- Основные понятия баз данных

Содержание
- 2. Основные темы лекций по курсу СУБД 1. Основные понятия баз данных. Этапы развития СУБД. Требования к
- 3. Литература Дейт К. Введение в системы баз данных. – 8 изд., Вильямс, 2005 Кузнецов С.Д. Базы
- 4. Основные понятия баз данных Информация, хранящаяся в базах данных, является отражением объектов реального мира. В традиционной
- 5. Основные определения БД - это система специальным образом организованных данных (баз данных), программных, технических, языковых средств,
- 6. База данных База данных - это единое, большое хранилище данных, которое однократно определяется, а затем используется
- 7. СУБД СУБД - это программное обеспечение, которое взаимодействует с прикладными программами пользователя и базой данных и
- 8. Этапы развития СУБД В истории развития и совершенствования систем управления базами данных, можно условно выделить три
- 9. 3) Представители второго поколения в настоящее время сохраняют определенную популярность среди производителей СУБД и развились в
- 10. Требования к современным СУБД функциональность, производительность, защищенность, целостность масштабируемость надежность (катастрофоустойчивость), реактивность
- 11. Архитектура Баз Данных
- 12. Внешний уровень Представление базы данных с точки зрения пользователей. Этот уровень описывает ту часть базы данных,
- 13. Логическая и физическая независимость данных Основным назначением трехуровневой архитектуры является обеспечение независимости от данных, которая означает,
- 14. Схема прохождения запроса к базе данных БМД – База метаданных, в которой хранится вся информация об
- 15. Схема прохождения запроса к базе данных 1) Пользователь посылает запрос на получение данных из БД. 2)
- 16. Схема прохождения запроса к базе данных Стоит отметить, что описанный выше процесс прохождения запроса не всегда
- 17. Данные и модели данных Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и
- 18. Классификация моделей данных
- 19. Классификация моделей данных Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий
- 20. Классификация моделей данных Дескрипторные модели – самые простые из документальных моделей, они широко использовались на ранних
- 21. Режимы работы с базой данных При размещении БД на персональном компьютере, который не находится в сети,
- 22. Режимы работы с базой данных Параллельный доступ к одной БД нескольких пользователей, в том случае если
- 23. Модель «клиент-сервер» Вычислительная модель «клиент-сервер» исходно связана с парадигмой открытых систем, которая появилась в 90-х годах
- 24. Разделение функций Основной принцип технологии «клиент-сервер» применительно к технологии баз данных заключается в разделении функций стандартного
- 25. Разделение функций Бизнес-логика (Business Logic) – это исполняемая часть приложения, которая определяет алгоритмы решения конкретных задач
- 26. Модель файлового сервера В модели файлового сервера (File Server, FS) презентационная логика и бизнес-логика располагаются на
- 27. Модель удаленного доступа к данным Отличием модели удаленного доступа к данным (Remote Data Access, RDA) от
- 28. Модель сервера баз данных Модель сервера баз данных (Database Server, DBS) поддерживается многими современными СУБД: Informix,
- 29. Модель сервера баз данных В данной модели сервер является активным, потому что не только клиент, но
- 30. Модель сервера приложений Модель сервера приложений (Application Server, AS) является расширением двухуровневой модели и в ней
- 31. Реляционная модель БД Реляционная модель данных была разработана Коддом в 1970 году на основе математической теории
- 32. Реляционная модель БД
- 33. Соответствие формальных реляционных терминов и их неформальных эквивалентов
- 34. Вся информация в реляционных базах данных представляется значениями в таблицах (table). В реляционных системах таблицы состоят
- 35. Основные достоинства реляционной модели 1) Наличие небольшого набора абстракций, которые позволяют моделировать предметную область и допускают
- 36. Обеспечение целостности данных Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира.
- 37. Операторы реляционной алгебры Традиционные операции над множествами Объединением (Union) двух отношений называется отношение, содержащее множество кортежей,
- 38. Специальные операции реляционной алгебры Операция выбора (Select), заданная на отношении R в виде булевского выражения, определенного
- 39. Понятия полной и транзитивной функциональной зависимости Функциональная зависимость ( functional dependence - FD) - в отношении
- 40. Нормализация Вообще говоря, руководство по нормализации – это набор стандартов проектирования данных, называемых нормальными формами (normal
- 41. Нормализация, нормальные формы Нормализация – это набор стандартов проектирования данных, называемых нормальными формами (normal form). Общепринятыми
- 42. Первая нормальная форма (1NF) требует, чтобы на любом пересечении строки и столбца находилось единственное значение, которое
- 43. Четвертая нормальная форма запрещает независимые отношения типа один-ко-многим между ключевыми и неключевыми столбцами. Пятая нормальная форма
- 44. В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм: • первая нормальная форма (1NF);
- 45. Проектирование баз данных При проектировании базы данных решаются две основные проблемы: Отображение объектов предметной области в
