- Машнное обучение. Практический пример. Подготовка данных. Применение алгоритмов ML

Содержание
- 3. Загружаем данные Задача - определение кредитной платежеспособности. Пусть имеются данные о клиентах, обратившихся за кредитом. Здесь:
- 4. строки соответствуют объектам столбцы – признакам этих объектов. Объекты также называются наблюдениями или примерами (samples), а
- 5. Ответ Требуется по имеющейся таблице научиться по новому объекту, которого нет в таблице, но для которого
- 6. Если ответ количественный, то задача называется задачей восстановления регрессии. Если ответ категориальный, то задача называется задачей
- 7. Язык: python. Библиотеки: numpy, pandas и scikit-learn. numpy содержит реализации многомерных массивов и алгоритмов линейной алгебры.
- 8. Анализируем данные Данные загружены. Попытаемся вначале их качественно проанализировать. Узнаем размеры таблицы: (690, 16) data.shape 690
- 9. Для удобства зададим столбцам имена: data.columns = ['A' + (i) for i in (1, 16)] +
- 10. data.describe() Заметим, что количество элементов в столбцах A2, A14 меньше общего количества объектов (690), что говорит
- 11. Выделим числовые и категориальные признаки: categorical_columns = [c for c in data.columns if data[c].dtype.name == 'object']
- 12. Функция scatter_matrix из модуля pandas.tools.plotting позволяет построить для каждой количественной переменной гистограмму, а для каждой пары
- 13. Готовим данные Алгоритмы машинного обучения из библиотеки scikit-learn не работают напрямую с категориальными признаками и данными,
- 14. Количественные признаки Заполним, например, медианными значениями: data = data.fillna(data.median(axis=0), axis=0) Категориальные признаки Простая стратегия – заполнение
- 15. Векторизация Библиотека scikit-learn не умеет напрямую обрабатывать категориальные признаки. Поэтому прежде чем подавать данные на вход
- 16. Нормализация количественных признаков Многие алгоритмы машинного обучения чувствительны к масштабированию данных. К таким алгоритмам, например, относится
- 17. Обучающая и тестовая выборки Обучаться, или, как говорят, строить модель, мы будем на обучающей выборке, а
- 18. Алгоритмы машинного обучения Некоторые алгоритмы машинного обучения, реализованные в scikit-learn:
