- Индексация в СУБД

Содержание
- 2. Понятие индекса Основная проблема в СУБД – это поиск нужных данных за минимальное время Индекс –
- 3. Методы организации индекса Плотным индексом (некластерный индекс) Индексно-прямой файл Первичного ключа Методы организации индексов Вторичного ключа
- 4. Плотный индекс Индексный ключ Талица индекса Основная таблица Содержит последовательность записей одинаковой длины в произвольном порядке.
- 5. Плотный индекс Блок 1 Блок 2 Блок 3 Блок 4 Таблица индекса Основная таблица
- 6. Плотный индекс 2-я таблица индекса Основная таблица Блок 1 Блок 2 Блок 3
- 7. Плотный индекс Алгоритм поиска данных Поиск индексного блока Блок существует Вычислить номер блока основного файла Считать
- 8. Плотный индекс Алгоритм добавления записи Поиск индексного блока начало конец Запись последнего блока основного файла Добавление
- 9. Плотный индекс Алгоритм удаления записи Поиск индексного блока Пометить запись на удаление в блоке начало конец
- 10. Плотный индекс Оценка времени на выполнение основных операций (в максимальном количестве обращений к диску) без использования
- 11. Неплотный индекс Индексный ключ Таблица индекса Основная таблица Содержит последовательность записей одинаковой длины в отсортированном порядке
- 12. Неплотный индекс Основная таблица Блок 1 Блок 2 Блок 3 Блок 1 Блок 2 Таблица индекса
