- Концепция машины с хранимой в памяти программой. (Тема 2)

Содержание
- 2. Основными свойствами алгоритма являются: дискретность, определенность, массовость и результативность. Дискретность выражается в том, что алгоритм описывает
- 3. Массовость алгоритма подразумевает его применимость к множеству значений исходных данных, а не только к каким-то уникальным
- 4. В основе архитектуры современных ВМ лежит представление алгоритма решения задачи в виде программы последовательных вычислений. Согласно
- 5. Сущность фон-неймановской концепции вычислительной машины можно свести к четырем принципам: двоичного кодирования; программного управления; однородности памяти;
- 6. Согласно принципу двоичного кодирования, вся информация, как данные, так и команды, кодируются двоичными цифрами 0 и
- 7. Код операции представляет собой указание, какая операция должна быть выполнена, и задается с помощью n-разрядной двоичной
- 8. Принцип программного управления Все вычисления, предусмотренные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей
- 9. Принцип однородности памяти Команды и данные хранятся в одной и той же памяти и внешне в
- 10. Концепция вычислительной машины, изложенная в статье фон Неймана, предполагает единую память для хранения команд и данных.
- 11. Принцип адресности Структурно основная память состоит из пронумерованных ячеек, причем процессору в произвольный момент доступна любая
- 12. Фон-неймановская архитектура
- 13. Фон Неймана определил основные устройства ВМ, с помощью которых должны быть реализованы вышеперечисленные принципы. Большинство современных
- 14. Введенная информация сначала запоминается в основной памяти, а затем переносится во вторичную память, для длительного хранения.
- 15. Для таких ЗУ характерна энергозависимость – хранимая информация теряется при отключении электропитания. Если необходимо, чтобы часть
- 16. Для долговременного хранения больших программ и массивов данных в ВМ обычно имеется дополнительная память, известная как
- 17. Устройство управления (УУ) – важнейшая часть ВМ, организующая автоматическое выполнение программ (путем реализации функций управления) и
- 18. Пересылка информации между любыми элементами ВМ инициируется своим сигналом управления (СУ), то есть управление вычислительным процессом
- 19. Еще одной неотъемлемой частью ВМ является арифметико-логическое устройство (АЛУ). АЛУ обеспечивает арифметическую и логическую обработку двух
- 20. Флаги могут анализироваться в УУ с целью принятия решения о дальнейшей последовательности выполнения команд программы. УУ
- 21. Классификация архитектур По структуре вычислительных машин
- 22. В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и
- 23. Структура фон-неймановской вычислительной машины
- 24. У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между ЦП и памятью, и «развязать»
- 25. Структура вычислительной машины на базе общей шины
- 26. Благодаря этим свойствам шинная архитектура получила широкое распространение в мини и микроЭВМ. Вместе с тем, именно
- 27. В целом, при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная архитектура в чистом ее виде
- 28. Структура с одной шиной
- 29. Структура с двумя видами шин
- 30. Структура с многими видами шин
- 31. Классификация архитектур По системам команд
- 32. Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь,
- 34. Стековая архитектура Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Принципы построения
- 35. Принцип действия стековой памяти
- 36. Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в
- 37. Архитектура вычислительной машины на базе стека
- 38. Для выполнения арифметической или логической операции на вход АЛУ подается информация, считанная из двух верхних ячеек
- 39. К достоинствам АСК на базе стека следует отнести возможность сокращения адресной части команд, поскольку все операции
- 40. Аккумуляторная архитектура Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного
- 41. Архитектура ВМ на базе аккумулятора.
- 42. Для выполнения операции в АЛУ производится считывание одного из операндов из памяти в регистр данных. Второй
- 43. Регистровая архитектура В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как
- 44. RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако типичная для таких ВМ длина
- 45. В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них же засылается и результат. Подтип
- 46. К достоинствам регистровых АСК следует отнести: компактность получаемого кода, высокую скорость вычислений за счет замены обращений
- 47. Архитектура с выделенным доступом к памяти В архитектуре с выделенным доступом к памяти обращение к основной
- 48. В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти. Допускается наличие в АСК ограниченного
- 49. Классификация по составу и сложности команд Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная
- 50. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают один из трех подходов и,
- 51. В вычислительных машинах типа CISC проблема семантического разрыва решается за счет расширения системы команд, дополнения ее
- 52. К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 1980-х годов, и значительную часть
- 53. Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в 1980 году. Идея заключается в
- 54. Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании Cray Research. Достаточно успешно
- 55. Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один тип АСК — архитектура с
- 56. Основные направления в развитии архитектур процессоров Конвейеризация вычислений Суперконвейерные процессоры Суперскалярные процессоры
- 57. Конвейер команд Идея конвейера команд была предложена в 1956 году академиком С. А. Лебедевым. Как известно,
- 58. 3. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов в соответствии с указанным в
- 59. Логика работы конвейера команд
- 60. На рисунке показан конвейер с шестью ступенями, соответствующими шести этапам цикла команды. В диаграмме предполагается, что
- 61. Суперконвейер Разбиение каждой ступени конвейера на n «подступеней» при одновременном повышении тактовой частоты внутри конвейера также
- 63. Каждая из шести ступеней стандартного конвейера разбита на две более простые подступени, обозначенные индексами 1 и
- 64. Структурный риск - попытка нескольких команд одновременно обратиться к одному и тому же ресурсу ВМ. Риск
- 65. Структурный риск имеет место, когда несколько команд, находящихся на разных ступенях конвейера, пытаются одновременно пользовать один
- 66. «Чтение после записи» (ЧПЗ): команда j читает X до того, как команда i успеет записать новое
- 67. Для решения этих проблем применяют предвыборку команд и их спекулятивное выполнение. Команды выполняются не в естественном
- 68. Влияние условного перехода на работу конвейера команд
- 69. Пусть команда 3 – это условный переход к команде 15. До завершения команды 3 невозможно определить,
- 70. Статическое предсказание переходов. Динамическое предсказание переходов. Классификации схем предсказания переходов
- 71. Переход происходит всегда. Переход не происходит никогда. Предсказание определяется по результатам профилирования. Предсказание определяется кодом операции
- 72. Предполагается, что каждая команда условного перехода в программе обязательно завершится переходом, и, с учетом такого предсказания,
- 73. Предполагается, что ни одна из команд условного перехода в программе никогда не завершается переходом, поэтому выборка
- 74. По результатам профилирования, тем командам, которые чаще завершались переходом, назначается стратегия ПВ, а всем остальным —
- 75. Для одних команд предполагается, что переход произойдет, для других — его не случится. Предсказание определяется кодом
- 76. Одноуровневые или бимодальные. Двухуровневые или коррелированные. Гибридные. Асимметричные. Стратегии динамического предсказания для команд УП
- 77. Одноуровневые схемы предсказания переходов Идея одноуровневых схем предсказания, сводится к отделению команд, имеющих склонность завершаться переходом,
- 78. Предсказание осуществляется на основе предыдущих исходов как команды УП, для которой производится предсказание, так и от
- 79. Гибридные схемы объединяют в себе несколько различных механизмов предсказания — элементарных предикторов (средств прогнозирования ). Идея
- 80. Асимметричная схема сочетает в себе черты гибридных и коррелированных схем предсказания. От гибридных схем она переняла
- 81. Суперскалярность Суперскалярным (этот термин впервые был использован в 1987 году) называется центральный процессор (ЦП), который одновременно
- 82. Архитектура суперскалярного процессора
- 83. Блок выборки команд извлекает команды из основной памяти через кэш-память команд. Этот блок хранит несколько значений
- 84. Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число накопителей обычно равно числу ФБ,
- 85. Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет каждую команду в своих очередях
- 89. БФА - блок формирования адреса БРЗ - блок регистров замещения FPU - АЛУ для выполнения инструкций
- 90. Hyper-threading ( Hyper-threading — Гиперпоточность) В процессорах с использованием этой технологии каждый физический процессор может хранить
- 91. Потоки С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда поток отправляется
- 92. Развитие микропроцессоров CMP (Chip Multi Processing -многоядерность ) SMT (Simultaneous MultiThreading -многонитевая архитектура ) EPIC (Explicitly
- 93. Направление CMP Создание на одном кристалле нескольких микропроцессоров и организация их работы по принципу мультипроцессорных систем
- 94. Направление SMT На одном процессоре осуществляется запуск нескольких задач одновременно, при этом распараллеливание программ осуществляется аппаратными
- 95. Архитектура EPIC На входе процессора последовательность больших команд, состоящих из нескольких простых операций, которые могут исполняться
- 96. Недостатки Значительно усложняются компиляторы Производительность микропроцессора во многом определяется качеством компилятора Увеличивается сложность отладки
- 97. Развитие микропроцессоров на примере линейки микропроцессоров X86 фирмы Intel
- 99. Архитектура Pentium M Мобильная версия RISC архитектура как в Pentium III, IV Пять исполнительных устройств в
- 100. Архитектура Intel Core Conroe - настольные ПК
- 103. Основные особенности архитектуры Intel Core Технология широкого динамического выполнения (Wide Dynamic Execution) Интеллектуальная система управления энергопотреблением
- 104. Технология широкого динамического выполнения Призвана обеспечить выполнение большего количества команд за каждый такт, повышая эффективность выполнения
- 109. Интеллектуальная система управления энергопотреблением Технологии стробирования тактовых импульсов (clock gating) и "спящих" транзисторов (sleep transistors) гарантируют,
- 111. Улучшенный "умный" кэш Два ядра совместно используют кэш объёмом 2 или 4 Мбайт. Кэширование производится более
- 113. "Умный" доступ к памяти Улучшенная предварительная выборка Каждый двуядерный процессор Core оснащён восемью блоками предварительной выборки
- 114. "Умный" доступ к памяти Улучшенная предварительная выборка Блоки предварительной выборки памяти постоянно оценивают картину использования памяти,
- 115. "Умный" доступ к памяти Устранение неоднозначностей памяти Блок устранения неоднозначностей памяти выбирает операции чтения, которые не
- 118. Улучшенная работа с цифровым медиа-содержанием АЛУ обычно разбивает инструкции на два блока, что приводит к двум
- 121. Архитектура Core i3 - i7 Основной чертой новой архитектуры стала модульность Ядро это классический одноядерный x86-процессор:
- 122. Прочие блоки могут быть следующими: разделяемый кэш 3-го уровня; контроллер памяти; контроллер шины QPI (QuickPath Interconnect);
- 123. Core i3 Компания Intel разработала в 2006 году концепцию Tick-Tock (тик-так). Суть ее в том, что
- 125. Core i3 Самое основное отличие новых процессоров от предыдущих версий – это двухкристальная структура. Суть данного
- 127. ТЕХНОЛОГИИ CORE i3 Новая улучшенная версия Hyper-threading Simultaneous MultiThreading (SMT). Благодаря SMT приложения с поддержкой многопоточности
- 129. ТЕХНОЛОГИИ CORE i3 Для слежения за состоянием процессора, в нем был размещен специальный микроконтроллер Power Control
- 130. ТЕХНОЛОГИИ CORE i3 Линейка процессоров Core i3, в отличии от более дорогих Core i5/i7, не поддерживает
- 131. ТЕХНОЛОГИИ CORE i3 Virtualization Technology (VT) - Аппаратная виртуализация, позволяет запускать на одном физическом компьютере несколько
- 132. ТЕХНОЛОГИИ CORE i3 Execute Disable Bit обеспечивает защиту от вредоносных атак, направленных на переполнение буфера. Эта
- 133. ТЕХНОЛОГИИ CORE i3 Enhanced Intel SpeedStep - энергосберегающая технология Intel, вызывающая, в зависимости от потребностей системы,
- 134. ТЕХНОЛОГИИ CORE i3 Trusted Execution состоит из последовательно защищённых этапов обработки. В основе технологии лежит безопасное
- 135. ТЕХНОЛОГИИ CORE i3 Intel 64 Architecture поддерживает 64-битные вычисления, что позволяет устанавливать и использовать 64-битные версии
- 136. ГРАФИЧЕСКОЕ ЯДРО Графический чип Intel HD Graphics так же использует систему из унифицированных конвейеров. Производительность новой
- 137. ГРАФИЧЕСКОЕ ЯДРО Графический чип находится на общем кристалле с контроллером памяти, что позволит производить обмен данными
- 139. Core i7 920
- 140. Core i7 920 Трёхканальный контроллер памяти DDR3 с максимальной скоростью 32 GBps Процессорная шина Intel (QuickPath
- 141. Core i7 920 Управление энергопотреблением частота и напряжение питания для каждого ядра регулируются отдельно на основании
- 142. Core i7 920 Управление энергопотреблением Технология Turbo Boost процессора может повышать частоту работы одного или нескольких
- 143. Подсистема кэширования L2 является «персональной собственностью» конкретного ядра, и оно ни с кем его не делит
- 144. Ядро 0 запрашивает данные из L3-кэша, и они там не обнаруживаются слева не инклюзивный кэш
- 146. Скачать презентацию

