- Масштабируемая веб-архитектура и распределенные системы

Содержание
- 2. Схема распределенных вычислений Распределенная система - система, в которой обработка информации сосредоточена не на одной вычислительной
- 3. Выделяется три типа архитектур распределенных систем. Архитектура клиент/сервер. В этой модели систему можно представить как набор
- 4. Недостатки распределенных систем Сложность. Намного труднее понять и оценить свойства распределенных систем в целом, их сложнее
- 5. Принципы построения распределенных веб-систем Доступность: длительность работоспособного состояния веб-сайта критически важна по отношению к репутации и
- 6. Масштабируемость: Когда дело доходит до любой крупной распределенной системы, размер оказывается всего лишь одним пунктом из
- 7. Архитектура распределенных приложений В разных источниках приводятся различные варианты построения распределенных приложений. И все они имеют
- 8. Основные уровни трехзвенной архитектуры распределенного приложения
- 9. Нередко такую архитектуру называют трехуровневой или трехзвенной. И очень часто на основе этих "трех китов" создается
- 10. Четырехуровневая распределенная архитектура · представление данных (пользовательский уровень); · правила бизнес-логики (уровень обработки данных); · управление
- 11. EJB (Java Beans) Технологию EJB (Enterprise Java Beans) можно рассматривать с двух точек зрения: как фреймворк,
- 12. Основные архитектуры EJB Существует 2 основные архитектуры при разработке enterprise-приложений: традиционная слоистая архитектура (traditional layered architecture)
- 13. Архитектура DDD предполагает, что объекты обладают бизнесс-логикой, а не являются простой репликацией объектов БД. Многие программисты
- 14. Session bean представляет собой EJB-компоненту, связанную с одним клиентом. ``Бины'' этого типа, как правило, имеют ограниченный
- 15. Entity bean, наоборот, представляет собой компоненту, работающую с постоянной (persistent) информацией, хранящейся, например, в базе данных.
- 16. Entities и Java Persistence API Одним из главным достоинством EJB3 стал новый механизм работы с persistence
- 17. Реализация Hассмотрим реализацию этих сущностей. В EJB3 мы используем POJO (Plain Old Java Objects), POJI (Plain
- 18. Перехватчики При создании enterprise-приложений часто возникает необходимость записывать лог вызываемых методов (в целях отладки или для
- 19. Использовать перехватчики можно двумя путями: указать его применение через аннтоации для каждого класса или метода в
- 20. DCOM Distributed Component Object Model (DCOM) - программная архитектура, разработанная компанией Microsoft для распределения приложений между
- 21. Достоинства и недостатки DCOM DCOM является лишь частным решением проблемы распределенных объектных систем. Он хорошо подходит
- 22. CORBA CORBA специфицирует инфраструктуру взаимодействия компонент (объектов) на представительском уровне и уровне приложений модели OSI. Она
- 23. Достоинства и недостатки CORBA Достоинства Платформенная независимость Языковая независимость Динамические вызовы Динамическое обнаружение объектов Масштабируемость CORBA-сервисы
- 24. ORM Object-relational mapping (рус. Объектно-реляционное отображение) — это технология программирования, которая позволяет преобразовывать несовместимые типы моделей
- 25. Принцип работы ORM Ключевой особенностью ORM является отображение, которое используется для привязки объекта к его данным
- 27. Скачать презентацию
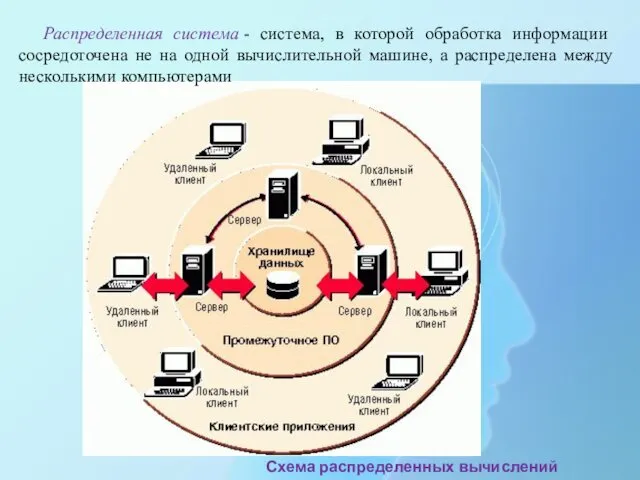
Схема распределенных вычислений
Распределенная система - система, в которой обработка информации сосредоточена не
Схема распределенных вычислений
Распределенная система - система, в которой обработка информации сосредоточена не

Выделяется три типа архитектур распределенных систем.
Архитектура клиент/сервер. В этой модели систему
Выделяется три типа архитектур распределенных систем.
Архитектура клиент/сервер. В этой модели систему

Недостатки распределенных систем
Сложность. Намного труднее понять и оценить свойства распределенных систем
Недостатки распределенных систем
Сложность. Намного труднее понять и оценить свойства распределенных систем

