- Distributed file system

Содержание
- 2. CHAPTER 8: DISTRIBUTED FILE SYSTEM Introduction to File System File-System Structure Directory Implementation Allocation Methods Distributed
- 3. FILE-SYSTEM STRUCTURE File structure Logical storage unit Collection of related information File system resides on secondary
- 4. LAYERED FILE SYSTEM
- 5. A TYPICAL FILE CONTROL BLOCK
- 6. VIRTUAL FILE SYSTEMS Virtual File Systems (VFS) provide an object-oriented way of implementing file systems. VFS
- 7. SCHEMATIC VIEW OF VIRTUAL FILE SYSTEM
- 8. DIRECTORY IMPLEMENTATION Linear list of file names with pointer to the data blocks. simple to program
- 9. ALLOCATION METHODS An allocation method refers to how disk blocks are allocated for files: Contiguous allocation
- 10. CONTIGUOUS ALLOCATION Each file occupies a set of contiguous blocks on the disk Simple – only
- 11. CONTIGUOUS ALLOCATION OF DISK SPACE
- 12. EXTENT-BASED SYSTEMS Many newer file systems (I.e. Veritas File System) use a modified contiguous allocation scheme
- 13. LINKED ALLOCATION Each file is a linked list of disk blocks: blocks may be scattered anywhere
- 14. LINKED ALLOCATION
- 15. FILE-ALLOCATION TABLE
- 16. INDEXED ALLOCATION Brings all pointers together into the index block. Logical view. index table
- 17. EXAMPLE OF INDEXED ALLOCATION
- 18. INDEXED ALLOCATION – MAPPING (CONT.) outer-index index table file
- 19. COMBINED SCHEME: UNIX (4K BYTES PER BLOCK)
- 20. LINKED FREE SPACE LIST ON DISK
- 21. DISTRIBUTED FILE SYSTEM
- 22. DISTRIBUTED FILE SYSTEMS A special case of distributed system Allows multi-computer systems to share files Examples:
- 23. DISTRIBUTED FILE SYSTEMS (CONTINUED) One of most common uses of distributed computing Goal: provide common view
- 24. NAMING OF DISTRIBUTED FILES Naming – mapping between logical and physical objects. A transparent DFS hides
- 25. DFS – THREE NAMING SCHEMES Mount remote directories to local directories, giving the appearance of a
- 26. THE SUN NETWORK FILE SYSTEM (NFS) An implementation and a specification of a software system for
- 27. NFS (CONT.) Interconnected workstations viewed as a set of independent machines with independent file systems, which
- 28. NFS (CONT.) NFS is designed to operate in a heterogeneous environment of different machines, operating systems,
- 29. THREE INDEPENDENT FILE SYSTEMS
- 30. MOUNTING IN NFS Mounts Cascading mounts
- 31. NFS MOUNT PROTOCOL Establishes initial logical connection between server and client Mount operation includes name of
- 32. NFS PROTOCOL Provides a set of remote procedure calls for remote file operations. The procedures support
- 33. THREE MAJOR LAYERS OF NFS ARCHITECTURE UNIX file-system interface (based on the open, read, write, and
- 34. SCHEMATIC VIEW OF NFS ARCHITECTURE
- 35. NFS PATH-NAME TRANSLATION Performed by breaking the path into component names and performing a separate NFS
- 36. NFS REMOTE OPERATIONS Nearly one-to-one correspondence between regular UNIX system calls and the NFS protocol RPCs
- 37. ANDREW FILE SYSTEM (AFS) Completely different kind of file system Developed at CMU to support all
- 38. ANDREW FILE SYSTEM (AFS) Stateful Single name space File has the same names everywhere in the
- 39. AFS Need for scaling led to reduction of client-server message traffic. Once a file is cached,
- 40. AFS On file open() If client has received a callback for file, it must fetch new
- 41. DISTRIBUTED FILE SYSTEMS REQUIREMENTS Performance is always an issue Tradeoff between performance and the semantics of
- 43. Скачать презентацию

CHAPTER 8: DISTRIBUTED FILE SYSTEM
Introduction to File System
File-System Structure
Directory Implementation
Allocation
CHAPTER 8: DISTRIBUTED FILE SYSTEM
Introduction to File System
File-System Structure
Directory Implementation
Allocation

