- Postgresql view. Index. Transactions. Acid properties

Содержание
- 2. POSTGRESQL INDEXES PostgreSQL indexes are effective tools to enhance database performance. Indexes help the database server
- 3. EXPLANATION Let’s assume we have a table: CREATE TABLE test1 ( Id INT, Content VARCHAR );
- 4. SYNTAX CREATE INDEX index_name ON table_name [USING method] ( column_name [ASC | DESC] [NULLS {FIRST |
- 5. CREATION EXAMPLE CREATE INDEX test1_id_index ON test1 (id); Name of the index is custom. To drop
- 6. EXAMPLE Gives us: To look on the query plan. Scanning a table sequentially.
- 7. EXAMPLE CONT. Creating a new index on title column in film table. Query plan gives: Scanning
- 8. LIST INDEXES: SELECT tablename, indexname, indexdef FROM pg_indexes WHERE schemaname = 'public’ ORDER BY tablename, indexname;
- 9. Gives a list of indexes in a film table: Place in memory for indexes
- 10. INDEXES WITH ORDER BY CLAUSE In addition to simply finding strings to return from a query,
- 11. YOU MAY ORDER BY ADDING: ASC, DESC, NULLS FIRST and / or NULLS LAST order when
- 12. UNIQUE INDEXES Indexes can also enforce the uniqueness of a value in a column or a
- 13. MULTICOLUMN INDEXES You can create an index on more than one column of a table. This
- 14. MULTICOLUMN INDEXES We have a table: CREATE TABLE test2 ( major INT, minor INT, name VARCHAR
- 15. INDEXES ON EXPRESSIONS (FUNCTIONAL-BASED INDEXES) An index can be created not only on a column of
- 16. Example2: SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith'; Index
- 17. REINDEX REINDEX [ ( VERBOSE ) ] { INDEX | TABLE | SCHEMA | DATABASE |
- 18. REINDEX VS. DROP INDEX & CREATE INDEX The REINDEX statement: Locks writes but not reads of
- 19. POSTGRESQL VIEW A view is a database object that is of a named (stored) query. When
- 20. POSTGRESQL VIEW BENEFITS A view can be very useful in some cases such as: A view
- 21. CREATING VIEWS CREATE [OR REPLACE] VIEW view_name AS SELECT column(s) FROM table(s) [WHERE condition(s)]; The OR
- 22. MODIFYING AND REMOVING VIEWS CREATE OR REPLACE view_name AS query ALTER VIEW view_name RENAME TO new_name;
- 23. EXAMPLE SELECT statement gives info about customers and films they took in rent:
- 24. EXAMPLE CONT. By creating a view the SELECT statement becomes shorter, but gives the same result:
- 25. POSTGRESQL UPDATABLE VIEWS A PostgreSQL view is updatable when it meets the following conditions: The defining
- 26. DBMS TRANSACTIONS Transaction is a fundamental concept in all DBMSs. A transaction is a single logical
- 27. ACID PROPERTIES.
- 28. WHY USE TRANSACTIONS The main selling point for transactions is that they are easy to handle.
- 29. ADVANTAGES OF USING TRANSACTIONS Chaining Events Together We can chain some events together using multiple transactions
- 30. ADVANTAGES OF USING TRANSACTIONS Flexibility Flexibility is another primary advantage of database transactions. Using transactions allows
- 31. Avoiding Data Loss Data loss is extremely common in the real world, with millions of people
- 32. Database Management Transactional databases make the jobs of many database administrators quite simple. Most transactional databases
- 33. POSTGRESQL TRANSACTIONS In PostgreSQL, a transaction is defined by a set of SQL commands surrounded by
- 34. There are following commands used to control transactions: BEGIN: to start a transaction. COMMIT: to save
- 35. PostgreSQL BEGIN command is used to initiate a transaction. A transaction is nothing but a unit
- 36. The COMMIT command is the transactional command used to save changes invoked by a transaction to
- 37. PostgreSQL ROLLBACK command is used to undo the changes done in transactions. As we know transactions
- 38. Savepoints allow you to selectively undo some parts of a transaction and commit all others. After
- 39. EXAMPLE Consider a bank database that contains information about customer accounts, as well as total amounts
- 40. EXAMPLE CONT. UPDATE accounts SET balance = balance - 100.00 WHERE name = 'Alice’; UPDATE accounts
- 42. Скачать презентацию

