- Компьютерные сети. (Лекция 12)

Содержание
- 2. Компьютерные сети. Основные понятия и технологии Облачные вычисления Проблемы и перспективы поиска и обработки данных План
- 3. Первые компьютеры 1950-х гг. основным предназначением являлось небольшое число избранных операций. Данные компьютеры не применялись для
- 4. В начале 1960-х гг. появились новые способы организации вычислительного процесса, позволяющие учесть интересы пользователей. Началось развитие
- 5. В 1970-х гг. наблюдался технологический прорыв в сфере производства компьютерных компонентов, что выразилось в появлении БИС.
- 6. В 1980-х гг. Появились стандартные технологии объединения компьютеров в сеть – Ethernet, Arcnet, Token Ring. Сильный
- 7. В настоящий момент вычислительные сети непрерывно развиваются, и достаточно быстро. Соединяющий компьютеры пассивный кабель в них
- 8. вычислительная сеть является сложным комплексом взаимосвязанных и согласованно функционирующих программных и аппаратных компонентов. Это многослойная модель,
- 9. Критерием для классификации сетей является их масштаб. LAN - Local Area Network - локальная сеть, компьютеры
- 10. 1.3. Локальные компьютерные сети (ЛКС) Локальная компьютерная сеть объединяет небольшое количество компью- теров и позволяет пользователям
- 11. Существуют три базовые топологии ЛКС: шина, звезда и кольцо. Топология ЛКС Выбор топологии влияет на: -
- 12. Топология «Шина» Один кабель используется всеми рабочими станциями по очереди. Пассивная топология. Сообщение, посылаемое одним компьютером,
- 13. Топология «Звезда» Каждая рабочая станция подключена к объединяющему устройству - концентратору (hub). По этой схеме могут
- 14. Топология «Кольцо» Данные, ведомые маркером, передаются последовательно от одной рабочей станции к другой и проходят через
- 15. Комбинированные топологии Сегменты сети с топологией «звезда» объединяются при помощи магистральной линейной шины. Топология «Звезда-шина» Топология
- 16. Одноранговые сети Сети на основе сервера Существует два принципиальных способа организации программного обеспе- чения ЛКС: одноранговые
- 17. Многоуровневый подход. Сетевые протоколы. Сетевая модель OSI ( open systems interconnection basic reference model ) -
- 18. Сетевые протоколы. Модель OSI. Прикладной уровень (уровень приложений; англ. application layer) — верхний уровень модели, обеспечивающий
- 19. Сетевые протоколы. Модель OSI. Уровень представления (presentation layer) обеспечивает преобразование протоколов и шифрование/расшифровку данных. Запросы приложений,
- 20. Сетевые протоколы. Модель OSI. Сеансовый уровень (session layer) модели обеспечивает поддержание сеанса связи, позволяя приложениям взаимодействовать
- 21. Сетевые протоколы. Модель OSI. Транспортный уровень (transport layer) модели предназначен для обеспечения надёжной передачи данных от
- 22. Сетевые протоколы. Модель OSI. Сетевой уровень (network layer) модели предназначен для определения пути передачи данных. Отвечает
- 23. Сетевые протоколы. Модель OSI. Канальный уровень (data link layer) предназначен для обеспечения взаимодействия сетей по физическому
- 24. Сетевые протоколы. Модель OSI. Физический уровень ( physical layer) — нижний уровень модели, который определяет метод
- 25. Сетевые протоколы. Модель OSI. Семейство TCP/IP. Имеет три транспортных протокола: TCP, полностью соответствующий OSI, обеспечивающий проверку
- 26. 1.3. Глобальная компьютерная сеть Интернет В 1969 году специалистами из Пентагона была создана крупная децентрализованная компьютерная
- 27. Каждый компьютер, подключённый к Интернету, имеет свой уникальный 32-битовый IP-адрес (Internet Protocol). Возможно 232 = 4
- 28. Доменная система имён (DNS - Domain Name System) ставит в соответствие числовому IP-адресу компьютера уникальное доменное
- 29. Домены верхнего уровня бывают двух типов: географические (двухбуквен- ные - каждой стране соответствует двухбуквенный код) и
- 30. Сеть Интернет функционирует и развивается благодаря использованию единого протокола передачи данных TCP/IP. Протокол передачи данных TCP/IP
- 31. Информационные системы Интернет World Wide Web (WWW) = спецификация URL (Uniform Resource Locator, Унифицированный указатель ресурса)
- 32. Термины WWW WWW – это единое информационное пространство, состоящее из множества взаимосвязанных электронных документов, хранящихся на
- 33. Унифицированный указатель ресурса Адрес любого файла в WWW определяется унифицированным указателем ресурса – URL. Этот адрес
- 34. условное наименование протокола взаимодействия ( http, ftp…); полное доменное имя компьютера; полный путь доступа к ресурсу
- 35. Вид сообщений в протоколе TCP/IP
- 36. Службы и сервисы ГВС сервис DNS, или система доменных имен, обеспечивающий возможность использования для адресации узлов
- 37. Службы и сервисы ГВС сервис FTP — система файловых архивов, обеспечивающая хранение и пересылку файлов различных
- 38. Услуги Интернет
- 39. 2. Облачные вычисления Облако (cloud) - модель организации IT-инфраструктуры, состоящая из распределенных и разделяемых конфигурируемых аппаратных
- 40. Облачные вычисления 1960 г. Джон Маккарти высказал предположение, что когда-нибудь компьютерные вычисления будут производиться с помощью
- 41. Облачные вычисления 2008 г. HP, Intel и Yahoo! Создание глобальной, охватывающей множество площадок, открытой вычислительной лаборатории
- 42. Облачные вычисления Основные характеристики Самообслуживание по требованию (On-demand self-service) Широкий сетевой доступ (Broad network access) Объединение
- 43. Облачные вычисления Модели развертывания Частное облако (Private cloud). Облако сообщества и коммунальное облако (Community cloud). Публичное
- 44. Облачные вычисления Модели облачных служб Программное обеспечение как услуга (SaaS). Платформа как услуга (PaaS). Инфраструктура как
- 45. Облачные вычисления Достоинства и недостатки
- 46. Облачные вычисления Мифы и заблуждения «Облако» основано только на программном обеспечении Объединяем несколько виртуальных устройств и
- 47. Облачные вычисления Мифы и заблуждения «Облако» и объединенные ресурсы Это еще одна область, которую многие связывают
- 48. Облачные вычисления Мифы и заблуждения Виртуализация делает «облако» более гибким Абсолютная правда, в отношении динамического распределения
- 49. Облачные вычисления Мифы и заблуждения Виртуальная машина – это тот же сервер, только программный Это не
- 50. Облачные вычисления Мифы и заблуждения «Облака» планируют, а сети администрируют Это подразумевает, что ваша компьютерная среда
- 51. Облачные вычисления Основные разработчики
- 52. Основные игроки рынка По подсчетам экспертов, в первом квартале 2015 года объем рынка сервисов, предназначенных для
- 53. Основные игроки Российского рынка Облачные вычисления
- 54. 4. Перспективные информационные технологии, понятия и проблемы Data Mining –интеллектуальный анализ данных Data Mining переводится как
- 55. Перспективные информационные технологии, понятия и проблемы Колоссальные потоки информационной «руды» в самых различных областях. Что делать
- 56. Перспективные информационные технологии, понятия и проблемы Методы математической статистики— концепция усреднения по выборке Методы математической статистики
- 57. Перспективные информационные технологии, понятия и проблемы В основу современной технологии Data Mining (discovery-driven data mining) положена
- 58. Перспективные информационные технологии, понятия и проблемы Примеры формулировок задач для OLAP и Data Mining
- 59. Перспективные информационные технологии, понятия и проблемы Важное положение Data Mining — нетривиальность разыскиваемых шаблонов. Это означает,
- 60. Перспективные информационные технологии, понятия и проблемы
- 61. Перспективные информационные технологии, понятия и проблемы Классы систем Data Mining Data Mining является мульти-дисциплинарной областью, возникшей
- 62. Перспективные информационные технологии, понятия и проблемы классификация ключевых компонент
- 63. Перспективные информационные технологии, понятия и проблемы 1. Предметно-ориентированные аналитические системы Предметно-ориентированные аналитические системы очень разнообразны. Наиболее
- 64. 2. Статистические пакеты Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами
- 65. Перспективные информационные технологии, понятия и проблемы 3. Нейронные сети Это большой класс систем, архитектура которых имеет
- 66. Перспективные информационные технологии, понятия и проблемы 4. Системы рассуждений на основе аналогичных случаев Идея систем case
- 67. Перспективные информационные технологии, понятия и проблемы 5. Деревья решений (decision trees) Деревья решения являются одним из
- 68. Перспективные информационные технологии, понятия и проблемы 6. Эволюционное программирование Гипотезы о виде зависимости целевой переменной от
- 69. Перспективные информационные технологии, понятия и проблемы 7. Генетические алгоритмы Мощное средство решения разнообразных комбинаторных задач и
- 70. Перспективные информационные технологии, понятия и проблемы Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно
- 71. Перспективные информационные технологии, понятия и проблемы 8. Алгоритмы ограниченного перебора Эти алгоритмы вычисляют частоты комбинаций простых
- 72. Перспективные информационные технологии, понятия и проблемы 9. Системы для визуализации многомерных данных Средства для графического отображения
- 73. 4. Перспективные информационные технологии. Резюме 1. Рынок систем Data Mining развивается экспоненциально. В этом развитии принимают
- 74. Резюме 3. Несмотря на обилие методов Data Mining, на сегодня приоритет смещен в сторону логических алгоритмов
- 76. Скачать презентацию

