- Поиск подстрок

Содержание
- 2. Определения Алфавит – конечное множество символов. Строка (слово) – это последовательность символов из некоторого алфавита. Длина
- 3. Определения Строка X называется подстрокой строки Y, если найдутся такие строки Z1 и Z2, что Y=Z1XZ2.
- 4. Постановка задачи Есть образец и строка, надо определить индекс, начиная с которого образец содержится в строке.
- 5. Пример Дана последовательность символов x[1]..x[n]. Определить, встречаются ли в ней идущие друг за другом символы "abcd".
- 6. Простой алгоритм Решение. Имеется примерно n (если быть точным, n-3) позиций, на которых может находиться искомая
- 7. Применение простого алгоритма
- 8. Алгоритм Рабина-Карпа Пусть алфавит D={0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, то есть
- 9. 23590(mod 13)=8, 35902(mod 13)=9, 59023(mod 13)=9, … k1=31415 (mod 13) ≡7– вхождение образца, k2=67399(mod 13) ≡
- 10. Хеш функция Ключ к производительности алгоритма Рабина — Карпа - низкая вероятность коллизий и эффективное вычисление
- 11. Алгоритм Рабина-Карпа Для ускорения модульной арифметики q выбирают равным степени двойки минус один (так называемые простые
- 12. Алгоритм Рабина-Карпа Для быстрого вычисления р используют схему Горнера: P[1..m]- образец, р – число, которое является
- 13. Алгоритм Рабина-Карпа Т[1..n]- текст, ts – число, которое является десятичной записью T[s+1..s+m]. Если вычислено ts ,
- 14. Алгоритм Рабина-Карпа n=length[T] m=length[P] h= dm-1 mod q p=0 t0 = 0 For i=1 to m
- 15. Алгоритм Рабина-Карпа(продолжение) For s=0 to n-m { if p== ts if P[1..m]== T[s+1..s+m] print образец входит
- 16. Временная сложность алгоритма Рабина-Карпа O(n)+O(mv), v – количество вхождений образца в текст
- 17. Поиск подстрок с помощью конечных автоматов(abcd) при чтении слова x слева направо мы в каждый момент
- 18. Конечные автоматы Читая очередную букву, мы переходим в следующее состояние по правилу:
- 19. Алгоритм состояние буква состояние 0 a 1 0 кроме a 0 1 b 2 1 a
- 20. Фрагмент алгоритма1 i=1; state=0; {i - первая непрочитанная буква, state - состояние} while (i n+1) and
- 21. Фрагмент алгоритма2 else { state= 0; } } else if state = 1 { if x[i]
- 22. Фрагмент алгоритма3 { state= 0; } }else if state == 2 { if x[i] == ‘c’
- 23. Фрагмент алгоритма4 }else if state == 3 { if x[i] == ‘d’ { state= 4; }
- 24. Усовершенствованный алгоритм Написать программу, которая ищет произвольный образец в произвольном слове. Это можно делать в два
- 25. Алгоритм Кнута - Морриса – Пратта (КМП) Работает за время O(m+n), где m – длина образца,
- 26. КМП Длина наиболее длинного префикса, являющегося одновременно суффиксом есть префикс-функция от строки. Префикс –функция заданного образца
- 27. π-функция Алгоритм вычисления Символы строк нумеруются с 1. Пусть π(S,i) = k. Попробуем вычислить префикс-функцию для
- 28. π-функция При S[i + 1] = S[k + 1] — положить π(S,i + 1) = k
- 29. Пример Для строки 'abcdabscabcdabia' вычисление будет таким: 'a'!='b' => π=0;(длина строки 2; строка ab ) 'a'!='c'
- 30. Пример 'a'=='a' => π=π+1=1; (длина строки 8; строка abcdаbsса) 'b'=='b' => π=π+1=2; (длина строки 9; строка
- 31. Пример реализации Пример. (Символы, подвергшиеся сравнению, подчеркнуты.)