- 19. Основные методы классов, реализующих алгоритмы машинного обучения Все алгоритмы выполнены в виде классов, обладающих по крайней
- 20. kNN – метод ближайших соседей
- 21. kNN – метод ближайших соседей Начнем с одного из самых простых алгоритмов машинного обучения – метода
- 22. Для нас более важной является ошибка на тестовой выборке, так как мы должны уметь предсказывать правильное
- 23. Как видим, метод ближайших соседей на этой задаче дает не слишком удовлетворительные результаты. knn = KNeighborsClassifier(n_neighbors=best_n_neighbors)
- 24. SVC – машина опорных векторов
- 25. SVC – машина опорных векторов Следующий метод, который мы попробуем – машина опорных векторов (SVM –
- 26. Радиальное ядро Получили ошибку перекрестного контроля в 13.9%. Посмотрим, чему равна ошибка на тестовой выборке при
- 27. Random Forest – случайный лес
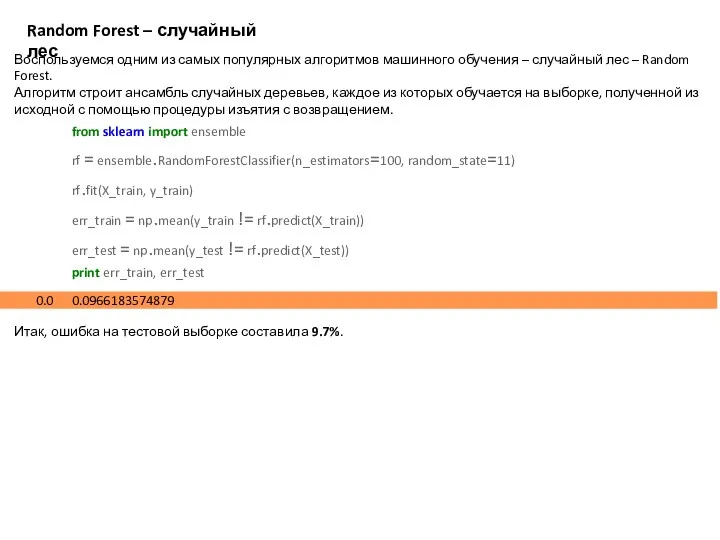
- 28. Random Forest – случайный лес Воспользуемся одним из самых популярных алгоритмов машинного обучения – случайный лес
- 29. Отбор признаков (Feature Selection) с помощью алгоритма случайного леса Одной из важных процедур предобработки данных в
- 30. importances = rf.feature_importances_ indices = np.argsort(importances)[::-1] print("Feature importances:") for f, idx in enumerate(indices): print("{:2d}. feature '{:5s}'
- 31. GBT – градиентный бустинг деревьев решений
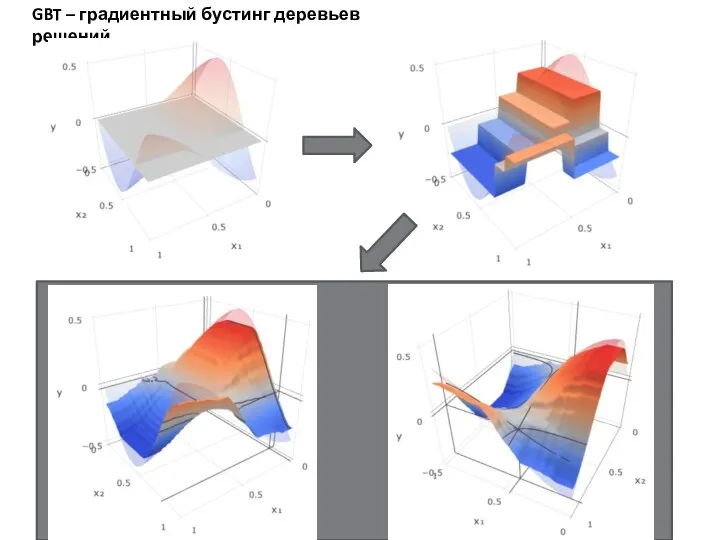
- 32. GBT – градиентный бустинг деревьев решений GBT – еще один метод, строящий ансамбль деревьев решений. На
- 34. Скачать презентацию


Загружаем данные
Задача - определение кредитной платежеспособности.
Пусть имеются данные о клиентах, обратившихся
Загружаем данные
Задача - определение кредитной платежеспособности.
Пусть имеются данные о клиентах, обратившихся
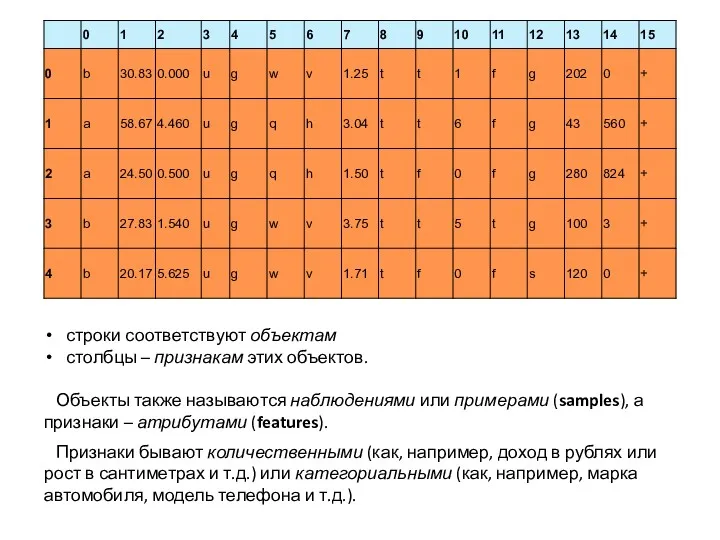
строки соответствуют объектам
столбцы – признакам этих объектов.
Объекты также называются наблюдениями или примерами (samples), а признаки – атрибутами (features).
строки соответствуют объектам
столбцы – признакам этих объектов.
Объекты также называются наблюдениями или примерами (samples), а признаки – атрибутами (features).