FILE-SYSTEM STRUCTURE
File structure
Logical storage unit
Collection of related information
File system resides on
FILE-SYSTEM STRUCTURE
File structure
Logical storage unit
Collection of related information
File system resides on
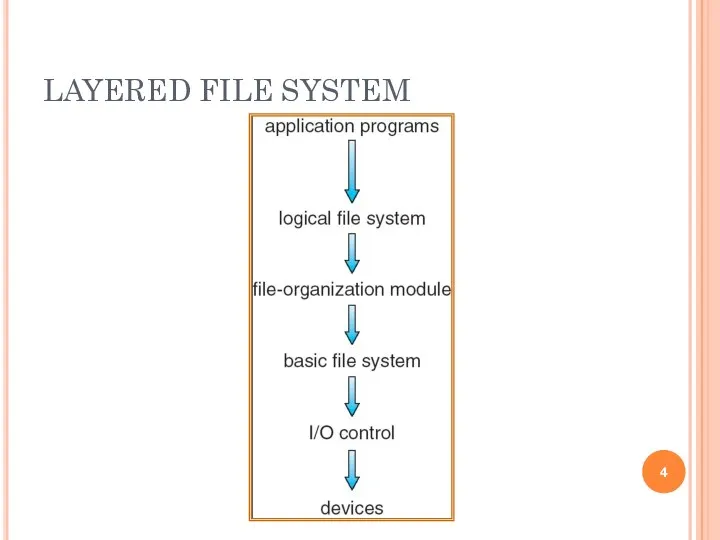
LAYERED FILE SYSTEM
LAYERED FILE SYSTEM
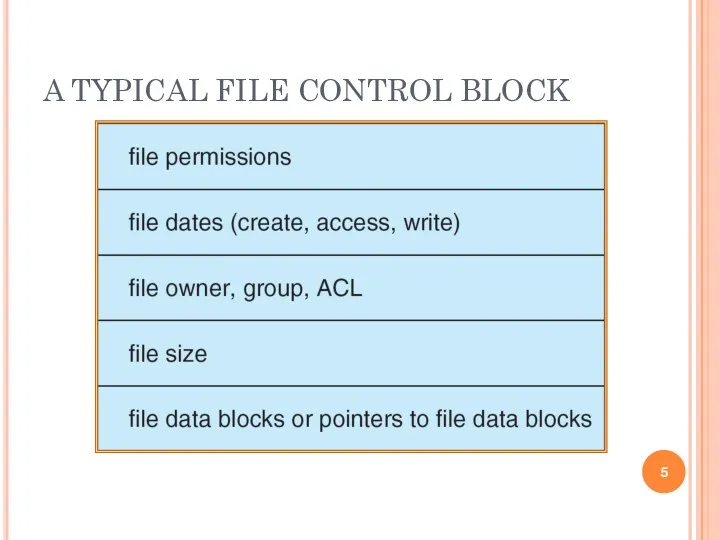
A TYPICAL FILE CONTROL BLOCK
A TYPICAL FILE CONTROL BLOCK

VIRTUAL FILE SYSTEMS
Virtual File Systems (VFS) provide an object-oriented way of
VIRTUAL FILE SYSTEMS
Virtual File Systems (VFS) provide an object-oriented way of
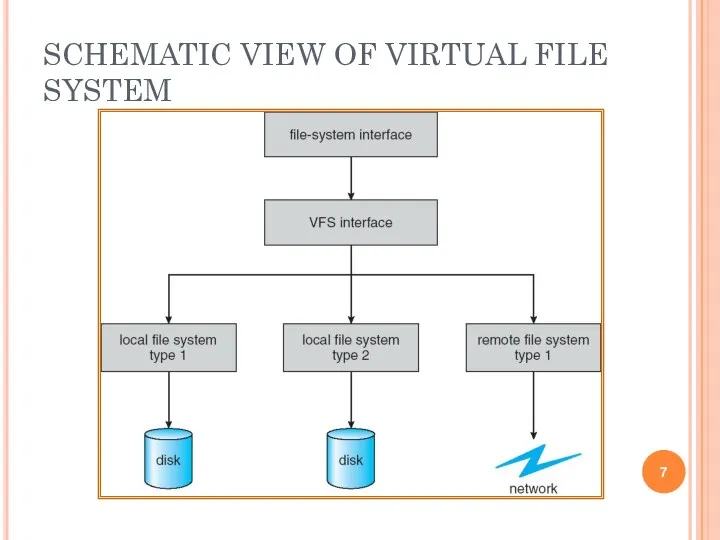
SCHEMATIC VIEW OF VIRTUAL FILE SYSTEM
SCHEMATIC VIEW OF VIRTUAL FILE SYSTEM

