- Методы и средства хранения информации

Содержание
- 2. Структура курса Лекции – 18 часов Лабораторные занятия – 18 часов Самостоятельная работа студента – 90
- 3. Структура лекционного материала СТРУКТУРЫ ДАННЫХ ДЛЯ ХРАНЕНИЯ И ПОИСКА МЕТОДЫ ОРГАНИЗАЦИИ ХРАНЕНИЯ ДАННЫХ В СУБД РОЛЬ
- 4. Содержание лабораторного практикума
- 5. Литература
- 6. Для работы со списком обязательно хранится указатель на первый элемент(голову) списка. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ.
- 7. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Основным отличием списка от массива
- 8. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. При удалении некоторого элемента списка
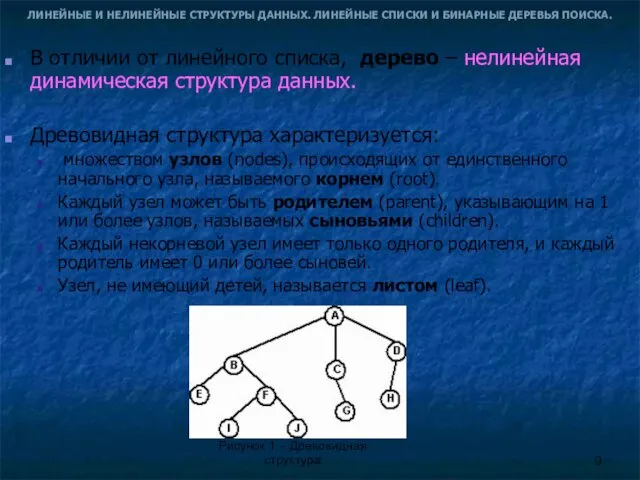
- 9. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. В отличии от линейного списка,
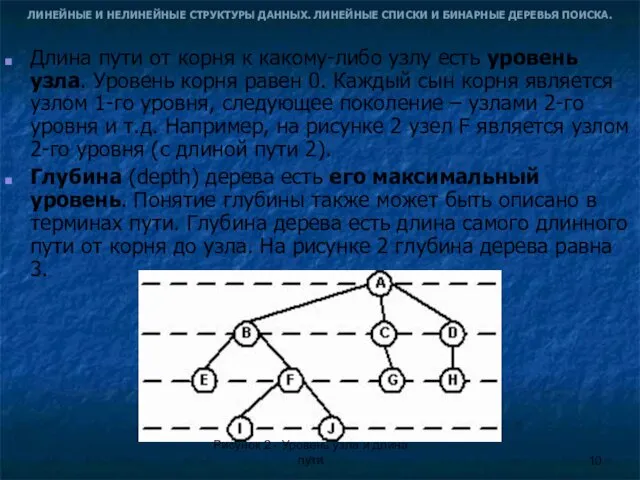
- 10. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Длина пути от корня к
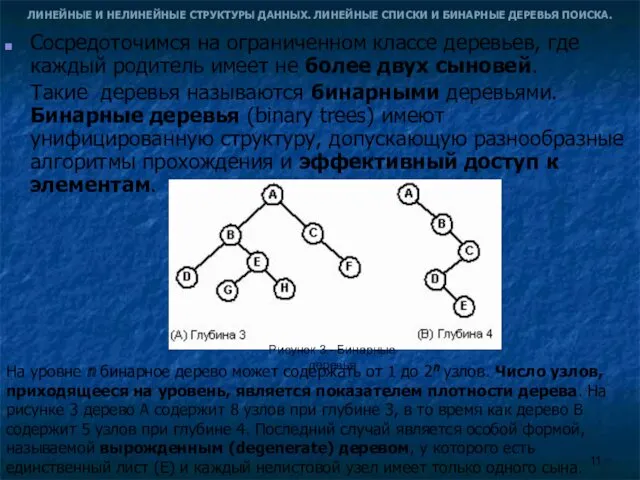
- 11. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Cосредоточимся на ограниченном классе деревьев,
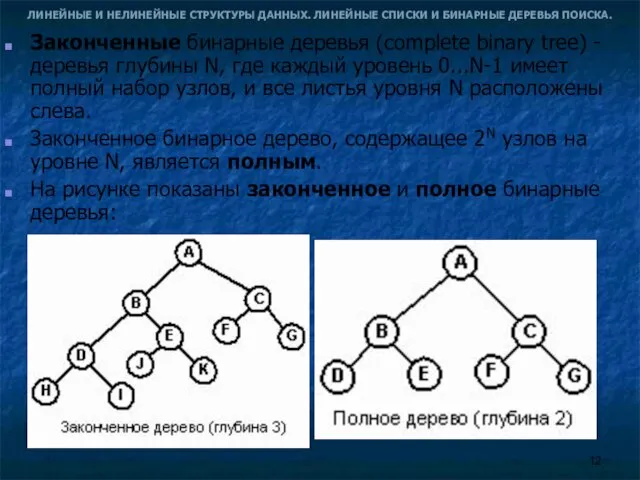
- 12. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Законченные бинарные деревья (complete binary
- 13. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Законченные и полные бинарные деревья
- 14. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Очевидно, что бинарное дерево поиска
- 15. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА. Как известно, при удалении узла
- 16. Сбалансированные деревья. AVL-деревья. Как известно, при некотором стечении обстоятельств бинарное дерево поиска может оказаться вырожденным. Тогда
- 17. Сбалансированные деревья. AVL-деревья. В общем случае высота сбалансированного дерева не превышает log2N. Таким образом, AVL-дерево является
- 18. Сбалансированные деревья. AVL-деревья. Если показатель сбалансированности отрицателен, то узел «перевешивает влево», так как высота левого поддерева
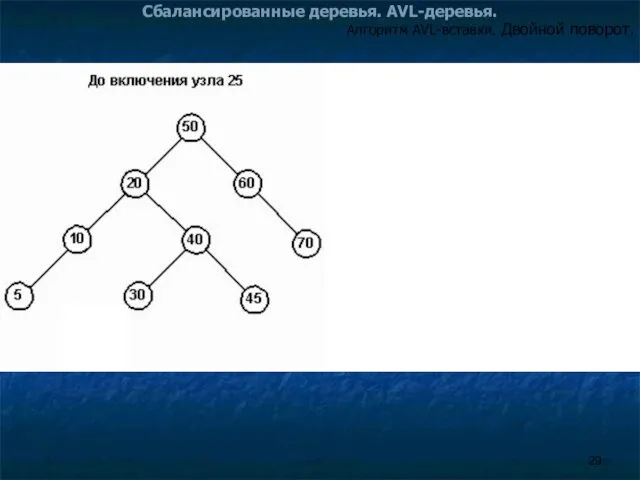
- 19. Сбалансированные деревья. AVL-деревья. Процесс поиска места для вставки нового узла в AVL-дерево такой же, как и
- 20. Сбалансированные деревья. AVL-деревья. Есть три возможных ситуации. В двух первых случаях узел сохраняет сбалансированность, и реорганизация
- 21. Сбалансированные деревья. AVL-деревья. Случай 1. Узел на поисковом маршруте изначально является сбалансированным (показатель сбалансированности равен 0).
- 22. Сбалансированные деревья. AVL-деревья. Случай 2. Одно из поддеревьев узла перевешивает, и новый узел вставляется в более
- 23. Сбалансированные деревья. AVL-деревья. Случай 3. Одно из поддеревьев узла перевешивает, и новый узел помещается в более
- 24. Сбалансированные деревья. AVL-деревья. В процессе одинарного поворота: LC замещает своего родителя, который становится правым сыном. Бывшее
- 25. Сбалансированные деревья. AVL-деревья. Алгоритм AVL-вставки
- 26. Сбалансированные деревья. AVL-деревья. Алгоритм AVL-вставки. Одинарный поворот. template void AVLTree ::SingleRotateRight (AVLTreeNode * &p) { AVLTreeNode
- 27. Сбалансированные деревья. AVL-деревья. Двойной поворот вправо (double right rotation) нужен тогда, когда родительский узел (P) становится
- 28. Сбалансированные деревья. AVL-деревья. Алгоритм AVL-вставки. Двойной поворот.
- 29. Сбалансированные деревья. AVL-деревья. Алгоритм AVL-вставки. Двойной поворот.