- 13. Неплотный индекс Алгоритм добавления записи Поиск индексного блока начало конец Запись блока основной области Чтение блока
- 14. Неплотный индекс Алгоритм удаления записи Поиск индексного блока начало конец Запись блока основной области Чтение блока
- 15. Неплотный индекс Оценка времени на выполнение основных операций (в максимальном количестве обращений к диску) где N
- 16. Индекс Б-дерево 1 уровень 2 уровень 3 уровень 4 уровень 12500 бл. 12500/73 = 172 бл.
- 17. Индекс Б-дерево Оценка времени на выполнение основных операций (в максимальном количестве обращений к диску) где NLI
- 18. Инвертируемые списки Индексный ключ Индексная таблица 1-го уровня Основная таблица Содержит последовательность записей одинаковой длины в
- 19. Инвертируемые списки Основная таблица Ном.зап. Блок 1 Блок 2 Блок 3 Блок 4 Блок 5 Индексная
- 20. Рекомендации по созданию индексов Факторы, определяющие «хороший» индекс - число столбцов в индексе не более 4-5
- 21. Оператор создания индекса СУБД всегда создает индекс для первичного ключа таблицы Для создания индексов для других
- 22. Оператор создания индекса CREATE [ UNIDUE ] [ CLASTERED | NOCLASTERED ] INDEX имя_индекса ON {имя_таблицы
- 24. Скачать презентацию

Понятие индекса
Основная проблема в СУБД – это поиск нужных данных за
Понятие индекса
Основная проблема в СУБД – это поиск нужных данных за
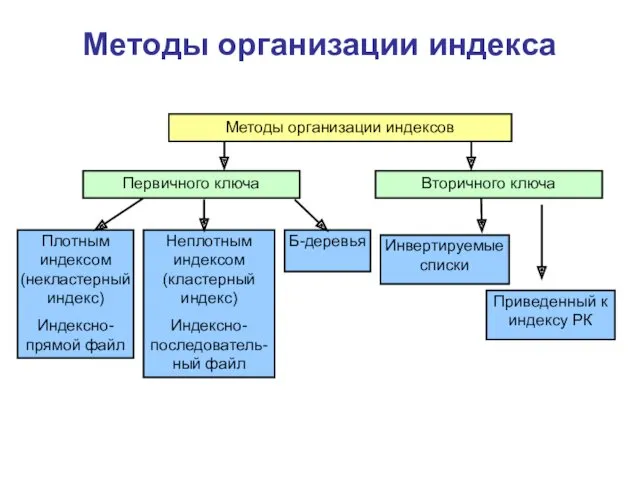
