- Онтологии. RDF

Содержание
- 2. RDF RDF - язык представления информации о ресурсах WWW. В частности, RDF служит для представления метаданных,
- 3. Может оказаться, что в некоторых случаях для управления метаданными достаточно использовать XML и XML Schema (либо
- 4. Модель данных RDF. RDF-граф Базовой структурной единицей RDF является коллекция троек (или триплетов), каждая из которых
- 5. Каждая тройка представляет некоторое высказывание, увязывающее S, P и O. Первые два элемента RDF-тройки (субъект и
- 6. Архитектура метаданных в World Wide Web Документы, метаданные, связи Когда вы переходите по ссылке URL, то
- 7. Пример 1. Метаданные. Объект, извлеченный из сети по протоколу HTTP, может иметь дополнительную информацию (метаданные): дата
- 8. А1. Метаданные - это данные (другими словами, информация об информации - это тоже информация). Поскольку метаданные
- 9. А2. Архитектура, представляемая метаданными, является набором независимых высказываний (утверждений). Как следствие, при группировке двух и более
- 10. ресурс - это объект, о котором фиксируется высказывание, атрибут - некоторое свойство или параметр объекта, значение
- 11. Cвязи Отношение между двумя ресурсами будем называть связью. Связь представляется тройкой (A u1 u2), где А
- 12. RDF-литералы (или символьные константы) RDF-литералы бывают двух видов: типизированные и нетипизированные. Каждый литерал в RDF-графе содержит
- 13. Замечание. Язык литерала не нужно путать с идентификатором (языком) локали. Язык относится только к текстам, написанным
- 14. Сравнение литералов Два литерала равны тогда и только тогда, когда выполняются все перечисленные ниже условия. Строки
- 15. Определение значения типизированного литерала Рассмотрим следующий пример. Пусть множество {T, F} - множество значений истинности в
- 16. Языки представления онтологий: RDFS, OWL. Язык запросов SPARQL Для того чтобы реализовывать различные онтологии, необходимо разработать
- 17. RDFS Каждый из элементов триплета определяется ссылкой на тип элемента и URI. Предикат (в контексте RDF
- 18. RDFS является семантическим расширением RDF. Он предоставляет механизмы для описания групп связанных ресурсов и отношений между
- 19. Система классов и свойств языка описания RDF-словарей похожа на систему типов объектно-ориентированных языков программирования, например, Java.
- 20. Пример. Определим свойство "автор" с доменом "Документ" и диапазоном "Человек". В случае появления дополнительной информации о
- 21. Основное преимущество такого подхода - в легкой расширяемости: добавление/удаление свойств интуитивно проще, чем управление множеством классов,
- 22. Классы Ресурсы могут объединяться в группы, называемые классами. Члены класса (здесь наиболее близкий термин - "экземпляры"
- 23. Экстенсионал и интенсионал Рассмотрим множества A = {0, 2, 4, 6, 8}, B = {x |
- 24. Парадокс Рассела (иногда парадокс Рассела — Цермело) открытый в 1901 году[1] Бертраном Расселом и позднее независимо
- 25. Группа ресурсов, являющихся классами, в RDFS описывается термином rdfs:Class. На множестве классов определено отношение ПОДКЛАСС-НАДКЛАСС, описываемое
- 26. Реификация (материализация, овеществление утверждений) В случае, когда необходимо сделать утверждение об утверждении RDF, прибегают к так
- 27. Пример. В базе данных электронного магазина хранится информация о том, что некий товар ( Т )
- 29. Отметим один важный момент: фиксация только тех утверждений, которые помечены " * ", не означает, что
- 30. полный список классов и свойств RDF/RDFS. Классы RDFS
- 31. Свойства RDFS
- 33. Возможности и ограничения языка RDF (RDF Schema) Сам по себе RDF не является стандартом метаданных, как,
- 34. Недостатки RDF Открытость и расширяемость RDF ведет к тому, что "кто угодно (т.е. любой пользователь RDF)
- 35. Способы представления RDF-описаний Ниже приводится пример двух способов представления RDF графов: в форме XML-документа (часто более
- 36. На этих примерах можно заметить "тяжеловесность" XML-синтаксиса RDF по сравнению с N3-синтаксисом. Но он более удобен
- 37. OWL ( Ontology Web Language ) - это язык, базирующийся на направлении Semantic Web, служащий для
- 38. В качестве своего синтаксиса OWL использует язык XML. Основными элементами языка являются свойства, классы и ограничения.
- 39. Кроме того, на свойства могут накладываться ограничения. Ограничения подразделяются на два вида: глобальные и локальные. К
- 40. Структура OWL-онтологии Любая онтология имеет заголовок и тело. В заголовке содержится информация о самой онтологии (версия,
- 41. Особое место занимают два взаимодополняющих класса - owl:Thing и owl:Nothing. Первый из них является надклассом любого
- 42. Только первый способ определяет именованный класс OWL. Все оставшиеся определяют анонимный класс через ограничение его экстенсионала.
- 43. В OWL определены еще 3 конструкции, комбинируя которые, можно определять более сложные аксиомы классов: rdfs:subClassOf говорит
- 44. Свойства В OWL выделяют две категории свойств: свойства-объекты (или объектные свойства ) и свойства-значения. Первые связывают
- 45. Кроме того, OWL поддерживает следующие конструкции для построения аксиом свойств: Конструкции RDFS: rdfs:subPropertyOf (определяет подсвойство данного
- 46. Индивиды определяются при помощи аксиом индивидов (т.н. фактов ). Рассмотрим два вида фактов: факты членства индивидов
- 47. Аксиомы второго вида необходимы для суждения об идентичности индивидов. Дело в том, что в OWL не
- 49. SPARQL Вероятно, сами по себе языки представления онтологий не были бы так сильно востребованы, если бы
- 50. Где: список_перем - список имен переменных; URI_онтологии - URI-ссылка на онтологию; список_шаблонов - список шаблонов; фильтр
- 51. Проследим за ходом выполнения запроса (имена переменных предваряются знаком " ?") SELECT ?cat ?val FROM WHERE
- 53. Скачать презентацию