POSTGRESQL INDEXES
PostgreSQL indexes are effective tools to enhance database performance.
Indexes help
POSTGRESQL INDEXES
PostgreSQL indexes are effective tools to enhance database performance.
Indexes help
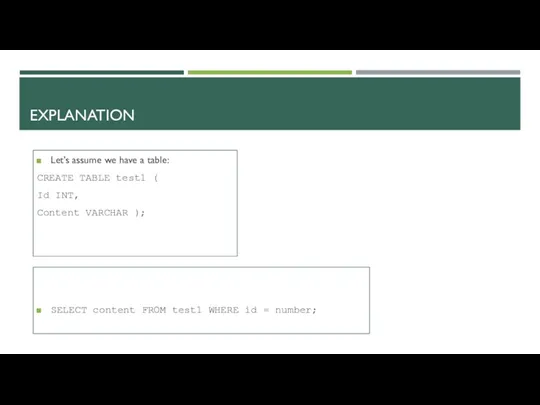
EXPLANATION
Let’s assume we have a table:
CREATE TABLE test1 (
Id INT,
Content VARCHAR
EXPLANATION
Let’s assume we have a table:
CREATE TABLE test1 (
Id INT,
Content VARCHAR
![SYNTAX CREATE INDEX index_name ON table_name [USING method] ( column_name](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/611029/slide-3.jpg)
SYNTAX
CREATE INDEX index_name ON table_name [USING method]
( column_name [ASC |
SYNTAX
CREATE INDEX index_name ON table_name [USING method]
( column_name [ASC |
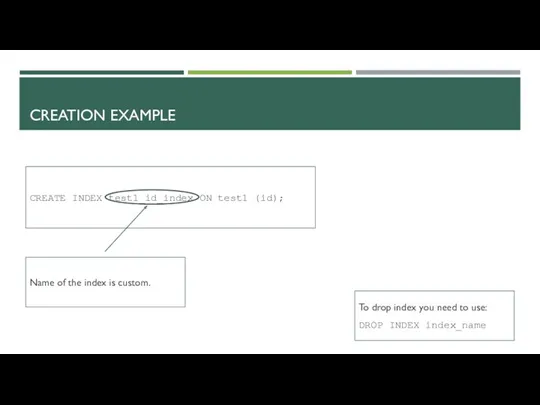
CREATION EXAMPLE
CREATE INDEX test1_id_index ON test1 (id);
Name of the index is
CREATION EXAMPLE
CREATE INDEX test1_id_index ON test1 (id);
Name of the index is
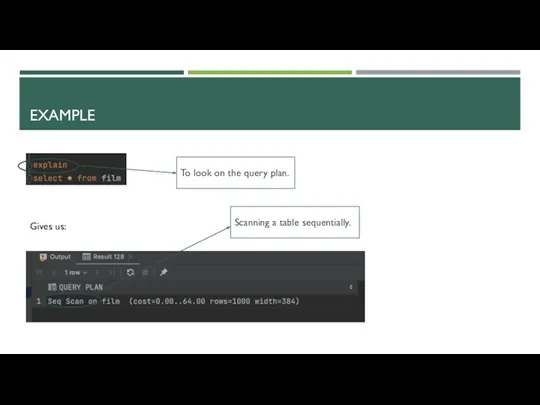
EXAMPLE
Gives us:
To look on the query plan.
Scanning a table sequentially.
EXAMPLE
Gives us:
To look on the query plan.
Scanning a table sequentially.
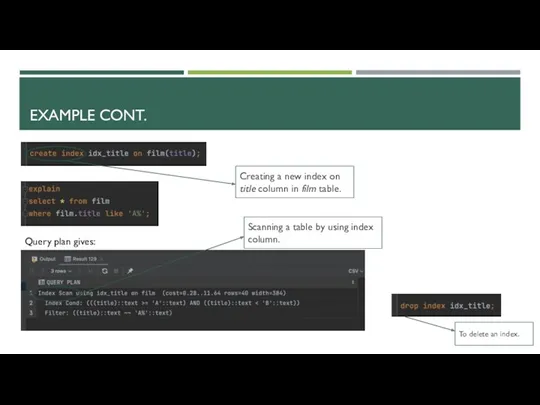
EXAMPLE CONT.
Creating a new index on title column in film table.
Query
EXAMPLE CONT.
Creating a new index on title column in film table.
Query