- 46. Семантические модели данных Потребности проектировщиков баз данных в удобных и мощных средствах моделирования предметной области породили
- 47. ER - модель (Entity-Relationship, Сущность-Связи) На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз
- 48. Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и
- 49. Связи делятся на три типа по множественности: Один-к-одному (1:1) экземпляр одной сущности связан с одним экземпляром
- 50. Лаконичной устной трактовкой изображенной диаграммы является следующая: Каждый БИЛЕТ предназначен для одного и только одного ПАССАЖИРА;
- 51. Язык SQL, его структура, стандарты, история развития. Доступ к данным осуществляется в виде запросов, которые формулируются
- 52. Язык SQL делится на подмножества. 1) Язык определения данных (DDL - Data Definition Language) предоставляет пользователям
- 53. Каждый столбец в любой таблице хранит данные определенных типов. Различают базовые типы данных: строки символов фиксированной
- 54. Пример базы данных для иллюстрации операторов языка SQL Таблица 1 Salespeople (Продавцы) snum уникальный номер продавца
- 55. cnum уникальный номер покупателя cname имя покупателя city расположение покупателя ( город ). rating код, указывающий
- 56. CREATE TABLE salespeople (snum integer NOT NULL PRIMARY KEY, sname char(10) NOT NULL, city char(10), comm.
- 57. Последовательности В реляционных или объектно-реляционных базах данных часто возникает необходимость в генерации целочисленных столбцов, где каждая
- 58. Последовательность создается с помощью команды DDL CREATE SEQUENCE. После того, как последовательность создана, к ней можно
- 59. Подмножество языка DML: операторы SELECT, INSERT, UPDATE, DELETE Язык обработки данных DML позволяет добавлять (insert), изменять
- 60. Оператор выбора SELECT Синтаксис оператора имеет следующий вид: SELECT [ ALL ! DISTINCT ] ! *
- 61. Примеры: 1) Вывести все данные из таблицы Salespeople SELECT snum, sname, city, comm FROM Salespeople; или
- 62. 5) Вывести максимальный заказ для каждого продавца SELECT snum, MAX(amt) FROM orders GROUP BY snum; 6)
- 63. Оператор ввода новых строк INSERT Синтаксис оператора имеет следующий вид: INSERT INTO VALUES ( , …)
- 64. Оператор удаления строк DELETE 1) Удаление всех строк в таблице DELETE FROM salespeople; 2) Удаление определенной
- 65. Оператор изменения значений полей UPDATE 1) Изменение значения поля в определенной строке таблицы UPDATE customers SET
- 66. Подмножество языка DDL: операторы CREATE, ALTER, DROP Язык определения данных DDL представляет собой подмножество команд языка
- 68. Оператор CREATE TABLE CREATE TABLE ( [ [ ]], [ [ ]],…); Ограничения в таблицах: NOT
- 69. Поддержка ccылочной целостности данных FOREIGN KEY REFERENCES [ ] FOREIGN KEY (snum) REFERENCES salespeople (snum) Для
- 70. Параметры ON UPDATE и ON DELETE указываются при необходимости осуществлять каскадные действия при, соответственно, изменении или
- 71. Использовать значение CASCADE параметров ON UPDATE и ON DELETE следует с особой осторожностью, поскольку одна ошибочная
- 72. CREATE TABLE customers (cnum integer NOT NULL PRIMARY KEY, cname char(10) NOT NULL, city char(10), rating
- 73. Представления, их значение Представление – объект базы данных, позволяющий получить определенную пользователем выборку данных из одной
- 74. Примеры представлений 1) CREATE VIEW londonstaff AS SELECT * FROM salespeople WHERE city = ‘London’; 2)
- 75. Обновляемые представления Если к представлению можно применить операторы обновления, то представление является обновляемым (updateble), иначе оно
- 76. Пример обновляемого представления: CREATE VIEW Highratings AS SELECT cnum,rating FROM customers WHERE rating = 300; В
- 77. Объектные и системные привилегии До сих пор предполагалось, что каждый пользователь базы данных может обращаться к
- 78. Операторы GRANT, REVOKE Предоставление пользователям необходимых полномочий и лишение полномочий осуществляется с помощью операторов DCL: GRANT
- 79. Для объектных привилегий синтаксис оператора REVOKE таков: REVOKE привилегия ON объект FROM обладатель_привилегий [CASCADE CONSTRAINTS]; где
- 80. Роли Для организаций, в которых работает множество пользователей, управление привилегиями является достаточно сложной задачей. Для ее
- 81. Транзакции Транзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое неделимое действие над базой
- 82. Таким образом, возможны два варианта завершения транзакции. Если все операторы выполнены успешно, и в процессе выполнения
- 83. Oператоры управления транзакциями: COMMIT, ROLLBACK, SAVEPOINT COMMIT - зафиксировать транзакцию ROLLBACK - отменить изменения в текущей
- 84. Режим ARCHIVELOG: возможность полного восстановления При работе базы данных в режиме ARCHIVELOG все журналы повтора транзакций
- 85. Режим NOARCHIVELOG При работе базы данных в режиме NOARCHIVELOG (именно этот режим устанавливается по умолчанию) сохранение
- 86. SQL* Plus: резюме SQL*Plus представляет собой вариант языка SQL, разработанный корпорацией Oracle, где слово "Plus" обозначает
- 87. Этапы проектирования баз данных Концептуальное проектирование базы данных Этап 1. Создание локальной концептуальной модели данных исходя
- 88. Логическое проектирование базы данных (для реляционной модели) Этап 2. Построение и проверка локальной логической модели данных
- 90. Скачать презентацию