Компьютерные сети. Основные понятия и технологии
Облачные вычисления
Проблемы и перспективы поиска и
Компьютерные сети. Основные понятия и технологии
Облачные вычисления
Проблемы и перспективы поиска и

Первые компьютеры 1950-х гг. основным предназначением являлось небольшое число избранных операций.
Первые компьютеры 1950-х гг. основным предназначением являлось небольшое число избранных операций.

В начале 1960-х гг. появились новые способы организации вычислительного процесса, позволяющие
В начале 1960-х гг. появились новые способы организации вычислительного процесса, позволяющие

В 1970-х гг. наблюдался технологический прорыв в сфере производства компьютерных компонентов,
В 1970-х гг. наблюдался технологический прорыв в сфере производства компьютерных компонентов,

В 1980-х гг. Появились стандартные технологии объединения компьютеров в сеть –
В 1980-х гг. Появились стандартные технологии объединения компьютеров в сеть –

В настоящий момент вычислительные сети непрерывно развиваются, и достаточно быстро. Соединяющий
В настоящий момент вычислительные сети непрерывно развиваются, и достаточно быстро. Соединяющий

вычислительная сеть является сложным комплексом взаимосвязанных и согласованно функционирующих программных и
вычислительная сеть является сложным комплексом взаимосвязанных и согласованно функционирующих программных и