RDF
RDF - язык представления информации о ресурсах WWW. В частности, RDF
RDF
RDF - язык представления информации о ресурсах WWW. В частности, RDF

Может оказаться, что в некоторых случаях для управления метаданными достаточно использовать
Может оказаться, что в некоторых случаях для управления метаданными достаточно использовать

Модель данных RDF. RDF-граф
Базовой структурной единицей RDF является коллекция троек (или
Модель данных RDF. RDF-граф
Базовой структурной единицей RDF является коллекция троек (или

Каждая тройка представляет некоторое высказывание, увязывающее S, P и O.
Первые два
Каждая тройка представляет некоторое высказывание, увязывающее S, P и O.
Первые два

Архитектура метаданных в World Wide Web
Документы, метаданные, связи
Когда вы переходите по
Архитектура метаданных в World Wide Web
Документы, метаданные, связи
Когда вы переходите по

Пример 1. Метаданные.
Объект, извлеченный из сети по протоколу HTTP, может иметь
Пример 1. Метаданные.
Объект, извлеченный из сети по протоколу HTTP, может иметь

А1. Метаданные - это данные (другими словами, информация об информации -
А1. Метаданные - это данные (другими словами, информация об информации -

А2. Архитектура, представляемая метаданными, является набором независимых высказываний (утверждений).
Как следствие, при
А2. Архитектура, представляемая метаданными, является набором независимых высказываний (утверждений).
Как следствие, при

ресурс - это объект, о котором фиксируется высказывание, атрибут - некоторое
ресурс - это объект, о котором фиксируется высказывание, атрибут - некоторое

Cвязи
Отношение между двумя ресурсами будем называть связью. Связь представляется тройкой (A
Cвязи
Отношение между двумя ресурсами будем называть связью. Связь представляется тройкой (A

RDF-литералы (или символьные константы)
RDF-литералы бывают двух видов: типизированные и нетипизированные.
Каждый литерал
RDF-литералы (или символьные константы)
RDF-литералы бывают двух видов: типизированные и нетипизированные.
Каждый литерал

Замечание. Язык литерала не нужно путать с идентификатором (языком) локали. Язык
Замечание. Язык литерала не нужно путать с идентификатором (языком) локали. Язык