- 30. Сбалансированные деревья. AVL-деревья. Оценка сбалансированных деревьев AVL-деревья требуют дополнительных затрат на поддержание сбалансированности при вставке или
- 31. Доступ к данным во внешней памяти. B-деревья. До сих пор задача поиска решалась в предположении, что
- 32. Доступ к данным во внешней памяти. B-деревья. В 1970 году Р. Байер и Маккрейт предложили структуру
- 33. Доступ к данным во внешней памяти. B-деревья. Каждая страница имеет не более 2n элементов Каждая страница,
- 34. Доступ к данным во внешней памяти. B-деревья. Элементы на страницах B-деревьев располагаются в возрастающем порядке. Если
- 35. Доступ к данным во внешней памяти. B-деревья. Пусть задан некоторый аргумент поиска х и страница имеет
- 36. Доступ к данным во внешней памяти. B-деревья. Включение в B-дерево проводится только в листовые страницы. При
- 37. Доступ к данным во внешней памяти. B-деревья. Включение элемента в B-дерево 1. Обнаруживается, что ключ 23
- 38. Доступ к данным во внешней памяти. B-деревья. Включение элемента в B-дерево Процесс добавления элементов в Б-дерево
- 39. Доступ к данным во внешней памяти. B-деревья. При исключении элемента из B-дерева можно выделить два случая:
- 40. Доступ к данным во внешней памяти. B-деревья. В том случае, если занять элемент на соседних страницах
- 41. Доступ к данным во внешней памяти. B-деревья. Исключение элемента из B-дерева Рассмотрим деградацию Б-дерева в случае
- 42. Программная реализация B-дерева. //задаем порядок дерева #define LEVEL 3 //количество элементов на странице #define ITEM_ON_LEVEL 2*LEVEL
- 43. Программная реализация B-дерева. template class CBTreePage { public: //массив элементов на странице DATA m_arkeys[ITEM_ON_LEVEL]; //массив смещений
- 44. Программная реализация B-дерева. template class CBTree { private: //смещение корневой страницы int m_iroot; //максимальное смещение занимаемое
- 45. Хеширование данных. Хеш-таблицы. Для ускорения доступа к данным в таблицах баз данных можно использовать предварительное упорядочивание
- 46. Хеширование данных Идеальной хеш-функцией является такая хеш-функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса:
- 47. Хеширование данных В большинстве приложений ключ обеспечивает косвенную ссылку на данные. Ключ отображается во множество целых
- 48. Хеширование данных Очевидно, что при заполнении хеш-таблицы могут возникать ситуации, когда для двух неодинаковых ключей функция
- 49. Хеширование данных Коллизии и методы разрешения коллизий
- 50. Хеширование данных Коллизии и методы разрешения коллизий Поиск в хеш-таблице с цепочками переполнения: вычисляется адрес по
- 51. Хеширование данных Коллизии и методы разрешения коллизий Методы открытой адресации состоят в том, чтобы, пользуясь каким-либо
- 52. Хеширование данных Коллизии и методы разрешения коллизий Квадратичное опробование отличается от линейного тем, что шаг перебора
- 53. Хеширование данных Коллизии и методы разрешения коллизий Еще одна разновидность метода открытой адресации, которая называется двойным
- 54. Хеширование данных Коллизии и методы разрешения коллизий Алгоритмы вставки и поиска для метода линейного опробования: Вставка:
- 55. Хеширование данных Коллизии и методы разрешения коллизий С процедурой удаления дело обстоит не так просто, так
- 56. Хеширование данных Коллизии и методы разрешения коллизий Сформулируем алгоритмы вставки, поиска и удаления для хеш-таблицы, имеющей
- 57. Хеширование данных Переполнение таблицы и рехеширование
- 59. Скачать презентацию