Основными свойствами алгоритма являются: дискретность, определенность, массовость и результативность.
Дискретность выражается в
Основными свойствами алгоритма являются: дискретность, определенность, массовость и результативность.
Дискретность выражается в

Массовость алгоритма подразумевает его применимость к множеству значений исходных данных, а
Массовость алгоритма подразумевает его применимость к множеству значений исходных данных, а

В основе архитектуры современных ВМ лежит представление алгоритма решения задачи в
В основе архитектуры современных ВМ лежит представление алгоритма решения задачи в

Сущность фон-неймановской концепции вычислительной машины можно свести к четырем принципам:
двоичного кодирования;
Сущность фон-неймановской концепции вычислительной машины можно свести к четырем принципам:
двоичного кодирования;

Согласно принципу двоичного кодирования, вся информация, как данные, так и команды,
Согласно принципу двоичного кодирования, вся информация, как данные, так и команды,

Код операции представляет собой указание, какая операция должна быть выполнена, и
Код операции представляет собой указание, какая операция должна быть выполнена, и

Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть
Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть

Принцип однородности памяти
Команды и данные хранятся в одной и той же
Принцип однородности памяти
Команды и данные хранятся в одной и той же

Концепция вычислительной машины, изложенная в статье фон Неймана, предполагает единую память
Концепция вычислительной машины, изложенная в статье фон Неймана, предполагает единую память

