- Python. Основы. Работа с файлами. Лекция 11

Содержание
- 2. Чаще всего данные для обработки поступают из внешних источников – файлов. Существуют различные форматы файлов, наиболее
- 3. Работа с файлами в Python Обыкновенные текстовые файлы Операции с файлами Текстовые файлы Обыкновенные текстовые файлы
- 4. Работа с текстовыми файлами
- 5. Работа с файлами
- 6. file = open('example_text.txt', 'r') contents = file.read() print(contents) file.close() Чтение данных из файла
- 7. Список режимов доступа к файлу в Python
- 8. Атрибуты файлового объекта в Python Как только файл был открыт и у вас появился файловый объект,
- 9. my_file = open("some.txt", "w") print("Имя файла: ", my_file.name) print("Файл закрыт: ", my_file.closed) print("В каком режиме файл
- 10. my_file = open("myFile.txt", "w+") my_file.write("Привет, файл! ") my_file.close() Создание текстового файла В начале объявляется переменная my_file.
- 11. my_file = open("myFile.txt", "a+") my_file.write("Добавляем новый текст") my_file.close() Если нужно добавить новые данные в файл, тогда
- 12. my_file = open("myFile.txt", "a+") file_contents == my_file.read() print(file_contents) Чтение данных из созданного нами файла Привет, файл!
- 13. Создать файл my_file = open("file.txt", "w+") Записать в файл my_file.write("Привет, файл!") Сохранить и закрыть файл my_file.close()
- 14. Существует много способов чтение из файла построчно в Python. Можно считать строки в список или обращаться
- 15. Открываем файл в режиме чтения. При этом возвращается дескриптор файла. Создаём бесконечный цикл while. В каждой
- 16. # получим объект файла file1 = open("sample.txt", "r") while True: # считываем строку line = file1.readline()
- 17. Функция readlines() возвращает все строки файла в виде списка. Пройдясь по списку и получить доступ к
- 18. # получим объект файла file1 = open("sample.txt", "r") # считываем все строки lines = file1.readlines() #
- 19. В предыдущем примере, мы считываем каждую строку файла при помощи бесконечного цикла while и функции readline().
- 20. Операции с файлами (удаление, перемещение)
- 21. Обработка файлов в Python выполняется с помощью стандартного модуля os включает создание, переименование, перемещение, удаление файлов
- 22. Для получения текущего рабочего каталога используется os.getcwd(): import os # вывести текущую директорию print("Текущая деректория:", os.getcwd())
- 23. Для создания папки/каталога в любой операционной системе нужна следующая команда: # создать пустой каталог (папку) os.mkdir("folder")
- 24. Если запустить ее еще раз, будет вызвана ошибка FileExistsError, потому что такая папка уже есть. Для
- 25. Менять директории довольно просто. Проделаем это с только что созданным: # изменение текущего каталога на 'folder'
- 26. Предположим, вы хотите создать не только одну папку, но и несколько вложенных: # вернуться в предыдущую
- 27. Для создания файлов в Python модули не нужны. Можно использовать встроенную функцию open(). Она принимает название
- 28. С помощью модуля os достаточно просто переименовать файл. Поменяем название созданного в прошлом шаге. # переименовать
- 29. Функцию os.replace() можно использовать для перемещения файлов или каталогов: # заменить (переместить) этот файл в другой
- 30. # распечатать все файлы и папки в текущем каталоге print("Все папки и файлы:", os.listdir()) Функция os.listdir()
- 31. А что если нужно узнать состав и этих папок тоже? Для этого нужно использовать функцию os.walk():
- 32. Модуль os предоставляет множество функций для работы с операционной системой, причём их поведение, как правило, не
- 33. os.access(path, mode, *, dir_fd=None, effective_ids=False, follow_symlinks=True) - проверка доступа к объекту у текущего пользователя. Флаги: os.F_OK
- 34. os.link(src, dst, *, src_dir_fd=None, dst_dir_fd=None, follow_symlinks=True) - создаёт жёсткую ссылку. os.listdir(path=".") - список файлов и директорий
- 35. os.replace(src, dst, *, src_dir_fd=None, dst_dir_fd=None) - переименовывает из src в dst с принудительной заменой. os.rmdir(path, *,
- 36. os.walk(top, topdown=True, onerror=None, followlinks=False) - генерация имён файлов в дереве каталогов, сверху вниз (если topdown равен
- 37. Работа с текстовыми файлами в формате CSV, JSON
- 38. CSV (от англ. Comma-Separated Values — значения, разделённые запятыми) — текстовый формат, предназначенный для представления табличных
- 39. CSV (от англ. Comma-Separated Values — значения, разделённые запятыми)
- 40. CSV — текстовой формат, ориентированный на работу с данными несложных электронных таблиц, хранящихся в обычных тестовых
- 41. Файл example.csv, из которого будем читать: 05.04.2015 13:34;Яблоки;73 05.04.2015 3:41;Вишни;85 06.04.2015 12:46;Груши;14 Чтение CSV-файлов