Структура курса
Лекции – 18 часов
Лабораторные занятия – 18 часов
Самостоятельная работа студента
Структура курса
Лекции – 18 часов
Лабораторные занятия – 18 часов
Самостоятельная работа студента

Структура лекционного материала
СТРУКТУРЫ ДАННЫХ ДЛЯ ХРАНЕНИЯ И ПОИСКА
МЕТОДЫ ОРГАНИЗАЦИИ ХРАНЕНИЯ ДАННЫХ
Структура лекционного материала
СТРУКТУРЫ ДАННЫХ ДЛЯ ХРАНЕНИЯ И ПОИСКА
МЕТОДЫ ОРГАНИЗАЦИИ ХРАНЕНИЯ ДАННЫХ

Содержание лабораторного практикума
Содержание лабораторного практикума

Литература
Литература

Для работы со списком обязательно хранится указатель на первый элемент(голову) списка.
Для работы со списком обязательно хранится указатель на первый элемент(голову) списка.

ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.

ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.

ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.

ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.

ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ СТРУКТУРЫ ДАННЫХ. ЛИНЕЙНЫЕ СПИСКИ И БИНАРНЫЕ ДЕРЕВЬЯ ПОИСКА.
Сбалансированные деревья. AVL-деревья.
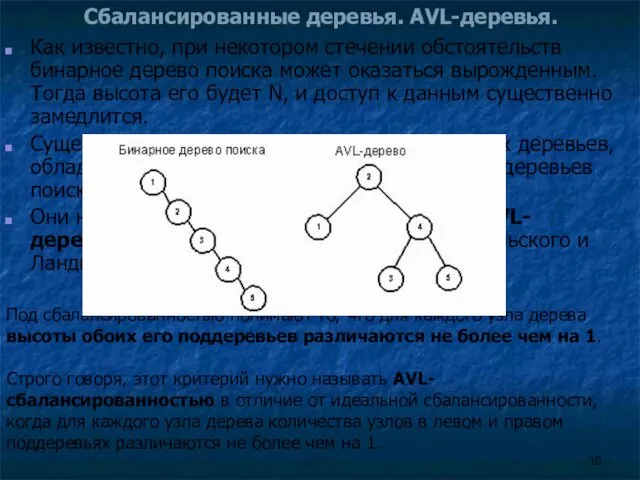
Как известно, при некотором стечении обстоятельств бинарное дерево
Сбалансированные деревья. AVL-деревья.
Как известно, при некотором стечении обстоятельств бинарное дерево

