Инструменты для распознавания текстов и системы компьютерного перевода. Оценка количественных параметров текстовых документов презентация
- Инструменты для распознавания текстов и системы компьютерного перевода. Оценка количественных параметров текстовых документов

Содержание
- 2. Программы оптического распознавания документов Для ввода текстов в память компьютера с бумажных носителей используют сканеры и
- 3. Программы оптического распознавания документов Вместо сканера можно использовать цифровой фотоаппарат или камеру мобильного телефона. Фотографии текста
- 4. Программа ABBYY FineReader Программа позволяет сканировать и преобразовывать с оптическим распознаванием изображения документов (фотографий, результатов сканирования,
- 5. Компьютерные словари Компьютерные словари выполняют перевод отдельных слов и словосочетаний. Компьютерные словари обеспечивают мгновенный поиск словарных
- 6. Программа ABBYY Lingvo Одной из наиболее известных программ-словарей. Имеются пакеты для многих популярных операционных систем, таких
- 7. Конструирование текста на требуемом языке Для перевода текстовых документов применяются программы-переводчики. Формальное знание языка Анализ текста
- 8. Одной из наиболее известных у нас программ-переводчиков является PROMT от одноимённой российской компании PROMT (проприетарное программное
- 9. Google Переводчик (англ. Google Translate) — веб-служба компании Google, предназначенная для автоматического перевода части текста или
- 10. Представление текстовой информации в памяти компьютера Текст состоит из символов - букв, цифр, знаков препинания и
- 11. Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц. Фрагмент кодовой таблицы ASCII
- 12. 8-битные коды русских букв Код ASCII содержит изначально 128 символов (0–127). Среди них нет русских букв.
- 13. Коды русских букв в разных кодовых таблицах
- 14. Кодовая таблица символов Unicode позволяет пользоваться более чем двумя языками в одном тексте. В Unicode каждый
- 15. Информационный объём фрагмента текста I = K×i I – информационный объём сообщения K – количество символов
- 16. Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания
- 17. Задача 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из
- 18. Задача 3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде,
- 19. Ответ: 3,39 Мбайт. K = 740 × 80 × 60 N = 256 I - ?
- 20. Задание Откройте стр. 193 – Задание 4.16. Создайте в личной папке (папка Фамилия) файл типа документ
- 21. Работаем за компьютером
- 23. Скачать презентацию
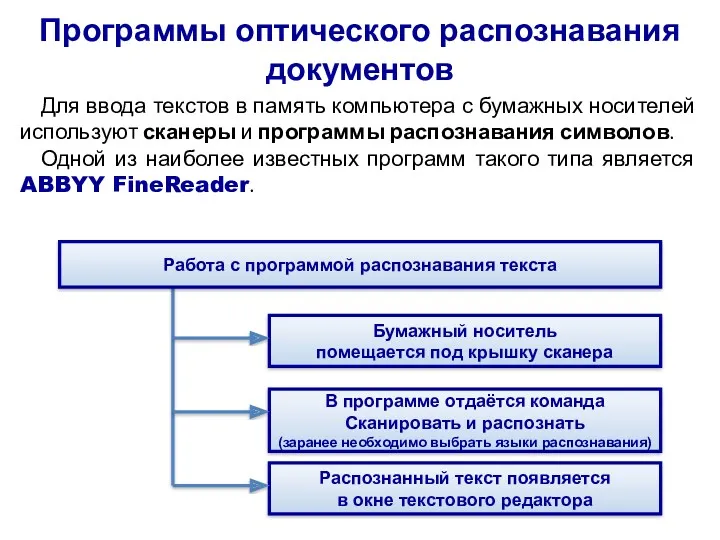
Программы оптического распознавания документов
Для ввода текстов в память компьютера с бумажных
Программы оптического распознавания документов
Для ввода текстов в память компьютера с бумажных
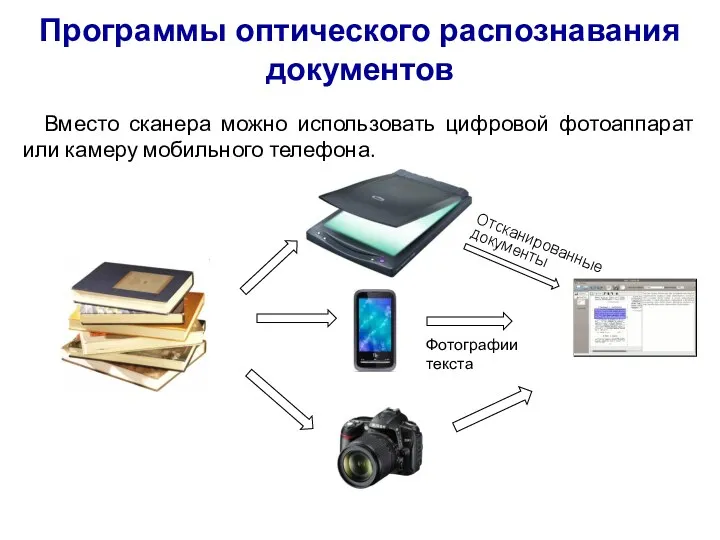
Программы оптического распознавания документов
Вместо сканера можно использовать цифровой фотоаппарат или камеру
Программы оптического распознавания документов
Вместо сканера можно использовать цифровой фотоаппарат или камеру

