- Параллельное и многопоточное программирование. (Лекция 7)

Содержание
- 2. Многопоточное программирование Используется для создания параллельных программ для систем с общей памятью И для других целей…
- 3. Модель памяти OpenMP Модель разделяемой памяти Нити взаимодействуют через разделяемые переменные Разделение определяется синтаксически Любая переменная,
- 4. OpenMP – это… Стандарт интерфейса для многопоточного программирования над общей памятью Набор средств для языков C/C++
- 5. Модель программирования Fork-join параллелизм Явное указание параллельных секций Поддержка вложенного параллелизма Поддержка динамических потоков
- 6. Подключение в Visual Studio
- 7. Формат записи директив и клауз OpenMP #pragma omp имя_директивы [clause,…] #pragma omp parallel default(shared)private(beta,pi) Формат записи
- 8. Пример: Объявление параллельной секции #include int main() { // последовательный код #pragma omp parallel { //
- 9. Некоторые функции OpenMP omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной секции всегда вернёт 0
- 10. Пример: Hello, World! #include #include int main() { printf(“Hello, World!\n”); #pragma omp parallel { int i,n;
- 11. Задание числа потоков Переменная среды OMP_NUM_THREADS Функция omp_set_num_threads(int) omp_set_num_threads(4); #pragma omp parallel { . . .
- 12. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 13. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 14. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 15. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 16. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 17. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 18. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 19. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 20. #pragma omp parallel Директива определяет параллельную область. Область программы, которая выполняется несколькими потоками одновременно. Это фундаментальная
- 21. #pragma omp parallel При входе в параллельную область порождаются новые OMP_NUM_THREADS-1 нитей, каждая нить получает свой
- 22. #pragma omp parallel Главный поток группы (master thread), получает номер 0, и все потоки, включая основной,
- 23. #pragma omp parallel Директива parallel сообщает компилятору, что структурированный блок кода должен быть выполнен параллельно, в
- 24. #pragma omp parallel Пример #include #include void test(int val) { #pragma omp parallel if (val) if
- 25. #pragma omp parallel В конце параллельной области осуществляется, не указанная явно, барьерная синхронизация. Здесь по умолчанию
- 26. #pragma omp parallel Клауза одна из следующих: if (скалярное выражение) num_threads (целое число) private (список) shared
- 27. #pragma omp parallel Клаузы if (условие) – выполнение параллельной области по условию. Вхождение в параллельную область
- 28. #pragma omp parallel Клаузы shared (список) – задаёт список переменных, общих для всех нитей; copyin (список)
- 29. #pragma omp parallel Если поток в группе, выполняя параллельную область кода, встретит другую параллельную конструкцию, она
- 30. #pragma omp parallel Вложенность. Пример #include #include void report_num_threads(int level) { #pragma omp single { printf("Level
- 31. omp_set_nested Функция omp_set_nested() разрешает или запрещает вложенный параллелизм. В качестве значения параметра задаётся 0 или 1.
- 32. omp_set_dynamic Omp_set_dynamic функция позволяет включить или отключить динамическую корректировку числа потоков, доступных для выполнения параллельных областей.
- 33. #pragma omp parallel Примечания Если выполнение потока аварийно прерывается внутри параллельной области, то также прерывается выполнение
- 34. #pragma omp parallel Ограничения Программа не должна зависеть от какого-либо порядка определения опций параллельной директивы, или
- 35. #pragma omp parallel Распределение работы OpenMP определяет следующие конструкции распределения работ: директива for директива sections директива
- 36. Основные способы разделения работы между потоками
- 37. #pragma omp for Бесконечный цикл — это дать сонному человеку треугольное одеяло. Автор неизвестен Директива for
- 38. #pragma omp for Ограничения Директива for накладывает ограничения на структуру соответствующего цикла. Определенно, соответствующий цикл должен
- 39. #pragma omp for выражение одно из следующих: var = lb integer-type var = lb for (
- 40. #pragma omp for Клауза schedule Клауза schedule определяет, каким образом итерации цикла делятся между потоками группы.
- 41. #pragma omp for Клауза schedule (static, X) Если определена клауза schedule(static, длина_порции) , то итерации делятся
- 42. #pragma omp for Клауза schedule (static, X) Каждый поток получает примерно равное число итераций. Если вместо
- 43. #pragma omp for Клауза schedule (dynamic, X) Если определена клауза schedule( dynamic, длина_порции) , то порции