Принципы построения распределенных веб-систем
Доступность: длительность работоспособного состояния веб-сайта критически важна по
Принципы построения распределенных веб-систем
Доступность: длительность работоспособного состояния веб-сайта критически важна по

Масштабируемость: Когда дело доходит до любой крупной распределенной системы, размер оказывается
Масштабируемость: Когда дело доходит до любой крупной распределенной системы, размер оказывается

Архитектура распределенных приложений
В разных источниках приводятся различные варианты построения распределенных приложений.
Архитектура распределенных приложений
В разных источниках приводятся различные варианты построения распределенных приложений.
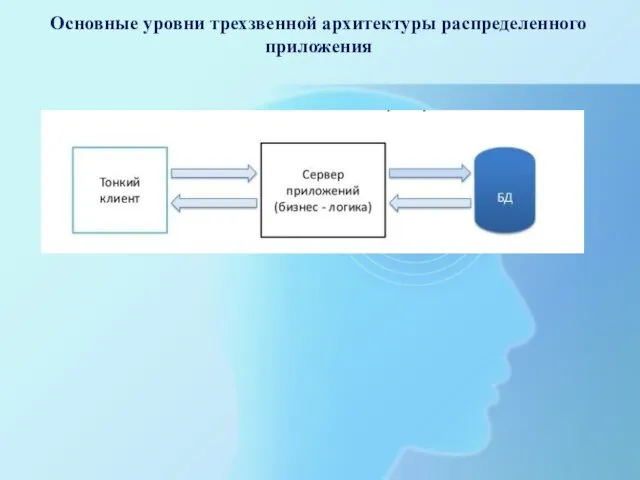
Основные уровни трехзвенной архитектуры распределенного приложения
Основные уровни трехзвенной архитектуры распределенного приложения
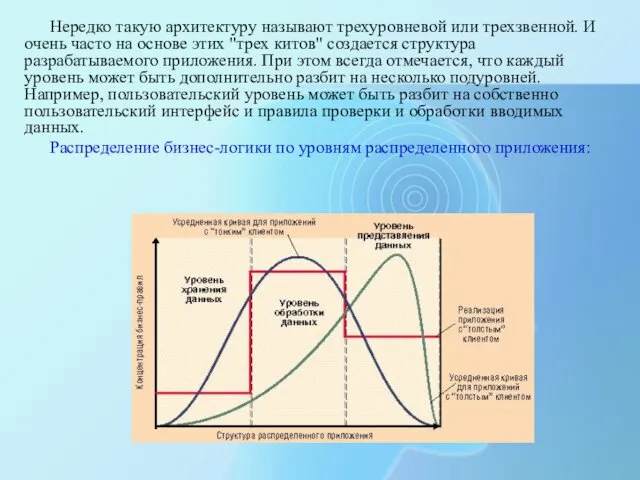
Нередко такую архитектуру называют трехуровневой или трехзвенной. И очень часто на
Нередко такую архитектуру называют трехуровневой или трехзвенной. И очень часто на
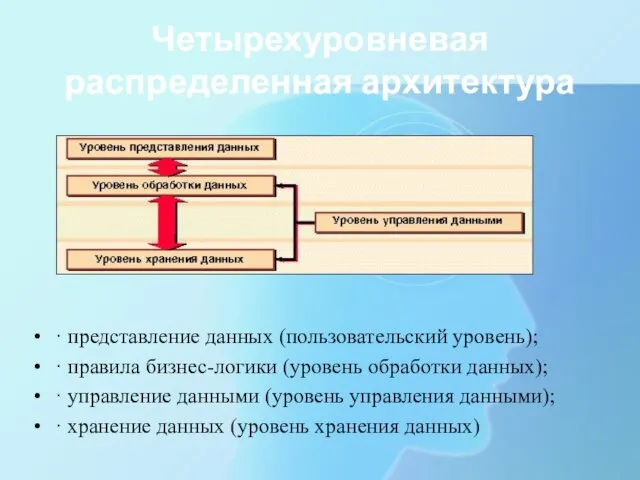
Четырехуровневая распределенная архитектура
· представление данных (пользовательский уровень);
· правила бизнес-логики (уровень обработки
Четырехуровневая распределенная архитектура
· представление данных (пользовательский уровень);
· правила бизнес-логики (уровень обработки

EJB (Java Beans)
Технологию EJB (Enterprise Java Beans) можно рассматривать с двух
EJB (Java Beans)
Технологию EJB (Enterprise Java Beans) можно рассматривать с двух

Основные архитектуры EJB
Существует 2 основные архитектуры при разработке enterprise-приложений:
традиционная слоистая архитектура
Основные архитектуры EJB
Существует 2 основные архитектуры при разработке enterprise-приложений:
традиционная слоистая архитектура

Архитектура DDD предполагает, что объекты обладают бизнесс-логикой, а не являются простой
Архитектура DDD предполагает, что объекты обладают бизнесс-логикой, а не являются простой

Session bean представляет собой EJB-компоненту, связанную с одним клиентом. ``Бины'' этого типа, как
Session bean представляет собой EJB-компоненту, связанную с одним клиентом. ``Бины'' этого типа, как

