- Области применения информационных технологий в лингвистике

Содержание
- 2. Автоматический анализ и синтез звучащей речи Одним из первых важных шагов использования информационных технологий в лингвистике
- 3. Процесс автоматического анализа речи включает следующие этапы: 1) ввод звучащей речи в компьютер с помощью микрофона.
- 4. В основе пофонемного распознавания звуков речи лежит анализ: длительности и динамики звучания, чередования акустического сигнала и
- 5. Задачей автоматического анализа звучащей речи при использовании спектрограмм становится перевод спектрограмм в фонологическую транскрипцию. В итоге
- 6. Примеры программ, в которых применяются средства автоматического анализа речи: • программы голосового управления компьютером и бытовой
- 7. Автоматически синтезируется речь в следующих ситуациях: • называние текущего времени по телефону, • объявление остановок в
- 8. 2. Технологии обработки текста Представление текста Под “текстовым” понимают такое представление информации, в котором она представлена
- 9. Правила машинописного набора текста Для облегчения анализа и последующего преобразования текста при его наборе в самых
- 10. Оформление текста Шрифт характеризуется рядом параметров: 1. Рисунок шрифта — графические особенности, определяющие общность шрифта и
- 11. Совокупность всех возможных размеров и вариантов написания шрифта называется гарнитурой. Гарнитуры имеют имена, по которым часто
- 12. Структурирование теста Для оформления абзаца используют несколько параметров: 1. Выравнивание (выключка) — правило расположения букв в
- 13. Автоматизированная обработка текста Расшифровка или уточнение значений слова Системы автоматизированной обработки текста Примеры программных продуктов Системы
- 14. 3. Автоматическое распознавание текста Для ввода информации в компьютер используются специальные устройства — клавиатура, мышь и
- 15. 4. Автоматическое аннотирование и реферирование текста Для обработки большого массива текстов за минимальное количество времени требуется
- 16. В большинстве программ, направленных на автоматическое составление краткого содержания текста, можно задать разную степень компрессии текста,
- 17. Наиболее простыми системами автоматического реферирования и аннотирования является функция Аиto Summarize в MS Word, системы Intelligent
- 18. 5. Автоматический анализ и синтез текста При автоматическом анализе текст последовательно преобразуется в его лексемно-морфологические, синтаксические
- 19. При морфологическом анализе каждое использованное в тексте слово возводится к его исходной форме и определяется набор
- 20. При синтаксическом анализе необходимо определить роли слов в предложении и их связи между собой. Результатом этого
- 21. Семантический анализ представляет собой, пожалуй, наиболее сложное направление автоматического анализа текста. В этом случае требуется установление
- 22. Автоматический синтез представляет собой процесс производства связного текста, отдельные этапы которого являются теми же, что и
- 24. Скачать презентацию

Автоматический анализ и синтез
звучащей речи
Одним из первых важных шагов использования
Автоматический анализ и синтез
звучащей речи
Одним из первых важных шагов использования

Процесс автоматического анализа речи включает следующие этапы:
1) ввод звучащей речи в
Процесс автоматического анализа речи включает следующие этапы:
1) ввод звучащей речи в

В основе пофонемного распознавания звуков речи лежит анализ:
длительности и динамики
В основе пофонемного распознавания звуков речи лежит анализ:
длительности и динамики

Задачей автоматического анализа звучащей речи при использовании спектрограмм становится перевод спектрограмм
Задачей автоматического анализа звучащей речи при использовании спектрограмм становится перевод спектрограмм

Примеры программ, в которых применяются средства автоматического анализа речи:
• программы голосового
Примеры программ, в которых применяются средства автоматического анализа речи:
• программы голосового

Автоматически синтезируется речь в следующих ситуациях:
• называние текущего времени по телефону,
•
Автоматически синтезируется речь в следующих ситуациях:
• называние текущего времени по телефону,
•

2. Технологии обработки текста
Представление текста
Под “текстовым” понимают такое представление информации, в
2. Технологии обработки текста
Представление текста
Под “текстовым” понимают такое представление информации, в

Правила машинописного набора текста
Для облегчения анализа и последующего преобразования текста при
Правила машинописного набора текста
Для облегчения анализа и последующего преобразования текста при

Оформление текста
Шрифт характеризуется рядом параметров:
1. Рисунок шрифта — графические особенности, определяющие
Оформление текста
Шрифт характеризуется рядом параметров:
1. Рисунок шрифта — графические особенности, определяющие

Совокупность всех возможных размеров и вариантов написания шрифта называется гарнитурой. Гарнитуры имеют
Совокупность всех возможных размеров и вариантов написания шрифта называется гарнитурой. Гарнитуры имеют

Структурирование теста
Для оформления абзаца используют несколько параметров:
1. Выравнивание (выключка) — правило расположения букв
Структурирование теста
Для оформления абзаца используют несколько параметров:
1. Выравнивание (выключка) — правило расположения букв

Автоматизированная обработка текста
Расшифровка или уточнение значений слова
Системы автоматизированной обработки текста
Примеры программных
Автоматизированная обработка текста
Расшифровка или уточнение значений слова
Системы автоматизированной обработки текста
Примеры программных