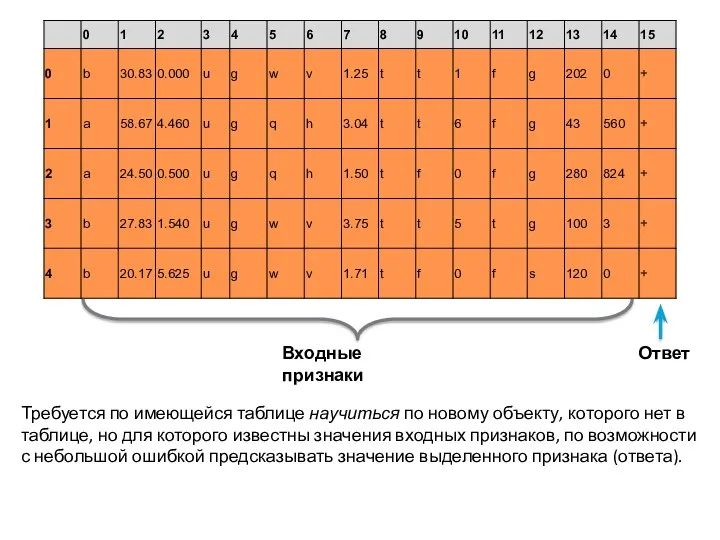
Ответ
Требуется по имеющейся таблице научиться по новому объекту, которого нет в таблице, но
Ответ
Требуется по имеющейся таблице научиться по новому объекту, которого нет в таблице, но
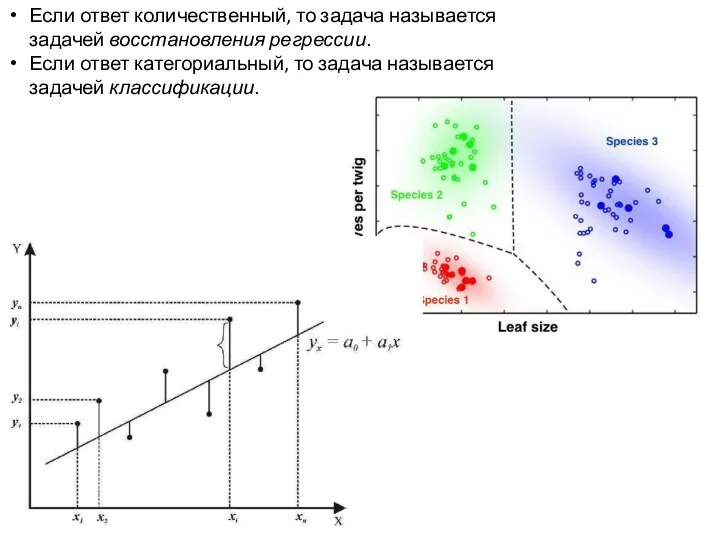
Если ответ количественный, то задача называется задачей восстановления регрессии.
Если ответ категориальный, то
Если ответ количественный, то задача называется задачей восстановления регрессии.
Если ответ категориальный, то

Язык: python.
Библиотеки: numpy, pandas и scikit-learn.
numpy содержит реализации многомерных массивов и алгоритмов линейной алгебры.
Язык: python.
Библиотеки: numpy, pandas и scikit-learn.
numpy содержит реализации многомерных массивов и алгоритмов линейной алгебры.
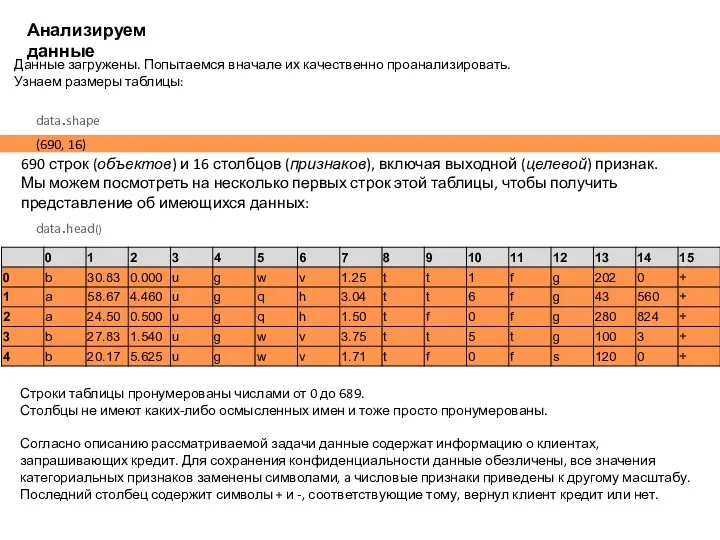
Анализируем данные
Данные загружены. Попытаемся вначале их качественно проанализировать.