- 44. #pragma omp for Клауза schedule (dynamic, X) Во время динамического распределения не существует предсказуемого порядка назначения
- 45. #pragma omp for Клауза schedule (guided, X) Если клауза schedule(guided, длина_порции) определена, то итерации назначаются потокам
- 46. #pragma omp for Клауза schedule (guided, X) #pragma omp parallel for schedule (dynamic) for ( i=0;
- 47. #pragma omp for Клауза schedule (guided, X) Динамический способ планирования характеризуется тем свойством, что нити не
- 48. #pragma omp for Клауза schedule (guided, X) Подобно динамическому планированию, планирование способом guided гарантирует, что в
- 49. Пример: Директива omp for #include #include int main() { int i; #pragma omp parallel { #pragma
- 50. Пример: Директива omp for #include #include int main() { int i; #pragma omp parallel for for
- 51. Пример: Директива omp sections #include #include int main() { int i; #pragma omp parallel sections private(i)
- 52. Пример: Директива omp single #include #include int main() { int i; #pragma omp parallel private(i) {
- 53. Пример: Директива omp master #include #include int main() { int i; #pragma omp parallel private(i) {
- 54. Способы разделения работы между потоками Параллельное исполнение цикла for #pragma omp for параметры: schedule - распределения
- 55. Пример: Директива omp for #include #include int main() { int i; #pragma omp parallel private(i) {
- 56. Области видимости переменных Переменные, объявленные внутри параллельного блока, являются локальными для потока: #pragma omp parallel {
- 57. Области видимости переменных Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP: private firstprivate lastprivate shared
- 58. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Блокировки omp_lock_t
- 59. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Выполнение кода только главным потоком
- 60. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Критическая секция int x; x
- 61. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Барьер int i; #pragma omp
- 62. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Атомарная операция int i,index[N],x[M]; #pragma
- 63. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Согласование значения переменных между потоками
- 64. Синхронизация потоков Директивы синхронизации потоков: master critical barrier atomic flush ordered Выделение упорядоченного блока в цикле
- 65. Синхронизация потоков Блокировки omp_lock_t void omp_init_lock(omp_lock_t *lock) void omp_destroy_lock(omp_lock_t *lock) void omp_set_lock(omp_lock_t *lock) void omp_unset_lock(omp_lock_t *lock)
- 66. Пример: Использование блокировок #include #include #include int x[1000]; int main() { int i,max; omp_lock_t lock; omp_init_lock(&lock);
- 67. Функции OpenMP void omp_set_num_threads(int num_threads) int omp_get_num_threads(void) int omp_get_max_threads(void) int omp_get_thread_num(void) int omp_get_num_procs(void) int omp_in_parallel(void) void
- 68. Порядок создания параллельных программ Написать и отладить последовательную программу Дополнить программу директивами OpenMP Скомпилировать программу компилятором
- 69. Пример программы: сложение двух векторов Последовательная программа #define N 1000 double x[N],y[N],z[N]; int main() { int
- 70. Пример программы: сложение двух векторов Параллельная программа #include #define N 1000 double x[N],y[N],z[N]; int main() {
- 71. Пример программы: решение краевой задачи Метод Зейделя do { dmax = 0; // максимальное изменение значений
- 72. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock (&dmax_lock); do { dmax = 0; // максимальное
- 73. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock (&dmax_lock); do { dmax = 0; // максимальное
- 74. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock(&dmax_lock); do { dmax = 0; // максимальное изменение
- 75. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock(&dmax_lock); do { dmax = 0; // максимальное изменение
- 76. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock(&dmax_lock); do { dmax = 0; // максимальное изменение
- 77. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock(&dmax_lock); do { dmax = 0; // максимальное изменение
- 78. Пример программы: решение краевой задачи Другие способы устранения зависимостей Четно-нечетное упорядочивание Волновые схемы
- 79. Пример программы: решение краевой задачи omp_lock_t dmax_lock; omp_init_lock(&dmax_lock); do { // максимальное изменение значений u dmax
- 80. Пример программы: решение краевой задачи Волновая схема с разбиением на блоки
- 82. Скачать презентацию
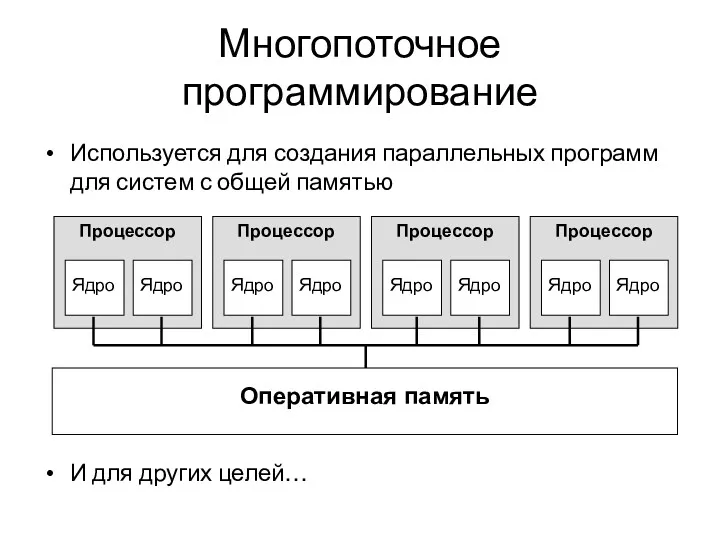
Многопоточное программирование
Используется для создания параллельных программ для систем с общей памятью
И
Многопоточное программирование
Используется для создания параллельных программ для систем с общей памятью
И

