- Оптимизация в БД

Содержание
- 2. "Сложная система, спроектированная наспех, никогда не работает, и исправить её, чтобы заставить работать, невозможно".
- 3. SQL – декларативный язык Мы говорим, что надо получить в результате запроса, но не говорим, как.
- 4. Что влияет на выполнение запроса? Внутренний оптимизатор СУБД, который в определяет наиболее эффективный способ выполнения реляционных
- 5. Оптимизация производительности сервера Конфигурация памяти Конфигурация ввода и вывода Настройка параметров Windows c 2017 г.
- 6. Конфигурация памяти Компонент управления памятью при запуске SQL Server динамически определяет объема выделяемой для него памяти.
- 7. Настройки памяти min server memory max server memory max worker threads (255 по умолчанию) максимальное число
- 8. Оптимизация производительности сервера с помощью параметров конфигурации ввода и вывода Параметр recovery interval используется, чтобы установить
- 9. Оптимизация производительности сервера с помощью параметров Windows Максимальное увеличение пропускной способности Настройка управления задачами на сервере
- 10. Выполнение запросов Язык SQL является декларативным языком. В его командах отсутствует информация о том, как выполнить
- 11. План выполнения запроса Задача: по декларативной формулировке запроса построить программу — план выполнения запроса, которая выполнялась
- 12. Шаги при выборе оптимального плана Прежде всего, необходимо обнаружить все корректные планы выполнения запроса или, по
- 13. Теперь, что касается самонастраивающихся оптимизаторов запросов. Эта идея (как и большинство идей вообще) не нова. В
- 14. Пример № 1 БД Сотрудники 4-го отдела не старше 25 лет с «чистой» ЗП >= 30000
- 15. SELECT * FROM Emp WHERE depNo=4 AND born>'1985/01/01' AND salary*0.87>=30000; Если есть индексы, то способы выполнения
- 16. Пример № 2 БД employees (enr, ename, status, city) papers (enr, title, year) departments (dname, city,
- 17. Найти названия отделов, расположенных в Нью-Йорке и предлагающих курсы по управлению базами данных Имеется 100 отделов,
- 18. Стратегия 1 Сформировать декартово произведение отношений "courses", "lectures" и "departments" (r: 200000) Оставить столбец dname из
- 19. Стратегия 2 Выполнить слияние отношений "courses" и "lectures" (r: 50 + 200; w: 400) Отсортировать результат
- 20. Стратегия 3 Выполнить слияние отношений "courses" и "lectures" (r: 50 + 200) Оставить только dnames из
- 21. Построение плана выполнения запроса Цель СУБД – выполнить запрос, причём сделать это как можно более эффективным
- 22. Квазиоптимальный процедурный план План называется квазиоптимальным, т.к. система не гарантирует, что она для любого запроса выберет
- 23. Работа оптимизатора состоит из 5 стадий На первой фазе запрос, представленный на языке запросов, подвергается лексическому
- 24. Оптимизация запросов Синтаксическая проверка Привязка указанных таблиц столбцов к физическим объектам Алгебраический анализатор Оптимизатор запроса План
- 25. 1. Лексический и синтаксический анализ Лексический анализатор разбивает запрос на лексические единицы – лексемы (наименования полей
- 26. 2. Логическая оптимизация различные преобразования, "улучшающие" начальное представление запроса. Среди этих преобразований могут быть эквивалентные преобразования.
- 27. Пример № 1 БД Например, если для таблицы Emp определено такое ограничение целостности: (CHECK (salary>9500 AND
- 28. Пример № 1 БД Например, если для таблицы Emp определено такое ограничение целостности: (CHECK (salary>9500 AND
- 29. Подходы: Преобразовывать формулировку запроса к такому виду, чтобы ограничения индивидуальных таблиц производились до их соединения. Преобразовать
- 30. 3. Процедурные планы выполнения запроса Основой является информация о существующих путях доступа к данным. Единственный путь