Критерием для классификации сетей является их масштаб.
LAN - Local Area Network
Критерием для классификации сетей является их масштаб.
LAN - Local Area Network
1.3. Локальные компьютерные сети (ЛКС)
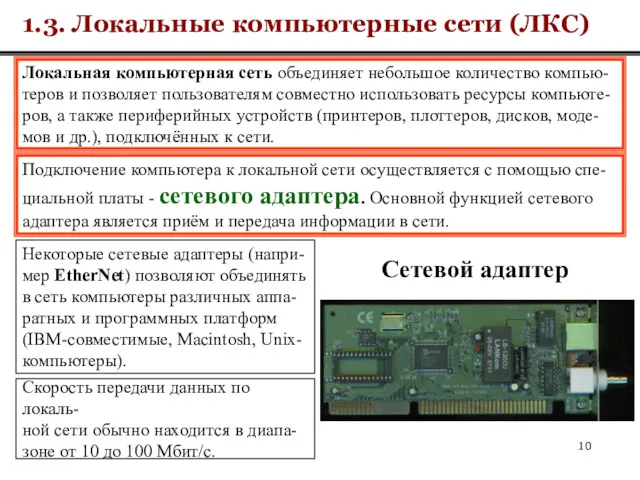
Локальная компьютерная сеть объединяет небольшое количество компью-
теров
1.3. Локальные компьютерные сети (ЛКС)
Локальная компьютерная сеть объединяет небольшое количество компью-
теров
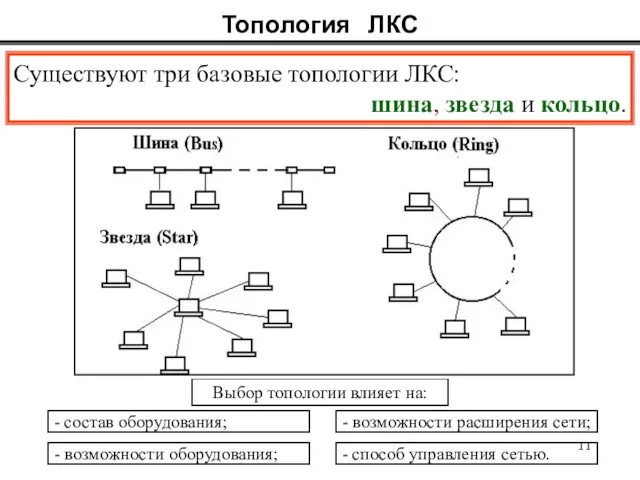
Существуют три базовые топологии ЛКС:
шина, звезда и кольцо.
Топология ЛКС
Существуют три базовые топологии ЛКС:
шина, звезда и кольцо.
Топология ЛКС
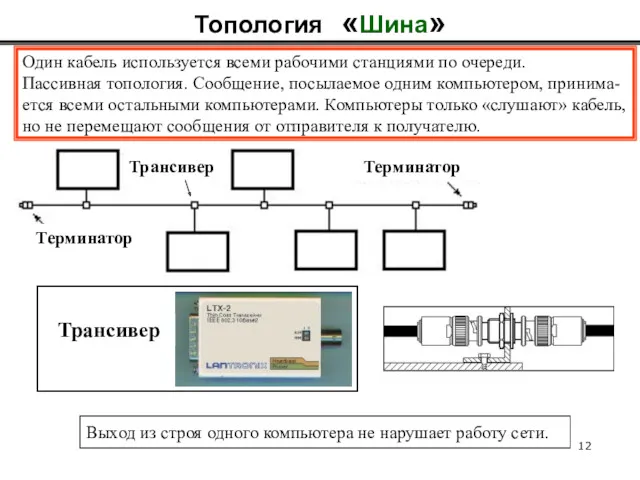
Топология «Шина»
Один кабель используется всеми рабочими станциями по очереди.
Пассивная
Топология «Шина»
Один кабель используется всеми рабочими станциями по очереди.
Пассивная
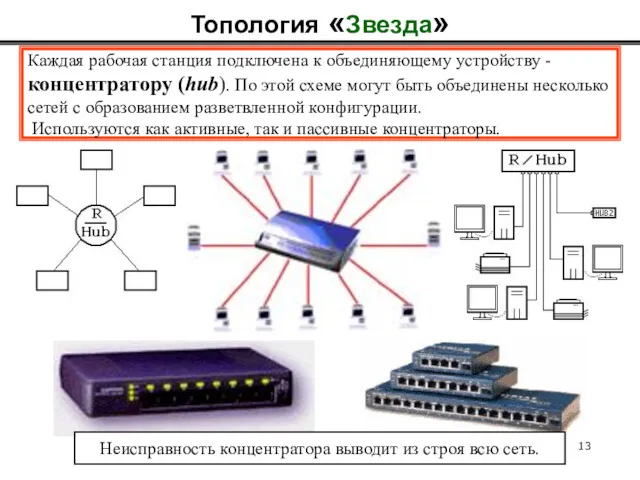
Топология «Звезда»
Каждая рабочая станция подключена к объединяющему устройству -
концентратору
Топология «Звезда»
Каждая рабочая станция подключена к объединяющему устройству -
концентратору
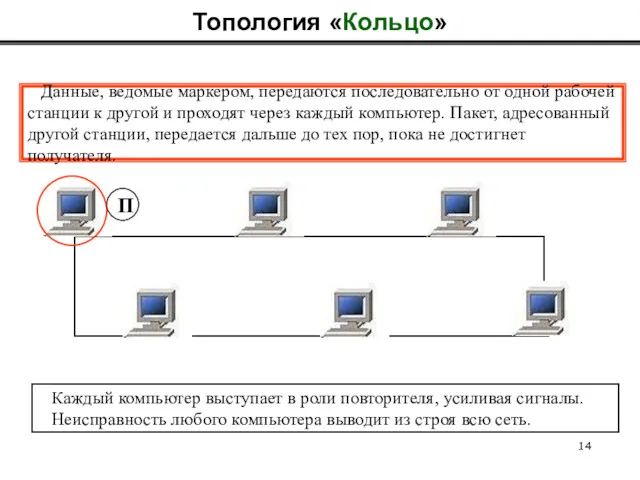
Топология «Кольцо»
Данные, ведомые маркером, передаются последовательно от одной рабочей
станции
Топология «Кольцо»
Данные, ведомые маркером, передаются последовательно от одной рабочей
станции
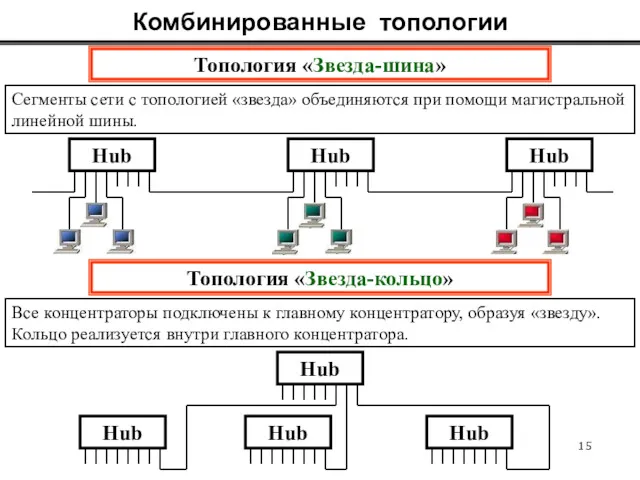
Комбинированные топологии
Сегменты сети с топологией «звезда» объединяются при помощи магистральной
линейной шины.
Топология
Комбинированные топологии
Сегменты сети с топологией «звезда» объединяются при помощи магистральной
линейной шины.
Топология
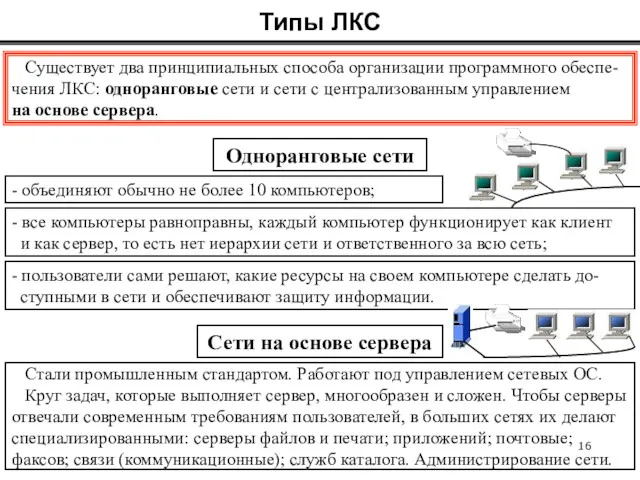
Одноранговые сети
Сети на основе сервера
Существует два принципиальных способа организации программного
Одноранговые сети
Сети на основе сервера
Существует два принципиальных способа организации программного