Модель памяти OpenMP
Модель разделяемой памяти
Нити взаимодействуют через разделяемые переменные
Разделение определяется
Модель памяти OpenMP
Модель разделяемой памяти
Нити взаимодействуют через разделяемые переменные
Разделение определяется

OpenMP – это…
Стандарт интерфейса для многопоточного программирования над общей памятью
Набор средств
OpenMP – это…
Стандарт интерфейса для многопоточного программирования над общей памятью
Набор средств
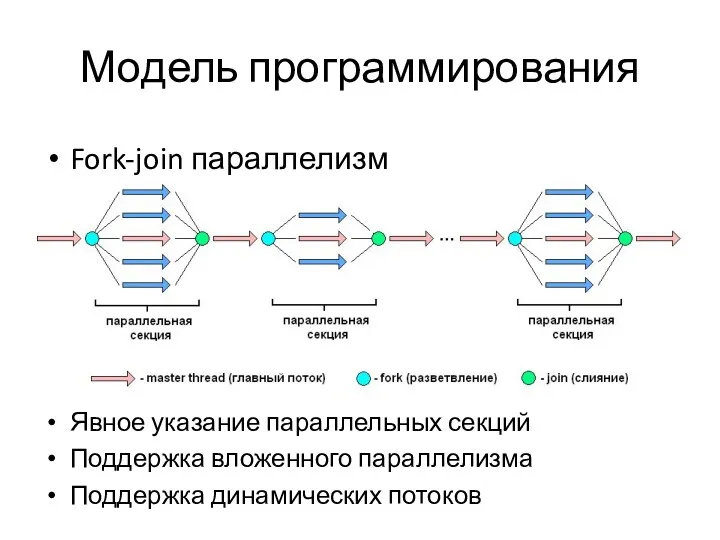
Модель программирования
Fork-join параллелизм
Явное указание параллельных секций
Поддержка вложенного параллелизма
Поддержка динамических потоков
Модель программирования
Fork-join параллелизм
Явное указание параллельных секций
Поддержка вложенного параллелизма
Поддержка динамических потоков
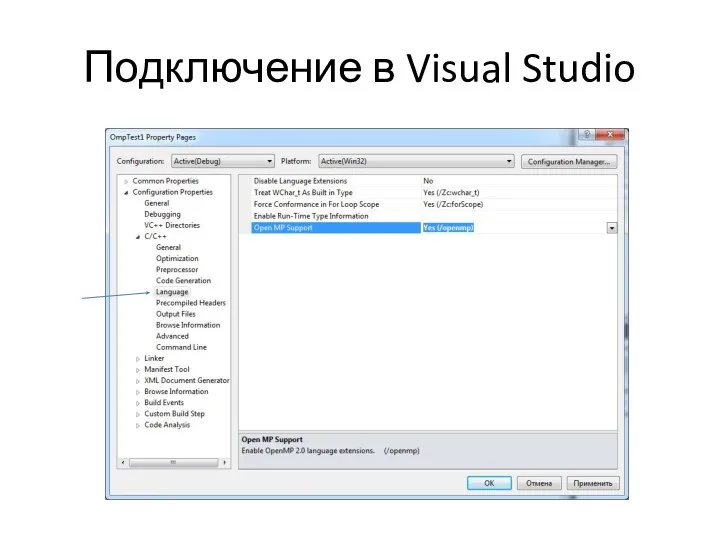
Подключение в Visual Studio
Подключение в Visual Studio
![Формат записи директив и клауз OpenMP #pragma omp имя_директивы [clause,…]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/224520/slide-6.jpg)
Формат записи директив и клауз OpenMP
#pragma omp имя_директивы [clause,…]
#pragma
Формат записи директив и клауз OpenMP
#pragma omp имя_директивы [clause,…]
#pragma

Пример:
Объявление параллельной секции
#include
int main()
{
// последовательный код
#pragma omp
Пример:
Объявление параллельной секции
#include
int main()
{
// последовательный код
#pragma omp

Некоторые функции OpenMP
omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной
Некоторые функции OpenMP
omp_get_thread_num(); - возвращает номер нити типом int. Вне параллельной

Пример:
Hello, World!
#include
#include
int main()
{
printf(“Hello, World!\n”);
#pragma omp parallel
Пример:
Hello, World!
#include
#include
int main()
{
printf(“Hello, World!\n”);
#pragma omp parallel