Узнаем размеры таблицы:
(690, 16)
Анализируем данные
Данные загружены. Попытаемся вначале их качественно проанализировать.
Узнаем размеры таблицы:
(690, 16)
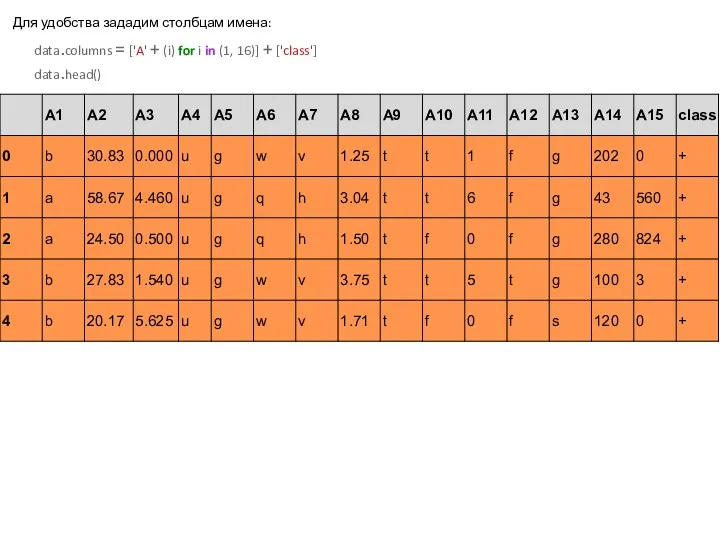
Для удобства зададим столбцам имена:
data.columns = ['A' + (i) for i
Для удобства зададим столбцам имена:
data.columns = ['A' + (i) for i
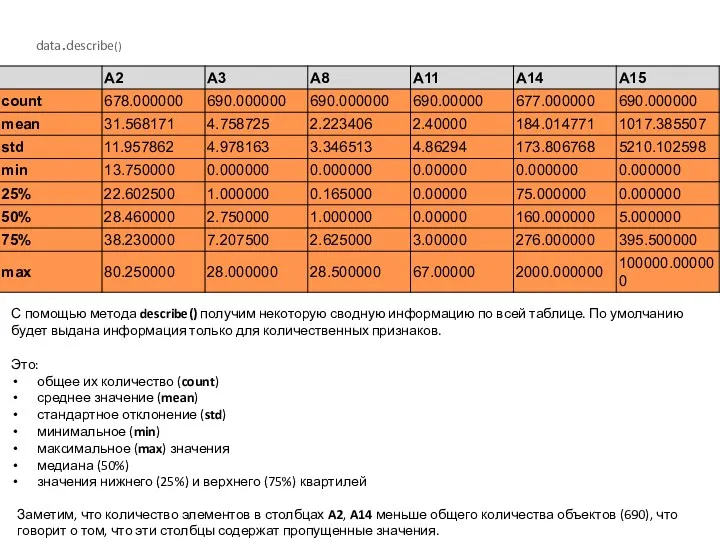
data.describe()
Заметим, что количество элементов в столбцах A2, A14 меньше общего количества объектов (690),
data.describe()
Заметим, что количество элементов в столбцах A2, A14 меньше общего количества объектов (690),
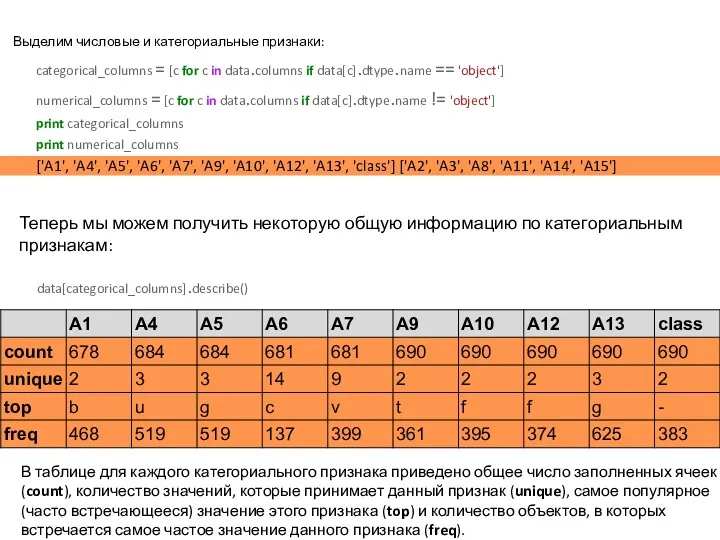
Выделим числовые и категориальные признаки:
categorical_columns = [c for c in data.columns
Выделим числовые и категориальные признаки:
categorical_columns = [c for c in data.columns
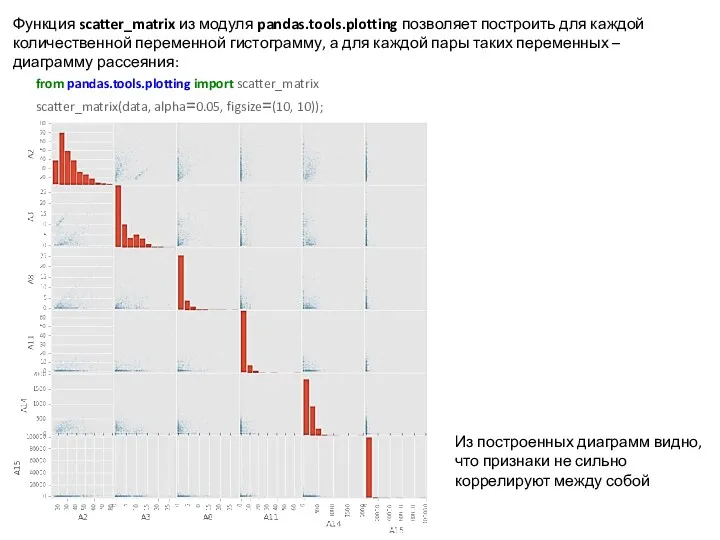
Функция scatter_matrix из модуля pandas.tools.plotting позволяет построить для каждой количественной переменной гистограмму, а для каждой
