- Кодирование текстовой информации

Содержание
- 2. Ключевые слова текстовая информация кодирование кодовые таблицы
- 3. … 64 65 66 67 68 … 01000000 01000001 01000010 01000011 01000100 Компьютерное представление текстовой информации
- 4. Кодировка ASCII American Standard Code for Information Interchange – американский стандартный код для обмена информацией, разработанный
- 5. Расширение кодировки ASCII Стандартная часть кода (0 … 127) Расширение ASCII (128 … 255) (буквы национального
- 6. Расширение кодировки ASCII
- 7. Стандарт Unicode Unicode — это «уникальный код для любого символа, независимо от платформы, независимо от программы,
- 8. Клавиатуры некоторых стран мира
- 9. Кодировки стандарта Unicode Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок. Кодировка
- 10. Информационный объем сообщения Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт, мегабайт и т. д.),
- 11. Вопросы и задания В Советском энциклопедическом словаре (1983 года издания) 1600 страниц. На одной странице размещается
- 12. Самое главное Текстовая информация по своей природе дискретна, так как представляется последовательностью отдельных символов. В памяти
- 13. Самое главное В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий
- 14. Вопросы и задания Задание 1. Представьте в кодировке ASCII текст Happy New Year! а) шестнадцатеричным кодом
- 15. Windows-1251 Подходы к расположению русских букв в различных кодировках Задание 2. Сравните подходы к расположению русских
- 16. Вопросы и задания Задание 3. В 15-м издании энциклопедии Britannica 32 тома, в каждом из которых
- 18. Скачать презентацию

Ключевые слова
текстовая информация
кодирование
кодовые таблицы
Ключевые слова
текстовая информация
кодирование
кодовые таблицы
…
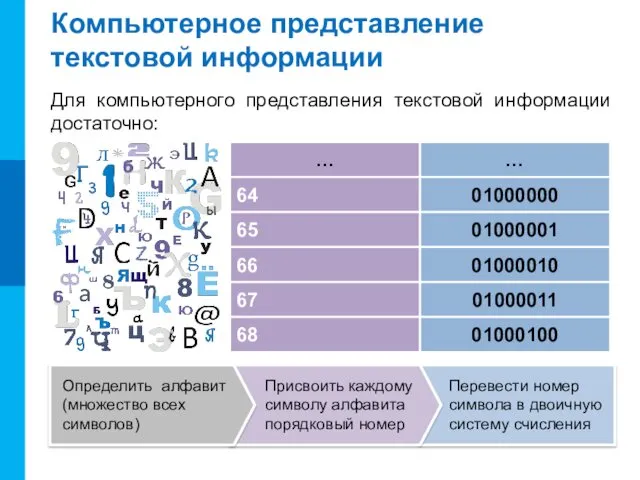
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:
…
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:
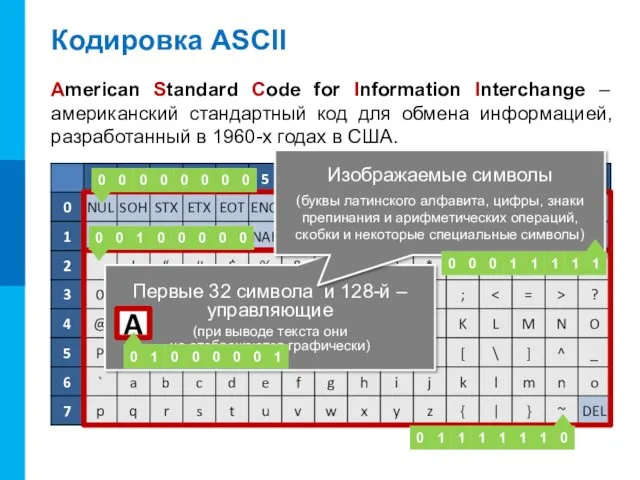
Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код
Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код
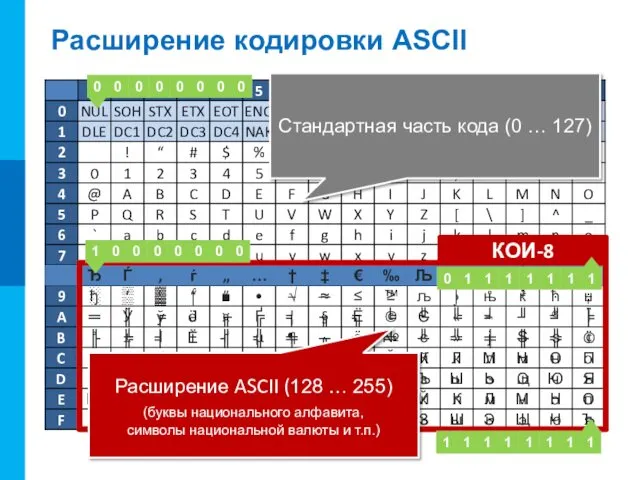
Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 …
Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 …
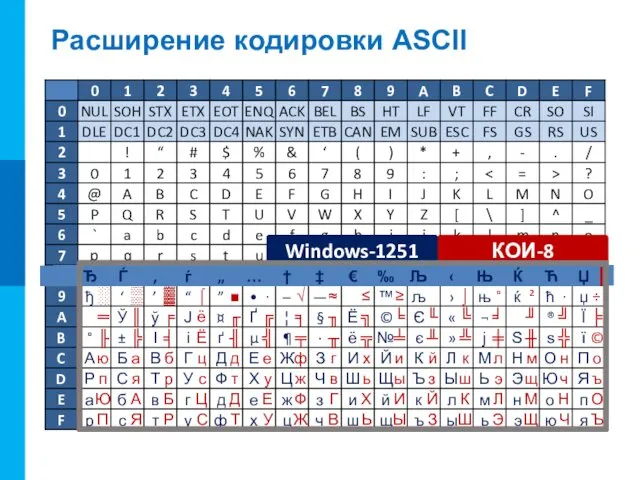
Расширение кодировки ASCII
Расширение кодировки ASCII

Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от
Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от

Клавиатуры некоторых стран мира
Клавиатуры некоторых стран мира
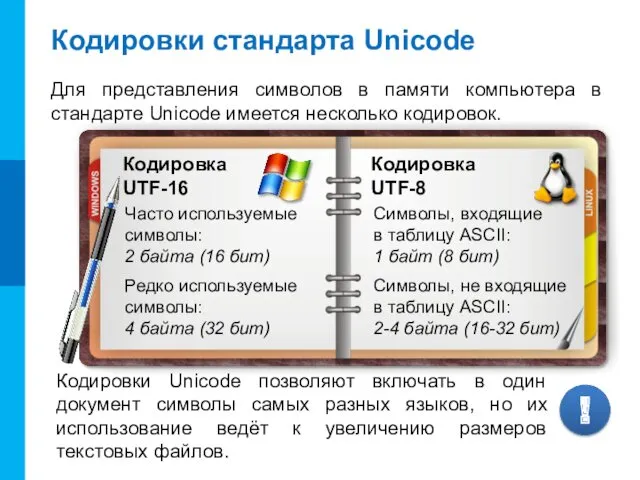
Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode
Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode

Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт,
Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт,

Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц.
Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц.

Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью
Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью

Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший
Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший
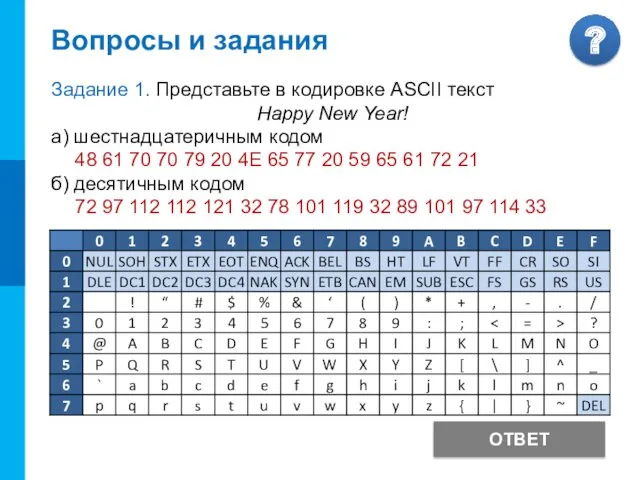
Вопросы и задания
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а)
Вопросы и задания
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а)
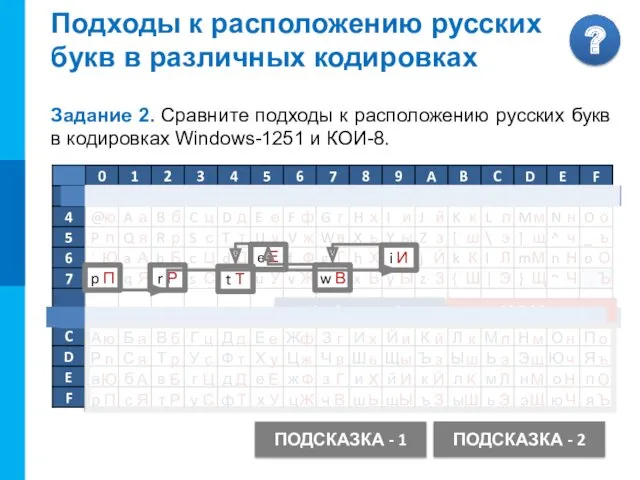
Windows-1251
Подходы к расположению русских
букв в различных кодировках
Задание 2. Сравните подходы
Windows-1251
Подходы к расположению русских
букв в различных кодировках
Задание 2. Сравните подходы

Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома,
Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома,
 Фирменные шрифты
Фирменные шрифты Створення й виконання запитів на вибірку даних. Урок 14. Інформатика. 10 (11) клас
Створення й виконання запитів на вибірку даних. Урок 14. Інформатика. 10 (11) клас Принципы работы контекстной рекламы
Принципы работы контекстной рекламы Кодирование звуковой информации
Кодирование звуковой информации Компьютерные сети. § 49. Всемирная паутина
Компьютерные сети. § 49. Всемирная паутина О религии в компьютерных играх
О религии в компьютерных играх Санау жүйесі
Санау жүйесі Газета Известия
Газета Известия Научные архивы информации
Научные архивы информации Геоинформационные средства для трехмерного представления объектов кадастрового учета
Геоинформационные средства для трехмерного представления объектов кадастрового учета Введение в язык Python. Вычисления
Введение в язык Python. Вычисления Язык программирования C#
Язык программирования C# Основы языка программирования PHP
Основы языка программирования PHP Периодическая печать
Периодическая печать Блокчейн: потенциал роста
Блокчейн: потенциал роста Computer engineering
Computer engineering Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №6
Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №6 Принципы обработки информации компьютером. Алгоритмы и способы их описания
Принципы обработки информации компьютером. Алгоритмы и способы их описания Безопасный интернет
Безопасный интернет Топ 10 инструментов. Тренды SMM 2017
Топ 10 инструментов. Тренды SMM 2017 Разработка web-сайта рекламного агентства по созданию движущейся рекламы
Разработка web-сайта рекламного агентства по созданию движущейся рекламы Вирусы и антивирусные программы
Вирусы и антивирусные программы Представление чисел в компьютере. Математические основы информатики
Представление чисел в компьютере. Математические основы информатики Системы счисления
Системы счисления Методы теории нечетких систем
Методы теории нечетких систем Формирование изображения на экране монитора. Компьютерное представление цвета
Формирование изображения на экране монитора. Компьютерное представление цвета Программное обеспечение ПК. Операционная система. Файловая система
Программное обеспечение ПК. Операционная система. Файловая система Git. Python tools. Basic operators
Git. Python tools. Basic operators