Задание числа потоков
Переменная среды OMP_NUM_THREADS
Функция omp_set_num_threads(int)
omp_set_num_threads(4);
#pragma omp parallel
{ . . .
}
Параметр(клауза,
Задание числа потоков
Переменная среды OMP_NUM_THREADS
Функция omp_set_num_threads(int)
omp_set_num_threads(4);
#pragma omp parallel
{ . . .
}
Параметр(клауза,

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Своя
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Своя

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Локальная
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Локальная

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Локальная
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Локальная

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Разделяемая
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Разделяемая

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Задание
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Задание

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Переменная
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Переменная

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Объявление
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Объявление

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Объявление
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copyin
Объявление

#pragma omp parallel
Директива определяет параллельную область. Область программы, которая выполняется несколькими
#pragma omp parallel
Директива определяет параллельную область. Область программы, которая выполняется несколькими

#pragma omp parallel
При входе в параллельную область порождаются новые OMP_NUM_THREADS-1 нитей,
#pragma omp parallel
При входе в параллельную область порождаются новые OMP_NUM_THREADS-1 нитей,
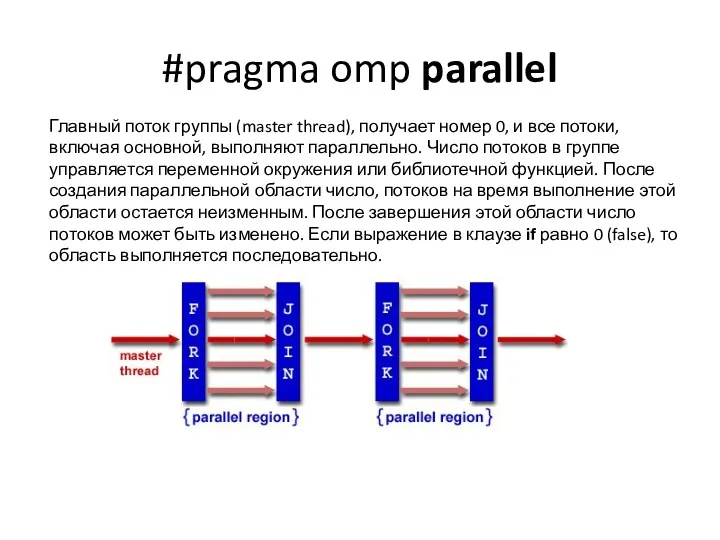
#pragma omp parallel
Главный поток группы (master thread), получает номер 0, и
#pragma omp parallel
Главный поток группы (master thread), получает номер 0, и
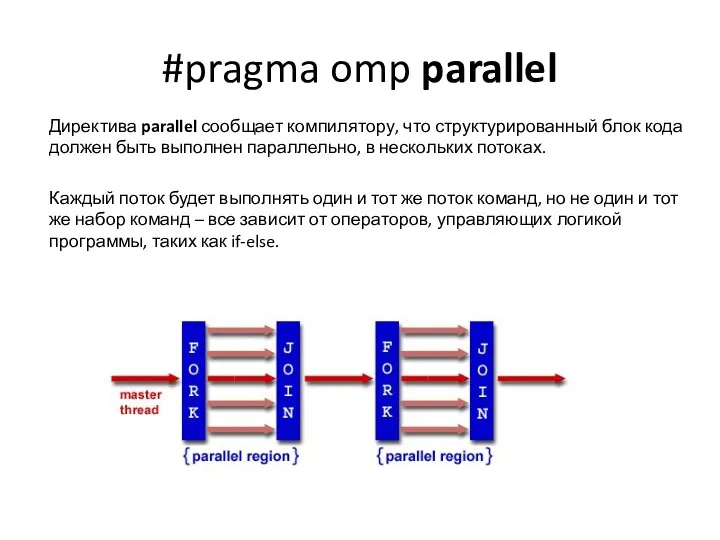
#pragma omp parallel
Директива parallel сообщает компилятору, что структурированный блок кода должен
#pragma omp parallel
Директива parallel сообщает компилятору, что структурированный блок кода должен