Принцип адресности
Структурно основная память состоит из пронумерованных ячеек, причем процессору в
Принцип адресности
Структурно основная память состоит из пронумерованных ячеек, причем процессору в
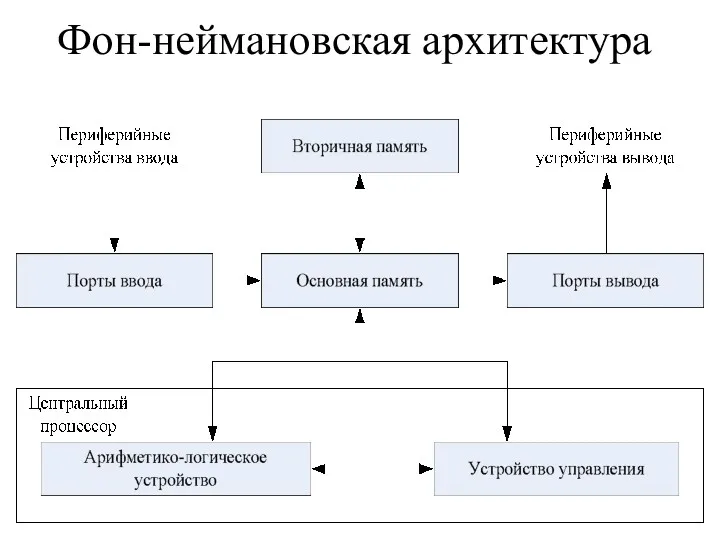
Фон-неймановская архитектура
Фон-неймановская архитектура

Фон Неймана определил основные устройства ВМ, с помощью которых должны быть
Фон Неймана определил основные устройства ВМ, с помощью которых должны быть

Введенная информация сначала запоминается в основной памяти, а затем переносится во
Введенная информация сначала запоминается в основной памяти, а затем переносится во

Для таких ЗУ характерна энергозависимость – хранимая информация теряется при отключении
Для таких ЗУ характерна энергозависимость – хранимая информация теряется при отключении

Для долговременного хранения больших программ и массивов данных в ВМ обычно
Для долговременного хранения больших программ и массивов данных в ВМ обычно

Устройство управления (УУ) – важнейшая часть ВМ, организующая автоматическое выполнение программ
Устройство управления (УУ) – важнейшая часть ВМ, организующая автоматическое выполнение программ

Пересылка информации между любыми элементами ВМ инициируется своим сигналом управления (СУ),
Пересылка информации между любыми элементами ВМ инициируется своим сигналом управления (СУ),

Еще одной неотъемлемой частью ВМ является арифметико-логическое устройство (АЛУ). АЛУ обеспечивает
Еще одной неотъемлемой частью ВМ является арифметико-логическое устройство (АЛУ). АЛУ обеспечивает

Флаги могут анализироваться в УУ с целью принятия решения о дальнейшей
Флаги могут анализироваться в УУ с целью принятия решения о дальнейшей

Классификация архитектур
По структуре вычислительных машин
Классификация архитектур
По структуре вычислительных машин

В настоящее время примерно одинаковое распространение получили два способа построения вычислительных
В настоящее время примерно одинаковое распространение получили два способа построения вычислительных
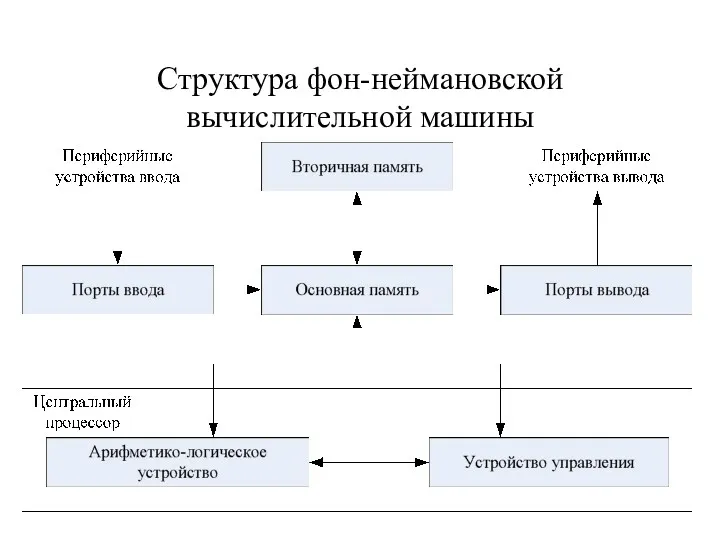
Структура фон-неймановской вычислительной машины
Структура фон-неймановской вычислительной машины

У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между
У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между
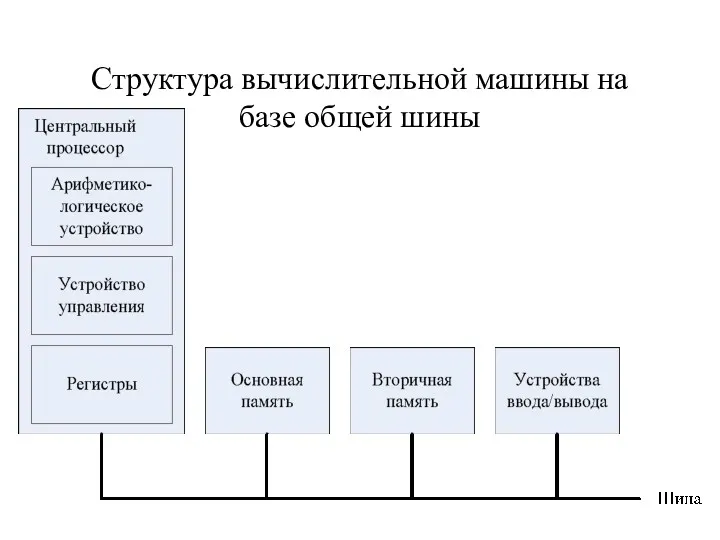
Структура вычислительной машины на базе общей шины
Структура вычислительной машины на базе общей шины

Благодаря этим свойствам шинная архитектура получила широкое распространение в мини и
Благодаря этим свойствам шинная архитектура получила широкое распространение в мини и

В целом, при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная
В целом, при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная
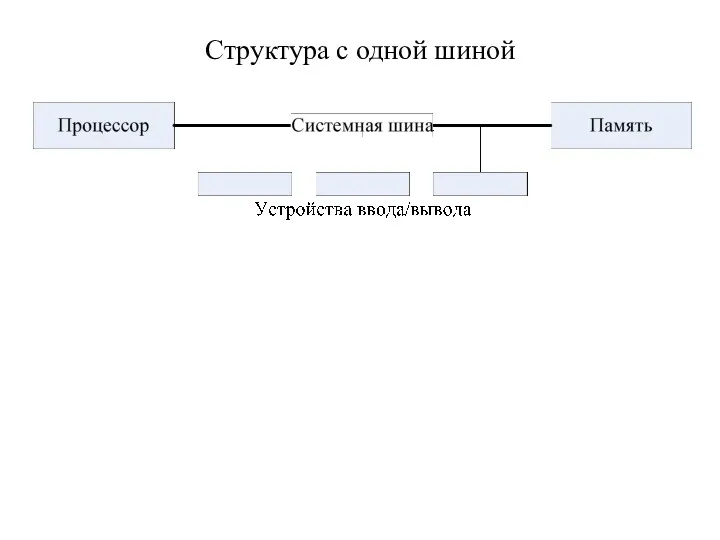
Структура с одной шиной
Структура с одной шиной
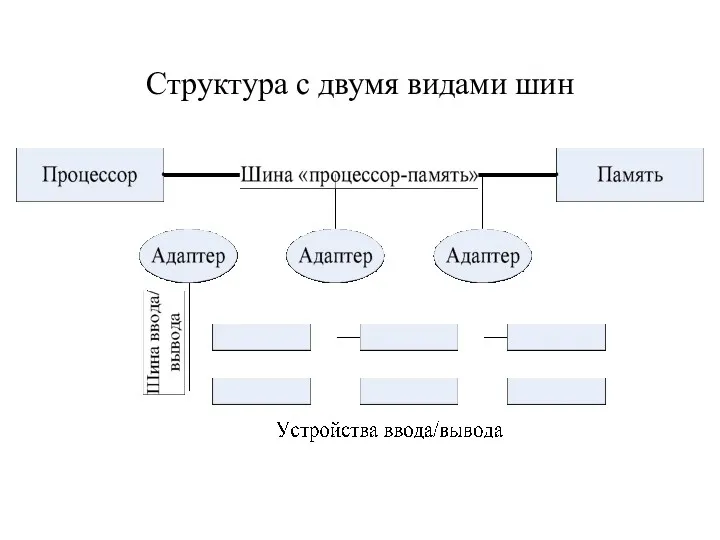
Структура с двумя видами шин
Структура с двумя видами шин
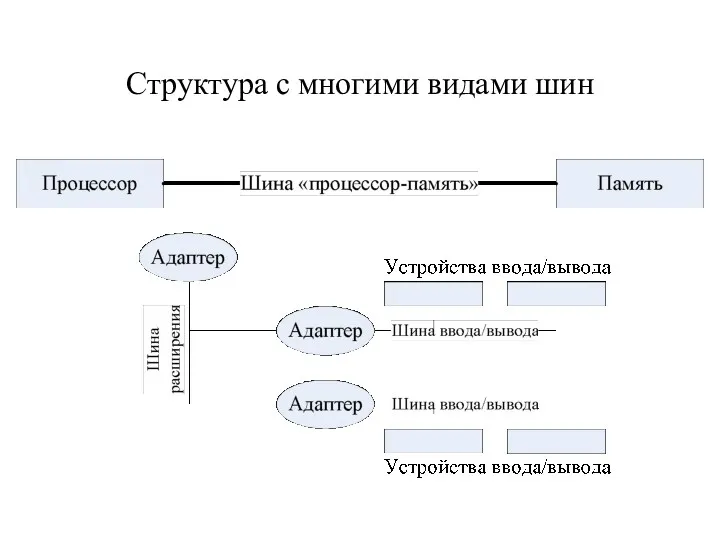
Структура с многими видами шин
Структура с многими видами шин