Методы организации индекса
Плотным индексом (некластерный индекс)
Индексно-прямой файл
Первичного ключа
Методы организации индексов
Вторичного
Методы организации индекса
Плотным индексом (некластерный индекс)
Индексно-прямой файл
Первичного ключа
Методы организации индексов
Вторичного
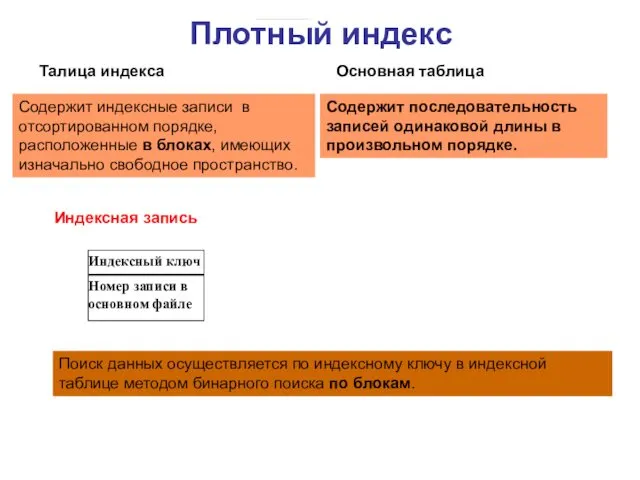
Плотный индекс
Индексный ключ
Талица индекса
Основная таблица
Содержит последовательность записей одинаковой длины в произвольном
Плотный индекс
Индексный ключ
Талица индекса
Основная таблица
Содержит последовательность записей одинаковой длины в произвольном
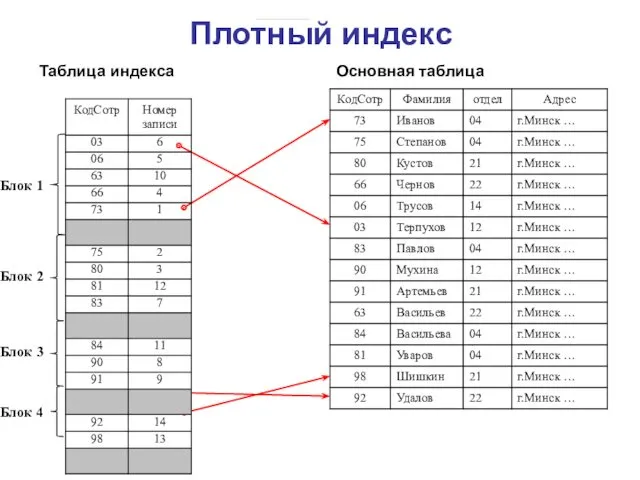
Плотный индекс
Блок 1
Блок 2
Блок 3
Блок 4
Таблица индекса
Основная таблица
Плотный индекс
Блок 1
Блок 2
Блок 3
Блок 4
Таблица индекса
Основная таблица
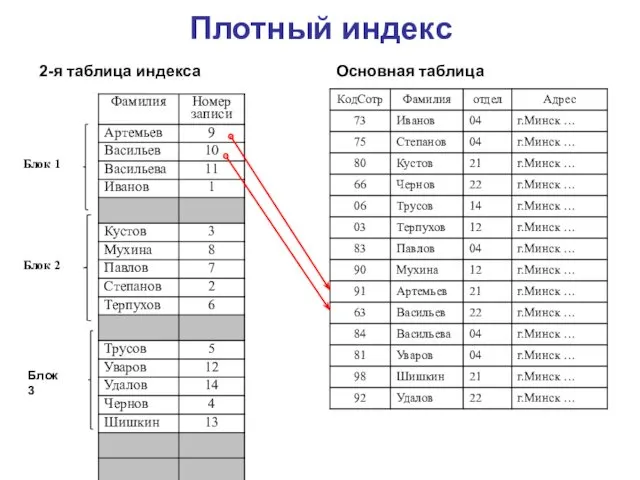
Плотный индекс
2-я таблица индекса
Основная таблица
Блок 1
Блок 2
Блок 3
Плотный индекс
2-я таблица индекса
Основная таблица
Блок 1
Блок 2
Блок 3
Плотный индекс
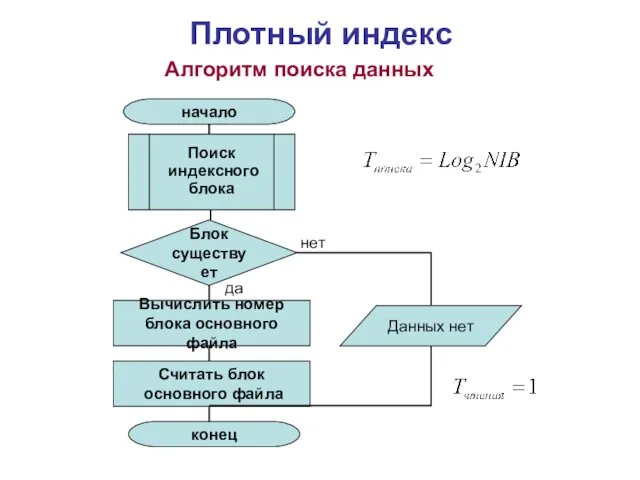
Алгоритм поиска данных
Поиск
индексного
блока
Блок
существует
Вычислить номер
блока основного файла
Считать
Плотный индекс
Алгоритм поиска данных
Поиск
индексного
блока
Блок
существует
Вычислить номер
блока основного файла
Считать
Плотный индекс
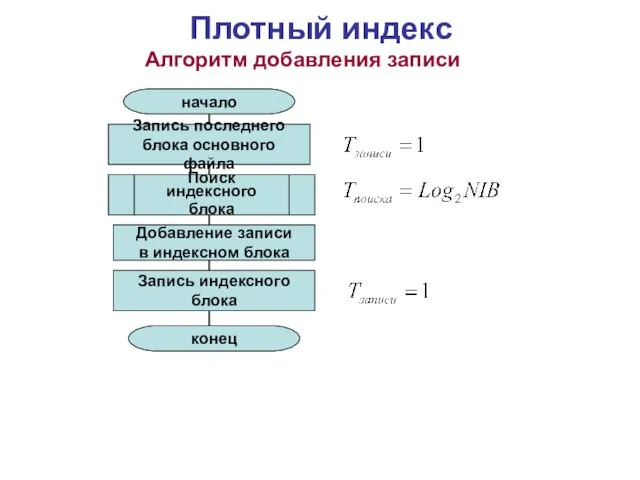
Алгоритм добавления записи
Поиск индексного