Entity bean, наоборот, представляет собой компоненту, работающую с постоянной (persistent) информацией, хранящейся,
Entity bean, наоборот, представляет собой компоненту, работающую с постоянной (persistent) информацией, хранящейся,

Entities и Java Persistence API
Одним из главным достоинством EJB3 стал новый
Entities и Java Persistence API
Одним из главным достоинством EJB3 стал новый

Реализация
Hассмотрим реализацию этих сущностей. В EJB3 мы используем POJO (Plain
Реализация Hассмотрим реализацию этих сущностей. В EJB3 мы используем POJO (Plain

Перехватчики
При создании enterprise-приложений часто возникает необходимость записывать лог вызываемых методов (в
Перехватчики
При создании enterprise-приложений часто возникает необходимость записывать лог вызываемых методов (в

Использовать перехватчики можно двумя путями: указать его применение через аннтоации для
Использовать перехватчики можно двумя путями: указать его применение через аннтоации для

DCOM
Distributed Component Object Model (DCOM) - программная архитектура, разработанная компанией Microsoft для распределения приложений между несколькими компьютерами
DCOM
Distributed Component Object Model (DCOM) - программная архитектура, разработанная компанией Microsoft для распределения приложений между несколькими компьютерами

Достоинства и недостатки DCOM
DCOM является лишь частным решением проблемы распределенных объектных
Достоинства и недостатки DCOM
DCOM является лишь частным решением проблемы распределенных объектных

CORBA
CORBA специфицирует инфраструктуру взаимодействия компонент (объектов) на представительском уровне и уровне
CORBA
CORBA специфицирует инфраструктуру взаимодействия компонент (объектов) на представительском уровне и уровне

Достоинства и недостатки CORBA
Достоинства
Платформенная независимость
Языковая независимость
Динамические вызовы
Динамическое обнаружение объектов
Масштабируемость
CORBA-сервисы
Широкая индустриальная поддержка
Недостатки
Нет
Достоинства и недостатки CORBA
Достоинства
Платформенная независимость
Языковая независимость
Динамические вызовы
Динамическое обнаружение объектов
Масштабируемость
CORBA-сервисы
Широкая индустриальная поддержка
Недостатки
Нет

ORM
Object-relational mapping (рус. Объектно-реляционное отображение) — это технология программирования, которая позволяет
ORM
Object-relational mapping (рус. Объектно-реляционное отображение) — это технология программирования, которая позволяет

Принцип работы ORM
Ключевой особенностью ORM является отображение, которое используется для привязки
Принцип работы ORM
Ключевой особенностью ORM является отображение, которое используется для привязки
 Самозахист авторського права в мережі Інтернет
Самозахист авторського права в мережі Інтернет НЕТ Этикет
НЕТ Этикет Классификация ИТ. Структура АИТ
Классификация ИТ. Структура АИТ Архитектура вычислительных систем и сетей
Архитектура вычислительных систем и сетей Astra Linux А́стра Ли́нукс — операционная система специального назначения
Astra Linux А́стра Ли́нукс — операционная система специального назначения Ms word редакторы туралы негізгі мағлұматтар
Ms word редакторы туралы негізгі мағлұматтар Новые элементы HyperText Markup Language
Новые элементы HyperText Markup Language Презентация к уроку информатики на тему: Правила поведения в компьютерном классе.
Презентация к уроку информатики на тему: Правила поведения в компьютерном классе. Объявление и вызов методов в C#
Объявление и вызов методов в C# Алгоритмическая структура Цикл. Решение задач со счетчиком. 9 класс
Алгоритмическая структура Цикл. Решение задач со счетчиком. 9 класс Introduction to computer systems. Architectures of computer systems
Introduction to computer systems. Architectures of computer systems The term computer programmer
The term computer programmer Расчет и проектировка СКС в программах Netplanner и Microsoft Office visio
Расчет и проектировка СКС в программах Netplanner и Microsoft Office visio Исполнитель чертёжник
Исполнитель чертёжник Linux Commands
Linux Commands Базы данных. Программирование баз данных
Базы данных. Программирование баз данных Информационно-поисковые системы
Информационно-поисковые системы Компьютерный сленг
Компьютерный сленг Проектная деятельность на уроках информатики
Проектная деятельность на уроках информатики Информация. Понятие информации
Информация. Понятие информации Проектирование АСУ. Комплекс подсистем технической подготовки производства
Проектирование АСУ. Комплекс подсистем технической подготовки производства Строковый тип данных Операции со строками и стандартные функции
Строковый тип данных Операции со строками и стандартные функции Учебник по Pawn программированию
Учебник по Pawn программированию Разработка открытого урока по информатике Текстовый редактор MicrosoftWord
Разработка открытого урока по информатике Текстовый редактор MicrosoftWord Сеть и облачные технологии
Сеть и облачные технологии Делегаты и события в C#. Введение в язык XAML
Делегаты и события в C#. Введение в язык XAML Личный помощник. Ввод
Личный помощник. Ввод Презентация Создание простых текстовых документов
Презентация Создание простых текстовых документов