Основные темы лекций по курсу СУБД
1. Основные понятия баз данных. Этапы развития
Основные темы лекций по курсу СУБД
1. Основные понятия баз данных. Этапы развития

Литература
Дейт К. Введение в системы баз данных. – 8 изд., Вильямс,
Литература
Дейт К. Введение в системы баз данных. – 8 изд., Вильямс,

Основные понятия баз данных
Информация, хранящаяся в базах данных, является отражением объектов
Основные понятия баз данных
Информация, хранящаяся в базах данных, является отражением объектов

Основные определения
БД - это система специальным образом организованных данных (баз
Основные определения
БД - это система специальным образом организованных данных (баз

База данных
База данных - это единое, большое хранилище данных, которое однократно
База данных
База данных - это единое, большое хранилище данных, которое однократно

СУБД
СУБД - это программное обеспечение, которое взаимодействует с прикладными программами пользователя
СУБД
СУБД - это программное обеспечение, которое взаимодействует с прикладными программами пользователя

Этапы развития СУБД
В истории развития и совершенствования систем управления базами данных,
Этапы развития СУБД
В истории развития и совершенствования систем управления базами данных,

3) Представители второго поколения в настоящее время сохраняют определенную популярность среди
3) Представители второго поколения в настоящее время сохраняют определенную популярность среди

Требования к современным СУБД
функциональность,
производительность,
защищенность,
целостность
масштабируемость
надежность (катастрофоустойчивость),
Требования к современным СУБД
функциональность,
производительность,
защищенность,
целостность
масштабируемость
надежность (катастрофоустойчивость),
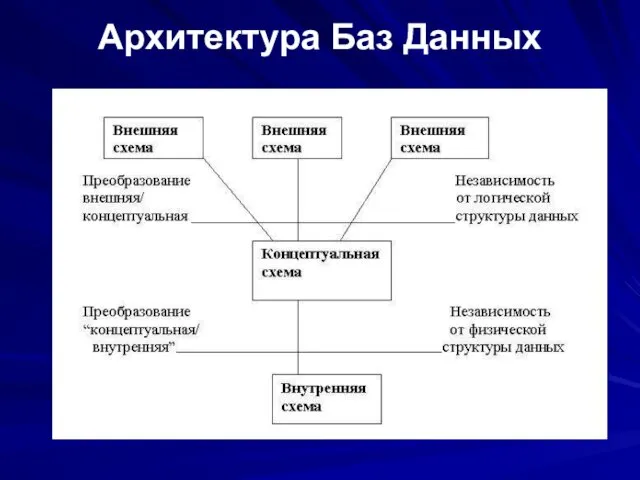
Архитектура Баз Данных
Архитектура Баз Данных

Внешний уровень
Представление базы данных с точки зрения пользователей. Этот уровень
Представление базы данных с точки зрения пользователей. Этот уровень

Логическая и физическая независимость данных
Основным назначением трехуровневой архитектуры является обеспечение независимости
Логическая и физическая независимость данных
Основным назначением трехуровневой архитектуры является обеспечение независимости
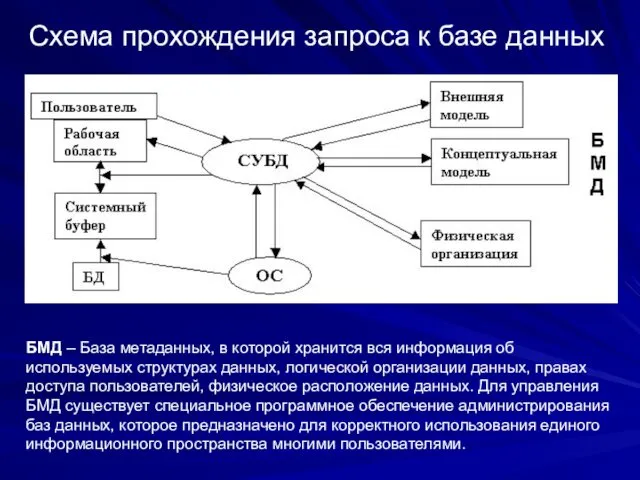
Схема прохождения запроса к базе данных
БМД – База метаданных, в которой
Схема прохождения запроса к базе данных
БМД – База метаданных, в которой