Функция scatter_matrix из модуля pandas.tools.plotting позволяет построить для каждой количественной переменной гистограмму, а для каждой

Готовим данные
Алгоритмы машинного обучения из библиотеки scikit-learn не работают напрямую с
Готовим данные
Алгоритмы машинного обучения из библиотеки scikit-learn не работают напрямую с
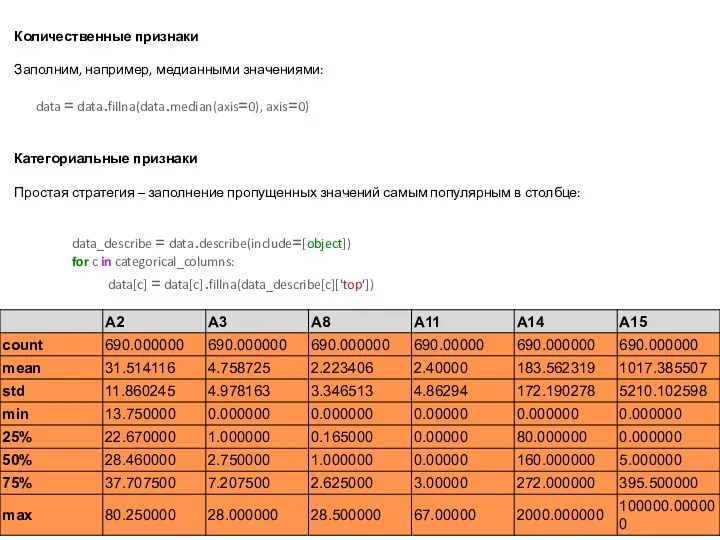
Количественные признаки
Заполним, например, медианными значениями:
data = data.fillna(data.median(axis=0), axis=0)
Категориальные признаки
Простая стратегия –
Количественные признаки
Заполним, например, медианными значениями:
data = data.fillna(data.median(axis=0), axis=0)
Категориальные признаки
Простая стратегия –

Векторизация
Библиотека scikit-learn не умеет напрямую обрабатывать категориальные признаки.
Поэтому прежде чем
Векторизация
Библиотека scikit-learn не умеет напрямую обрабатывать категориальные признаки.
