- OpenMP. Параллельное программирование для многоядерных систем

Содержание
- 2. Концепция OpenMP Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем с общей памятью
- 3. Положительные качества OpenMP Поэтапное распараллеливание Можно распараллеливать последовательные программы поэтапно, не меняя их структуру Единственность разрабатываемого
- 4. Принципы организации параллелизма Использование потоков на общем адресном пространстве Пульсирующий (fork-join) параллелизм
- 5. Принципы организации параллелизма При выполнении обычного кода (вне параллельных областей) программа исполняется одним потоком (master thread)
- 6. Когда следует использовать технологию Open MP Целевая платформа является многопроцессорной или многоядерной Выполнение циклов нужно распараллелить
- 7. Когда эффективно использовать технологию Open MP Параллельная версия настигает по быстродействию последовательную или при большом количестве
- 8. Настройки компилятора Microsoft Visual Studio Project ? ?Property Pages ? C/C++ ? Language ?OpenMP Support ?Yes
- 9. Средства openMP Категории: Функции времени выполнения Функции инициализации/завершения Переменные среды окружения Параллельные регионы Распределение работ и
- 10. Структура программы #include int main(){ // по умолчанию кол-во потоков: int numTh = omp_get_num_threads(); // сами
- 11. Простейшая программа #include #include int main (int argc, char * argv[]) { #pragma omp parallel {
- 12. Простейшая программа – результат работы
- 13. Простейшие директивы OpenMP #pragma omp parallel { } // выполнится столько раз, сколько потоков #pragma omp
- 14. Ограничения на оператор for OpenMP 1. Переменная цикла должна иметь тип integer. 2. Цикл должен являться
- 15. Пример 1 #pragma omp parallel num_threads(2) for (int i = 0; i myFunc(); // при запуске
- 16. Пример 1-а (parallel без указания количества потоков) #pragma omp parallel for (int i = 0; i
- 17. Пример 2 (ошибка!) #pragma omp parallel num_threads(2) { ... // N строк кода #pragma omp parallel
- 18. Пример 2 - правильно #pragma omp parallel num_threads(2) { ... // N строк кода #pragma omp
- 19. Ограничение на переопределение количества потоков Количество потоков нельзя переопределять внутри параллельной секции. Это приводит к ошибкам
- 20. Планирование и разбиение циклов Static scheduling – цикл делится на фрагменты одинакового размера Dynamic scheduling –
- 21. Планирование и разбиение циклов (Static scheduling - пример работы) int s; #pragma omp parallel for private
- 22. Планирование и разбиение циклов (Static scheduling - пример работы)
- 23. Планирование и разбиение циклов (Dinamic scheduling - пример работы) int s; #pragma omp parallel for private
- 24. Планирование и разбиение циклов Dinamic scheduling - пример работы schedule(dynamic, 2)
- 25. Планирование и разбиение циклов Dinamic scheduling - пример работы schedule(dynamic, 1)
- 26. Dinamic scheduling - пример работы для быстрых операций во втором потоке и медленных в первом
- 27. Вывод данных в консоль в параллельных потоках - операция ОЧЕНЬ опасная!!! Операция вывода строки на экран
- 28. Вывод данных в консоль в параллельных потоках надо оградить блокировкой #pragma omp parallel num_threads(2) { #pragma
- 29. Гонки данных Незащищенный доступ к общей памяти double data; #pragma omp parallel for for (int i
- 30. ПРИЧИНА: все глобальные переменные в OpenMP считаются shared по умолчанию/ РЕШЕНИЕ (первый вариант): просто объявлять соответствующие
- 31. Приватные переменные - метод борьбы с гонками данных double data; #pragma omp parallel for for (int
- 32. Локальные переменные становятся приватными – первый вариант решения // double data; // удалили внешнее объявление! #pragma
- 33. Явно указанные приватные переменные – решение, эквивалентное по результату double data; #pragma omp parallel for private(data)