- 31. Преобразования операций реляционной алгебры Операндами операций РА являются отношения, т.е. неупорядоченные множества кортежей. Для выполнения операций
- 32. Преобразования операций реляционной алгебры Оптимизация выполнения запросов реляционной алгебры основана на понятии эквивалентности реляционных выражений. Операндами
- 33. Законы для эквивалентных преобразований выражений реляционной алгебры (1): 1. Закон коммутативности для декартовых произведений: R1×R2=R2×R1 2.
- 34. 8. Перестановка селекции с объединением: sF(R1UR2)=sF(R1)UsF(R2) 9. Перестановка селекции с декартовым произведением: sF(R1×R2)= (sF1(R1))×(sF2(R2)) 10. Перестановка
- 35. Порядок выполнения операторов Операторы выполняются слева направо – идет запрос к данным.
- 36. Виды соединения таблиц Соединение вложенных циклов Nested Loops Сложность: O(NlogM) Используется, если хотя бы одна таблица
- 37. Выбор процедурного плана Для выбора альтернативных процедурных планов выполнения запроса в соответствии с его внутренним представлением,
- 38. два основных вида оптимизаторов. Оптимизатор, основанный на анализе заданных правил (rule-based optimizer). Оптимизатор, основанный на анализе
- 39. rule-based optimizer (Oracle) Этот оптимизатор выбирает методы доступа на основе предположения о статичности СУБД Такой оптимизатор
- 40. Ранжирование методов доступа в Oracle
- 41. Стоимость выполнения Стоимость (затраты)– это оценка ожидаемого времени выполнения запроса с использованием конкретного плана выполнения. Оптимизатор
- 42. Оценка стоимости Для каждого из выбранных планов оценивается предполагаемая стоимость выполнения запроса по этому плану. При
- 43. Оптимизация выполнения запроса осуществляется в следующем порядке: 1.Вычисление выражений и условий, содержащих константы. 2.Преобразование сложной команды
- 44. Статистика – основа для оценки стоимости Во время выполнения запросы оптимизатор пытается найти наиболее оптимальный план
- 45. Статистика по таблице общее количество блоков данных (страниц памяти), выделенных таблице; количество пустых блоков данных (страниц
- 46. Статистика по индексам общее количество проиндексированных записей (оно может быть меньше, чем количество записей в таблице);
- 47. Как увидеть статистику?
- 48. Статистика Статистика влияет на метод выборки данных: Сканирование таблицы Поиск по индексу Перед выполнением запроса оптимизатор
- 49. Опции базы данных по статистике Создание статистики Обновление статистики Удаление статистики Create statistics FULLSCAN, SAMPLE number
- 50. Пример оптимизации на уровне выражений 1. SELECT ИД FROM ПРОДАВЦЫ WHERE ДОЛЖНОСТЬ='МЕНЕДЖЕР' 2. SELECT ИД FROM
- 51. Индекс – использовать или нет? при использовании оптимизации, основанной на анализе затрат, знание некоторых характеристик распределения
- 52. Полное сканирование или индекс? При необходимости доступа к значительной части строк какой-либо таблицы полное сканирование является
- 53. Процедурное представление плана Выполняемое представление плана хранится в процедурном кэше. Процедура «с плохими параметрами». На последнем
- 54. Оптимизация приложений В ОП хранятся все результаты ранее выполненных запросов до тех пор, пока эта память
- 55. Рекомендации по оптимизации Пишите так, чтобы помочь оптимизатору запросов. Можно сильно затруднить работу оптимизатора, написав запрос,
- 56. 1. Раздел WHERE является критическим. Для следующих примеров раздела WHERE индексный путь доступа не будет использоваться,
- 57. 1.1. Не использовать выражения от индексных столбцов Любые выражения, функции и вычисления, включающие индексированные столбцы, препятствуют
- 58. 2. Для фильтрации записей используйте WHERE, а не HAVING. Если для таблицы EMP существует индекс на
- 59. 3. Указывайте в разделе WHERE начальные столбцы ключа индекса. Для следующего запроса может быть применен составной