Сравнение литералов
Два литерала равны тогда и только тогда, когда выполняются все
Сравнение литералов
Два литерала равны тогда и только тогда, когда выполняются все

Определение значения типизированного литерала
Рассмотрим следующий пример. Пусть множество {T, F} -
Определение значения типизированного литерала
Рассмотрим следующий пример. Пусть множество {T, F} -

Языки представления онтологий: RDFS, OWL. Язык запросов SPARQL
Для того чтобы реализовывать
Языки представления онтологий: RDFS, OWL. Язык запросов SPARQL
Для того чтобы реализовывать
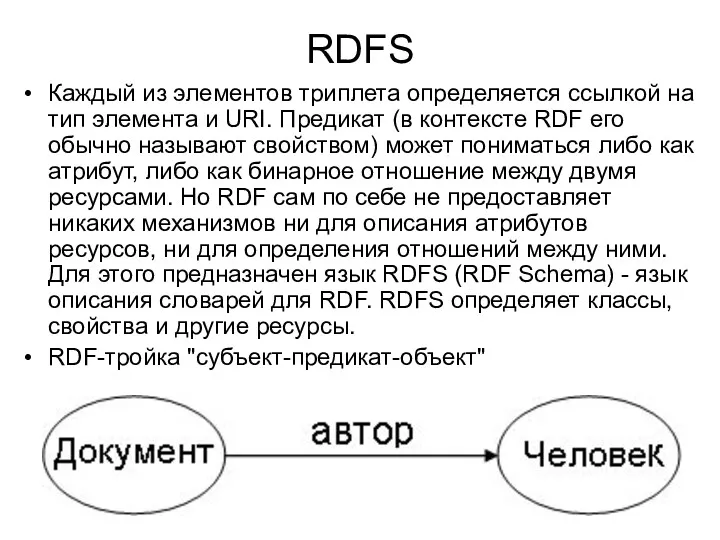
RDFS
Каждый из элементов триплета определяется ссылкой на тип элемента и URI.
RDFS
Каждый из элементов триплета определяется ссылкой на тип элемента и URI.

RDFS является семантическим расширением RDF. Он предоставляет механизмы для описания групп
RDFS является семантическим расширением RDF. Он предоставляет механизмы для описания групп

Система классов и свойств языка описания RDF-словарей похожа на систему типов
Система классов и свойств языка описания RDF-словарей похожа на систему типов

Пример. Определим свойство "автор" с доменом "Документ" и диапазоном "Человек". В
Пример. Определим свойство "автор" с доменом "Документ" и диапазоном "Человек". В

Основное преимущество такого подхода - в легкой расширяемости: добавление/удаление свойств интуитивно
Основное преимущество такого подхода - в легкой расширяемости: добавление/удаление свойств интуитивно

Классы
Ресурсы могут объединяться в группы, называемые классами. Члены класса (здесь наиболее
Классы
Ресурсы могут объединяться в группы, называемые классами. Члены класса (здесь наиболее

Экстенсионал и интенсионал
Рассмотрим множества
A = {0, 2, 4, 6, 8},
B
Экстенсионал и интенсионал
Рассмотрим множества
A = {0, 2, 4, 6, 8},
B

Парадокс Рассела (иногда парадокс Рассела — Цермело)
открытый в 1901 году[1] Бертраном
Парадокс Рассела (иногда парадокс Рассела — Цермело)
открытый в 1901 году[1] Бертраном

Группа ресурсов, являющихся классами, в RDFS описывается термином rdfs:Class.
На множестве классов
Группа ресурсов, являющихся классами, в RDFS описывается термином rdfs:Class.
На множестве классов

Реификация (материализация, овеществление утверждений)
В случае, когда необходимо сделать утверждение об утверждении
Реификация (материализация, овеществление утверждений)
В случае, когда необходимо сделать утверждение об утверждении