блока
начало
конец
Запись последнего
блока основного файла
Добавление записи
в
Плотный индекс
Алгоритм добавления записи
Поиск индексного
блока
начало
конец
Запись последнего
блока основного файла
Добавление записи
в
Плотный индекс
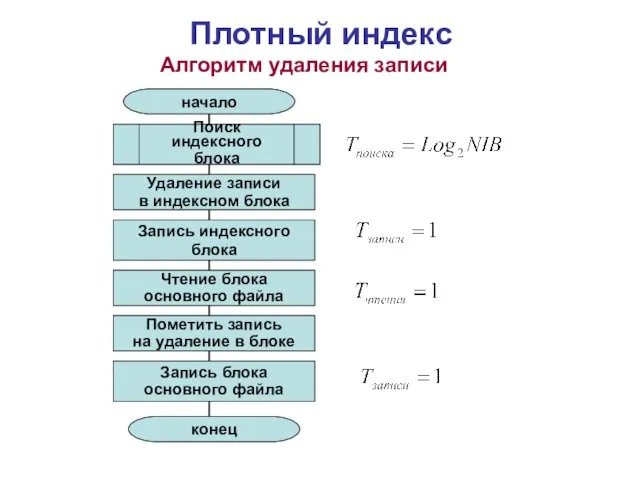
Алгоритм удаления записи
Поиск индексного
блока
Пометить запись
на удаление в блоке
Плотный индекс
Алгоритм удаления записи
Поиск индексного
блока
Пометить запись
на удаление в блоке

Плотный индекс
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
Плотный индекс
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
Неплотный индекс
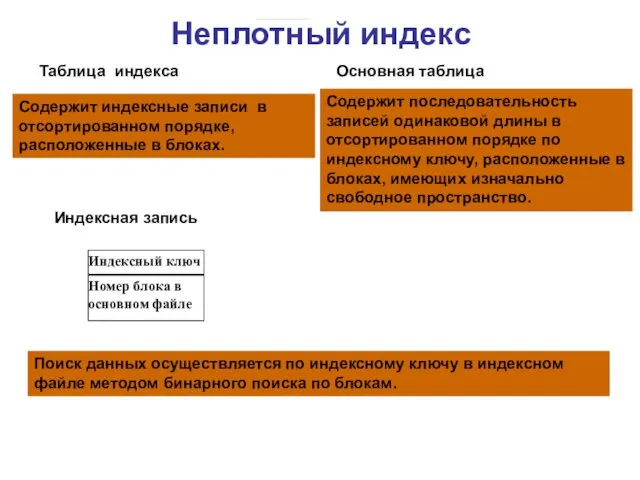
Индексный ключ
Таблица индекса
Основная таблица
Содержит последовательность записей одинаковой длины в
Неплотный индекс
Индексный ключ
Таблица индекса
Основная таблица
Содержит последовательность записей одинаковой длины в
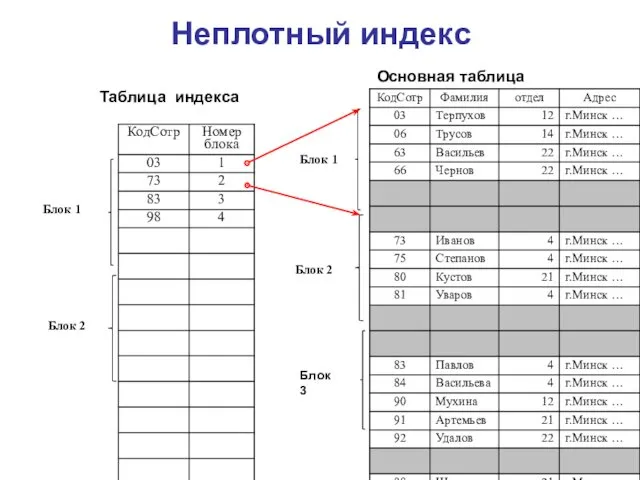
Неплотный индекс
Основная таблица
Блок 1
Блок 2
Блок 3
Блок 1
Блок 2
Таблица индекса
Неплотный индекс
Основная таблица
Блок 1
Блок 2
Блок 3
Блок 1
Блок 2
Таблица индекса
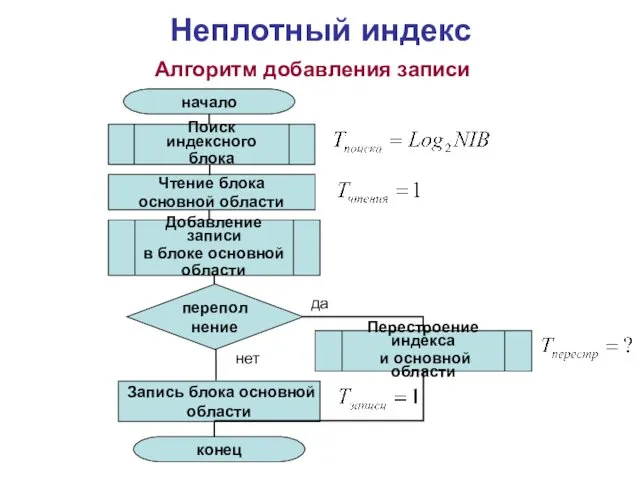
Неплотный индекс
Алгоритм добавления записи
Поиск индексного
блока
начало
конец
Запись блока основной
области
Чтение блока
основной области
Добавление записи
Неплотный индекс
Алгоритм добавления записи
Поиск индексного
блока
начало
конец