- 32. Алгоритм КМП-поиска После частичного совпадения начальной части образца W с соответствующими символами строки Т фактически известна
- 33. Алгоритм КМП Идея КМП-поиска – при каждом несовпадении двух символов текста и образца образец сдвигается на
- 34. Z- функция Пусть ищется строка S1 в строке S2. Построим строку S= S1$S2, где $ —
- 35. Алгоритм поиска строки Бойера —Мура Был разработан Робертом Бойером и и Джеем Муром в 1977г. Считается
- 36. Описание алгоритма. Алгоритм основан на трёх идеях Сканирование слева направо, сравнение справа налево. 2. Эвристика стоп-символа.
- 37. Сканирование слева направо, сравнение справа налево. Совмещается начало текста (строки) и шаблона, проверка начинается с последнего
- 38. Сканирование слева направо, сравнение справа налево Если какой-то символ шаблона не совпадает с соответствующим символом строки,
- 39. Эвристика стоп-символа. Пример: поиск слова «колокол». Пусть первая же буква не совпала — «к» (назовём эту
- 40. Эвристика стоп-символа. Если стоп-символа в шаблоне вообще нет, шаблон смещается за этот стоп-символ. Строка: * *
- 41. Эвристика стоп-символа. Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа не работает Строка: *
- 42. Эвристика совпавшего суффикса Если при сравнении строки и шаблона совпало один или больше символов, шаблон сдвигается
- 43. Алгоритм Бойера —Мура Обе эвристики требуют предварительных вычислений. По шаблону поиска заполняются две таблицы. Таблица стоп-символов
- 44. Таблица стоп-символов В таблице стоп-символов указывается последняя позиция в образце (исключая последнюю букву) каждого из символов
- 45. Таблица стоп-символов образец =«abcdadcd» Символ a b c d [остальные] Последняя позиция 5 2 7 6
- 46. Таблица суффиксов Для каждого возможного суффикса S шаблона указывается наименьшая величина, на которую нужно сдвинуть вправо
- 47. Таблица суффиксов Например, для «abcdadcd» Суффикс [пустой] d cd dcd ... abcdadcd Сдвиг 1 2 4
- 48. Таблица суффиксов Если шаблон начинается и заканчивается одной и той же комбинацией букв, |шаблон| вообще не
- 49. Быстрый алгоритм вычисления таблицы суффиксов Использует префикс-функцию строки m = length(suff) pi[] = префикс-функция(suff) pi1[] =
- 50. Быстрый алгоритм вычисления таблицы суффиксов suffshift[0] соответствует всей совпавшей строке; suffshift[m] — пустому суффиксу. Так как
- 51. Пример работы алгоритма БМ Искомый шаблон — «abbad». Таблица стоп-символов: Символ a b [остальные] Позиция 4
- 52. Пример работы алгоритма БМ Накладываем образец на строку. abeccaabadbabbad abbad Совпадения суффикса нет — таблица суффиксов
- 53. Пример работы алгоритма БМ аbeccaabadbabbad abbad Символы 3—5 совпали, а второй — нет. Эвристика стоп-символа для
- 54. Пример работы алгоритма БМ аbeccaabadbabbad abbad Совпадения суффикса нет. По таблице стоп-символов сдвигаем образец на 1
- 55. Алгоритм Бойера-Мура Достоинства Алгоритм Бойера-Мура на «хороших» данных очень быстр, а вероятность появления «плохих» данных крайне
- 56. Алгоритм Бойера-Мура Недостатки не расширяются до приблизительного поиска, поиска любой строки из нескольких. Не рекомендуют использовать
- 58. Скачать презентацию