Сбалансированные деревья. AVL-деревья.
В общем случае высота сбалансированного дерева не превышает
Сбалансированные деревья. AVL-деревья.
В общем случае высота сбалансированного дерева не превышает
Сбалансированные деревья. AVL-деревья.
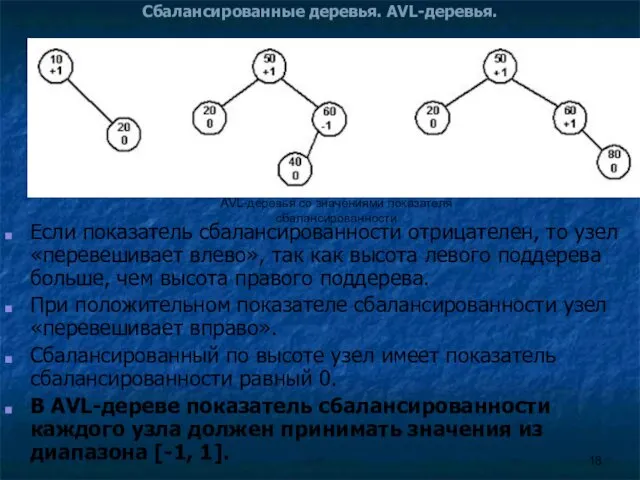
Если показатель сбалансированности отрицателен, то узел «перевешивает влево»,
Сбалансированные деревья. AVL-деревья.
Если показатель сбалансированности отрицателен, то узел «перевешивает влево»,

Сбалансированные деревья. AVL-деревья.
Процесс поиска места для вставки нового узла в
Сбалансированные деревья. AVL-деревья.
Процесс поиска места для вставки нового узла в

Сбалансированные деревья. AVL-деревья.
Есть три возможных ситуации.
В двух первых случаях
Сбалансированные деревья. AVL-деревья.
Есть три возможных ситуации.
В двух первых случаях
Сбалансированные деревья. AVL-деревья.
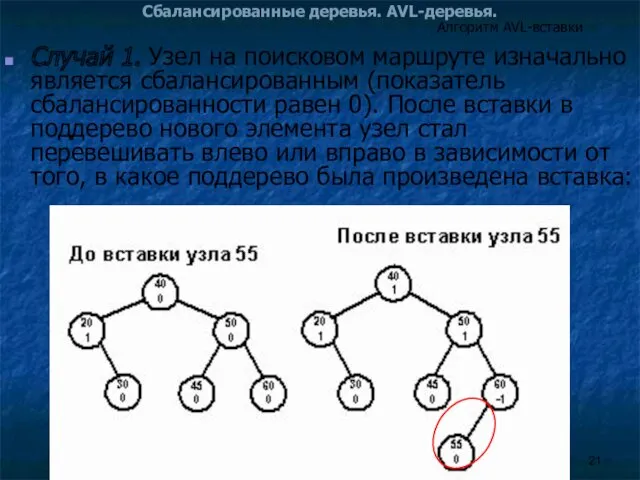
Случай 1. Узел на поисковом маршруте изначально является
Сбалансированные деревья. AVL-деревья.
Случай 1. Узел на поисковом маршруте изначально является
Сбалансированные деревья. AVL-деревья.
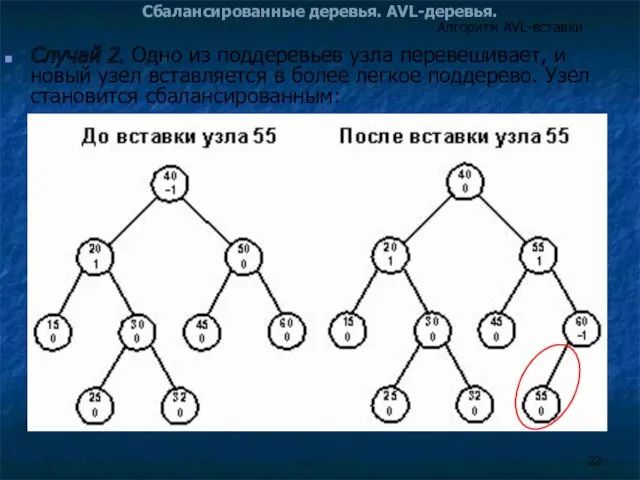
Случай 2. Одно из поддеревьев узла перевешивает, и
Сбалансированные деревья. AVL-деревья.
Случай 2. Одно из поддеревьев узла перевешивает, и