Запись блока основной
области
Чтение блока
основной области
Добавление записи
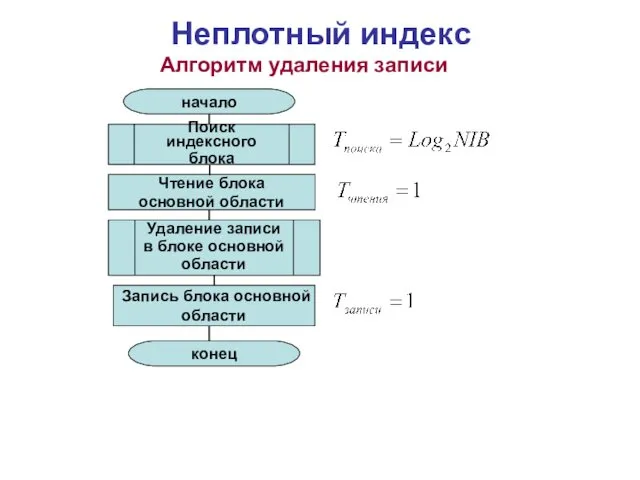
Неплотный индекс
Алгоритм удаления записи
Поиск индексного
блока
начало
конец
Запись блока основной
области
Чтение блока
основной области
Удаление записи
Неплотный индекс
Алгоритм удаления записи
Поиск индексного
блока
начало
конец
Запись блока основной
области
Чтение блока
основной области
Удаление записи

Неплотный индекс
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
Неплотный индекс
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
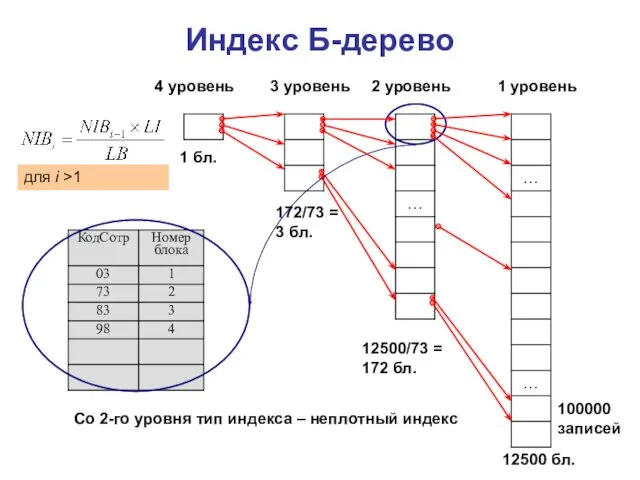
Индекс Б-дерево
1 уровень
2 уровень
3 уровень
4 уровень
12500 бл.
12500/73 = 172 бл.
172/73 =
Индекс Б-дерево
1 уровень
2 уровень
3 уровень
4 уровень
12500 бл.
12500/73 = 172 бл.
172/73 =

Индекс Б-дерево
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
Индекс Б-дерево
Оценка времени на выполнение основных операций
(в максимальном количестве обращений к
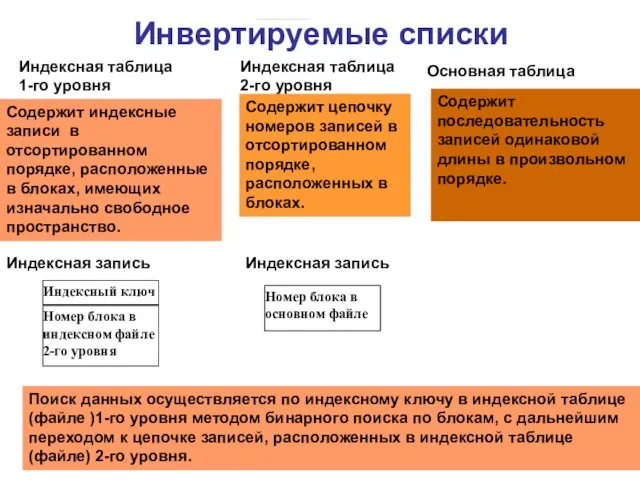
Инвертируемые списки
Индексный ключ
Индексная таблица 1-го уровня
Основная таблица
Содержит последовательность записей одинаковой
Инвертируемые списки
Индексный ключ
Индексная таблица 1-го уровня
Основная таблица
Содержит последовательность записей одинаковой
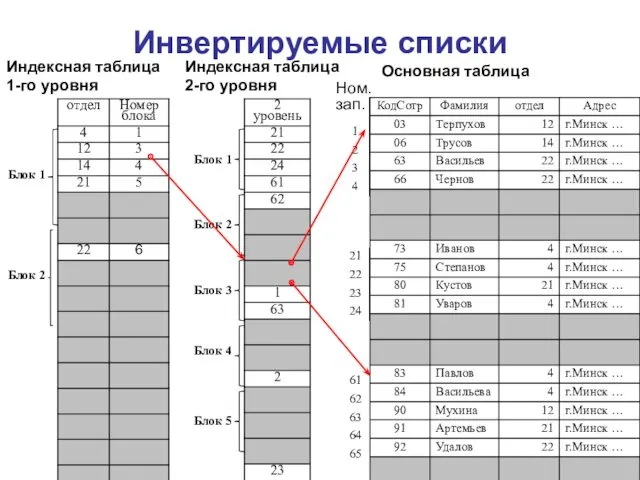
Инвертируемые списки
Основная таблица
Ном.зап.