Классификация архитектур
По системам команд
Классификация архитектур
По системам команд

Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять


Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной
Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной
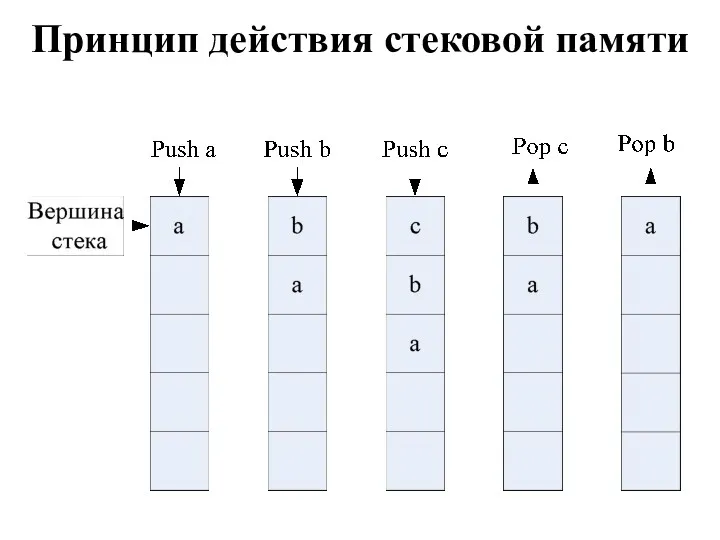
Принцип действия стековой памяти
Принцип действия стековой памяти

Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две

Архитектура вычислительной машины на базе стека
Архитектура вычислительной машины на базе стека

Для выполнения арифметической или логической операции на вход АЛУ подается информация,
Для выполнения арифметической или логической операции на вход АЛУ подается информация,

К достоинствам АСК на базе стека следует отнести возможность сокращения адресной
К достоинствам АСК на базе стека следует отнести возможность сокращения адресной

Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В
Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В
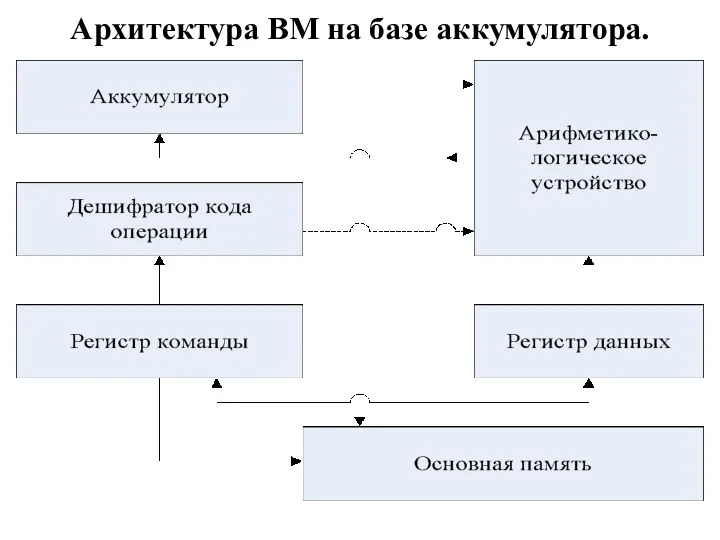
Архитектура ВМ на базе аккумулятора.
Архитектура ВМ на базе аккумулятора.

Для выполнения операции в АЛУ производится считывание одного из операндов из
Для выполнения операции в АЛУ производится считывание одного из операндов из

Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров
Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров

RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако
RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако

В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них
В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них

К достоинствам регистровых АСК следует отнести: компактность получаемого кода, высокую скорость
К достоинствам регистровых АСК следует отнести: компактность получаемого кода, высокую скорость

Архитектура с выделенным доступом к памяти
В архитектуре с выделенным доступом к
Архитектура с выделенным доступом к памяти
В архитектуре с выделенным доступом к

В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти.
В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти.

Классификация по составу и сложности команд
Современная технология программирования ориентирована на
Классификация по составу и сложности команд
Современная технология программирования ориентирована на

Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают
Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают

В вычислительных машинах типа CISC проблема семантического разрыва решается за счет
В вычислительных машинах типа CISC проблема семантического разрыва решается за счет

К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины
К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины

Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в
Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в

Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ

Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один
Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один

Основные направления в развитии архитектур процессоров
Конвейеризация вычислений
Суперконвейерные процессоры
Суперскалярные
Основные направления в развитии архитектур процессоров
Конвейеризация вычислений
Суперконвейерные процессоры
Суперскалярные

Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком
Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком

3. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов
3. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов

Логика работы конвейера команд
Логика работы конвейера команд

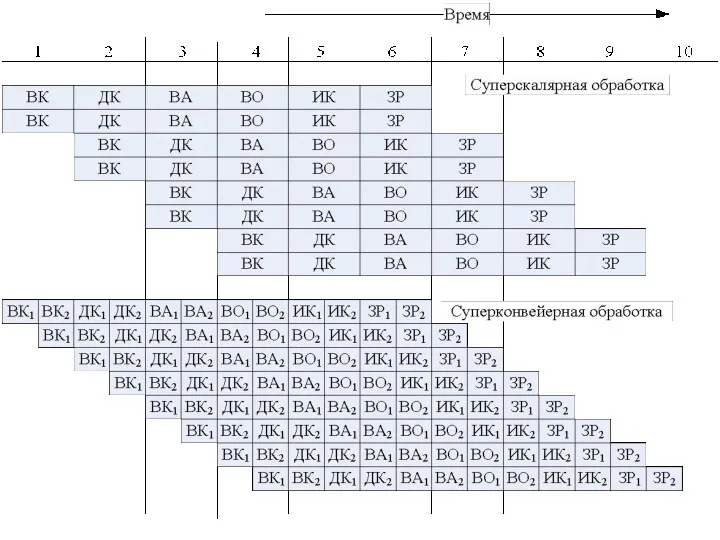
На рисунке показан конвейер с шестью ступенями, соответствующими шести этапам цикла
На рисунке показан конвейер с шестью ступенями, соответствующими шести этапам цикла