DIRECTORY IMPLEMENTATION
Linear list of file names with pointer to the data
DIRECTORY IMPLEMENTATION
Linear list of file names with pointer to the data

ALLOCATION METHODS
An allocation method refers to how disk blocks are allocated
ALLOCATION METHODS
An allocation method refers to how disk blocks are allocated

CONTIGUOUS ALLOCATION
Each file occupies a set of contiguous blocks on the
CONTIGUOUS ALLOCATION
Each file occupies a set of contiguous blocks on the
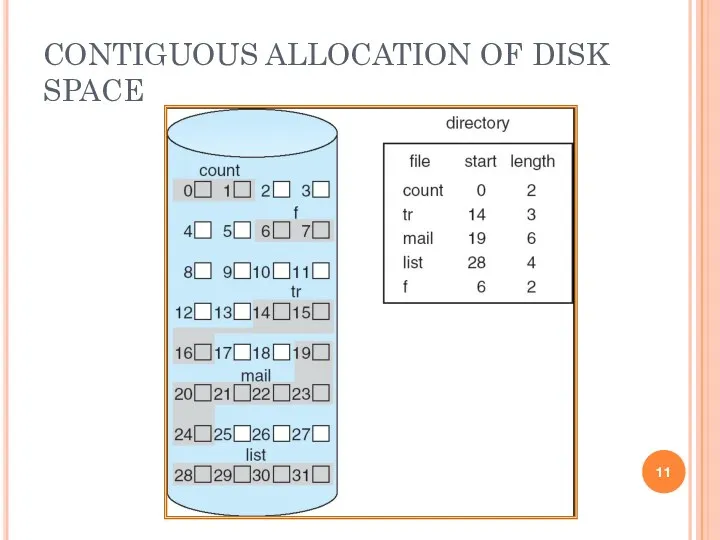
CONTIGUOUS ALLOCATION OF DISK SPACE
CONTIGUOUS ALLOCATION OF DISK SPACE

EXTENT-BASED SYSTEMS
Many newer file systems (I.e. Veritas File System) use a
EXTENT-BASED SYSTEMS
Many newer file systems (I.e. Veritas File System) use a