Сбалансированные деревья. AVL-деревья.
Случай 3. Одно из поддеревьев узла перевешивает, и
Сбалансированные деревья. AVL-деревья.
Случай 3. Одно из поддеревьев узла перевешивает, и
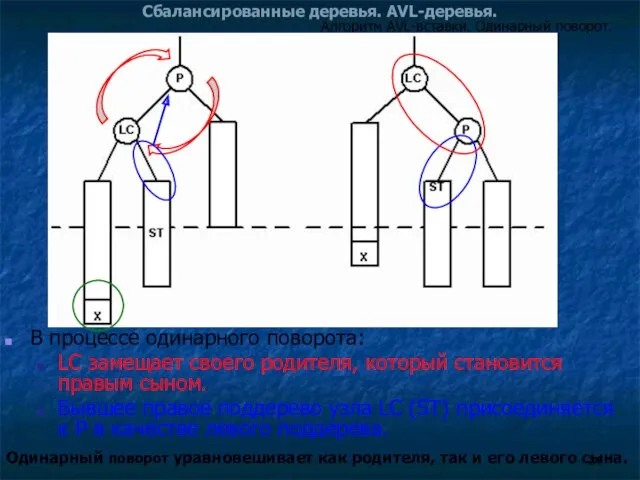
Сбалансированные деревья. AVL-деревья.
В процессе одинарного поворота:
LC замещает своего родителя, который
Сбалансированные деревья. AVL-деревья.
В процессе одинарного поворота:
LC замещает своего родителя, который
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки
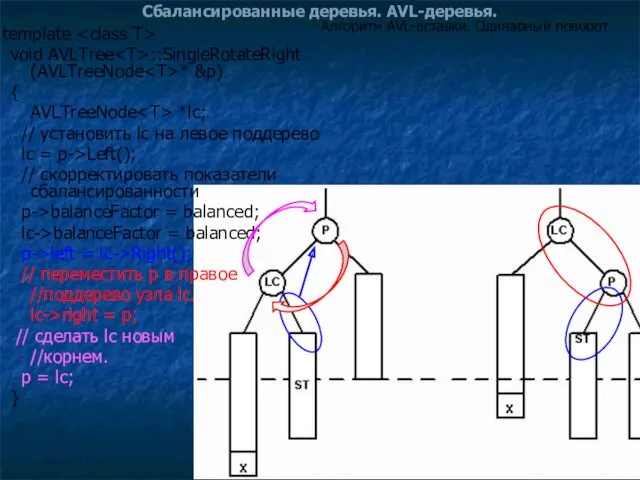
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Одинарный поворот.
template
void AVLTree::SingleRotateRight
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Одинарный поворот.
template
void AVLTree
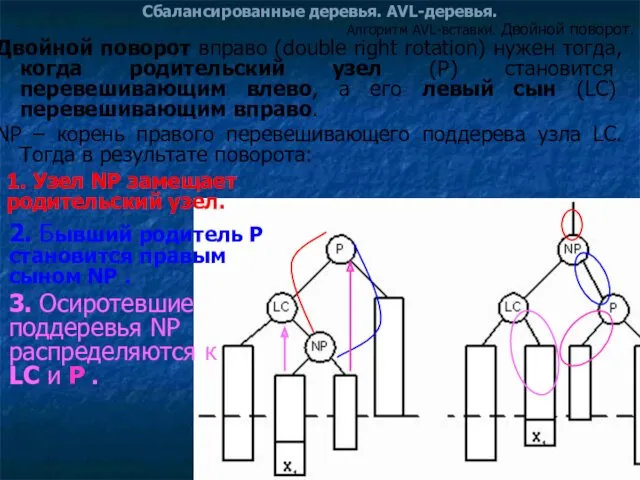
Сбалансированные деревья. AVL-деревья.
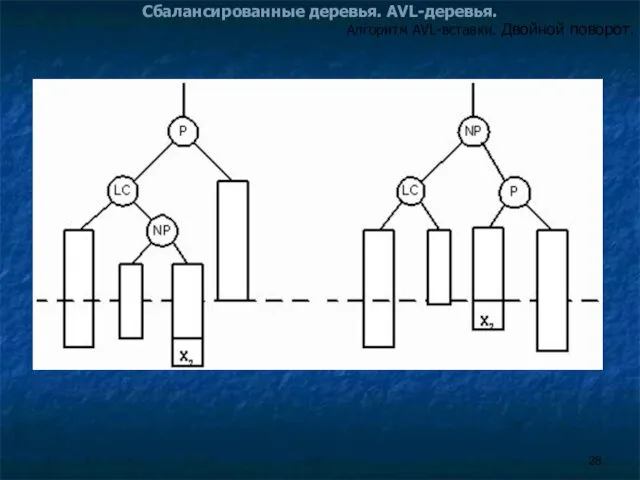
Двойной поворот вправо (double right rotation) нужен тогда,
Сбалансированные деревья. AVL-деревья.
Двойной поворот вправо (double right rotation) нужен тогда,
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Двойной поворот.
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Двойной поворот.
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Двойной поворот.
Сбалансированные деревья. AVL-деревья.
Алгоритм AVL-вставки. Двойной поворот.

