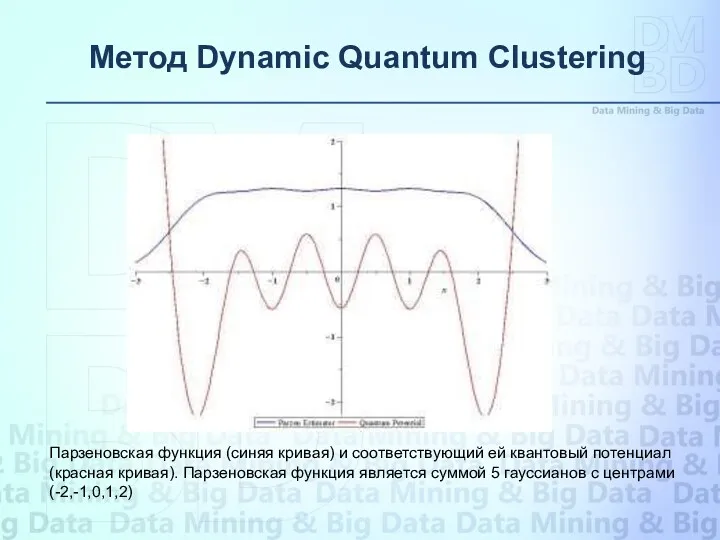
Парзеновская функция (синяя кривая) и соответствующий ей квантовый
Парзеновская функция (синяя кривая) и соответствующий ей квантовый
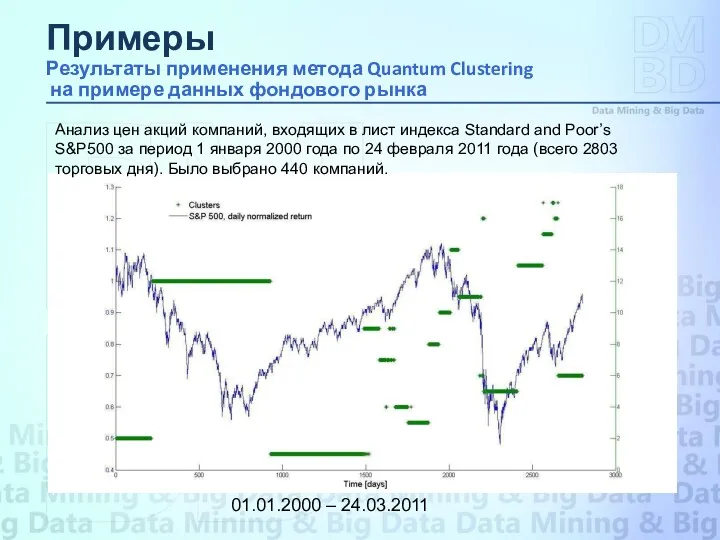
Анализ цен акций компаний, входящих в лист индекса Standard and Poor’s
Анализ цен акций компаний, входящих в лист индекса Standard and Poor’s

01.01.2000 – 24.03.2011
Примеры
Результаты применения метода Quantum Clustering
на примере данных фондового
01.01.2000 – 24.03.2011
Примеры Результаты применения метода Quantum Clustering на примере данных фондового

Анализируется пространственное распределение 139798 галактик (каталогизированные данные из Sloan Digital Sky
Анализируется пространственное распределение 139798 галактик (каталогизированные данные из Sloan Digital Sky

Хорошо видна эволюция начального распределения (cлева) к структуре, которая действительно напоминает
Хорошо видна эволюция начального распределения (cлева) к структуре, которая действительно напоминает

"Гусеница" - будущий классический метод анализа временных рядов
- Каковы принципиальные
"Гусеница" - будущий классический метод анализа временных рядов
- Каковы принципиальные

Важнейшим условием успешного развития мировой экономики на современном этапе становится
Важнейшим условием успешного развития мировой экономики на современном этапе становится

Важнейшим условием успешного развития мировой экономики на современном этапе становится возможность
Важнейшим условием успешного развития мировой экономики на современном этапе становится возможность

Big Data. Bibliography
Bernard Marr. “Big Data: Using SMART Big Data,
Big Data. Bibliography
Bernard Marr. “Big Data: Using SMART Big Data,

8) Денис Серов. “Аналитика “больших данных”– новые перспективы”. “Storage News”, №1
8) Денис Серов. “Аналитика “больших данных”– новые перспективы”. “Storage News”, №1
 Особенности работы с OC семейства Windows
Особенности работы с OC семейства Windows Электронная книга знаний
Электронная книга знаний Методы замены
Методы замены Информация в обществе и технике
Информация в обществе и технике Пошук об'єктів файлової системи
Пошук об'єктів файлової системи Составляющие компьютера
Составляющие компьютера Brawl Stars — игра для мобильных устройств
Brawl Stars — игра для мобильных устройств Геоинформационные системы (ГИС)
Геоинформационные системы (ГИС) Автоматизация научных исследований
Автоматизация научных исследований Программирование на Java. Массивы в Java. (Лекция 3.2)
Программирование на Java. Массивы в Java. (Лекция 3.2) Модели и моделирование. Модели и их типы
Модели и моделирование. Модели и их типы Инструкция по работе с сервисом создания инфографики Infogram.com
Инструкция по работе с сервисом создания инфографики Infogram.com Создание таблиц в среде текстового процессора Word
Создание таблиц в среде текстового процессора Word Выпускная квалификационная работа на тему: разработка моделей поведения персонажей
Выпускная квалификационная работа на тему: разработка моделей поведения персонажей Методы анализа сложности рекурсивных алгоритмов
Методы анализа сложности рекурсивных алгоритмов Информационные технологии в историческом исследовании и образовании
Информационные технологии в историческом исследовании и образовании Prefer interfaces to reflection. (Item 53)
Prefer interfaces to reflection. (Item 53) Внеклассное мероприятие Спаси компьютер от вируса
Внеклассное мероприятие Спаси компьютер от вируса Компьютерные коммуникации и сети. Обзор системы linux
Компьютерные коммуникации и сети. Обзор системы linux Доступ к сети Интернет
Доступ к сети Интернет Веб-обозреватели
Веб-обозреватели Soul.village. Личный аккаунт
Soul.village. Личный аккаунт Usage to MTK SN_STATION Tool
Usage to MTK SN_STATION Tool Working from your Services to Clouds and Cloud Services. Module 4. Meta Services
Working from your Services to Clouds and Cloud Services. Module 4. Meta Services Использование ИКТ, как средства повышения качества знаний учащихся на уроках английского языка
Использование ИКТ, как средства повышения качества знаний учащихся на уроках английского языка Java6 (Строки)
Java6 (Строки) Создание сайта по оказанию фото-услуг
Создание сайта по оказанию фото-услуг Электронный листок нетрудоспособности
Электронный листок нетрудоспособности