LINKED ALLOCATION
Each file is a linked list of disk blocks: blocks
LINKED ALLOCATION
Each file is a linked list of disk blocks: blocks
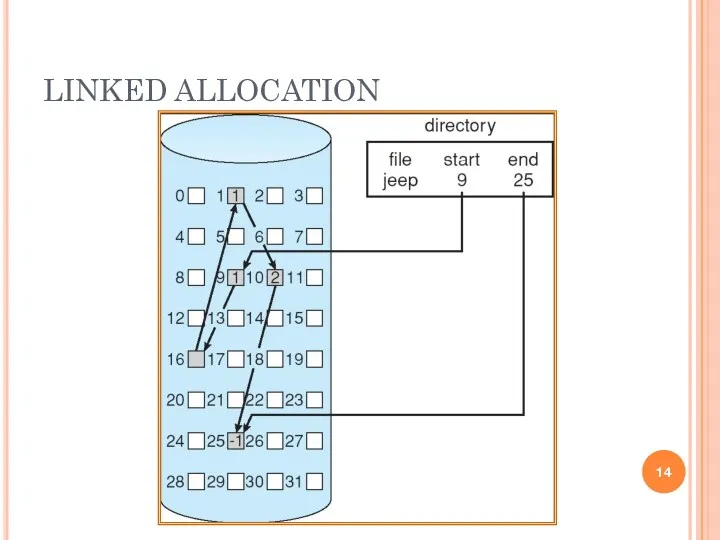
LINKED ALLOCATION
LINKED ALLOCATION
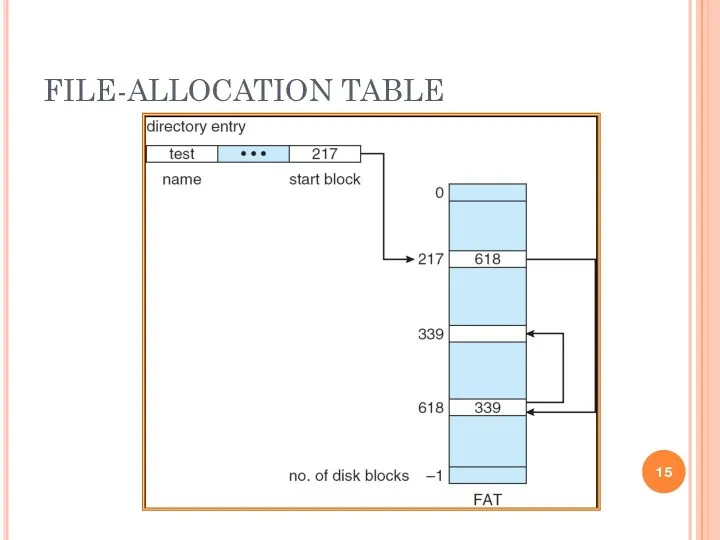
FILE-ALLOCATION TABLE
FILE-ALLOCATION TABLE
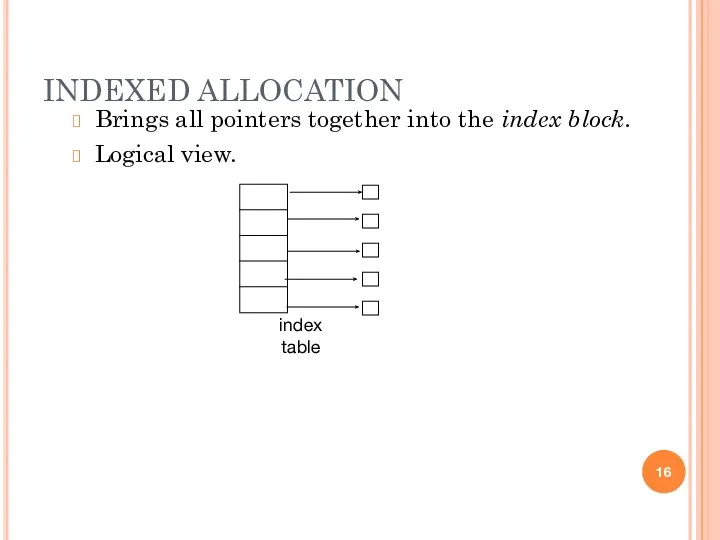
INDEXED ALLOCATION
Brings all pointers together into the index block.
Logical view.
index table
INDEXED ALLOCATION
Brings all pointers together into the index block.
Logical view.
index table
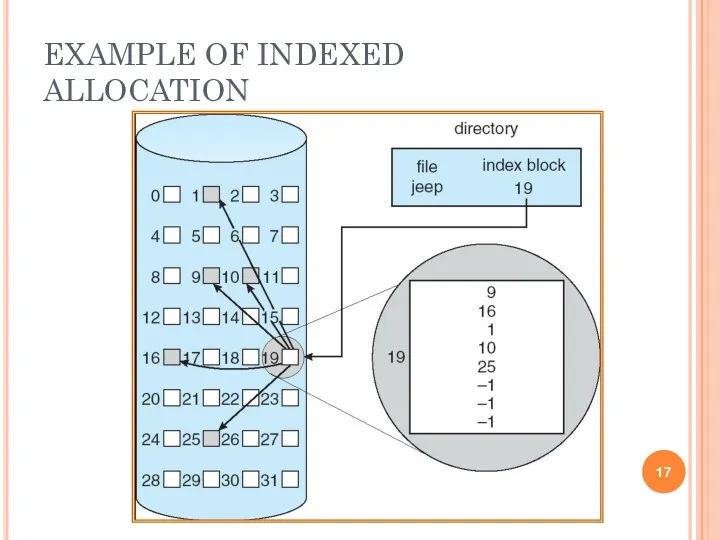
EXAMPLE OF INDEXED ALLOCATION
EXAMPLE OF INDEXED ALLOCATION
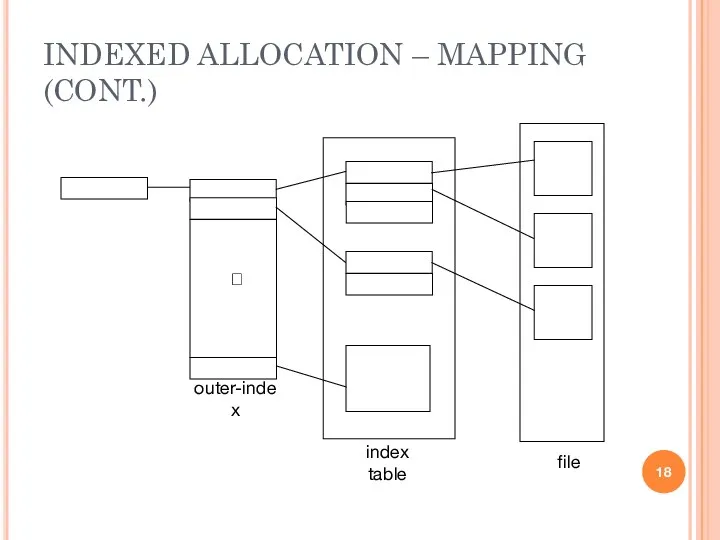
INDEXED ALLOCATION – MAPPING (CONT.)
outer-index
index table
file
INDEXED ALLOCATION – MAPPING (CONT.)
outer-index
index table
file
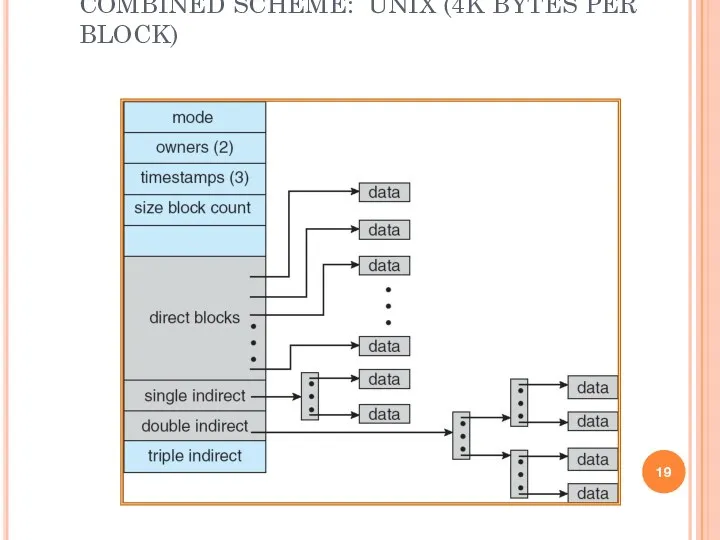
COMBINED SCHEME: UNIX (4K BYTES PER BLOCK)
COMBINED SCHEME: UNIX (4K BYTES PER BLOCK)