LIST INDEXES:
SELECT tablename,
indexname,
indexdef
FROM pg_indexes
WHERE schemaname = 'public’
LIST INDEXES:
SELECT tablename,
indexname,
indexdef
FROM pg_indexes
WHERE schemaname = 'public’
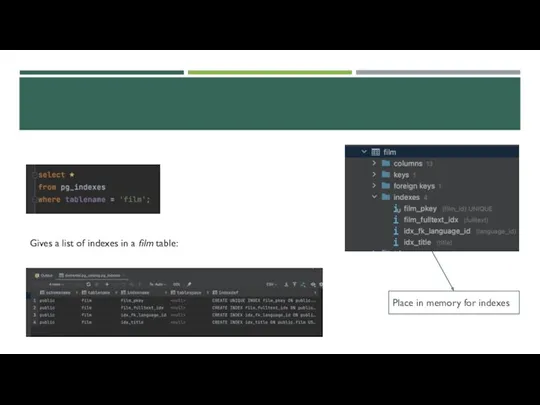
Gives a list of indexes in a film table:
Place in memory
Gives a list of indexes in a film table:
Place in memory

INDEXES WITH ORDER BY CLAUSE
In addition to simply finding strings to
INDEXES WITH ORDER BY CLAUSE
In addition to simply finding strings to
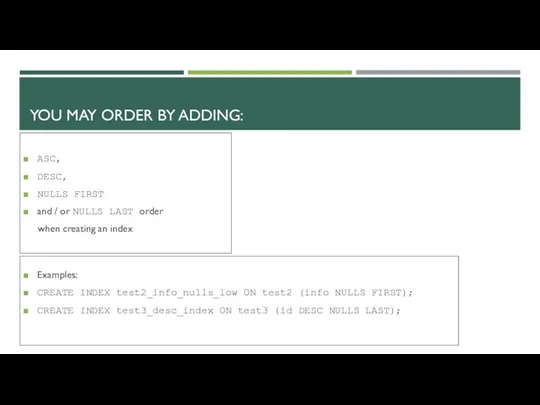
YOU MAY ORDER BY ADDING:
ASC,
DESC,
NULLS FIRST
and / or
YOU MAY ORDER BY ADDING:
ASC,
DESC,
NULLS FIRST
and / or

UNIQUE INDEXES
Indexes can also enforce the uniqueness of a value in
UNIQUE INDEXES
Indexes can also enforce the uniqueness of a value in

MULTICOLUMN INDEXES
You can create an index on more than one column
MULTICOLUMN INDEXES
You can create an index on more than one column
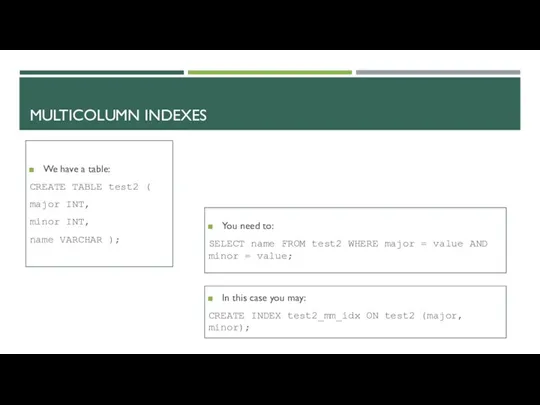
MULTICOLUMN INDEXES
We have a table:
CREATE TABLE test2 (
major INT,
minor
MULTICOLUMN INDEXES
We have a table:
CREATE TABLE test2 (
major INT,
minor