- 34. Приватные переменные – возможные ошибки 1. При входе в поток для переменных, являющиеся параметрами выражений private,
- 35. Приватные переменные – ограничения Переменная в выражении private не должна иметь ссылочный тип. Причина ограничения очевидна
- 36. Правила разделения переменных (1) Неявное правило 1: Все переменные, определенные вне omp parallel, являются глобальными для
- 37. Правила разделения переменных (2) Явное правило 1: Переменные, приведенные в shared(), являются глобальными для всех потоков
- 38. Параллельные секции #pragma omp parallel sections // создан параллельный регион секций { #pragma omp section #pragma
- 39. Параллельные секции Директива sections – распределение вычислений для раздельных фрагментов кода Фрагменты выделяются при помощи директивы
- 40. Редукции в циклах int sum =0; #pragma omp parallel for reduction (+ sum) { for (int
- 41. Редукции в циклах Параметр reduction определяет список переменных, для которых выполняется операция редукции перед выполнением параллельной
- 42. Барьеры int sum =0; #pragma omp parallel for reduction (+ sum) { for (int i=0; i
- 43. Барьеры и nowait В некоторых случаях возникает потребность отключать синхронизацию, Для этого существует оператор nowait Это
- 44. Барьеры и nowait #pragma omp parallel { #pragma omp for nowait for(int i = 0; i
- 45. Барьеры и nowait В рассмотренном примере потоки, которые освободились после обработки первого цикла, переходят к обработке
- 46. Критические секции С помощью критических разделов можно предотвратить одновременный доступ к одному сегменту кода из нескольких
- 47. Критические секции Применение критических секций там, где они не нужны, нежелательно : из-за критических секций потокам
- 48. Выполнение в одном потоке внутри параллельного фрагмента #pragma omp parallel num_threads(4) { … // что-то выполняем
- 49. Выполнение в одном потоке внутри параллельного фрагмента Потоков 4, но сообщение выдано только одним потоком !
- 50. Два базовых типа конструкций OpenMP Директивы #pragma Функции исполняющей среды OpenMP Функции OpenMP служат в основном
- 51. Прагмы синхронизации #pragma omp single – исполняет следующую команду только с помощью одного (случайного) потока #pragma
- 52. Критическая секция #pragma omp parallel for schedule(static) for (int i = 0; i PerformSomeComputation(i); // внутри
- 53. Критическая секция Избежать ситуацию возникновения гонки за ресурсами позволяет использование критических секций: void PerformSomeComputation(int i) {
- 54. Критическая секция #pragma omp critical позволяет только одному потоку выполнить операцию даже внутри параллельного фрагмента int
- 55. Библиотека функций void omp_set_num_threads(int numThreads) Позволяет назначить максимальное число потоков для использования в следующей параллельной области
- 56. Библиотека функций int omp_get_max_threads() Возвращает максимальное число потоков int omp_get_num_threads() Возвращает фактическое число потоков в параллельной
- 57. Библиотека функций int omp_get_thread_num() Возвращает номер потока int omp_get_num_procs() Возвращает число процессоров, доступных приложению
- 58. Библиотека функций int omp_in_parallel() Возвращает true, если вызвана из параллельной области программы
- 59. Библиотека функций Блокировки omp_lock_t myLock; omp_init_lock( &myLock ); omp_set_lock( &myLock ); omp_unset_lock( &myLock ); omp_test_lock (
- 60. Правильный код блокировки omp_lock_t myLock; omp_init_lock(&myLock); #pragma omp parallel sections { #pragma omp section { ...
- 62. Скачать презентацию
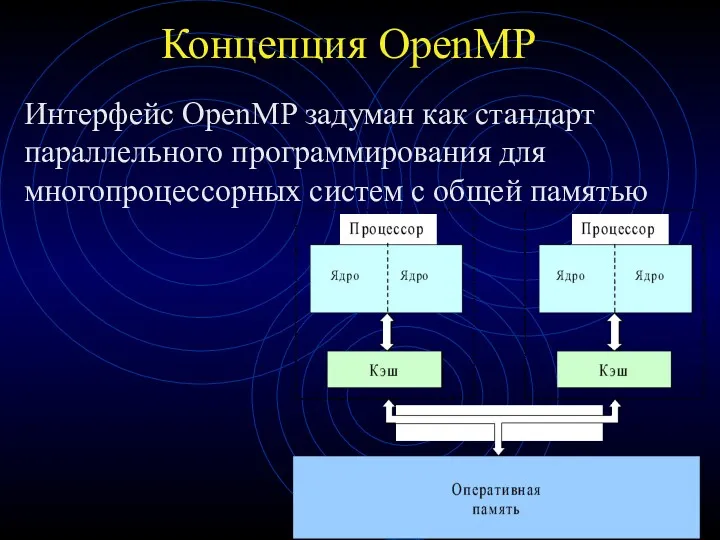
Концепция OpenMP
Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем
Концепция OpenMP
Интерфейс OpenMP задуман как стандарт параллельного программирования для многопроцессорных систем