Поэтому прежде чем
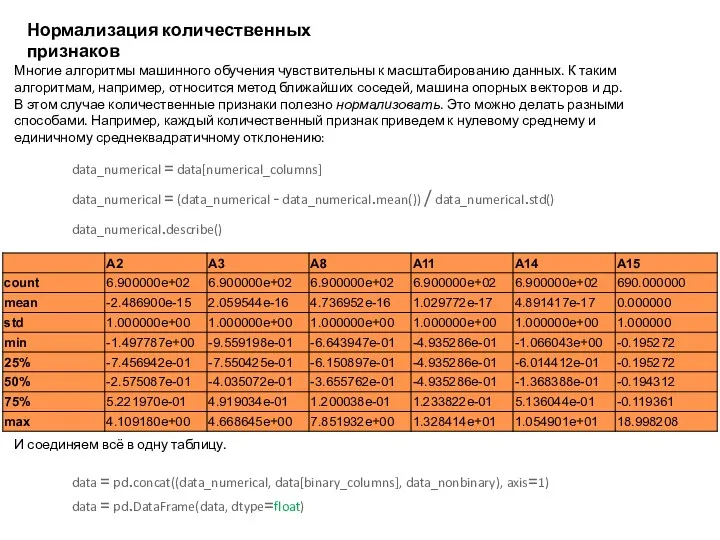
Нормализация количественных признаков
Многие алгоритмы машинного обучения чувствительны к масштабированию данных. К
Нормализация количественных признаков
Многие алгоритмы машинного обучения чувствительны к масштабированию данных. К

Обучающая и тестовая выборки
Обучаться, или, как говорят, строить модель, мы будем на обучающей
Обучающая и тестовая выборки
Обучаться, или, как говорят, строить модель, мы будем на обучающей
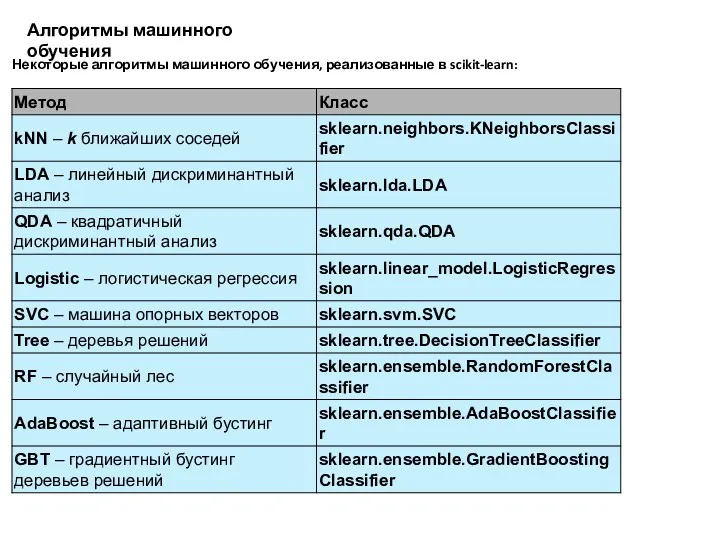
Алгоритмы машинного обучения
Некоторые алгоритмы машинного обучения, реализованные в scikit-learn:
Алгоритмы машинного обучения
Некоторые алгоритмы машинного обучения, реализованные в scikit-learn:
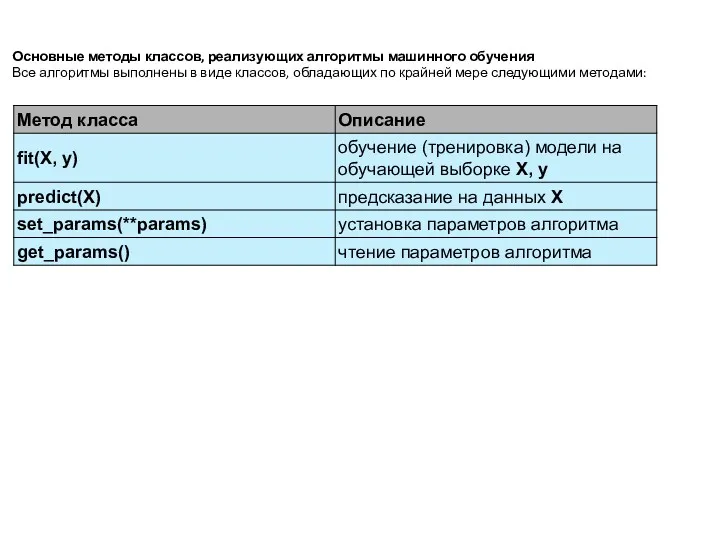
Основные методы классов, реализующих алгоритмы машинного обучения
Все алгоритмы выполнены в виде
Основные методы классов, реализующих алгоритмы машинного обучения
Все алгоритмы выполнены в виде