INDEXES ON EXPRESSIONS (FUNCTIONAL-BASED INDEXES)
An index can be created not only
INDEXES ON EXPRESSIONS (FUNCTIONAL-BASED INDEXES)
An index can be created not only
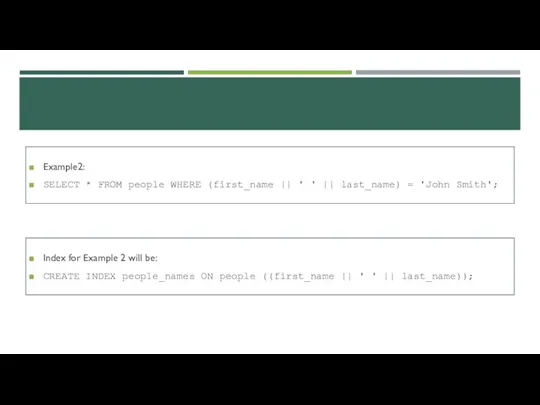
Example2:
SELECT * FROM people WHERE (first_name || ' ' || last_name)
Example2:
SELECT * FROM people WHERE (first_name || ' ' || last_name)
![REINDEX REINDEX [ ( VERBOSE ) ] { INDEX |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/611029/slide-16.jpg)
REINDEX
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE |
REINDEX
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE |

REINDEX VS. DROP INDEX & CREATE INDEX
The REINDEX statement:
Locks writes but not reads
REINDEX VS. DROP INDEX & CREATE INDEX
The REINDEX statement:
Locks writes but not reads

POSTGRESQL VIEW
A view is a database object that is of a named
POSTGRESQL VIEW
A view is a database object that is of a named

POSTGRESQL VIEW BENEFITS
A view can be very useful in some cases such
POSTGRESQL VIEW BENEFITS
A view can be very useful in some cases such
![CREATING VIEWS CREATE [OR REPLACE] VIEW view_name AS SELECT column(s)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/611029/slide-20.jpg)
CREATING VIEWS
CREATE [OR REPLACE] VIEW view_name AS
SELECT column(s)
FROM table(s)
CREATING VIEWS
CREATE [OR REPLACE] VIEW view_name AS
SELECT column(s)
FROM table(s)
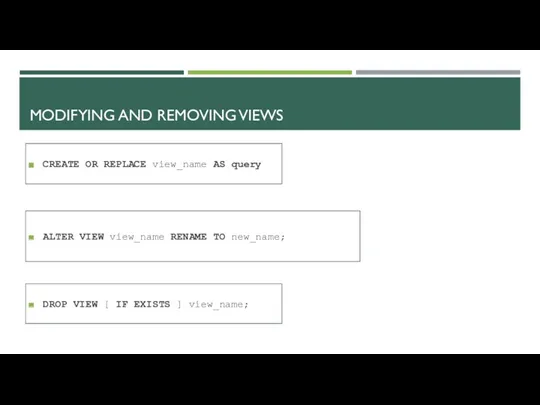
MODIFYING AND REMOVING VIEWS
CREATE OR REPLACE view_name AS query
ALTER VIEW view_name
MODIFYING AND REMOVING VIEWS
CREATE OR REPLACE view_name AS query
ALTER VIEW view_name
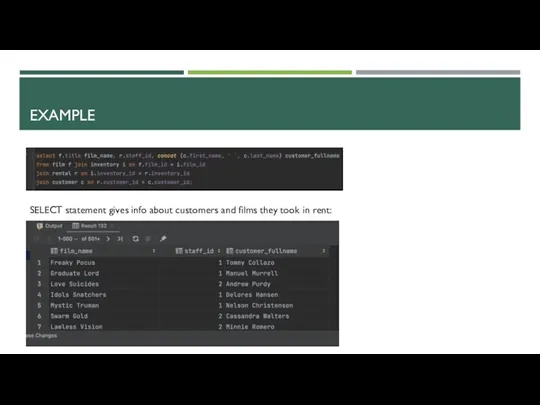
EXAMPLE
SELECT statement gives info about customers and films they took in
EXAMPLE
SELECT statement gives info about customers and films they took in