Положительные качества OpenMP
Поэтапное распараллеливание
Можно распараллеливать последовательные программы поэтапно, не меняя их
Положительные качества OpenMP
Поэтапное распараллеливание
Можно распараллеливать последовательные программы поэтапно, не меняя их
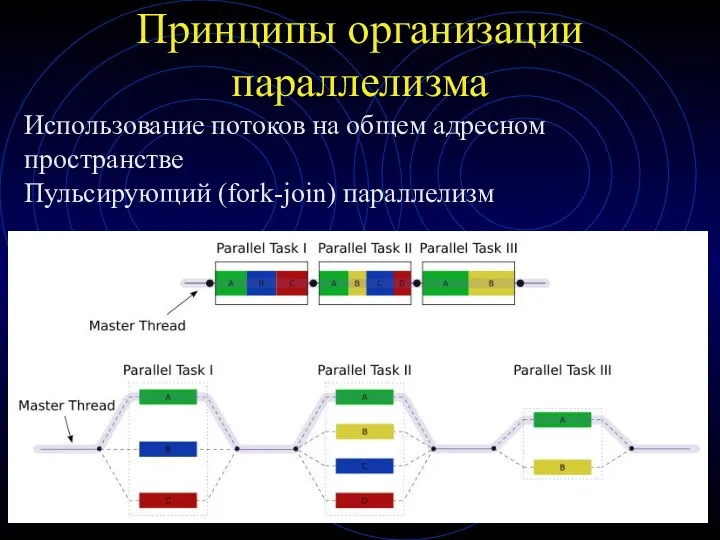
Принципы организации параллелизма
Использование потоков на общем адресном пространстве
Пульсирующий (fork-join) параллелизм
Принципы организации параллелизма
Использование потоков на общем адресном пространстве
Пульсирующий (fork-join) параллелизм

Принципы организации параллелизма
При выполнении обычного кода (вне параллельных областей) программа исполняется
Принципы организации параллелизма
При выполнении обычного кода (вне параллельных областей) программа исполняется

Когда следует использовать технологию Open MP
Целевая платформа является многопроцессорной или
Когда следует использовать технологию Open MP
Целевая платформа является многопроцессорной или

Когда эффективно использовать технологию Open MP
Параллельная версия настигает по быстродействию последовательную
Когда эффективно использовать технологию Open MP
Параллельная версия настигает по быстродействию последовательную

Настройки компилятора
Microsoft Visual Studio
Project ?
?Property Pages
? C/C++
? Language
?OpenMP Support
?Yes
Настройки компилятора
Microsoft Visual Studio
Project ?
?Property Pages
? C/C++
? Language
?OpenMP Support
?Yes

Средства openMP
Категории:
Функции времени выполнения
Функции инициализации/завершения
Переменные среды окружения
Параллельные регионы
Распределение работ и диспетчеризация
Синхронизация
Средства openMP
Категории:
Функции времени выполнения
Функции инициализации/завершения
Переменные среды окружения
Параллельные регионы
Распределение работ и диспетчеризация
Синхронизация

Структура программы
#include
int main(){
// по умолчанию кол-во потоков:
int numTh
Структура программы
#include
int main(){
// по умолчанию кол-во потоков:
int numTh

Простейшая программа
#include
#include
int main (int argc, char * argv[]) {
Простейшая программа
#include
#include
int main (int argc, char * argv[]) {
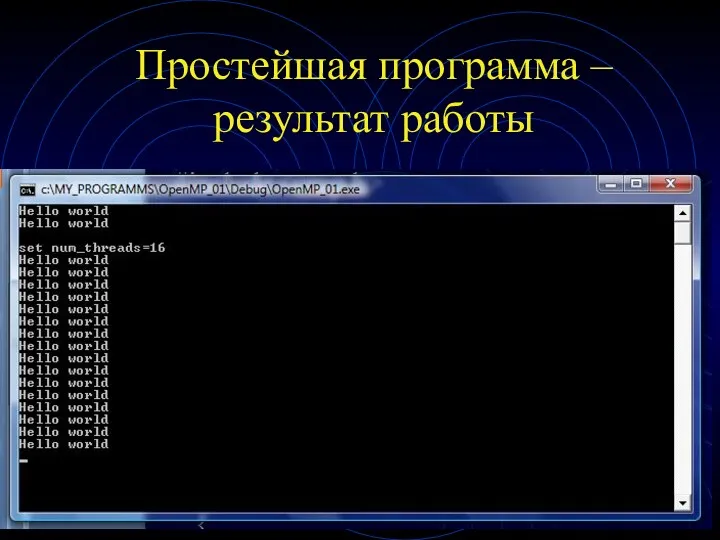
Простейшая программа – результат работы
Простейшая программа – результат работы