- 60. Как заставить использовать индекс? Последний запрос можно переписать так, чтобы индекс можно было применить. В этом
- 61. 4. Сравните сканирование через индекс с полным просмотром таблицы. При выборе из таблицы более 15 процентов
- 62. 5. Используйте ORDER BY для индексного сканирования. Оптимизатор будет использовать индексное сканирование, если запрос содержит раздел
- 63. 6. Минимизируйте число просмотров таблиц Таблица STUDENT содержит четыре столбца с именами NAME, STATUS, PARENT_INCOME и
- 64. 7. Соединяйте таблицы в правильном порядке. Всегда следует выполнять сначала максимально ограничивающий поиск, чтобы отфильтровать как
- 65. 8. При возможности используйте только поиск через индексы. Оптимизатор будет использовать только поиск в индексе, если
- 66. 9. Старайтесь писать как можно более простые («тупые») операторы SQL. Много мелких запросов в цикле лучше
- 67. 10. Варьируйте использование UNION или OR в зависимости от наличия индекса. Например, список пациентов палат №3
- 68. 11. Если после слияния таблиц отбираются поля только из одной таблицы, то вместо операции join надо
- 69. 11. IN, EXISTS или JOIN? Если в основной выборке много строк, а в подзапросе мало, то
- 70. 12. Группировка Если после группировки надо отсортировать результат, то желательно, чтобы поля сортировки и поля группировки
- 71. 13. CTE не имеют индексов Значительно облегчает жизнь, если запрос в with необходимо использовать несколько раз
- 72. 14. Используем кеш В ОП хранятся все результаты ранее выполненных запросов до тех пор, пока эта
- 73. 15. Избегайте неявного преобразования типов Использование неправильных типов данных Когда происходит неявное преобразование типа для столбца
- 74. Использование Multi-statement UDF Multi-statement UDF в русской редакции msdn переводится примерно как «Функции, определяемые пользователем, состоящие
- 75. Необоснованное использование хинтов в запросах Люди слишком поспешно принимают решение об использовании хинтов. Наиболее часто встречающаяся
- 76. Необоснованное использование вложенных представлений Представления, ссылающиеся на представления, соединяющиеся с представлениями, ссылающимися на другие представления, соединяющиеся
- 77. Улучшение оценки количества элементов для переменных и функций Если в предикате запроса используется локальная переменная, рекомендуется
- 78. Функции с табличным значением Для хранения результатов функции с табличным значением с несколькими инструкциями рекомендуется использовать
- 79. Используйте временные таблицы вместо табличных переменных Вместо табличных переменных рекомендуется использовать стандартную или временную таблицу. Оптимизатор
- 80. План параметризованных процедур Создаем процедуру с параметром create procedure proc1 (@user_name varchar(10)) as … При первом
- 81. Пример распределения значений ключа
- 82. Способы решения Постоянная перекомпиляция (RECOMPILE) Использование нескольких процедур Динамические запросы Опция OPTIMIZE FOR
- 83. Постоянная перекомпиляция (RECOMPILE) Создание хранимой процедуры с параметром WITH RECOMPILE в определении указывает, что SQL Server
- 84. Использование нескольких процедур Две процедуры: для пользователя User01 (99% данных в таблице) для всех остальных create
- 85. Динамические запросы create procedure dbo.p_user_activity_log ( @user_name varchar(10)) as begin declare @str nvarchar(max); set @str =
- 86. Опция OPTIMIZE FOR Подсказка OPTIMIZE FOR может использоваться для отмены определения параметров по первому вызову при
- 87. Опция OPTIMIZE FOR UNKNOWN Наши данные регулярно меняются и мы не можем передать в качестве подсказки
- 88. Улучшение оценки количества элементов с помощью указаний запросов Чтобы улучшить оценку количества элементов для локальных переменных,
- 90. Скачать презентацию