Определения
Алфавит – конечное множество символов.
Строка (слово) – это последовательность символов из
Определения
Алфавит – конечное множество символов.
Строка (слово) – это последовательность символов из

Определения
Строка X называется подстрокой строки Y, если найдутся такие строки Z1
Определения
Строка X называется подстрокой строки Y, если найдутся такие строки Z1

Постановка задачи
Есть образец и строка, надо определить индекс, начиная с которого
Постановка задачи
Есть образец и строка, надо определить индекс, начиная с которого
![Пример Дана последовательность символов x[1]..x[n]. Определить, встречаются ли в ней](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-4.jpg)
Пример
Дана последовательность символов x[1]..x[n]. Определить, встречаются ли в ней идущие друг
Пример
Дана последовательность символов x[1]..x[n]. Определить, встречаются ли в ней идущие друг

Простой алгоритм
Решение. Имеется примерно n (если быть точным, n-3) позиций, на
Простой алгоритм
Решение. Имеется примерно n (если быть точным, n-3) позиций, на
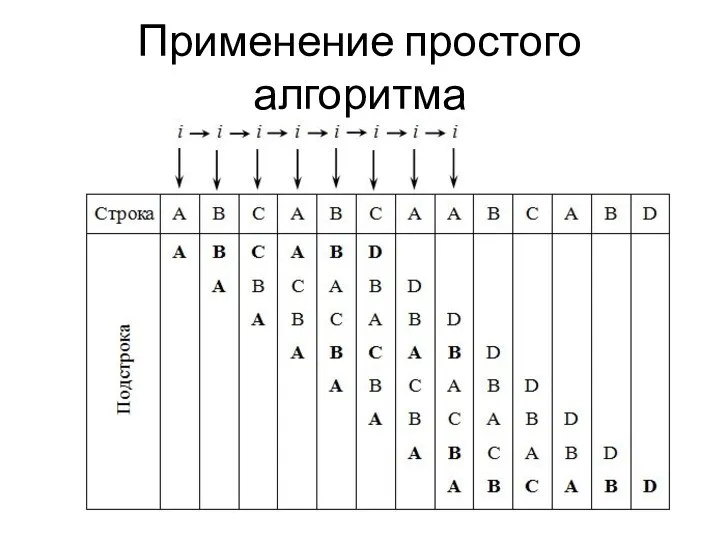
Применение простого алгоритма
Применение простого алгоритма

Алгоритм Рабина-Карпа
Пусть алфавит D={0, 1, 2, 3, 4, 5, 6, 7,
Алгоритм Рабина-Карпа
Пусть алфавит D={0, 1, 2, 3, 4, 5, 6, 7,

23590(mod 13)=8, 35902(mod 13)=9, 59023(mod 13)=9, …
k1=31415 (mod 13) ≡7– вхождение
23590(mod 13)=8, 35902(mod 13)=9, 59023(mod 13)=9, … k1=31415 (mod 13) ≡7– вхождение

Хеш функция
Ключ к производительности алгоритма Рабина — Карпа - низкая вероятность
Хеш функция
Ключ к производительности алгоритма Рабина — Карпа - низкая вероятность

Алгоритм Рабина-Карпа
Для ускорения модульной арифметики q выбирают равным степени двойки минус
Алгоритм Рабина-Карпа
Для ускорения модульной арифметики q выбирают равным степени двойки минус
![Алгоритм Рабина-Карпа Для быстрого вычисления р используют схему Горнера: P[1..m]-](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-11.jpg)
Алгоритм Рабина-Карпа
Для быстрого вычисления р используют схему Горнера:
P[1..m]- образец, р –
Алгоритм Рабина-Карпа
Для быстрого вычисления р используют схему Горнера:
P[1..m]- образец, р –
![Алгоритм Рабина-Карпа Т[1..n]- текст, ts – число, которое является десятичной](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-12.jpg)
Алгоритм Рабина-Карпа
Т[1..n]- текст, ts – число, которое является десятичной записью T[s+1..s+m].
Если
Алгоритм Рабина-Карпа
Т[1..n]- текст, ts – число, которое является десятичной записью T[s+1..s+m].
Если
![Алгоритм Рабина-Карпа n=length[T] m=length[P] h= dm-1 mod q p=0 t0](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-13.jpg)
Алгоритм Рабина-Карпа
n=length[T]
m=length[P]
h= dm-1 mod q
p=0
t0 = 0
For i=1 to m
{p= (d
Алгоритм Рабина-Карпа
n=length[T]
m=length[P]
h= dm-1 mod q
p=0
t0 = 0
For i=1 to m
{p= (d

Алгоритм Рабина-Карпа(продолжение)
For s=0 to n-m
{ if p== ts
if P[1..m]== T[s+1..s+m]
Алгоритм Рабина-Карпа(продолжение)
For s=0 to n-m
{ if p== ts
if P[1..m]== T[s+1..s+m]

Временная сложность алгоритма Рабина-Карпа
O(n)+O(mv),
v – количество вхождений образца в текст
Временная сложность алгоритма Рабина-Карпа
O(n)+O(mv),
v – количество вхождений образца в текст

Поиск подстрок с помощью конечных автоматов(abcd)
при чтении слова x слева направо
Поиск подстрок с помощью конечных автоматов(abcd)
при чтении слова x слева направо

Конечные автоматы
Читая очередную букву, мы переходим в
следующее состояние по правилу:
<Текущее состояние>
Конечные автоматы
Читая очередную букву, мы переходим в
следующее состояние по правилу:
<Текущее состояние>

Алгоритм
состояние буква состояние
0 a 1
0 кроме a 0
1 b 2
1 a
Алгоритм
состояние буква состояние 0 a 1 0 кроме a 0 1 b 2 1 a