Сбалансированные деревья. AVL-деревья.
Оценка сбалансированных деревьев
AVL-деревья требуют дополнительных затрат на
Сбалансированные деревья. AVL-деревья.
Оценка сбалансированных деревьев
AVL-деревья требуют дополнительных затрат на

Доступ к данным во внешней памяти.
B-деревья.
До сих пор задача
Доступ к данным во внешней памяти.
B-деревья.
До сих пор задача

Доступ к данным во внешней памяти. B-деревья.
В 1970 году Р.
Доступ к данным во внешней памяти. B-деревья.
В 1970 году Р.
Доступ к данным во внешней памяти. B-деревья.
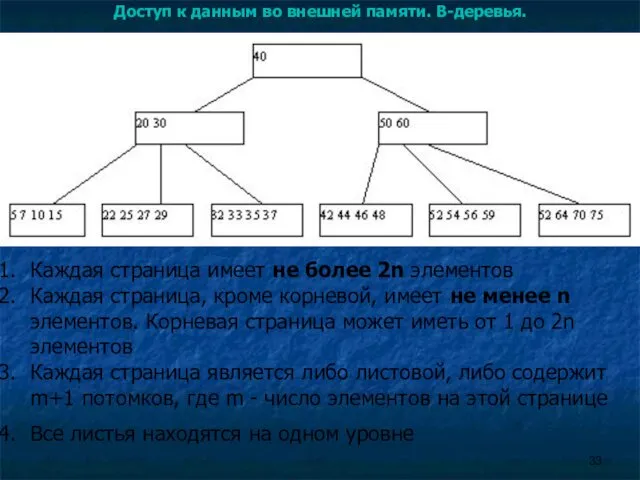
Каждая страница имеет не
Доступ к данным во внешней памяти. B-деревья.
Каждая страница имеет не
Доступ к данным во внешней памяти. B-деревья.
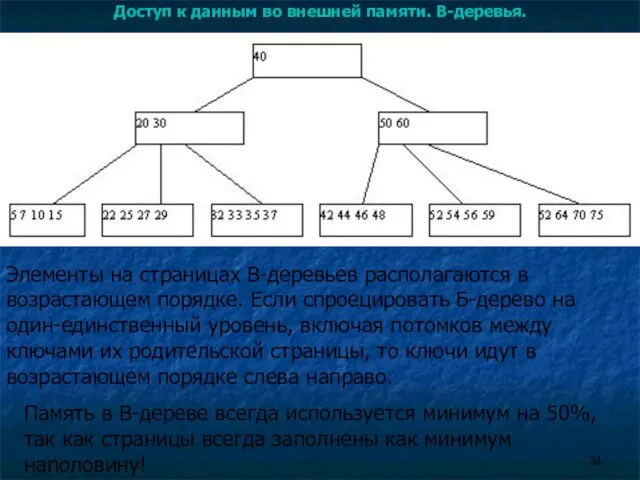
Элементы на страницах B-деревьев
Доступ к данным во внешней памяти. B-деревья.
Элементы на страницах B-деревьев

Доступ к данным во внешней памяти. B-деревья.
Пусть задан некоторый аргумент
Доступ к данным во внешней памяти. B-деревья.
Пусть задан некоторый аргумент