Суперконвейер
Разбиение каждой ступени конвейера на n «подступеней» при одновременном повышении тактовой
Суперконвейер
Разбиение каждой ступени конвейера на n «подступеней» при одновременном повышении тактовой
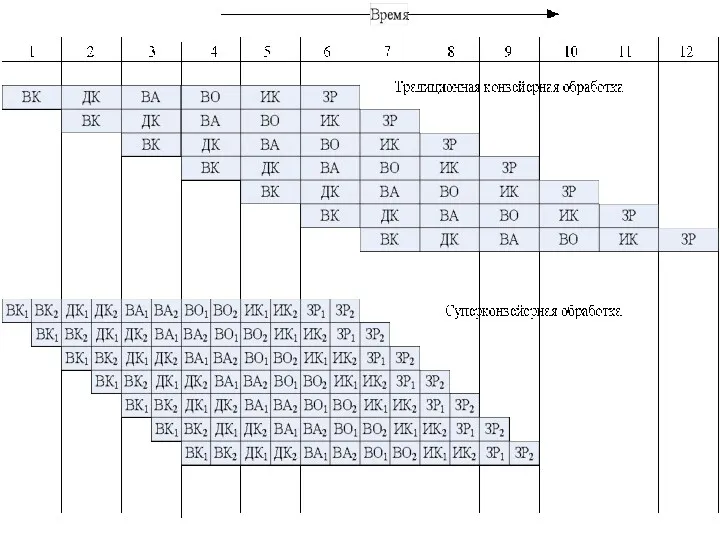

Каждая из шести ступеней стандартного конвейера разбита на две более простые
Каждая из шести ступеней стандартного конвейера разбита на две более простые

Структурный риск - попытка нескольких команд одновременно обратиться к одному и
Структурный риск - попытка нескольких команд одновременно обратиться к одному и

Структурный риск имеет место, когда несколько команд, находящихся на разных ступенях
Структурный риск имеет место, когда несколько команд, находящихся на разных ступенях

«Чтение после записи» (ЧПЗ): команда j читает X до того, как
«Чтение после записи» (ЧПЗ): команда j читает X до того, как

Для решения этих проблем применяют предвыборку команд и их спекулятивное выполнение.
Для решения этих проблем применяют предвыборку команд и их спекулятивное выполнение.

Влияние условного перехода на работу конвейера команд
Влияние условного перехода на работу конвейера команд

Пусть команда 3 – это условный переход к команде 15. До
Пусть команда 3 – это условный переход к команде 15. До

Статическое предсказание переходов.
Динамическое предсказание переходов.
Классификации схем предсказания переходов
Статическое предсказание переходов.
Динамическое предсказание переходов.
Классификации схем предсказания переходов

Переход происходит всегда.
Переход не происходит никогда.
Предсказание определяется по результатам профилирования.
Предсказание определяется
Переход происходит всегда.
Переход не происходит никогда.
Предсказание определяется по результатам профилирования.
Предсказание определяется

Предполагается, что каждая команда условного перехода в программе обязательно завершится переходом,
Предполагается, что каждая команда условного перехода в программе обязательно завершится переходом,

Предполагается, что ни одна из команд условного перехода в программе никогда
Предполагается, что ни одна из команд условного перехода в программе никогда

По результатам профилирования, тем командам, которые чаще завершались переходом, назначается стратегия
По результатам профилирования, тем командам, которые чаще завершались переходом, назначается стратегия

Для одних команд предполагается, что переход произойдет, для других — его
Для одних команд предполагается, что переход произойдет, для других — его

Одноуровневые или бимодальные.
Двухуровневые или коррелированные.
Гибридные.
Асимметричные.
Стратегии динамического предсказания для команд УП
Одноуровневые или бимодальные.
Двухуровневые или коррелированные.
Гибридные.
Асимметричные.
Стратегии динамического предсказания для команд УП

Одноуровневые схемы предсказания переходов
Идея одноуровневых схем предсказания, сводится к отделению
Одноуровневые схемы предсказания переходов
Идея одноуровневых схем предсказания, сводится к отделению

Предсказание осуществляется на основе предыдущих исходов как команды УП, для которой
Предсказание осуществляется на основе предыдущих исходов как команды УП, для которой

Гибридные схемы объединяют в себе несколько различных механизмов предсказания — элементарных
Гибридные схемы объединяют в себе несколько различных механизмов предсказания — элементарных

Асимметричная схема сочетает в себе черты гибридных и коррелированных схем
Асимметричная схема сочетает в себе черты гибридных и коррелированных схем

Суперскалярность
Суперскалярным (этот термин впервые был использован в 1987 году) называется
Суперскалярность
Суперскалярным (этот термин впервые был использован в 1987 году) называется
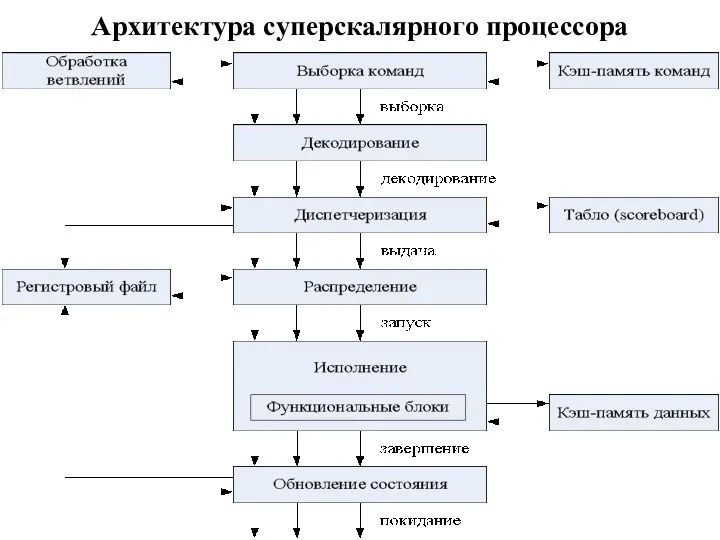
Архитектура суперскалярного процессора
Архитектура суперскалярного процессора

Блок выборки команд извлекает команды из основной памяти через кэш-память команд.
Блок выборки команд извлекает команды из основной памяти через кэш-память команд.

Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число
Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число

Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет
Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет

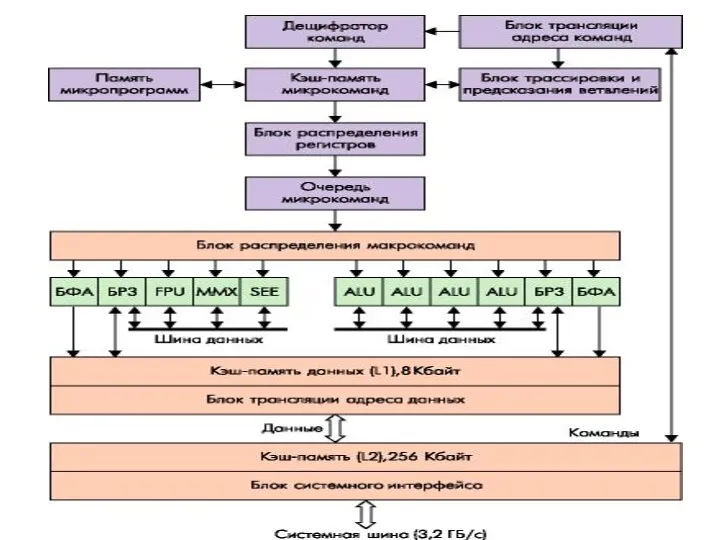

БФА - блок формирования адреса
БРЗ - блок регистров замещения
FPU - АЛУ
БФА - блок формирования адреса
БРЗ - блок регистров замещения
FPU - АЛУ

Hyper-threading ( Hyper-threading — Гиперпоточность)
В процессорах с использованием этой технологии каждый
Hyper-threading ( Hyper-threading — Гиперпоточность)
В процессорах с использованием этой технологии каждый

Потоки
С точки зрения процессора, поток – это набор инструкций, которые необходимо
Потоки
С точки зрения процессора, поток – это набор инструкций, которые необходимо

Развитие микропроцессоров
CMP (Chip Multi Processing -многоядерность )
SMT (Simultaneous MultiThreading -многонитевая
Развитие микропроцессоров
CMP (Chip Multi Processing -многоядерность )
SMT (Simultaneous MultiThreading -многонитевая

Направление CMP
Создание на одном кристалле нескольких микропроцессоров и организация их работы
Направление CMP
Создание на одном кристалле нескольких микропроцессоров и организация их работы

Направление SMT
На одном процессоре осуществляется запуск нескольких задач одновременно, при
Направление SMT
На одном процессоре осуществляется запуск нескольких задач одновременно, при

Архитектура EPIC
На входе процессора последовательность больших команд, состоящих из нескольких простых
Архитектура EPIC
На входе процессора последовательность больших команд, состоящих из нескольких простых

Недостатки
Значительно усложняются компиляторы
Производительность микропроцессора во многом определяется качеством компилятора
Увеличивается сложность отладки
Недостатки
Значительно усложняются компиляторы
Производительность микропроцессора во многом определяется качеством компилятора
Увеличивается сложность отладки

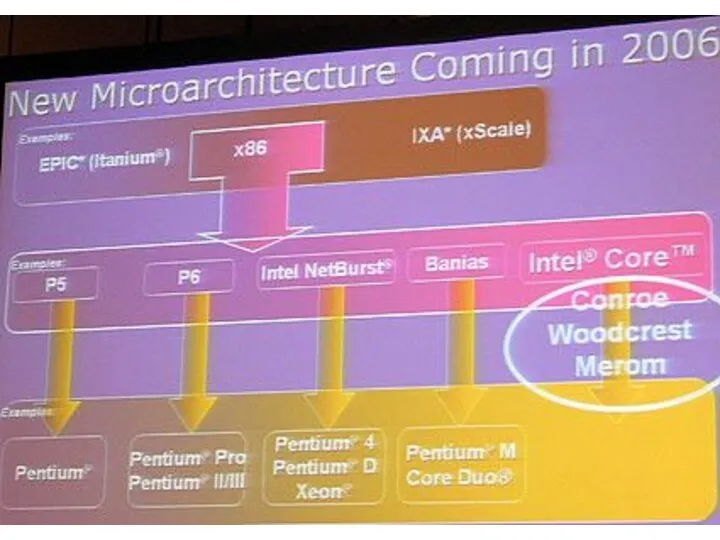
Развитие микропроцессоров
на примере линейки микропроцессоров X86
фирмы Intel
Развитие микропроцессоров
на примере линейки микропроцессоров X86
фирмы Intel


Архитектура Pentium M
Мобильная версия
RISC архитектура как в Pentium III, IV
Пять
Архитектура Pentium M
Мобильная версия
RISC архитектура как в Pentium III, IV
Пять

Архитектура Intel Core
Conroe - настольные ПК
Архитектура Intel Core
Conroe - настольные ПК

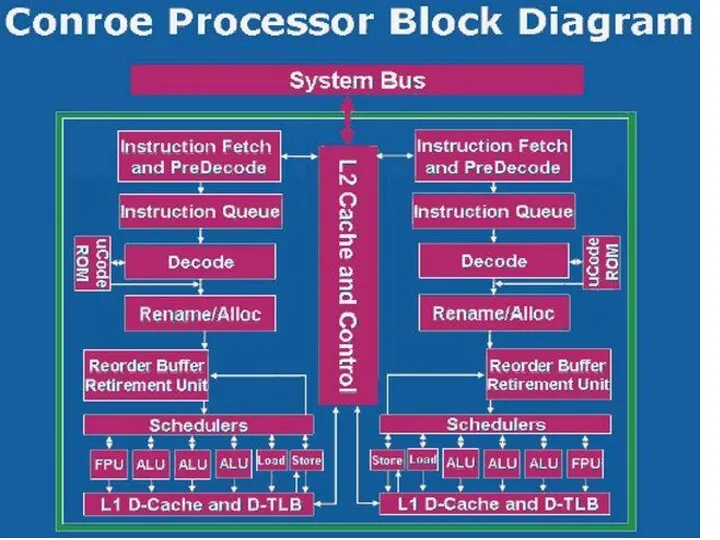

Основные особенности архитектуры Intel Core
Технология широкого динамического выполнения (Wide Dynamic Execution)
Основные особенности архитектуры Intel Core
Технология широкого динамического выполнения (Wide Dynamic Execution)

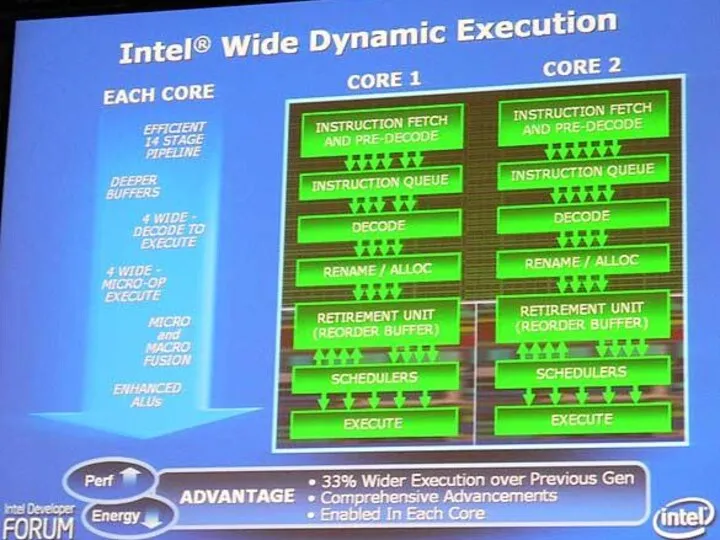
Технология широкого динамического выполнения
Призвана обеспечить выполнение большего количества команд за каждый
Технология широкого динамического выполнения
Призвана обеспечить выполнение большего количества команд за каждый
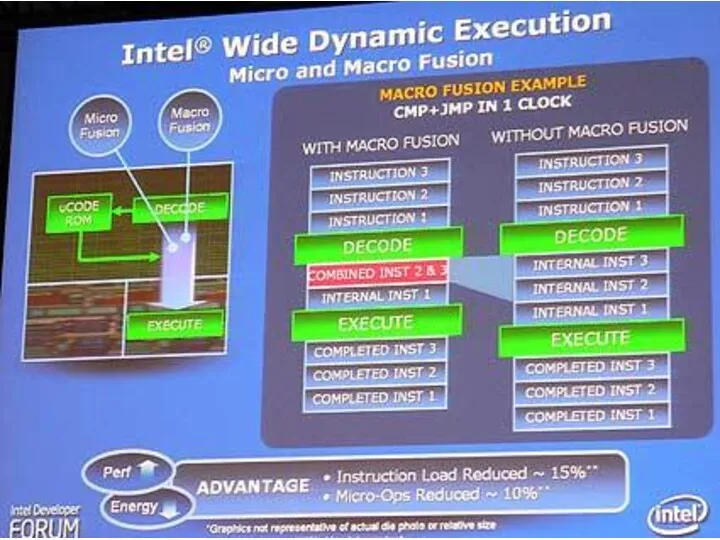