Многоуровневый подход. Сетевые протоколы.
Сетевая модель OSI ( open systems interconnection basic reference
Многоуровневый подход. Сетевые протоколы.
Сетевая модель OSI ( open systems interconnection basic reference

Сетевые протоколы. Модель OSI.
Прикладной уровень (уровень приложений; англ. application layer) — верхний уровень
Сетевые протоколы. Модель OSI.
Прикладной уровень (уровень приложений; англ. application layer) — верхний уровень

Сетевые протоколы. Модель OSI.
Уровень представления (presentation layer) обеспечивает преобразование протоколов
Сетевые протоколы. Модель OSI.
Уровень представления (presentation layer) обеспечивает преобразование протоколов

Сетевые протоколы. Модель OSI.
Сеансовый уровень (session layer) модели обеспечивает поддержание
Сетевые протоколы. Модель OSI.
Сеансовый уровень (session layer) модели обеспечивает поддержание

Сетевые протоколы. Модель OSI.
Транспортный уровень (transport layer) модели предназначен для
Сетевые протоколы. Модель OSI.
Транспортный уровень (transport layer) модели предназначен для

Сетевые протоколы. Модель OSI.
Сетевой уровень (network layer) модели предназначен для
Сетевые протоколы. Модель OSI.
Сетевой уровень (network layer) модели предназначен для

Сетевые протоколы. Модель OSI.
Канальный уровень (data link layer) предназначен для
Сетевые протоколы. Модель OSI.
Канальный уровень (data link layer) предназначен для

Сетевые протоколы. Модель OSI.
Физический уровень ( physical layer) — нижний уровень модели,
Сетевые протоколы. Модель OSI.
Физический уровень ( physical layer) — нижний уровень модели,