EXAMPLE CONT.
By creating a view the SELECT statement becomes shorter, but
EXAMPLE CONT.
By creating a view the SELECT statement becomes shorter, but

POSTGRESQL UPDATABLE VIEWS
A PostgreSQL view is updatable when it meets the
POSTGRESQL UPDATABLE VIEWS
A PostgreSQL view is updatable when it meets the

DBMS TRANSACTIONS
Transaction is a fundamental concept in all DBMSs.
A transaction
DBMS TRANSACTIONS
Transaction is a fundamental concept in all DBMSs.
A transaction
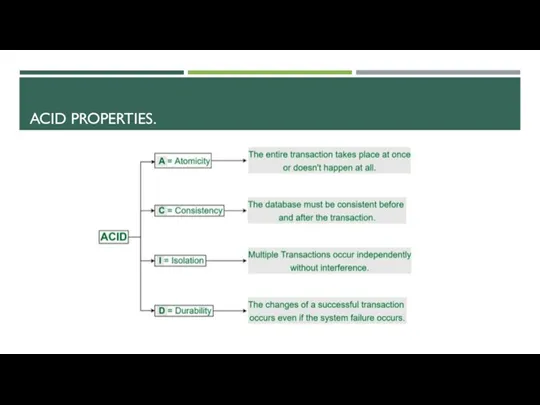
ACID PROPERTIES.
ACID PROPERTIES.

WHY USE TRANSACTIONS
The main selling point for transactions is that they
WHY USE TRANSACTIONS
The main selling point for transactions is that they

ADVANTAGES OF USING TRANSACTIONS
Chaining Events Together
We can chain some events together
ADVANTAGES OF USING TRANSACTIONS
Chaining Events Together
We can chain some events together

ADVANTAGES OF USING TRANSACTIONS
Flexibility
Flexibility is another primary advantage of database transactions.
Using transactions allows
ADVANTAGES OF USING TRANSACTIONS
Flexibility
Flexibility is another primary advantage of database transactions.
Using transactions allows

Avoiding Data Loss
Data loss is extremely common in the real world,
Avoiding Data Loss
Data loss is extremely common in the real world,

Database Management
Transactional databases make the jobs of many database administrators quite
Database Management
Transactional databases make the jobs of many database administrators quite
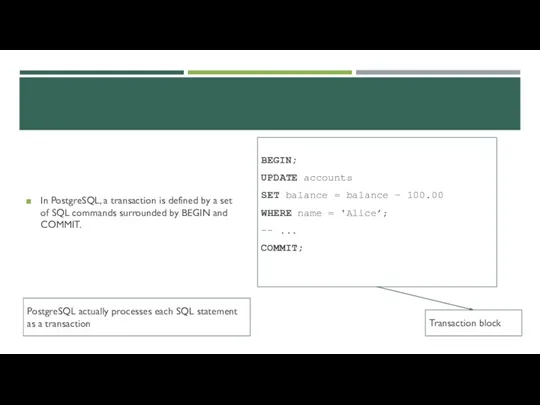
POSTGRESQL TRANSACTIONS
In PostgreSQL, a transaction is defined by a set of
POSTGRESQL TRANSACTIONS
In PostgreSQL, a transaction is defined by a set of