LINKED FREE SPACE LIST ON DISK
LINKED FREE SPACE LIST ON DISK

DISTRIBUTED FILE SYSTEM
DISTRIBUTED FILE SYSTEM

DISTRIBUTED FILE SYSTEMS
A special case of distributed system
Allows multi-computer systems to
DISTRIBUTED FILE SYSTEMS
A special case of distributed system
Allows multi-computer systems to

DISTRIBUTED FILE SYSTEMS (CONTINUED)
One of most common uses of distributed computing
Goal:
DISTRIBUTED FILE SYSTEMS (CONTINUED)
One of most common uses of distributed computing
Goal:

NAMING OF DISTRIBUTED FILES
Naming – mapping between logical and physical objects.
A
NAMING OF DISTRIBUTED FILES
Naming – mapping between logical and physical objects.
A

DFS – THREE NAMING SCHEMES
Mount remote directories to local directories, giving
DFS – THREE NAMING SCHEMES
Mount remote directories to local directories, giving

THE SUN NETWORK FILE SYSTEM (NFS)
An implementation and a specification of
THE SUN NETWORK FILE SYSTEM (NFS)
An implementation and a specification of

NFS (CONT.)
Interconnected workstations viewed as a set of independent machines with
NFS (CONT.)
Interconnected workstations viewed as a set of independent machines with