Сетевые протоколы. Модель OSI.
Семейство TCP/IP. Имеет три транспортных протокола: TCP, полностью
Сетевые протоколы. Модель OSI.
Семейство TCP/IP. Имеет три транспортных протокола: TCP, полностью
1.3. Глобальная компьютерная сеть Интернет
В 1969 году специалистами из Пентагона
1.3. Глобальная компьютерная сеть Интернет
В 1969 году специалистами из Пентагона
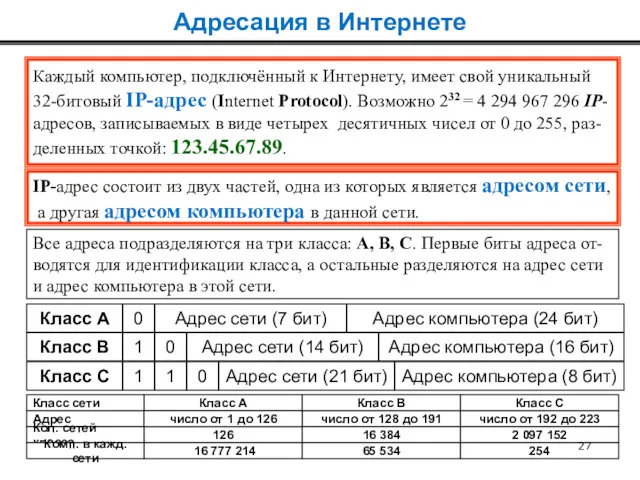
Каждый компьютер, подключённый к Интернету, имеет свой уникальный
32-битовый IP-адрес (Internet Protocol).
Каждый компьютер, подключённый к Интернету, имеет свой уникальный
32-битовый IP-адрес (Internet Protocol).
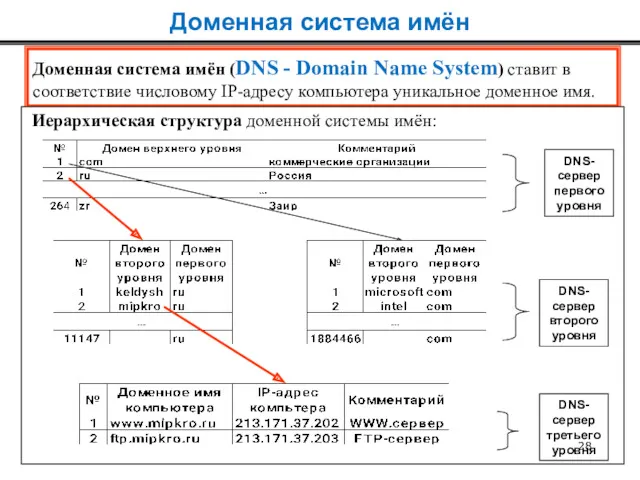
Доменная система имён (DNS - Domain Name System) ставит в
соответствие
Доменная система имён (DNS - Domain Name System) ставит в
соответствие
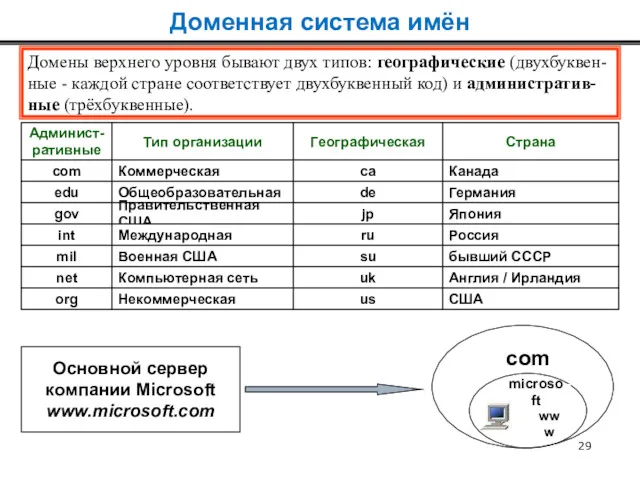
Домены верхнего уровня бывают двух типов: географические (двухбуквен-
ные - каждой стране
Домены верхнего уровня бывают двух типов: географические (двухбуквен-
ные - каждой стране

Сеть Интернет функционирует и развивается благодаря использованию
единого протокола передачи данных TCP/IP.
Протокол
Сеть Интернет функционирует и развивается благодаря использованию
единого протокола передачи данных TCP/IP.
Протокол

Информационные системы Интернет
World Wide Web (WWW) = спецификация URL (Uniform Resource
Информационные системы Интернет
World Wide Web (WWW) = спецификация URL (Uniform Resource

Термины WWW
WWW – это единое информационное пространство, состоящее из множества взаимосвязанных
Термины WWW
WWW – это единое информационное пространство, состоящее из множества взаимосвязанных

Унифицированный указатель ресурса
Адрес любого файла в WWW определяется унифицированным указателем ресурса
Унифицированный указатель ресурса
Адрес любого файла в WWW определяется унифицированным указателем ресурса

условное наименование протокола взаимодействия ( http, ftp…);
полное доменное имя компьютера;
полный путь доступа
условное наименование протокола взаимодействия ( http, ftp…);
полное доменное имя компьютера;
полный путь доступа
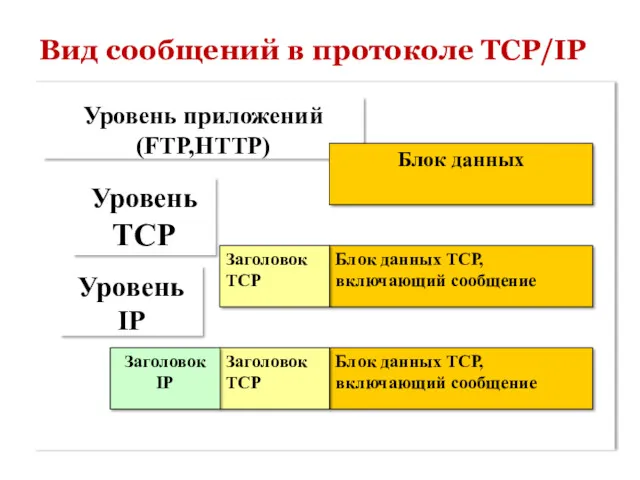
Вид сообщений в протоколе TCP/IP
Вид сообщений в протоколе TCP/IP

Службы и сервисы ГВС
сервис DNS, или система доменных имен, обеспечивающий
Службы и сервисы ГВС
сервис DNS, или система доменных имен, обеспечивающий

Службы и сервисы ГВС
сервис FTP — система файловых архивов, обеспечивающая хранение и
Службы и сервисы ГВС
сервис FTP — система файловых архивов, обеспечивающая хранение и