Простейшие директивы OpenMP
#pragma omp parallel
{
<код>
}
// выполнится столько раз, сколько потоков
#pragma
Простейшие директивы OpenMP
#pragma omp parallel
{
<код>
}
// выполнится столько раз, сколько потоков
#pragma

Ограничения на оператор for OpenMP
1. Переменная цикла должна иметь тип integer.
Ограничения на оператор for OpenMP
1. Переменная цикла должна иметь тип integer.

Пример 1
#pragma omp parallel num_threads(2)
for (int i = 0; i <
Пример 1
#pragma omp parallel num_threads(2)
for (int i = 0; i <

Пример 1-а (parallel без указания количества потоков)
#pragma omp parallel
for (int i
Пример 1-а (parallel без указания количества потоков)
#pragma omp parallel
for (int i

Пример 2 (ошибка!)
#pragma omp parallel num_threads(2)
{
... // N строк кода
#pragma omp
Пример 2 (ошибка!)
#pragma omp parallel num_threads(2)
{
... // N строк кода
#pragma omp

Пример 2 - правильно
#pragma omp parallel num_threads(2)
{
... // N строк кода
#pragma
Пример 2 - правильно
#pragma omp parallel num_threads(2)
{
... // N строк кода
#pragma

Ограничение на переопределение количества потоков
Количество потоков нельзя переопределять внутри параллельной секции.
Ограничение на переопределение количества потоков
Количество потоков нельзя переопределять внутри параллельной секции.

Планирование и разбиение циклов
Static scheduling – цикл делится на фрагменты
одинакового
Планирование и разбиение циклов
Static scheduling – цикл делится на фрагменты
одинакового

Планирование и разбиение циклов
(Static scheduling - пример работы)
int s;
#pragma omp parallel
Планирование и разбиение циклов
(Static scheduling - пример работы)
int s;
#pragma omp parallel
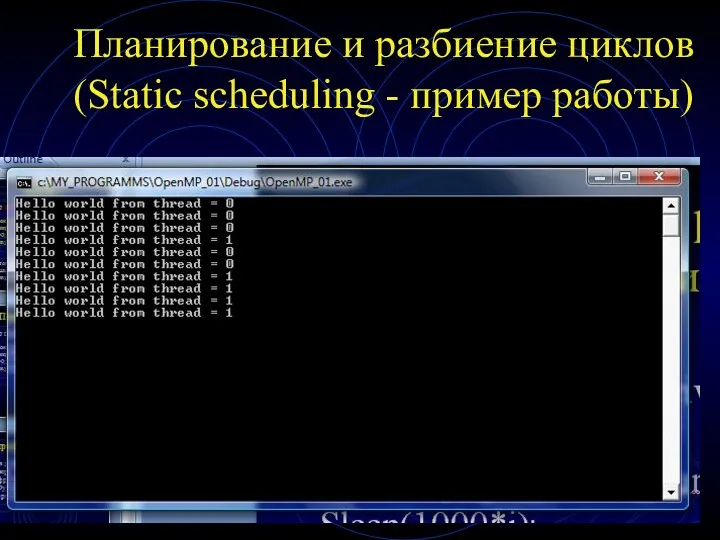
Планирование и разбиение циклов
(Static scheduling - пример работы)
Планирование и разбиение циклов
(Static scheduling - пример работы)