NFS (CONT.)
NFS is designed to operate in a heterogeneous environment of
NFS (CONT.)
NFS is designed to operate in a heterogeneous environment of
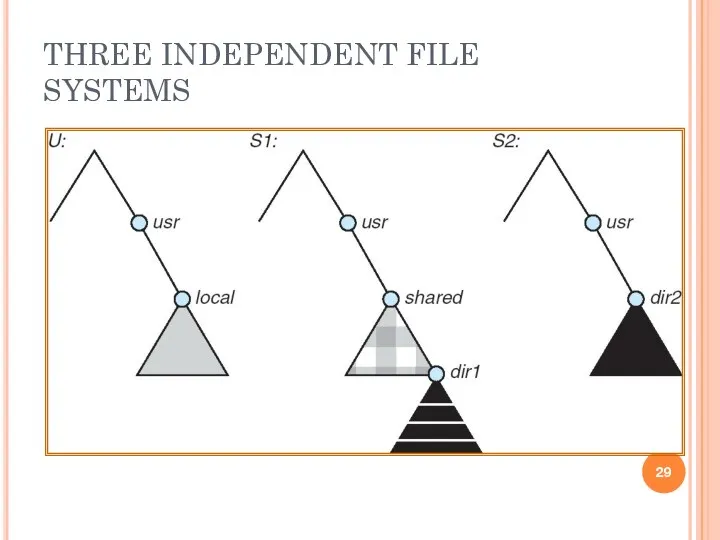
THREE INDEPENDENT FILE SYSTEMS
THREE INDEPENDENT FILE SYSTEMS
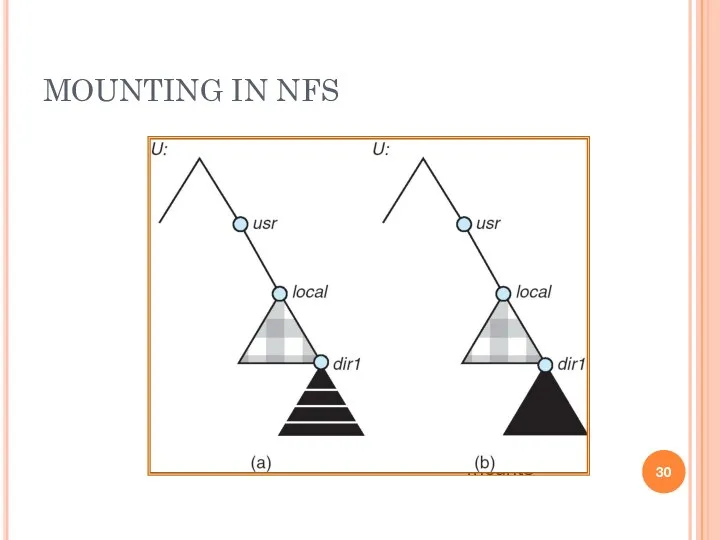
MOUNTING IN NFS
Mounts
Cascading mounts
MOUNTING IN NFS
Mounts
Cascading mounts

NFS MOUNT PROTOCOL
Establishes initial logical connection between server and client
Mount operation
NFS MOUNT PROTOCOL
Establishes initial logical connection between server and client
Mount operation

NFS PROTOCOL
Provides a set of remote procedure calls for remote file
NFS PROTOCOL
Provides a set of remote procedure calls for remote file

THREE MAJOR LAYERS OF NFS ARCHITECTURE
UNIX file-system interface (based on
THREE MAJOR LAYERS OF NFS ARCHITECTURE
UNIX file-system interface (based on
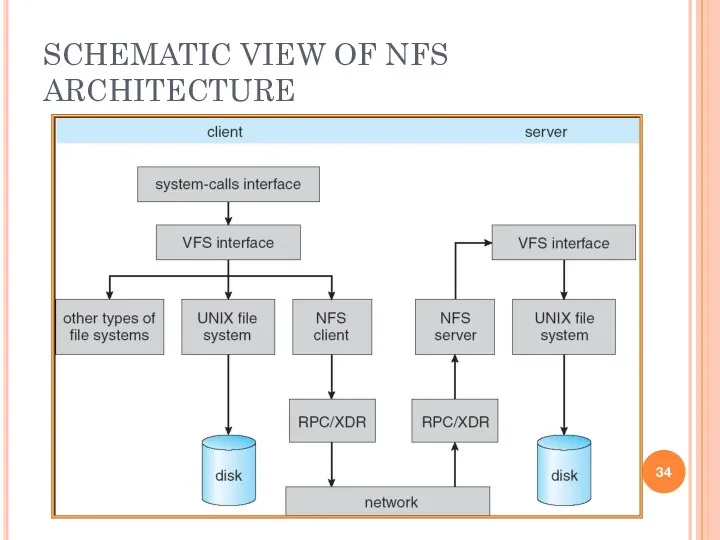
SCHEMATIC VIEW OF NFS ARCHITECTURE
SCHEMATIC VIEW OF NFS ARCHITECTURE