Услуги Интернет
Услуги Интернет

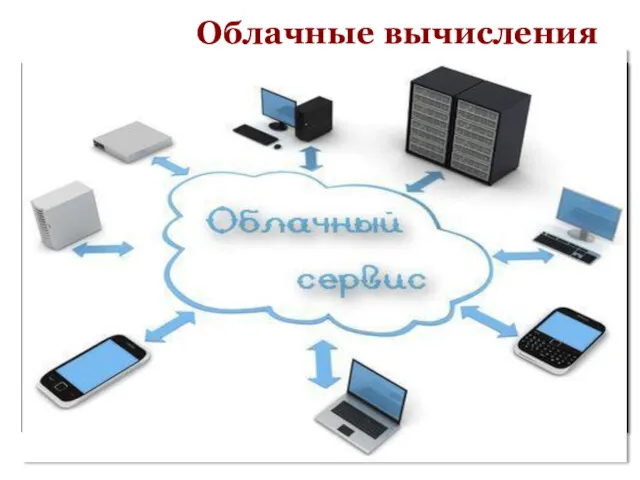
2. Облачные вычисления
Облако (cloud) - модель организации IT-инфраструктуры, состоящая из распределенных
2. Облачные вычисления
Облако (cloud) - модель организации IT-инфраструктуры, состоящая из распределенных
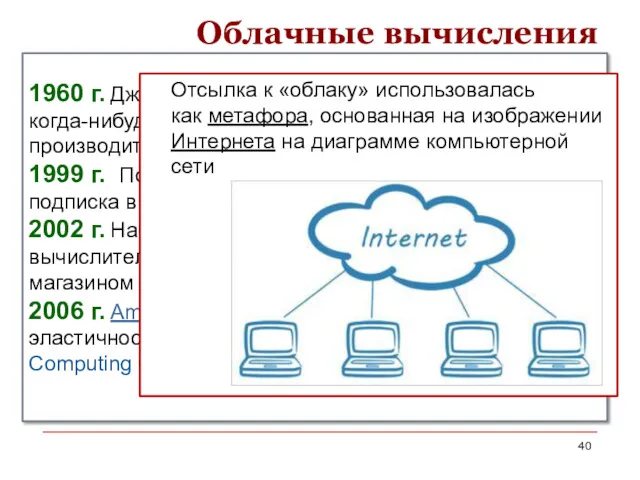
Облачные вычисления
1960 г. Джон Маккарти высказал предположение, что когда-нибудь компьютерные вычисления
Облачные вычисления
1960 г. Джон Маккарти высказал предположение, что когда-нибудь компьютерные вычисления
Облачные вычисления
2008 г. HP, Intel и Yahoo! Создание глобальной, охватывающей множество площадок, открытой вычислительной лаборатории
Облачные вычисления
2008 г. HP, Intel и Yahoo! Создание глобальной, охватывающей множество площадок, открытой вычислительной лаборатории
Облачные вычисления
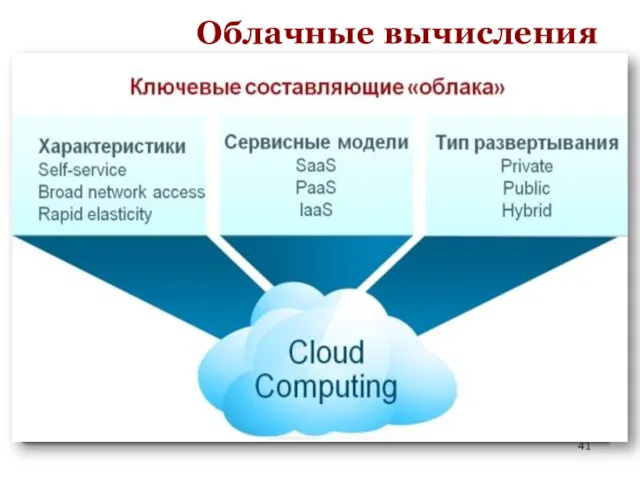
Основные характеристики
Самообслуживание по требованию (On-demand self-service)
Широкий сетевой доступ (Broad network
Облачные вычисления
Основные характеристики
Самообслуживание по требованию (On-demand self-service)
Широкий сетевой доступ (Broad network
Облачные вычисления
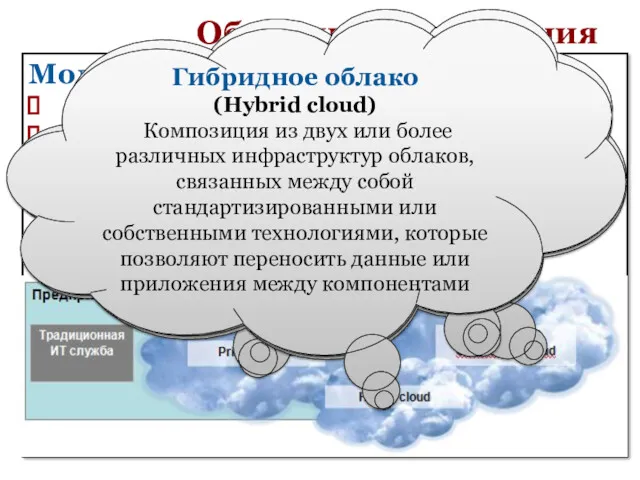
Модели развертывания
Частное облако (Private cloud).
Облако сообщества и
Облачные вычисления
Модели развертывания
Частное облако (Private cloud).
Облако сообщества и

Облачные вычисления
Модели облачных служб
Программное обеспечение как услуга (SaaS).
Платформа
Облачные вычисления
Модели облачных служб
Программное обеспечение как услуга (SaaS).
Платформа
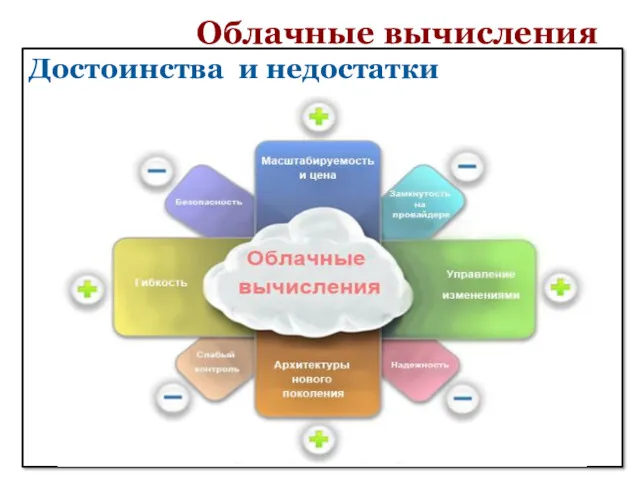
Облачные вычисления
Достоинства и недостатки
Облачные вычисления
Достоинства и недостатки

Облачные вычисления
Мифы и заблуждения
«Облако» основано только на программном обеспечении
Объединяем несколько виртуальных
Облачные вычисления
Мифы и заблуждения
«Облако» основано только на программном обеспечении
Объединяем несколько виртуальных

