- Инструменты Эксплуатации. Операционные системы

Содержание
- 2. План занятия Теория - Операционные системы - Мониторинг - Средства Диагностики - Bash и другие скриптовые
- 3. Операционные системы
- 4. Дистрибутивы Linux Как развивалось и множилось
- 8. Сравнение производительности ОС 1) Создание и удаление директории - Во время теста создётся большое количество вложенных
- 9. 2) Синтетический тест, с использованием MYSQL Тесты проводились по 3 раза без заметной разницы, количество созданных
- 11. Мониторинг
- 12. ЗАЧЕМ ВСЁ ЭТО НУЖНО??? Раньше: Мониторились, в основном, системные показатели: CPU, память, диски, сеть. Этого вполне
- 16. Средства Диагностики Материалы: https://habr.com/company/ua-hosting/blog/281519/
- 17. #!Bash https://linuxconfig.org/bash-scripting-tutorial Пример #!/bin/bash echo -e "Hi, please type the word: \c " read word echo
- 19. Скачать презентацию

План занятия
Теория
- Операционные системы
- Мониторинг
- Средства Диагностики
План занятия
Теория
- Операционные системы
- Мониторинг
- Средства Диагностики

Операционные системы
Операционные системы
Дистрибутивы Linux
Как развивалось и множилось
Дистрибутивы Linux
Как развивалось и множилось

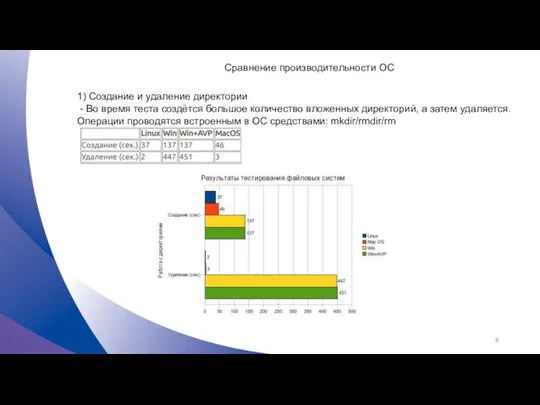
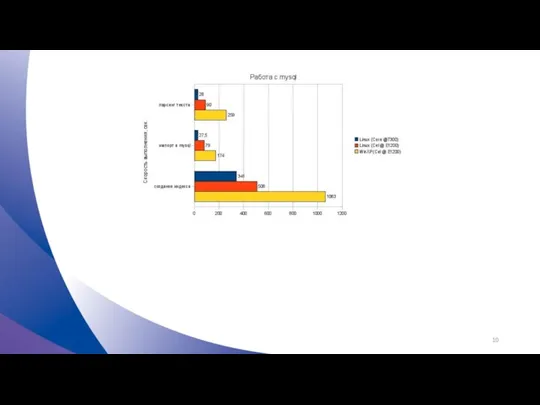
Сравнение производительности ОС
1) Создание и удаление директории
- Во время теста
Сравнение производительности ОС
1) Создание и удаление директории
- Во время теста

2) Синтетический тест, с использованием MYSQL
Тесты проводились по 3 раза без
2) Синтетический тест, с использованием MYSQL
Тесты проводились по 3 раза без