"Сложная система, спроектированная наспех,
никогда не работает,
и исправить её, чтобы
"Сложная система, спроектированная наспех, никогда не работает, и исправить её, чтобы

SQL – декларативный язык
Мы говорим, что надо получить в результате запроса,
SQL – декларативный язык
Мы говорим, что надо получить в результате запроса,

Что влияет на выполнение запроса?
Внутренний оптимизатор СУБД, который в определяет наиболее
Что влияет на выполнение запроса?
Внутренний оптимизатор СУБД, который в определяет наиболее

Оптимизация производительности сервера
Конфигурация памяти
Конфигурация ввода и вывода
Настройка параметров Windows
c 2017 г.
Оптимизация производительности сервера
Конфигурация памяти
Конфигурация ввода и вывода
Настройка параметров Windows
c 2017 г.

Конфигурация памяти
Компонент управления памятью при запуске SQL Server динамически определяет объема
Конфигурация памяти
Компонент управления памятью при запуске SQL Server динамически определяет объема

Настройки памяти
min server memory
max server memory
max worker threads (255
Настройки памяти
min server memory
max server memory
max worker threads (255

Оптимизация производительности сервера с помощью параметров конфигурации ввода и вывода
Параметр recovery interval используется,
Оптимизация производительности сервера с помощью параметров конфигурации ввода и вывода
Параметр recovery interval используется,

Оптимизация производительности сервера с помощью параметров Windows
Максимальное увеличение пропускной способности
Настройка управления
Оптимизация производительности сервера с помощью параметров Windows
Максимальное увеличение пропускной способности
Настройка управления

Выполнение запросов
Язык SQL является декларативным языком. В его командах отсутствует информация
Выполнение запросов
Язык SQL является декларативным языком. В его командах отсутствует информация

План выполнения запроса
Задача:
по декларативной формулировке запроса построить программу — план
План выполнения запроса
Задача:
по декларативной формулировке запроса построить программу — план

Шаги при выборе оптимального плана
Прежде всего, необходимо обнаружить все корректные планы
Шаги при выборе оптимального плана
Прежде всего, необходимо обнаружить все корректные планы

Теперь, что касается самонастраивающихся оптимизаторов запросов. Эта идея (как и большинство
Теперь, что касается самонастраивающихся оптимизаторов запросов. Эта идея (как и большинство

Пример № 1 БД
Сотрудники 4-го отдела не старше 25 лет с
Пример № 1 БД
Сотрудники 4-го отдела не старше 25 лет с

SELECT * FROM Emp
WHERE depNo=4 AND born>'1985/01/01'
AND salary*0.87>=30000;
Если есть индексы, то
SELECT * FROM Emp
WHERE depNo=4 AND born>'1985/01/01'
AND salary*0.87>=30000;
Если есть индексы, то

Пример № 2 БД
employees (enr, ename, status, city)
papers (enr, title, year)
departments
Пример № 2 БД
employees (enr, ename, status, city)
papers (enr, title, year)
departments

Найти названия отделов, расположенных в Нью-Йорке и предлагающих курсы по управлению
Найти названия отделов, расположенных в Нью-Йорке и предлагающих курсы по управлению

Стратегия 1
Сформировать декартово произведение отношений "courses", "lectures" и "departments"
(r: 200000)
Оставить столбец
Стратегия 1
Сформировать декартово произведение отношений "courses", "lectures" и "departments"
(r: 200000)
Оставить столбец

Стратегия 2
Выполнить слияние отношений "courses" и "lectures"
(r: 50 + 200; w:
Стратегия 2
Выполнить слияние отношений "courses" и "lectures"
(r: 50 + 200; w:

Стратегия 3
Выполнить слияние отношений "courses" и "lectures"
(r: 50 + 200)
Оставить только
Стратегия 3
Выполнить слияние отношений "courses" и "lectures"
(r: 50 + 200)
Оставить только

Построение плана выполнения запроса
Цель СУБД – выполнить запрос, причём сделать это
Построение плана выполнения запроса
Цель СУБД – выполнить запрос, причём сделать это

Квазиоптимальный процедурный план
План называется квазиоптимальным, т.к. система не гарантирует, что она
Квазиоптимальный процедурный план
План называется квазиоптимальным, т.к. система не гарантирует, что она

Работа оптимизатора состоит из 5 стадий
На первой фазе запрос, представленный на
Работа оптимизатора состоит из 5 стадий
На первой фазе запрос, представленный на

Оптимизация запросов
Синтаксическая проверка
Привязка указанных таблиц столбцов к физическим объектам
Алгебраический анализатор
Оптимизатор запроса
План
Оптимизация запросов
Синтаксическая проверка
Привязка указанных таблиц столбцов к физическим объектам
Алгебраический анализатор
Оптимизатор запроса
План

1. Лексический и синтаксический анализ
Лексический анализатор разбивает запрос на лексические
1. Лексический и синтаксический анализ
Лексический анализатор разбивает запрос на лексические

