- Обзор инструментов обработки Big Data

Содержание
- 2. 1. Собрать данные; 2. Преобразовать данные в формат, подходящий для их хранения; 3. Произвести очистку данных;
- 3. Copyright © Econophysica 2019. All Rights Reserved Постоянная задержка менее 10 мс. Репликация обеспечивает более высокую
- 4. Платформа программного обеспечения с открытым исходным кодом, поддерживающая распределенные приложения с интенсивным использованием данных, лицензированная по
- 5. Гибкий и мощный открытый распределенный поисковый и аналитический движок в реальном времени для облака. Возможности: Работа
- 6. O (1) поиск узла; Хранилище с подходом Ключ – Значение; Хранилище данных на основе столбцов; Высоко
- 7. Cassandra 7 Copyright © Econophysica 2019. All Rights Reserved Масштабируемость, тест Netflix
- 8. Дробление: Как данные распределяются по узлам; Репликация: Как данные дублируются на узлах; Членство в кластере Как
- 9. Узлы логически структурированы в кольцевой топологии. Хешированное значение ключа, связанного с разделом данных, используется для назначения
- 10. Каждый элемент данных реплицируется в N (фактор репликации) узлах. Различные политики репликации Rack Unaware - реплицируйте
- 11. Cassandra Copyright © Econophysica 2019. All Rights Reserved Модель данных
- 12. Cassandra Copyright © Econophysica 2019. All Rights Reserved PACELC в случае разделения сети (P) в распределённой
- 13. Cassandra: использование Copyright © Econophysica 2019. All Rights Reserved
- 14. Cassandra Copyright © Econophysica 2019. All Rights Reserved Подойдет ли Cassandra для моей задачи? Вам требуется
- 15. Open-source; Основана на документах – объектах в формате BSON (Binary JSON); “High performance, high availability”; Автоматическое
- 16. Авто-Sharding (горизонтальное масштабирование); Большие наборы данных могут быть разделены и распределены по нескольким шардам; Быстрые обновления
- 17. Высокопроизводительные и масштабируемые приложения; Большинство веб-приложений, в которых вы ранее использовали SQL; Не используйте для: Приложений,
- 18. MongoDB Copyright © Econophysica 2019. All Rights Reserved Пользователи:
- 19. CouchDB - это документно-ориентированная СУБД, не реляционная: без схемы базы данных; Модель ключ-значение; Распределенная и отказоустойчивая;
- 20. Различные типы данных поддерживаются как дополнительные документы (видео, аудио, изображения и т. Д.) Связь с приложениями
- 21. Протокол: GET извлекает ресурс, на который ссылается URI. PUT создает ресурс по указанному URI. POST отправляет
- 22. Отправить запрос HTTP, получить ответ. $ curl -X GET http://mycouch.org {"couchdb":"Welcome","version":"1.0.1"} Создать базу данных. $ curl
- 23. Кассандра и CouchDB предлагают доступность. Hadoop и MongoDB предлагают согласованность. ElasticSearch следует примеру реляционных баз данных
- 24. Сбор, агрегация потоковых данных о событиях; Обычно используется для данных журналов событий; Значительные преимущества перед специальными
- 25. Событие - это основная единица данных, транспортируемых Flume от пункта отправления до конечного пункта назначения. Событие
- 26. Сущность, которая генерирует события и отправляет их одному или нескольким агентам. Примеры: Flume log4j Appender Пользовательский
- 27. Контейнер для размещения источников, каналов, приемников и других компонентов, которые позволяют переносить события из одного места
- 28. Активный компонент, который получает события из специализированного местоположения или механизма и размещает его на одном или
- 29. Пассивный компонент, который буферизует входящие события до тех пор, пока они не будут взяты из канала
- 30. Активный компонент, который забирает события из канала и передает их в пункт назначения следующего перехода. Различные
- 31. Flume Copyright © Econophysica 2019. All Rights Reserved Архитектура:
- 32. Flume Copyright © Econophysica 2019. All Rights Reserved Архитектура:
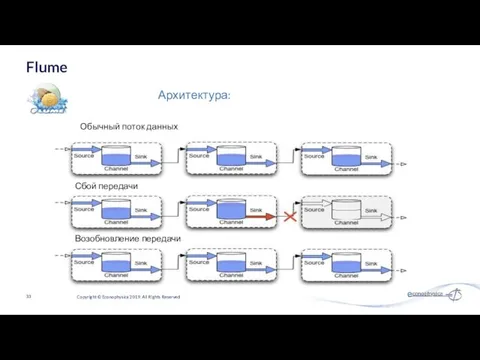
- 33. Flume Copyright © Econophysica 2019. All Rights Reserved Архитектура: Обычный поток данных Сбой передачи Возобновление передачи
- 34. Logstash - это приложение, которое собирает файлы журналов с серверов приложений, анализирует их, форматирует и отправляет
- 35. Очень высокая производительность; Эластически масштабируемая; Низкие эксплуатационные расходы; Надежная, высокодоступная; Гарантирует: Проверку целостности данных; Доставку данных
- 36. Открытый инструмент для очистки больших данных, предназначенный для очистки сырых данных. Удобный; Хорошее сообщество; Требуются некоторые
- 37. Удобный инструмент для очистки больших данных, предназначенный для очистки сырых данных. Закрытый исходный код, платный по
- 38. Веб-плагин для ElasticSearch, который позволяет осуществлять полную визуализацию данных кластера. Гибкая платформа для аналитики и визуализации.
- 39. Matplotlib - это библиотека Python 2D для построения графиков, которая генерирует графики уровня публикаций в различных
- 40. Tableau - это инструмент визуализации данных, в котором основное внимание уделяется бизнес-аналитике. Вы можете создавать карты,
- 41. Jupyter Notebooks; Matplotlib; Hadoop; Spark; PanDA. NumPy, SciPy, Scikit-Learn, и т. д. Python Copyright © Econophysica
- 42. R - это свободная программная среда для статистических вычислений и графики. R предоставляет широкий спектр статистических
- 43. Используется в Java, Scala, Python и R. Высококачественные алгоритмы, в 100 раз быстрее, чем MapReduce. Работает
- 44. Заключение При выборе технологий обратите пристальное внимание на сильные и слабые стороны конкретных реализаций, а также
- 46. Скачать презентацию

