- Параллельное программирование с использованием OpenMP. Лекция 1

Содержание
- 2. Параллельное программирование с использованием OpenMP
- 3. ОСНОВЫ ПОДХОДА Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2014 г. из 44
- 4. Технология OpenMP для систем с общей памятью Технология OpenMP задумана как стандарт параллельного программирования для многопроцессорных
- 5. Способы разработки программ для параллельных вычислений… Способ 1: автоматическое распараллеливание последовательных программ. возможности автоматического построения параллельных
- 6. Способы разработки программ для параллельных вычислений… Способ 4: использование тех или иных внеязыковых средств языка программирования.
- 7. Способы разработки программ для параллельных вычислений Способ 4: Положительные стороны: Снижает потребность переработки существующего программного кода.
- 8. Принципы организации параллелизма… Использование потоков (общее адресное пространство). «Пульсирующий» (fork-join) параллелизм. *Источник: http://en.wikipedia.org/wiki/OpenMP Параллельное программирование с
- 9. Принципы организации параллелизма При выполнении обычного кода (вне параллельных областей) программа исполняется одним потоком (master thread).
- 10. Структура OpenMP Компоненты: Набор директив компилятора. Библиотека функций. Набор переменных окружения. Изложение материала будет проводиться на
- 11. ДИРЕКТИВЫ OPENMP Формат, области видимости, типы. Директива определения параллельной области. Параллельное программирование с использованием OpenMP Н.
- 12. Формат записи директив… Формат: #pragma omp имя_директивы [параметр,…] Пример: #pragma omp parallel default(shared) private(beta,pi) Примечание: На
- 13. node.cpp void TypeThreadNum() { int num; num = omp_get_thread_num(); #pragma omp critical printf("Hello from %d\n",num); }
- 14. Типы директив Определение параллельной области. Разделение работы. Синхронизация. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ,
- 15. Определение параллельной области Директива parallel (основная директива OpenMP): Когда основной поток выполнения достигает директиву parallel ,
- 16. Формат директивы Формат директивы parallel : #pragma omp parallel [clause ...] structured_block Возможные параметры (clauses): if
- 17. Пример использования директивы… #include void main() { int nthreads, tid; // Создание параллельной области #pragma omp
- 18. Пример использования директивы Hello World from thread = 1 Hello World from thread = 3 Hello
- 19. Установка количества потоков Способы задания (по убыванию старшинства) Параметр директивы: num_threads(N) Функция установки числа потоков: omp_set_num_threads(N)
- 20. Определение времени выполнения параллельной программы Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2014 г. double
- 21. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2014 г. ДИРЕКТИВЫ OPENMP Управление областью видимости данных.
- 22. Директивы управления областью видимости Управление областью видимости обеспечивается при помощи параметров (clauses) директив: shared, default private
- 23. Параметр shared Параметр shared определяет список переменных, которые будут общими для всех потоков параллельной области. #pragma
- 24. Параметр private Параметр private определяет список переменных, которые будут локальными для каждого потока. #pragma omp parallel
- 25. Пример использования директивы private #include void main () { int nthreads, tid; // Создание параллельной области
- 26. Параметр firstprivate Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием инициализируются значениями исходных переменных.
- 27. Параметр lastprivate Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются в исходных переменных после
- 28. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2014 г. ДИРЕКТИВЫ OPENMP Распределение вычислений между потоками
- 29. Директивы распределения вычислений между потоками Существует 3 директивы для распределения вычислений в параллельной области: for –
- 30. Директива for Формат директивы for: #pragma omp for [clause ...] for loop Возможные параметры (clause): private(list)
- 31. Пример использования директивы for #include #define CHUNK 100 #define NMAX 1000 void main() { int i,
- 32. Директива for. Параметр schedule static – итерации делятся на блоки по chunk итераций и статически разделяются
- 33. Пример использования директивы for #include #define CHUNK 100 #define NMAX 1000 void main() { int i,
- 34. Директива sections… Формат директивы sections: #pragma omp sections [clause ...] { #pragma omp section // несколько
- 35. Директива sections Директива sections – распределение вычислений для раздельных фрагментов кода. Фрагменты кода: Выделяются при помощи
- 36. Пример использования директивы sections… #include #define NMAX 1000 void main() { int i, n; float a[NMAX],
- 37. Пример использования директивы sections #pragma omp sections nowait { #pragma omp section for (i=0; i c[i]
- 38. Объединение директив parallel и for/sections #include #define CHUNK 100 #define NMAX 1000 void main () {
- 39. Параллельное программирование с использованием OpenMP Н. Новгород, ННГУ, 2014 г. ДИРЕКТИВЫ OPENMP Операция редукции из 44
- 40. Параметр reduction Параметр reduction определяет список переменных, для которых выполняется операция редукции (объединения). reduction (operator: list)
- 41. Пример использования параметра reduction #include void main() { // vector dot product int i, n, chunk;
- 42. Правила записи параметра reduction Возможный формат записи выражения: x = x op expr x = expr
- 43. Заключение Данная лекция посвящена рассмотрению методов параллельного программирования для вычислительных систем с общей памятью с использованием
- 45. Скачать презентацию