2. Логическая оптимизация
различные преобразования, "улучшающие" начальное представление запроса. Среди этих преобразований
2. Логическая оптимизация
различные преобразования, "улучшающие" начальное представление запроса. Среди этих преобразований

Пример № 1 БД
Например, если для таблицы Emp определено такое ограничение
Пример № 1 БД
Например, если для таблицы Emp определено такое ограничение

Пример № 1 БД
Например, если для таблицы Emp определено такое ограничение
Пример № 1 БД
Например, если для таблицы Emp определено такое ограничение

Подходы:
Преобразовывать формулировку запроса к такому виду, чтобы ограничения индивидуальных таблиц производились
Подходы:
Преобразовывать формулировку запроса к такому виду, чтобы ограничения индивидуальных таблиц производились

3. Процедурные планы выполнения запроса
Основой является информация о существующих
3. Процедурные планы выполнения запроса
Основой является информация о существующих

Преобразования операций реляционной алгебры
Операндами операций РА являются отношения, т.е. неупорядоченные множества
Преобразования операций реляционной алгебры
Операндами операций РА являются отношения, т.е. неупорядоченные множества

Преобразования операций реляционной алгебры
Оптимизация выполнения запросов реляционной алгебры основана на понятии
Преобразования операций реляционной алгебры
Оптимизация выполнения запросов реляционной алгебры основана на понятии

Законы для эквивалентных преобразований выражений реляционной алгебры (1):
1. Закон коммутативности для декартовых
Законы для эквивалентных преобразований выражений реляционной алгебры (1):
1. Закон коммутативности для декартовых

8. Перестановка селекции с объединением: sF(R1UR2)=sF(R1)UsF(R2)
9. Перестановка селекции с декартовым произведением:
sF(R1×R2)= (sF1(R1))×(sF2(R2))
10. Перестановка
8. Перестановка селекции с объединением: sF(R1UR2)=sF(R1)UsF(R2)
9. Перестановка селекции с декартовым произведением:
sF(R1×R2)= (sF1(R1))×(sF2(R2))
10. Перестановка

Порядок выполнения операторов
Операторы выполняются слева направо – идет запрос к данным.
Порядок выполнения операторов
Операторы выполняются слева направо – идет запрос к данным.

Виды соединения таблиц
Соединение вложенных циклов Nested Loops
Сложность: O(NlogM)
Используется, если хотя бы
Виды соединения таблиц
Соединение вложенных циклов Nested Loops
Сложность: O(NlogM)
Используется, если хотя бы

Выбор процедурного плана
Для выбора альтернативных процедурных планов выполнения запроса в соответствии
Выбор процедурного плана
Для выбора альтернативных процедурных планов выполнения запроса в соответствии

два основных вида оптимизаторов.
Оптимизатор, основанный на анализе заданных правил (rule-based optimizer).
два основных вида оптимизаторов.
Оптимизатор, основанный на анализе заданных правил (rule-based optimizer).

rule-based optimizer (Oracle)
Этот оптимизатор выбирает методы доступа на основе предположения о
rule-based optimizer (Oracle)
Этот оптимизатор выбирает методы доступа на основе предположения о

Ранжирование методов доступа в Oracle
Ранжирование методов доступа в Oracle

Стоимость выполнения
Стоимость (затраты)– это оценка ожидаемого времени выполнения запроса с использованием
Стоимость выполнения
Стоимость (затраты)– это оценка ожидаемого времени выполнения запроса с использованием

Оценка стоимости
Для каждого из выбранных планов оценивается предполагаемая стоимость выполнения запроса
Оценка стоимости
Для каждого из выбранных планов оценивается предполагаемая стоимость выполнения запроса

Оптимизация выполнения запроса осуществляется в следующем порядке:
1.Вычисление выражений и условий, содержащих
Оптимизация выполнения запроса осуществляется в следующем порядке:
1.Вычисление выражений и условий, содержащих

Статистика – основа для оценки стоимости
Во время выполнения запросы оптимизатор пытается
Статистика – основа для оценки стоимости
Во время выполнения запросы оптимизатор пытается

Статистика по таблице
общее количество блоков данных (страниц памяти), выделенных таблице;
количество пустых
Статистика по таблице
общее количество блоков данных (страниц памяти), выделенных таблице;
количество пустых