There are following commands used to control transactions:
BEGIN: to start a transaction.
COMMIT: to
There are following commands used to control transactions:
BEGIN: to start a transaction.
COMMIT: to

PostgreSQL BEGIN command is used to initiate a transaction.
A transaction is
PostgreSQL BEGIN command is used to initiate a transaction.
A transaction is
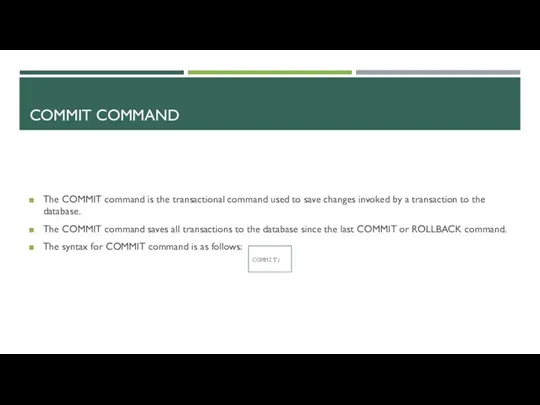
The COMMIT command is the transactional command used to save changes
The COMMIT command is the transactional command used to save changes

PostgreSQL ROLLBACK command is used to undo the changes done in transactions.
PostgreSQL ROLLBACK command is used to undo the changes done in transactions.

Savepoints allow you to selectively undo some parts of a transaction
Savepoints allow you to selectively undo some parts of a transaction

EXAMPLE
Consider a bank database that contains information about customer accounts, as
EXAMPLE
Consider a bank database that contains information about customer accounts, as

EXAMPLE CONT.
UPDATE accounts
SET balance = balance - 100.00
WHERE name
EXAMPLE CONT.
UPDATE accounts
SET balance = balance - 100.00
WHERE name
 Главные тренды
Главные тренды Подготовка эффективных презентаций
Подготовка эффективных презентаций Измерение информации
Измерение информации Комплекс по оптимизации аппаратно-программного обеспечения
Комплекс по оптимизации аппаратно-программного обеспечения презентация воскресенский
презентация воскресенский Комп'ютерні мережі
Комп'ютерні мережі Архитектура ЭВМ
Архитектура ЭВМ Косметология. Шаблон
Косметология. Шаблон Расчет геометрических параметров объекта
Расчет геометрических параметров объекта Презентация по информатике 6 класс Компьютер - универсальная машина для работы с информацией
Презентация по информатике 6 класс Компьютер - универсальная машина для работы с информацией Для чего нужны СМИ
Для чего нужны СМИ Apx UI. New UI. Marvell Confidential
Apx UI. New UI. Marvell Confidential Информационнная безопасность РФ и проблемы ее обеспечения в условиях межгосударственного противоборства
Информационнная безопасность РФ и проблемы ее обеспечения в условиях межгосударственного противоборства NTFS MFT Example
NTFS MFT Example Правила создания презентации в программе Power Point для школьников
Правила создания презентации в программе Power Point для школьников Лекция 2 – Основы языка C#
Лекция 2 – Основы языка C# Основы работы в системе MAPLE
Основы работы в системе MAPLE Процессы и потоки. Лекция 3
Процессы и потоки. Лекция 3 Дизайн сайта
Дизайн сайта Сети ISDN. Технология xDSL
Сети ISDN. Технология xDSL Инвестиции
Инвестиции Операциялық жүйелер. Операциялық жүйелердің даму тарихы
Операциялық жүйелер. Операциялық жүйелердің даму тарихы Интернет-сервис Антиплагиат. Ру
Интернет-сервис Антиплагиат. Ру Притяжение. Действие магнита
Притяжение. Действие магнита Основы программирования. Лабораторная работа №5. Рекурсия
Основы программирования. Лабораторная работа №5. Рекурсия Практическое применение 3D-моделирования
Практическое применение 3D-моделирования Модели CatBoost в ClickHouse
Модели CatBoost в ClickHouse Программа MS Access
Программа MS Access