Планирование и разбиение циклов
(Dinamic scheduling - пример работы)
int s;
#pragma omp parallel
Планирование и разбиение циклов
(Dinamic scheduling - пример работы)
int s;
#pragma omp parallel
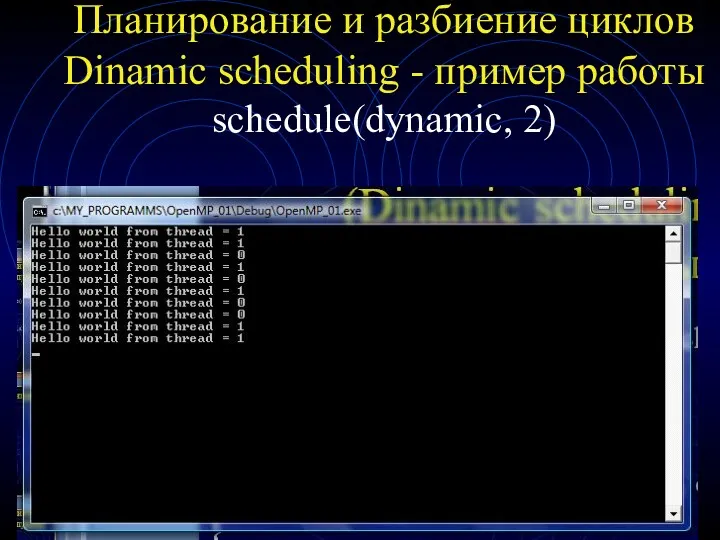
Планирование и разбиение циклов
Dinamic scheduling - пример работы schedule(dynamic, 2)
Планирование и разбиение циклов
Dinamic scheduling - пример работы schedule(dynamic, 2)
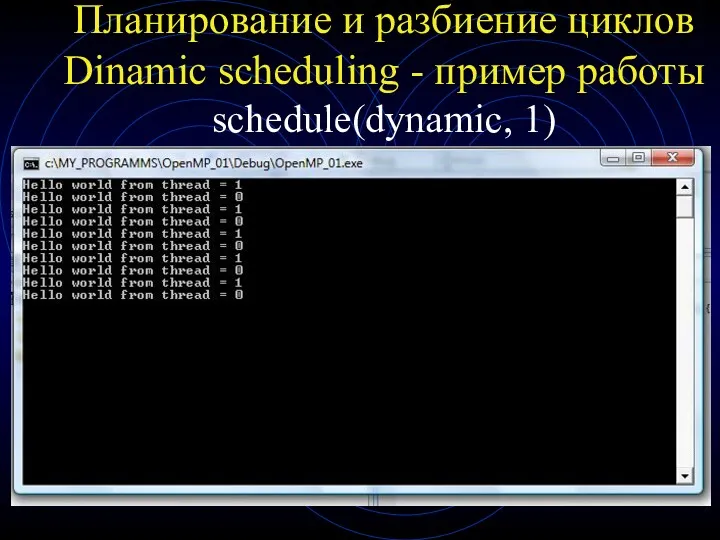
Планирование и разбиение циклов
Dinamic scheduling - пример работы schedule(dynamic, 1)
Планирование и разбиение циклов
Dinamic scheduling - пример работы schedule(dynamic, 1)
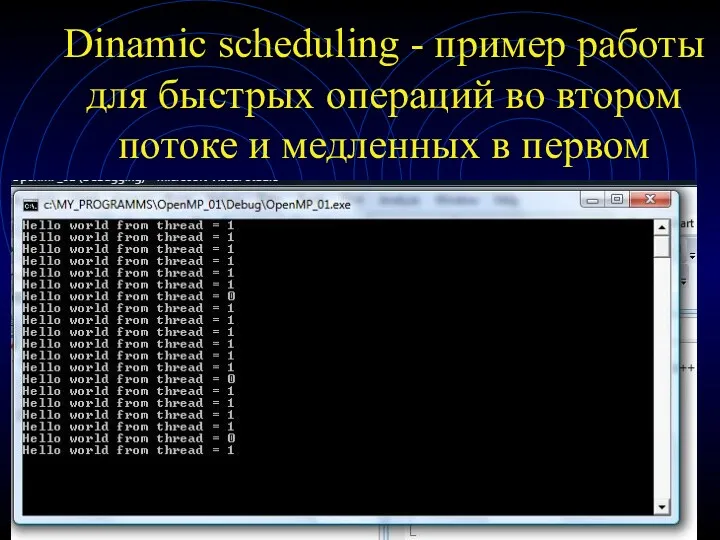
Dinamic scheduling - пример работы для быстрых операций во втором потоке
Dinamic scheduling - пример работы для быстрых операций во втором потоке