Статистика по индексам
общее количество проиндексированных записей (оно может быть меньше, чем
Статистика по индексам
общее количество проиндексированных записей (оно может быть меньше, чем
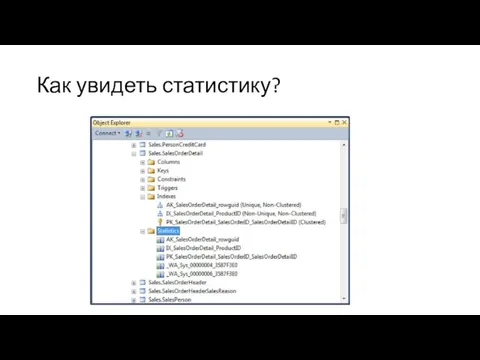
Как увидеть статистику?
Как увидеть статистику?

Статистика
Статистика влияет на метод выборки данных:
Сканирование таблицы
Поиск по индексу
Перед выполнением запроса
Статистика
Статистика влияет на метод выборки данных:
Сканирование таблицы
Поиск по индексу
Перед выполнением запроса

Опции базы данных по статистике
Создание статистики
Обновление статистики
Удаление статистики
Create statistics
FULLSCAN, SAMPLE number
Опции базы данных по статистике
Создание статистики
Обновление статистики
Удаление статистики
Create statistics
FULLSCAN, SAMPLE number

Пример оптимизации на уровне выражений
1. SELECT ИД FROM ПРОДАВЦЫ WHERE ДОЛЖНОСТЬ='МЕНЕДЖЕР'
2.
Пример оптимизации на уровне выражений
1. SELECT ИД FROM ПРОДАВЦЫ WHERE ДОЛЖНОСТЬ='МЕНЕДЖЕР'
2.

Индекс – использовать или нет?
при использовании оптимизации, основанной на анализе затрат,
Индекс – использовать или нет?
при использовании оптимизации, основанной на анализе затрат,

Полное сканирование или индекс?
При необходимости доступа к значительной части строк какой-либо
Полное сканирование или индекс?
При необходимости доступа к значительной части строк какой-либо

Процедурное представление плана
Выполняемое представление плана хранится в процедурном кэше. Процедура «с
Процедурное представление плана
Выполняемое представление плана хранится в процедурном кэше. Процедура «с

Оптимизация приложений
В ОП хранятся все результаты ранее выполненных запросов до тех
Оптимизация приложений
В ОП хранятся все результаты ранее выполненных запросов до тех

Рекомендации по оптимизации
Пишите так, чтобы помочь оптимизатору запросов.
Можно сильно затруднить
Рекомендации по оптимизации
Пишите так, чтобы помочь оптимизатору запросов.
Можно сильно затруднить

1. Раздел WHERE является критическим.
Для следующих примеров раздела WHERE индексный
1. Раздел WHERE является критическим.
Для следующих примеров раздела WHERE индексный

1.1. Не использовать выражения от индексных столбцов
Любые выражения, функции и вычисления,
1.1. Не использовать выражения от индексных столбцов
Любые выражения, функции и вычисления,

2. Для фильтрации записей используйте WHERE, а не HAVING.
Если для таблицы
2. Для фильтрации записей используйте WHERE, а не HAVING.
Если для таблицы

3. Указывайте в разделе WHERE начальные столбцы ключа индекса.
Для следующего запроса
3. Указывайте в разделе WHERE начальные столбцы ключа индекса.
Для следующего запроса

Как заставить использовать индекс?
Последний запрос можно переписать так, чтобы индекс можно
Как заставить использовать индекс?
Последний запрос можно переписать так, чтобы индекс можно

4. Сравните сканирование через индекс с полным просмотром таблицы.
При выборе из
4. Сравните сканирование через индекс с полным просмотром таблицы.
При выборе из

5. Используйте ORDER BY для индексного сканирования.
Оптимизатор будет использовать индексное
5. Используйте ORDER BY для индексного сканирования.
Оптимизатор будет использовать индексное

6. Минимизируйте число просмотров таблиц
Таблица STUDENT содержит четыре столбца с именами
6. Минимизируйте число просмотров таблиц
Таблица STUDENT содержит четыре столбца с именами