NFS PATH-NAME TRANSLATION
Performed by breaking the path into component names and
NFS PATH-NAME TRANSLATION
Performed by breaking the path into component names and

NFS REMOTE OPERATIONS
Nearly one-to-one correspondence between regular UNIX system calls and
NFS REMOTE OPERATIONS
Nearly one-to-one correspondence between regular UNIX system calls and

ANDREW FILE SYSTEM (AFS)
Completely different kind of file system
Developed at CMU
ANDREW FILE SYSTEM (AFS)
Completely different kind of file system
Developed at CMU

ANDREW FILE SYSTEM (AFS)
Stateful
Single name space
File has the same names everywhere
ANDREW FILE SYSTEM (AFS)
Stateful
Single name space
File has the same names everywhere

AFS
Need for scaling led to reduction of client-server message traffic.
Once a
AFS
Need for scaling led to reduction of client-server message traffic.
Once a

AFS
On file open()
If client has received a callback for file, it
AFS
On file open()
If client has received a callback for file, it

DISTRIBUTED FILE SYSTEMS REQUIREMENTS
Performance is always an issue
Tradeoff between performance
DISTRIBUTED FILE SYSTEMS REQUIREMENTS
Performance is always an issue
Tradeoff between performance
 Операції над об’єктами файлової системи
Операції над об’єктами файлової системи Электронные таблицы. Обработка числовой информации в электронных таблицах. Информатика. 9 класс
Электронные таблицы. Обработка числовой информации в электронных таблицах. Информатика. 9 класс Многообразие компьютеров
Многообразие компьютеров Serialization in .Net. 2023
Serialization in .Net. 2023 Конструкторы и деструкторы
Конструкторы и деструкторы Тезаурусы эпохи Интернет: эволюция взглядов, области применения и расширение категорий пользователей
Тезаурусы эпохи Интернет: эволюция взглядов, области применения и расширение категорий пользователей Using objects in JavaScript. Accessing DOM in JavaScript
Using objects in JavaScript. Accessing DOM in JavaScript Школа глазами домашнего животного. Фотокросс
Школа глазами домашнего животного. Фотокросс Информация. Источники информации. Работа с информационными источниками
Информация. Источники информации. Работа с информационными источниками AutoCAD графикалық жүйесінде дөңгелек сызу
AutoCAD графикалық жүйесінде дөңгелек сызу Презентация к уроку информатики Информационная культура 10 класс
Презентация к уроку информатики Информационная культура 10 класс Аппаратное обеспечение компьютера
Аппаратное обеспечение компьютера Градиентный бустинг
Градиентный бустинг Информационные технологии и их классификация
Информационные технологии и их классификация Архитектура многоуровневой системы управления технологическими процессами нефтяной и газовой промышленности
Архитектура многоуровневой системы управления технологическими процессами нефтяной и газовой промышленности Презентация 7 класс Типы таблиц
Презентация 7 класс Типы таблиц Языки программирования для машинного обучения
Языки программирования для машинного обучения Статические Методы (РПМ)
Статические Методы (РПМ) Интернет-мем
Интернет-мем Автоматизированные системы управления технологическими процессами нефтегазового производства
Автоматизированные системы управления технологическими процессами нефтегазового производства Программное обеспечение персонального компьютера. Software
Программное обеспечение персонального компьютера. Software Компьютерная графика
Компьютерная графика Технология и процесс разработки ПО. Лекция 6
Технология и процесс разработки ПО. Лекция 6 Глобальная компьютерная сеть интернет
Глобальная компьютерная сеть интернет Техническая оптимизация сайта. Ошибки кода и верстки
Техническая оптимизация сайта. Ошибки кода и верстки Разработка внеклассного мероприятия по информатике Путешествие в страну компьютерная графика
Разработка внеклассного мероприятия по информатике Путешествие в страну компьютерная графика Компьютерная графика. Создание gif-анимации
Компьютерная графика. Создание gif-анимации Локальная вычислительная сеть
Локальная вычислительная сеть