- 42. Чтобы прочитать данные из CSV-файла, необходимо создать объект Reader, который обеспечивает возможность итерирования по строкам файла:
- 43. Теперь, когда у нас есть список списков, можно обращаться к отдельным ячейкам с помощью exampleData[row][col]. В
- 44. import csv exampleFile = open('example.csv', encoding = 'UTF-8') exampleReader = csv.reader(exampleFile, delimiter = ';') for row
- 45. import csv exampleFile = open('output.csv', 'w', encoding = 'UTF-8’, newline = '') exampleWriter = csv.writer(exampleFile, delimiter
- 46. JSON (JavaScript Object Notation)
- 47. JSON (JavaScript Object Notation) — текстовый формат обмена данными, удобный для чтения и написания как человеком,
- 48. Файлы в формате JSON имеют несколько преимуществ по сравнению с CSV-файлами. JSON поддерживает иерархические структуры, упрощая
- 49. В нотации JSON это выглядит так: Объект — неупорядоченный набор пар ключ-значение. Объект начинается с {
- 50. Массив — упорядоченная коллекция значений. Массив начинается с [ и заканчивается ]. Значения разделены запятой. ["ivanov@mail.ru",
- 51. Строка — коллекция нуля или больше символов Unicode, заключенная в двойные кавычки, используя \ (обратную косую
- 52. Модуль json позволяет легко записывать и читать данные в формате JSON. Для чтения данных в JSON-формате
- 53. JSON - Таблица конвертации данных
- 54. import json string = '{"id":765, "email":"ivanov@mail.ru", "surname":"Иванов", "age":45, "admin":false, "friends":[123,456,789]}' data = json.loads(string) print(data["email"]) print(data["surname"]) print(data["admin"])
- 55. import json # читаем json-данные из файла и преобразуем в словарь with open('data.json', encoding = 'UTF-8')
- 56. import json data = {"id":765, "email":"ivanov@mail.ru", "surname":"Иванов", "age":45, "admin":False, "friends":[123,456,789]} # преобразуем словарь в json-строку string
- 57. import json data = {"id":765, "email":"ivanov@mail.ru", "surname":"Иванов", "age":45, "admin":False, "friends":[123,456,789]} # преобразуем словарь в json и
- 58. Преобразуем словарь в json и записываем в файл
- 59. Работа с файлами Word Библиотека Python-Docx
- 60. Официальный сайт библиотеки Python-Docx https://python-docx.readthedocs.io/en/latest/ Библиотека Python-Docx
- 61. Работа с файлами MS Word в Python (С помощью модуля python-docx) https://tokmakov.msk.ru/blog/item/78 Документация по модулю python-docx
- 62. Работа с файлами Excel
- 63. http://www.python-excel.org/ Openpyxl - The recommended package for reading and writing Excel 2010 files (ie: .xlsx) Download
- 64. Официальный сайт библиотеки openpyxl https://openpyxl.readthedocs.io/en/stable/ Библиотека openpyxl
- 65. Pandas — программная библиотека на языке Python для обработки и анализа данных https://pandas.pydata.org/ Библиотека pandas
- 66. Библиотека XlsxWriter https://xlsxwriter.readthedocs.io/ Библиотека XlsxWriter
- 67. Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды
- 68. Работа с файлами PDF Библиотека Для работы с PDF форматов существует большое количество библиотек
- 69. PyPDF2 — библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц
- 70. PDFMiner — это инструмент для извлечения информации из PDF-документов. В отличие от других инструментов, связанных с
- 71. PDFQuery — позиционируется как «быстрая и удобная библиотека чистого PDF» и реализована как оболочка для PDFMiner,
- 72. tabula-py — простая оболочка Python для tabula-java, которая может читать таблицы из PDF‑файлов и преобразовывать их
- 73. pdflib — расширение библиотеки Poppler, которое позволяет анализировать и конвертировать PDF‑документы. Не следует его путать с
- 74. PyFPDF — библиотека для создания документов PDF под Python. Портировано из библиотеки FPDF (PHP), известной замены
- 75. PDFTables — коммерческий сервис, предлагающий извлечение данных из таблиц документов PDF. Предлагает API, позволяющий использовать PDFTables
- 76. PyX — графический пакет Python для создания файлов PostScript, PDF и SVG. Он сочетает в себе
- 77. ReportLab — амбициозная промышленная библиотека, в основном ориентированная на оздание высококачественных PDF‑документов. Доступны как свободная версия
- 78. PyMuPDF (он же «fitz») — привязка Python для MuPDF, который является облегченным средством просмотра PDF и
- 79. pdfrw — чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит
- 80. КУТУЗОВ Виктор Владимирович Благодарю за внимание Белорусско-Российский университет, Республика Беларусь, Могилев, 2021 Информатика. Программирование на Python
- 81. Python https://www.python.org/ Google Colaboratory https://colab.research.google.com/ Федоров, Д. Ю. Программирование на языке высокого уровня Python : учеб.