Программа ABBYY FineReader
Программа позволяет сканировать и преобразовывать с оптическим распознаванием изображения
Программа ABBYY FineReader
Программа позволяет сканировать и преобразовывать с оптическим распознаванием изображения
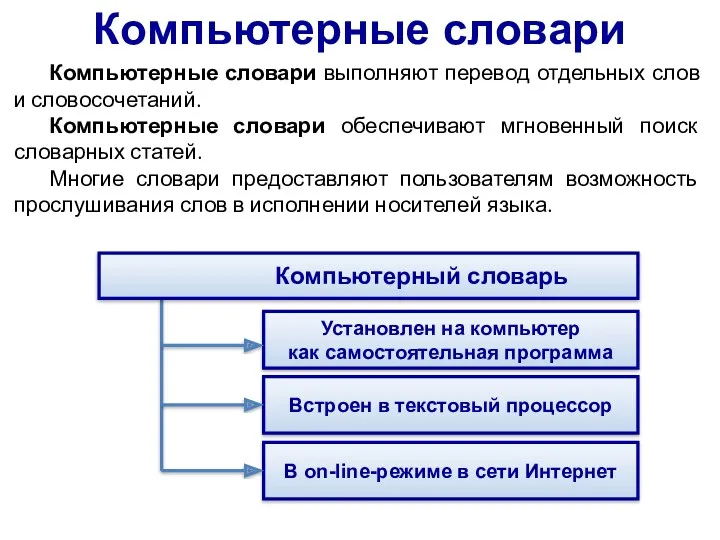
Компьютерные словари
Компьютерные словари выполняют перевод отдельных слов и словосочетаний.
Компьютерные словари обеспечивают
Компьютерные словари
Компьютерные словари выполняют перевод отдельных слов и словосочетаний.
Компьютерные словари обеспечивают

Программа ABBYY Lingvo
Одной из наиболее известных программ-словарей. Имеются пакеты для многих
Программа ABBYY Lingvo
Одной из наиболее известных программ-словарей. Имеются пакеты для многих
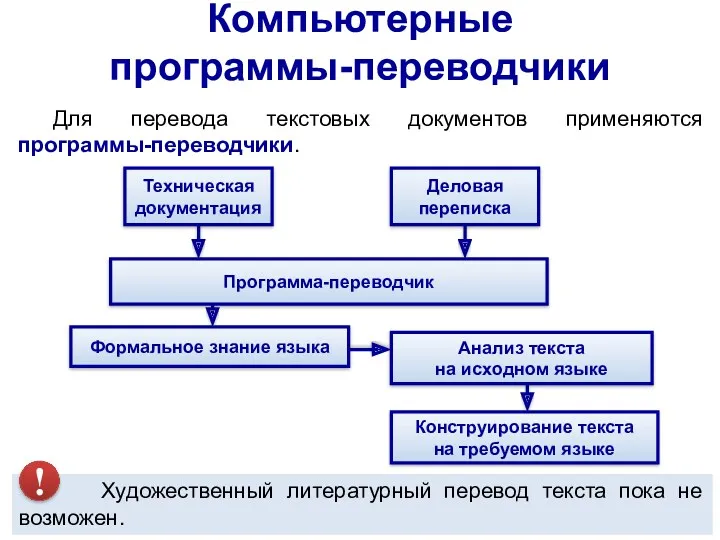
Конструирование текста
на требуемом языке
Для перевода текстовых документов применяются программы-переводчики.
Формальное
Конструирование текста
на требуемом языке
Для перевода текстовых документов применяются программы-переводчики.
Формальное