#pragma omp parallel
Пример
#include
#include
void test(int val)
{
#pragma omp parallel
#pragma omp parallel
Пример
#include
#include
void test(int val)
{
#pragma omp parallel
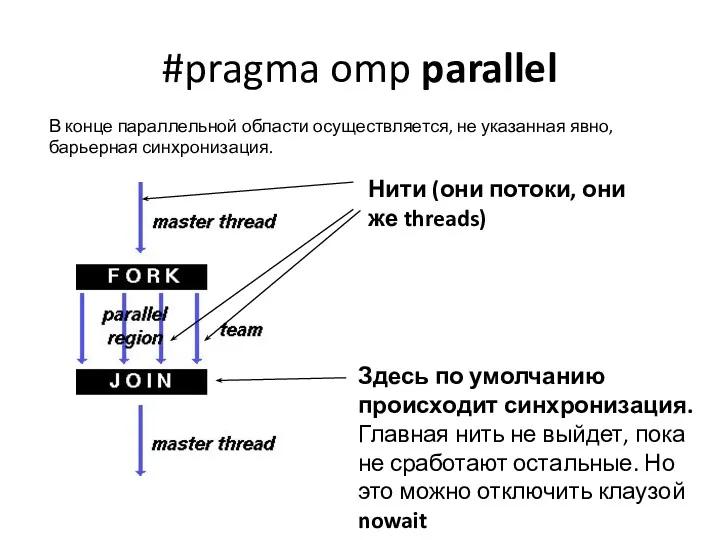
#pragma omp parallel
В конце параллельной области осуществляется, не указанная явно, барьерная
#pragma omp parallel
В конце параллельной области осуществляется, не указанная явно, барьерная

#pragma omp parallel
Клауза одна из следующих:
if (скалярное выражение)
num_threads (целое число)
private (список)
shared
#pragma omp parallel
Клауза одна из следующих:
if (скалярное выражение)
num_threads (целое число)
private (список)
shared

#pragma omp parallel
Клаузы
if (условие) – выполнение параллельной области по условию. Вхождение
#pragma omp parallel
Клаузы
if (условие) – выполнение параллельной области по условию. Вхождение

#pragma omp parallel
Клаузы
shared (список) – задаёт список переменных, общих для всех
#pragma omp parallel
Клаузы
shared (список) – задаёт список переменных, общих для всех

#pragma omp parallel
Если поток в группе, выполняя параллельную область кода, встретит
#pragma omp parallel
Если поток в группе, выполняя параллельную область кода, встретит

#pragma omp parallel
Вложенность. Пример
#include
#include
void report_num_threads(int level)
{
#pragma omp
#pragma omp parallel
Вложенность. Пример
#include
#include
void report_num_threads(int level)
{
#pragma omp

omp_set_nested
Функция omp_set_nested() разрешает или запрещает вложенный параллелизм. В качестве значения параметра
omp_set_nested
Функция omp_set_nested() разрешает или запрещает вложенный параллелизм. В качестве значения параметра

omp_set_dynamic
Omp_set_dynamic функция позволяет включить или отключить динамическую корректировку числа потоков, доступных
omp_set_dynamic
Omp_set_dynamic функция позволяет включить или отключить динамическую корректировку числа потоков, доступных

#pragma omp parallel
Примечания
Если выполнение потока аварийно прерывается внутри параллельной области,
#pragma omp parallel
Примечания
Если выполнение потока аварийно прерывается внутри параллельной области,

#pragma omp parallel
Ограничения
Программа не должна зависеть от какого-либо порядка определения
#pragma omp parallel
Ограничения
Программа не должна зависеть от какого-либо порядка определения

#pragma omp parallel
Распределение работы
OpenMP определяет следующие конструкции распределения работ:
директива for
директива sections
директива
#pragma omp parallel
Распределение работы
OpenMP определяет следующие конструкции распределения работ:
директива for
директива sections
директива
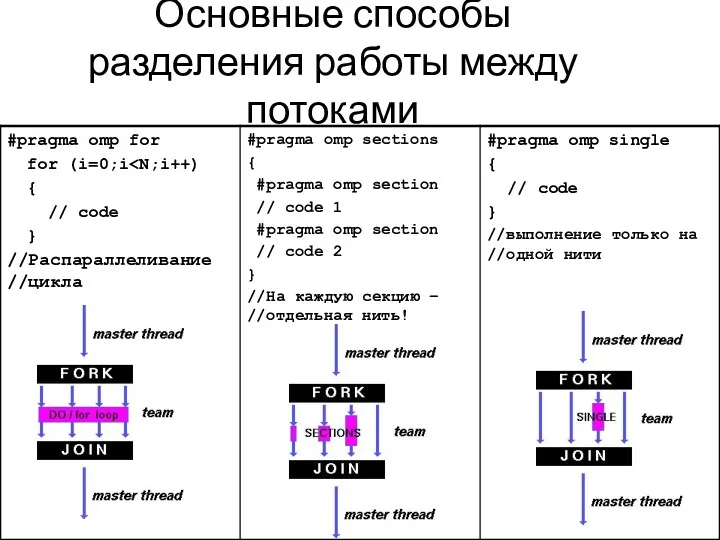
Основные способы разделения работы между потоками
Основные способы разделения работы между потоками