- 82. Википедия CSV формат https://ru.wikipedia.org/wiki/CSV Работа с CSV-файлами в Python https://tokmakov.msk.ru/blog/item/83 Работа с CSV- и JSON-файлами в
- 83. Официальный сайт библиотеки openpyxl https://openpyxl.readthedocs.io/en/stable/ Библиотека XlsxWriter https://xlsxwriter.readthedocs.io/ Pandas https://pandas.pydata.org/ Создание информативных и красивых Excel документов.
- 84. Работа с PDF-файлами в Python (часть I): чтение и разбор https://chel-center.ru/python-yfc/2020/02/17/rabota-s-pdf-fajlami-v-python-chast-i-chtenie-i-razbor/ Работа с PDF-файлами https://chel-center.ru/python-yfc/category/rabota-s-pdf-afjlami/ pip
- 85. github pdfquery https://github.com/jcushman/pdfquery github tabula-py https://github.com/chezou/tabula-py tabula-py Docs https://tabula-py.readthedocs.io/en/latest/ tabula-py Docs PDF https://readthedocs.org/projects/tabula-py/downloads/pdf/latest/ github pdflib https://github.com/alephdata/pdflib
- 86. PyX — Python graphics package https://pyx-project.org/ PyX Docs https://pyx-project.org/manual/index.html PyX Gallery https://sourceforge.net/p/pyx/gallery/index/ ReportLab https://www.reportlab.com ReportLab Documentation
- 88. Скачать презентацию
 Анализ программной поддержки периферийных устройств
Анализ программной поддержки периферийных устройств Табличное решение логических задач. (§ 2.6. 7 класс)
Табличное решение логических задач. (§ 2.6. 7 класс) Мультимедиа технологии. Технологии виртуальной реальности
Мультимедиа технологии. Технологии виртуальной реальности Разработка web-приложений для мобильных систем
Разработка web-приложений для мобильных систем Динамические массивы
Динамические массивы Исполнитель Чертежник. Вспомогательные алгоритмы
Исполнитель Чертежник. Вспомогательные алгоритмы Обзор программы Figm
Обзор программы Figm Язык Python в школьном курсе информатики
Язык Python в школьном курсе информатики Обработка текстовой информации
Обработка текстовой информации Подпрограммы. Выполнение подпрограмм
Подпрограммы. Выполнение подпрограмм Операционная система. Графический интерфейс
Операционная система. Графический интерфейс Кіріспе. Java тілі туралы түсінік
Кіріспе. Java тілі туралы түсінік Использование триггеров для создания интерактивных презентаций
Использование триггеров для создания интерактивных презентаций Общие понятия теории графов
Общие понятия теории графов Устройство компьютера
Устройство компьютера Анимация в WinForms
Анимация в WinForms Программирование на языке Python. Базовый уровень. Модуль 1. Введение в программирование. Тема 1.5. Типы данных (занятие 1)
Программирование на языке Python. Базовый уровень. Модуль 1. Введение в программирование. Тема 1.5. Типы данных (занятие 1) League of dance
League of dance Система электронного документооборота (СЭД) в органах государственной власти
Система электронного документооборота (СЭД) в органах государственной власти Проектирование баз данных. Преобразования запросов
Проектирование баз данных. Преобразования запросов Отмечалка. Система автоматизации учета посетителей в спортивных и обучающих центрах
Отмечалка. Система автоматизации учета посетителей в спортивных и обучающих центрах Машинно-зависимые языки и основы компиляции
Машинно-зависимые языки и основы компиляции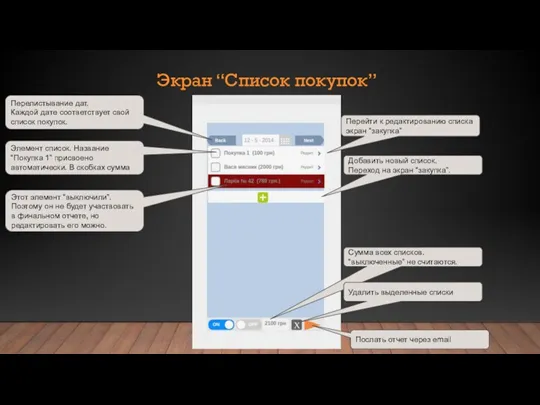 Экран “Список покупок”
Экран “Список покупок” Устройство компьютера. Принципы устройства компьютеров
Устройство компьютера. Принципы устройства компьютеров Анализ современных требований по обеспечению информационной безопасности телекоммуникационных систем цифровой железной дороги
Анализ современных требований по обеспечению информационной безопасности телекоммуникационных систем цифровой железной дороги Создание документа. Форматирование абзацев
Создание документа. Форматирование абзацев Информационная безопасность в сети Интернет
Информационная безопасность в сети Интернет Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (внутренний проезд)
Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (внутренний проезд)