Фрагмент алгоритма1
i=1; state=0;
{i - первая непрочитанная буква, state - состояние}
while (i
Фрагмент алгоритма1
i=1; state=0; {i - первая непрочитанная буква, state - состояние} while (i

Фрагмент алгоритма2
else {
state= 0;
}
} else if state = 1 {
if x[i]
Фрагмент алгоритма2
else { state= 0; } } else if state = 1 { if x[i]

Фрагмент алгоритма3
{
state= 0;
}
}else if state == 2 {
if x[i] == ‘c’
Фрагмент алгоритма3
{ state= 0; } }else if state == 2 { if x[i] == ‘c’
![Фрагмент алгоритма4 }else if state == 3 { if x[i]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-22.jpg)
Фрагмент алгоритма4
}else if state == 3 {
if x[i] == ‘d’ {
state=
Фрагмент алгоритма4
}else if state == 3 { if x[i] == ‘d’ { state=

Усовершенствованный алгоритм
Написать программу, которая ищет произвольный образец в произвольном слове.
Усовершенствованный алгоритм
Написать программу, которая ищет произвольный образец в произвольном слове.

Алгоритм Кнута - Морриса – Пратта (КМП)
Работает за время O(m+n), где
Алгоритм Кнута - Морриса – Пратта (КМП)
Работает за время O(m+n), где

КМП
Длина наиболее длинного префикса, являющегося одновременно суффиксом есть префикс-функция от строки.
Префикс –функция заданного
КМП
Длина наиболее длинного префикса, являющегося одновременно суффиксом есть префикс-функция от строки.
Префикс –функция заданного

π-функция
Алгоритм вычисления
Символы строк нумеруются с 1.
Пусть π(S,i) = k. Попробуем вычислить префикс-функцию для i +
π-функция
Алгоритм вычисления
Символы строк нумеруются с 1.
Пусть π(S,i) = k. Попробуем вычислить префикс-функцию для i +
![π-функция При S[i + 1] = S[k + 1] —](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-27.jpg)
π-функция
При S[i + 1] = S[k + 1] — положить π(S,i + 1) = k + 1.
Иначе при k = 0 — положить π(S,i +
π-функция
При S[i + 1] = S[k + 1] — положить π(S,i + 1) = k + 1.
Иначе при k = 0 — положить π(S,i +

Пример
Для строки 'abcdabscabcdabia' вычисление будет таким:
'a'!='b' => π=0;(длина строки 2; строка ab )
'a'!='c'
Пример
Для строки 'abcdabscabcdabia' вычисление будет таким:
'a'!='b' => π=0;(длина строки 2; строка ab )
'a'!='c'

Пример
'a'=='a' => π=π+1=1; (длина строки 8; строка abcdаbsса)
'b'=='b' => π=π+1=2; (длина
Пример
'a'=='a' => π=π+1=1; (длина строки 8; строка abcdаbsса)
'b'=='b' => π=π+1=2; (длина
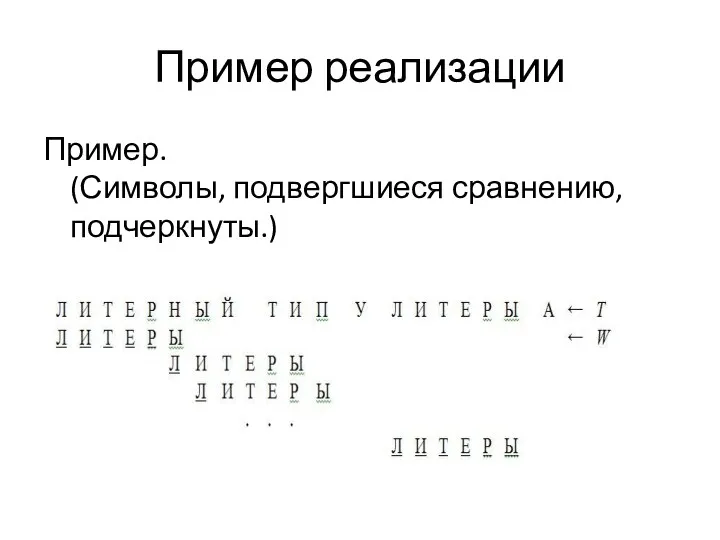
Пример реализации
Пример.
(Символы, подвергшиеся сравнению, подчеркнуты.)
Пример реализации
Пример.
(Символы, подвергшиеся сравнению, подчеркнуты.)