1. Собрать данные;
2. Преобразовать данные в формат, подходящий для их хранения;
3.
1. Собрать данные; 2. Преобразовать данные в формат, подходящий для их хранения; 3.

Copyright © Econophysica 2019. All Rights Reserved
Постоянная задержка менее 10 мс.
Репликация
Copyright © Econophysica 2019. All Rights Reserved
Постоянная задержка менее 10 мс.
Репликация

Платформа программного обеспечения с открытым исходным кодом, поддерживающая распределенные приложения с
Платформа программного обеспечения с открытым исходным кодом, поддерживающая распределенные приложения с

Гибкий и мощный открытый распределенный поисковый и аналитический движок в реальном
Гибкий и мощный открытый распределенный поисковый и аналитический движок в реальном

O (1) поиск узла;
Хранилище с подходом Ключ – Значение;
Хранилище данных
O (1) поиск узла;
Хранилище с подходом Ключ – Значение;
Хранилище данных
Cassandra
7
Copyright © Econophysica 2019. All Rights Reserved
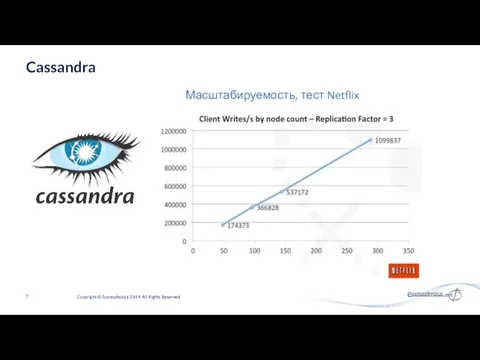
Масштабируемость, тест Netflix
Cassandra
7
Copyright © Econophysica 2019. All Rights Reserved
Масштабируемость, тест Netflix

