- Стандарт OpenMP. Информационные ресурсы. Лекция 3

Содержание
- 2. Информационные ресурсы www.openmp.org http://parallel.ru/tech/tech_dev/openmp.html www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D., McDonald,
- 3. Стратегия подхода OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей памятью. Модели параллельного компьютера
- 4. Динамика развития стандарта OpenMP Fortran API v1.0 (1997) OpenMP C/C++ API v1.0 (1998) OpenMP Fortran API
- 5. Динамика развития стандарта OpenMP Fortran API v1.0 (1997) OpenMP C/C++ API v1.0 (1998) OpenMP Fortran API
- 6. Достоинства Поэтапное (инкрементальное) распараллеливание Единственность разрабатываемого кода Эффективность Стандартизированность
- 7. Принцип организации параллелизма Использование потоков Пульсирующий («вилочный») параллелизм
- 8. Структура OpenMP: Набор директив Библиотека функций Набор переменных окружения
- 9. Директивы OpenMP Формат #pragma omp имя_директивы [clause,…] Пример #pragma omp parallel default (shared) \ private (beta,
- 10. Области видимости директив
- 11. Типы директив Определение параллельной области; Разделение работы; Синхронизация.
- 12. Определение параллельной области Директива parallel: #pragma omp parallel [clause …] structured_block clause if (scalar_expression) private (list)
- 13. Определение параллельной области #include #include int main(int argc, char *argv[]) { int nthreads, tid; #pragma omp
- 14. Распределение вычислений DO/for – распараллеливание циклов sections – распараллеливание раздельных фрагментов кода single – директива последовательного
- 15. Директива DO/for Директива DO/for: #pragma omp for [clause …] for_loop clause scheldule (type [,chunk]) ordered private
- 16. Директива DO/for #include #include int main(int argc, char *argv[]) { int A[10], B[10], C[10], i, n;
- 17. Директива sections Директива section: #pragma omp sections [clause …] { #pragma omp section structured_block… } clause
- 18. Директива sections #include #include int main(int argc, char *argv[]) { int n = 0; #pragma omp
- 19. Директива single Директива single: #pragma omp single [clause …] { #pragma omp section structured_block… } clause
- 20. Директива master #include int main(int argc, char *argv[]) { int n; #pragma omp parallel private(n) {
- 21. Директива critical #include #include int main(int argc, char *argv[]) { int n; #pragma omp parallel {
- 22. Директива barrier #include #include int main(int argc, char *argv[]) { #pragma omp parallel { printf("Сообщение 1\n");
- 23. Директива atomic #include #include int main(int argc, char *argv[]) { int count = 0; #pragma omp
- 24. Директива flush #include #include int main(int argc, char *argv[]) { int count = 0; #pragma omp
- 25. Директива ordered #include #include int main(int argc, char *argv[]) { int i, n; #pragma omp parallel
- 26. Управление областью видимости if (scalar_expression) shared (list) private (list) clause: firstprivate (list) lastprivate (list) reduction (operator:
- 27. Параметр reduction Возможный формат записи: x = x op expr x = expr op x x
- 28. Совместимость директив и параметров
- 29. Библиотека функций OpenMP void omp_set_num_threads(int num) int omp_get_max_threads(void) int omp_get_num_threads(void) int omp_get_thread_num (void) int omp_get_num_procs (void)
- 30. Библиотека функций OpenMP void omp_init_lock(omp_lock_t *lock) void omp_nest_init_lock(omp_nest_lock_t *lock) void omp_destroy_lock(omp_lock_t *lock) void omp_destroy_nest_lock(omp_nest_lock_t *lock) void
- 31. Переменные среды OpenMP OMP_SCHEDULE OMP_NUM_THREADS OMP_DYNAMIC OMP_NESTED
- 33. Скачать презентацию

Информационные ресурсы
www.openmp.org
http://parallel.ru/tech/tech_dev/openmp.html
www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D.,
Информационные ресурсы
www.openmp.org
http://parallel.ru/tech/tech_dev/openmp.html
www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra, R., Menon R., Dagum, L., Kohr, D., Maydan, D.,
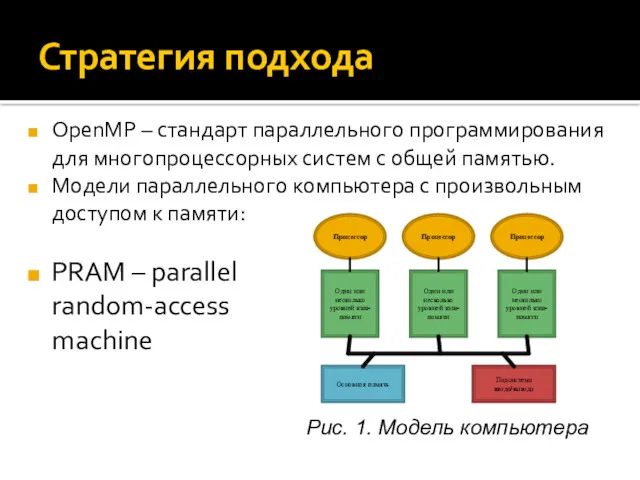
Стратегия подхода
OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей
Стратегия подхода
OpenMP – стандарт параллельного программирования для многопроцессорных систем с общей

Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP
Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP

Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP
Динамика развития стандарта
OpenMP Fortran API v1.0 (1997)
OpenMP C/C++ API v1.0 (1998)
OpenMP

Достоинства
Поэтапное (инкрементальное) распараллеливание
Единственность разрабатываемого кода
Эффективность
Стандартизированность
Достоинства
Поэтапное (инкрементальное) распараллеливание
Единственность разрабатываемого кода
Эффективность
Стандартизированность
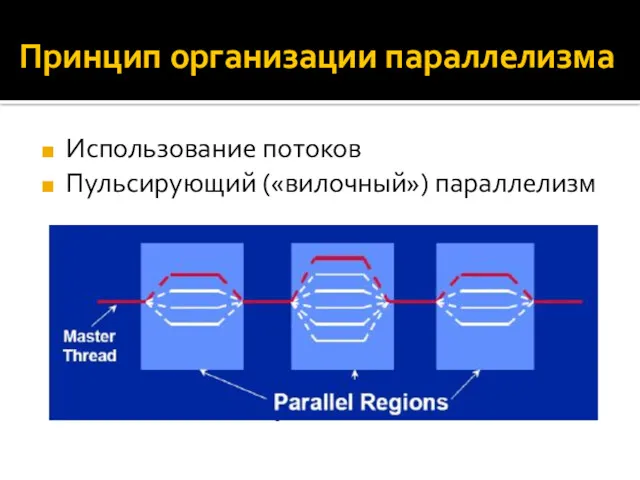
Принцип организации параллелизма
Использование потоков
Пульсирующий («вилочный») параллелизм
Принцип организации параллелизма
Использование потоков
Пульсирующий («вилочный») параллелизм

Структура OpenMP:
Набор директив
Библиотека функций
Набор переменных окружения
Структура OpenMP:
Набор директив
Библиотека функций
Набор переменных окружения
![Директивы OpenMP Формат #pragma omp имя_директивы [clause,…] Пример #pragma omp](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-8.jpg)
Директивы OpenMP
Формат
#pragma omp имя_директивы [clause,…]
Пример
#pragma omp parallel default (shared)
Директивы OpenMP
Формат
#pragma omp имя_директивы [clause,…]
Пример
#pragma omp parallel default (shared)
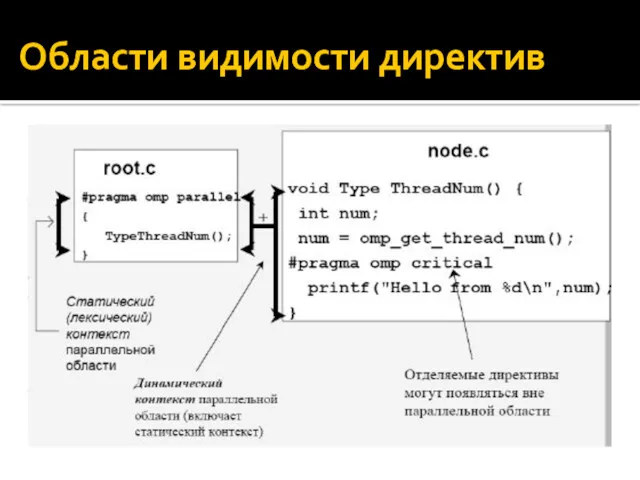
Области видимости директив
Области видимости директив

Типы директив
Определение параллельной области;
Разделение работы;
Синхронизация.
Типы директив
Определение параллельной области;
Разделение работы;
Синхронизация.
![Определение параллельной области Директива parallel: #pragma omp parallel [clause …]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-11.jpg)
Определение параллельной области
Директива parallel:
#pragma omp parallel [clause …] structured_block
clause
if (scalar_expression)
private
Определение параллельной области
Директива parallel:
#pragma omp parallel [clause …] structured_block
clause
if (scalar_expression)
private
![Определение параллельной области #include #include int main(int argc, char *argv[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-12.jpg)
Определение параллельной области
#include
#include
int main(int argc, char *argv[])
Определение параллельной области
#include
#include
int main(int argc, char *argv[])