Блок 1
Блок 2
Блок 3
Блок 4
Блок 5
Индексная таблица 1-го уровня
Блок
Инвертируемые списки
Основная таблица
Ном.зап.
Блок 1
Блок 2
Блок 3
Блок 4
Блок 5
Индексная таблица 1-го уровня
Блок

Рекомендации по созданию индексов
Факторы, определяющие «хороший» индекс
- число столбцов в
Рекомендации по созданию индексов
Факторы, определяющие «хороший» индекс
- число столбцов в

Оператор создания индекса
СУБД всегда создает индекс для первичного ключа таблицы
Для создания
Оператор создания индекса
СУБД всегда создает индекс для первичного ключа таблицы
Для создания
![Оператор создания индекса CREATE [ UNIDUE ] [ CLASTERED |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1958/slide-21.jpg)
Оператор создания индекса
CREATE [ UNIDUE ]
[ CLASTERED | NOCLASTERED ]
Оператор создания индекса
CREATE [ UNIDUE ]
[ CLASTERED | NOCLASTERED ]
 Целевая аудитория
Целевая аудитория Конвергентная журналистика
Конвергентная журналистика История языков программирования
История языков программирования Типы алгоритмов. Линейные алгоритмы
Типы алгоритмов. Линейные алгоритмы Презентация Профессии, по которым необходимы знания по программе Microsoft Access
Презентация Профессии, по которым необходимы знания по программе Microsoft Access Журналистика. Первые шаги в создании сюжетов
Журналистика. Первые шаги в создании сюжетов Практична робота №4 Анімація тексту
Практична робота №4 Анімація тексту Основы работы с пакетом имитационного моделирования Arena
Основы работы с пакетом имитационного моделирования Arena Введение в проектную деятельность. Лекция 1. Введение. Цифровые порты ввода-вывода
Введение в проектную деятельность. Лекция 1. Введение. Цифровые порты ввода-вывода Сабақтың тақырыбы: Ақпаратты сығу. Ақпаратты қорғау. Вирусқа қарсы программалар
Сабақтың тақырыбы: Ақпаратты сығу. Ақпаратты қорғау. Вирусқа қарсы программалар Проблемы изучения информационных технологий в общеобразовательной и профессиональной школе
Проблемы изучения информационных технологий в общеобразовательной и профессиональной школе Компьютерная технология обработки текстовой информации
Компьютерная технология обработки текстовой информации Конспект урока информатики на тему Исследование физической модели
Конспект урока информатики на тему Исследование физической модели Платформы HeadHunter
Платформы HeadHunter Конспект урока по теме Информация и знания.
Конспект урока по теме Информация и знания. Java. Inheritance
Java. Inheritance Роль графического дизайнера в мультипликации
Роль графического дизайнера в мультипликации Интернет-портал администрации Масальского сельсовета, Алтайского края
Интернет-портал администрации Масальского сельсовета, Алтайского края Захист інформації в банківських та комерційних системах
Захист інформації в банківських та комерційних системах Компьютерные вирусы, признаки заражения
Компьютерные вирусы, признаки заражения Test automation
Test automation Битва за килобиты
Битва за килобиты Основы интернет-технологий. PL/SQL. (Лекция 10)
Основы интернет-технологий. PL/SQL. (Лекция 10) Особенности электронной почты
Особенности электронной почты Презентация к первому уроку по теме Системы счисления
Презентация к первому уроку по теме Системы счисления Устройство персонального компьютера
Устройство персонального компьютера Компьютерные вирусы и защита от них
Компьютерные вирусы и защита от них Списки (окончание). Графы. Лекция 9, 10
Списки (окончание). Графы. Лекция 9, 10