Дробление:
Как данные распределяются по узлам;
Репликация:
Как данные дублируются на узлах;
Членство в кластере
Как
Дробление:
Как данные распределяются по узлам;
Репликация:
Как данные дублируются на узлах;
Членство в кластере
Как

Узлы логически структурированы в кольцевой топологии.
Хешированное значение ключа, связанного с разделом
Узлы логически структурированы в кольцевой топологии.
Хешированное значение ключа, связанного с разделом

Каждый элемент данных реплицируется в N (фактор репликации) узлах.
Различные политики репликации
Rack
Каждый элемент данных реплицируется в N (фактор репликации) узлах.
Различные политики репликации
Rack
Cassandra
Copyright © Econophysica 2019. All Rights Reserved
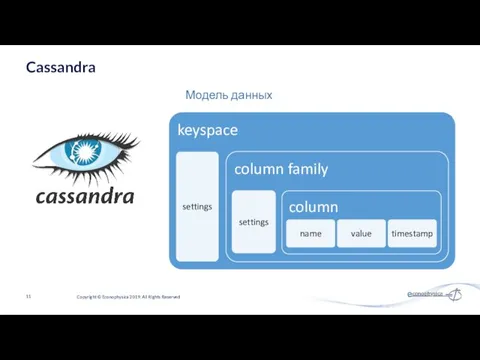
Модель данных
Cassandra
Copyright © Econophysica 2019. All Rights Reserved
Модель данных

Cassandra
Copyright © Econophysica 2019. All Rights Reserved
PACELC
в случае разделения сети (P)
Cassandra
Copyright © Econophysica 2019. All Rights Reserved
PACELC
в случае разделения сети (P)

Cassandra: использование
Copyright © Econophysica 2019. All Rights Reserved
Cassandra: использование
Copyright © Econophysica 2019. All Rights Reserved

Cassandra
Copyright © Econophysica 2019. All Rights Reserved
Подойдет ли Cassandra для моей
Cassandra
Copyright © Econophysica 2019. All Rights Reserved
Подойдет ли Cassandra для моей

Open-source;
Основана на документах – объектах в формате BSON (Binary JSON);
“High performance,
Open-source;
Основана на документах – объектах в формате BSON (Binary JSON);
“High performance,

Авто-Sharding (горизонтальное масштабирование);
Большие наборы данных могут быть разделены и распределены по
Авто-Sharding (горизонтальное масштабирование);
Большие наборы данных могут быть разделены и распределены по

Высокопроизводительные и масштабируемые приложения;
Большинство веб-приложений, в которых вы ранее использовали SQL;
Не
Высокопроизводительные и масштабируемые приложения;
Большинство веб-приложений, в которых вы ранее использовали SQL;
Не

MongoDB
Copyright © Econophysica 2019. All Rights Reserved
Пользователи:
MongoDB
Copyright © Econophysica 2019. All Rights Reserved
Пользователи:

CouchDB - это документно-ориентированная СУБД, не реляционная: без схемы базы данных;
CouchDB - это документно-ориентированная СУБД, не реляционная: без схемы базы данных;

Различные типы данных поддерживаются как дополнительные документы (видео, аудио, изображения и
Различные типы данных поддерживаются как дополнительные документы (видео, аудио, изображения и

Протокол:
GET извлекает ресурс, на который ссылается URI.
PUT создает ресурс по указанному
Протокол:
GET извлекает ресурс, на который ссылается URI.
PUT создает ресурс по указанному

Отправить запрос HTTP, получить ответ.
$ curl -X GET http://mycouch.org
{"couchdb":"Welcome","version":"1.0.1"}
Создать базу данных.
$
Отправить запрос HTTP, получить ответ. $ curl -X GET http://mycouch.org {"couchdb":"Welcome","version":"1.0.1"} Создать базу данных. $

Кассандра и CouchDB предлагают доступность.
Hadoop и MongoDB предлагают согласованность.
ElasticSearch
Кассандра и CouchDB предлагают доступность.
Hadoop и MongoDB предлагают согласованность.
ElasticSearch