Доступ к данным во внешней памяти. B-деревья.
Включение в B-дерево проводится
Доступ к данным во внешней памяти. B-деревья.
Включение в B-дерево проводится
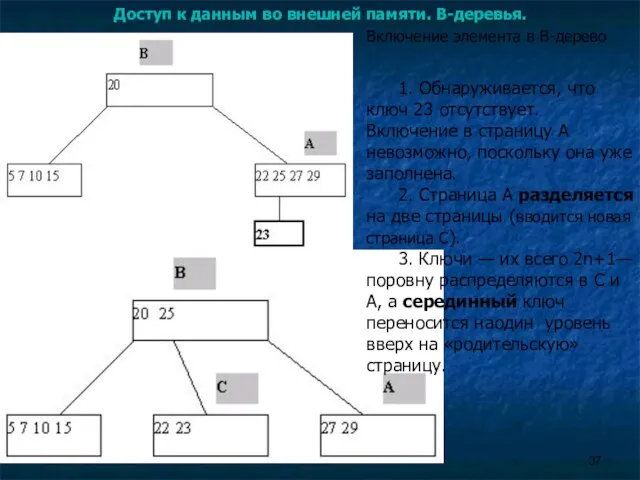
Доступ к данным во внешней памяти. B-деревья.
Включение элемента в B-дерево
1.
Доступ к данным во внешней памяти. B-деревья.
Включение элемента в B-дерево
1.
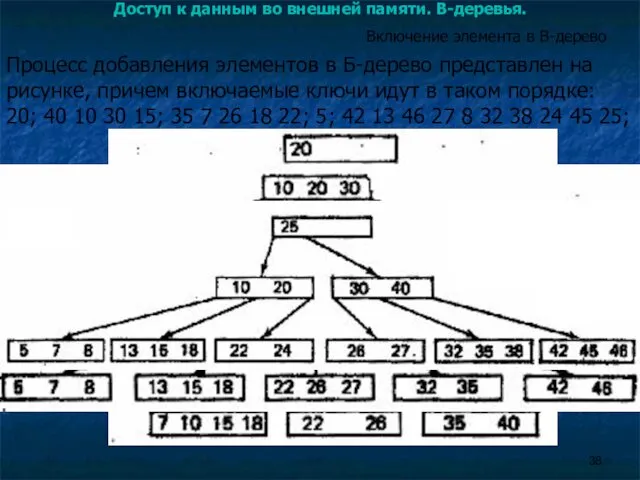
Доступ к данным во внешней памяти. B-деревья.
Включение элемента в B-дерево
Процесс
Доступ к данным во внешней памяти. B-деревья.
Включение элемента в B-дерево
Процесс

Доступ к данным во внешней памяти. B-деревья.
При исключении элемента из
Доступ к данным во внешней памяти. B-деревья.
При исключении элемента из

Доступ к данным во внешней памяти. B-деревья.
В том случае, если
Доступ к данным во внешней памяти. B-деревья.
В том случае, если

Доступ к данным во внешней памяти. B-деревья.
Исключение элемента из B-дерева
Рассмотрим
Доступ к данным во внешней памяти. B-деревья.
Исключение элемента из B-дерева
Рассмотрим

Программная реализация B-дерева.
//задаем порядок дерева
#define LEVEL 3
//количество элементов на странице
#define
Программная реализация B-дерева.
//задаем порядок дерева
#define LEVEL 3
//количество элементов на странице
#define

Программная реализация B-дерева.
template
class CBTreePage
{
public:
//массив элементов на странице
DATA
Программная реализация B-дерева.
template
class CBTreePage
{
public:
//массив элементов на странице
DATA

Программная реализация B-дерева.
template
class CBTree
{
private:
//смещение корневой страницы
int m_iroot;
//максимальное смещение
Программная реализация B-дерева.
template
class CBTree
{
private:
//смещение корневой страницы
int m_iroot;
//максимальное смещение

Хеширование данных. Хеш-таблицы.
Для ускорения доступа к данным в таблицах баз
Хеширование данных. Хеш-таблицы.
Для ускорения доступа к данным в таблицах баз

Хеширование данных
Идеальной хеш-функцией является такая хеш-функция, которая для любых двух
Хеширование данных
Идеальной хеш-функцией является такая хеш-функция, которая для любых двух
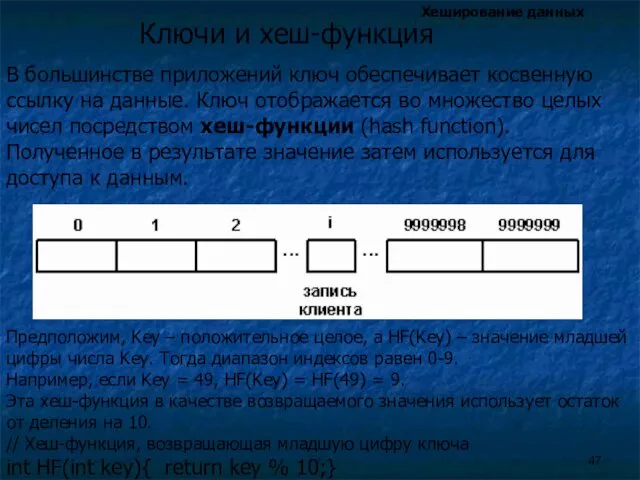
Хеширование данных
В большинстве приложений ключ обеспечивает косвенную ссылку на данные.
Хеширование данных
В большинстве приложений ключ обеспечивает косвенную ссылку на данные.