Интеллектуальная система управления энергопотреблением
Технологии стробирования тактовых импульсов (clock gating) и "спящих"
Интеллектуальная система управления энергопотреблением
Технологии стробирования тактовых импульсов (clock gating) и "спящих"


Улучшенный "умный" кэш
Два ядра совместно используют кэш объёмом 2 или 4
Улучшенный "умный" кэш
Два ядра совместно используют кэш объёмом 2 или 4
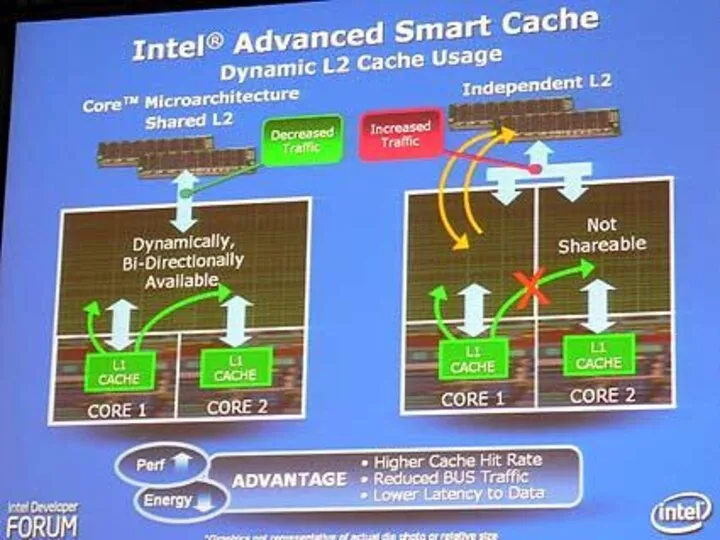

"Умный" доступ к памяти
Улучшенная предварительная выборка
Каждый двуядерный процессор Core оснащён восемью
"Умный" доступ к памяти
Улучшенная предварительная выборка
Каждый двуядерный процессор Core оснащён восемью

"Умный" доступ к памяти
Улучшенная предварительная выборка
Блоки предварительной выборки памяти постоянно оценивают
"Умный" доступ к памяти
Улучшенная предварительная выборка
Блоки предварительной выборки памяти постоянно оценивают

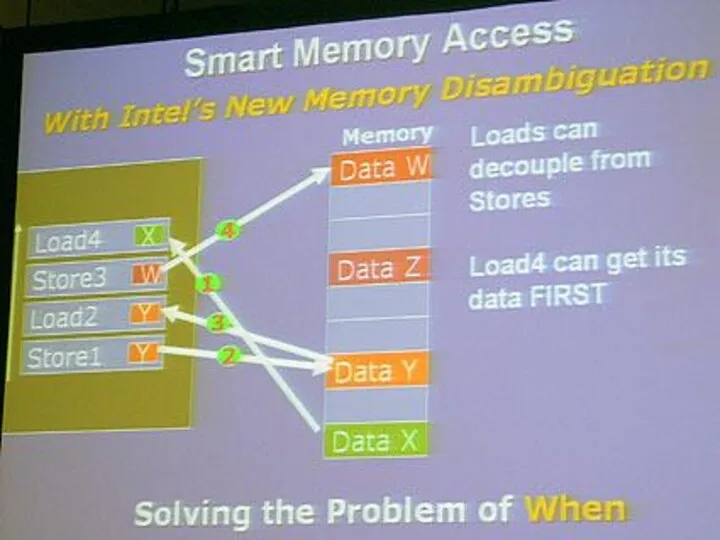
"Умный" доступ к памяти
Устранение неоднозначностей памяти
Блок устранения неоднозначностей памяти выбирает операции
"Умный" доступ к памяти
Устранение неоднозначностей памяти
Блок устранения неоднозначностей памяти выбирает операции


Улучшенная работа с цифровым медиа-содержанием
АЛУ обычно разбивает инструкции на два блока,
Улучшенная работа с цифровым медиа-содержанием
АЛУ обычно разбивает инструкции на два блока,


Архитектура Core i3 - i7
Основной чертой новой архитектуры стала модульность
Архитектура Core i3 - i7
Основной чертой новой архитектуры стала модульность

Прочие блоки могут быть следующими:
разделяемый кэш 3-го уровня;
контроллер памяти;
контроллер шины QPI
Прочие блоки могут быть следующими:
разделяемый кэш 3-го уровня;
контроллер памяти;
контроллер шины QPI

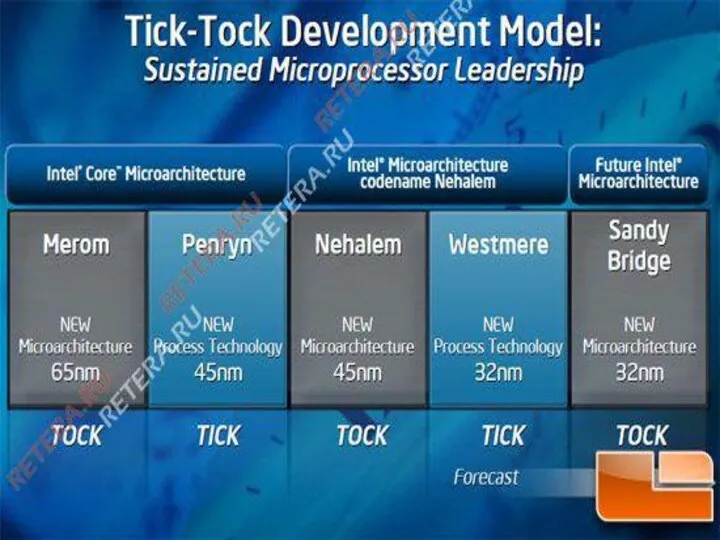
Core i3
Компания Intel разработала в 2006 году концепцию Tick-Tock (тик-так). Суть
Core i3
Компания Intel разработала в 2006 году концепцию Tick-Tock (тик-так). Суть

Core i3
Самое основное отличие новых процессоров от предыдущих версий – это
Core i3
Самое основное отличие новых процессоров от предыдущих версий – это


ТЕХНОЛОГИИ CORE i3
Новая улучшенная версия Hyper-threading Simultaneous MultiThreading (SMT). Благодаря SMT
ТЕХНОЛОГИИ CORE i3
Новая улучшенная версия Hyper-threading Simultaneous MultiThreading (SMT). Благодаря SMT

ТЕХНОЛОГИИ CORE i3
Для слежения за состоянием процессора, в нем был размещен
ТЕХНОЛОГИИ CORE i3
Для слежения за состоянием процессора, в нем был размещен

ТЕХНОЛОГИИ CORE i3
Линейка процессоров Core i3, в отличии от более дорогих
ТЕХНОЛОГИИ CORE i3
Линейка процессоров Core i3, в отличии от более дорогих

ТЕХНОЛОГИИ CORE i3
Virtualization Technology (VT) - Аппаратная виртуализация, позволяет запускать на
ТЕХНОЛОГИИ CORE i3
Virtualization Technology (VT) - Аппаратная виртуализация, позволяет запускать на

