- Кодирование и обработка текстовой информации

Содержание
- 2. Информация, выраженная с помощью естественных и формальных языков(системы счисления, языки программирования) в письменной форме, обычно называется
- 3. Кодирование и декодирование текстовой информации Для кодирования прописных и строчных букв русского и латинского алфавитов, цифр
- 4. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до
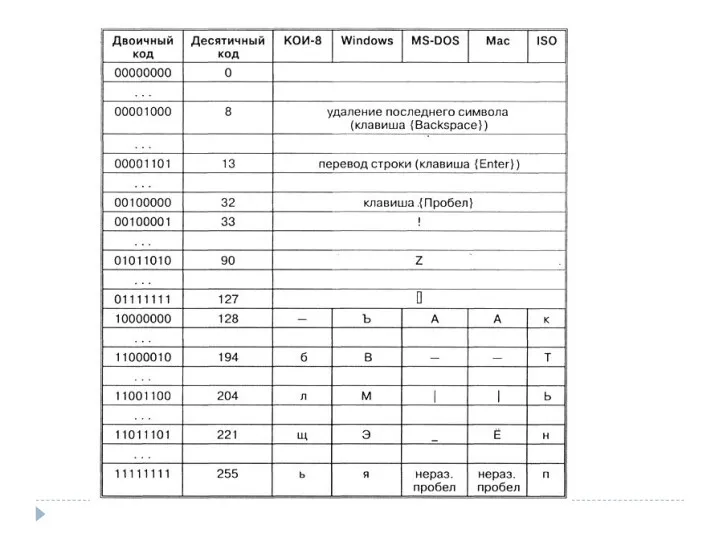
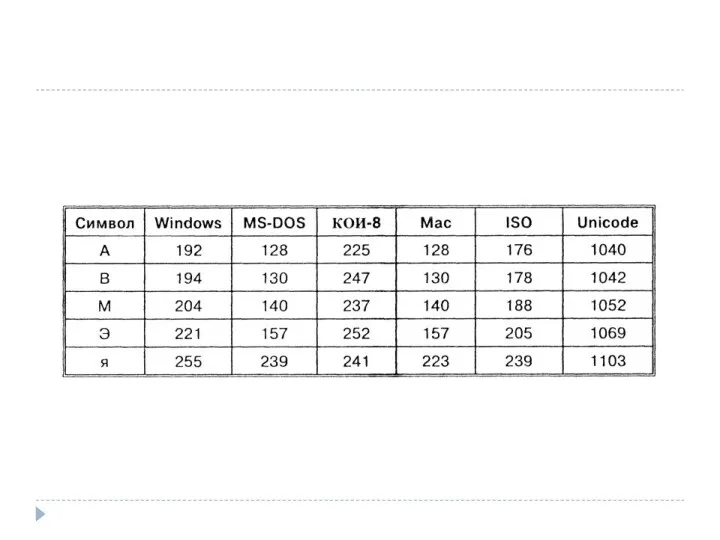
- 5. Кодировки русского алфавита Важно, что присваивание символу конкретного кода – это вопрос соглашения, которое фиксируется в
- 9. Скачать презентацию

Информация, выраженная с помощью естественных и формальных языков(системы счисления, языки программирования)
Информация, выраженная с помощью естественных и формальных языков(системы счисления, языки программирования)

Кодирование и декодирование текстовой информации
Для кодирования прописных и строчных букв русского
Кодирование и декодирование текстовой информации
Для кодирования прописных и строчных букв русского

Кодирование заключается в том, что каждому символу ставится в соответствие уникальный
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный

Кодировки русского алфавита
Важно, что присваивание символу конкретного кода – это вопрос
Кодировки русского алфавита
Важно, что присваивание символу конкретного кода – это вопрос
 Понятие информационного процесса. Сбор и обработка информации
Понятие информационного процесса. Сбор и обработка информации За 7 печатями
За 7 печатями Группы смерти в Сети
Группы смерти в Сети Python
Python Обслуживание диска. Жесткий диск
Обслуживание диска. Жесткий диск Интервью, как жанр тележурналистики
Интервью, как жанр тележурналистики Государственная автоматизированная система Законотворчество
Государственная автоматизированная система Законотворчество Облачные технологии в управлении проектами
Облачные технологии в управлении проектами Конспект урока по теме Создание и редактирование диаграмм в среде Excel
Конспект урока по теме Создание и редактирование диаграмм в среде Excel NET Windows Forms
NET Windows Forms Обработка прерываний
Обработка прерываний Программирование на языке Си
Программирование на языке Си Интернет-зависимость
Интернет-зависимость Этика, право и безопасность в информационной сфере. Нормативно-правовые документы ДНР
Этика, право и безопасность в информационной сфере. Нормативно-правовые документы ДНР Мы этой памяти верны
Мы этой памяти верны Движение робота
Движение робота Кодирование и обработка звуковой информации
Кодирование и обработка звуковой информации New homepage
New homepage Языки и системы программирования
Языки и системы программирования Базы данных и знаний. Метод нормальных форм. (Лекция 6.2)
Базы данных и знаний. Метод нормальных форм. (Лекция 6.2) Кибербуллинг: как помочь ребенку в ситуации онлайн-травли
Кибербуллинг: как помочь ребенку в ситуации онлайн-травли Инструкция по заполнению ведомости объемов и стоимости работ
Инструкция по заполнению ведомости объемов и стоимости работ Разработка урока по информатике на тему Кодирование текстовой информации 6 класс
Разработка урока по информатике на тему Кодирование текстовой информации 6 класс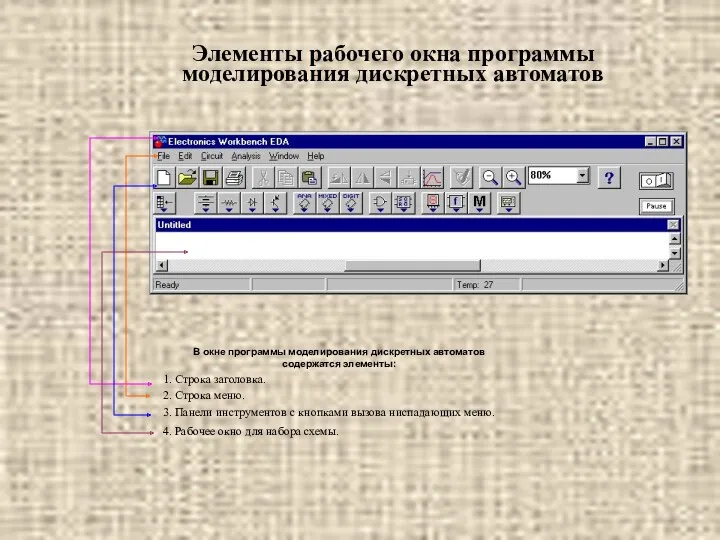 Элементы рабочего окна программы моделирования дискретных автоматов
Элементы рабочего окна программы моделирования дискретных автоматов Mobile Applications for education processes
Mobile Applications for education processes Информация и её кодирование. Способы измерения информации
Информация и её кодирование. Способы измерения информации Основы web. Протокол НTТР
Основы web. Протокол НTТР Многообразие схем. Информационные модели на графах. Использование графов при решении задач
Многообразие схем. Информационные модели на графах. Использование графов при решении задач