Одной из наиболее известных у нас программ-переводчиков является PROMT от одноимённой
Одной из наиболее известных у нас программ-переводчиков является PROMT от одноимённой

Google Переводчик (англ. Google Translate) — веб-служба компании Google, предназначенная для
Google Переводчик (англ. Google Translate) — веб-служба компании Google, предназначенная для

Представление текстовой информации
в памяти компьютера
Текст состоит из символов - букв, цифр,
Представление текстовой информации
в памяти компьютера
Текст состоит из символов - букв, цифр,
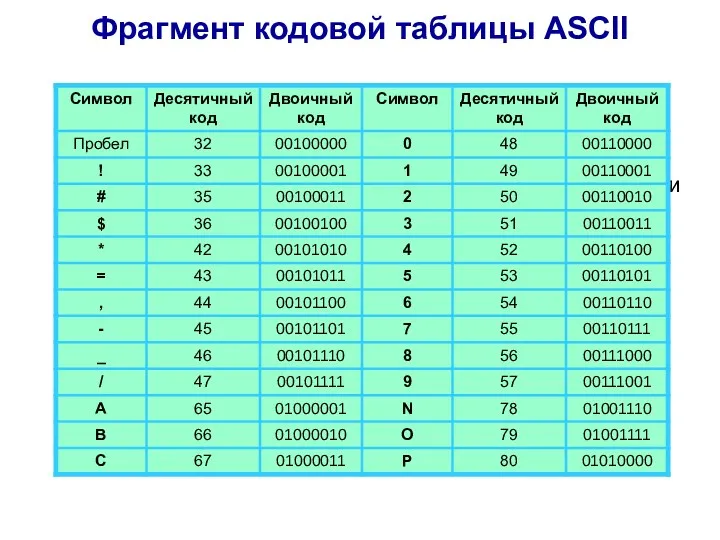
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых
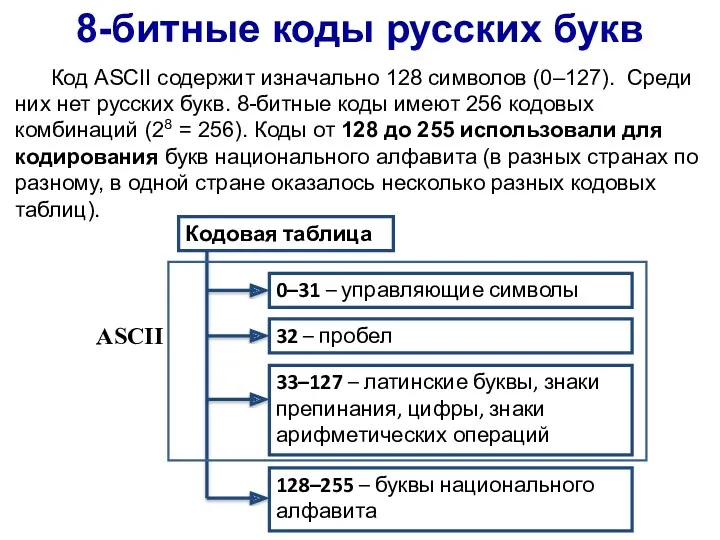
8-битные коды русских букв
Код ASCII содержит изначально 128 символов (0–127). Среди
8-битные коды русских букв
Код ASCII содержит изначально 128 символов (0–127). Среди
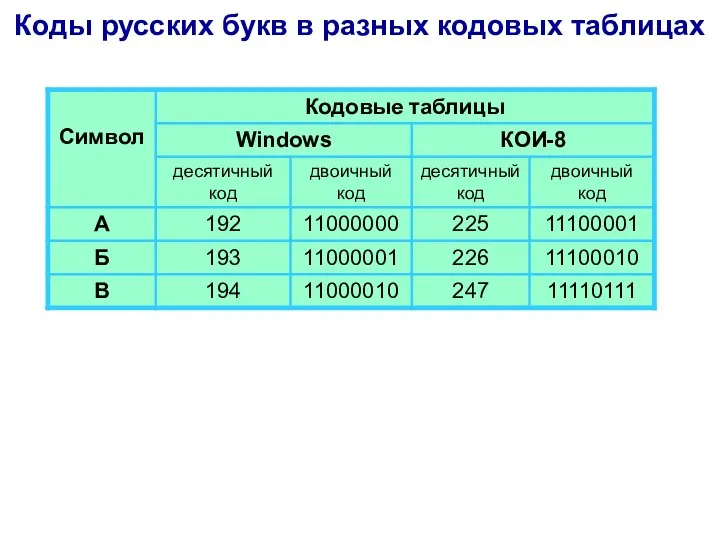
Коды русских букв в разных кодовых таблицах
Коды русских букв в разных кодовых таблицах