Сбор, агрегация потоковых данных о событиях;
Обычно используется для данных журналов
Сбор, агрегация потоковых данных о событиях;
Обычно используется для данных журналов

Событие - это основная единица данных, транспортируемых Flume от пункта отправления
Событие - это основная единица данных, транспортируемых Flume от пункта отправления

Сущность, которая генерирует события и отправляет их одному или нескольким агентам.
Примеры:
Flume
Сущность, которая генерирует события и отправляет их одному или нескольким агентам.
Примеры:
Flume

Контейнер для размещения источников, каналов, приемников и других компонентов, которые позволяют
Контейнер для размещения источников, каналов, приемников и других компонентов, которые позволяют

Активный компонент, который получает события из специализированного местоположения или механизма и
Активный компонент, который получает события из специализированного местоположения или механизма и

Пассивный компонент, который буферизует входящие события до тех пор, пока они
Пассивный компонент, который буферизует входящие события до тех пор, пока они

Активный компонент, который забирает события из канала и передает их в
Активный компонент, который забирает события из канала и передает их в
Flume
Copyright © Econophysica 2019. All Rights Reserved
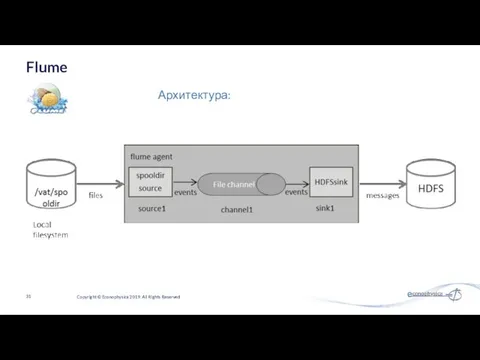
Архитектура:
Flume
Copyright © Econophysica 2019. All Rights Reserved
Архитектура:
Flume
Copyright © Econophysica 2019. All Rights Reserved
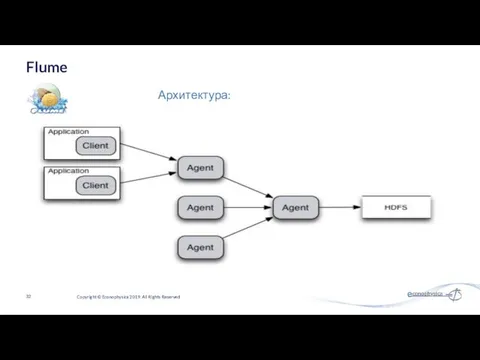
Архитектура:
Flume
Copyright © Econophysica 2019. All Rights Reserved
Архитектура:
Flume
Copyright © Econophysica 2019. All Rights Reserved
Архитектура:
Обычный поток данных
Сбой передачи
Возобновление передачи
Flume
Copyright © Econophysica 2019. All Rights Reserved
Архитектура:
Обычный поток данных
Сбой передачи
Возобновление передачи

Logstash - это приложение, которое собирает файлы журналов с серверов приложений,
Logstash - это приложение, которое собирает файлы журналов с серверов приложений,

Очень высокая производительность;
Эластически масштабируемая;
Низкие эксплуатационные расходы;
Надежная, высокодоступная;
Гарантирует:
Проверку целостности данных;
Доставку данных минимум
Очень высокая производительность;
Эластически масштабируемая;
Низкие эксплуатационные расходы;
Надежная, высокодоступная;
Гарантирует:
Проверку целостности данных;
Доставку данных минимум

Открытый инструмент для очистки больших данных, предназначенный для очистки сырых данных.
Открытый инструмент для очистки больших данных, предназначенный для очистки сырых данных.

Удобный инструмент для очистки больших данных, предназначенный для очистки сырых данных.
Удобный инструмент для очистки больших данных, предназначенный для очистки сырых данных.