Алгоритм КМП-поиска
После частичного совпадения начальной части образца W с соответствующими
Алгоритм КМП-поиска
После частичного совпадения начальной части образца W с соответствующими

Алгоритм КМП
Идея КМП-поиска – при каждом несовпадении двух символов текста и
Алгоритм КМП
Идея КМП-поиска – при каждом несовпадении двух символов текста и

Z- функция
Пусть ищется строка S1 в строке S2. Построим строку S=
Z- функция
Пусть ищется строка S1 в строке S2. Построим строку S=

Алгоритм поиска строки Бойера —Мура
Был разработан Робертом Бойером и и Джеем Муром в 1977г.
Считается наиболее
Алгоритм поиска строки Бойера —Мура
Был разработан Робертом Бойером и и Джеем Муром в 1977г.
Считается наиболее

Описание алгоритма.
Алгоритм основан на трёх идеях
Сканирование слева направо, сравнение справа налево.
2.
Описание алгоритма.
Алгоритм основан на трёх идеях
Сканирование слева направо, сравнение справа налево.
2.

Сканирование слева направо, сравнение справа налево.
Совмещается начало текста (строки) и шаблона,
Сканирование слева направо, сравнение справа налево.
Совмещается начало текста (строки) и шаблона,

Сканирование слева направо, сравнение справа налево
Если какой-то символ шаблона не совпадает
Сканирование слева направо, сравнение справа налево
Если какой-то символ шаблона не совпадает

Эвристика стоп-символа.
Пример: поиск слова «колокол».
Пусть первая же буква не совпала —
Эвристика стоп-символа.
Пример: поиск слова «колокол».
Пусть первая же буква не совпала —

Эвристика стоп-символа.
Если стоп-символа в шаблоне вообще нет, шаблон смещается за этот
Эвристика стоп-символа.
Если стоп-символа в шаблоне вообще нет, шаблон смещается за этот

Эвристика стоп-символа.
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа
Эвристика стоп-символа.
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа

Эвристика совпавшего суффикса
Если при сравнении строки и шаблона совпало один или
Эвристика совпавшего суффикса
Если при сравнении строки и шаблона совпало один или

Алгоритм Бойера —Мура
Обе эвристики требуют предварительных вычислений.
По шаблону поиска заполняются две
Алгоритм Бойера —Мура
Обе эвристики требуют предварительных вычислений.
По шаблону поиска заполняются две

Таблица стоп-символов
В таблице стоп-символов указывается последняя позиция в образце (исключая последнюю букву)
Таблица стоп-символов
В таблице стоп-символов указывается последняя позиция в образце (исключая последнюю букву)
![Таблица стоп-символов образец =«abcdadcd» Символ a b c d [остальные]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-44.jpg)
Таблица стоп-символов
образец =«abcdadcd»
Символ a b c d [остальные]
Последняя позиция 5 2
Таблица стоп-символов
образец =«abcdadcd»
Символ a b c d [остальные]
Последняя позиция 5 2

Таблица суффиксов
Для каждого возможного суффикса S шаблона указывается наименьшая величина, на которую
Таблица суффиксов
Для каждого возможного суффикса S шаблона указывается наименьшая величина, на которую
![Таблица суффиксов Например, для «abcdadcd» Суффикс [пустой] d cd dcd](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-46.jpg)
Таблица суффиксов
Например, для «abcdadcd»
Суффикс
[пустой] d cd dcd ... abcdadcd
Сдвиг
Таблица суффиксов
Например, для «abcdadcd»
Суффикс
[пустой] d cd dcd ... abcdadcd
Сдвиг

Таблица суффиксов
Если шаблон начинается и заканчивается одной и той же комбинацией
Таблица суффиксов
Если шаблон начинается и заканчивается одной и той же комбинацией

Быстрый алгоритм вычисления таблицы суффиксов
Использует префикс-функцию строки
m = length(suff)
pi[] = префикс-функция(suff)
pi1[]
Быстрый алгоритм вычисления таблицы суффиксов
Использует префикс-функцию строки
m = length(suff)
pi[] = префикс-функция(suff)
pi1[]
![Быстрый алгоритм вычисления таблицы суффиксов suffshift[0] соответствует всей совпавшей строке;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/355857/slide-49.jpg)
Быстрый алгоритм вычисления таблицы суффиксов
suffshift[0] соответствует всей совпавшей строке;
suffshift[m] — пустому суффиксу.
Так
Быстрый алгоритм вычисления таблицы суффиксов
suffshift[0] соответствует всей совпавшей строке;
suffshift[m] — пустому суффиксу.
Так