Распределение вычислений
DO/for – распараллеливание циклов
sections – распараллеливание раздельных фрагментов кода
single –
Распределение вычислений
DO/for – распараллеливание циклов
sections – распараллеливание раздельных фрагментов кода
single –
![Директива DO/for Директива DO/for: #pragma omp for [clause …] for_loop](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-14.jpg)
Директива DO/for
Директива DO/for:
#pragma omp for [clause …]
for_loop
clause
scheldule (type [,chunk])
ordered
private (list)
firstprivate (list)
lastprivate
Директива DO/for
Директива DO/for:
#pragma omp for [clause …]
for_loop
clause
scheldule (type [,chunk])
ordered
private (list)
firstprivate (list)
lastprivate
![Директива DO/for #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-15.jpg)
Директива DO/for
#include
#include
int main(int argc, char *argv[]) {
Директива DO/for
#include
#include
int main(int argc, char *argv[]) {
![Директива sections Директива section: #pragma omp sections [clause …] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-16.jpg)
Директива sections
Директива section:
#pragma omp sections [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
Директива sections
Директива section:
#pragma omp sections [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
![Директива sections #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-17.jpg)
Директива sections
#include
#include
int main(int argc, char *argv[]) {
Директива sections
#include
#include
int main(int argc, char *argv[]) {
![Директива single Директива single: #pragma omp single [clause …] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-18.jpg)
Директива single
Директива single:
#pragma omp single [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
Директива single
Директива single:
#pragma omp single [clause …]
{
#pragma omp section
structured_block…
}
clause
private (list)
firstprivate
![Директива master #include int main(int argc, char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-19.jpg)
Директива master
#include
int main(int argc, char *argv[]) {
int
Директива master
#include
int main(int argc, char *argv[]) {
int
![Директива critical #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-20.jpg)
Директива critical
#include
#include
int main(int argc, char *argv[])
{
Директива critical
#include
#include
int main(int argc, char *argv[])
{
![Директива barrier #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-21.jpg)
Директива barrier
#include
#include
int main(int argc, char *argv[])
{
Директива barrier
#include
#include
int main(int argc, char *argv[])
{
![Директива atomic #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-22.jpg)
Директива atomic
#include
#include
int main(int argc, char *argv[])
{
Директива atomic
#include
#include
int main(int argc, char *argv[])
{
![Директива flush #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-23.jpg)
Директива flush
#include
#include
int main(int argc, char *argv[])
{
Директива flush
#include
#include
int main(int argc, char *argv[])
{
![Директива ordered #include #include int main(int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/137203/slide-24.jpg)
Директива ordered
#include
#include
int main(int argc, char *argv[]) {
Директива ordered
#include
#include
int main(int argc, char *argv[]) {

Управление областью видимости
if (scalar_expression)
shared (list)
private (list)
clause:
firstprivate (list)
lastprivate (list)
reduction (operator: list)
default (shared
Управление областью видимости
if (scalar_expression)
shared (list)
private (list)
clause:
firstprivate (list)
lastprivate (list)
reduction (operator: list)
default (shared

Параметр reduction
Возможный формат записи:
x = x op expr
x =
Параметр reduction
Возможный формат записи:
x = x op expr
x =
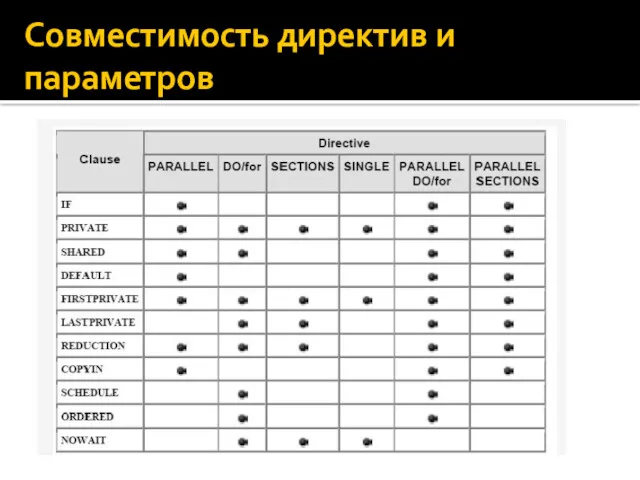
Совместимость директив и параметров
Совместимость директив и параметров