Схема прохождения запроса к базе данных
1) Пользователь посылает запрос на получение
Схема прохождения запроса к базе данных
1) Пользователь посылает запрос на получение

Схема прохождения запроса к базе данных
Стоит отметить, что описанный выше процесс
Схема прохождения запроса к базе данных
Стоит отметить, что описанный выше процесс

Данные и модели данных
Одними из основополагающих в концепции баз данных являются
Данные и модели данных
Одними из основополагающих в концепции баз данных являются
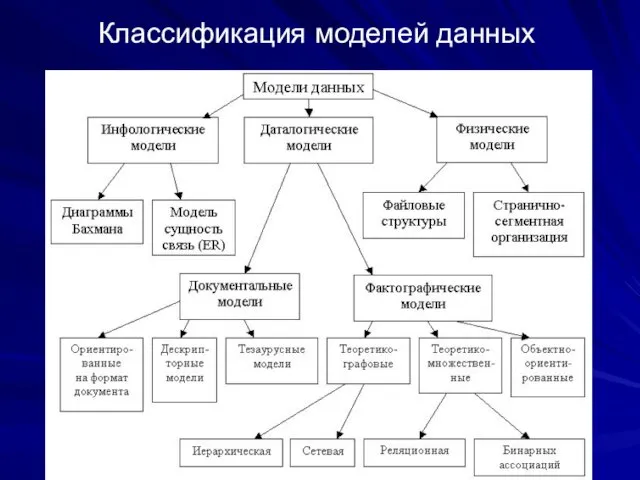
Классификация моделей данных
Классификация моделей данных

Классификация моделей данных
Кроме трех рассмотренных уровней абстракции при проектировании БД существует
Классификация моделей данных
Кроме трех рассмотренных уровней абстракции при проектировании БД существует

Классификация моделей данных
Дескрипторные модели – самые простые из документальных моделей, они
Классификация моделей данных
Дескрипторные модели – самые простые из документальных моделей, они

Режимы работы с базой данных
При размещении БД на персональном компьютере, который
Режимы работы с базой данных
При размещении БД на персональном компьютере, который
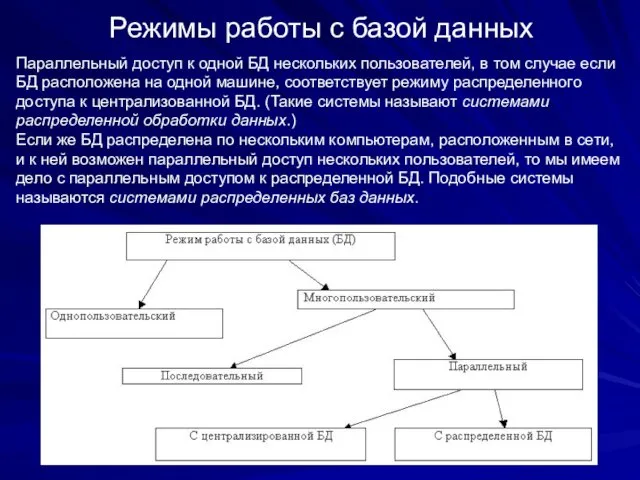
Режимы работы с базой данных
Параллельный доступ к одной БД нескольких пользователей,
Режимы работы с базой данных
Параллельный доступ к одной БД нескольких пользователей,

Модель «клиент-сервер»
Вычислительная модель «клиент-сервер» исходно связана с парадигмой открытых систем, которая
Модель «клиент-сервер»
Вычислительная модель «клиент-сервер» исходно связана с парадигмой открытых систем, которая

Разделение функций
Основной принцип технологии «клиент-сервер» применительно к технологии баз данных заключается
Разделение функций
Основной принцип технологии «клиент-сервер» применительно к технологии баз данных заключается

Разделение функций
Бизнес-логика (Business Logic) – это исполняемая часть приложения, которая определяет
Разделение функций
Бизнес-логика (Business Logic) – это исполняемая часть приложения, которая определяет

Модель файлового сервера
В модели файлового сервера (File Server, FS) презентационная логика
Модель файлового сервера
В модели файлового сервера (File Server, FS) презентационная логика