#pragma omp for
Бесконечный цикл — это дать сонному человеку треугольное одеяло.
Автор
#pragma omp for
Бесконечный цикл — это дать сонному человеку треугольное одеяло.
Автор

#pragma omp for
Ограничения
Директива for накладывает ограничения на структуру соответствующего цикла. Определенно,
#pragma omp for
Ограничения
Директива for накладывает ограничения на структуру соответствующего цикла. Определенно,

#pragma omp for
выражение одно из следующих:
var = lb
integer-type var =
#pragma omp for
выражение одно из следующих:
var = lb
integer-type var =

#pragma omp for
Клауза schedule
Клауза schedule определяет, каким образом итерации цикла
#pragma omp for
Клауза schedule
Клауза schedule определяет, каким образом итерации цикла

#pragma omp for
Клауза schedule (static, X)
Если определена клауза schedule(static, длина_порции)
#pragma omp for
Клауза schedule (static, X)
Если определена клауза schedule(static, длина_порции)

#pragma omp for
Клауза schedule (static, X)
Каждый поток получает примерно равное
#pragma omp for
Клауза schedule (static, X)
Каждый поток получает примерно равное

#pragma omp for
Клауза schedule (dynamic, X)
Если определена клауза schedule( dynamic,
#pragma omp for
Клауза schedule (dynamic, X)
Если определена клауза schedule( dynamic,

#pragma omp for
Клауза schedule (dynamic, X)
Во время динамического распределения не
#pragma omp for
Клауза schedule (dynamic, X)
Во время динамического распределения не

#pragma omp for
Клауза schedule (guided, X)
Если клауза schedule(guided, длина_порции) определена,
#pragma omp for
Клауза schedule (guided, X)
Если клауза schedule(guided, длина_порции) определена,

#pragma omp for
Клауза schedule (guided, X)
#pragma omp parallel for schedule
#pragma omp for
Клауза schedule (guided, X)
#pragma omp parallel for schedule

#pragma omp for
Клауза schedule (guided, X)
Динамический способ планирования характеризуется тем
#pragma omp for
Клауза schedule (guided, X)
Динамический способ планирования характеризуется тем

#pragma omp for
Клауза schedule (guided, X)
Подобно динамическому планированию, планирование способом
#pragma omp for
Клауза schedule (guided, X)
Подобно динамическому планированию, планирование способом

Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel

Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel

Пример:
Директива omp sections
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp sections
#include
#include
int main()
{ int i;
#pragma omp parallel

Пример:
Директива omp single
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp single
#include
#include
int main()
{ int i;
#pragma omp parallel

Пример:
Директива omp master
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp master
#include
#include
int main()
{ int i;
#pragma omp parallel

Способы разделения работы между потоками
Параллельное исполнение цикла for
#pragma omp for параметры:
schedule
Способы разделения работы между потоками
Параллельное исполнение цикла for
#pragma omp for параметры:
schedule

Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel
Пример:
Директива omp for
#include
#include
int main()
{ int i;
#pragma omp parallel

Области видимости переменных
Переменные, объявленные внутри параллельного блока, являются локальными для потока:
#pragma
Области видимости переменных
Переменные, объявленные внутри параллельного блока, являются локальными для потока:
#pragma

Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copying
Области видимости переменных
Переменные, объявленные вне параллельного блока, определяются параметрами директив OpenMP:
private
firstprivate
lastprivate
shared
default
reduction
threadprivate
copying

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Блокировки
omp_lock_t
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Блокировки
omp_lock_t
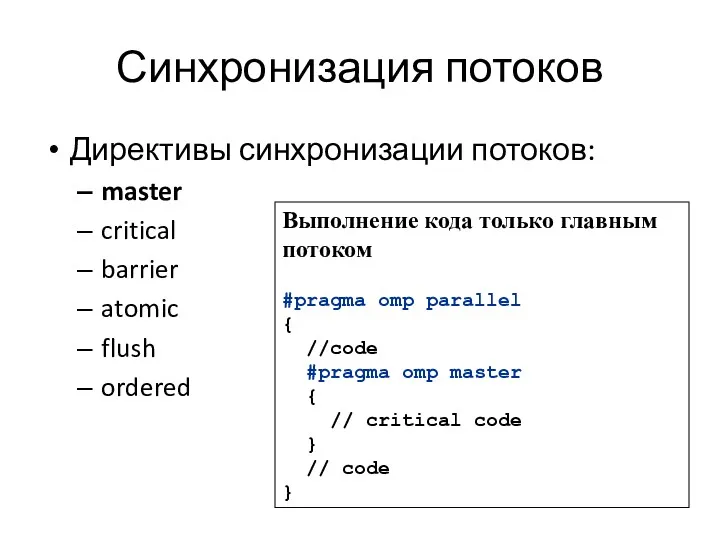
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Выполнение кода только главным потоком
#pragma omp parallel
{
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Выполнение кода только главным потоком
#pragma omp parallel
{