Библиотека функций OpenMP
void omp_set_num_threads(int num)
int omp_get_max_threads(void)
int omp_get_num_threads(void)
int omp_get_thread_num (void)
int omp_get_num_procs (void)
int omp_in_parallel (void)
void omp_set_dynamic(int num)
int omp_get_dynamic(void)
void omp_get_nested(void)
void omp_set_nested(int nested)
Библиотека функций OpenMP
void omp_set_num_threads(int num)
int omp_get_max_threads(void)
int omp_get_num_threads(void)
int omp_get_thread_num (void)
int omp_get_num_procs (void)
int omp_in_parallel (void)
void omp_set_dynamic(int num)
int omp_get_dynamic(void)
void omp_get_nested(void)
void omp_set_nested(int nested)

Библиотека функций OpenMP
void omp_init_lock(omp_lock_t *lock)
void omp_nest_init_lock(omp_nest_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_destroy_nest_lock(omp_nest_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_set_nest_lock(omp_nest_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
void omp_unset_nest_lock(omp_nest_lock_t *lock)
void omp_test_lock(omp_lock_t *lock)
void omp_test_nest_lock(omp_nest_lock_t *lock)
Библиотека функций OpenMP
void omp_init_lock(omp_lock_t *lock)
void omp_nest_init_lock(omp_nest_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_destroy_nest_lock(omp_nest_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_set_nest_lock(omp_nest_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
void omp_unset_nest_lock(omp_nest_lock_t *lock)
void omp_test_lock(omp_lock_t *lock)
void omp_test_nest_lock(omp_nest_lock_t *lock)

Переменные среды OpenMP
OMP_SCHEDULE
OMP_NUM_THREADS
OMP_DYNAMIC
OMP_NESTED
Переменные среды OpenMP
OMP_SCHEDULE
OMP_NUM_THREADS
OMP_DYNAMIC
OMP_NESTED
 Настройка и удаление Retail Demo
Настройка и удаление Retail Demo Системы счисления
Системы счисления ПРЕДСТАВЛЕНИЕ ЧИСЛОВОЙ ИНФОРМАЦИИВ КОМПЬЮТЕРЕ
ПРЕДСТАВЛЕНИЕ ЧИСЛОВОЙ ИНФОРМАЦИИВ КОМПЬЮТЕРЕ Поняття моделі. Типи моделей. Моделювання, як метод дослідження об'єктів
Поняття моделі. Типи моделей. Моделювання, як метод дослідження об'єктів Технология разработки дизайна тематических открыток в редакторе adobe photoshop
Технология разработки дизайна тематических открыток в редакторе adobe photoshop Процесс создания дизайнерского календаря Год зайца в программе CorelDraw
Процесс создания дизайнерского календаря Год зайца в программе CorelDraw Компьютерные объекты
Компьютерные объекты Фактчекинг и продвижение. Как работать с текстами в 2019 году
Фактчекинг и продвижение. Как работать с текстами в 2019 году Призначення, завдання, функції, класифікація ІОС
Призначення, завдання, функції, класифікація ІОС Управление информационными технологиями на предприятии
Управление информационными технологиями на предприятии Компьютерная графика (Autodesk 3ds max). Материалы. (Лекция 7)
Компьютерная графика (Autodesk 3ds max). Материалы. (Лекция 7) Centre Monitoring System PH-BC911 (Operation)
Centre Monitoring System PH-BC911 (Operation) Проектирование информационной системы Планирование организационно-технических мероприятий предприятия
Проектирование информационной системы Планирование организационно-технических мероприятий предприятия Исполнители вокруг нас
Исполнители вокруг нас Опасный контент и опасные персоны (9 класс)
Опасный контент и опасные персоны (9 класс) I-media. Управление репутацией в поисковых системах
I-media. Управление репутацией в поисковых системах Величина в информатике. Информационный объект
Величина в информатике. Информационный объект Информация о платформах дистанционного обучения
Информация о платформах дистанционного обучения Информатика. Что такое информатика
Информатика. Что такое информатика Интенсив-курс по React JS. Занятие 5. Redux
Интенсив-курс по React JS. Занятие 5. Redux The baseband bane
The baseband bane Парадигмы программирования 2024 ОАиП
Парадигмы программирования 2024 ОАиП Информационные процессы в живой природе
Информационные процессы в живой природе Создание Web-сайтов в программе Microsoft FrontPage
Создание Web-сайтов в программе Microsoft FrontPage Интерфейс Excel
Интерфейс Excel Как самостоятельно получить ключ доступа к информационному ресурсу, содержащему сведения ЕГРП
Как самостоятельно получить ключ доступа к информационному ресурсу, содержащему сведения ЕГРП IP-телефония и как она работает
IP-телефония и как она работает Решение олимпиадных задач по информатике
Решение олимпиадных задач по информатике