Вывод данных в консоль в параллельных потоках
- операция ОЧЕНЬ опасная!!!
Операция
Вывод данных в консоль в параллельных потоках - операция ОЧЕНЬ опасная!!! Операция

Вывод данных в консоль в параллельных потоках
надо оградить блокировкой
#pragma
Вывод данных в консоль в параллельных потоках
надо оградить блокировкой
#pragma

Гонки данных
Незащищенный доступ к общей памяти
double data;
#pragma omp parallel for
Гонки данных
Незащищенный доступ к общей памяти
double data;
#pragma omp parallel for

ПРИЧИНА:
все глобальные переменные в OpenMP
считаются shared по умолчанию/
РЕШЕНИЕ (первый вариант):
просто
ПРИЧИНА:
все глобальные переменные в OpenMP
считаются shared по умолчанию/
РЕШЕНИЕ (первый вариант):
просто

Приватные переменные
- метод борьбы с гонками данных
double data;
#pragma omp parallel for
Приватные переменные
- метод борьбы с гонками данных
double data;
#pragma omp parallel for

Локальные переменные становятся приватными –
первый вариант решения
// double data; //
Локальные переменные становятся приватными –
первый вариант решения
// double data; //

Явно указанные приватные переменные –
решение, эквивалентное по результату
double data;
#pragma omp
Явно указанные приватные переменные –
решение, эквивалентное по результату
double data;
#pragma omp

Приватные переменные –
возможные ошибки
1. При входе в поток для переменных,
Приватные переменные –
возможные ошибки
1. При входе в поток для переменных,

Приватные переменные –
ограничения
Переменная в выражении private не должна иметь ссылочный
Приватные переменные –
ограничения
Переменная в выражении private не должна иметь ссылочный

Правила разделения переменных (1)
Неявное правило 1: Все переменные, определенные вне omp
Правила разделения переменных (1)
Неявное правило 1: Все переменные, определенные вне omp

Правила разделения переменных (2)
Явное правило 1: Переменные, приведенные в shared(), являются
Правила разделения переменных (2)
Явное правило 1: Переменные, приведенные в shared(), являются

Параллельные секции
#pragma omp parallel sections
// создан параллельный регион секций
{
#pragma omp section
<код>
#pragma
Параллельные секции
#pragma omp parallel sections
// создан параллельный регион секций
{
#pragma omp section
<код>
#pragma

Параллельные секции
Директива sections – распределение вычислений для раздельных фрагментов кода
Параллельные секции
Директива sections – распределение вычислений для раздельных фрагментов кода

Редукции в циклах
int sum =0;
#pragma omp parallel for reduction (+ sum)
{
for
Редукции в циклах
int sum =0;
#pragma omp parallel for reduction (+ sum)
{
for

Редукции в циклах
Параметр reduction определяет список переменных, для которых выполняется операция
Редукции в циклах
Параметр reduction определяет список переменных, для которых выполняется операция

Барьеры
int sum =0;
#pragma omp parallel for reduction (+ sum)
{
for (int i=0;
Барьеры
int sum =0;
#pragma omp parallel for reduction (+ sum)
{
for (int i=0;

Барьеры и nowait
В некоторых случаях возникает потребность отключать синхронизацию,
Для этого
Барьеры и nowait
В некоторых случаях возникает потребность отключать синхронизацию,
Для этого

Барьеры и nowait
#pragma omp parallel
{
#pragma omp for nowait
for(int i =
Барьеры и nowait
#pragma omp parallel { #pragma omp for nowait for(int i =

Барьеры и nowait
В рассмотренном примере потоки, которые освободились после обработки первого
Барьеры и nowait
В рассмотренном примере потоки, которые освободились после обработки первого

Критические секции
С помощью критических разделов можно предотвратить одновременный доступ к одному
Критические секции
С помощью критических разделов можно предотвратить одновременный доступ к одному

Критические секции
Применение критических секций там, где они не нужны, нежелательно
Критические секции
Применение критических секций там, где они не нужны, нежелательно