Облачные вычисления
Мифы и заблуждения
«Облако» и объединенные ресурсы
Это еще одна область, которую
Облачные вычисления
Мифы и заблуждения
«Облако» и объединенные ресурсы
Это еще одна область, которую

Облачные вычисления
Мифы и заблуждения
Виртуализация делает «облако» более гибким
Абсолютная правда, в отношении
Облачные вычисления
Мифы и заблуждения
Виртуализация делает «облако» более гибким
Абсолютная правда, в отношении

Облачные вычисления
Мифы и заблуждения
Виртуальная машина – это тот же сервер, только
Облачные вычисления
Мифы и заблуждения
Виртуальная машина – это тот же сервер, только

Облачные вычисления
Мифы и заблуждения
«Облака» планируют, а сети администрируют
Это подразумевает, что ваша
Облачные вычисления
Мифы и заблуждения
«Облака» планируют, а сети администрируют
Это подразумевает, что ваша
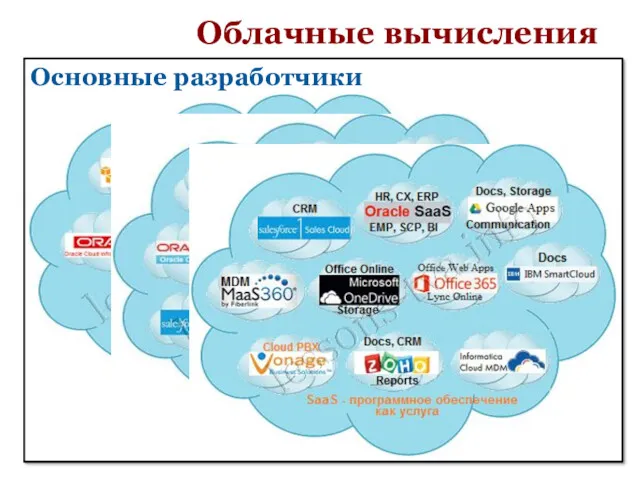
Облачные вычисления
Основные разработчики
Облачные вычисления
Основные разработчики
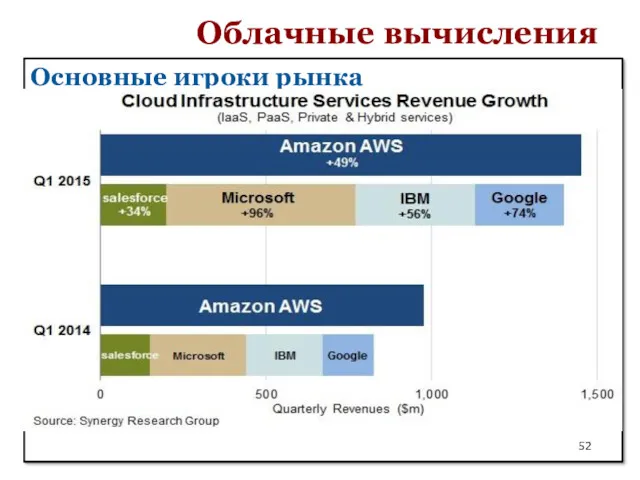
Основные игроки рынка
По подсчетам экспертов, в первом квартале 2015 года объем
Основные игроки рынка
По подсчетам экспертов, в первом квартале 2015 года объем
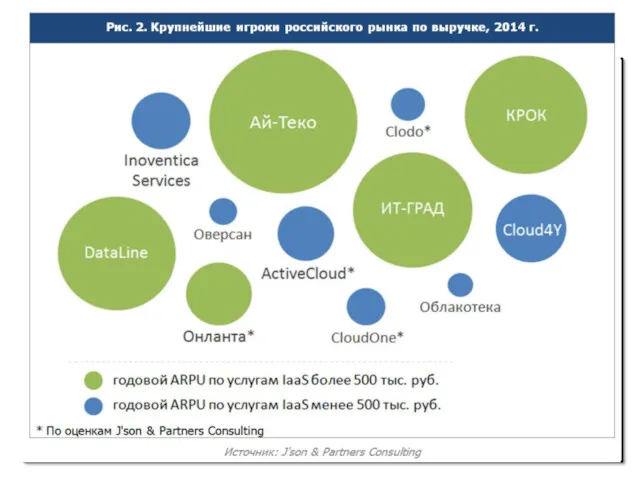
Основные игроки Российского рынка
Облачные вычисления
Основные игроки Российского рынка
Облачные вычисления

4. Перспективные информационные технологии, понятия и проблемы
Data Mining –интеллектуальный анализ
4. Перспективные информационные технологии, понятия и проблемы
Data Mining –интеллектуальный анализ

Перспективные информационные технологии, понятия и проблемы
Колоссальные потоки информационной «руды» в самых
Перспективные информационные технологии, понятия и проблемы
Колоссальные потоки информационной «руды» в самых

Перспективные информационные технологии, понятия и проблемы
Методы математической статистики— концепция усреднения по выборке
Методы
Перспективные информационные технологии, понятия и проблемы
Методы математической статистики— концепция усреднения по выборке
Методы

Перспективные информационные технологии, понятия и проблемы
В основу современной технологии Data Mining
Перспективные информационные технологии, понятия и проблемы
В основу современной технологии Data Mining

Перспективные информационные технологии, понятия и проблемы
Примеры формулировок задач для OLAP и
Перспективные информационные технологии, понятия и проблемы
Примеры формулировок задач для OLAP и