Параллельное программирование с использованием OpenMP
Параллельное программирование с использованием OpenMP

ОСНОВЫ ПОДХОДА
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
из
ОСНОВЫ ПОДХОДА
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
из
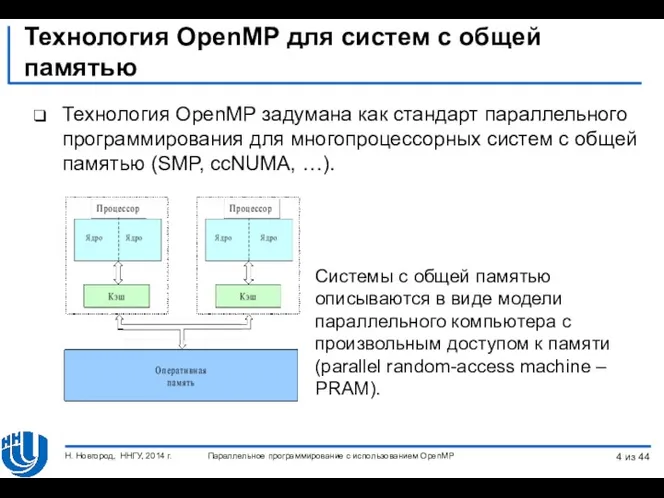
Технология OpenMP для систем с общей памятью
Технология OpenMP задумана как стандарт
Технология OpenMP для систем с общей памятью
Технология OpenMP задумана как стандарт

Способы разработки программ для параллельных вычислений…
Способ 1: автоматическое распараллеливание последовательных программ.
возможности
Способы разработки программ для параллельных вычислений…
Способ 1: автоматическое распараллеливание последовательных программ.
возможности

Способы разработки программ для параллельных вычислений…
Способ 4: использование тех или иных
Способы разработки программ для параллельных вычислений…
Способ 4: использование тех или иных

Способы разработки программ для параллельных вычислений
Способ 4: Положительные стороны:
Снижает потребность переработки
Способы разработки программ для параллельных вычислений
Способ 4: Положительные стороны:
Снижает потребность переработки
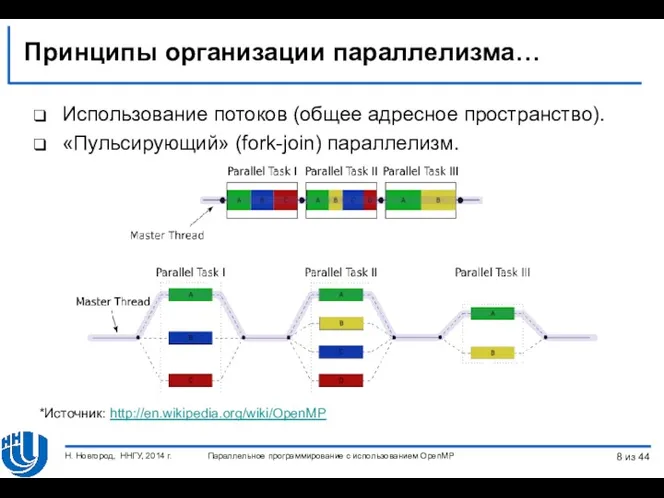
Принципы организации параллелизма…
Использование потоков (общее адресное пространство).
«Пульсирующий» (fork-join) параллелизм.
*Источник: http://en.wikipedia.org/wiki/OpenMP
Параллельное программирование
Принципы организации параллелизма…
Использование потоков (общее адресное пространство).
«Пульсирующий» (fork-join) параллелизм.
*Источник: http://en.wikipedia.org/wiki/OpenMP
Параллельное программирование

Принципы организации параллелизма
При выполнении обычного кода (вне параллельных областей) программа исполняется
Принципы организации параллелизма
При выполнении обычного кода (вне параллельных областей) программа исполняется

Структура OpenMP
Компоненты:
Набор директив компилятора.
Библиотека функций.
Набор переменных окружения.
Изложение материала будет проводиться на
Структура OpenMP
Компоненты:
Набор директив компилятора.
Библиотека функций.
Набор переменных окружения.
Изложение материала будет проводиться на