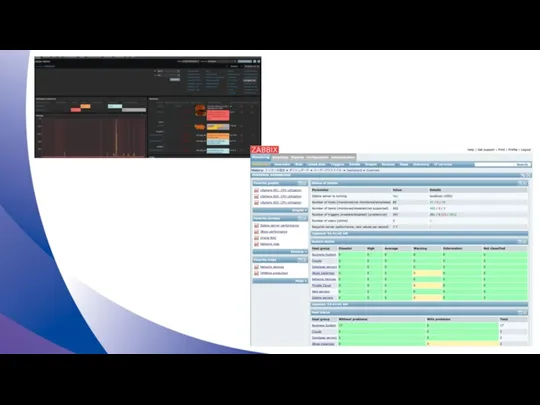
Мониторинг
Мониторинг

ЗАЧЕМ ВСЁ ЭТО НУЖНО???
Раньше:
Мониторились, в основном, системные показатели: CPU, память, диски,
ЗАЧЕМ ВСЁ ЭТО НУЖНО???
Раньше:
Мониторились, в основном, системные показатели: CPU, память, диски,
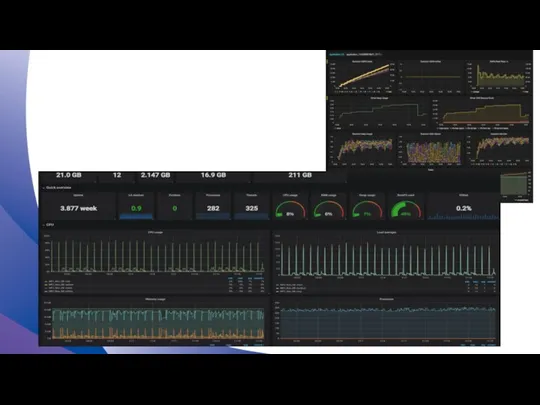
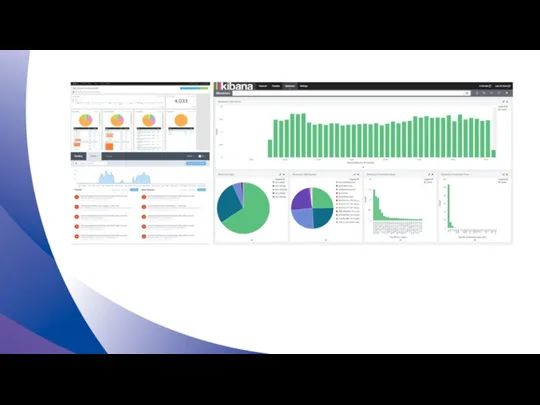

Средства Диагностики
Материалы:
https://habr.com/company/ua-hosting/blog/281519/
Средства Диагностики
Материалы:
https://habr.com/company/ua-hosting/blog/281519/

#!Bash
https://linuxconfig.org/bash-scripting-tutorial
Пример
#!/bin/bash
echo -e "Hi, please type the word: \c "
read word
echo "The
#!Bash
https://linuxconfig.org/bash-scripting-tutorial
Пример
#!/bin/bash
echo -e "Hi, please type the word: \c "
read word
echo "The
 Виды контента. Занятие №10 Основатель
Виды контента. Занятие №10 Основатель Сравнительный анализ антивирусных программ
Сравнительный анализ антивирусных программ Элементная база ЭВМ
Элементная база ЭВМ Дети в интернете. Викторина для учащихся начальных классов
Дети в интернете. Викторина для учащихся начальных классов PR органов государственной власти
PR органов государственной власти CSS 3. Cascading Style Sheets
CSS 3. Cascading Style Sheets Презентация Логика. Тренировочные задания ЕГЭ
Презентация Логика. Тренировочные задания ЕГЭ Первая пара. Динамическое пр-е и рекурсия
Первая пара. Динамическое пр-е и рекурсия Виды Баз Данных
Виды Баз Данных Словарная работа по теме Интернет.
Словарная работа по теме Интернет. Программалық жасақтаманы таңдау
Программалық жасақтаманы таңдау Мониторинг состояния московского книжного рынка
Мониторинг состояния московского книжного рынка Онлайн-сервисы и пространство в сети Интернет
Онлайн-сервисы и пространство в сети Интернет Урок информатики в 5 классе на тему: Метод координат
Урок информатики в 5 классе на тему: Метод координат Петрохимические программы. (Лекция 7)
Петрохимические программы. (Лекция 7) Аватария
Аватария Oxyfuel Cutting Routine
Oxyfuel Cutting Routine Правильное место для торговли бинарными опционами
Правильное место для торговли бинарными опционами Система Ладошки
Система Ладошки Создание анимированных сорбонок для начальной школы
Создание анимированных сорбонок для начальной школы Язык программирования Pascal. Основные понятия
Язык программирования Pascal. Основные понятия Устройство компьютерной сети
Устройство компьютерной сети Итераторы, генераторы и декораторы. Python 5.0
Итераторы, генераторы и декораторы. Python 5.0 Характеристика специализированных изданий
Характеристика специализированных изданий Обработка информации. Разнообразие задач обработки информации
Обработка информации. Разнообразие задач обработки информации История развития вычислительной техники
История развития вычислительной техники Своя игра по информатике и истории для старшеклассников
Своя игра по информатике и истории для старшеклассников Використання графічних можливостей технології Windows Forms
Використання графічних можливостей технології Windows Forms