Пример. В базе данных электронного магазина хранится информация о том, что
Пример. В базе данных электронного магазина хранится информация о том, что
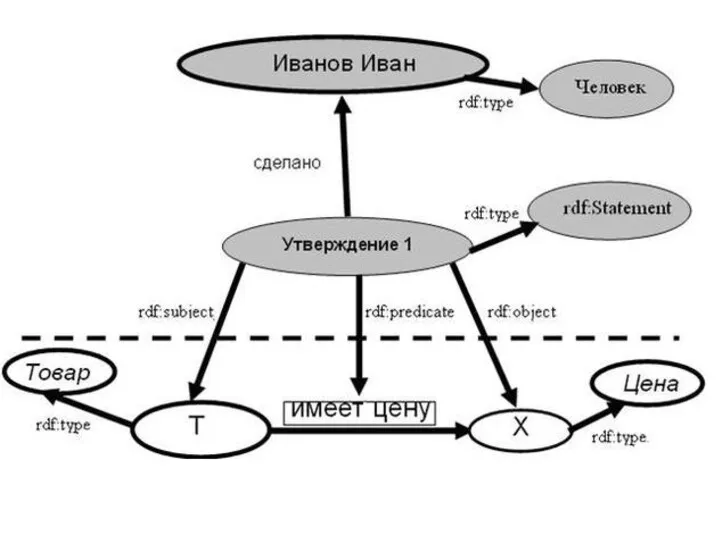

Отметим один важный момент: фиксация только тех утверждений, которые помечены "
Отметим один важный момент: фиксация только тех утверждений, которые помечены "
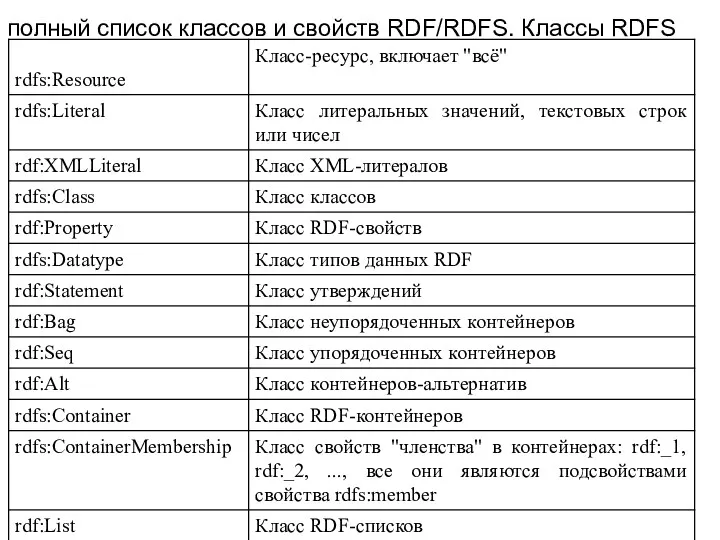
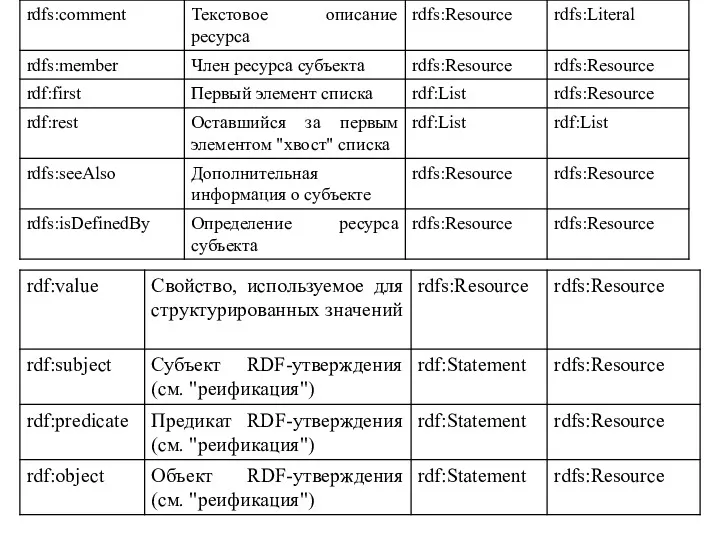
полный список классов и свойств RDF/RDFS. Классы RDFS
полный список классов и свойств RDF/RDFS. Классы RDFS
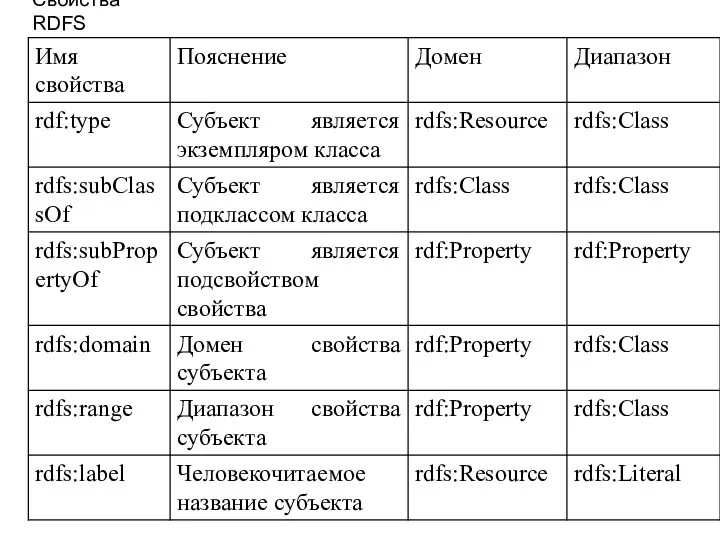
Свойства RDFS
Свойства RDFS

