- Обработка больших данных

Содержание
- 2. ЛИТЕРАТУРА
- 3. Python 2 и Python 3 Python 3 - более новая версия. Иногда код, написанный на Python
- 4. Скопировать файл affinity_dataset.txt [в папку python (по умолчанию при установке C:\Users\User ), или указывать путь] import
- 5. - Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1 по каждому item. Решить задачу
- 6. Пример реализации для произвольной пары #Составляем правила: если X1=1 и X2=1 – то valid, иначе –
- 7. # Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1 # (т.е. когда X1=1, а
- 9. Скачать презентацию

ЛИТЕРАТУРА
ЛИТЕРАТУРА

Python 2 и Python 3
Python 3 - более новая версия.
Иногда
Python 2 и Python 3
Python 3 - более новая версия.
Иногда

Скопировать файл affinity_dataset.txt
[в папку python (по умолчанию при установке C:\Users\User
Скопировать файл affinity_dataset.txt
[в папку python (по умолчанию при установке C:\Users\User

- Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1
- Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1

Пример реализации для произвольной пары
#Составляем правила: если X1=1 и X2=1 –
Пример реализации для произвольной пары
#Составляем правила: если X1=1 и X2=1 –
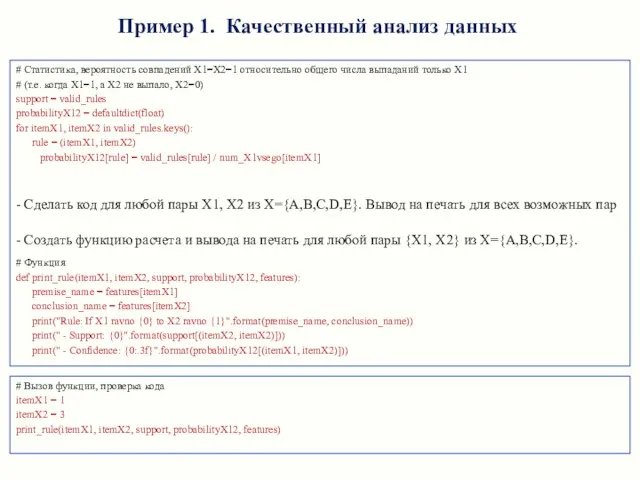
# Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1
# Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1
 Сетевые характеристики. Лекция 6
Сетевые характеристики. Лекция 6 Производные типы данных MPI, коммуникаторы и виртуальные топологии
Производные типы данных MPI, коммуникаторы и виртуальные топологии Урок информатики в 5 классе Этапы подготовки документа на компьютере (УМК Л.Л. Босова)
Урок информатики в 5 классе Этапы подготовки документа на компьютере (УМК Л.Л. Босова) Данные. Типы данных
Данные. Типы данных Кодирование графической информации. Задачи
Кодирование графической информации. Задачи Математичне програмування. Задачі оптимізації. Задача лінійного програмування. Лекція 5
Математичне програмування. Задачі оптимізації. Задача лінійного програмування. Лекція 5 Области применения информационных технологий в лингвистике
Области применения информационных технологий в лингвистике Программное обеспечение персонального компьютера
Программное обеспечение персонального компьютера 16-сабақ. Ғаламтормен дұрыс жұмыс жасау -мәдениет
16-сабақ. Ғаламтормен дұрыс жұмыс жасау -мәдениет Алгоритмы и программы. Решение олимпиадных задач
Алгоритмы и программы. Решение олимпиадных задач Свертывание информации. Виды свертывания. Понятие и структура текста. (Тема 3)
Свертывание информации. Виды свертывания. Понятие и структура текста. (Тема 3) Машинное обучение
Машинное обучение Интернет-безопасность, что надо о ней знать
Интернет-безопасность, что надо о ней знать Логомиры. Кто такие черепашки?
Логомиры. Кто такие черепашки? Глубокое машинное обучение ПРИ-120
Глубокое машинное обучение ПРИ-120 Multithreading. User Group’s Web Site
Multithreading. User Group’s Web Site Средства массовой информации (СМИ) и их роль в современном обществе
Средства массовой информации (СМИ) и их роль в современном обществе Киберпреступность и кибертерроризм
Киберпреступность и кибертерроризм Оформление сайта. Диагностика кожи
Оформление сайта. Диагностика кожи Метод сортировки вставками
Метод сортировки вставками Комплексный подход к защите информации. (Лекция 2)
Комплексный подход к защите информации. (Лекция 2) Графический редактор Paint
Графический редактор Paint Технологии доступа к данным формирование отчетов. (Лекция 19)
Технологии доступа к данным формирование отчетов. (Лекция 19) Информатика и ИКТ
Информатика и ИКТ История развития вычислительной техники
История развития вычислительной техники Оқу орындарына wi-fi керек пе?
Оқу орындарына wi-fi керек пе? Информация
Информация Моделирование и формализация. Классификация и структуры моделей
Моделирование и формализация. Классификация и структуры моделей