Модель удаленного доступа к данным
Отличием модели удаленного доступа к данным (Remote
Модель удаленного доступа к данным
Отличием модели удаленного доступа к данным (Remote
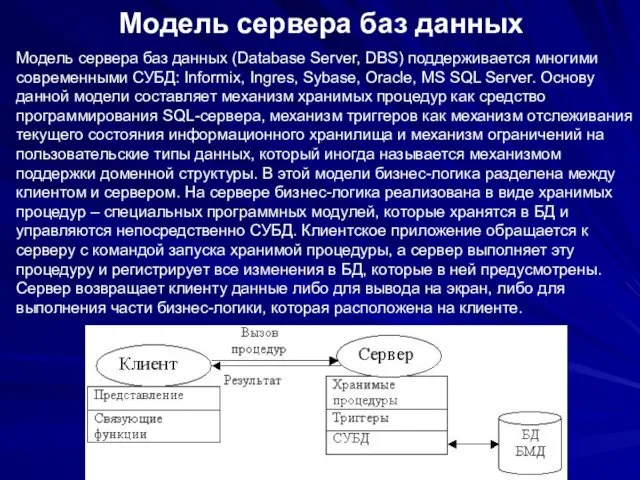
Модель сервера баз данных
Модель сервера баз данных (Database Server, DBS) поддерживается
Модель сервера баз данных
Модель сервера баз данных (Database Server, DBS) поддерживается

Модель сервера баз данных
В данной модели сервер является активным, потому что
Модель сервера баз данных
В данной модели сервер является активным, потому что
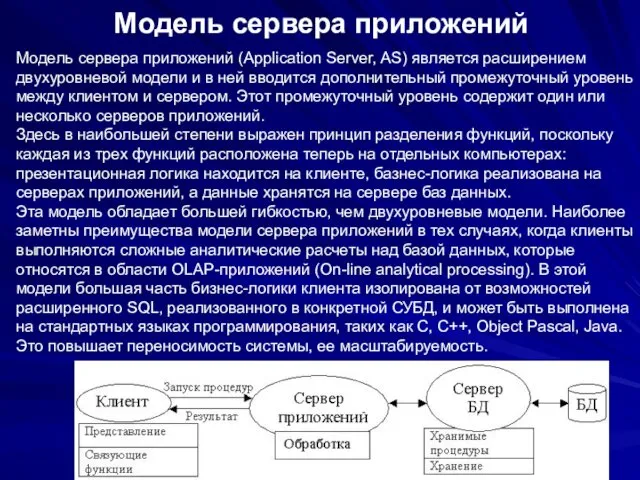
Модель сервера приложений
Модель сервера приложений (Application Server, AS) является расширением двухуровневой
Модель сервера приложений
Модель сервера приложений (Application Server, AS) является расширением двухуровневой

Реляционная модель БД
Реляционная модель данных была разработана Коддом в 1970 году
Реляционная модель БД
Реляционная модель данных была разработана Коддом в 1970 году
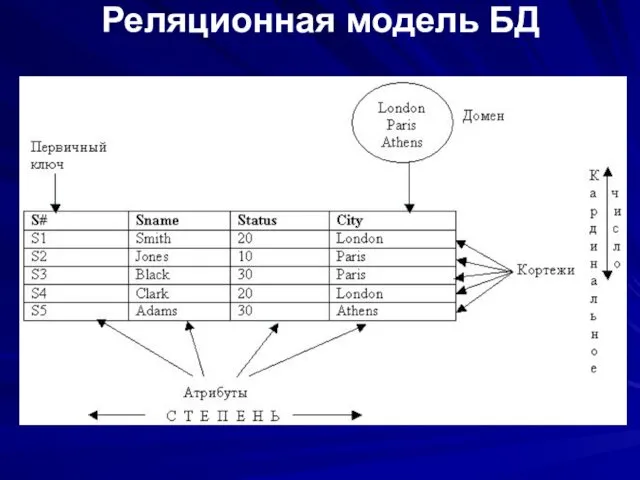
Реляционная модель БД
Реляционная модель БД

Соответствие формальных реляционных терминов и их неформальных эквивалентов
Соответствие формальных реляционных терминов и их неформальных эквивалентов

Вся информация в реляционных базах данных представляется значениями в таблицах (table).
Вся информация в реляционных базах данных представляется значениями в таблицах (table).

Основные достоинства реляционной модели
1) Наличие небольшого набора абстракций, которые позволяют моделировать
Основные достоинства реляционной модели
1) Наличие небольшого набора абстракций, которые позволяют моделировать

Обеспечение целостности данных
Для пользователей информационной системы недостаточно, чтобы база данных просто
Обеспечение целостности данных
Для пользователей информационной системы недостаточно, чтобы база данных просто

Операторы реляционной алгебры
Традиционные операции над множествами
Объединением (Union) двух отношений называется отношение,
Операторы реляционной алгебры
Традиционные операции над множествами
Объединением (Union) двух отношений называется отношение,

Специальные операции реляционной алгебры
Операция выбора (Select), заданная на отношении R в
Специальные операции реляционной алгебры
Операция выбора (Select), заданная на отношении R в

Понятия полной и транзитивной функциональной зависимости
Функциональная зависимость ( functional dependence -
Понятия полной и транзитивной функциональной зависимости
Функциональная зависимость ( functional dependence -