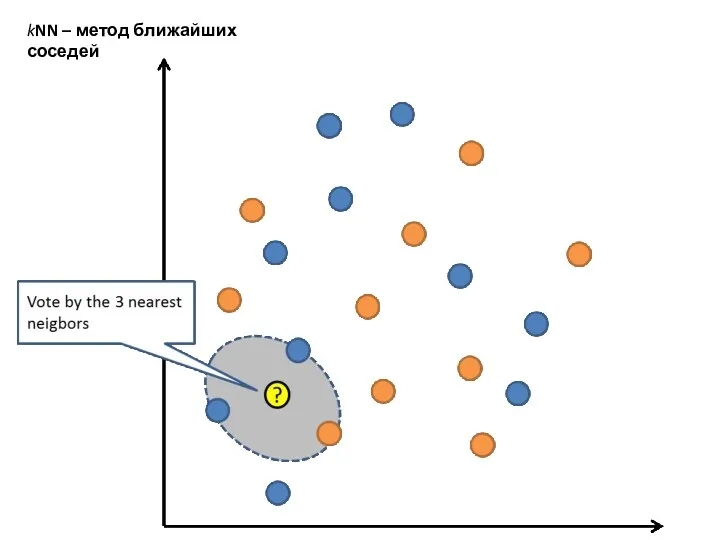
kNN – метод ближайших соседей
kNN – метод ближайших соседей
kNN – метод ближайших соседей
Начнем с одного из самых простых алгоритмов
kNN – метод ближайших соседей
Начнем с одного из самых простых алгоритмов

Для нас более важной является ошибка на тестовой выборке, так как
Для нас более важной является ошибка на тестовой выборке, так как

Как видим, метод ближайших соседей на этой задаче дает не слишком
Как видим, метод ближайших соседей на этой задаче дает не слишком
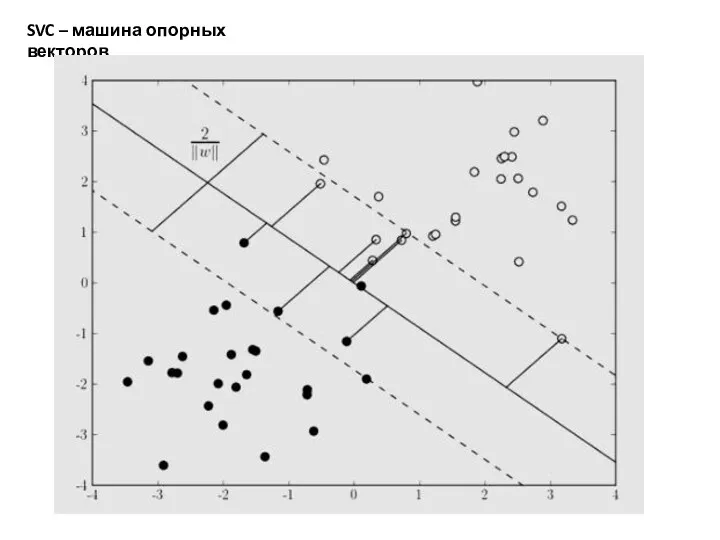
SVC – машина опорных векторов
SVC – машина опорных векторов

SVC – машина опорных векторов
Следующий метод, который мы попробуем – машина опорных
SVC – машина опорных векторов
Следующий метод, который мы попробуем – машина опорных

Радиальное ядро
Получили ошибку перекрестного контроля в 13.9%.
Посмотрим, чему равна ошибка на
Радиальное ядро
Получили ошибку перекрестного контроля в 13.9%.