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Критическая секция
int x;
x = 0;
#pragma omp parallel
{
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Критическая секция
int x;
x = 0;
#pragma omp parallel
{

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Барьер
int i;
#pragma omp parallel for
for (i=0;i<1000;i++)
{
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Барьер
int i;
#pragma omp parallel for
for (i=0;i<1000;i++)
{

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Атомарная операция
int i,index[N],x[M];
#pragma omp parallel for \
shared(index,x)
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Атомарная операция
int i,index[N],x[M];
#pragma omp parallel for \
shared(index,x)

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Согласование значения переменных между потоками
int x = 0;
#pragma
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Согласование значения переменных между потоками
int x = 0;
#pragma

Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Выделение упорядоченного блока в цикле
int i,j,k;
double x;
#pragma omp
Синхронизация потоков
Директивы синхронизации потоков:
master
critical
barrier
atomic
flush
ordered
Выделение упорядоченного блока в цикле
int i,j,k;
double x;
#pragma omp

Синхронизация потоков
Блокировки
omp_lock_t
void omp_init_lock(omp_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
int omp_test_lock(omp_lock_t
Синхронизация потоков
Блокировки
omp_lock_t
void omp_init_lock(omp_lock_t *lock)
void omp_destroy_lock(omp_lock_t *lock)
void omp_set_lock(omp_lock_t *lock)
void omp_unset_lock(omp_lock_t *lock)
int omp_test_lock(omp_lock_t
![Пример: Использование блокировок #include #include #include int x[1000]; int main()](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/224520/slide-65.jpg)
Пример:
Использование блокировок
#include
#include
#include
int x[1000];
int main()
{ int i,max;
omp_lock_t lock;
Пример:
Использование блокировок
#include
#include
#include
int x[1000];
int main()
{ int i,max;
omp_lock_t lock;

Функции OpenMP
void omp_set_num_threads(int num_threads)
int omp_get_num_threads(void)
int omp_get_max_threads(void)
int omp_get_thread_num(void)
int
Функции OpenMP
void omp_set_num_threads(int num_threads)
int omp_get_num_threads(void)
int omp_get_max_threads(void)
int omp_get_thread_num(void)
int

Порядок создания параллельных программ
Написать и отладить последовательную программу
Дополнить программу директивами
Порядок создания параллельных программ
Написать и отладить последовательную программу
Дополнить программу директивами

Пример программы: сложение двух векторов
Последовательная программа
#define N 1000
double x[N],y[N],z[N];
int main()
{ int
Пример программы: сложение двух векторов
Последовательная программа
#define N 1000
double x[N],y[N],z[N];
int main()
{ int

Пример программы: сложение двух векторов
Параллельная программа
#include
#define N 1000
double x[N],y[N],z[N];
int main()
{ int
Пример программы: сложение двух векторов
Параллельная программа
#include
#define N 1000
double x[N],y[N],z[N];
int main()
{ int

Пример программы:
решение краевой задачи
Метод Зейделя
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
Метод Зейделя
do {
dmax = 0; // максимальное

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock (&dmax_lock);
do {
dmax = 0; //
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock (&dmax_lock);
do {
dmax = 0; //

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock (&dmax_lock);
do {
dmax = 0; //
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock (&dmax_lock);
do {
dmax = 0; //

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
dmax = 0; // максимальное
Пример программы:
решение краевой задачи
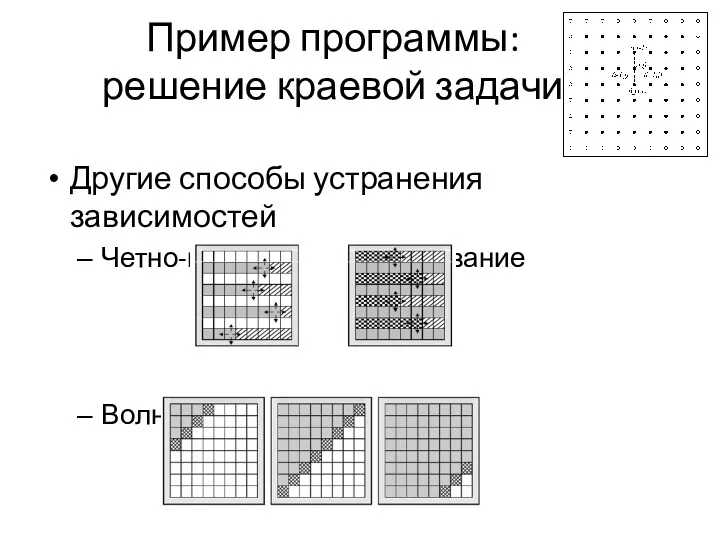
Другие способы устранения зависимостей
Четно-нечетное упорядочивание
Волновые схемы
Пример программы:
решение краевой задачи
Другие способы устранения зависимостей
Четно-нечетное упорядочивание
Волновые схемы

Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
// максимальное изменение значений u
Пример программы:
решение краевой задачи
omp_lock_t dmax_lock;
omp_init_lock(&dmax_lock);
do {
// максимальное изменение значений u
Пример программы:
решение краевой задачи
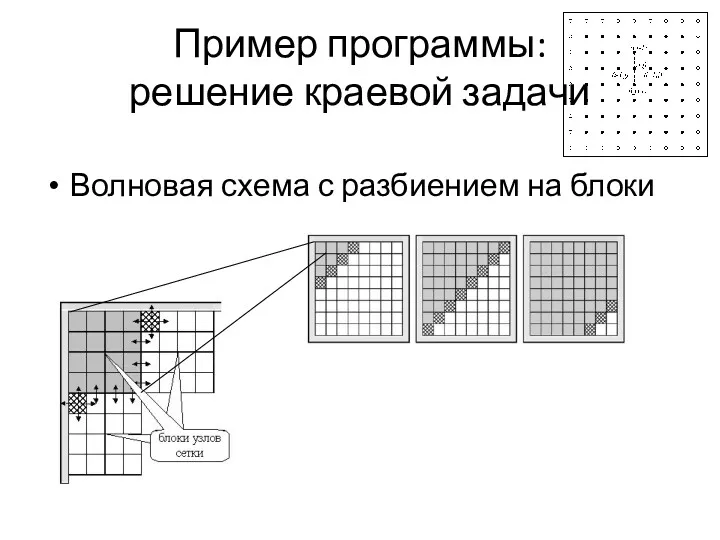
Волновая схема с разбиением на блоки
Пример программы:
решение краевой задачи
Волновая схема с разбиением на блоки
 Введение в курс Manual QA. (Лекция 1.1)
Введение в курс Manual QA. (Лекция 1.1) Программирование Python. Списки (list): Часть 1 Одномерные массивы (Лекция 9)
Программирование Python. Списки (list): Часть 1 Одномерные массивы (Лекция 9) Сучасний підхід до обліку земельного банку від ОМП
Сучасний підхід до обліку земельного банку від ОМП Python. Основы. Работа с файлами. Лекция 11
Python. Основы. Работа с файлами. Лекция 11 ВКР: Разработка прототипа автоматизированного рабочего места диспетчера учебного учреждения
ВКР: Разработка прототипа автоматизированного рабочего места диспетчера учебного учреждения Понятие и основные задачи информатики
Понятие и основные задачи информатики Влияние интернета на культуру и язык учащихся
Влияние интернета на культуру и язык учащихся Деректер базасының архитектурасы
Деректер базасының архитектурасы История серии видеоигр: Crysis, Wolfenstein, Dead Space
История серии видеоигр: Crysis, Wolfenstein, Dead Space Позиционирование и продвижение в соцсетях
Позиционирование и продвижение в соцсетях Лекция 1. Основные понятия баз данных и СУБД
Лекция 1. Основные понятия баз данных и СУБД Работа с файлами. Глава 5
Работа с файлами. Глава 5 Неиерархические классификации
Неиерархические классификации Информационная система автоматизированного управления работой сервиса по ремонту автомобилей
Информационная система автоматизированного управления работой сервиса по ремонту автомобилей Базы данных и SQL. Семинар 3
Базы данных и SQL. Семинар 3 Вкладені алгоритмічні структури повторення з передумовою та лічильником
Вкладені алгоритмічні структури повторення з передумовою та лічильником Основные процессы жизненного цикла АИС
Основные процессы жизненного цикла АИС Растровая и векторная графика
Растровая и векторная графика Written Scientific and Technical Communication
Written Scientific and Technical Communication Аптека 1С:Розница 8
Аптека 1С:Розница 8 Informasion prosesler: informasiýalary saklamak, geçirmek, täzeden işlemek, gözlemek
Informasion prosesler: informasiýalary saklamak, geçirmek, täzeden işlemek, gözlemek Создание программного продукта генерации бланковых тестов
Создание программного продукта генерации бланковых тестов Представление числовой информации с помощью систем счисления Урок информатики в 10 классе
Представление числовой информации с помощью систем счисления Урок информатики в 10 классе Git Система контроля версий
Git Система контроля версий Испытания РЭА в процессе производства и эксплуатации
Испытания РЭА в процессе производства и эксплуатации Искусственный интеллект как субъект трудового права: реально или нет?
Искусственный интеллект как субъект трудового права: реально или нет? Безопасный Интернет
Безопасный Интернет Виды базы данных
Виды базы данных