ДИРЕКТИВЫ OPENMP
Формат, области видимости, типы.
Директива определения параллельной области.
Параллельное программирование с использованием
ДИРЕКТИВЫ OPENMP
Формат, области видимости, типы.
Директива определения параллельной области.
Параллельное программирование с использованием
![Формат записи директив… Формат: #pragma omp имя_директивы [параметр,…] Пример: #pragma](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/168009/slide-11.jpg)
Формат записи директив…
Формат:
#pragma omp имя_директивы [параметр,…]
Пример:
#pragma omp parallel default(shared) private(beta,pi)
Примечание: На
Формат записи директив…
Формат:
#pragma omp имя_директивы [параметр,…]
Пример:
#pragma omp parallel default(shared) private(beta,pi)
Примечание: На
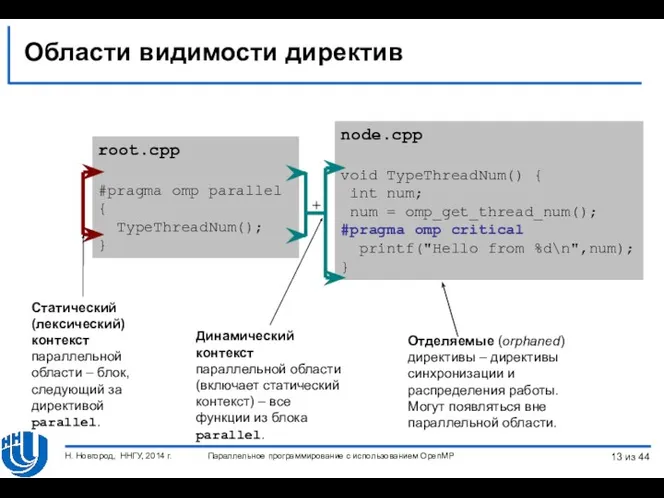
node.cpp
void TypeThreadNum() {
int num;
num = omp_get_thread_num();
#pragma omp critical
printf("Hello
node.cpp
void TypeThreadNum() {
int num;
num = omp_get_thread_num();
#pragma omp critical
printf("Hello

Типы директив
Определение параллельной области.
Разделение работы.
Синхронизация.
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,
Типы директив
Определение параллельной области.
Разделение работы.
Синхронизация.
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,

Определение параллельной области
Директива parallel (основная директива OpenMP):
Когда основной поток выполнения достигает
Определение параллельной области
Директива parallel (основная директива OpenMP):
Когда основной поток выполнения достигает

Формат директивы
Формат директивы parallel :
#pragma omp parallel [clause ...]
structured_block
Возможные параметры
Формат директивы
Формат директивы parallel :
#pragma omp parallel [clause ...]
structured_block
Возможные параметры

Пример использования директивы…
#include
void main() {
int
Пример использования директивы…
#include
void main() {
int

Пример использования директивы
Hello World from thread = 1
Hello World from
Пример использования директивы
Hello World from thread = 1
Hello World from

Установка количества потоков
Способы задания (по убыванию старшинства)
Параметр директивы:
num_threads(N)
Функция установки числа потоков:
Установка количества потоков
Способы задания (по убыванию старшинства)
Параметр директивы:
num_threads(N)
Функция установки числа потоков:

Определение времени выполнения параллельной программы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,
Определение времени выполнения параллельной программы
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ,

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Управление областью
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Управление областью

Директивы управления областью видимости
Управление областью видимости обеспечивается при помощи параметров (clauses)
Директивы управления областью видимости
Управление областью видимости обеспечивается при помощи параметров (clauses)

Параметр shared
Параметр shared определяет список переменных, которые будут общими для всех
Параметр shared
Параметр shared определяет список переменных, которые будут общими для всех

Параметр private
Параметр private определяет список переменных, которые будут локальными для каждого
Параметр private
Параметр private определяет список переменных, которые будут локальными для каждого

Пример использования директивы private
#include
void main () {
Пример использования директивы private
#include
void main () {

Параметр firstprivate
Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием
Параметр firstprivate
Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием

Параметр lastprivate
Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются
Параметр lastprivate
Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Распределение вычислений
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Распределение вычислений

Директивы распределения вычислений между потоками
Существует 3 директивы для распределения вычислений в
Директивы распределения вычислений между потоками
Существует 3 директивы для распределения вычислений в
![Директива for Формат директивы for: #pragma omp for [clause ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/168009/slide-29.jpg)
Директива for
Формат директивы for:
#pragma omp for [clause ...]
for loop
Возможные
Директива for
Формат директивы for:
#pragma omp for [clause ...]
for loop
Возможные