Кодовая таблица символов Unicode позволяет пользоваться более чем двумя языками в
Кодовая таблица символов Unicode позволяет пользоваться более чем двумя языками в

Информационный объём фрагмента текста
I = K×i
I – информационный объём сообщения
K –
Информационный объём фрагмента текста
I = K×i
I – информационный объём сообщения
K –

Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему

Задача 2. В кодировке Unicode на каждый символ отводится два байта.
Задача 2. В кодировке Unicode на каждый символ отводится два байта.

Задача 3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке,
Задача 3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке,

Ответ: 3,39 Мбайт.
K = 740 × 80 × 60
N = 256
Ответ: 3,39 Мбайт.
K = 740 × 80 × 60
N = 256

Задание
Откройте стр. 193 – Задание 4.16.
Создайте в личной папке (папка Фамилия)
Задание
Откройте стр. 193 – Задание 4.16.
Создайте в личной папке (папка Фамилия)

Работаем за компьютером
Работаем за компьютером
 Основы программирования: ТЕМА 04. УСЛОВНЫЙ ОПЕРАТОР.
Основы программирования: ТЕМА 04. УСЛОВНЫЙ ОПЕРАТОР. Программирование. Парадигма программирования
Программирование. Парадигма программирования Internet Security
Internet Security Сравнительный анализ дизайна интернет-сайтов
Сравнительный анализ дизайна интернет-сайтов Моделирование в электронных таблицах
Моделирование в электронных таблицах Строки. Таблица символов ASCII. Обращение к символам строки. Процедуры работы со строками
Строки. Таблица символов ASCII. Обращение к символам строки. Процедуры работы со строками Электронная таблица Excel
Электронная таблица Excel ВКР: Проектирование и разработка базы данных аэропорта
ВКР: Проектирование и разработка базы данных аэропорта Сети и системы телекоммуникаций. Введение в компьютерные сети
Сети и системы телекоммуникаций. Введение в компьютерные сети Әдеби мәліметтер көздерінің критикалық анализі. Плагиат және антиплагиат
Әдеби мәліметтер көздерінің критикалық анализі. Плагиат және антиплагиат Презентация Ссылки в электронных таблицах Microsoft Excel
Презентация Ссылки в электронных таблицах Microsoft Excel Функции пользователя - классы памяти
Функции пользователя - классы памяти Современные СМИ: телевидение
Современные СМИ: телевидение Розвиток інформатики в Україні
Розвиток інформатики в Україні Справочные, энциклопедические издания. Терминологические, лингвистические словари
Справочные, энциклопедические издания. Терминологические, лингвистические словари Тестирование мобильных приложений. (Лекция 19)
Тестирование мобильных приложений. (Лекция 19) Тема1-Компьютерная Графика-Основные понятия
Тема1-Компьютерная Графика-Основные понятия Функції. Лекція 5.0
Функції. Лекція 5.0 Программирование
Программирование Реализация коррекционно-образовательного процесса в учреждении для детей с нарушениями развития с использованием ИКТ
Реализация коррекционно-образовательного процесса в учреждении для детей с нарушениями развития с использованием ИКТ Корпоративна комп’ютерна мережа сервісного центру
Корпоративна комп’ютерна мережа сервісного центру Жасанды нейрондық желілер. 3 дарис
Жасанды нейрондық желілер. 3 дарис USB Driver. Marvell Confidential
USB Driver. Marvell Confidential Памятка по оформлению земельных отношений. Как получить услуги Департамента городского имущества города Москвы онлайн?
Памятка по оформлению земельных отношений. Как получить услуги Департамента городского имущества города Москвы онлайн? Сбор информации
Сбор информации Adobe Photoshop графикалық бағдарламасы
Adobe Photoshop графикалық бағдарламасы Компьютерная графика. Векторная и растровая графика
Компьютерная графика. Векторная и растровая графика Условная функция и логические выражения в табличном процессоре Excel
Условная функция и логические выражения в табличном процессоре Excel