Возможности и ограничения языка RDF (RDF Schema)
Сам по себе RDF не
Возможности и ограничения языка RDF (RDF Schema)
Сам по себе RDF не

Недостатки RDF
Открытость и расширяемость RDF ведет к тому, что "кто угодно
Недостатки RDF
Открытость и расширяемость RDF ведет к тому, что "кто угодно

Способы представления RDF-описаний
Ниже приводится пример двух способов представления RDF графов: в
Способы представления RDF-описаний
Ниже приводится пример двух способов представления RDF графов: в

На этих примерах можно заметить "тяжеловесность" XML-синтаксиса RDF по сравнению с
На этих примерах можно заметить "тяжеловесность" XML-синтаксиса RDF по сравнению с

OWL ( Ontology Web Language ) - это язык, базирующийся на
OWL ( Ontology Web Language ) - это язык, базирующийся на

В качестве своего синтаксиса OWL использует язык XML. Основными элементами языка
В качестве своего синтаксиса OWL использует язык XML. Основными элементами языка

Кроме того, на свойства могут накладываться ограничения. Ограничения подразделяются на два
Кроме того, на свойства могут накладываться ограничения. Ограничения подразделяются на два

Структура OWL-онтологии
Любая онтология имеет заголовок и тело. В заголовке содержится информация
Структура OWL-онтологии
Любая онтология имеет заголовок и тело. В заголовке содержится информация

Особое место занимают два взаимодополняющих класса - owl:Thing и owl:Nothing. Первый
Особое место занимают два взаимодополняющих класса - owl:Thing и owl:Nothing. Первый

Только первый способ определяет именованный класс OWL. Все оставшиеся определяют анонимный
Только первый способ определяет именованный класс OWL. Все оставшиеся определяют анонимный

В OWL определены еще 3 конструкции, комбинируя которые, можно определять более
В OWL определены еще 3 конструкции, комбинируя которые, можно определять более

Свойства
В OWL выделяют две категории свойств: свойства-объекты (или объектные свойства )
Свойства
В OWL выделяют две категории свойств: свойства-объекты (или объектные свойства )

Кроме того, OWL поддерживает следующие конструкции для построения аксиом свойств:
Конструкции RDFS:
Кроме того, OWL поддерживает следующие конструкции для построения аксиом свойств:
Конструкции RDFS:

Индивиды определяются при помощи аксиом индивидов (т.н. фактов ). Рассмотрим два
Индивиды определяются при помощи аксиом индивидов (т.н. фактов ). Рассмотрим два