Веб-плагин для ElasticSearch, который позволяет осуществлять полную визуализацию данных кластера.
Гибкая
Веб-плагин для ElasticSearch, который позволяет осуществлять полную визуализацию данных кластера.
Гибкая

Matplotlib - это библиотека Python 2D для построения графиков, которая генерирует
Matplotlib - это библиотека Python 2D для построения графиков, которая генерирует

Tableau - это инструмент визуализации данных, в котором основное внимание уделяется
Tableau - это инструмент визуализации данных, в котором основное внимание уделяется

Jupyter Notebooks;
Matplotlib;
Hadoop;
Spark;
PanDA.
NumPy, SciPy, Scikit-Learn, и т. д.
Python
Copyright © Econophysica 2019. All
Jupyter Notebooks;
Matplotlib;
Hadoop;
Spark;
PanDA.
NumPy, SciPy, Scikit-Learn, и т. д.
Python
Copyright © Econophysica 2019. All

R - это свободная программная среда для статистических вычислений и графики.
R - это свободная программная среда для статистических вычислений и графики.

Используется в Java, Scala, Python и R.
Высококачественные алгоритмы, в 100
Используется в Java, Scala, Python и R.
Высококачественные алгоритмы, в 100

Заключение
При выборе технологий обратите пристальное внимание на сильные и слабые стороны
Заключение
При выборе технологий обратите пристальное внимание на сильные и слабые стороны
 Как устроена компьютерная сеть
Как устроена компьютерная сеть Worldwide system of integrated computer networks for storing and transmitting information
Worldwide system of integrated computer networks for storing and transmitting information Текстові і графічні обʼєкти на слайдах. Урок 30
Текстові і графічні обʼєкти на слайдах. Урок 30 Система и окружающая среда. Урок информатики в 7 классе
Система и окружающая среда. Урок информатики в 7 классе Groovy and testing
Groovy and testing Picture gallery component. Technical task
Picture gallery component. Technical task Структурно-функциональное проектирование ИС. Лекция 5
Структурно-функциональное проектирование ИС. Лекция 5 Нахождение оптимального маршрута с пересадками на железной дороге
Нахождение оптимального маршрута с пересадками на железной дороге Transonic Flow Over a NACA 0012 Airfoil
Transonic Flow Over a NACA 0012 Airfoil Поиск простых чисел. PascalABC, FreePascal
Поиск простых чисел. PascalABC, FreePascal Автоматизированная система управления технологическим процессом. Этапы создания АСУ ТП
Автоматизированная система управления технологическим процессом. Этапы создания АСУ ТП Инструкция по регистрации участников соревнования VISTA 2017-2018
Инструкция по регистрации участников соревнования VISTA 2017-2018 Использование информационных технологий в проектном методе на занятиях по музыке
Использование информационных технологий в проектном методе на занятиях по музыке Курсовий проект з дисципліни Програмування на тему: напівпровідникові прилади
Курсовий проект з дисципліни Програмування на тему: напівпровідникові прилади Виды коммуникации. Виды коммуникации в сети интернет
Виды коммуникации. Виды коммуникации в сети интернет Соціальна мережі як платформи масової комунікації в молодіжному середовищі
Соціальна мережі як платформи масової комунікації в молодіжному середовищі Кестелердің құрылуы
Кестелердің құрылуы Алгоритми сортування. Частина 2
Алгоритми сортування. Частина 2 Логические основы компьютеров
Логические основы компьютеров Использование сети Интернет террористическими и экстремистскими организациями
Использование сети Интернет террористическими и экстремистскими организациями Структурированные типы данных: Одномерные массивы
Структурированные типы данных: Одномерные массивы Основы языка программирования. Язык С#
Основы языка программирования. Язык С# Хорошая презентация - залог удачного выступления
Хорошая презентация - залог удачного выступления Назначение программного продукта. Структура 1С: Предприятие
Назначение программного продукта. Структура 1С: Предприятие Mass Media. Game
Mass Media. Game LINUX. Файловая система. Настройки. Команды
LINUX. Файловая система. Настройки. Команды Инструкция по приложению для интервьюера
Инструкция по приложению для интервьюера Работа с текстовым редактором
Работа с текстовым редактором