Выполнение в одном потоке внутри параллельного фрагмента
#pragma omp parallel num_threads(4)
Выполнение в одном потоке внутри параллельного фрагмента
#pragma omp parallel num_threads(4)
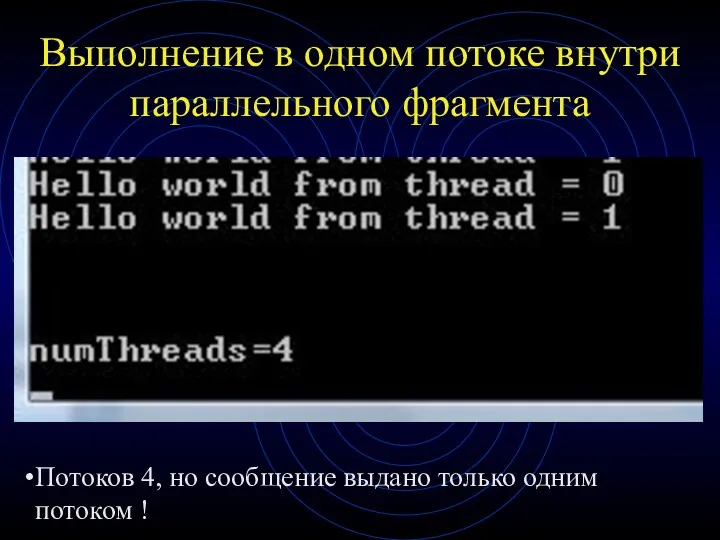
Выполнение в одном потоке внутри параллельного фрагмента
Потоков 4, но сообщение выдано
Выполнение в одном потоке внутри параллельного фрагмента
Потоков 4, но сообщение выдано

Два базовых типа конструкций OpenMP
Директивы #pragma
Функции исполняющей среды
Два базовых типа конструкций OpenMP
Директивы #pragma
Функции исполняющей среды

Прагмы синхронизации
#pragma omp single – исполняет следующую команду только с помощью
Прагмы синхронизации
#pragma omp single – исполняет следующую команду только с помощью

Критическая секция
#pragma omp parallel for schedule(static)
for (int i = 0; i
Критическая секция
#pragma omp parallel for schedule(static)
for (int i = 0; i

Критическая секция
Избежать ситуацию возникновения гонки за ресурсами позволяет использование критических секций:
void
Критическая секция
Избежать ситуацию возникновения гонки за ресурсами позволяет использование критических секций:
void

Критическая секция
#pragma omp critical позволяет только одному потоку выполнить операцию даже
Критическая секция
#pragma omp critical позволяет только одному потоку выполнить операцию даже

Библиотека функций
void omp_set_num_threads(int numThreads)
Позволяет назначить максимальное число потоков для использования в
Библиотека функций
void omp_set_num_threads(int numThreads)
Позволяет назначить максимальное число потоков для использования в

Библиотека функций
int omp_get_max_threads()
Возвращает максимальное число потоков
int omp_get_num_threads()
Возвращает фактическое число потоков в
Библиотека функций
int omp_get_max_threads()
Возвращает максимальное число потоков
int omp_get_num_threads()
Возвращает фактическое число потоков в

Библиотека функций
int omp_get_thread_num()
Возвращает номер потока
int omp_get_num_procs()
Возвращает число процессоров, доступных приложению
Библиотека функций
int omp_get_thread_num()
Возвращает номер потока
int omp_get_num_procs()
Возвращает число процессоров, доступных приложению

Библиотека функций
int omp_in_parallel()
Возвращает true, если вызвана из параллельной области программы
Библиотека функций
int omp_in_parallel()
Возвращает true, если вызвана из параллельной области программы

Библиотека функций
Блокировки
omp_lock_t myLock;
omp_init_lock( &myLock );
omp_set_lock( &myLock );
omp_unset_lock(
Библиотека функций
Блокировки
omp_lock_t myLock;
omp_init_lock( &myLock );
omp_set_lock( &myLock );
omp_unset_lock(