Посмотрим, чему равна ошибка на
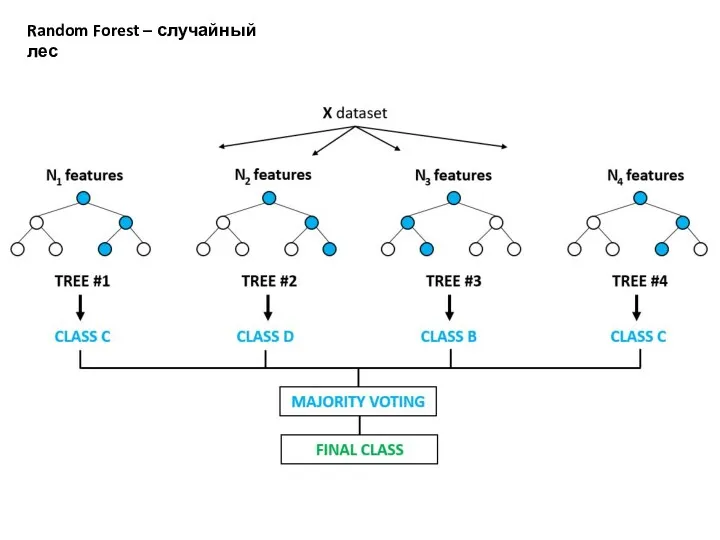
Random Forest – случайный лес
Random Forest – случайный лес
Random Forest – случайный лес
Воспользуемся одним из самых популярных алгоритмов машинного
Random Forest – случайный лес
Воспользуемся одним из самых популярных алгоритмов машинного

Отбор признаков (Feature Selection) с помощью алгоритма случайного леса
Одной из важных
Отбор признаков (Feature Selection) с помощью алгоритма случайного леса
Одной из важных
![importances = rf.feature_importances_ indices = np.argsort(importances)[::-1] print("Feature importances:") for f,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/279128/slide-29.jpg)
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature importances:")
for f, idx
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature importances:")
for f, idx
GBT – градиентный бустинг деревьев решений
GBT – градиентный бустинг деревьев решений

GBT – градиентный бустинг деревьев решений
GBT – еще один метод, строящий ансамбль
GBT – градиентный бустинг деревьев решений
GBT – еще один метод, строящий ансамбль
 Для чего нужны СМИ
Для чего нужны СМИ Подсистема прерываний. Лабораторная работа №3
Подсистема прерываний. Лабораторная работа №3 Module 3. Mass media. Case study. Problem 6
Module 3. Mass media. Case study. Problem 6 Оценка информационных рисков при использовании облачных сервисов
Оценка информационных рисков при использовании облачных сервисов Нормоконтроль. Стандарт организации
Нормоконтроль. Стандарт организации Основы логики
Основы логики Технология мультимедиа
Технология мультимедиа Знакомство с рабочим местом webquik
Знакомство с рабочим местом webquik Установка Honda Application center
Установка Honda Application center Программирование на языке Си
Программирование на языке Си Пошаговая инструкция получения сертификата персонифицированного финансирования дополнительного образования
Пошаговая инструкция получения сертификата персонифицированного финансирования дополнительного образования Программное обеспечение ГИС. Лекция 18
Программное обеспечение ГИС. Лекция 18 Информационные жанры
Информационные жанры Извлечение данных из таблиц. Семинар 2
Извлечение данных из таблиц. Семинар 2 Информационные технологии в работе ДОУ
Информационные технологии в работе ДОУ Разработка предложений по созданию системы защиты ПДн в медицинской лаборатории ИНВИТРО
Разработка предложений по созданию системы защиты ПДн в медицинской лаборатории ИНВИТРО Microsoft Word 2010. Интерфейс
Microsoft Word 2010. Интерфейс Электронный документ и электронная подпись
Электронный документ и электронная подпись Презентация Циклы
Презентация Циклы Inżynieria oprogramowania
Inżynieria oprogramowania Финальное собрание осеннего IT-клуба
Финальное собрание осеннего IT-клуба Технологии локальных вычислительных сетей (ЛВС)
Технологии локальных вычислительных сетей (ЛВС) Арифметические и логические основы вычислительной техники
Арифметические и логические основы вычислительной техники Применение аддитивных технологий
Применение аддитивных технологий Создание файла для создания новой детали
Создание файла для создания новой детали Искусственный интеллект. Методы исследования
Искусственный интеллект. Методы исследования Типизация документов по сфере создания и преимущественного использования
Типизация документов по сфере создания и преимущественного использования Сетевые педагогические сообщества
Сетевые педагогические сообщества