Пример использования директивы for
#include
#define CHUNK 100
Пример использования директивы for
#include
#define CHUNK 100

Директива for. Параметр schedule
static – итерации делятся на блоки по chunk
Директива for. Параметр schedule
static – итерации делятся на блоки по chunk

Пример использования директивы for
#include
#define CHUNK 100
Пример использования директивы for
#include
#define CHUNK 100
![Директива sections… Формат директивы sections: #pragma omp sections [clause ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/168009/slide-33.jpg)
Директива sections…
Формат директивы sections:
#pragma omp sections [clause ...]
{
#pragma
Директива sections…
Формат директивы sections:
#pragma omp sections [clause ...]
{
#pragma

Директива sections
Директива sections – распределение вычислений для раздельных фрагментов кода.
Фрагменты кода:
Выделяются
Директива sections
Директива sections – распределение вычислений для раздельных фрагментов кода.
Фрагменты кода:
Выделяются

Пример использования директивы sections…
#include
#define NMAX 1000
Пример использования директивы sections…
#include
#define NMAX 1000

Пример использования директивы sections
#pragma omp sections nowait
{
Пример использования директивы sections
#pragma omp sections nowait
{

Объединение директив parallel и for/sections
#include
#define CHUNK 100
Объединение директив parallel и for/sections
#include
#define CHUNK 100

Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Операция редукции
Параллельное программирование с использованием OpenMP
Н. Новгород, ННГУ, 2014 г.
ДИРЕКТИВЫ OPENMP
Операция редукции

Параметр reduction
Параметр reduction определяет список переменных, для которых выполняется операция редукции
Параметр reduction
Параметр reduction определяет список переменных, для которых выполняется операция редукции

Пример использования параметра reduction
#include
void main() { //
Пример использования параметра reduction
#include
void main() { //

Правила записи параметра reduction
Возможный формат записи выражения:
x = x op expr
x
Правила записи параметра reduction
Возможный формат записи выражения:
x = x op expr
x

Заключение
Данная лекция посвящена рассмотрению методов параллельного программирования для вычислительных систем с
Заключение
Данная лекция посвящена рассмотрению методов параллельного программирования для вычислительных систем с
 Файлы записей. Структуры данных. Лекция 4
Файлы записей. Структуры данных. Лекция 4 Администрирование информационных систем. Серверы имен. DNS, WINS
Администрирование информационных систем. Серверы имен. DNS, WINS Алгоритмы и исполнители. Основы алгоритмизации
Алгоритмы и исполнители. Основы алгоритмизации Базы данных. Система управления базами данных
Базы данных. Система управления базами данных Растрові моделі даних
Растрові моделі даних Измерение информации. Кодирование информации
Измерение информации. Кодирование информации Основні поняття реляційної моделі даних
Основні поняття реляційної моделі даних Алфавитный подход к измерению количества информации.
Алфавитный подход к измерению количества информации. Кодирование информации
Кодирование информации Виды баз данных
Виды баз данных По мотивам Python Tips, Tricks, and Hacks
По мотивам Python Tips, Tricks, and Hacks Документационное обеспечение управления
Документационное обеспечение управления Система защиты от DDoS атак на основе анализа логов
Система защиты от DDoS атак на основе анализа логов Алгоритми з повторенням і розгалуженням. 7 клас. Урок №11
Алгоритми з повторенням і розгалуженням. 7 клас. Урок №11 Система делает возможным приобрести билеты на многие мероприятия на сайте
Система делает возможным приобрести билеты на многие мероприятия на сайте Элементарное программирование
Элементарное программирование Работа с таблицами в редакторе MS Word
Работа с таблицами в редакторе MS Word Algorithms and data structures. Lecture 6. Sorting
Algorithms and data structures. Lecture 6. Sorting Программирование (Python)
Программирование (Python) Кодирование графической информации
Кодирование графической информации Лекция 2 по архитектуре компьютеров. Типы структур вычислительных машин
Лекция 2 по архитектуре компьютеров. Типы структур вычислительных машин Знакомство с JavaScript
Знакомство с JavaScript Измерение информации: вероятностный подход
Измерение информации: вероятностный подход Язык программирования Pascal
Язык программирования Pascal SWI Prolog Стандартные предикаты управления логическим выводом
SWI Prolog Стандартные предикаты управления логическим выводом Жизненный цикл информационных систем
Жизненный цикл информационных систем Урок - КВН
Урок - КВН Виртуальный литературный навигатор
Виртуальный литературный навигатор