Пример работы алгоритма БМ
Искомый шаблон — «abbad».
Таблица стоп-символов:
Символ a b [остальные]
Позиция 4 3
Пример работы алгоритма БМ
Искомый шаблон — «abbad».
Таблица стоп-символов:
Символ a b [остальные]
Позиция 4 3

Пример работы алгоритма БМ
Накладываем образец на строку.
abeccaabadbabbad
abbad
Совпадения суффикса нет — таблица суффиксов
Пример работы алгоритма БМ
Накладываем образец на строку.
abeccaabadbabbad
abbad
Совпадения суффикса нет — таблица суффиксов

Пример работы алгоритма БМ
аbeccaabadbabbad
abbad
Символы 3—5 совпали, а второй — нет. Эвристика
Пример работы алгоритма БМ
аbeccaabadbabbad
abbad
Символы 3—5 совпали, а второй — нет. Эвристика

Пример работы алгоритма БМ
аbeccaabadbabbad
abbad
Совпадения суффикса нет. По таблице стоп-символов сдвигаем
Пример работы алгоритма БМ
аbeccaabadbabbad
abbad
Совпадения суффикса нет. По таблице стоп-символов сдвигаем

Алгоритм Бойера-Мура
Достоинства
Алгоритм Бойера-Мура на «хороших» данных очень быстр, а вероятность
Алгоритм Бойера-Мура
Достоинства
Алгоритм Бойера-Мура на «хороших» данных очень быстр, а вероятность

Алгоритм Бойера-Мура
Недостатки
не расширяются до приблизительного поиска, поиска любой строки из
Алгоритм Бойера-Мура
Недостатки
не расширяются до приблизительного поиска, поиска любой строки из
 Морской бой. Описание программы
Морской бой. Описание программы Разнообразие задач обработки информации
Разнообразие задач обработки информации ООП 8. Варианты наследования
ООП 8. Варианты наследования Монтаж та налагодження мікропроцесорних систем
Монтаж та налагодження мікропроцесорних систем Объекты текстового документа
Объекты текстового документа Информационный чат-бот универа
Информационный чат-бот универа Поколение Z. Игра по станциям Вместе сделаем Интернет безопасным
Поколение Z. Игра по станциям Вместе сделаем Интернет безопасным Измерение информации. Алфавитный подход к определению количества информации
Измерение информации. Алфавитный подход к определению количества информации Введение. Компиляция и запуск. (Тема 1.2)
Введение. Компиляция и запуск. (Тема 1.2) Контент-план. Вконтакте, Инстаграм, Фейсбук, Одноклассники
Контент-план. Вконтакте, Инстаграм, Фейсбук, Одноклассники Презентация к воспитательному мероприятию по физике и информатике Путешествие на планету Intel
Презентация к воспитательному мероприятию по физике и информатике Путешествие на планету Intel История ВТ и ОС. Назначение и функции операционных систем
История ВТ и ОС. Назначение и функции операционных систем Flexbox
Flexbox Системы автоматизированного проектирования технологических процессов (САПР ТП)
Системы автоматизированного проектирования технологических процессов (САПР ТП) Урок информатики Табличная форма представления информации
Урок информатики Табличная форма представления информации Подпрограммы: процедуры, функции
Подпрограммы: процедуры, функции Разработка проекта сети для предприятия с введением дополнительного сегмента
Разработка проекта сети для предприятия с введением дополнительного сегмента Презентация Системы счисления для учащихся 10 класса
Презентация Системы счисления для учащихся 10 класса История счета и систем счисления
История счета и систем счисления Информация и информационные процессы
Информация и информационные процессы Тема 2. Основные элементы языка Паскаль
Тема 2. Основные элементы языка Паскаль Шифр простой замены (моноалфавитный шифр). Полиалфовитный шифр
Шифр простой замены (моноалфавитный шифр). Полиалфовитный шифр Програмування на мові Паскаль. Частина II. Масиви
Програмування на мові Паскаль. Частина II. Масиви Информационная безопасность в интернете
Информационная безопасность в интернете Улучшение изображений
Улучшение изображений Графика в Windows (API – функции), обработка сообщений от клавиатуры, мыши, меню, полос прокрутки. (Тема 9)
Графика в Windows (API – функции), обработка сообщений от клавиатуры, мыши, меню, полос прокрутки. (Тема 9) Информационная безопасность
Информационная безопасность Двоичная система счисления.Двоичная арифметика
Двоичная система счисления.Двоичная арифметика