Хеширование данных
Очевидно, что при заполнении хеш-таблицы могут возникать ситуации, когда
Хеширование данных
Очевидно, что при заполнении хеш-таблицы могут возникать ситуации, когда

Хеширование данных
Коллизии и методы разрешения коллизий
Хеширование данных
Коллизии и методы разрешения коллизий

Хеширование данных
Коллизии и методы разрешения коллизий
Поиск в хеш-таблице с цепочками
Хеширование данных
Коллизии и методы разрешения коллизий
Поиск в хеш-таблице с цепочками

Хеширование данных
Коллизии и методы разрешения коллизий
Методы открытой адресации состоят в
Хеширование данных
Коллизии и методы разрешения коллизий
Методы открытой адресации состоят в

Хеширование данных
Коллизии и методы разрешения коллизий
Квадратичное опробование отличается от линейного
Хеширование данных
Коллизии и методы разрешения коллизий
Квадратичное опробование отличается от линейного

Хеширование данных
Коллизии и методы разрешения коллизий
Еще одна разновидность метода открытой
Хеширование данных
Коллизии и методы разрешения коллизий
Еще одна разновидность метода открытой

Хеширование данных
Коллизии и методы разрешения коллизий
Алгоритмы вставки и поиска для
Хеширование данных
Коллизии и методы разрешения коллизий
Алгоритмы вставки и поиска для

Хеширование данных
Коллизии и методы разрешения коллизий
С процедурой удаления дело обстоит
Хеширование данных
Коллизии и методы разрешения коллизий
С процедурой удаления дело обстоит

Хеширование данных
Коллизии и методы разрешения коллизий
Сформулируем алгоритмы вставки, поиска и
Хеширование данных
Коллизии и методы разрешения коллизий
Сформулируем алгоритмы вставки, поиска и
Хеширование данных
Переполнение таблицы и рехеширование
Хеширование данных
Переполнение таблицы и рехеширование
 Support Desk Technologies. Общение в чатах
Support Desk Technologies. Общение в чатах Механизмы синхронизации и взаимоблокировка ресурсов в многозадачных системах
Механизмы синхронизации и взаимоблокировка ресурсов в многозадачных системах Spatial data development for SDI
Spatial data development for SDI Image manipulation program GIMP GNU
Image manipulation program GIMP GNU Бот для магазина цветов в Telegram
Бот для магазина цветов в Telegram OSPF. Основы протокола
OSPF. Основы протокола Разработка корпоративного WEB сайта организации
Разработка корпоративного WEB сайта организации Матричные функции в MS EXCEL
Матричные функции в MS EXCEL История языков. Поколения языков программирования
История языков. Поколения языков программирования создание кисти в фотошопе
создание кисти в фотошопе ГАЖ-технологиясымен мұнай төгілген жерлерді картаға түсіру
ГАЖ-технологиясымен мұнай төгілген жерлерді картаға түсіру Классификация информационных технологий
Классификация информационных технологий Ақпаратты қорғау негіздері
Ақпаратты қорғау негіздері Онлайн-переводчики и ГДЗ: помощники или вредители
Онлайн-переводчики и ГДЗ: помощники или вредители ВКонтакті
ВКонтакті Кодирование и обработка звуковой информации. Создание звукового клипа
Кодирование и обработка звуковой информации. Создание звукового клипа Операционная система. Прикладное ПО
Операционная система. Прикладное ПО By Artem Morozov
By Artem Morozov Представление 2D - графики
Представление 2D - графики Dispose Pattern in C#
Dispose Pattern in C# Представление текстов в памяти компьютера. Кодировочные таблицы
Представление текстов в памяти компьютера. Кодировочные таблицы Индексирование, программирование, векторизация, графические возможности MatLab
Индексирование, программирование, векторизация, графические возможности MatLab Особенности работы с информацией в различных типах источников. Лекция 3
Особенности работы с информацией в различных типах источников. Лекция 3 DeepScale стартап компаниясының SqueezeNet жүйесі
DeepScale стартап компаниясының SqueezeNet жүйесі Путешествие по интернету
Путешествие по интернету Условный рендеринг
Условный рендеринг Основы электротехники. Платформа Arduino
Основы электротехники. Платформа Arduino Разработка проекта локальной вычислительной сети
Разработка проекта локальной вычислительной сети