7. Соединяйте таблицы в правильном порядке.
Всегда следует выполнять сначала максимально
7. Соединяйте таблицы в правильном порядке.
Всегда следует выполнять сначала максимально

8. При возможности используйте только поиск через индексы.
Оптимизатор будет использовать
8. При возможности используйте только поиск через индексы.
Оптимизатор будет использовать

9. Старайтесь писать как можно более простые («тупые») операторы SQL.
Много
9. Старайтесь писать как можно более простые («тупые») операторы SQL.
Много

10. Варьируйте использование UNION или OR в зависимости от наличия индекса.
10. Варьируйте использование UNION или OR в зависимости от наличия индекса.

11. Если после слияния таблиц отбираются поля только из одной таблицы,
11. Если после слияния таблиц отбираются поля только из одной таблицы,

11. IN, EXISTS или JOIN?
Если в основной выборке много строк, а
11. IN, EXISTS или JOIN?
Если в основной выборке много строк, а

12. Группировка
Если после группировки надо отсортировать результат, то желательно, чтобы
12. Группировка
Если после группировки надо отсортировать результат, то желательно, чтобы

13. CTE не имеют индексов
Значительно облегчает жизнь, если запрос в with
13. CTE не имеют индексов
Значительно облегчает жизнь, если запрос в with

14. Используем кеш
В ОП хранятся все результаты ранее выполненных запросов до
14. Используем кеш
В ОП хранятся все результаты ранее выполненных запросов до

15. Избегайте неявного преобразования типов
Использование неправильных типов данных
Когда происходит неявное преобразование
15. Избегайте неявного преобразования типов
Использование неправильных типов данных
Когда происходит неявное преобразование

Использование Multi-statement UDF
Multi-statement UDF в русской редакции msdn переводится примерно как
Использование Multi-statement UDF
Multi-statement UDF в русской редакции msdn переводится примерно как

Необоснованное использование хинтов в запросах
Люди слишком поспешно принимают решение об использовании
Необоснованное использование хинтов в запросах
Люди слишком поспешно принимают решение об использовании

Необоснованное использование вложенных представлений
Представления, ссылающиеся на представления, соединяющиеся с представлениями, ссылающимися
Необоснованное использование вложенных представлений
Представления, ссылающиеся на представления, соединяющиеся с представлениями, ссылающимися

Улучшение оценки количества элементов для переменных и функций
Если в предикате запроса
Улучшение оценки количества элементов для переменных и функций
Если в предикате запроса

Функции с табличным значением
Для хранения результатов функции с табличным значением с
Функции с табличным значением
Для хранения результатов функции с табличным значением с

Используйте временные таблицы вместо табличных переменных
Вместо табличных переменных рекомендуется использовать стандартную
Используйте временные таблицы вместо табличных переменных
Вместо табличных переменных рекомендуется использовать стандартную

План параметризованных процедур
Создаем процедуру с параметром
create procedure proc1 (@user_name varchar(10)) as
План параметризованных процедур
Создаем процедуру с параметром create procedure proc1 (@user_name varchar(10)) as

Пример распределения значений ключа
Пример распределения значений ключа

Способы решения
Постоянная перекомпиляция (RECOMPILE)
Использование нескольких процедур
Динамические запросы
Опция OPTIMIZE
Способы решения
Постоянная перекомпиляция (RECOMPILE)
Использование нескольких процедур
Динамические запросы
Опция OPTIMIZE

Постоянная перекомпиляция (RECOMPILE)
Создание хранимой процедуры с параметром WITH RECOMPILE в
Постоянная перекомпиляция (RECOMPILE)
Создание хранимой процедуры с параметром WITH RECOMPILE в

Использование нескольких процедур
Две процедуры:
для пользователя User01 (99% данных в
Использование нескольких процедур
Две процедуры:
для пользователя User01 (99% данных в

Динамические запросы
create procedure dbo.p_user_activity_log ( @user_name varchar(10)) as
begin
declare @str
Динамические запросы
create procedure dbo.p_user_activity_log ( @user_name varchar(10)) as begin declare @str