Нормализация
Вообще говоря, руководство по нормализации – это набор стандартов проектирования данных,
Нормализация
Вообще говоря, руководство по нормализации – это набор стандартов проектирования данных,

Нормализация, нормальные формы
Нормализация – это набор стандартов проектирования данных, называемых нормальными
Нормализация, нормальные формы
Нормализация – это набор стандартов проектирования данных, называемых нормальными

Первая нормальная форма (1NF) требует, чтобы на любом пересечении строки и
Первая нормальная форма (1NF) требует, чтобы на любом пересечении строки и

Четвертая нормальная форма запрещает независимые отношения типа один-ко-многим между ключевыми и
Четвертая нормальная форма запрещает независимые отношения типа один-ко-многим между ключевыми и

В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
•
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
•

Проектирование баз данных
При проектировании базы данных решаются две основные проблемы:
Отображение объектов
Проектирование баз данных
При проектировании базы данных решаются две основные проблемы:
Отображение объектов

Семантические модели данных
Потребности проектировщиков баз данных в удобных и мощных средствах
Семантические модели данных
Потребности проектировщиков баз данных в удобных и мощных средствах

ER - модель (Entity-Relationship, Сущность-Связи)
На использовании разновидностей ER-модели основано большинство современных
ER - модель (Entity-Relationship, Сущность-Связи)
На использовании разновидностей ER-модели основано большинство современных

Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта

Связи делятся на три типа по множественности:
Один-к-одному (1:1) экземпляр одной сущности
Связи делятся на три типа по множественности:
Один-к-одному (1:1) экземпляр одной сущности

Лаконичной устной трактовкой изображенной диаграммы является следующая:
Каждый БИЛЕТ предназначен для одного
Лаконичной устной трактовкой изображенной диаграммы является следующая: Каждый БИЛЕТ предназначен для одного

Язык SQL, его структура, стандарты, история развития.
Доступ к данным осуществляется в
Язык SQL, его структура, стандарты, история развития.
Доступ к данным осуществляется в

Язык SQL делится на подмножества.
1) Язык определения данных (DDL - Data
Язык SQL делится на подмножества.
1) Язык определения данных (DDL - Data

Каждый столбец в любой таблице хранит данные определенных типов.
Различают базовые
Каждый столбец в любой таблице хранит данные определенных типов.
Различают базовые
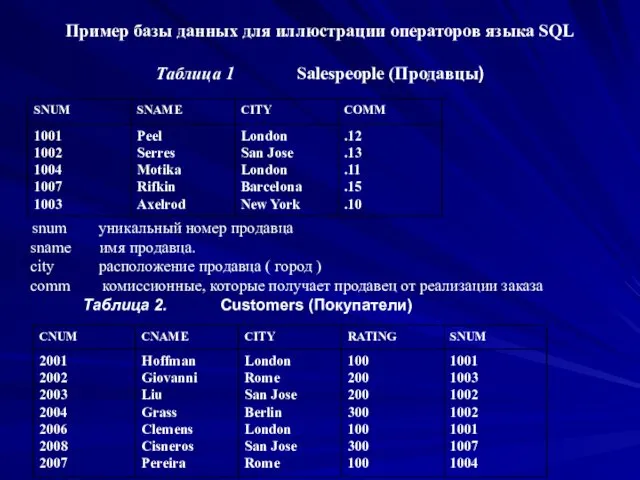
Пример базы данных для иллюстрации операторов языка SQL
Таблица 1 Salespeople
Пример базы данных для иллюстрации операторов языка SQL Таблица 1 Salespeople
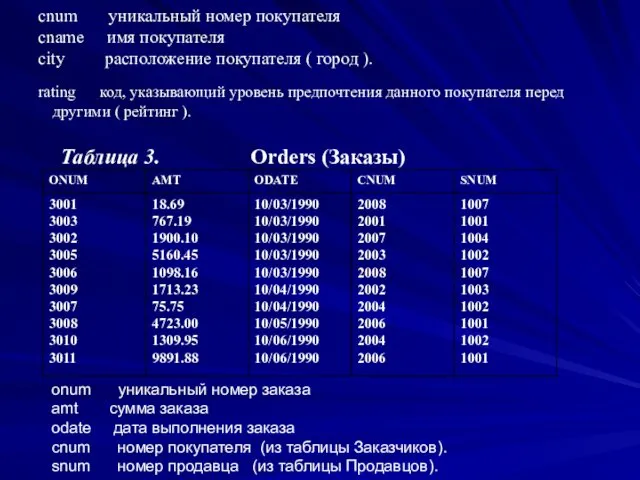
cnum уникальный номер покупателя
cname имя покупателя
city расположение покупателя (
cnum уникальный номер покупателя cname имя покупателя city расположение покупателя (

CREATE TABLE salespeople
(snum integer NOT NULL PRIMARY KEY,
sname char(10)
CREATE TABLE salespeople
(snum integer NOT NULL PRIMARY KEY,
sname char(10)