ТЕХНОЛОГИИ CORE i3
Execute Disable Bit обеспечивает защиту от вредоносных атак, направленных
ТЕХНОЛОГИИ CORE i3
Execute Disable Bit обеспечивает защиту от вредоносных атак, направленных

ТЕХНОЛОГИИ CORE i3
Enhanced Intel SpeedStep - энергосберегающая технология Intel, вызывающая, в
ТЕХНОЛОГИИ CORE i3
Enhanced Intel SpeedStep - энергосберегающая технология Intel, вызывающая, в

ТЕХНОЛОГИИ CORE i3
Trusted Execution состоит из последовательно защищённых этапов обработки. В
ТЕХНОЛОГИИ CORE i3
Trusted Execution состоит из последовательно защищённых этапов обработки. В

ТЕХНОЛОГИИ CORE i3
Intel 64 Architecture поддерживает 64-битные вычисления, что позволяет устанавливать
ТЕХНОЛОГИИ CORE i3
Intel 64 Architecture поддерживает 64-битные вычисления, что позволяет устанавливать

ГРАФИЧЕСКОЕ ЯДРО
Графический чип Intel HD Graphics так же использует систему из
ГРАФИЧЕСКОЕ ЯДРО
Графический чип Intel HD Graphics так же использует систему из

ГРАФИЧЕСКОЕ ЯДРО
Графический чип находится на общем кристалле с контроллером памяти, что
ГРАФИЧЕСКОЕ ЯДРО
Графический чип находится на общем кристалле с контроллером памяти, что

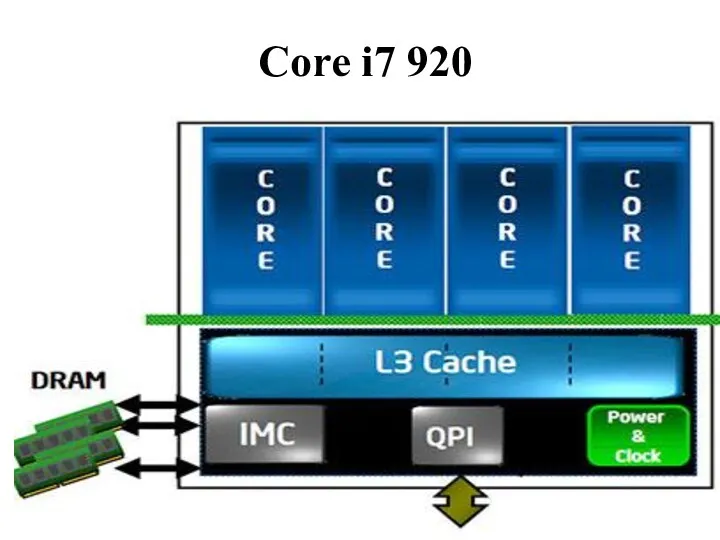
Core i7 920
Core i7 920

Core i7 920
Трёхканальный контроллер памяти DDR3 с максимальной скоростью 32 GBps
Core i7 920
Трёхканальный контроллер памяти DDR3 с максимальной скоростью 32 GBps

Core i7 920
Управление энергопотреблением
частота и напряжение питания для каждого ядра
Core i7 920
Управление энергопотреблением
частота и напряжение питания для каждого ядра

Core i7 920
Управление энергопотреблением
Технология Turbo Boost процессора может повышать частоту
Core i7 920
Управление энергопотреблением
Технология Turbo Boost процессора может повышать частоту

Подсистема кэширования
L2 является «персональной собственностью» конкретного ядра, и оно ни с
Подсистема кэширования
L2 является «персональной собственностью» конкретного ядра, и оно ни с
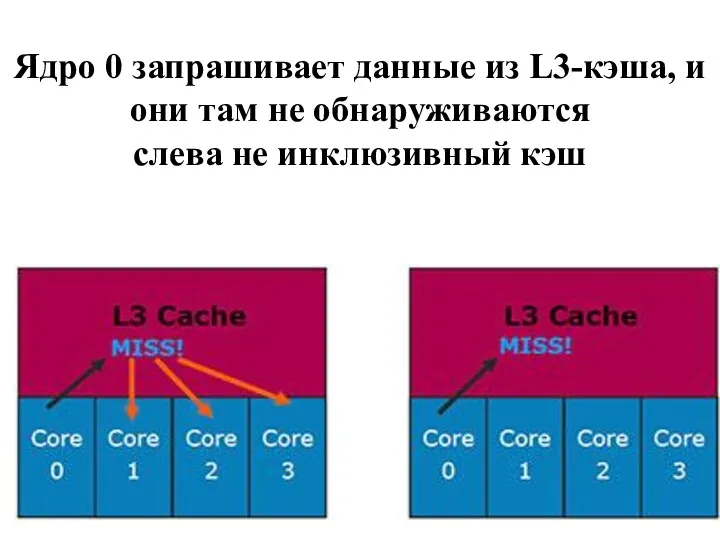
Ядро 0 запрашивает данные из L3-кэша, и они там не обнаруживаются
слева
Ядро 0 запрашивает данные из L3-кэша, и они там не обнаруживаются слева
 Использование анимации и звука в презентации
Использование анимации и звука в презентации участие в проекте Компьютер для школьника
участие в проекте Компьютер для школьника История Вконтакте
История Вконтакте Маршрутизаторы, функция VPN
Маршрутизаторы, функция VPN Комплексная автоматизированная система учёта, контроля устранения отказов технических средств и анализа их надежности (Касант)
Комплексная автоматизированная система учёта, контроля устранения отказов технических средств и анализа их надежности (Касант) Образовательные сайты для педагогов
Образовательные сайты для педагогов Функционирование ЭВМ с канальной организацией
Функционирование ЭВМ с канальной организацией Банк бизнес-партнеров. Проверка контрагента. Онлайн-чат
Банк бизнес-партнеров. Проверка контрагента. Онлайн-чат Программирование на языке С. Модуль 2. Операции
Программирование на языке С. Модуль 2. Операции Правила игры. Цепочка позиций
Правила игры. Цепочка позиций Основные понятия и определения. Основы программирования и баз данных www.specialist.ru
Основные понятия и определения. Основы программирования и баз данных www.specialist.ru Команды и алгоритм
Команды и алгоритм Стандарт OpenMP. Информационные ресурсы. Лекция 3
Стандарт OpenMP. Информационные ресурсы. Лекция 3 KPI в SMM
KPI в SMM Пресс для тюбика на 3D принтере
Пресс для тюбика на 3D принтере Ma’lumot modeli tushunchasi. Ierarxik (shajara) ma’lumot modeli
Ma’lumot modeli tushunchasi. Ierarxik (shajara) ma’lumot modeli Аппаратное обеспечение для подключения к сети интернет
Аппаратное обеспечение для подключения к сети интернет Files, file share, permissions
Files, file share, permissions Мобильное приложение
Мобильное приложение Уровни организации ЭВМ. Операционные системы
Уровни организации ЭВМ. Операционные системы Платформы для дистанционного обучения
Платформы для дистанционного обучения An Introduction to Computer Networking
An Introduction to Computer Networking Компьютеры первого поколения
Компьютеры первого поколения L–атрибутты трансляциялау грамматикалары. Атрибутты түрлендірушілер
L–атрибутты трансляциялау грамматикалары. Атрибутты түрлендірушілер Платформа Ардуино
Платформа Ардуино История развития языков программирования
История развития языков программирования Логикалық операциялар, салыстыру операциялары
Логикалық операциялар, салыстыру операциялары Элементы алгебры логики. Математические основы информатики
Элементы алгебры логики. Математические основы информатики