Опция OPTIMIZE FOR
Подсказка OPTIMIZE FOR может использоваться для отмены определения
Опция OPTIMIZE FOR
Подсказка OPTIMIZE FOR может использоваться для отмены определения

Опция OPTIMIZE FOR UNKNOWN
Наши данные регулярно меняются и мы не
Опция OPTIMIZE FOR UNKNOWN
Наши данные регулярно меняются и мы не

Улучшение оценки количества элементов с помощью указаний запросов
Чтобы улучшить оценку количества
Улучшение оценки количества элементов с помощью указаний запросов
Чтобы улучшить оценку количества
 Интеллектуальные информационные системы (ИИС). Лекция 7. Нечеткий логический вывод
Интеллектуальные информационные системы (ИИС). Лекция 7. Нечеткий логический вывод Информационная деятельность человека: сбор, обработка, хранение, передача, защита информации. Урок №2
Информационная деятельность человека: сбор, обработка, хранение, передача, защита информации. Урок №2 Все на поиск терминов. Компьютерный турнир
Все на поиск терминов. Компьютерный турнир Системы управления базами данных (СУБД) MS Access
Системы управления базами данных (СУБД) MS Access Мультимедийная презентация-сказкаРепкав технике оригами.
Мультимедийная презентация-сказкаРепкав технике оригами. Основные сведения о персональных компьютерах. (Тема 4)
Основные сведения о персональных компьютерах. (Тема 4) Устройство компьютера
Устройство компьютера Apache Kafka
Apache Kafka Настройка сетевых параметров операционных систем Windows и Linux
Настройка сетевых параметров операционных систем Windows и Linux Типы информационных моделей. Основные этапы разработки и исследования моделей на компьютере
Типы информационных моделей. Основные этапы разработки и исследования моделей на компьютере Цветовые модели компьютерной графики
Цветовые модели компьютерной графики Разработка движка для сайта “Музыкальный портал”
Разработка движка для сайта “Музыкальный портал” Диаграмма состояний. Применение языка UML при разработке информационных систем
Диаграмма состояний. Применение языка UML при разработке информационных систем Графика в Pascal ABC
Графика в Pascal ABC Система Ладошки
Система Ладошки Электронное правительство
Электронное правительство Технологии обработки данных. Сетевые технологии обработки данных. (Лекция 8)
Технологии обработки данных. Сетевые технологии обработки данных. (Лекция 8) Модуль 1: Установка и настройка SQL Server 2008
Модуль 1: Установка и настройка SQL Server 2008 Введение в C#. Новый язык от Microsoft
Введение в C#. Новый язык от Microsoft Информация и информационные технологии
Информация и информационные технологии Постановка задачи обеспечения информационной безопасности баз данных
Постановка задачи обеспечения информационной безопасности баз данных Системы управления контентом CMS (08)
Системы управления контентом CMS (08) Spring Framework
Spring Framework Как пройти нормоконтроль
Как пройти нормоконтроль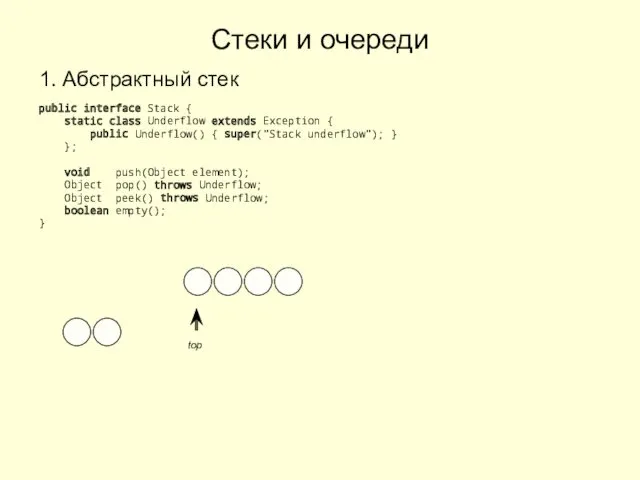 Стеки и очереди
Стеки и очереди Подготовка к ОГЭ (информатика)
Подготовка к ОГЭ (информатика) Аддитивные технологии
Аддитивные технологии Компьютерный сленг и его использование в молодёжной среде
Компьютерный сленг и его использование в молодёжной среде