Последовательности
В реляционных или объектно-реляционных базах данных часто возникает необходимость в генерации
Последовательности
В реляционных или объектно-реляционных базах данных часто возникает необходимость в генерации

Последовательность создается с помощью команды DDL CREATE SEQUENCE. После того, как
Последовательность создается с помощью команды DDL CREATE SEQUENCE. После того, как

Подмножество языка DML: операторы SELECT, INSERT, UPDATE, DELETE
Язык обработки данных DML
Подмножество языка DML: операторы SELECT, INSERT, UPDATE, DELETE
Язык обработки данных DML

Оператор выбора SELECT
Синтаксис оператора имеет следующий вид:
SELECT [ ALL ! DISTINCT
Оператор выбора SELECT
Синтаксис оператора имеет следующий вид:
SELECT [ ALL ! DISTINCT

Примеры:
1) Вывести все данные из таблицы Salespeople
SELECT snum, sname,
Примеры:
1) Вывести все данные из таблицы Salespeople
SELECT snum, sname,

5) Вывести максимальный заказ для каждого продавца
SELECT snum, MAX(amt)
5) Вывести максимальный заказ для каждого продавца
SELECT snum, MAX(amt)

Оператор ввода новых строк INSERT
Синтаксис оператора имеет следующий вид:
INSERT INTO <имя
Оператор ввода новых строк INSERT
Синтаксис оператора имеет следующий вид:
INSERT INTO <имя

Оператор удаления строк DELETE
1) Удаление всех строк в таблице
DELETE FROM
Оператор удаления строк DELETE
1) Удаление всех строк в таблице
DELETE FROM

Оператор изменения значений полей UPDATE
1) Изменение значения поля в определенной строке
Оператор изменения значений полей UPDATE
1) Изменение значения поля в определенной строке

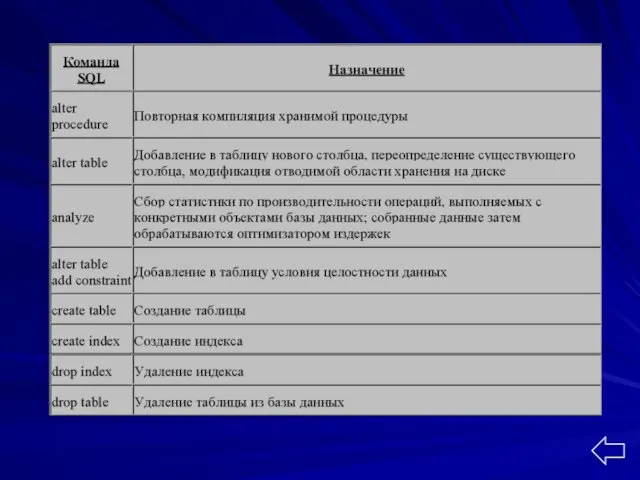
Подмножество языка DDL:
операторы CREATE, ALTER, DROP
Язык определения данных DDL
Подмножество языка DDL:
операторы CREATE, ALTER, DROP
Язык определения данных DDL
![Оператор CREATE TABLE CREATE TABLE ( [ [ ]], [](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1586/slide-67.jpg)
Оператор CREATE TABLE
CREATE TABLE <имя таблицы>
(<имя столбца> <тип> [<размер> [<ограничения>
Оператор CREATE TABLE
CREATE TABLE <имя таблицы>
(<имя столбца> <тип> [<размер> [<ограничения>
![Поддержка ccылочной целостности данных FOREIGN KEY REFERENCES [ ] FOREIGN](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1586/slide-68.jpg)
Поддержка ccылочной целостности данных
FOREIGN KEY <список столбцов> REFERENCES < имя
Поддержка ccылочной целостности данных
FOREIGN KEY <список столбцов> REFERENCES < имя

Параметры ON UPDATE и ON DELETE указываются при необходимости осуществлять каскадные
Параметры ON UPDATE и ON DELETE указываются при необходимости осуществлять каскадные

Использовать значение CASCADE параметров ON UPDATE и ON DELETE следует с
Использовать значение CASCADE параметров ON UPDATE и ON DELETE следует с

CREATE TABLE customers
(cnum integer NOT NULL PRIMARY KEY,
cname char(10)
CREATE TABLE customers
(cnum integer NOT NULL PRIMARY KEY,
cname char(10)

Представления, их значение
Представление – объект базы данных, позволяющий получить определенную пользователем
Представления, их значение
Представление – объект базы данных, позволяющий получить определенную пользователем

Примеры представлений
1) CREATE VIEW londonstaff
AS SELECT *
FROM salespeople
Примеры представлений
1) CREATE VIEW londonstaff
AS SELECT *
FROM salespeople

Обновляемые представления
Если к представлению можно применить операторы обновления, то представление является
Обновляемые представления
Если к представлению можно применить операторы обновления, то представление является