Правильный код
блокировки
omp_lock_t myLock;
omp_init_lock(&myLock);
#pragma omp parallel sections
{
#pragma omp section
{ ...
omp_set_lock(&myLock); ...
omp_unset_lock(&myLock); ...
}
#pragma omp
Правильный код
блокировки
omp_lock_t myLock;
omp_init_lock(&myLock);
#pragma omp parallel sections
{
#pragma omp section
{ ...
omp_set_lock(&myLock); ...
omp_unset_lock(&myLock); ...
}
#pragma omp
 Algorytmy szeregowe, z rozgałęzieniami, zawierające pętle
Algorytmy szeregowe, z rozgałęzieniami, zawierające pętle Условия выбора и простые логические выражения.
Условия выбора и простые логические выражения. Разработка автоматизированной информационной системы контроля и учета рабочего времени компании
Разработка автоматизированной информационной системы контроля и учета рабочего времени компании Объектно-ориентированное программирование на алгоритмическом языке С++. Схема архитектуры программы Дерево объектов
Объектно-ориентированное программирование на алгоритмическом языке С++. Схема архитектуры программы Дерево объектов Технические средства автоматизации торговли
Технические средства автоматизации торговли Лекция 1 по архитектуре компьютеров. Концепция машины с хранимой в памяти программой
Лекция 1 по архитектуре компьютеров. Концепция машины с хранимой в памяти программой Контроль пропускної здатності корпоративної комп'ютерної мережі засобами NMS моделі ISO
Контроль пропускної здатності корпоративної комп'ютерної мережі засобами NMS моделі ISO Program NN1
Program NN1 План дій, інструкція, команда. Поняття алгоритму. Алгоритми і виконавці. Урок №17
План дій, інструкція, команда. Поняття алгоритму. Алгоритми і виконавці. Урок №17 Характеристика сервисных програм ЭВМ
Характеристика сервисных програм ЭВМ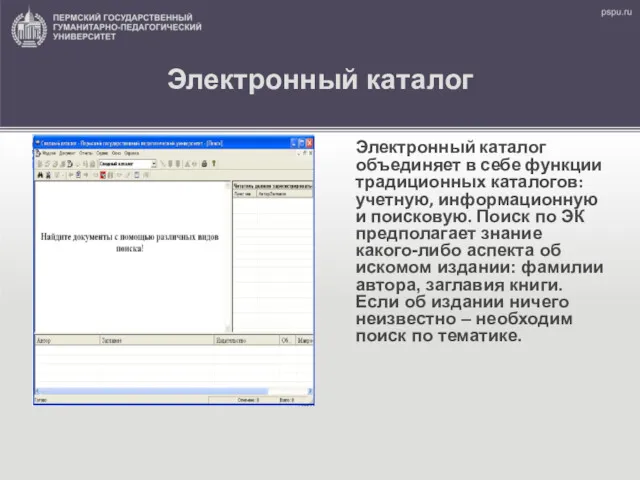 Электронный каталог и Электронная библиотека
Электронный каталог и Электронная библиотека 3D-печать
3D-печать Как вставить презентацию на страницу блога.pptx
Как вставить презентацию на страницу блога.pptx Программирование на языке Паскаль. Введение
Программирование на языке Паскаль. Введение Новая версия сайта https://www.vesk-spb.com/
Новая версия сайта https://www.vesk-spb.com/ Сплайны - работа с элементами объектов. Autodesk 3ds max. Лекция №2
Сплайны - работа с элементами объектов. Autodesk 3ds max. Лекция №2 Развитие информационного общества: перспективные направления исследования
Развитие информационного общества: перспективные направления исследования Урок информатики в 3 классе по теме Свойства объекта
Урок информатики в 3 классе по теме Свойства объекта Віртуальна реальність
Віртуальна реальність Язык запросов SQL
Язык запросов SQL Электронная цифровая подпись (ЭЦП)
Электронная цифровая подпись (ЭЦП) Информация в природе, обществе и технике
Информация в природе, обществе и технике Параллельное программирование с использованием OpenMP. Лекция 1
Параллельное программирование с использованием OpenMP. Лекция 1 Сравнение нотаций ВS с ARIS и BPMN 2022
Сравнение нотаций ВS с ARIS и BPMN 2022 Презентация по теме: Структурное программирование
Презентация по теме: Структурное программирование Метрология. Метрики программного обеспечения
Метрология. Метрики программного обеспечения Технологическая карта со сценарием блог-урока по информатике в 6 классе согласно ФГОС ООО по теме Кодирование текстовой информации
Технологическая карта со сценарием блог-урока по информатике в 6 классе согласно ФГОС ООО по теме Кодирование текстовой информации Информационная безопасность и ее задачи
Информационная безопасность и ее задачи