Аксиомы второго вида необходимы для суждения об идентичности индивидов. Дело в
Аксиомы второго вида необходимы для суждения об идентичности индивидов. Дело в
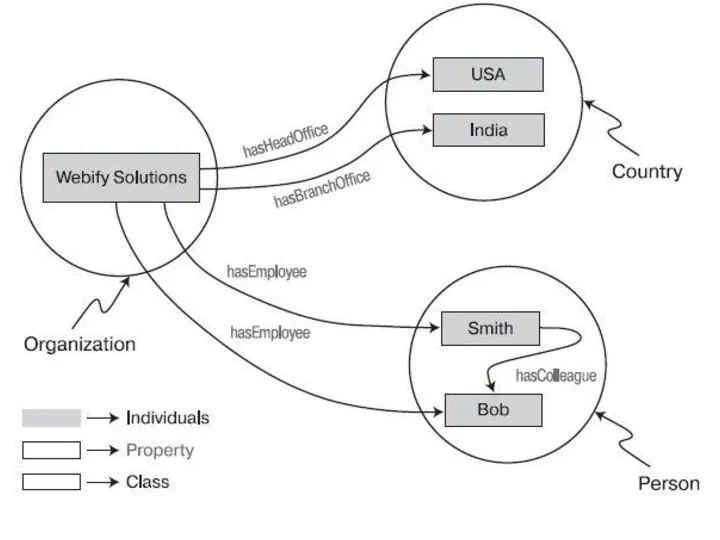

SPARQL
Вероятно, сами по себе языки представления онтологий не были бы так
SPARQL
Вероятно, сами по себе языки представления онтологий не были бы так

Где: список_перем - список имен переменных; URI_онтологии - URI-ссылка на онтологию;
Где: список_перем - список имен переменных; URI_онтологии - URI-ссылка на онтологию;

Проследим за ходом выполнения запроса (имена переменных предваряются знаком " ?")
SELECT
Проследим за ходом выполнения запроса (имена переменных предваряются знаком " ?")
SELECT
 Отладка кода в среде разработки Visual Studio
Отладка кода в среде разработки Visual Studio Штриховой код - штрих-ко́д
Штриховой код - штрих-ко́д Лабораторная работа №5. Основы DipTrace: Подготовка платы к трассировке
Лабораторная работа №5. Основы DipTrace: Подготовка платы к трассировке Электронные российские учебники
Электронные российские учебники Текстовый редактор Microsoft Word. Основные возможности и назначение
Текстовый редактор Microsoft Word. Основные возможности и назначение Что такое сайт
Что такое сайт Построение диаграмм и графиков в электронных таблицах
Построение диаграмм и графиков в электронных таблицах Page Cache
Page Cache Локальные и глобальные компьютерные сети
Локальные и глобальные компьютерные сети Презентация урока по информатике Конъюнция и Дизъюнкция
Презентация урока по информатике Конъюнция и Дизъюнкция Оборудование, формат кадров, топология сетей SDH
Оборудование, формат кадров, топология сетей SDH Модульное программирование
Модульное программирование Основные команды и директивы ATmega16 (продолжение)
Основные команды и директивы ATmega16 (продолжение) Профессии, в которых необходимы знания по работе с графическими редакторами
Профессии, в которых необходимы знания по работе с графическими редакторами Персональный компьютер как система
Персональный компьютер как система Циклы с тактированием. Изоляция [c]FP. Интеграция [c]FP в системы SCADA
Циклы с тактированием. Изоляция [c]FP. Интеграция [c]FP в системы SCADA Компоненты сетей и модель OSI
Компоненты сетей и модель OSI Понятие информации. Информационные процессы
Понятие информации. Информационные процессы Комп'ютерні віруси і антивірусні програми
Комп'ютерні віруси і антивірусні програми Основы языка программирования. Объекты, классы, методы. Лекция 5.1
Основы языка программирования. Объекты, классы, методы. Лекция 5.1 Представление игр серии TotalWar
Представление игр серии TotalWar Основы языка HTML
Основы языка HTML Интернет-протоколы
Интернет-протоколы Информатика и информация
Информатика и информация ГИС технологии в современной картографии
ГИС технологии в современной картографии Разработка Веб - сайта по продаже цветов
Разработка Веб - сайта по продаже цветов Основные понятия и определения компьютерной графики. Виды компьютерной графики
Основные понятия и определения компьютерной графики. Виды компьютерной графики Fierycut. Фигурный раскрой листового материала в autocad
Fierycut. Фигурный раскрой листового материала в autocad