Перспективные информационные технологии, понятия и проблемы
Важное положение Data Mining — нетривиальность
Перспективные информационные технологии, понятия и проблемы
Важное положение Data Mining — нетривиальность
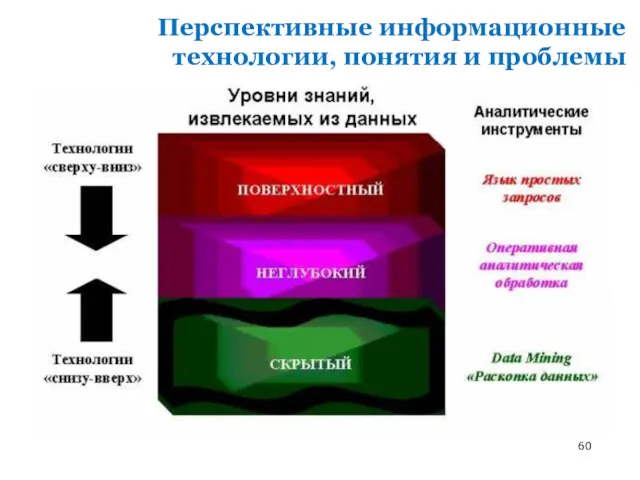
Перспективные информационные технологии, понятия и проблемы
Перспективные информационные технологии, понятия и проблемы

Перспективные информационные технологии, понятия и проблемы
Классы систем Data Mining
Data Mining является
Перспективные информационные технологии, понятия и проблемы
Классы систем Data Mining
Data Mining является

Перспективные информационные технологии, понятия и проблемы
классификация ключевых компонент
Перспективные информационные технологии, понятия и проблемы
классификация ключевых компонент

Перспективные информационные технологии, понятия и проблемы
1. Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы
Перспективные информационные технологии, понятия и проблемы
1. Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы

2. Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду
2. Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду

Перспективные информационные технологии, понятия и проблемы
3. Нейронные сети
Это большой класс систем,
Перспективные информационные технологии, понятия и проблемы
3. Нейронные сети
Это большой класс систем,

Перспективные информационные технологии, понятия и проблемы
4. Системы рассуждений на основе аналогичных
Перспективные информационные технологии, понятия и проблемы
4. Системы рассуждений на основе аналогичных

Перспективные информационные технологии, понятия и проблемы
5. Деревья решений (decision trees)
Деревья решения
Перспективные информационные технологии, понятия и проблемы
5. Деревья решений (decision trees)
Деревья решения

Перспективные информационные технологии, понятия и проблемы
6. Эволюционное программирование
Гипотезы о виде зависимости
Перспективные информационные технологии, понятия и проблемы
6. Эволюционное программирование
Гипотезы о виде зависимости

Перспективные информационные технологии, понятия и проблемы
7. Генетические алгоритмы
Мощное средство решения разнообразных
Перспективные информационные технологии, понятия и проблемы
7. Генетические алгоритмы
Мощное средство решения разнообразных

Перспективные информационные технологии, понятия и проблемы
Генетические алгоритмы удобны тем, что их
Перспективные информационные технологии, понятия и проблемы
Генетические алгоритмы удобны тем, что их

Перспективные информационные технологии, понятия и проблемы
8. Алгоритмы ограниченного перебора
Эти алгоритмы вычисляют
Перспективные информационные технологии, понятия и проблемы
8. Алгоритмы ограниченного перебора
Эти алгоритмы вычисляют

Перспективные информационные технологии, понятия и проблемы
9. Системы для визуализации многомерных данных
Средства
Перспективные информационные технологии, понятия и проблемы
9. Системы для визуализации многомерных данных
Средства

4. Перспективные информационные технологии. Резюме
1. Рынок систем Data Mining развивается экспоненциально. В
4. Перспективные информационные технологии. Резюме
1. Рынок систем Data Mining развивается экспоненциально. В

Резюме
3. Несмотря на обилие методов Data Mining, на сегодня приоритет смещен в
Резюме
3. Несмотря на обилие методов Data Mining, на сегодня приоритет смещен в
 Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка
Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка Средства создания и сопровождения сайта
Средства создания и сопровождения сайта Комп’ютерні ігри
Комп’ютерні ігри Подготовка к ОГЭ по информатике
Подготовка к ОГЭ по информатике Хмарні IDE
Хмарні IDE Microsoft EXCEL. Основы работы с программой
Microsoft EXCEL. Основы работы с программой Команды текста в AutoCAD
Команды текста в AutoCAD Лекция 11. Планирование и диспетчеризация процессора
Лекция 11. Планирование и диспетчеризация процессора Программные продукты 1С для обмена данными с ФГТС МДЛП (Мониторинг движения лекарственных препаратов)
Программные продукты 1С для обмена данными с ФГТС МДЛП (Мониторинг движения лекарственных препаратов) Работа с Joomla
Работа с Joomla Сайт andreevats.ru
Сайт andreevats.ru Системы. Информационные системы. Классификация правовых автоматизированных информационных систем
Системы. Информационные системы. Классификация правовых автоматизированных информационных систем Введение в язык С
Введение в язык С Отображение XML в браузере. (Лекция 2)
Отображение XML в браузере. (Лекция 2) Продвинутый javascript. Лучшие практики и шаблоны проектирования
Продвинутый javascript. Лучшие практики и шаблоны проектирования Test Case Writing Guideline
Test Case Writing Guideline Дослідження ефективності застосування сучасних бездротових мереж Wlan
Дослідження ефективності застосування сучасних бездротових мереж Wlan Виды современных компьютеров (от мощных компьютерных систем, до мини-компьютеров)
Виды современных компьютеров (от мощных компьютерных систем, до мини-компьютеров) Безпека дітей в інтернете
Безпека дітей в інтернете Инфографика в социологии
Инфографика в социологии Программирование на языке Python. Введение в язык Python
Программирование на языке Python. Введение в язык Python Компьютерный сленг
Компьютерный сленг Электронные библиотеки и другие интернет-ресурсы
Электронные библиотеки и другие интернет-ресурсы Создание буклетов.
Создание буклетов. Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17)
Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17) Узагальнене програмування на мові Java (Generics). Лекція 4
Узагальнене програмування на мові Java (Generics). Лекція 4 Ошибки продвижения бизнеса в интернете
Ошибки продвижения бизнеса в интернете Создание проекта супермаркета в 3D-редакторе SKETCHUP
Создание проекта супермаркета в 3D-редакторе SKETCHUP