Пример обновляемого представления:
CREATE VIEW Highratings
AS SELECT cnum,rating
FROM customers
Пример обновляемого представления:
CREATE VIEW Highratings
AS SELECT cnum,rating
FROM customers

Объектные и системные привилегии
До сих пор предполагалось, что каждый пользователь базы
Объектные и системные привилегии
До сих пор предполагалось, что каждый пользователь базы

Операторы GRANT, REVOKE
Предоставление пользователям необходимых полномочий и лишение полномочий осуществляется с
Операторы GRANT, REVOKE
Предоставление пользователям необходимых полномочий и лишение полномочий осуществляется с

Для объектных привилегий синтаксис оператора REVOKE таков:
REVOKE привилегия ON объект
Для объектных привилегий синтаксис оператора REVOKE таков: REVOKE привилегия ON объект

Роли
Для организаций, в которых работает множество пользователей, управление привилегиями является достаточно
Роли
Для организаций, в которых работает множество пользователей, управление привилегиями является достаточно

Транзакции
Транзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое
Транзакции
Транзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое

Таким образом, возможны два варианта завершения транзакции. Если все операторы выполнены
Таким образом, возможны два варианта завершения транзакции. Если все операторы выполнены

Oператоры управления транзакциями: COMMIT, ROLLBACK, SAVEPOINT
COMMIT - зафиксировать транзакцию
ROLLBACK -
Oператоры управления транзакциями: COMMIT, ROLLBACK, SAVEPOINT
COMMIT - зафиксировать транзакцию ROLLBACK -

Режим ARCHIVELOG: возможность полного восстановления
При работе базы данных в режиме ARCHIVELOG
Режим ARCHIVELOG: возможность полного восстановления
При работе базы данных в режиме ARCHIVELOG

Режим NOARCHIVELOG
При работе базы данных в режиме NOARCHIVELOG (именно этот
Режим NOARCHIVELOG
При работе базы данных в режиме NOARCHIVELOG (именно этот

SQL* Plus: резюме
SQL*Plus представляет собой вариант языка SQL, разработанный корпорацией Oracle,
SQL* Plus: резюме
SQL*Plus представляет собой вариант языка SQL, разработанный корпорацией Oracle,

Этапы проектирования баз данных
Концептуальное проектирование базы данных
Этап 1. Создание локальной концептуальной
Этапы проектирования баз данных
Концептуальное проектирование базы данных
Этап 1. Создание локальной концептуальной

Логическое проектирование базы данных (для реляционной модели)
Этап 2. Построение и проверка
Логическое проектирование базы данных (для реляционной модели)
Этап 2. Построение и проверка
 Introduction to computer systems. Architecture of computer systems
Introduction to computer systems. Architecture of computer systems Компьютерные сети. Общая характеристика и классификация компьютерных сетей
Компьютерные сети. Общая характеристика и классификация компьютерных сетей Расчет корреляционных зависимостей в MS Excel
Расчет корреляционных зависимостей в MS Excel Массивы, циклы в JavaScript
Массивы, циклы в JavaScript Лекция 4. Виды телекоммуникационных технологий
Лекция 4. Виды телекоммуникационных технологий Расчетно-графическое задание
Расчетно-графическое задание Файл. Файловая система
Файл. Файловая система Microsoft Excel - электронные таблицы
Microsoft Excel - электронные таблицы Simulation examples
Simulation examples Влияние бизнес-архитектуры холдинга на его операционную эффективность
Влияние бизнес-архитектуры холдинга на его операционную эффективность Медиа-карта Красноярского края: История
Медиа-карта Красноярского края: История VII. Страницы. Контейнеры областей
VII. Страницы. Контейнеры областей Персональный компьютер. Внутренние и внешние устройства
Персональный компьютер. Внутренние и внешние устройства Урок №28-29 за 08.02
Урок №28-29 за 08.02 Illumina data QC & basic NGS tools
Illumina data QC & basic NGS tools Моделирование. 9 класс
Моделирование. 9 класс Python. Структура программы. Переменные и присваивание. Ввод-вывод
Python. Структура программы. Переменные и присваивание. Ввод-вывод Новые информационные технологии
Новые информационные технологии Курс С#. Программирование на языке высокого уровня. Лекция 2
Курс С#. Программирование на языке высокого уровня. Лекция 2 Инструкция – настройки телефона
Инструкция – настройки телефона Строки С++
Строки С++ Режимы и способы обработки данных
Режимы и способы обработки данных Scrum: определение и краткая история
Scrum: определение и краткая история Безопасность и эргономика. Защита информации
Безопасность и эргономика. Защита информации Средства обмена информацией в Интернет
Средства обмена информацией в Интернет Система DNS
Система DNS Создатели операционных систем
Создатели операционных систем Введение в проектирование
Введение в проектирование