3. Автоматическое распознавание текста
Для ввода информации в компьютер используются специальные устройства
3. Автоматическое распознавание текста
Для ввода информации в компьютер используются специальные устройства

4. Автоматическое аннотирование и реферирование текста
Для обработки большого массива текстов за
4. Автоматическое аннотирование и реферирование текста
Для обработки большого массива текстов за

В большинстве программ, направленных на автоматическое составление краткого содержания текста, можно
В большинстве программ, направленных на автоматическое составление краткого содержания текста, можно

Наиболее простыми системами автоматического реферирования и аннотирования является функция Аиto Summarize
Наиболее простыми системами автоматического реферирования и аннотирования является функция Аиto Summarize

5. Автоматический анализ и синтез текста
При автоматическом анализе текст последовательно преобразуется
5. Автоматический анализ и синтез текста
При автоматическом анализе текст последовательно преобразуется

При морфологическом анализе каждое использованное в тексте слово возводится к его
При морфологическом анализе каждое использованное в тексте слово возводится к его
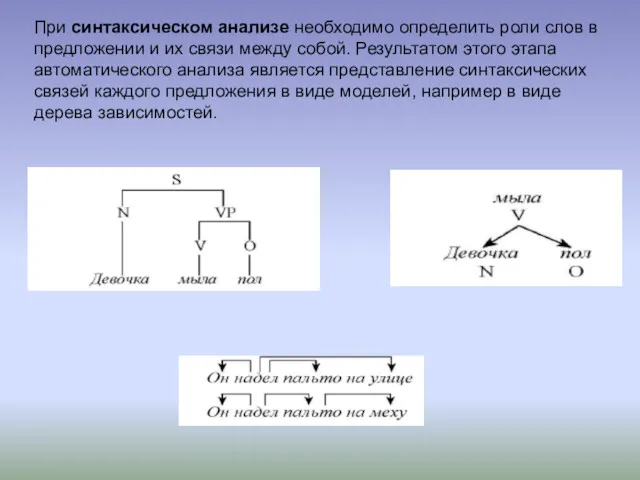
При синтаксическом анализе необходимо определить роли слов в предложении и их
При синтаксическом анализе необходимо определить роли слов в предложении и их

Семантический анализ представляет собой, пожалуй, наиболее сложное направление автоматического анализа текста.
Семантический анализ представляет собой, пожалуй, наиболее сложное направление автоматического анализа текста.

Автоматический синтез представляет собой процесс производства связного текста, отдельные этапы которого
Автоматический синтез представляет собой процесс производства связного текста, отдельные этапы которого
 Компьютерная графика. Векторная и растровая графика
Компьютерная графика. Векторная и растровая графика Аудит сайта
Аудит сайта Сутність технології COM
Сутність технології COM Как создать свой сайт
Как создать свой сайт Условный оператор в Паскале. 9 класс
Условный оператор в Паскале. 9 класс Как образуются понятия
Как образуются понятия Файлы и файловые структуры. Компьютер как унивесальное устройство для работы с информацией
Файлы и файловые структуры. Компьютер как унивесальное устройство для работы с информацией Статистические методы обработки информации
Статистические методы обработки информации Методическая разработка урока информатики по теме Законы алгебры логики в 9 классе
Методическая разработка урока информатики по теме Законы алгебры логики в 9 классе Интернет. Основные понятия и возможности
Интернет. Основные понятия и возможности Технічна експлуатація автоматизованих систем поштового зв’язку
Технічна експлуатація автоматизованих систем поштового зв’язку Измерение информации
Измерение информации Разработка мероприятия по информатике Системы управления базами данных
Разработка мероприятия по информатике Системы управления базами данных Принципы и структура системного анализа. Декомпозиция системы
Принципы и структура системного анализа. Декомпозиция системы КВН
КВН Представление чисел в памяти компьютера. 9 класс
Представление чисел в памяти компьютера. 9 класс Zelio Logic - Communication Extension
Zelio Logic - Communication Extension Презентация к урокуАлгоритм.Свойства алгоритмов
Презентация к урокуАлгоритм.Свойства алгоритмов Новые информационные технологии
Новые информационные технологии Алгоритмы, структуры алгоритмов, структурное программирование
Алгоритмы, структуры алгоритмов, структурное программирование Task 3. Internet. Тренажёр ЕГЭ
Task 3. Internet. Тренажёр ЕГЭ Wi-Fi тechnology
Wi-Fi тechnology Кодирование звуковой информации. Представление информации в компьютере
Кодирование звуковой информации. Представление информации в компьютере Технология создания мультимедийной презентации
Технология создания мультимедийной презентации Планування безпроводових мереж на базі технології Wi-Fi на прикладі Web-відділу компанії Вияр
Планування безпроводових мереж на базі технології Wi-Fi на прикладі Web-відділу компанії Вияр Контекстная реклама в Яндекс-Директ (ЯД*)
Контекстная реклама в Яндекс-Директ (ЯД*) Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих
Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих Сетевые операционные системы. Операционные среды, системы и оболочки
Сетевые операционные системы. Операционные среды, системы и оболочки